文章目录
- 模型选择与调优:从理论到实战
- 1. 引言
- 2. 模型评估:为选择提供依据
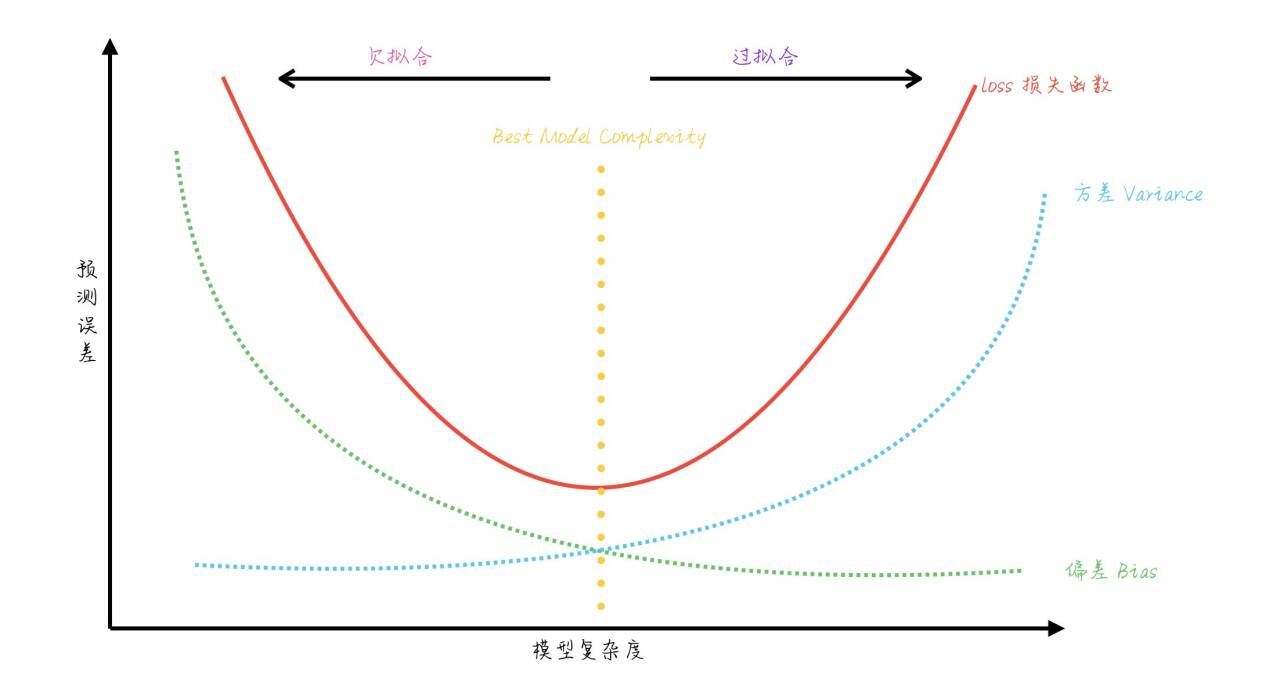
- 2.1 偏差-方差权衡
- 2.2 数据集划分与分层抽样
- 2.3 交叉验证(Cross-Validation)
- 2.4 信息准则(AIC / BIC)
- 3. 超参数调优:让模型更好
- 3.1 网格搜索 (Grid Search)
- 3.2 随机搜索 (Randomized Search)
- 3.3 贝叶斯优化 (Bayesian Optimization)
- 4. 模型选择:如何最终定夺
- 4.1 集成学习的思路
- 4.2 评估指标(详细公式)
- 分类任务:
- 回归任务:
- 5. 实战案例:以 KNN 和随机森林为例
- 6. 总结与建议
模型选择与调优:从理论到实战
1. 引言
在机器学习中,模型选择与调优是决定模型性能的关键步骤。一个好的算法如果参数配置不当,可能表现不如一个简单模型;而错误的评估方法也可能导致“看似很准”,实则泛化能力极差。本文将从模型评估、超参数调优和模型比较三个维度展开,并结合公式、代码和图示给出系统性理解。
2. 模型评估:为选择提供依据
2.1 偏差-方差权衡
模型预测误差可分解为:
E[(y−f^(x))2]=Bias2+Variance+σ2\mathbb{E}[(y-\hat{f}(x))^2] = \text{Bias}^2 + \text{Variance} + \sigma^2 E[(y−f^(x))2]=Bias2+Variance+σ2
- Bias(偏差):模型假设与真实分布的差异。
- Variance(方差):模型对训练数据波动的敏感性。
- σ2\sigma^2:不可约误差。
图示通常表现为:模型复杂度增加 → 偏差下降、方差上升。最佳点是两者平衡的位置。
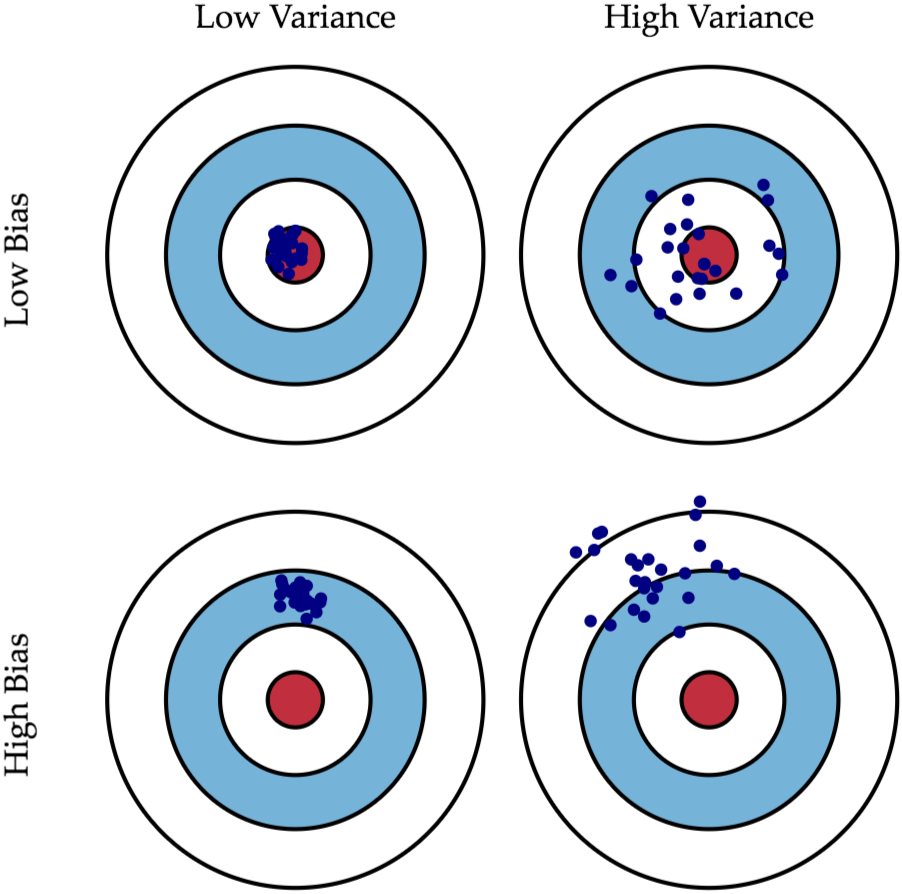
什么是偏差(Bias)? 什么是方差(Variance)?
其实可以套到生活中"准" 跟"确" 这两个概念,如果用高中军训课打靶的经验来说,那就是:
如果说你打靶打得很精"准",意味你子弹射中的地方离靶心很近,即Low Bias;
如果说你打靶打得很精"确",意味你在发射数枪之后这几枪彼此之间在靶上的距离很近,即Low Variance。
接着下面用一张图来说明,应该就一目了然了!
2.2 数据集划分与分层抽样
保留交叉验证Hold-Out(留出法)是最简单的评估方式:将数据分为训练集和测试集。但对于类别不平衡问题,普通划分可能导致训练或测试集中类别分布偏移。此时应使用 train_test_split 的分层参数:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42
)
stratify=y:确保分割后各数据集的类别比例与原始数据一致,减少评估偏差。
2.3 交叉验证(Cross-Validation)
不同交叉验证方法的对比:
-
K-Fold
-
K 折交叉验证将数据集分割为
K个互斥的子集(折叠,fold),每次用K-1个子集作为训练集,剩下的 1 个子集作为验证集,重复K次,最终得到K个模型的评估结果(如准确率、MSE 等),取平均值作为模型的最终性能指标。 -
实现:
from sklearn.model_selection import KFold -
公式:
CV Error=1K∑i=1KEi\text{CV Error} = \frac{1}{K} \sum_{i=1}^K E_i CV Error=K1i=1∑KEi -
适用于数据量较大、类别分布均衡的情况。
-
-
Stratified K-Fold
-
Stratified K-Fold(分层 K 折交叉验证) 是 K 折交叉验证的一种改进版本,专门用于分类问题,其核心特点是在划分数据集时保持每个折中类别比例与原始数据集一致,避免因随机划分导致的类别分布失衡,从而更稳健地评估模型性能。
-
实现:
from sklearn.model_selection import StratifiedKFold
-
-
Leave-One-Out (LOO)
- 每次只留一个样本作为验证,其余样本作为训练。
- 优点:几乎无偏估计。
- 缺点:计算量大、方差高。
-
Hold-Out
- 单次划分,计算效率高,但结果波动较大。
K 折交叉验证的作用不是“提高泛化性”,而是更稳定、无偏地估计泛化误差。调参过程中,它帮助选择在新数据上表现最好的模型。
代码示例:
from sklearn.datasets import load_wine
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
import numpy as np# 1. 加载数据
X, y = load_wine(return_X_y=True)# 2. 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 3. 创建KFold对象
kfold = KFold(n_splits=5, shuffle=True, random_state=42)# 4. 进行交叉验证
scores = []
for train_idx, test_idx in kfold.split(X_scaled):X_train, X_test = X_scaled[train_idx], X_scaled[test_idx]y_train, y_test = y[train_idx], y[test_idx]# 训练模型knn = KNeighborsClassifier(n_neighbors=5)knn.fit(X_train, y_train)# 预测并计算准确率y_pred = knn.predict(X_test)score = accuracy_score(y_test, y_pred)scores.append(score)# 5. 输出结果
print("每折的准确率:", scores)
print("平均准确率:", np.mean(scores))
print("标准差:", np.std(scores))
输出结果如下:
每折的准确率: [0.9444444444444444, 0.9444444444444444, 0.9722222222222222, 0.9142857142857143, 0.9714285714285714]
平均准确率: 0.9493650793650794
标准差: 0.02139268011280184
2.4 信息准则(AIC / BIC)
对于概率模型,可使用信息准则进行模型选择:
-
AIC(Akaike Information Criterion):
AIC=2k−2ln(L)\text{AIC} = 2k - 2\ln(L) AIC=2k−2ln(L)- kkk:模型参数数量
- LLL:似然函数最大值
- 目标:惩罚参数数量,鼓励较好拟合。
-
BIC(Bayesian Information Criterion):
BIC=kln(n)−2ln(L)\text{BIC} = k\ln(n) - 2\ln(L) BIC=kln(n)−2ln(L)- nnn:样本数量
- 与 AIC 区别:BIC 对模型复杂度惩罚更强,更倾向选择简单模型。
功能总结:
- AIC 偏好泛化能力强的模型。
- BIC 偏好更简单、更保守的模型。
- 二者都基于最大似然估计,适用于概率模型(如回归、时间序列)。
3. 超参数调优:让模型更好
3.1 网格搜索 (Grid Search)
穷举所有组合,计算成本高但适合小搜索空间:
from sklearn.model_selection import GridSearchCV
param_grid = {'n_neighbors': [3,5,7], 'weights': ['uniform','distance']}
grid = GridSearchCV(KNeighborsClassifier(), param_grid, cv=5)
grid.fit(X_train, y_train)
print(grid.best_params_, grid.best_score_)
weights='uniform'(默认值):等权重
- 含义:所有 K 个邻居的投票权重相同,预测结果由 “多数邻居的类别” 决定(简单多数投票)。
weights='distance':距离加权
- 含义:邻居的权重与其到待预测样本的距离成反比 ——距离越近的邻居,权重越大,对预测结果的影响越强。
3.2 随机搜索 (Randomized Search)
随机采样部分参数组合:
P(找到最优解)=1−(1−p)nP(\text{找到最优解}) = 1 - (1-p)^n P(找到最优解)=1−(1−p)n
(其中ppp 为采样一次命中最优区域的概率,nnn 为采样次数。)
3.3 贝叶斯优化 (Bayesian Optimization)
利用高斯过程或树模型拟合“超参数 → 评分”的函数,通过采集函数(如期望改进 EI)智能选择下一步采样位置。
4. 模型选择:如何最终定夺
4.1 集成学习的思路
- Bagging:降低方差(随机森林)。
- Boosting:降低偏差(XGBoost)。
- Stacking:综合多模型优势。
4.2 评估指标(详细公式)
分类任务:
-
准确率:
Accuracy=TP+TNTP+FP+TN+FN\text{Accuracy} = \frac{TP+TN}{TP+FP+TN+FN} Accuracy=TP+FP+TN+FNTP+TN -
精确率(Precision):
Precision=TPTP+FP\text{Precision} = \frac{TP}{TP+FP} Precision=TP+FPTP -
召回率(Recall):
Recall=TPTP+FN\text{Recall} = \frac{TP}{TP+FN} Recall=TP+FNTP -
F1 分数:
F1=2⋅Precision⋅RecallPrecision+RecallF1 = 2 \cdot \frac{\text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}} F1=2⋅Precision+RecallPrecision⋅Recall -
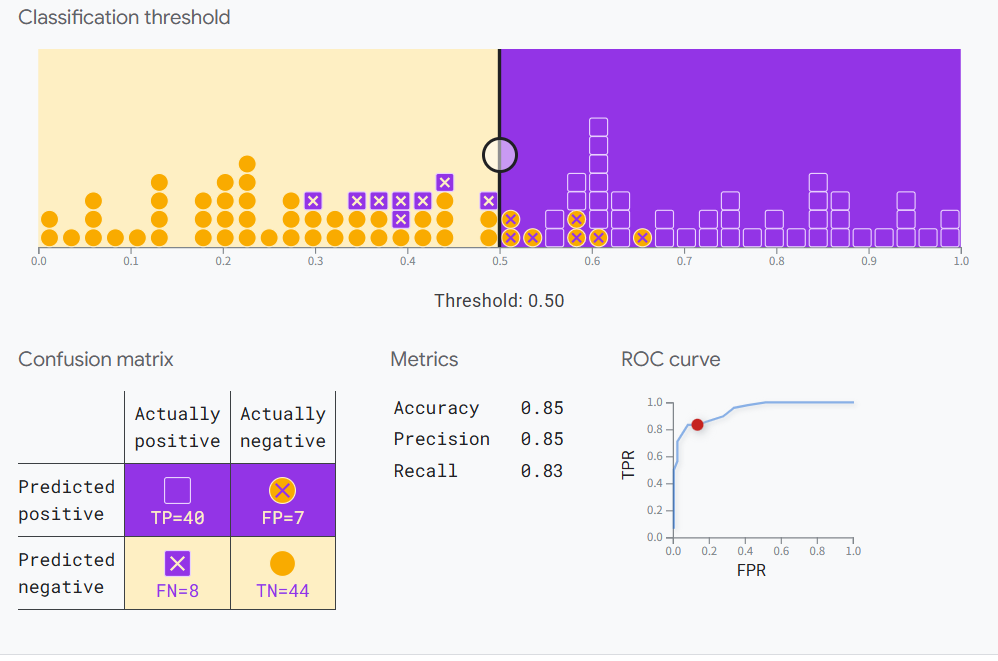
AUC(ROC 曲线下面积):衡量分类器对正负样本排序能力。
这个链接有个在线实验可以帮助理解:
Google实验案例
回归任务:
-
均方误差 (MSE):
MSE=1n∑i=1n(yi−y^i)2\text{MSE} = \frac{1}{n}\sum_{i=1}^n (y_i-\hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2 -
平均绝对误差 (MAE):
MAE=1n∑i=1n∣yi−y^i∣\text{MAE} = \frac{1}{n}\sum_{i=1}^n |y_i-\hat{y}_i| MAE=n1i=1∑n∣yi−y^i∣ -
决定系数 (R²):
R2=1−∑(yi−y^i)2∑(yi−yˉ)2R^2 = 1 - \frac{\sum (y_i-\hat{y}_i)^2}{\sum (y_i-\bar{y})^2} R2=1−∑(yi−yˉ)2∑(yi−y^i)2
5. 实战案例:以 KNN 和随机森林为例
-
划分数据集并进行标准化
-
使用 Stratified K-Fold 进行评估
-
分别通过 Grid Search 和 Random Search 调参
-
对比最佳模型性能(表格+曲线)
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split, StratifiedKFold, GridSearchCV, RandomizedSearchCV from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.pipeline import Pipeline from scipy.stats import randint# 1. 加载数据 data = make_classification(n_samples=1000, n_features=20, n_informative=10, n_redundant=5,n_classes=3, n_clusters_per_class=1, random_state=42 ) X, y = data print(f"数据集特征数: {X.shape[1]}, 样本数: {X.shape[0]}, 类别数: {len(np.unique(y))}")# 2. 分层划分训练集和测试集(保持类别比例) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42 )# 3. 定义分层K折交叉验证(适合分类问题) cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)# 4. KNN - 网格搜索(KNN需要标准化) knn_pipe = Pipeline([('scaler', StandardScaler()), # KNN对特征尺度敏感,必须标准化('knn', KNeighborsClassifier()) ]) param_knn = {'knn__n_neighbors': [3, 5, 7, 9], # 增加参数范围'knn__weights': ['uniform', 'distance'] } grid_knn = GridSearchCV(estimator=knn_pipe,param_grid=param_knn,cv=cv,scoring='accuracy',n_jobs=-1, # 使用所有可用CPUverbose=1 # 显示调参过程 ) grid_knn.fit(X_train, y_train)# 5. 随机森林 - 随机搜索(随机森林不需要标准化) rf_pipe = Pipeline([# 移除StandardScaler,随机森林对特征尺度不敏感('rf', RandomForestClassifier(random_state=42)) ]) param_rf = {'rf__n_estimators': randint(50, 200), # 增加参数范围'rf__max_depth': randint(3, 15),'rf__min_samples_split': randint(2, 10),'rf__min_samples_leaf': randint(1, 5) # 增加叶子节点参数 } random_rf = RandomizedSearchCV(estimator=rf_pipe,param_distributions=param_rf,n_iter=20, # 增加搜索迭代次数cv=cv,scoring='accuracy',n_jobs=-1,random_state=42,verbose=1 ) random_rf.fit(X_train, y_train)# 6. 性能对比表格 results = pd.DataFrame({'模型': ['KNN(网格搜索)', '随机森林(随机搜索)'],'最佳参数': [grid_knn.best_params_, random_rf.best_params_],'交叉验证准确率': [f"{grid_knn.best_score_:.4f}", f"{random_rf.best_score_:.4f}"],'测试集准确率': [f"{grid_knn.score(X_test, y_test):.4f}", f"{random_rf.score(X_test, y_test):.4f}"] }) print("\n模型性能对比:") print(results)# 7. 可视化 - KNN超参数(n_neighbors)与准确率关系 plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文 plt.rcParams['axes.unicode_minus'] = False # 显示负号 plt.figure(figsize=(10, 6))# 提取网格搜索结果 mean_scores = grid_knn.cv_results_['mean_test_score'] params = grid_knn.cv_results_['params']# 按权重分组绘制 for weight in ['uniform', 'distance']:# 筛选当前权重的结果scores = [mean_scores[i] for i, p in enumerate(params) if p['knn__weights'] == weight]n_neighbors = [p['knn__n_neighbors'] for i, p in enumerate(params) if p['knn__weights'] == weight]plt.plot(n_neighbors, scores, marker='o', label=f'权重={weight}')plt.xlabel('近邻数量(n_neighbors)') plt.ylabel('交叉验证准确率') plt.title('KNN不同近邻数量与权重的性能对比') plt.legend() plt.grid(alpha=0.3) plt.tight_layout() plt.show()# 8. 输出最佳模型在测试集上的表现 print("\nKNN最佳模型测试集准确率:", grid_knn.score(X_test, y_test)) print("随机森林最佳模型测试集准确率:", random_rf.score(X_test, y_test))数据集特征数: 20, 样本数: 1000, 类别数: 3 Fitting 5 folds for each of 8 candidates, totalling 40 fits Fitting 5 folds for each of 20 candidates, totalling 100 fits模型性能对比:模型 最佳参数 交叉验证准确率 \ 0 KNN(网格搜索) {'knn__n_neighbors': 7, 'knn__weights': 'dista... 0.9262 1 随机森林(随机搜索) {'rf__max_depth': 9, 'rf__min_samples_leaf': 1... 0.9287 测试集准确率 0 0.9450 1 0.9200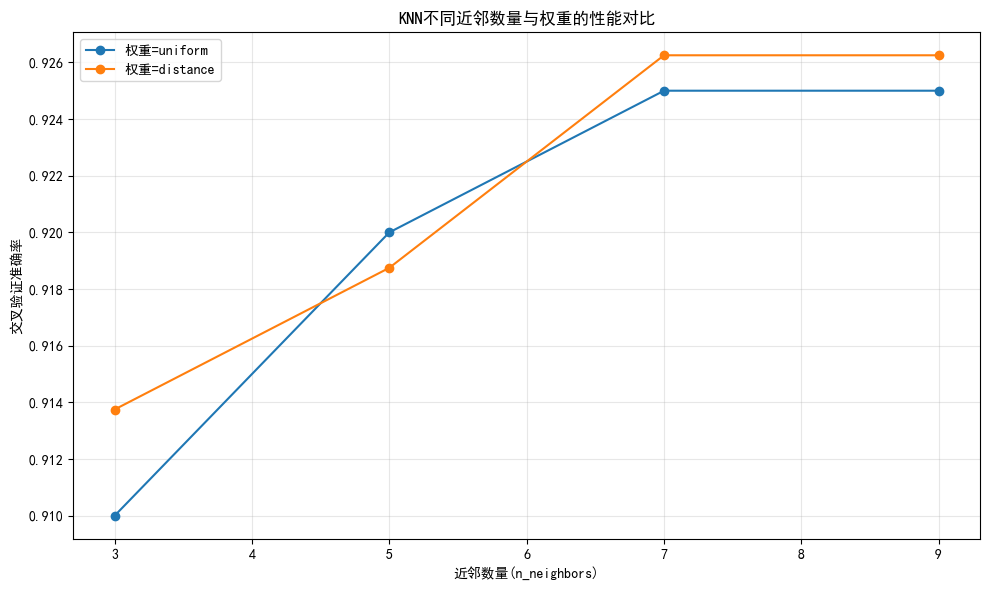
6. 总结与建议
- 分层抽样在类别不平衡下必不可少。
- K 折交叉验证是为了更稳定地估计泛化误差,而非直接“提高泛化性”。
- AIC/BIC更适用于概率模型;交叉验证适合通用机器学习场景。
- 实战中可结合随机搜索 + 贝叶斯优化以降低计算成本。
- 评估指标需根据业务目标选取,而非盲目追求单一指标。


)












)



