一、快速排序回顾
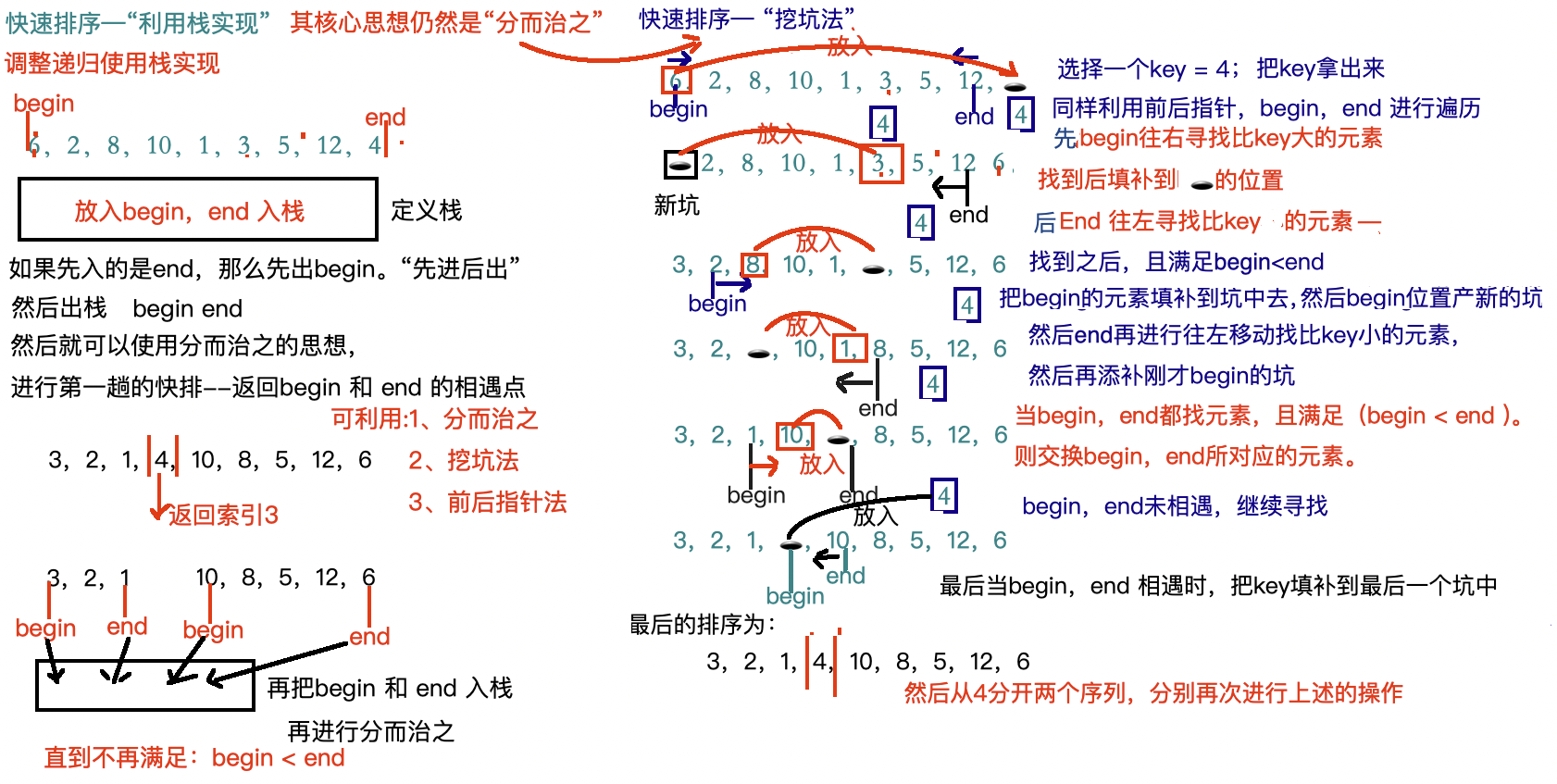
快速排序本质上是**“分而治之”(Divide and Conquer)策略的递归应用。但递归其实就是函数栈的一种体现,因此我们也可以显式使用栈(stack)来模拟递归过程**,从而实现非递归版本的快速排序。
往期“快速排序算法回顾”:
快速排序--挖坑法
快速排序-- 分而治之快速排序--前后指针法
注意:我们这里只是利用栈来模拟递归过程,递归算法会多次开辟额外的栈帧,利用栈的实现可以有效优化,避免爆栈。
🧱 二、利用栈实现非递归:
-
创建一个栈(保存左右区间的边界值);
-
把整个初始区间 [0, size-1] 入栈;
-
当栈不为空时:
-
弹出一个区间 [left, right];
-
对该区间做一次 Partition(分区);可利用前面我们学过的”前后指针“,”挖坑法“等
-
得到划分下标 pivot;
-
如果 [left, pivot-1] 有效,则入栈;
-
如果 [pivot+1, right] 有效,则入栈;
-
-
重复,直到栈为空。
思维导图:
代码实现:
void QuickSort_stack(int* arr,int left,int right){assert(arr);if(left>=right){return;}int size = right+1;int* stack = (int*)malloc(2*size*sizeof(int));//建立栈int top = 0;//先入左边,再入右边stack[top++] = left;stack[top++] = right;while (top>0){// 先进后出,所以先出右边int right = stack[--top]; //注意 -- 的用法int left = stack[--top];if(left<right){int div = PartSort2(arr,left,right); //利用分而治之的思想if(left<div-1){stack[top++] = left;stack[top++] = div-1;}if(div+1<right){stack[top++] = div+1;stack[top++] = right;}}} }
三、递归以及栈调用对比
| 项目 | 递归版 | 非递归(栈模拟) |
|---|---|---|
| 结构 | 简洁,易读 | 稍复杂,需维护栈 |
| 系统栈 | 占用系统调用栈 | 手动栈,控制更灵活 |
| 栈溢出风险 | 有,尤其数据近似有序 | 可优化,避免爆栈 |
| 应用场景 | 一般排序足够 | 资源受限场景、控制栈深度 |
| 可改进性 | 难以精细控制 | 可结合尾递归优化、栈平衡策略 |
四、📘 总结
栈实现快速排序的核心是把递归中“待处理的区间”压入一个显式栈,依次取出处理,用 迭代方式完成原本的递归流程。这样做不仅可以避免函数栈溢出,还可以为后续的性能优化提供空间。
五、进一步优化建议
-
栈小区间优先处理(如先压小区间)可以避免栈过深;
-
对小区间(如 <16 元素)可以切换为插入排序,提高性能;
-
使用“三数取中”或“随机选主元”策略改善最坏情况;



采用分布式哈希表优化区块链索引结构,提高区块链检索效率)
配置元件详解01)


)
--Cartographer在Gazebo仿真环境下的建图以及建图与定位阶段问题(实车也可参考))



)






