《DeepSeek原生应用与智能体开发实践》【摘要 书评 试读】- 京东图书
在人工智能与机器学习领域,模型的后训练阶段不仅是技术流程中的关键环节,更是提升模型性能,尤其是数学逻辑能力的“黄金时期”。这一阶段,通过对已初步训练好的模型进行精细化调优,能够显著增强其处理复杂数学逻辑任务的能力,使模型在诸如数学推理、数据分析、决策优化等场景中展现出更高的智能水平。
模型的后训练,本质上是对模型参数进行二次优化,旨在消除初次训练中的偏差与不足,提升模型的泛化能力和逻辑推断精度。特别是在数学逻辑能力方面,后训练通过引入更高级的数学概念、逻辑规则以及问题求解策略,引导模型学习并掌握更深层次的数学逻辑结构。这一过程不仅要求模型能够准确理解数学符号与表达式的含义,更需具备运用逻辑规则进行复杂推理和解决问题的能力。大模型后训练全景图如图15-1所示。
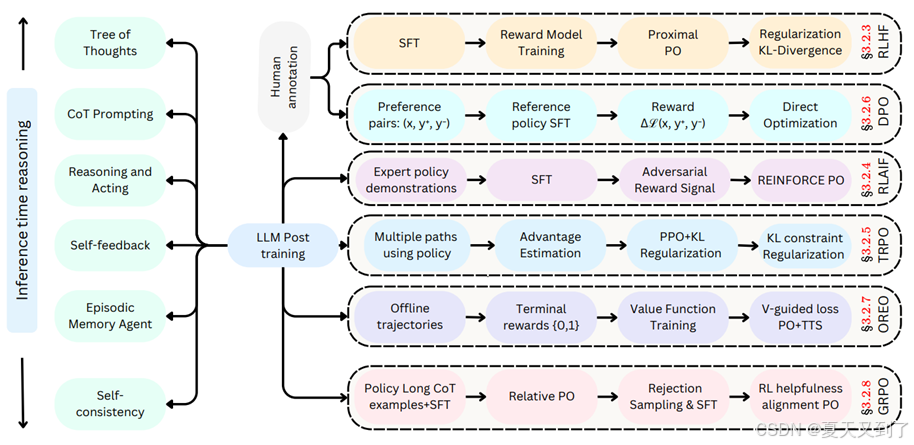
图15-1 大模型后训练全景图
为了有效提升模型的数学逻辑能力,后训练阶段可采用多种策略。一方面,可以设计专门的数学逻辑任务集,如数学证明题、逻辑推理题等,作为模型训练的数据源,通过大量实践让模型在“做中学”,逐步积累数学逻辑经验。另一方面,可借鉴人类解决数学问题的思维方式,如归纳推理、演绎推理等,将这些思维方法融入模型的后训练过程中,使模型能够模拟人类的逻辑思考过程,提高解题效率和准确性。
15.1.1 大模型的后训练概念与核心目标
大模型的后训练是在预训练阶段之后,对模型进行进一步调整与优化的关键过程。预训练通常利用海量无标注数据,让模型学习到语言的通用模式、结构以及丰富的语义信息,使模型具备基础的“语言能力”。
然而,预训练模型就像是一个拥有广泛知识但缺乏特定专业技能的“通才”,它虽然对语言有普遍的理解,但无法直接精准地处理各种具体的任务。后训练的目的就是把这个“通才”培养成在特定领域或任务上表现出色的“专才”。
例如,在科学领域,预训练模型可能知道很多通用的词汇和句子结构,但对于数学术语、物理定理等专业内容理解有限。通过后训练,使用大量科学领域的数据对模型进行微调,模型就能更好地理解和处理与逻辑计算相关的文本,比如准确解读论文等。后训练的核心目标就是提升模型在特定任务上的性能,使其能够更精准、高效地完成任务,满足实际应用的需求。
大模型后训练有多种方法和策略,其中监督微调(Supervised Fine-Tuning,SFT)和强化学习等微调手段是比较常用和有效的方法。微调就像是在已经建好的房子基础上进行局部装修。预训练模型就好比是建好的房子主体结构,而微调则是根据具体需求,对房子的内部布局、装饰等进行调整。微调的方法如图15-2所示。
在微调过程中,使用有标注的任务特定数据,对预训练模型的参数进行轻微调整。比如,要将一个预训练的语言模型用于情感分析任务,就会收集大量带有情感标签(积极、消极、中立)的文本数据,然后让模型在这些数据上进行训练,调整模型的参数,使其能够准确判断文本的情感倾向。
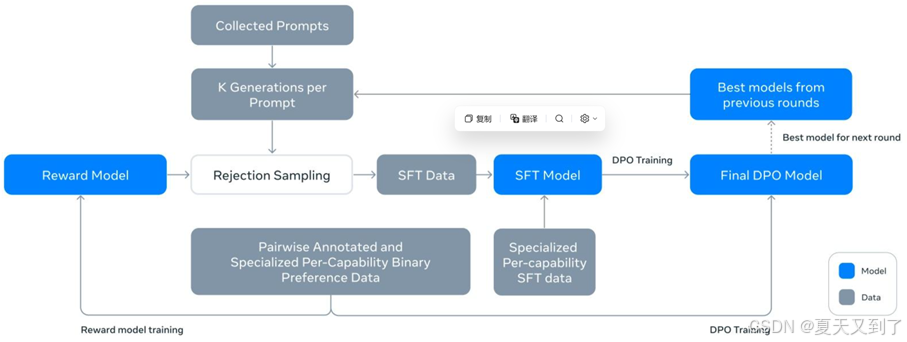
图15-2 微调的方法
除了微调,提示学习也是一种重要的后训练方法。提示学习就像是给模型一个“提示语”,引导模型按照特定的方式生成输出。例如,对于GLM系列模型,可以通过设计“请总结以下文章的主要内容”这样的提示,让模型对给定的文章进行摘要。这种方法不需要对模型进行大量的参数调整,只需要设计合适的提示,就能让模型适应新的任务。此外,还有参数高效微调方法,它只微调模型中的部分参数,而不是全部参数,这样可以在保证模型性能的同时,大大减少计算资源和时间成本。
大模型后训练面临着一些挑战。数据稀缺是一个常见问题,特定任务的数据可能非常有限,这就像是要做一道美味的菜肴,但食材却不够。为了解决这个问题,研究人员会使用数据增强技术,比如对文本进行回译、同义词替换等,增加训练数据的多样性。计算资源限制也是一个挑战,微调大型模型需要大量的计算资源,就像要建造一座大型建筑需要大量的人力和物力。
参数高效微调方法和模型压缩技术可以在一定程度上缓解这个问题。
未来,大模型后训练有着广阔的发展前景。一方面,研究人员会不断探索更高效的后训练方法,进一步减少计算资源和时间成本,提高模型的训练效率。另一方面,跨领域和跨任务学习将成为研究热点,让模型能够更好地适应不同的领域和任务,实现更广泛的应用。同时,提高模型的可解释性和安全性也是未来的重要方向,让模型不仅能够做出准确的预测,还能让用户理解其决策过程,并且防止模型被恶意攻击或滥用。
15.1.2 结果奖励与过程奖励:奖励建模详解
在上一节中,我们深入探讨了大模型后训练的多种方法与策略,其中最基础的两种便是监督微调(SFT)与强化学习。监督微调(SFT)我们已在前文(12.5节)有所阐述,它主要是通过标注好的数据对模型进行微调,使模型能够初步适应特定的任务需求。而强化学习,尤其是以梯度正则化策略优化(GRPO)为代表的算法,则为大模型的后训练提供了另一种高效的途径。
在强化学习的框架下,奖励建模扮演着至关重要的角色。奖励建模的核心在于构建一个能够准确反映人类偏好的奖励函数,以此引导模型在训练过程中不断优化其行为策略。其中,结果奖励与过程奖励是奖励建模中的两个关键维度。结果奖励关注的是模型最终输出的质量,即模型生成的答案或决策是否符合人类的期望;而过程奖励则侧重于模型在生成过程中的行为表现,如是否遵循了合理的逻辑、是否展现了创造性等。
在训练奖励模型时,我们通常采用最小化负对数似然函数的方法,其目标函数可以表示为:
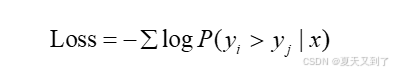
这个公式表明,我们希望奖励模型给出的奖励值能够尽可能地接近真实(SFT),或者符合人类的偏好(GRPO)。例如,如果人类更喜欢yi 而不是yj ,那么我们希望模型的输出尽可能地满足R(x,yi) 输出的概率大于(x,yj) 的输出概率。
奖励函数的设计在强化学习领域中占据着举足轻重的地位。它就像一位精准的导航员,为模型在不同状态下明确应得的奖励,进而巧妙地引导模型逐步学习到我们所期望的行为模式。一个精心设计的奖励函数,能够如同明灯照亮模型前行的道路,使其在复杂多变的环境中迅速找到最优的行为策略。在强化学习的宏大框架里,奖励函数的设计绝非可有可无的环节,而是决定模型训练成败与效果优劣的关键因素。
奖励根据来源进行划分,可以清晰地分为过程奖励和结果奖励两大类别。
1. 过程奖励(Process Reward)
过程奖励,顾名思义,是在模型执行任务的每一个具体步骤中,依据其当下的行为表现所给予的奖励。这种奖励机制就像是一位时刻陪伴在模型身边的严格导师,对模型每一步的操作都进行细致入微的评估与反馈。其显著优势在于能够提供极为密集的反馈信号,模型无须等待漫长的任务结束,就能在每一个小步骤中及时知晓自己的行为是否正确、是否符合预期。这种即时反馈的特性,极大地加速了模型的学习进程,使其能够更快地调整策略、优化行为。
下面我们用伪代码模拟了一个过程奖励,代码如下所示:
def calculate_step_reward(response):# 1. 语法正确性检查syntax = check_syntax(response)# 2. 逻辑连贯性评估coherence = model.predict_coherence(response)# 3. 事实一致性验证fact_check = retrieve_evidence(response)return 0.3*syntax + 0.5*coherence + 0.2*fact_check在这个例子中,奖励函数考虑了三个方面:
- 语法正确性检查:检查模型生成的文本是否符合语法规则。例如,可以使用语法分析器来判断文本是否存在语法错误。
- 逻辑连贯性评估:评估模型生成的文本是否逻辑连贯。例如,可以使用语言模型来预测文本的连贯性。
- 事实一致性验证:验证模型生成的文本是否与事实相符。例如,可以使用知识库来检索相关信息,然后判断模型生成的文本是否与知识库中的信息一致。
对这三个方面进行加权求和,得到最终的奖励值。权重的选择需要根据实际情况进行调整。一般来说,更重要的方面应该分配更高的权重。
然而,过程奖励并非完美无缺。其最大的挑战在于设计难度极高,这要求设计者必须对任务有极为深入、透彻的理解。不同的任务具有独特的规则、目标和约束条件,要设计出能够精准反映模型在每个步骤中行为优劣的过程奖励函数,需要综合考虑诸多因素。例如,在一个复杂的机器人控制任务中,机器人的每一个动作都可能受到多种环境因素的影响,设计者需要精确衡量这些动作在不同情境下的合理性,才能制定出合适的过程奖励规则。一旦过程奖励设计不当,可能会误导模型,使其学习到并非最优甚至错误的行为模式。
2. 结果奖励(Outcome Reward)
与过程奖励不同,结果奖励关注的是模型在完成整个任务后所达成的最终成果。它更像是一位在终点等待的评判者,根据模型最终呈现的结果给予相应的奖励或惩罚。结果奖励的设计相对比较直观,通常可以根据任务的明确目标来制定。比如,在一场棋类游戏中,赢得比赛即可获得正奖励,输掉比赛则得到负奖励。这种简洁明了的奖励方式,使得模型能够清晰地了解最终需要追求的目标。
结果奖励是指在任务完成后,根据模型的最终结果给出的奖励。结果奖励的设计比较简单,只需要关注最终结果即可。但可能提供较稀疏的反馈信号,导致模型学习困难。典型应用场景包括:
- 数学问题:最终答案正确性。例如,如果模型生成的答案与正确答案一致,则给出正奖励,否则给出负奖励。
- 代码生成:通过单元测试的比例。例如,如果模型生成的代码能够通过所有的单元测试,则给出正奖励,否则给出负奖励。
- 对话系统:用户满意度评分。例如,如果用户对模型的回复感到满意,则给出正奖励,否则给出负奖励。
在实际应用中,为了充分发挥强化学习的优势,往往需要综合考虑过程奖励和结果奖励,将它们巧妙地结合起来。通过合理设计两者的权重和交互方式,使模型既能在每个步骤中得到及时的反馈和指导,又能明确最终的目标方向,从而实现更高效、更优质的学习效果。
但结果奖励也存在一定的局限性。由于它仅关注最终结果,模型在训练过程中可能会缺乏足够的指导,就像在黑暗中摸索前行,只能凭借最终的结果反馈来调整方向。这可能导致模型在探索过程中走很多弯路,学习效率相对较低。而且,对于一些复杂任务,单一的结果奖励可能无法全面反映模型在整个过程中的表现,容易忽略一些重要的中间环节和行为细节。
最后需要提醒大家,结果奖励与过程奖励并不是孤立的,而是相互关联、相互影响的。一个优秀的模型不仅需要在最终结果上符合人类的期望,还需要在生成过程中展现出合理的逻辑和创造性。因此,在构建奖励模型时,我们需要综合考虑结果奖励和过程奖励,以实现模型性能的全面提升。




知识详解)











完全指南)

_笔记)

