目录
引言:
自链接查询:
递归查询:
编写service接口实现:
引言:
看下图,这是 course_category 课程分类表的结构:

这张表是一个树型结构,通过父结点id将各元素组成一个树。
我们可以看下该表的数据,下图是一部分数据:
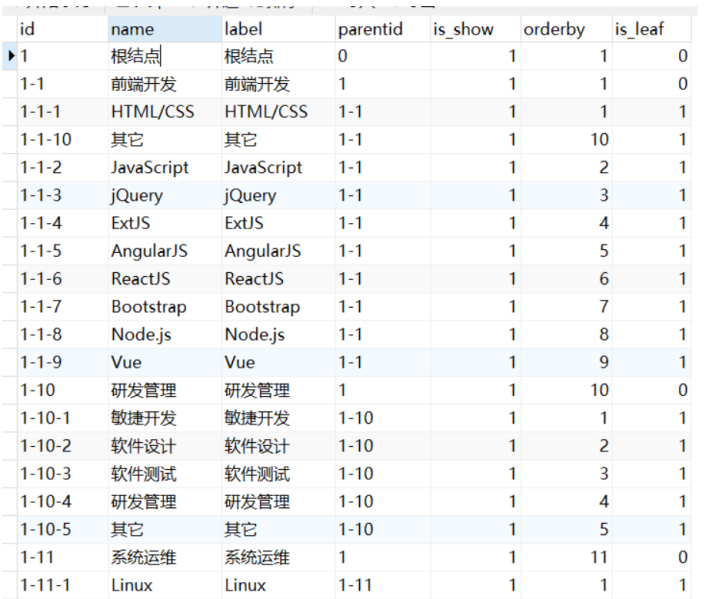
现在的需求是需要在内容管理服务中编写一个接口读取该课程分类表的数据,组成一个树型结构返回给前端。
树形表的根本在于它有一个 parentid 字段,而这个字段是为了记录当前结点的父节点的 id 值。所以每一个树型表都会有一个这样的字段。
通过查阅接口文档,此接口要返回全部课程分类,以树型结构返回,如下所示:
[{"childrenTreeNodes" : [{"childrenTreeNodes" : null,"id" : "1-1-1","isLeaf" : null,"isShow" : null,"label" : "HTML/CSS","name" : "HTML/CSS","orderby" : 1,"parentid" : "1-1"},{"childrenTreeNodes" : null,"id" : "1-1-2","isLeaf" : null,"isShow" : null,"label" : "JavaScript","name" : "JavaScript","orderby" : 2,"parentid" : "1-1"},{"childrenTreeNodes" : null,"id" : "1-1-3","isLeaf" : null,"isShow" : null,"label" : "jQuery","name" : "jQuery","orderby" : 3,"parentid" : "1-1"},{"childrenTreeNodes" : null,"id" : "1-1-4","isLeaf" : null,"isShow" : null,"label" : "ExtJS","name" : "ExtJS","orderby" : 4,"parentid" : "1-1"},{"childrenTreeNodes" : null,"id" : "1-1-5","isLeaf" : null,"isShow" : null,"label" : "AngularJS","name" : "AngularJS","orderby" : 5,"parentid" : "1-1"},{"childrenTreeNodes" : null,"id" : "1-1-6","isLeaf" : null,"isShow" : null,"label" : "ReactJS","name" : "ReactJS","orderby" : 6,"parentid" : "1-1"},{"childrenTreeNodes" : null,"id" : "1-1-7","isLeaf" : null,"isShow" : null,"label" : "Bootstrap","name" : "Bootstrap","orderby" : 7,"parentid" : "1-1"},{"childrenTreeNodes" : null,"id" : "1-1-8","isLeaf" : null,"isShow" : null,"label" : "Node.js","name" : "Node.js","orderby" : 8,"parentid" : "1-1"},{"childrenTreeNodes" : null,"id" : "1-1-9","isLeaf" : null,"isShow" : null,"label" : "Vue","name" : "Vue","orderby" : 9,"parentid" : "1-1"},{"childrenTreeNodes" : null,"id" : "1-1-10","isLeaf" : null,"isShow" : null,"label" : "其它","name" : "其它","orderby" : 10,"parentid" : "1-1"}],"id" : "1-1","isLeaf" : null,"isShow" : null,"label" : "前端开发","name" : "前端开发","orderby" : 1,"parentid" : "1"},{"childrenTreeNodes" : [{"childrenTreeNodes" : null,"id" : "1-2-1","isLeaf" : null,"isShow" : null,"label" : "微信开发","name" : "微信开发","orderby" : 1,"parentid" : "1-2"},{"childrenTreeNodes" : null,"id" : "1-2-2","isLeaf" : null,"isShow" : null,"label" : "iOS","name" : "iOS","orderby" : 2,"parentid" : "1-2"},{"childrenTreeNodes" : null,"id" : "1-2-3","isLeaf" : null,"isShow" : null,"label" : "手游开发","name" : "手游开发","orderby" : 3,"parentid" : "1-2"},{"childrenTreeNodes" : null,"id" : "1-2-4","isLeaf" : null,"isShow" : null,"label" : "Swift","name" : "Swift","orderby" : 4,"parentid" : "1-2"},{"childrenTreeNodes" : null,"id" : "1-2-5","isLeaf" : null,"isShow" : null,"label" : "Android","name" : "Android","orderby" : 5,"parentid" : "1-2"},{"childrenTreeNodes" : null,"id" : "1-2-6","isLeaf" : null,"isShow" : null,"label" : "ReactNative","name" : "ReactNative","orderby" : 6,"parentid" : "1-2"},{"childrenTreeNodes" : null,"id" : "1-2-7","isLeaf" : null,"isShow" : null,"label" : "Cordova","name" : "Cordova","orderby" : 7,"parentid" : "1-2"},{"childrenTreeNodes" : null,"id" : "1-2-8","isLeaf" : null,"isShow" : null,"label" : "其它","name" : "其它","orderby" : 8,"parentid" : "1-2"}],"id" : "1-2","isLeaf" : null,"isShow" : null,"label" : "移动开发","name" : "移动开发","orderby" : 2,"parentid" : "1"}]而上边的数据格式是一个数组结构,数组的元素即为分类信息,分类信息设计两级分类,第一级的分类信息示例如下:
"id" : "1-2",
"isLeaf" : null,
"isShow" : null,
"label" : "移动开发",
"name" : "移动开发",
"orderby" : 2,
"parentid" : "1"第二级的分类是第一级分类中childrenTreeNodes属性,它是一个数组结构:
{
"id" : "1-2",
"isLeaf" : null,
"isShow" : null,
"label" : "移动开发",
"name" : "移动开发",
"orderby" : 2,
"parentid" : "1",
"childrenTreeNodes" : [{"childrenTreeNodes" : null,"id" : "1-2-1","isLeaf" : null,"isShow" : null,"label" : "微信开发","name" : "微信开发","orderby" : 1,"parentid" : "1-2"}}所以我们采用下面的model来定义这张表:
package com.xuecheng.content.model.dto;import com.xuecheng.content.model.po.CourseCategory;
import lombok.Data;import java.io.Serializable;
import java.util.List;/*** @description 课程分类树型结点dto* @version 1.0*/
// Serializable 网络传输序列化
@Data
public class CourseCategoryTreeDto extends CourseCategory implements Serializable {List<CourseCategoryTreeDto> childrenTreeNodes;
}
接口定义如下:
package com.xuecheng.content.api;import com.xuecheng.content.model.dto.CourseCategoryTreeDto;
import com.xuecheng.content.service.CourseCategoryService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.List;/*** <p>* 数据字典 前端控制器* </p>*/
@Slf4j
@RestController
public class CourseCategoryController {@GetMapping("/course-category/tree-nodes")public List<CourseCategoryTreeDto> queryTreeNodes() {return null;}
}自链接查询:
课程分类表是一个树型结构,其中parentid字段为父结点ID,它是树型结构的标志字段。
如果树的层级固定可以使用表的自链接去查询,比如:我们只查询两级课程分类,可以用下边的SQL:
select * from course_category oneinner join course_category two on one.id = two.parentid我们让 course_category 表去 inner join 自己,之后起别名,one代表一级节点分类,two代表二级节点分类,所以通过查询 二级节点的父节点id = 一级节点id,这个就是查询条件。
如果不想显示根结点并且排序,参考下面代码:
selectone.id one_id,one.name one_name,one.parentid one_parentid,one.orderby one_orderby,one.label one_label,two.id two_id,two.name two_name,two.parentid two_parentid,two.orderby two_orderby,two.label two_labelfrom course_category oneinner join course_category two on one.id = two.parentidwhere one.parentid = 1and one.is_show = 1and two.is_show = 1order by one.orderby,two.orderby而如果我们还想要通过指定节点来查询另一张表的对应的数据,需要用到左右关联。

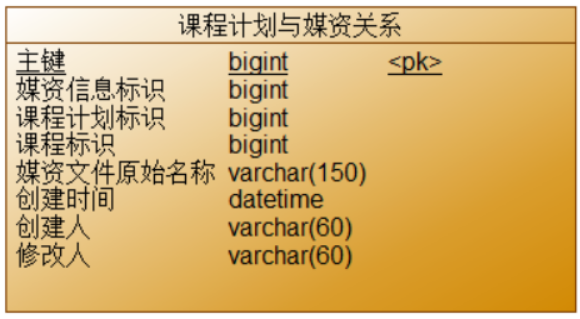
如上两张图,左侧图是课程计划(树型表),每个课程计划都有所属课程。每个课程的课程计划有两个级别,第一级为大章节,grade 为1、第二级为小章节,grade 为2。第二级的 parentid 为第一级的 id。课程计划的显示顺序根据排序字段去显示。根据业务流程中的界面原型,课程计划列表展示时还有课程计划关联的视频信息。
课程计划关联的视频信息在 teachplan_media 表,两张表是一对一关系,每个课程计划只能在teachplan_media表中存在一个视频。
我们的需求是无论关联不关联都必须查出课程计划(即使没有课程视频也要查出课程计划),所以选择使用左关联(left join)。
selectone.id one_id,one.pname one_pname,one.parentid one_parentid,one.grade one_grade,one.media_type one_mediaType,one.start_time one_stratTime,one.end_time one_endTime,one.orderby one_orderby,one.course_id one_courseId,one.course_pub_id one_coursePubId,two.id two_id,two.pname two_pname,two.parentid two_parentid,two.grade two_grade,two.media_type two_mediaType,two.start_time two_stratTime,two.end_time two_endTime,two.orderby two_orderby,two.course_id two_courseId,two.course_pub_id two_coursePubId,m1.media_fileName mediaFilename,m1.id teachplanMeidaId,m1.media_id mediaIdfrom teachplan oneINNER JOIN teachplan two on one.id = two.parentidLEFT JOIN teachplan_media m1 on m1.teachplan_id = two.idwhere one.parentid = 0 and one.course_id=#{value}order by one.orderby,two.orderby首先使用inner join自链接查询树型表,随后使用左关联根据课程视频的teachplan_id = 课程计划的id 来找到每个课程计划(二级分类)对应的课程视频。
 目前我们想要的数据是如上图,而目前查询到的数据如下图:
目前我们想要的数据是如上图,而目前查询到的数据如下图:
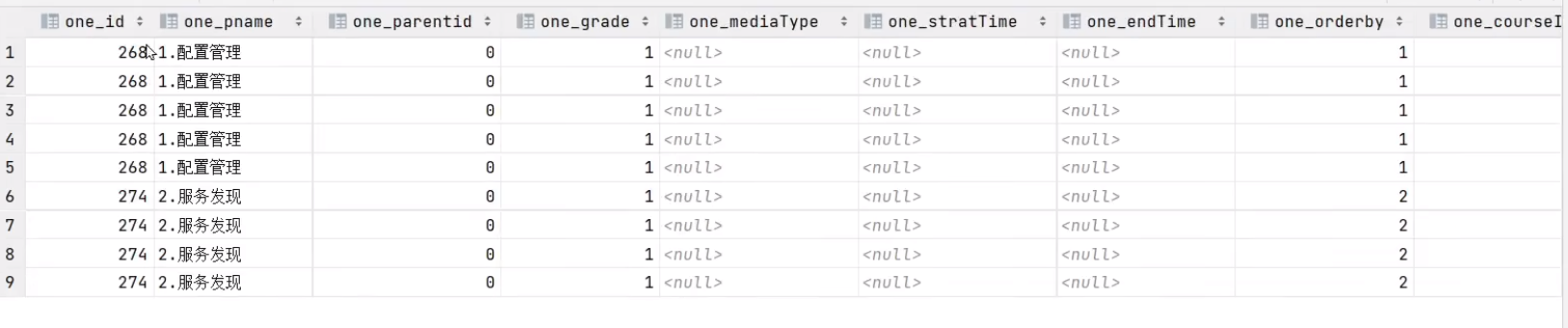
因为字段名与属性名不一致,所以需要定义 resultMap 手动映射。而且我们想要的数据格式内还有子节点,所以需要使用一对多映射(Collection),我们的数据模型如下图:
@Data
@ToString
public class TeachplanDto extends Teachplan {//课程计划关联的媒资信息TeachplanMedia teachplanMedia;//子结点List<TeachplanDto> teachPlanTreeNodes;
}所以 property 映射的属性就是 teachPlanTreeNodes,而 ofType 的 List 中的对象类型就是 TeachplanDto。
<!-- 一级中包含多个二级数据 -->
<collection property="teachPlanTreeNodes" ofType="com.xuecheng.content.model.dto.TeachplanDto">而在小章节内有一个视频,所以用到一对一映射(Assoiation),其中 property映射的就是"teachplanMedia"属性,也就是课程视频;而 javaType的类型就是"com.xuecheng.content.model.po.TeachplanMedia"。
<association property="teachplanMedia" javaType="com.xuecheng.content.model.po.TeachplanMedia">下面是对应的mapper.xml文件:(通过单次 SQL 关联查询 + 结果集映射,一次性获取所有层级数据,减少数据库交互。)
<!-- 课程分类树型结构查询映射结果 -->
<resultMap id="treeNodeResultMap" type="com.xuecheng.content.model.dto.TeachplanDto"><!-- 一级数据映射 --><id column="one_id" property="id" /><result column="one_pname" property="pname" /><result column="one_parentid" property="parentid" /><result column="one_grade" property="grade" /><result column="one_mediaType" property="mediaType" /><result column="one_stratTime" property="stratTime" /><result column="one_endTime" property="endTime" /><result column="one_orderby" property="orderby" /><result column="one_courseId" property="courseId" /><result column="one_coursePubId" property="coursePubId" /><!-- 一级中包含多个二级数据 --><collection property="teachPlanTreeNodes" ofType="com.xuecheng.content.model.dto.TeachplanDto"><!-- 二级数据映射 --><id column="two_id" property="id" /><result column="two_pname" property="pname" /><result column="two_parentid" property="parentid" /><result column="two_grade" property="grade" /><result column="two_mediaType" property="mediaType" /><result column="two_stratTime" property="stratTime" /><result column="two_endTime" property="endTime" /><result column="two_orderby" property="orderby" /><result column="two_courseId" property="courseId" /><result column="two_coursePubId" property="coursePubId" /><association property="teachplanMedia" javaType="com.xuecheng.content.model.po.TeachplanMedia"><result column="teachplanMeidaId" property="id" /><result column="mediaFilename" property="mediaFilename" /><result column="mediaId" property="mediaId" /><result column="two_id" property="teachplanId" /><result column="two_courseId" property="courseId" /><result column="two_coursePubId" property="coursePubId" /></association></collection>
</resultMap>
<!--课程计划树型结构查询-->
<select id="selectTreeNodes" resultMap="treeNodeResultMap" parameterType="long" >selectone.id one_id,one.pname one_pname,one.parentid one_parentid,one.grade one_grade,one.media_type one_mediaType,one.start_time one_stratTime,one.end_time one_endTime,one.orderby one_orderby,one.course_id one_courseId,one.course_pub_id one_coursePubId,two.id two_id,two.pname two_pname,two.parentid two_parentid,two.grade two_grade,two.media_type two_mediaType,two.start_time two_stratTime,two.end_time two_endTime,two.orderby two_orderby,two.course_id two_courseId,two.course_pub_id two_coursePubId,m1.media_fileName mediaFilename,m1.id teachplanMeidaId,m1.media_id mediaIdfrom teachplan oneINNER JOIN teachplan two on one.id = two.parentidLEFT JOIN teachplan_media m1 on m1.teachplan_id = two.idwhere one.parentid = 0 and one.course_id=#{value}order by one.orderby,two.orderby
</select>递归查询:
如果树的层级不确定,此时可以使用MySQL递归实现,使用with语法,如下:
WITH [RECURSIVE]cte_name [(col_name [, col_name] ...)] AS (subquery)[, cte_name [(col_name [, col_name] ...)] AS (subquery)] ...cte_name :公共表达式的名称,可以理解为表名,用来表示as后面跟着的子查询
col_name :公共表达式包含的列名,可以写也可以不写
下边是一个递归的简单例子:
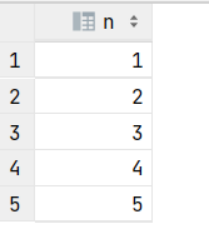
with RECURSIVE t1 AS
(SELECT 1 as nUNION ALLSELECT n + 1 FROM t1 WHERE n < 5
)
SELECT * FROM t1;通过上述SQL,其中 t1 相当于一个表名,select 1 相当于这个表的初始值,这里使用UNION ALL 不断将每次递归得到的数据加入到表中,而 n<5 为递归执行的条件,当 n>=5 时结束递归调用:
下边我们使用递归实现课程分类的查询:
with recursive t1 as (
select * from course_category p where id= '1'
union allselect t.* from course_category t inner join t1 on t1.id = t.parentid
)
select * from t1 order by t1.id, t1.orderby最开始根结点id=1,然后通过 union all 不断将每次递归得到的数据加入到 t1 表中(t1表存储查完的数据),随后向下递归,使用 inner join 去拿 course_category 表关联 t1 表,来查询当前 t1 表下的树枝,所以查询 t1.id = course_category.parentid,因为 parentid 中记录的是当前结点的父节点。
所以查询完的数据最终会保存到 t1表并且使用 order by 按照顺序输出。
查询结果如下:
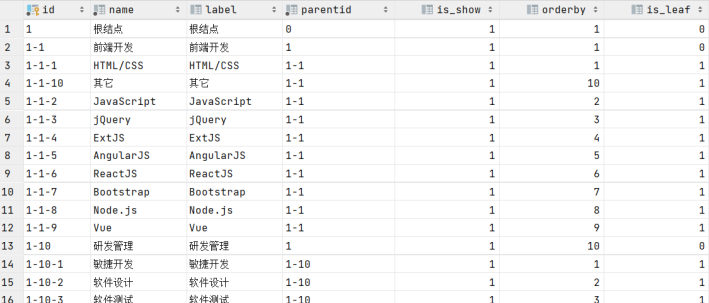
t1表中初始的数据是id等于1的记录,即根结点。
那如何向上递归?
下边的sql实现了向上递归:
with recursive t1 as (
select * from course_category p where id= '1-1-1'
union allselect t.* from course_category t inner join t1 on t1.parentid = t.id
)
select * from t1 order by t1.id, t1.orderby初始节点为1-1-1,通过递归找到它的父级节点,父级节点包括所有级别的节点。
以上是我们研究了树型表的查询方法,通过递归的方式查询课程分类比较灵活,因为它可以不限制层级。
mysql为了避免无限递归默认递归次数为1000,可以通过设置cte_max_recursion_depth参数增加递归深度,还可以通过max_execution_time限制执行时间,超过此时间也会终止递归操作。
mysql递归相当于在存储过程中执行若干次sql语句,java程序仅与数据库建立一次链接执行递归操作,所以只要控制好递归深度,控制好数据量性能就没有问题。
思考:如果java程序在递归操作中连接数据库去查询数据组装数据,这个性能高吗?
下边我们可自定义mapper方法查询课程分类,最终将查询结果映射到List<CourseCategoryTreeDto>中。
生成课程分类表的mapper文件并拷贝至内容管理模块 的service工程中。
public interface CourseCategoryMapper extends BaseMapper<CourseCategory> {public List<CourseCategoryTreeDto> selectTreeNodes(String id);
}找到对应的mapper.xml文件,编写sql语句:
<select id="selectTreeNodes" resultType="com.xuecheng.content.model.dto.CourseCategoryTreeDto" parameterType="string">with recursive t1 as (select * from course_category p where id= #{id}union allselect t.* from course_category t inner join t1 on t1.id = t.parentid)select * from t1 order by t1.id, t1.orderby</select>编写service接口实现:
由于现在我们查询是直接将所有的数据查出,而没有适应接口所返回的数据格式,所以我们要在Service层处理。
所以现在分为两步进行:
- 使用刚刚定义的mapper接口查询数据
- 将查询到的数据封装成 List<CourseCategoryTreeDto> 数据格式:
@Data public class CourseCategoryTreeDto extends CourseCategory implements Serializable {List<CourseCategoryTreeDto> childrenTreeNodes; }
下面我们讲述如何将查询到的数据封装成 List<CourseCategoryTreeDto> 数据格式。
- 将list转为map,key就是结点id,value就是CourseCategoryTreeDto对象,目的是为了方面从map获取结点。
- 从头遍历List<CourseCategoryTreeDto>,将遍历到的子节点放在父节点的childrenTreeNodes中。
首先List转map可以使用stream流,并给key、value赋值,但是也会遇到两个key重复,这个时候以第二个key为主,随后在使用filter将根结点过滤(判断查询id与当前id是否相等来判断是否为根结点,因为是通过根结点查询) :
//将list转map,以备使用,排除根节点
Map<String, CourseCategoryTreeDto> mapTemp = courseCategoryTreeDtos.stream().filter(item->!id.equals(item.getId())).collect(Collectors.toMap(key -> key.getId(), value -> value, (key1, key2) -> key2));先定义一个带返回的List数组对象:
List<CourseCategoryTreeDto> categoryTreeDtos = new ArrayList<>();随后同样使用stream流进行处理,如果当前节点的parentid=根结点的id,那么就将其放进 List<CourseCategoryTreeDto> categoryTreeDtos ,随后在判断当前结点是否有父节点(通过map的get(parentid)方法找),如果没有父节点就new一个集合放入(因为要向该集合中放入其子节点),如果要是找到其父节点,那么就将该节点放入其父节点的集合中。
下面是完整代码:
package com.xuecheng.content.service.impl;import com.xuecheng.content.mapper.CourseCategoryMapper;
import com.xuecheng.content.model.dto.CourseCategoryTreeDto;
import com.xuecheng.content.service.CourseCategoryService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;@Slf4j
@Service
public class CourseCategoryServiceImpl implements CourseCategoryService {@AutowiredCourseCategoryMapper courseCategoryMapper;public List<CourseCategoryTreeDto> queryTreeNodes(String id) {List<CourseCategoryTreeDto> courseCategoryTreeDtos = courseCategoryMapper.selectTreeNodes(id);//将list转map,以备使用,排除根节点Map<String, CourseCategoryTreeDto> mapTemp = courseCategoryTreeDtos.stream().filter(item->!id.equals(item.getId())).collect(Collectors.toMap(key -> key.getId(), value -> value, (key1, key2) -> key2));//最终返回的listList<CourseCategoryTreeDto> categoryTreeDtos = new ArrayList<>();//依次遍历每个元素,排除根节点courseCategoryTreeDtos.stream().filter(item->!id.equals(item.getId())).forEach(item->{if(item.getParentid().equals(id)){categoryTreeDtos.add(item);}//找到当前节点的父节点CourseCategoryTreeDto courseCategoryTreeDto = mapTemp.get(item.getParentid());if(courseCategoryTreeDto!=null){if(courseCategoryTreeDto.getChildrenTreeNodes() ==null){courseCategoryTreeDto.setChildrenTreeNodes(new ArrayList<CourseCategoryTreeDto>());}//下边开始往ChildrenTreeNodes属性中放子节点courseCategoryTreeDto.getChildrenTreeNodes().add(item);}});return categoryTreeDtos;}}




)








)
到未来自主Agent(L4))

)

