1. 引言
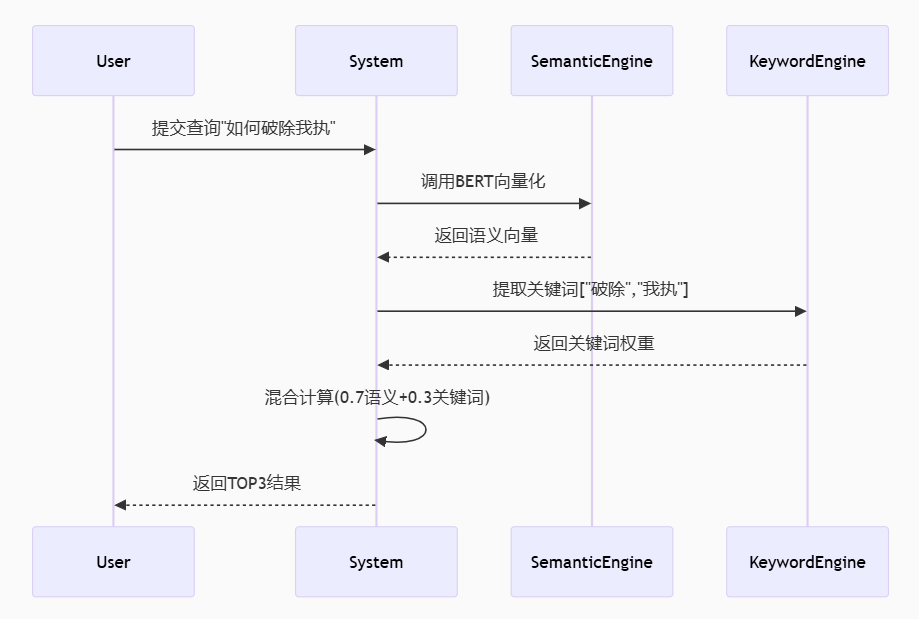
构建一个基于BERT与混合检索策略的智能问答系统,通过深度学习与传统检索技术的融合,解决了心法领域知识检索中的三个关键问题:(1)专业术语的语义理解不足;(2)问答匹配精度低;(3)检索结果多样性差。
2. 方法
2.1. 深度语义理解模块
BERT是预训练语言模型,基于 Transformer 架构,通过双向 Transformer 编码来学习文本的深层语义表示。BERT 的核心创新在于其双向训练方式,能够同时理解上下文的关系,常用于多项自然语言处理任务。
采用BERT最后四层隐藏状态的加权融合策略,将问题转换为向量表示。
- 选取了 BERT 模型的最后四层隐藏状态
- 定义了各层的权重( [0.15, 0.25, 0.35, 0.25]),并进行了归一化处理
- 提取了各层隐藏状态中 CLS 标记的向量表示
- 对各层的 CLS 向量进行加权求和
2.2. 混合检索算法
混合检索算法是结合符号检索(如关键词匹配、规则匹配)和语义检索(如向量匹配、深度学习模型)优势的检索技术,旨在平衡检索的准确性、召回率和语义理解能力。它解决了单一检索方式的局限性,如关键词检索无法理解语义,纯语义检索可能遗漏精确匹配结果;应用于信息检索、推荐系统、问答系统等领域。
2.2.1. 语义-关键词协同架构
既保证对 “显性关键词” 的精准匹配,又能理解 “隐性语义”(如同义词、上下文关联),最终提升检索的召回率和准确率,即不漏掉相关结果、返回更相关的结果。
语义检索通道:
- 原理:基于 “隐性语义理解”,将查询和文档转换为向量,通过向量相似度匹配语义相关内容,不依赖字面关键词。
- 优势:能理解同义词、上下文语义、跨语言检索。
- 局限性:可能引入语义相似但无关的 “噪声结果”(如 “猫的饲养方法” 匹配 “狗的训练技巧”)、计算成本高于关键词检索。
关键词检索通道:
- 原理:基于 “显性符号匹配”,聚焦查询中的核心关键词,通过精确匹配或模糊匹配定位相关内容。
- 优势:速度快、可解释性强、对专有名词、人名、地名的检索精准。
- 局限性:无法处理同义词、语义歧义、长句上下文关联(代词的指向)
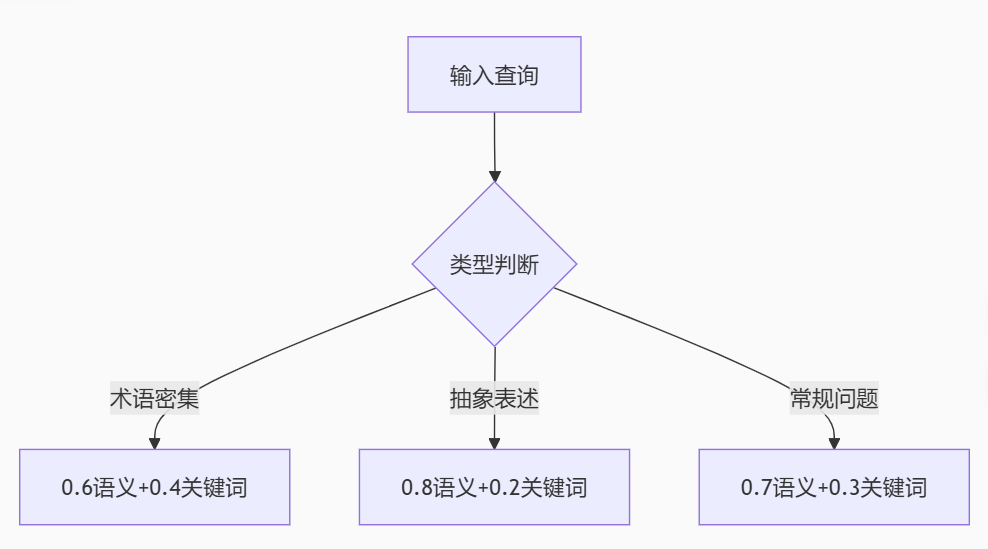
2.2.2. 权重分配策略
2.3. 智能去重模块
2.3.1. 三重去重机制
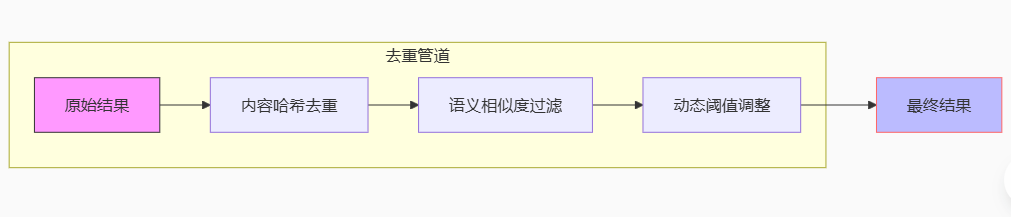
内容哈希级去重:
- 基于SimHash算法检测字面重复
- 设置5词滑动窗口处理近义表达(如"如何静心"与"怎样静心")
语义级去重:
- 93%相似度阈值基于实验确定:低于该值可能丢失合理变体,高于则产生冗余
- 采用余弦相似度+曼哈顿距离的双重度量
动态阈值扩展:
- 初始相似度阈值设为0.85
- 当返回结果不足5条时,以0.02为步长逐步放宽至0.75
- 确保在任何情况下都能返回适度数量的相关结果
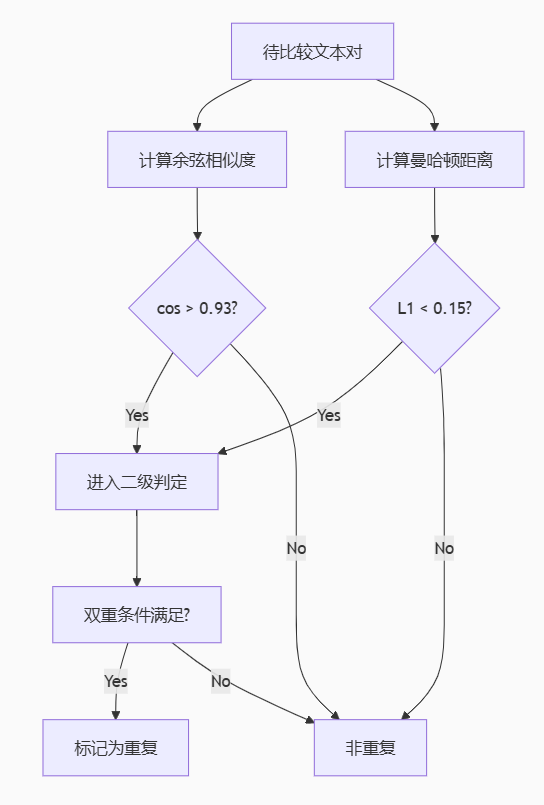
2.3.2. 语义相似度判定
采用双阈值判定策略:
- 余弦相似度>0.93
- 曼哈顿距离<0.15
同时满足上述两点才判定为重复
3. 实验结果
创建虚拟环境并激活
python -m venv venv
venv\Scripts\activate分步安装依赖
#升级pip工具
python -m pip install --upgrade pip
#安装核心依赖
pip install torch==2.0.1+cpu -f https://download.pytorch.org/whl/torch_stable.html
pip install transformers==4.30.0 jieba==0.42.1 numpy==1.24.2 flask==2.3.2准备
#确保BERT目录存在
if not exist BERT mkdir BERT
# 首次运行预加载
python -c "from transformers import BertModel; BertModel.from_pretrained('bert-base-chinese').save_pretrained('./BERT')"运行
python xinfa_QA.py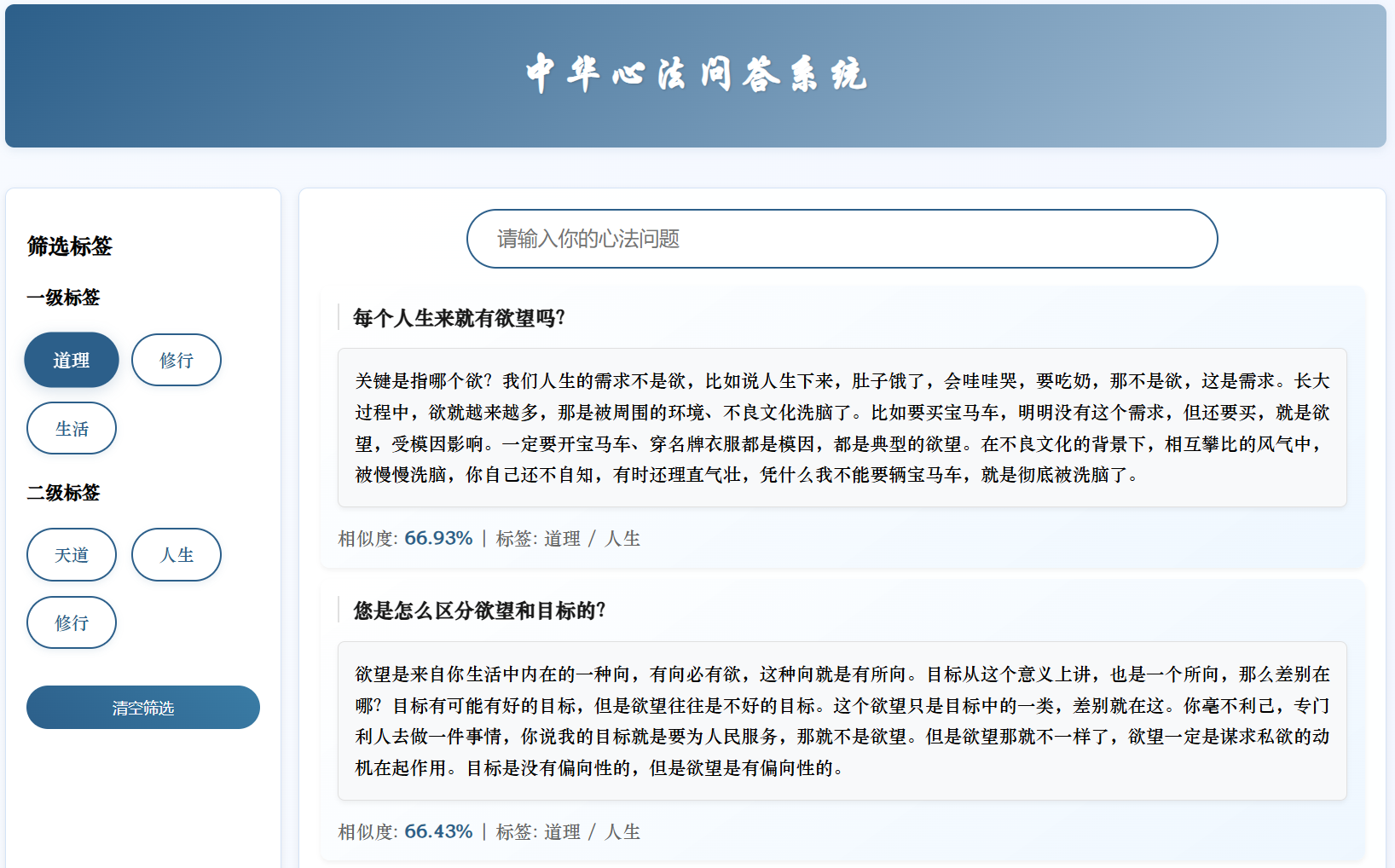
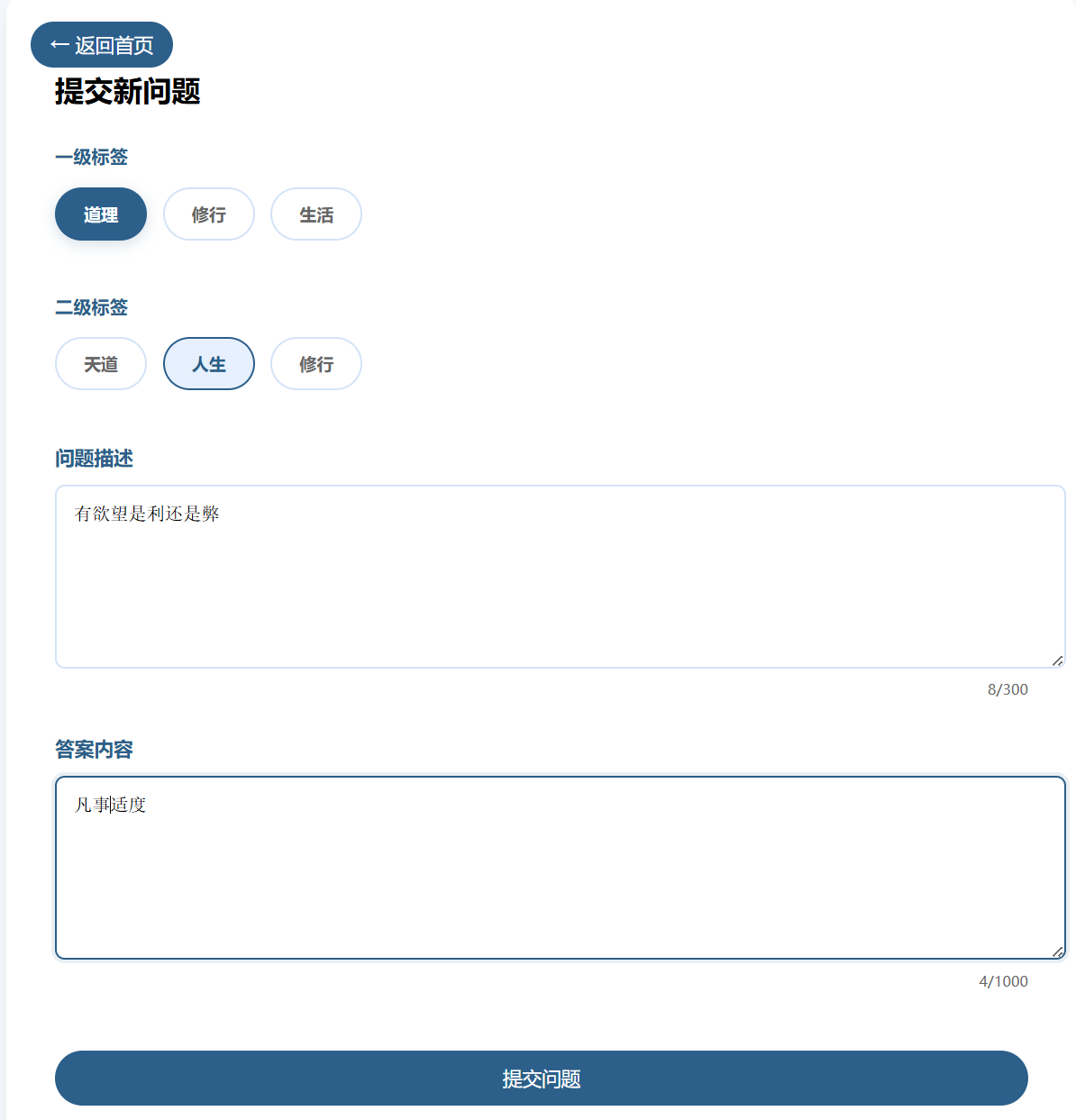
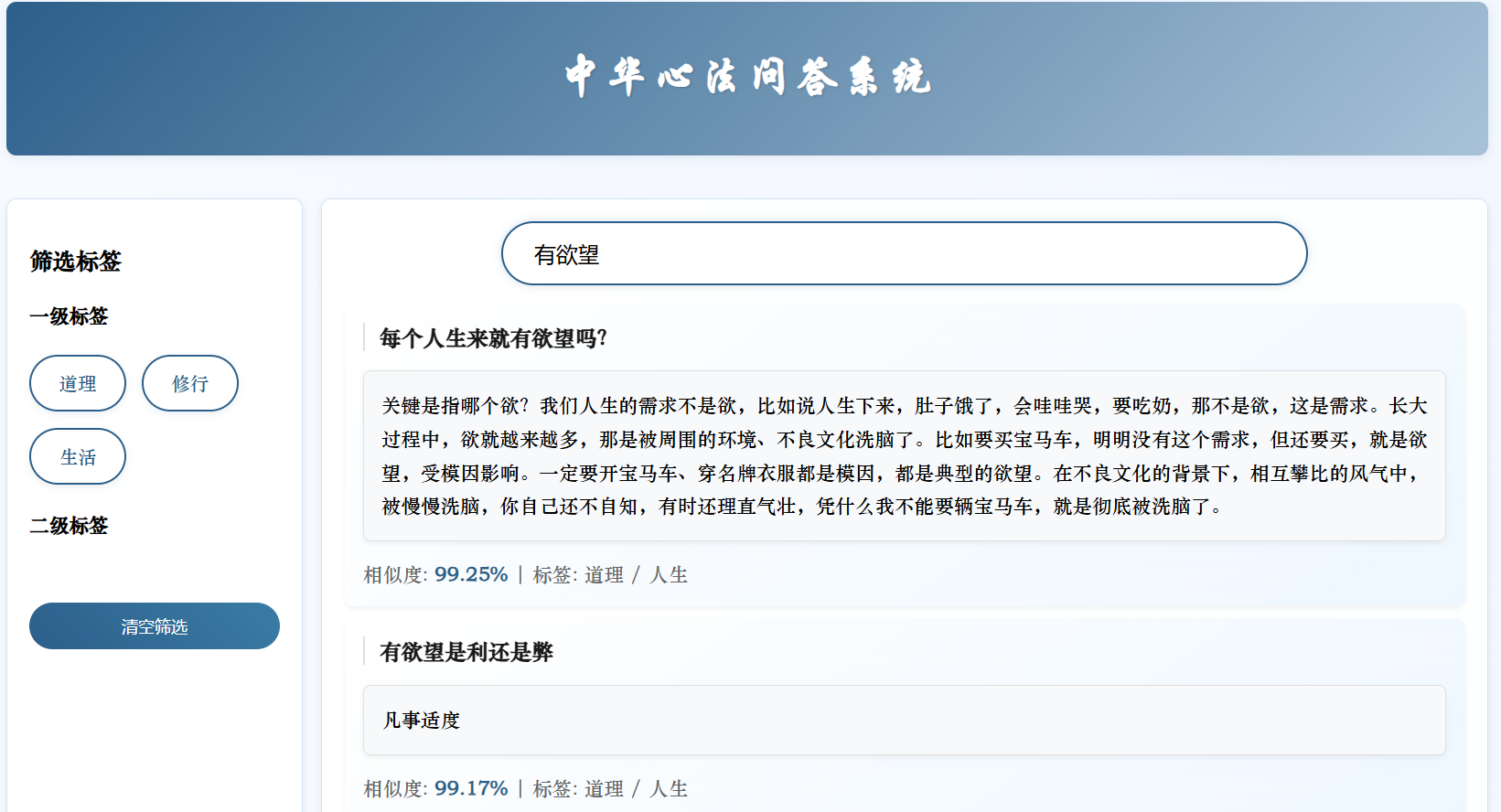
4. 总结
本周完成了戴雄斌学长的中华心法问答系统的复现,对其中的一些方法实现基本了解,了解了多层BERT向量融合、混合检索算法、三层去重的机制等方法的实现。




)



)






)



