代码质量其实在需求高压,业务快速迭代的场景下往往容易被人忽视的问题,大家的编码习惯和规范也经常会各有喜好,短期之内获取看不出来什么问题,但长此以往就会发现,屎山逐步成型了,而线上代码跑着往往就不想改也不敢改了,所以团队成员有一个良好的开发习惯,统一的编码规范和一定的代码洁癖是很重要的。
但是项目代码量一上来,其实再想逐行分析代码的问题就很麻烦了,由此便有了本文的亡羊补牢的方案。(最好还是防患于未然,不要亡羊补牢,至于预防方案后续再更)。
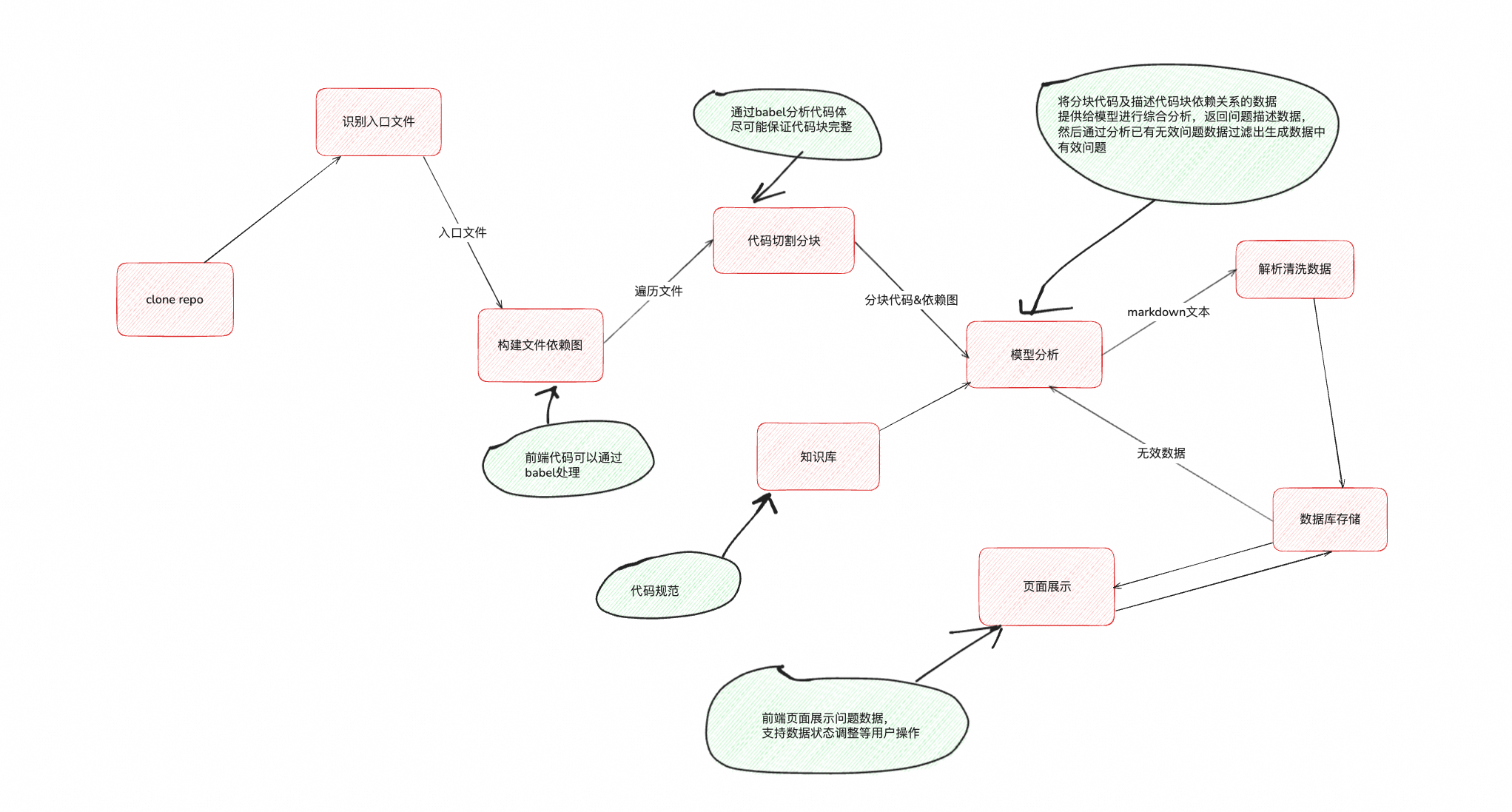
设计图
clone代码
账号准备
公共账号1个,使用公共账号作为clone仓库的账号,避免使用个人账号受权限和人员变动影响
clone工具
可以通过simple-git或者直接执行shell命令的方式来操作git仓库代码,机器硬盘存储空间充足的情况下可以考虑保存clone后的代码目录,clone前检查是否存在,存在就pull更新避免每次clone提高效率
入口文件分析
一般而言仓库代码入口文件是可知的,拿前端代码举例,一般为路由对应的页面入口文件或者npm包的入口文件。尤其在团队规范统一的情况下,入口文件的逻辑应该是一个相对标准的,更加易于识别。
构建依赖图
“依赖”和“图”是两个点,前端代码我们可以像项目构建一样,通过@babel/parser中的parse来从入口文件开始解析成ast,然后通过@babel/traverse来遍历ast解析其代码依赖文件,递归处理获取依赖关系,其他语言的项目也会有类似的工具可以处理。因为代码依赖不会是一个简单的“树”形结构,往往树“图”结构的,而“图”的结构数据体积也会相对小一些。
代码分块
模型在一次对话的输入数据的大小往往是有限制的,也就是常见的长文本处理问题。我们在通过@babel/parser获取ast后可以通过遍历ast.program.body来获取完整的代码区块。
const ast = parse(code, {sourceType: 'module',plugins: ['typescript'],errorRecovery: true,attachComment: false,});
for (const node of ast.program.body) {const codeSnippet = code.slice(node.start, node.end);// TODO: 自行拼接代码区块}
然后按照模型单次对话接收文本长度阈值的限制来拼接代码块,分多次对话提供给模型,利用模型记忆多轮历史对话的能力即可全部提供给模型。
模型分析
模型在接收完全部代码区块和依赖图数据后,对内容进行整体分析即可检查出代码存在的问题,此外我们可以通过在知识库中补充团队的代码规范、优秀代码demo示例等信息利用RAG的能力来提高输出结果的质量。因为模型会存在幻觉的问题,所以我们在模型输出一波问题以后让其参考人工标注过的无效问题数据来进行二次过滤,筛选出真正有效的问题,自此便可以拿到我们需要的结果
备注
提示词书写可以参考之前的文章:如何写高效的Prompt?
)
--Cartographer在Gazebo仿真环境下的建图以及建图与定位阶段问题(实车也可参考))



)








)
)


)
