一、混淆矩阵
混淆矩阵是机器学习中评估分类模型性能的重要工具,尤其适用于二分类或多分类任务。它通过展示模型预测结果与实际标签的匹配情况,帮助理解模型的错误类型(如假阳性、假阴性等)。以下通过二分类场景为例,结合图示和概念解析混淆矩阵的核心内容。
一、二分类混淆矩阵基础结构
二分类问题中,数据标签只有两类(通常称为 “正类” 和 “负类”),混淆矩阵为 2×2 矩阵,结构如下:
| 实际标签 \ 预测标签 | 预测为正类(Positive) | 预测为负类(Negative) |
|---|---|---|
| 实际为正类(Positive) | 真正例(TP) | 假负例(FN) |
| 实际为负类(Negative) | 假正例(FP) | 真负例(TN) |
二、核心概念与图示说明
为更直观理解,我们用一个场景举例:假设模型用于预测 “是否患癌症”,其中 “患癌症” 为正类(P),“未患癌症” 为负类(N)。
真正例(True Positive, TP)
- 实际标签为正类(确实患癌症),模型预测也为正类(正确预测患病)。
- 例:病人确实得了癌症,模型判断为 “患病”。
假负例(False Negative, FN)
- 实际标签为正类(确实患癌症),但模型预测为负类(错误预测为未患病)。
- 例:病人得了癌症,模型却判断为 “未患病”(漏诊)。
假正例(False Positive, FP)
- 实际标签为负类(未患癌症),但模型预测为正类(错误预测为患病)。
- 例:病人没患癌症,模型却判断为 “患病”(误诊)。
真负例(True Negative, TN)
- 实际标签为负类(未患癌症),模型预测也为负类(正确预测未患病)。
- 例:病人确实没患癌症,模型判断为 “未患病”。
三、从混淆矩阵衍生的关键指标
混淆矩阵的价值不仅在于展示错误分布,更能通过这些数值计算模型性能指标:
| 指标 | 计算公式 | 含义(以癌症预测为例) |
|---|---|---|
| 准确率(Accuracy) | (TP+TN)/(TP+TN+FP+FN) | 整体预测正确的比例(所有判断对的样本占比) |
| 精确率(Precision) | TP/(TP+FP) | 预测为正的样本中,实际真为正的比例(避免误诊) |
| 召回率(Recall) | TP/(TP+FN) | 实际为正的样本中,被正确预测的比例(避免漏诊) |
| F1 分数 | 2×(Precision×Recall)/(Precision+Recall) | 精确率和召回率的调和平均, |
还有多分类混淆矩阵就不介绍了,原理相同
用这个混淆举证是方便看代码的优化效果
二、正则化惩罚
正则化是机器学习中防止模型 “学过头”(过拟合)的技术,通过 “惩罚复杂模型” 让模型更简单、更通用。以下用图示和例子通俗讲解。
1、为什么需要正则化?—— 过拟合的问题
当模型太复杂(比如参数太多),会 “死记硬背” 训练数据里的细节甚至噪声,导致:
- 训练时表现极好(拟合了所有细节);
- 遇到新数据时表现很差(无法通用)。
直观对比图:
数据点(带噪声)→ ● ● ● ● ●
真实规律 → ───────(简单直线) 无正则化的模型 → ╲╱╲╱╲╱(曲线扭曲,贴合每个点,过拟合)
有正则化的模型 → ───────(曲线平滑,接近真实规律,泛化好) 正则化的作用:给复杂模型 “降复杂度”,让它别太纠结训练数据的细节。
2、正则化怎么工作?—— 给参数 “减肥”
模型的预测能力来自 “参数”(类似公式里的系数)。参数越大、数量越多,模型越复杂。
正则化通过 “惩罚大参数”,让参数值变小或变少,从而简化模型。
形象比喻:
- 把模型比作 “学生”,训练数据是 “课本”,测试数据是 “考试”。
- 过拟合的学生:死记硬背课本里的每个字(包括错别字),考试换题型就不会了。
- 正则化:要求学生 “理解核心原理”(参数简化),别死记细节,考试时更能灵活应对。
3、常见的两种正则化(图示对比)
1. L2 正则化:让参数 “变瘦”
- 效果:让所有参数的数值都变小(但很少变成 0),就像给参数 “整体减肥”,让模型更 “稳健”。
- 图示:
无正则化 → 参数值:[10, 8, -7](数值大,模型敏感) L2正则化后 → 参数值:[2, 1.5, -1.2](数值变小,模型更平缓)
2. L1 正则化:让参数 “消失”
- 效果:直接让不重要的参数变成 0(相当于删掉这些参数),实现 “特征选择”,让模型更 “简洁”。
- 图示:
无正则化 → 参数值:[10, 8, -7](3个参数都在用) L1正则化后 → 参数值:[3, 0, -2](中间参数被“删掉”,只剩2个有用参数)
3、正则化的强度控制(λ 的作用)
正则化的 “惩罚力度” 由参数 λ 控制:
λ太小 → 惩罚太轻 → 模型还是复杂(可能过拟合)
λ适中 → 惩罚刚好 → 模型简单且准确(最佳状态)
λ太大 → 惩罚太重 → 模型太简单(连基本规律都没学到,欠拟合)
图示
模型效果(测试集 accuracy)
↑
| 最佳λ → 效果峰值
| ┌───┐
| / \
| / \
| / \
+------------→ λ(惩罚力度) 过拟合 欠拟合 (λ小) (λ大)
正则化的核心就是:给复杂模型 “加约束”,通过惩罚大参数或冗余参数,让模型在 “拟合数据” 和 “保持通用” 之间找平衡。
- L2 正则化:让参数变 “小”,模型更稳健;
- L1 正则化:让参数变 “少”,模型更简洁;
- 选对惩罚力度(λ),模型才能既不 “学太死”,也不 “学不会”。
三、交叉验证
交叉验证是机器学习中评估模型 “真实能力” 的常用方法,能帮我们避免因数据划分不合理导致的评估偏差,判断模型是否真正 “学好了”。以下用通俗语言和图示介绍。
1、为什么需要交叉验证?—— 避免 “运气成分”
假设你训练模型时,随机把数据分成 “训练集”(学知识)和 “测试集”(考考试):
- 如果测试集刚好很简单,模型分数会虚高;
- 如果测试集刚好很难,模型分数会偏低。
问题:一次划分的结果可能受 “运气” 影响,无法反映模型真实水平。
交叉验证的作用:通过多次划分数据、多次评估,取平均值,让结果更可靠,就像 “多次考试取平均分” 更能反映真实成绩。
2、最常用的交叉验证:K 折交叉验证(图示步骤)
以 “5 折交叉验证” 为例,步骤如下:
1. 数据划分
把所有数据均匀分成 K 份(比如 5 份,每份叫一个 “折”):
原始数据 → [折1] [折2] [折3] [折4] [折5] (每份数据量相近)
2. 多次训练与评估
每次用 K-1 份当训练集,剩下 1 份当测试集,重复 K 次(每个折都当一次测试集):
第1次:训练集=[折2,3,4,5] → 测试集=[折1] → 得分数1
第2次:训练集=[折1,3,4,5] → 测试集=[折2] → 得分数2
第3次:训练集=[折1,2,4,5] → 测试集=[折3] → 得分数3
第4次:训练集=[折1,2,3,5] → 测试集=[折4] → 得分数4
第5次:训练集=[折1,2,3,4] → 测试集=[折5] → 得分数5
3. 结果平均
把 K 次的分数取平均值,作为模型的最终评估结果:
最终分数 = (分数1 + 分数2 + 分数3 + 分数4 + 分数5)÷ 5
2、交叉验证的优势(对比单次划分)
| 方法 | 优点 | 缺点 |
|---|---|---|
| 单次划分( train/test ) | 简单快速 | 结果受随机划分影响大,数据利用率低 |
| K 折交叉验证 | 结果更稳定可靠,充分利用所有数据 | 计算量增加(需训练 K 次模型) |
4、其他常见交叉验证类型
1. 留一交叉验证(Leave-One-Out)
- 把数据分成 N 份(N 等于样本数量),每次留 1 个样本当测试集,重复 N 次。
- 优点:结果极可靠;缺点:计算量极大(适合小数据集)。
2. 分层 K 折交叉验证
- 当数据不平衡(比如 90% 是正例,10% 是负例),保证每个折中正负例比例和原始数据一致。
- 例:原始数据正:负 = 9:1 → 每个折中也保持 9:1,避免测试集全是正例的极端情况。
5、交叉验证的核心作用
- 评估模型泛化能力:判断模型是否能在新数据上表现良好,而非只 “死记” 训练数据。
- 选择最佳参数:比如用交叉验证比较不同 λ 的正则化效果,选分数最高的 λ。
- 减少数据浪费:充分利用有限数据,尤其适合小数据集。
四、下采样和过采样
在机器学习中,采样是处理类别不平衡问题(即数据集中某一类样本数量远多于另一类)的常用方法。过采样和下采样是两种主要策略,核心目标是通过调整样本比例,让模型更公平地学习不同类别的特征。
1. 下采样(Undersampling)
- 核心思想:减少多数类(样本多的类别)的数量,使其与少数类(样本少的类别)数量接近。
- 操作方式:从多数类样本中随机挑选一部分,丢弃其余样本,让两类样本数量大致平衡。
- 例子:
假设数据集中有 1000 个正常交易(多数类)和 10 个欺诈交易(少数类),下采样可能会从 1000 个正常交易中随机选 10 个,最终用 10 个正常 + 10 个欺诈样本训练模型。 - 优点:计算成本低(样本量变少)。
- 缺点:可能丢失多数类中的重要信息(被丢弃的样本可能包含关键特征)。
2. 过采样(Oversampling)
- 核心思想:增加少数类(样本少的类别)的数量,使其与多数类数量接近。
- 操作方式:通过复制少数类样本,或用算法生成 “新的少数类样本”(如 SMOTE 算法:基于现有少数类样本的特征,生成相似的虚拟样本),扩大少数类规模。
- 例子:
对上述 10 个欺诈交易,过采样可能会复制它们 100 次(或生成 990 个相似样本),最终用 1000 个正常 + 1000 个欺诈样本训练模型。 - 优点:保留多数类的全部信息,避免关键数据丢失。
- 缺点:简单复制可能导致模型过拟合少数类(记住重复样本的细节);生成虚拟样本需谨慎,避免引入噪声。
总结对比
| 方法 | 核心操作 | 适用场景 | 关键问题 |
|---|---|---|---|
| 下采样 | 减少多数类样本 | 多数类样本极多、计算资源有限 | 可能丢失重要信息 |
| 过采样 | 增加少数类样本(复制 / 生成) | 少数类样本有价值但数量少 | 可能过拟合、需合理生成样本 |
实际应用中,常结合两者(如 “过采样少数类 + 下采样多数类”)或配合其他策略(如调整模型权重)来处理不平衡问题。
五、银行借贷案例
假设有一个银行,统计了很多贷款人的多条数据和对应的还款情况,想让你分析建立一个模型来检验一个即将贷款的人是否会按规定还款
数据集的大致形状如图所示(数据集可以去我主页下载)
进过前几天的学习,你很高兴的写出来如下代码
# 导入必要的库
import pandas as pd # 用于数据处理和分析
from sklearn.preprocessing import StandardScaler # 用于数据标准化
from sklearn.linear_model import LogisticRegression # 导入逻辑回归模型
from sklearn.model_selection import train_test_split # 用于拆分训练集和测试集
from sklearn import metrics # 用于模型评估指标计算# 读取信用卡交易数据
# 数据集包含信用卡交易信息,其中'Class'列为目标变量(1表示欺诈交易,0表示正常交易)
date = pd.read_csv('creditcard.csv')# 初始化标准化器,将数据缩放到均值为0、标准差为1的范围
sal = StandardScaler()
# 对交易金额(Amount)进行标准化处理,使其与其他特征具有相同的量级
date['Amount'] = sal.fit_transform(date[['Amount']])# 删除'Time'列(时间特征),因为该特征对欺诈检测可能没有帮助
date = date.drop(['Time'], axis=1)# 划分特征变量(X)和目标变量(y)
# 取除最后一列之外的所有列作为特征
x = date.iloc[:, :-1]
# 取最后一列'Class'作为目标变量(是否为欺诈交易)
y = date['Class']# 将数据集拆分为训练集和测试集
# test_size=0.3表示30%的数据作为测试集,70%作为训练集
# random_state=42保证每次运行代码时拆分结果一致,便于复现
xtr, xte, ytr, yte = train_test_split(x, y, test_size=0.3, random_state=42)# 初始化逻辑回归模型
# C=0.01:正则化强度的倒数,值越小正则化越强
# penalty='l2':使用L2正则化(岭回归)
# solver='lbfgs':优化算法
# max_iter=1000:最大迭代次数,确保模型收敛
lr = LogisticRegression(C=0.01, penalty='l2', solver='lbfgs', max_iter=1000)# 训练模型(注意:这里使用了全部数据训练,而不是之前拆分的训练集xtr)
lr.fit(x, y)# 使用训练好的模型对测试集进行预测
test_predicted = lr.predict(xte)# 计算模型在测试集上的准确率
score = lr.score(xte, yte)# 输出预测结果
print("预测结果:", test_predicted)
# 输出模型准确率
print("模型准确率:", score)
# 输出详细的分类评估报告,包括精确率、召回率、F1分数等
# 对于欺诈检测这类不平衡数据,这些指标比单纯的准确率更有参考价值
print(metrics.classification_report(yte, test_predicted))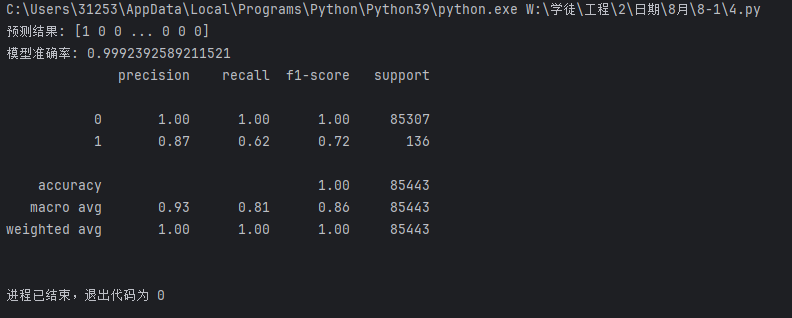
看了一下结果,不错,99.92%的模型准确率,你很高兴,但是银行的甲方斜着眼看你要你出门右转,为啥呢?
因为1这个数据的召回率(Recall)只有62%,和瞎猜的50%差不多,这个肯定不达标
这时你想了想,尝试换了参数,但怎么换呢?
可以试试用交叉验证来求出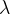 的最佳值
的最佳值
于是写出以下代码
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn import metrics
import numpy as np
date = pd.read_csv('creditcard.csv')
sal = StandardScaler()
date['Amount'] = sal.fit_transform(date[['Amount']])
date = date.drop(['Time'],axis = 1)
x = date.iloc[:,:-1]
y = date['Class']
xtr,xte,ytr,yte=train_test_split(x,y,test_size=0.3,random_state=42)
######################################
from sklearn.model_selection import cross_val_score
scores = []
c_param_range = [0.01,0.1,1,10,100]
for i in c_param_range:lr = LogisticRegression(C=i,penalty='l2',solver='lbfgs',max_iter=1000)score = cross_val_score(lr,xtr,ytr,cv=10,scoring='recall')score_mean = sum(score)/len(score)scores.append(score_mean)print(score_mean)
best_c = c_param_range[np.argmax(scores)]
print('最佳的惩罚值:',best_c)
##################################
lr = LogisticRegression(C=best_c,penalty='l2',solver='lbfgs',max_iter=1000)
lr.fit(x,y)
test_predicted = lr.predict(xte)
score = lr.score(xte,yte)
print("预测结果:", test_predicted)
print("模型准确率:", score)
print(metrics.classification_report(yte,test_predicted))
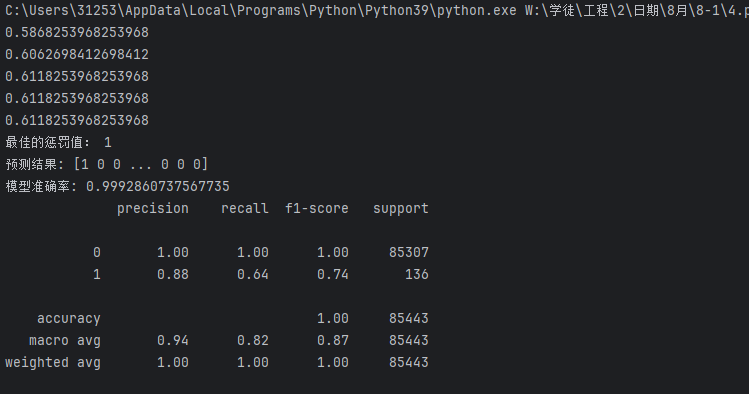
发现有改变,但不大
继续找方法
这时发现训练数据里面0的数据有几十万,但1的数据只有几百条
突然,你想到了下采样和过采样的方法,于是写出下列两个代码
下采样:
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn import metrics
import numpy as np
date = pd.read_csv('creditcard.csv')
sal = StandardScaler()
date['Amount'] = sal.fit_transform(date[['Amount']])
date = date.drop(['Time'],axis = 1)
x = date.iloc[:,:-1]
y = date['Class']
xtr,xte,ytr,yte=train_test_split(x,y,test_size=0.3,random_state=42)
##################################
new_date = xtr.copy()
new_date['Class'] = ytr
positive_eg = new_date[new_date['Class']==0]
negative_eg = new_date[new_date['Class']==1]
positive_eg = positive_eg.sample(len(negative_eg))
date_c = pd.concat([positive_eg,negative_eg])
x = date_c.iloc[:,:-1]
y = date_c['Class']
##################################
from sklearn.model_selection import cross_val_score
scores = []
c_param_range = [0.01,0.1,1,10,100]
for i in c_param_range:lr = LogisticRegression(C=i,penalty='l2',solver='lbfgs',max_iter=1000)score = cross_val_score(lr,xtr,ytr,cv=10,scoring='recall')score_mean = sum(score)/len(score)scores.append(score_mean)print(score_mean)
best_c = c_param_range[np.argmax(scores)]
print('最佳的惩罚值:',best_c)
lr = LogisticRegression(C=best_c,penalty='l2',solver='lbfgs',max_iter=1000)
lr.fit(x,y)
test_predicted = lr.predict(xte)
score = lr.score(xte,yte)
print("预测结果:", test_predicted)
print("模型准确率:", score)
print(metrics.classification_report(yte,test_predicted))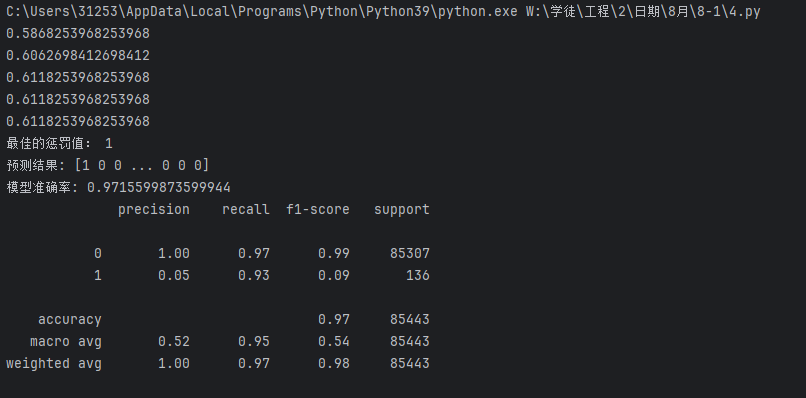
过采样:
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn import metrics
import numpy as np
print('过采样')
date = pd.read_csv('creditcard.csv')
sal = StandardScaler()
date['Amount'] = sal.fit_transform(date[['Amount']])
date = date.drop(['Time'],axis = 1)
x = date.iloc[:,:-1]
y = date['Class']
xtr,xte,ytr,yte=train_test_split(x,y,test_size=0.3,random_state=42)
############################################
from imblearn.over_sampling import SMOTE
oversampler = SMOTE(random_state=1000)
os_xtr,os_ytr = oversampler.fit_resample(xtr,ytr)
x = os_xtr
y = os_ytr
##########################################
from sklearn.model_selection import cross_val_score
scores = []
c_param_range = [0.01,0.1,1,10,100]
for i in c_param_range:lr = LogisticRegression(C=i,penalty='l2',solver='lbfgs',max_iter=1000)score = cross_val_score(lr,xtr,ytr,cv=10,scoring='recall')score_mean = sum(score)/len(score)scores.append(score_mean)print(score_mean)
best_c = c_param_range[np.argmax(scores)]
print('最佳的惩罚值:',best_c)
lr = LogisticRegression(C=best_c,penalty='l2',solver='lbfgs',max_iter=1000)
lr.fit(x,y)
test_predicted = lr.predict(xte)
score = lr.score(xte,yte)
print("预测结果:", test_predicted)
print("模型准确率:", score)
print(metrics.classification_report(yte,test_predicted))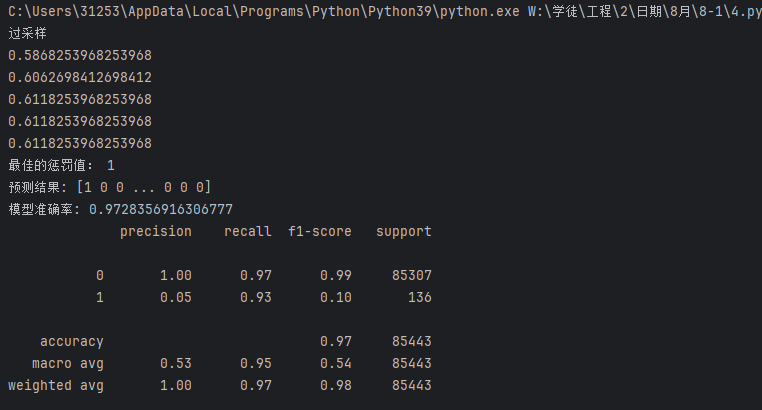
运行完你很高兴,准确率提高了不少
数据1的精确率(Precision)不太重要,毕竟银行错了没有损失,但漏了一个的损失就不小了
对比一下发现效果差不多,
但是甲方说要达到95%才行
于是你拿出另一个办法--改阙值
分类阈值的作用:逻辑回归默认使用 0.5 作为阈值(正类概率 > 0.5 则判定为正类),但在欺诈检测等场景中,我们可能需要调整阈值以提高对少数类(欺诈交易)的识别能力。
为何关注召回率:在检测中,召回率(对真实欺诈交易的识别率)通常比准确率更重要,因为漏检(假负例)的代价可能远高于误判(假正例)。
阈值调整的影响:
- 降低阈值(如 0.1):模型更 “容易” 判定为正类,可能提高召回率(减少漏检),但可能增加假正例
- 提高阈值(如 0.9):模型更 “严格” 判定为正类,可能降低召回率(增加漏检),但假正例会减少
这里用便利循环的方法来修改(在代码 最后加上以下代码)
# 定义一系列分类阈值(决策阈值),范围从0.1到0.9
# 分类阈值是模型判断样本属于正类的概率临界点
thresholds = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
# 用于存储不同阈值对应的召回率
recalls = []
# 遍历每个阈值,计算并观察召回率变化
for i in thresholds:# 获取模型对测试集的预测概率# 返回值是一个二维数组,每行包含两个概率:[负类概率, 正类概率]y_predict_proba = lr.predict_proba(xte)# 将概率数组转换为DataFrame,方便处理y_predict_proba = pd.DataFrame(y_predict_proba)# 根据当前阈值i调整预测结果:# 当正类(索引1对应的类别,即欺诈交易)的概率大于i时,判定为正类(1)y_predict_proba[y_predict_proba[[1]] > i] = 1# 当正类概率小于等于i时,判定为负类(0)y_predict_proba[y_predict_proba[[1]] <= i] = 0# 计算当前阈值下的召回率(Recall)# 召回率 = 真正例/(真正例+假负例),衡量模型对正类(欺诈交易)的识别能力recall = metrics.recall_score(yte, y_predict_proba[1])# 将当前阈值的召回率存入列表recalls.append(recall)# 打印当前阈值和对应的召回率,观察变化趋势print(i, recall)
print(f'调整阈值后的recall为:{max(recalls)}')
#这里直接输出1这个数据的召回率(Recall)运行结果:
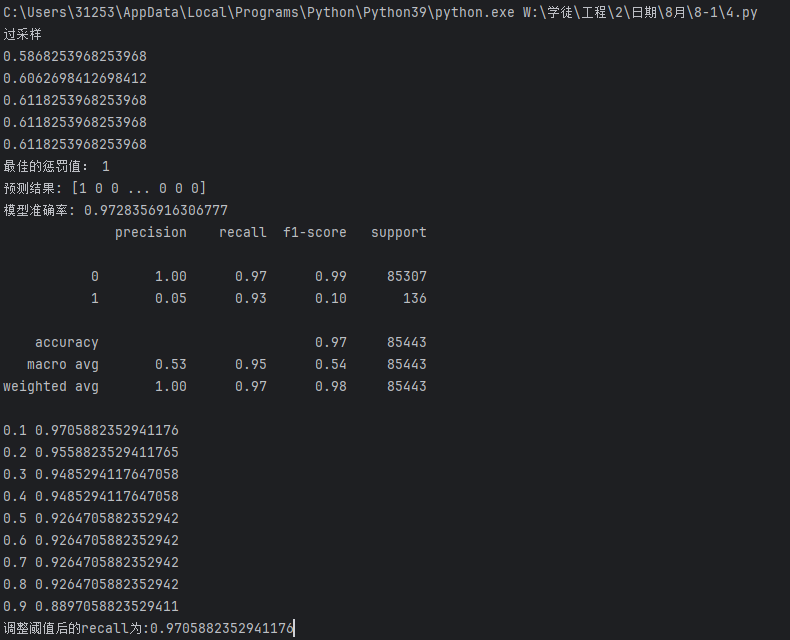
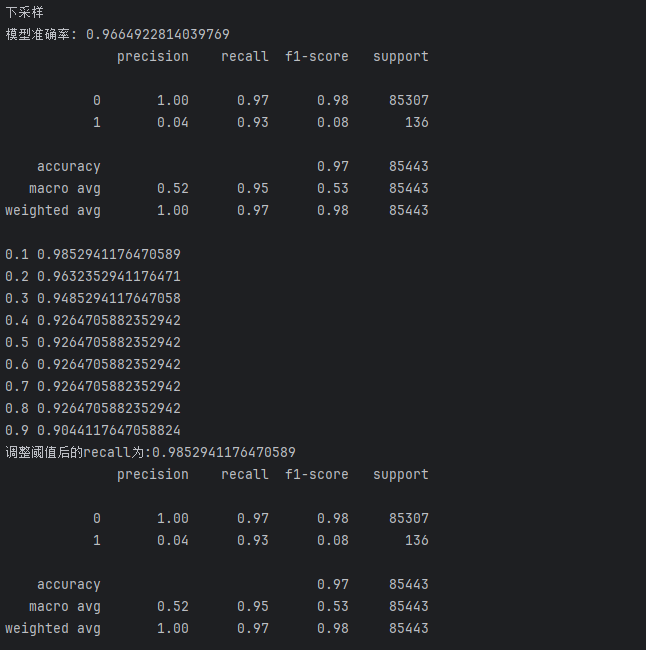
发现下采样效果好一点
但实际上也可以通过分割训练集测试集的随机种子来调整准确率的高低,但这个太费时间还没有定数,这里就不管了
最后,你把模型交给了银行的甲方
任务大功告

)
)





)










