上一篇,我们已经知道机器学习是将输入(比如图像)映射到目标(比如数字“4”)的过程。这一过程是通过观察许多输入和目标的示例来完成的。
我们还知道,深度神经网络通过一系列简单的数据变换(层)来实现这种输入到目标的映射,这些数据变换都是通过观察示例学习得到的。
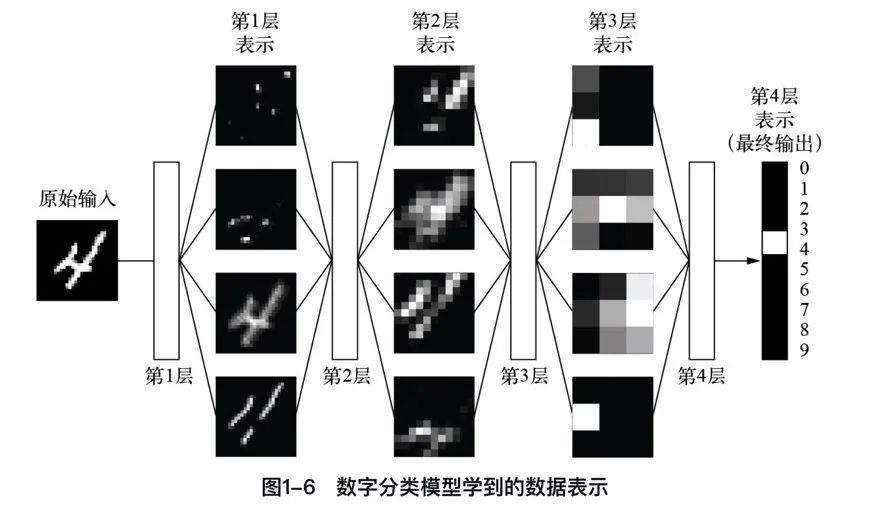
下面我们通过三张图来具体看一下这种学习过程是如何发生的,即深度学习的工作原理是什么。
一、权重和参数
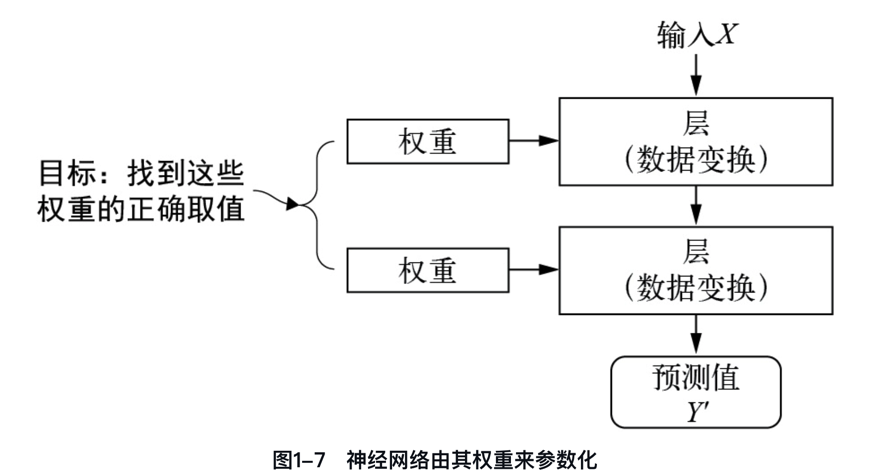
如何理解神经网络由其权重来参数化?神经网络由其权重参数化,意味着权重决定了网络如何处理输入数据并产生输出,且这些权重通过训练过程进行调整以优化网络性能。
深度学习中的“学习”的意思就是为神经网络的所有层找到一组权重值,使得该神经网络能够将每个示例的输入与其目标正确地一一对应。
“一图 + 一句话”彻底搞懂什么是权重和参数。
“在神经网络中,每层对输入数据所做的具体操作保存在该层的权重(weight)中,权重实质上就是一串数字。权重有时也被称为该层的参数(parameter)。”
二、损失函数
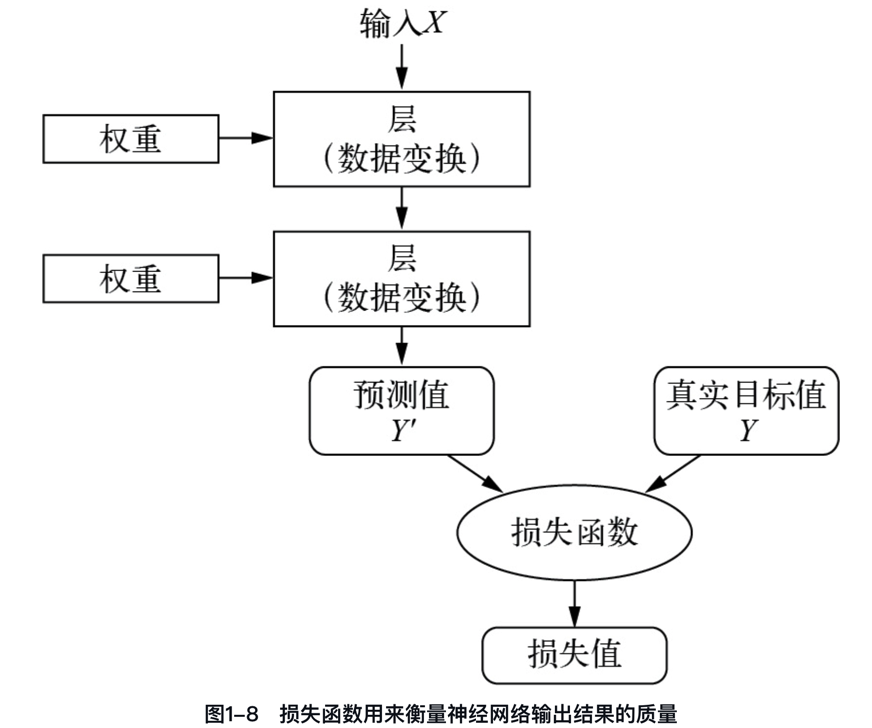
如何使用损失函数寻找神经网络的参数?一个深度神经网络可能包含上千万个参数(GPT-3参数有1750亿),找到所有参数的正确取值似乎是一项非常艰巨的任务,特别是考虑到修改一个参数值将影响其他所有参数的行为。
若要控制某个事物,首先需要能够观察它。若要控制神经网络的输出,需要能够衡量该输出与预期结果之间的距离。
损失函数如何衡量神经网络输出结果的质量?损失函数衡量神经网络预测与真实目标之间的距离,用于评估网络效果并指导控制输出。
“一图 + 一句话”彻底搞懂什么是损失函数。
“损失函数的输入是神经网络的预测值与真实目标值(你希望神经网络输出的结果),它的输出是一个距离值,反映该神经网络在这个示例上的效果好坏。”
三、优化器和反向传播
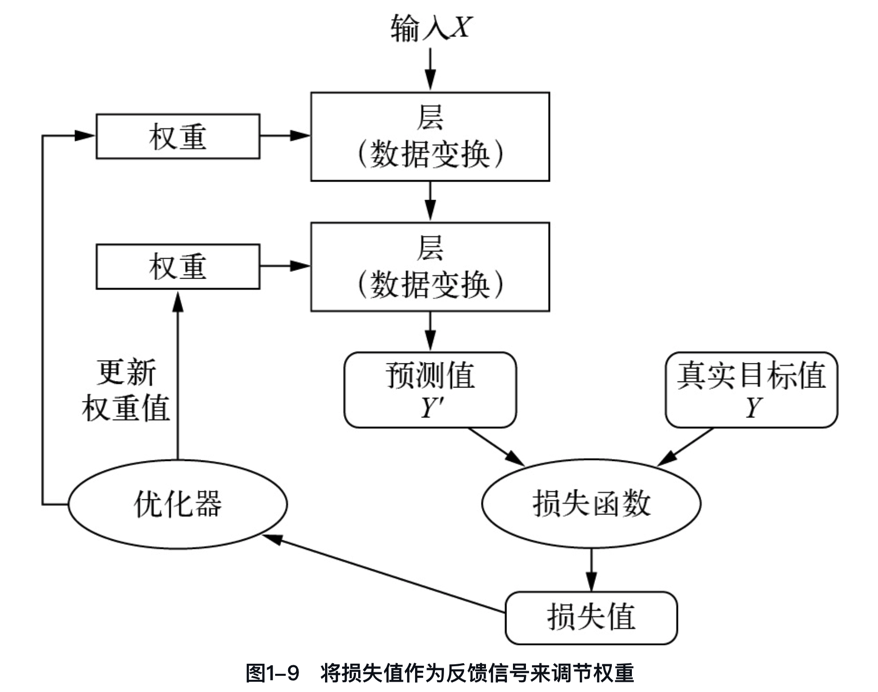
如何使用优化器和反向传播将损失值作为反馈信号来调节权重?深度学习的核心技巧是利用损失值作为反馈,通过优化器和反向传播算法微调权重,以降低损失并改进模型性能。
一开始神经网络的权重是随机赋值,因此神经网络仅实现了一系列随机变换,其输出值自然与理想结果相去甚远,相应地,损失值也很大。但是,神经网络每处理一个示例,权重值都会向着正确的方向微调,损失值也相应减小。
“一图 + 一句话”彻底搞懂什么是优化器和反向传播。
“优化器和反向传播通过迭代调整神经网络权重,最小化损失函数,使输出值接近目标值,实现网络训练。”
资料分享
为了方便大家学习,我整理了一份100G人工智能学习资料
包含数学与Python编程基础、深度学习+机器学习入门到实战,计算机视觉+自然语言处理+大模型资料合集,不仅有配套教程讲义还有对应源码数据集,更有零基础入门学习路线,不论你处于什么阶段,这份资料都能帮助你更好地入门到进阶。
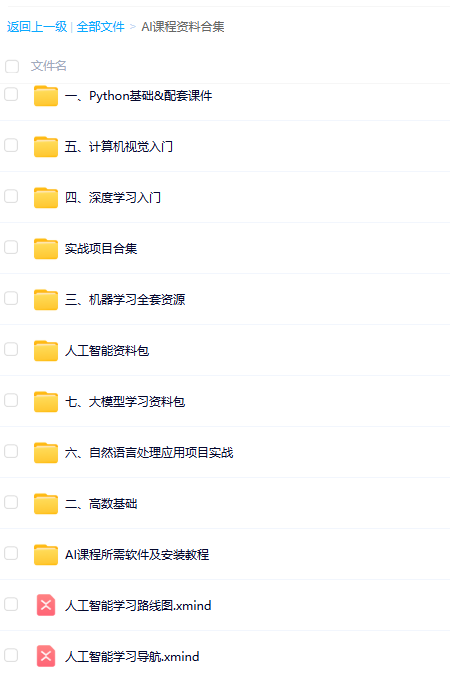
需要的兄弟可以按照这个图的方式免费获取







】)




Canvas基础(万字图文讲解))

)

)


