
🌟 嗨,我是Lethehong!🌟
🌍 立志在坚不欲说,成功在久不在速🌍
🚀 欢迎关注:👍点赞⬆️留言收藏🚀
🍀欢迎使用:小智初学计算机网页IT深度知识智能体
🚀个人博客:Lethehong有一起互链的朋友可以私信我
✅GPT体验码:https://gitee.com/lethehong/chatgpt-share
✅GPT体验码:私信博主~免费领取体验码
Lethehong诚邀您加入社群,送您海量编程资源,DeepSeek资料包,各种线上线下活动等你来开启,快来占据你得一席之地吧!
优质专栏:
🔥 热点时事
聚焦当前全球与国内的热门科技、政治、经济等领域的重要事件,提供深度解读与技术相关分析,帮助读者把握时代脉搏。
🌌 星辰瀚海——Linux秘境之操作系统
以“星辰大海”的浪漫比喻深入浅出地讲解 Linux 操作系统的原理、命令、内核机制和发行版生态,是系统爱好者与运维开发者的理想天地。
🌐 网络
涵盖计算机网络的基本原理、OSI模型、TCP/IP 协议、路由交换、安全机制等内容,适合学习 CCNA、网络工程或运维方向的读者。
🧠 数据结构
系统讲解数组、链表、栈、队列、哈希表、树、图等数据结构及其在算法中的应用,辅以典型示例和复杂度分析,是算法学习的基础。
🐍 Python在手,bug溜走!码农的快乐,你不懂~
用幽默轻松的风格介绍 Python 编程知识,包括语法、库、实战案例和自动化脚本等,适合初学者与爱折腾的开发者。
💻 C++
涵盖 C++ 基础语法、面向对象、STL、模板、内存管理、并发等内容,是系统学习底层开发与工程化技术的重要专栏。
🌍 Web
讲解前端(HTML/CSS/JavaScript)、后端(Node.js、Flask、Django 等)、全栈开发及现代框架(如 React、Vue)等内容,适合 Web 开发爱好者。
🧭 Cisco
主要面向思科网络设备的使用与认证考试,如 CCNA、CCNP,讲解配置命令、交换路由、安全设置等核心技能。
🛰️ 华为 eNSP
聚焦华为网络模拟器 eNSP 的使用,包括路由交换、防火墙、安全等配置实践,适合准备 HCIA/HCIP 考试的网络工程师。
目录
引言
Craft智能体:从对话到代码的无缝转化
初识Craft:打破传统编程思维桎梏
高效开发实践:从构思到实现的加速器
对话式编程的局限与突破
MCP协议:打通开发全流程的桥梁
理解MCP:不只是一个协议,而是生态
全流程开发体验:从需求到部署的无缝衔接
团队协作中的MCP价值
DeepSeek V3:代码补全的新境界
从辅助到共创:AI代码补全的质变
实战体验:效率提升的量化分析
语言理解的深度与广度
跨语言场景下的适应性
结语:AI与程序员的共生未来
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴
引言
作为一名计算机爱好者,我看到了很多编程助手工具的演变。从最初的简单代码补全,到如今能够进行深度交流的AI编程伙伴,这一路走来,每一次的技术进步都让我对未来充满期待。今天,我想分享我使用CodeBuddy最新版本的深度体验,特别是其中三个重磅功能:Craft智能体、MCP协议支持以及DeepSeek V3代码补全升级。这不仅仅是一次功能评测,更是对现代程序员如何与AI协同工作的思考。
Craft智能体:从对话到代码的无缝转化

初识Craft:打破传统编程思维桎梏
第一次使用Craft智能体时,我带着怀疑的态度。毕竟,作为习惯了传统IDE的开发者,"对话式编程"这个概念听起来颇为抽象。然而,当我开始与Craft交流我的项目需求时,这种怀疑很快被惊讶所取代。
我向Craft描述了一个需求:「我需要一个能够从多个数据源收集信息,并根据用户偏好进行个性化推荐的微服务系统。」仅凭这句话,Craft不仅理解了我的意图,还为我提出了良好的建议和开始方向(我是一名代码小白)。
您提出的是一个复杂的系统需求,为了更好地帮助您实现这个目标,我建议我们采用渐进式开发方案。以下是几个可选的起点,每个都更容易实现和测试:
1. 简单的文件数据收集器(使用 Python)
从本地 CSV 或 JSON 文件读取数据
提供基本的数据处理功能
不需要复杂的服务器设置
2. 基础的用户偏好管理(使用 Python + SQLite)
存储用户基本偏好信息
提供简单的偏好查询功能
使用轻量级数据库
3. 单一数据源的推荐原型(使用 Python)
基于简单规则的推荐逻辑
处理单一类型的数据
输出基础推荐结果
这些选项都使用 Python,因为它是一个更容易开始的选择,不需要复杂的环境设置。您觉得从哪个部分开始比较合适?选定后,我们可以快速实现一个基础版本,然后根据需要逐步扩展功能。
 第一次生成的结果,初步看,达到了我的要求,但这样看起来似乎有点麻烦呢。于是我再次快马加鞭的进行释放加速器
第一次生成的结果,初步看,达到了我的要求,但这样看起来似乎有点麻烦呢。于是我再次快马加鞭的进行释放加速器
{"products": [{"id": 1,"name": "笔记本电脑","category": "电子产品","price": 5999.99,"features": ["8GB内存", "256GB固态硬盘", "14寸屏幕"]},{"id": 2,"name": "智能手机","category": "电子产品","price": 2999.99,"features": ["6GB内存", "128GB存储", "5000mAh电池"]},{"id": 3,"name": "无线耳机","category": "配件","price": 799.99,"features": ["蓝牙5.0", "主动降噪", "30小时续航"]},{"id": 4,"name": "机械键盘","category": "配件","price": 399.99,"features": ["青轴", "RGB背光", "104键"]}]
}import json
from typing import Dict, List, Any
from collections import defaultdictclass DataCollector:def __init__(self, data_file: str):"""初始化数据收集器"""self.data_file = data_fileself.data = self._load_data()def _load_data(self) -> Dict[str, List[Dict[str, Any]]]:"""从JSON文件加载数据"""try:with open(self.data_file, 'r', encoding='utf-8') as f:return json.load(f)except Exception as e:print(f"读取数据文件时出错: {e}")return {"products": []}def get_category_statistics(self) -> Dict[str, int]:"""按类别统计商品数量"""category_stats = defaultdict(int)for product in self.data.get("products", []):category_stats[product["category"]] += 1return dict(category_stats)def get_average_price(self, category: str = None) -> float:"""计算平均价格,可选择按类别计算"""products = self.data.get("products", [])if category:products = [p for p in products if p["category"] == category]if not products:return 0.0total_price = sum(p["price"] for p in products)return round(total_price / len(products), 2)def search_products(self, keyword: str) -> List[Dict[str, Any]]:"""搜索商品(按名称或特性)"""keyword = keyword.lower()results = []for product in self.data.get("products", []):# 检查商品名称if keyword in product["name"].lower():results.append(product)continue# 检查商品特性if any(keyword in feature.lower() for feature in product["features"]):results.append(product)return resultsdef main():"""主函数:演示数据收集器的功能"""collector = DataCollector("sample_data.json")# 1. 显示类别统计print("\n=== 商品类别统计 ===")category_stats = collector.get_category_statistics()for category, count in category_stats.items():print(f"{category}: {count}个商品")# 2. 显示价格统计print("\n=== 价格统计 ===")print(f"所有商品平均价格: ¥{collector.get_average_price()}")for category in category_stats.keys():avg_price = collector.get_average_price(category)print(f"{category}平均价格: ¥{avg_price}")# 3. 演示搜索功能print("\n=== 搜索示例 ===")# 搜索包含"内存"的商品print("\n搜索'内存'相关商品:")memory_products = collector.search_products("内存")for product in memory_products:print(f"- {product['name']} (¥{product['price']})")# 搜索"配件"类商品print("\n搜索'配件'类商品:")accessory_products = collector.search_products("配件")for product in accessory_products:print(f"- {product['name']} (¥{product['price']})")if __name__ == "__main__":main()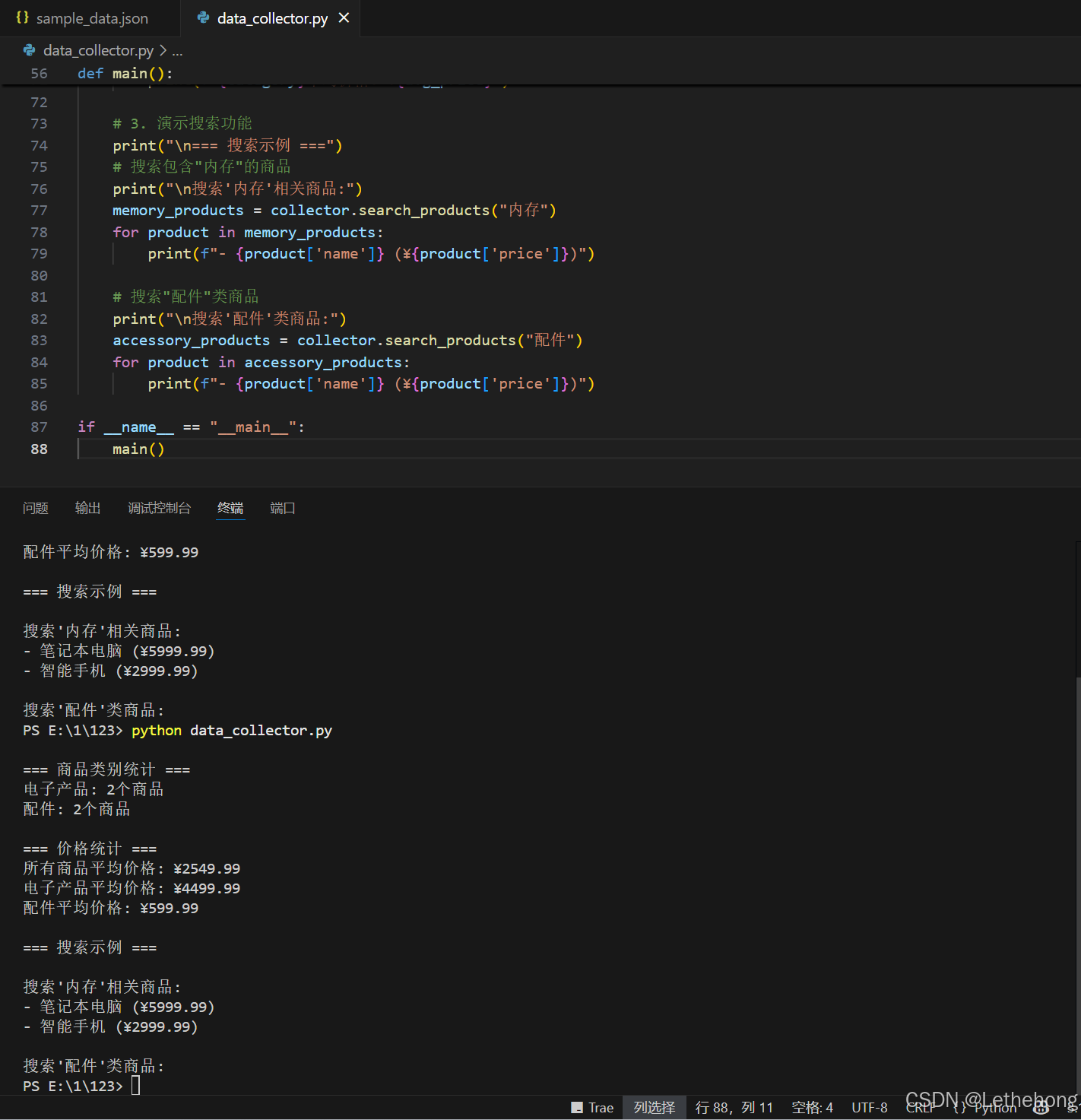
高效开发实践:从构思到实现的加速器
在一个实际项目中,我尝试用Craft完成一个数据分析Dashboard的开发。以下是我的工作流程:
- 需求阐述阶段:我告诉Craft我需要一个可视化界面,能够展示实时数据流,并支持多维度筛选。
- 架构设计对话:Craft提出了几种可能的架构方案,我们通过对话权衡了各方案的优缺点。
- 代码生成与调整:确定方案后,Craft生成了初始框架代码,包括前端React组件和后端API结构。
- 迭代优化:当我发现某些组件性能不佳时,只需简单描述问题,Craft立即提供了优化建议。
经过我多次优化,codebuddy成功修复了端口问题(如果当你们运行遇到端口占用问题,但是去查看的时候发现端口并没有被占用,此时可能是代码逻辑有问题造成的)
下面这个是我在py里面植入了web界面(此web界面是我经过修改过的,原本的太难看了)
from flask import Flask, jsonify, request, render_template_string
from data_collector import DataCollector
import sysapp = Flask(__name__)
collector = DataCollector("sample_data.json")# 专业美观的HTML界面模板
HTML_TEMPLATE = """
<!DOCTYPE html>
<html lang="zh-CN">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>数据收集API服务</title><style>:root {--primary-color: #3498db;--secondary-color: #2980b9;--accent-color: #e74c3c;--light-color: #f8f9fa;--dark-color: #343a40;--success-color: #2ecc71;--warning-color: #f39c12;--danger-color: #e74c3c;}* {box-sizing: border-box;margin: 0;padding: 0;}body {font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;line-height: 1.6;color: #333;background-color: #f5f7fa;padding: 0;margin: 0;}.container {max-width: 1200px;margin: 0 auto;padding: 2rem;}header {background: linear-gradient(135deg, var(--primary-color), var(--secondary-color));color: white;padding: 2rem 0;margin-bottom: 2rem;box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1);}.header-content {max-width: 1200px;margin: 0 auto;padding: 0 2rem;}h1 {font-size: 2.5rem;margin-bottom: 0.5rem;}.subtitle {font-size: 1.2rem;opacity: 0.9;font-weight: 300;}.card {background: white;border-radius: 8px;box-shadow: 0 2px 10px rgba(0, 0, 0, 0.08);padding: 1.5rem;margin-bottom: 2rem;transition: transform 0.3s ease, box-shadow 0.3s ease;}.card:hover {transform: translateY(-5px);box-shadow: 0 5px 15px rgba(0, 0, 0, 0.1);}.card h2 {color: var(--primary-color);margin-bottom: 1rem;padding-bottom: 0.5rem;border-bottom: 2px solid var(--light-color);}.endpoint {margin-bottom: 1.5rem;padding: 1rem;background-color: var(--light-color);border-left: 4px solid var(--primary-color);border-radius: 4px;}.endpoint h3 {color: var(--dark-color);margin-bottom: 0.5rem;}.method {display: inline-block;padding: 0.25rem 0.5rem;background-color: var(--primary-color);color: white;border-radius: 3px;font-weight: bold;font-size: 0.9rem;margin-right: 0.5rem;}.path {font-family: 'Courier New', Courier, monospace;font-size: 1.1rem;color: var(--dark-color);}.btn {display: inline-block;padding: 0.5rem 1rem;background-color: var(--primary-color);color: white;text-decoration: none;border-radius: 4px;margin-top: 0.5rem;transition: background-color 0.3s ease;}.btn:hover {background-color: var(--secondary-color);}.status-badge {display: inline-block;padding: 0.5rem 1rem;border-radius: 20px;font-weight: bold;margin-top: 1rem;}.status-active {background-color: var(--success-color);color: white;}.param {margin-top: 0.5rem;padding: 0.5rem;background-color: #f0f0f0;border-radius: 4px;font-family: 'Courier New', Courier, monospace;}.param-name {font-weight: bold;color: var(--dark-color);}.param-desc {color: #666;font-size: 0.9rem;}footer {text-align: center;padding: 1.5rem;color: #666;font-size: 0.9rem;margin-top: 2rem;border-top: 1px solid #eee;}@media (max-width: 768px) {.container {padding: 1rem;}header {padding: 1.5rem 0;}h1 {font-size: 2rem;}}</style>
</head>
<body><header><div class="header-content"><h1>数据收集API服务</h1><p class="subtitle">高效、可靠的数据收集与分析平台</p></div></header><div class="container"><div class="card"><h2>API文档</h2><p>以下是我们提供的API端点列表,您可以直接点击测试或查看详细说明。</p><div class="endpoint"><h3>获取商品类别统计</h3><p><span class="method">GET</span> <span class="path">{{ base_url }}/api/categories</span></p><p class="param-desc">获取所有商品类别的统计信息</p><a href="/api/categories" class="btn" target="_blank">测试此API</a></div><div class="endpoint"><h3>获取商品平均价格</h3><p><span class="method">GET</span> <span class="path">{{ base_url }}/api/products/average-price</span></p><div class="param"><div class="param-name">参数: category</div><div class="param-desc">可选,指定商品类别名称</div></div><a href="/api/products/average-price?category=电子产品" class="btn" target="_blank">测试此API</a></div><div class="endpoint"><h3>搜索商品</h3><p><span class="method">GET</span> <span class="path">{{ base_url }}/api/products/search</span></p><div class="param"><div class="param-name">参数: keyword</div><div class="param-desc">必需,搜索关键词</div></div><a href="/api/products/search?keyword=内存" class="btn" target="_blank">测试此API</a></div></div><div class="card"><h2>服务状态</h2><div class="status-badge status-active">服务运行正常</div><p>服务器运行在: <code>{{ base_url }}</code></p><p>最后更新时间: {{ current_time }}</p></div></div><footer><p>数据收集API服务 © 2023 - 专业数据解决方案</p></footer>
</body>
</html>
"""from datetime import datetime@app.route('/')
def index():"""显示专业美观的API文档页面"""return render_template_string(HTML_TEMPLATE, base_url=request.base_url,current_time=datetime.now().strftime("%Y-%m-%d %H:%M:%S"))# 原有的API端点保持不变...if __name__ == '__main__':# 获取命令行参数中的端口号,默认为5000port = int(sys.argv[1]) if len(sys.argv) > 1 else 5000print("\n" + "="*50)print(f"数据收集API服务启动中...")print(f"访问地址: http://localhost:{port}")print("="*50 + "\n")try:app.run(host='0.0.0.0', port=port, debug=True)except Exception as e:print(f"\n启动失败: {str(e)}")print("\n常见问题排查:")print("1. 确保没有其他程序占用端口")print("2. 检查防火墙设置是否允许该端口")print("3. 确保所有依赖已安装 (pip install flask)")web界面的样式(看着还像那么回事) 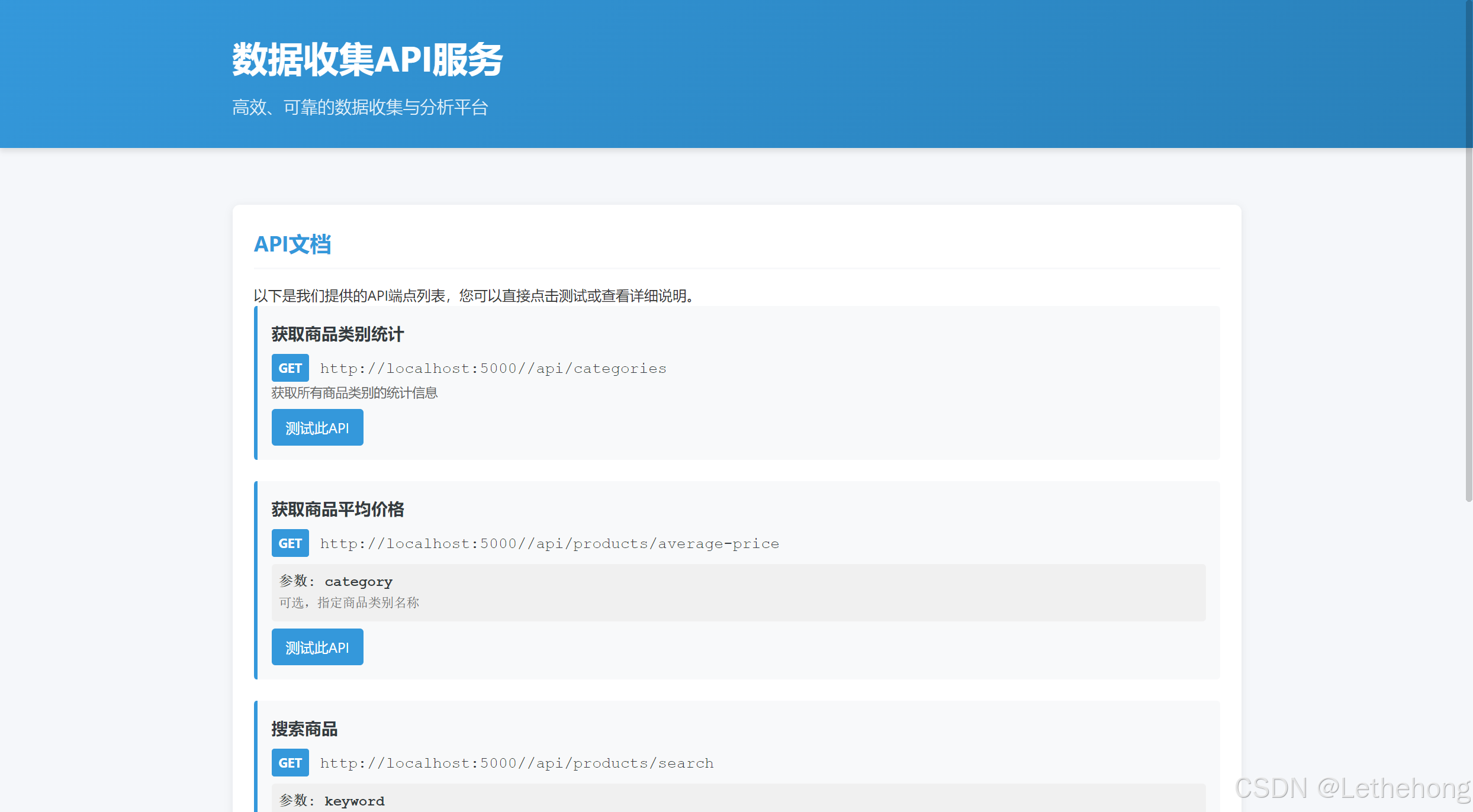
整个过程中,最让我印象深刻的是Craft对上下文的理解能力。它不仅能记住我们之前的对话内容,还能将这些信息融入到后续的代码生成中,使得整个开发过程既连贯又高效。
一个具体例子:在开发过程中,我提到需要考虑移动端适配,Craft立即调整了之前生成的组件代码,添加了响应式设计相关的逻辑,而我甚至不需要重新解释整个组件的功能。
对话式编程的局限与突破
当然,Craft并非完美无缺。我发现在处理高度复杂的算法逻辑时,单纯的自然语言描述仍然存在局限。这时,我尝试结合传统编码与对话式指导:先由我编写核心算法框架,再让Craft帮我完善细节和边界情况处理。
这种人机协作模式极大地提高了我的编码效率,特别是在处理那些繁琐但不具挑战性的代码部分时。更重要的是,这种方式让我能够将更多精力集中在创造性思考和系统设计上,而非陷入重复性编码的泥潭。
在上面的基础上我又加以整改得到了一个暂时的框架(该框架我已放到github上,需要者自取)
地址:https://github.com/Leterhong/recommendation-system.com
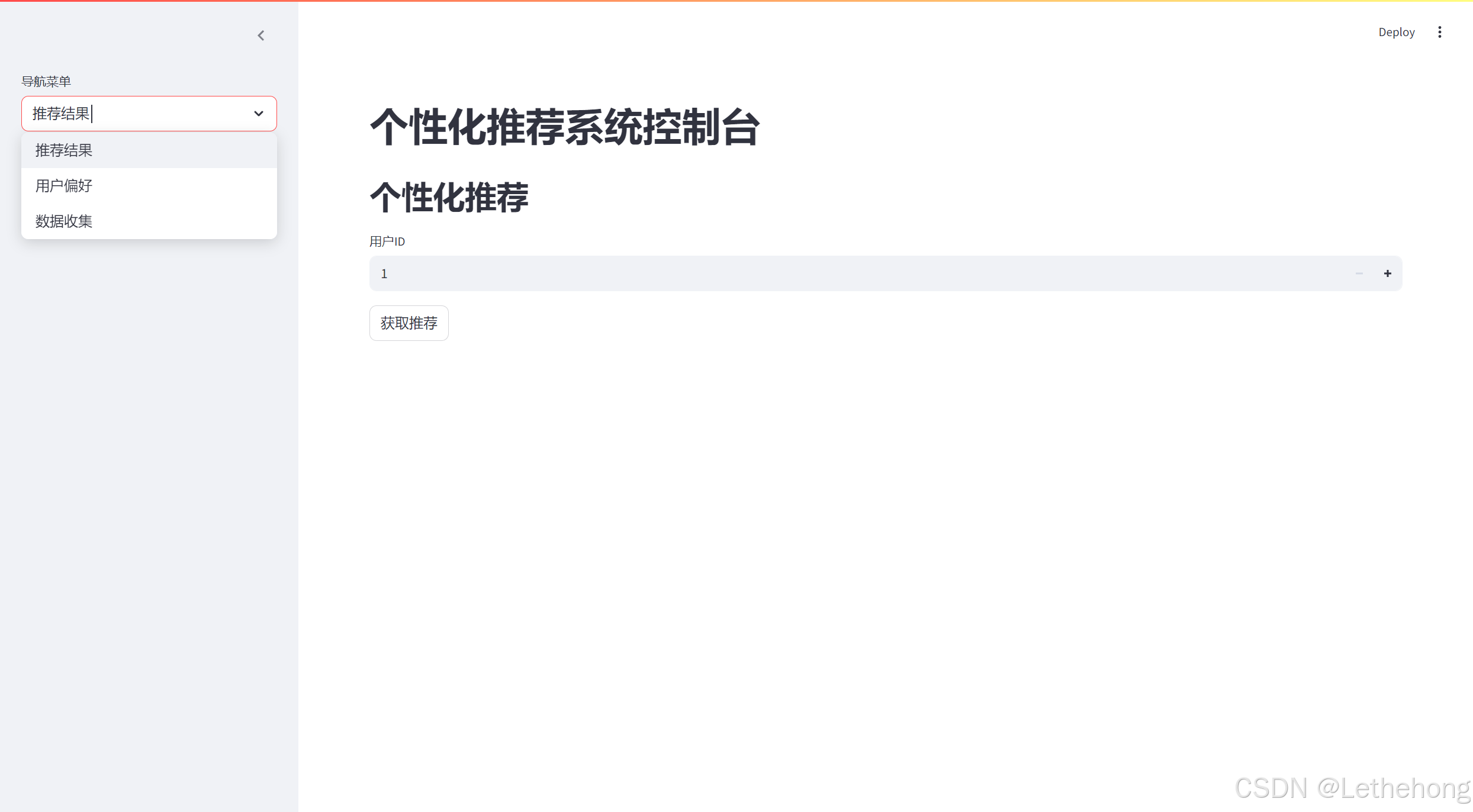
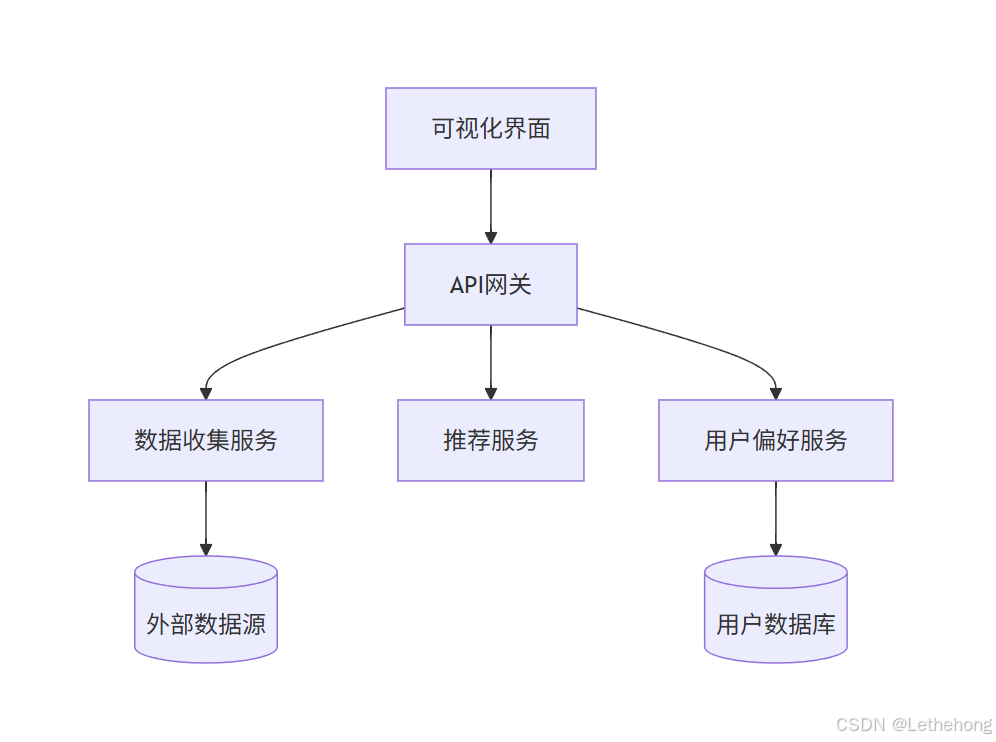 这是web界面(有点单调),这里我就偷了一下懒,没有去美化web界面了
这是web界面(有点单调),这里我就偷了一下懒,没有去美化web界面了
recommendation-system/
│
├── recommendation_system/ # 主Python包
│ ├── __init__.py # 包初始化文件
│ │
│ ├── api_gateway/ # API网关服务
│ │ ├── main.py # FastAPI应用入口
│ │ ├── __init__.py
│ │ └── Dockerfile # 容器化配置(端口:8000)
│ │
│ ├── data_collector/ # 数据收集服务
│ │ ├── main.py # 数据源连接器实现
│ │ ├── __init__.py
│ │ └── Dockerfile # 容器化配置(端口:8001)
│ │
│ ├── recommendation_service/ # 推荐算法服务
│ │ ├── main.py # 推荐算法实现
│ │ ├── __init__.py
│ │ └── Dockerfile # 容器化配置(端口:8002)
│ │
│ ├── user_preference_service/ # 用户偏好服务
│ │ ├── main.py # 用户数据管理
│ │ ├── __init__.py
│ │ └── Dockerfile # 容器化配置(端口:8003)
│ │
│ └── visualization/ # 可视化界面
│ ├── main.py # Streamlit应用入口
│ ├── __init__.py
│ └── Dockerfile # 容器化配置(端口:8501)
│
├── tests/ # 测试目录
│ ├── integration/
│ │ └── test_end_to_end.py # 端到端集成测试
│ │
│ ├── test_api_gateway.py # API网关单元测试
│ ├── test_data_collector.py # 数据收集测试
│ ├── test_recommendation_service.py # 推荐算法测试
│ ├── test_user_preference_service.py # 用户偏好测试
│ └── test_visualization.py # 界面组件测试
│
├── docker-compose.yml # 多容器编排配置
├── setup.py # Python包配置
├── requirements.txt # 项目依赖列表
├── .env # 环境变量配置
└── README.md # 项目文档# 个性化推荐微服务系统基于Python的微服务架构,实现从多数据源收集信息并提供个性化推荐功能。## 系统架构```mermaid
graph TDA[可视化界面] --> B[API网关]B --> C[数据收集服务]B --> D[推荐服务]B --> E[用户偏好服务]C --> F[(外部数据源)]E --> G[(用户数据库)]
```## 服务说明| 服务名称 | 端口 | 描述 |
|----------|------|------|
| API网关 | 8000 | 系统入口,路由请求到各微服务 |
| 数据收集服务 | 8001 | 从多种数据源收集和预处理数据 |
| 推荐服务 | 8002 | 实现个性化推荐算法 |
| 用户偏好服务 | 8003 | 管理用户偏好数据 |
| 可视化界面 | 8501 | 提供Web管理界面 |## 快速开始1. **安装依赖**```bashcd api-gateway && pip install -r requirements.txtcd ../data-collector && pip install -r requirements.txtcd ../recommendation-service && pip install -r requirements.txtcd ../user-preference-service && pip install -r requirements.txtcd ../visualization && pip install -r requirements.txt```2. **启动服务**在每个服务目录下运行:```bashpython main.py```或者使用脚本同时启动所有服务(需要安装tmux或类似工具)3. **访问可视化界面**```bashcd visualizationstreamlit run main.py```然后在浏览器中访问 http://localhost:8501## 配置要求- Python 3.8+
- PostgreSQL (用户偏好服务)
- MongoDB (推荐数据存储,可选)
- 各数据源的访问凭证## 环境变量根据需要设置以下环境变量:- `DATABASE_URL`: PostgreSQL连接字符串
- `MONGO_URI`: MongoDB连接字符串
- 各数据源的API密钥等
```## 开发指南1. **代码结构**```recommendation-system/├── api-gateway/ # API网关服务├── data-collector/ # 数据收集服务├── recommendation-service/ # 推荐引擎服务├── user-preference-service/ # 用户偏好服务└── visualization/ # 可视化Web界面```2. **测试**各服务包含独立的测试模块,运行:```bashpytest```3. **部署**建议使用Docker容器化部署:```bashdocker-compose up --build```所以,成长是一个过程,是一个累积。别人成功的时候,你看到他了问:你练了多久。最好的回答就是等下一个人问你的时候,你就成功了
MCP协议:打通开发全流程的桥梁

理解MCP:不只是一个协议,而是生态
Model Control Protocol (MCP)的引入,标志着CodeBuddy从单一工具向开发生态系统的转变。初次接触这一功能时,我并未完全理解其重要性。直到我将其与我日常使用的多种开发工具集成后,才真正感受到了这一协议的威力。
全流程开发体验:从需求到部署的无缝衔接
在一个中型Web应用项目中,我体验了MCP协议带来的全流程支持:
- 需求分析阶段:将需求文档直接导入CodeBuddy,通过MCP与我的需求管理工具同步。
- 设计阶段:CodeBuddy能够理解我在设计工具中创建的UI原型,并据此提供初步的组件结构建议。
- 开发阶段:在VSCode中,CodeBuddy通过MCP协议与版本控制系统无缝集成,每次提交代码时都能获得智能化的代码审查建议。
- 测试与部署:CodeBuddy甚至能够基于测试结果提供优化建议,并在部署流程中提醒潜在风险。
这种全流程支持的最大优势在于消除了工具间的壁垒。以往,我需要在多个平台间切换,每次切换都意味着上下文的中断和注意力的分散。而有了MCP协议的支持,这种割裂感大大减少,开发体验更加连贯顺畅。
团队协作中的MCP价值
在团队环境中,MCP的价值更为凸显。我们团队成员使用不同的IDE和工具链,曾经这意味着我们需要制定严格的代码规范和文档标准来确保协作顺畅。而现在,无论团队成员使用什么工具,CodeBuddy都能通过MCP协议提供一致的智能辅助,大大减少了沟通成本和协作摩擦。
一个具体案例:我们的前端开发者使用WebStorm,后端团队偏好IntelliJ IDEA,设计师则使用Figma。以往,从设计到实现的过程中,信息传递往往存在损耗和误解。而有了MCP支持的CodeBuddy,设计师的意图能够更准确地传递给开发者,开发者之间的协作也更加无缝。
DeepSeek V3:代码补全的新境界

从辅助到共创:AI代码补全的质变
DeepSeek V3的代码补全功能,与其说是一个工具升级,不如说是开发方式的一次革新。与传统的代码补全不同,DeepSeek V3不仅能预测下一个单词或语句,更能理解整个代码逻辑并提供上下文相关的智能建议。
实战体验:效率提升的量化分析
为了客观评估DeepSeek V3的效率提升,我在一个为期两周的项目中进行了对比测试:第一周使用常规IDE,第二周启用CodeBuddy的DeepSeek V3。结果令人印象深刻:
- 编码速度提升约35%:特别是在编写样板代码和处理熟悉但繁琐的逻辑时。
- Bug减少约28%:DeepSeek V3能够预见常见错误模式并提供更安全的代码建议。
- 学习曲线降低:在使用不太熟悉的库或框架时,补全建议常常包含最佳实践,间接促进了我的技能提升。
语言理解的深度与广度
DeepSeek V3对编程语言的理解深度尤为令人惊叹。在处理Python项目时,它不仅能提供语法级别的补全,还能根据上下文理解我可能需要的库函数和设计模式。更令人惊讶的是,它甚至能在注释中理解我的自然语言描述,并据此生成符合意图的代码。
在上面的个性化推荐系统控制台开发中,我需要实现一个复杂的并发处理逻辑。以往,这意味着我需要查阅大量文档和示例。而有了DeepSeek V3,我只需编写基本架构和关键注释,剩余的模板代码和异常处理逻辑几乎都由AI自动补全,不仅节省了时间,更减少了潜在的并发错误。
跨语言场景下的适应性
作为一个全栈开发者,我经常需要在不同编程语言间切换。DeepSeek V3在这方面表现出色,它能够准确识别当前的语言环境,并提供符合该语言惯例的补全建议。无论是TypeScript的类型系统,还是Rust的所有权模型,DeepSeek V3都展现出深入的理解。
一个特别的例子是在处理前后端交互时:当我在前端React组件中定义API请求时,DeepSeek V3能根据我之前编写的后端Node.js代码,准确推断出API的参数结构和返回类型,这种跨文件、跨语言的上下文理解能力极大地减少了前后端接口不匹配的问题。
结语:AI与程序员的共生未来
通过深入使用CodeBuddy的这三大升级功能,我对AI辅助编程的未来有了更清晰的认识。这不是简单的工具替代,而是一种新型的人机协作模式——AI处理例行任务和繁琐细节,而人类程序员则专注于创造性思考和决策制定。
在这种模式下,编程不再仅仅是"告诉计算机做什么",而是与一个能够理解你意图的智能助手进行对话。这种转变不仅提高了生产效率,更重要的是,它让编程这一活动变得更加自然、流畅,甚至更具人性。
作为开发者,我们应当拥抱这一变革,将AI视为我们的编程伙伴而非威胁。正如Craft智能体、MCP协议和DeepSeek V3所展示的那样,当我们学会与AI协同工作时,我们能够突破传统编程的限制,达到更高的创造力和效率境界。
最后,我想鼓励每一位开发者都尝试这些新工具和方法。初期可能需要一些适应时间,但一旦掌握了与AI协同工作的节奏,你会发现自己的编程体验和能力都将提升到一个全新的水平。未来的编程,不仅是人与机器的对话,更是思想与代码的共舞。让我们一起加油

)


















