一、pyahocorasick
1.安装 pyahocorasick 包:
pip install pyahocorasick -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install pyahocorasick:安装名为 pyahocorasick 的第三方库
👉 这个库是一个 Aho-Corasick 多模匹配算法 的 Python 实现,常用于高效的多关键词搜索。-i https://pypi.tuna.tsinghua.edu.cn/simple/:指定 pip 使用 清华镜像源,下载会更快、更稳定,尤其是在国内网络环境下。
2.介绍
✅ pyahocorasick 是 Python 的一个第三方库,
实现了 Aho–Corasick 多模式串匹配算法(自动机算法)。
👉 简单理解:
如果你有 很多关键词,想要在 一段文本 里 一次性高效匹配出所有关键词的位置,用普通的 for 循环挨个匹配会很慢,而 Aho–Corasick 算法可以用 O(n + m + k) 的时间(接近线性时间)搞定,非常高效。
二、创建医疗知识图谱
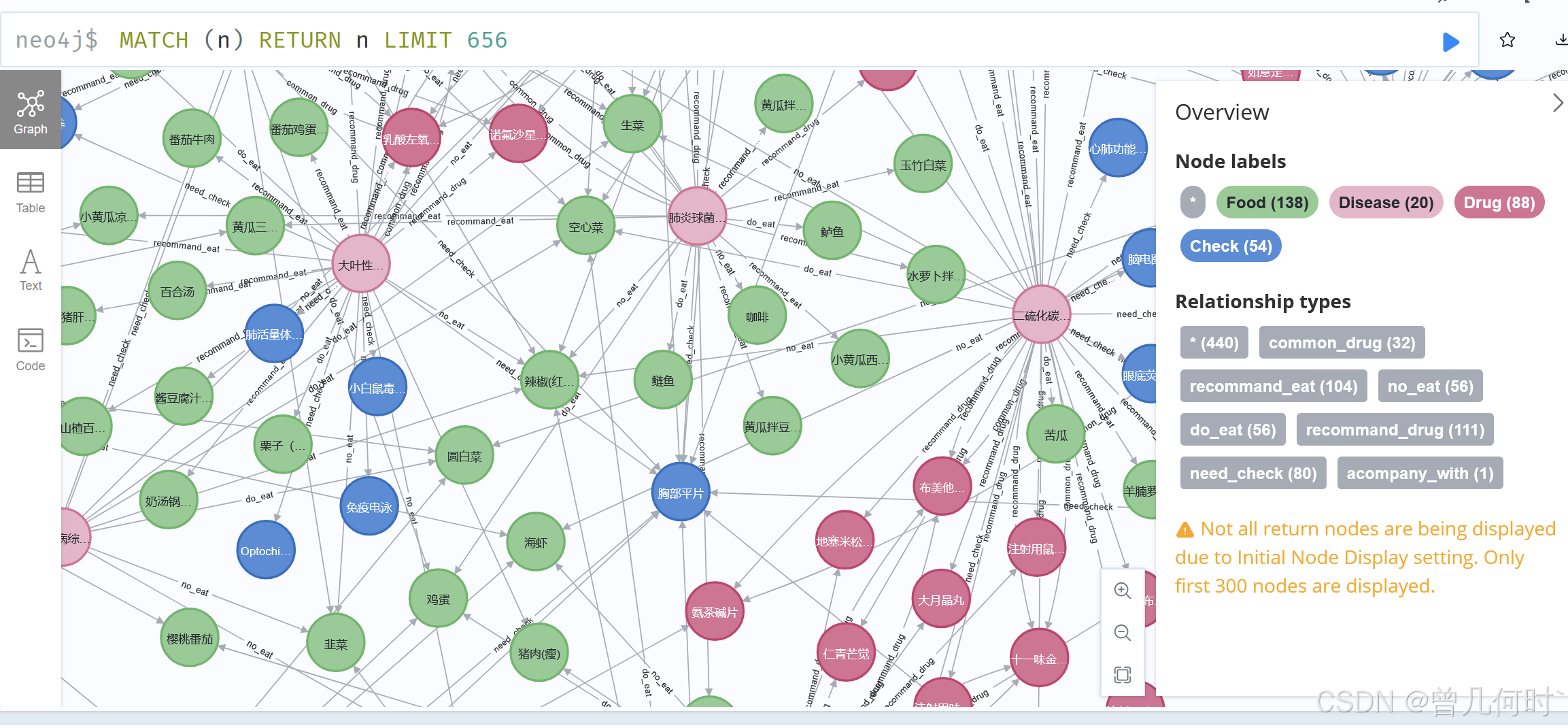
#选材自开源项目(刘焕勇,中国科学院软件研究所),数据集来自互联网爬虫数据
import os
import json
from py2neo import Graph,Nodeclass MedicalGraph:def __init__(self):cur_dir = '/'.join(os.path.abspath(__file__).split('/')[:-1])self.data_path = os.path.join(cur_dir, 'data/medical2.json')self.g = Graph("bolt://localhost:7687", auth=("neo4j", "weixuanlv0304"))'''读取文件'''def read_nodes(self):# 共7类节点drugs = [] # 药品foods = [] # 食物checks = [] # 检查departments = [] #科室producers = [] #药品大类diseases = [] #疾病symptoms = []#症状disease_infos = []#疾病信息# 构建节点实体关系rels_department = [] # 科室-科室关系rels_noteat = [] # 疾病-忌吃食物关系rels_doeat = [] # 疾病-宜吃食物关系rels_recommandeat = [] # 疾病-推荐吃食物关系rels_commonddrug = [] # 疾病-通用药品关系rels_recommanddrug = [] # 疾病-热门药品关系rels_check = [] # 疾病-检查关系rels_drug_producer = [] # 厂商-药物关系rels_symptom = [] #疾病症状关系rels_acompany = [] # 疾病并发关系rels_category = [] # 疾病与科室之间的关系count = 0for data in open(self.data_path):disease_dict = {}count += 1print(count)data_json = json.loads(data)disease = data_json['name']disease_dict['name'] = diseasediseases.append(disease)disease_dict['desc'] = ''disease_dict['prevent'] = ''disease_dict['cause'] = ''disease_dict['easy_get'] = ''disease_dict['cure_department'] = ''disease_dict['cure_way'] = ''disease_dict['cure_lasttime'] = ''disease_dict['symptom'] = ''disease_dict['cured_prob'] = ''if 'symptom' in data_json:symptoms += data_json['symptom']for symptom in data_json['symptom']:rels_symptom.append([disease, symptom])if 'acompany' in data_json:for acompany in data_json['acompany']:rels_acompany.append([disease, acompany])if 'desc' in data_json:disease_dict['desc'] = data_json['desc']if 'prevent' in data_json:disease_dict['prevent'] = data_json['prevent']if 'cause' in data_json:disease_dict['cause'] = data_json['cause']if 'get_prob' in data_json:disease_dict['get_prob'] = data_json['get_prob']if 'easy_get' in data_json:disease_dict['easy_get'] = data_json['easy_get']if 'cure_department' in data_json:cure_department = data_json['cure_department']if len(cure_department) == 1:rels_category.append([disease, cure_department[0]])if len(cure_department) == 2:big = cure_department[0]small = cure_department[1]rels_department.append([small, big])rels_category.append([disease, small])disease_dict['cure_department'] = cure_departmentdepartments += cure_departmentif 'cure_way' in data_json:disease_dict['cure_way'] = data_json['cure_way']if 'cure_lasttime' in data_json:disease_dict['cure_lasttime'] = data_json['cure_lasttime']if 'cured_prob' in data_json:disease_dict['cured_prob'] = data_json['cured_prob']if 'common_drug' in data_json:common_drug = data_json['common_drug']for drug in common_drug:rels_commonddrug.append([disease, drug])drugs += common_drugif 'recommand_drug' in data_json:recommand_drug = data_json['recommand_drug']drugs += recommand_drugfor drug in recommand_drug:rels_recommanddrug.append([disease, drug])if 'not_eat' in data_json:not_eat = data_json['not_eat']for _not in not_eat:rels_noteat.append([disease, _not])foods += not_eatdo_eat = data_json['do_eat']for _do in do_eat:rels_doeat.append([disease, _do])foods += do_eatrecommand_eat = data_json['recommand_eat']for _recommand in recommand_eat:rels_recommandeat.append([disease, _recommand])foods += recommand_eatif 'check' in data_json:check = data_json['check']for _check in check:rels_check.append([disease, _check])checks += checkif 'drug_detail' in data_json:drug_detail = data_json['drug_detail']producer = [i.split('(')[0] for i in drug_detail]rels_drug_producer += [[i.split('(')[0], i.split('(')[-1].replace(')', '')] for i in drug_detail]producers += producerdisease_infos.append(disease_dict)return set(drugs), set(foods), set(checks), set(departments), set(producers), set(symptoms), set(diseases), disease_infos,\rels_check, rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug, rels_drug_producer, rels_recommanddrug,\rels_symptom, rels_acompany, rels_category'''建立节点'''def create_node(self, label, nodes):count = 0for node_name in nodes:node = Node(label, name=node_name)self.g.create(node)count += 1print(count, len(nodes))return'''创建知识图谱中心疾病的节点'''def create_diseases_nodes(self, disease_infos):count = 0for disease_dict in disease_infos:node = Node("Disease", name=disease_dict['name'], desc=disease_dict['desc'],prevent=disease_dict['prevent'] ,cause=disease_dict['cause'],easy_get=disease_dict['easy_get'],cure_lasttime=disease_dict['cure_lasttime'],cure_department=disease_dict['cure_department'],cure_way=disease_dict['cure_way'] , cured_prob=disease_dict['cured_prob'])self.g.create(node)count += 1print(count)return'''创建知识图谱实体节点类型schema'''def create_graphnodes(self):Drugs, Foods, Checks, Departments, Producers, Symptoms, Diseases, disease_infos,rels_check, rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug, rels_drug_producer, rels_recommanddrug,rels_symptom, rels_acompany, rels_category = self.read_nodes()self.create_diseases_nodes(disease_infos)self.create_node('Drug', Drugs)print(len(Drugs))self.create_node('Food', Foods)print(len(Foods))self.create_node('Check', Checks)print(len(Checks))self.create_node('Department', Departments)print(len(Departments))self.create_node('Producer', Producers)print(len(Producers))self.create_node('Symptom', Symptoms)return'''创建实体关系边'''def create_graphrels(self):Drugs, Foods, Checks, Departments, Producers, Symptoms, Diseases, disease_infos, rels_check, rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug, rels_drug_producer, rels_recommanddrug,rels_symptom, rels_acompany, rels_category = self.read_nodes()self.create_relationship('Disease', 'Food', rels_recommandeat, 'recommand_eat', '推荐食谱')self.create_relationship('Disease', 'Food', rels_noteat, 'no_eat', '忌吃')self.create_relationship('Disease', 'Food', rels_doeat, 'do_eat', '宜吃')self.create_relationship('Department', 'Department', rels_department, 'belongs_to', '属于')self.create_relationship('Disease', 'Drug', rels_commonddrug, 'common_drug', '常用药品')self.create_relationship('Producer', 'Drug', rels_drug_producer, 'drugs_of', '生产药品')self.create_relationship('Disease', 'Drug', rels_recommanddrug, 'recommand_drug', '好评药品')self.create_relationship('Disease', 'Check', rels_check, 'need_check', '诊断检查')self.create_relationship('Disease', 'Symptom', rels_symptom, 'has_symptom', '症状')self.create_relationship('Disease', 'Disease', rels_acompany, 'acompany_with', '并发症')self.create_relationship('Disease', 'Department', rels_category, 'belongs_to', '所属科室')'''创建实体关联边'''def create_relationship(self, start_node, end_node, edges, rel_type, rel_name):count = 0# 去重处理set_edges = []for edge in edges:set_edges.append('###'.join(edge))all = len(set(set_edges))for edge in set(set_edges):edge = edge.split('###')p = edge[0]q = edge[1]query = "match(p:%s),(q:%s) where p.name='%s'and q.name='%s' create (p)-[rel:%s{name:'%s'}]->(q)" % (start_node, end_node, p, q, rel_type, rel_name)try:self.g.run(query)count += 1print(rel_type, count, all)except Exception as e:print(e)return'''导出数据'''def export_data(self):Drugs, Foods, Checks, Departments, Producers, Symptoms, Diseases, disease_infos, rels_check, rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug, rels_drug_producer, rels_recommanddrug, rels_symptom, rels_acompany, rels_category = self.read_nodes()f_drug = open('drug.txt', 'w+')f_food = open('food.txt', 'w+')f_check = open('check.txt', 'w+')f_department = open('department.txt', 'w+')f_producer = open('producer.txt', 'w+')f_symptom = open('symptoms.txt', 'w+')f_disease = open('disease.txt', 'w+')f_drug.write('\n'.join(list(Drugs)))f_food.write('\n'.join(list(Foods)))f_check.write('\n'.join(list(Checks)))f_department.write('\n'.join(list(Departments)))f_producer.write('\n'.join(list(Producers)))f_symptom.write('\n'.join(list(Symptoms)))f_disease.write('\n'.join(list(Diseases)))f_drug.close()f_food.close()f_check.close()f_department.close()f_producer.close()f_symptom.close()f_disease.close()returnif __name__ == '__main__':handler = MedicalGraph()#handler.export_data()handler.create_graphnodes()handler.create_graphrels()
三、问答机器人对话

from question_classifier import *
from question_parser import *
from answer_search import *'''问答类'''
class ChatBotGraph:def __init__(self):self.classifier = QuestionClassifier()self.parser = QuestionPaser()self.searcher = AnswerSearcher()def chat_main(self, sent):answer = '没能理解您的问题,我数据量有限。。。能不能问的标准点'res_classify = self.classifier.classify(sent)if not res_classify:return answerres_sql = self.parser.parser_main(res_classify)final_answers = self.searcher.search_main(res_sql)if not final_answers:return answerelse:return '\n'.join(final_answers)if __name__ == '__main__':handler = ChatBotGraph()while 1:question = input('咨询:')answer = handler.chat_main(question)print('客服机器人:', answer)拓扑结构比较)

 视频教程 - jieba库分词简介及使用)




知识详解)











完全指南)