前篇:Python 项目里的数据清理工作(数据清洗步骤应用)
一,先接上文添加两种数据填充的方法
1、线性回归填充
def lr_train_fill(train_data,train_label):train_data_all = pd.concat([train_data, train_label], axis=1)train_data_all = train_data_all.reset_index(drop=True)train_data_X = train_data_all.drop('矿物类型', axis=1)null_num = train_data_X.isnull().sum() # 查看每个特中存在空数据的个数null_num_sorted = null_num.sort_values(ascending=True) # 将空数据的类别从小到大进行排序filling_feature = [] # 用来存储需要传入模型的特征名称for i in null_num_sorted.index:filling_feature.append(i)if null_num_sorted[i] != 0: # 当前特征是否有空缺的内容。用来判断是否开始训练模型X = train_data_X[filling_feature].drop(i, axis=1) # 构建训练集y = train_data_X[i] # 构建测试集row_numbers_mg_null = train_data_X[train_data_X[i].isnull()].index.tolist() # 获取空数据对应行号X_train = X.drop(row_numbers_mg_null) # 非空的数据作为训练数据集y_train = y.drop(row_numbers_mg_null) # 非空的标签作为训练标签X_test = X.iloc[row_numbers_mg_null] # 空的数据作为测试数据集regr = LinearRegression() # 创建线性回归模型regr.fit(X_train, y_train) # 训练模型y_pred = regr.predict(X_test) # 使用模型进行预测train_data_X.loc[row_numbers_mg_null, i] = y_predprint('完成训练数据集中的{}列数据的填充'.format(i))return train_data_X, train_data_all['矿物类型']def lr_test_fill(train_data,train_label, test_data,test_label):'''使用随机森林算法对测试数据集中缺失的数据进行填充,主要是基于这样一个思想:根据已经填充后的训练数据集建立模型,来补充空缺的测试数据集。'''train_data_all = pd.concat([train_data,train_label], axis=1)train_data_all = train_data_all.reset_index(drop=True)test_data_all = pd.concat([test_data, test_label], axis=1)test_data_all = test_data_all.reset_index(drop=True)train_data_X = train_data_all.drop('矿物类型', axis=1) #多余。test_data_X = test_data_all.drop('矿物类型', axis=1)null_num = test_data_X.isnull().sum()null_num_sorted = null_num.sort_values(ascending=True)filling_feature = []for i in null_num_sorted.index:filling_feature.append(i)if null_num_sorted[i] != 0:y_train = train_data_X[i]X_test = test_data_X[filling_feature].drop(i, axis=1)row_numbers_mg_null = test_data_X[test_data_X[i].isnull()].index.tolist()X_train = train_data_X[filling_feature].drop(i, axis=1).drop(row_numbers_mg_null) # 非空的训练数据集y_train = y_train.drop(row_numbers_mg_null) # 非空的训练标签X_test = X_test.iloc[row_numbers_mg_null] # 空的测试数据集regr = RandomForestRegressor() # 创建随机森林回归模型regr.fit(X_train, y_train) # 训练模型y_pred = regr.predict(X_test) # 使用模型进行预测test_data_X.loc[row_numbers_mg_null, i] = y_pred # pandas.loc[3,4]print(f'完成测试数据集中的{i}列数据的填充')return train_data_X, train_data_all['矿物类型']'''使用线性回归填充训练数据集中的缺失值,主要是基于这样一个思想:特征和目标变量之间存在一定的关系,因此可以利用这种关系对缺失的特征进行预测。
以下是使用线性填充缺失值的一般步骤:
1、首先,确定哪些特征包含缺失值。
2、对于包含缺失值的特征,将其作为目标变量,而其他特征(可以包括原始的目标变量)作为输入特征。注意,如果多个特征都有缺失值,
通常建议按照缺失值的数量从小到大进行处理。因为缺失值较少的特征对预测的要求较低,准确性可能更高。
3、在处理某个特征的缺失值时,将该特征中的已知值(即非缺失值)作为训练集,而缺失值作为需要预测的目标。此时,其他特征的相应值作为输入特征。
4、使用线性回归模型进行训练,并对缺失值进行预测。
5、将预测得到的值填充到原始数据中的相应位置。
6、重复上述步骤,直到处理完所有包含缺失值的特征。
需要注意的是,使用线性回归填充缺失值时,可能会受到模型选择和过拟合等因素的影响。因此,在实际应用中,建议对数据进行适当的预处理,
如特征选择、异常值处理等,以提高填充的准确性和稳定性。同时,也可以使用交叉验证等方法来评估填充的效果。
'''
2、随机森林填充
#-----------随机森林算法实现训练数据集、测试数据集的填充-----------
def rf_train_fill(train_data,train_label):train_data_all = pd.concat([train_data, train_label], axis=1)train_data_all = train_data_all.reset_index(drop=True)#data数据行号存在混乱(因随机抽取70%的数train_data_X = train_data_all.drop('矿物类型', axis=1)null_num = train_data_X.isnull().sum() #查看每个种中存在空数据的个数null_num_sorted = null_num.sort_values(ascending=True)#将空数据的类别从小到大进行排序filling_feature = []for i in null_num_sorted.index:filling_feature.append(i)if null_num_sorted[i] != 0:X = train_data_X[filling_feature].drop(i, axis=1)y = train_data_X[i]row_numbers_mg_null = train_data_X[train_data_X[i].isnull()].index.tolist()# 获取空数据对应行号 row_numX_train = X.drop(row_numbers_mg_null) # 非空的数据作为训练数据集y_train = y.drop(row_numbers_mg_null) # 非空的标签作为训练标签X_test = X.iloc[row_numbers_mg_null] # 空的数据作为测试数据集regr = RandomForestRegressor(n_estimators=100, random_state=42) # 创建随机森林回归模型regr.fit(X_train, y_train) # 训练模型y_pred = regr.predict(X_test) # 使用模型进行预测 y_pred: [-0.02019263]train_data_X.loc[row_numbers_mg_null, i] = y_pred# loc和iloc的区别: iloc[行号,列号] loc[行名, 列名],例如iloprint('完成训练数据集中的{}列数据的填充'.format(i))return train_data_X, train_data_all['矿物类型']def rf_test_fill(train_data,train_label, test_data,test_label):'''使用随机森林算法对测试数据集中缺失的数据进行填充,主要是基于这样一个思想:根据已经填充后的训练数据集建立模型,来补充空缺的测试数据集。'''train_data_all = pd.concat([train_data,train_label], axis=1)train_data_all = train_data_all.reset_index(drop=True)test_data_all = pd.concat([test_data, test_label], axis=1)test_data_all = test_data_all.reset_index(drop=True)train_data_X = train_data_all.drop('矿物类型', axis=1) #多余。test_data_X = test_data_all.drop('矿物类型', axis=1)null_num = test_data_X.isnull().sum()null_num_sorted = null_num.sort_values(ascending=True)filling_feature = []for i in null_num_sorted.index:filling_feature.append(i)if null_num_sorted[i] != 0:y_train = train_data_X[i]X_test = test_data_X[filling_feature].drop(i, axis=1)row_numbers_mg_null = test_data_X[test_data_X[i].isnull()].index.tolist()X_train = train_data_X[filling_feature].drop(i, axis=1).drop(row_numbers_mg_null) # 非空的训练数据集y_train = y_train.drop(row_numbers_mg_null) # 非空的训练标签X_test = X_test.iloc[row_numbers_mg_null] # 空的测试数据集regr = RandomForestRegressor(n_estimators=100, random_state=42)regr.fit(X_train, y_train) # 训练模型y_pred = regr.predict(X_test) # 使用模型进行预测test_data_X.loc[row_numbers_mg_null, i] = y_pred # pandas.loc[3,4]print(f'完成测试数据集中的{i}列数据的填充')return train_data_X, train_data_all['矿物类型']
逐步填充策略:按照特征缺失值数量从少到多的顺序依次填充,先用完整数据填充缺失少的特征,再用已填充的特征作为输入去预测缺失多的特征,形成 "滚雪球" 式填充链条。
随机森林回归建模:对每个含缺失值的特征,将其作为目标变量,其他已填充特征作为输入变量,构建随机森林回归模型,利用模型预测缺失值。
分阶段填充逻辑:
- 先处理训练集:用训练集中的非缺失数据训练模型,预测并填充同集中的缺失值
- 再处理测试集:基于已完整填充的训练集构建模型,专门预测测试集中的缺失值
特征关联利用:通过多特征协同建模,充分利用特征间的内在关联性,相比简单均值填充能更好地保留数据分布特征。
二、六种数据训练方法
准备工作
import pandas as pd
from sklearn import metrics'''数据提取'''
train_data = pd.read_excel(r'./temp_data/2、测试数据集[平均值填充].xlsx')
# 训练数据集的特征
train_data_x = train_data.iloc[:, 1:]
# 训练数据集的测试标签label
train_data_y = train_data.iloc[:, 0]
# 读取测试数据集
test_data = pd.read_excel(r'./temp_data/2、训练数据集[平均值填充].xlsx')
# 测试数据集的特征
test_data_x = test_data.iloc[:, 1:]
# 测试数据集的测试标签label
test_data_y = test_data.iloc[:, 0]
# 用来保存在后面6种算法的结果。
result_data = {} 1、svm算法
在这里的训练过程中,我们使用了网格搜索,和之前的交叉验证相似,但是非常好
完整代码段:
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV#网格搜索param_grid = {# 核函数类型,线性核、多项式核、RBF核、sigmoid核'kernel': ['linear', 'poly', 'rbf', 'sigmoid'],# 正则化参数,控制间隔大小,较小的值表示更强的正则化'C': [0.1, 1, 1.5, 2],# RBF、poly和sigmoid核的核系数'gamma': ['scale', 'auto', 0.001, 0.01, 0.1, 1],# 多项式核的阶数(仅对poly有效)'degree': [2, 3, 4] # 多项式核的次数,通常3次以内效果较好
}svm = SVC()
# 创建GridSearchCV对象
grid_search = GridSearchCV(svm, param_grid, cv=5)
# 在训练集上执行网格搜索
grid_search.fit(train_data_x, train_data_y)
# 输出最佳参数
print("Best parameters set found on development set:")
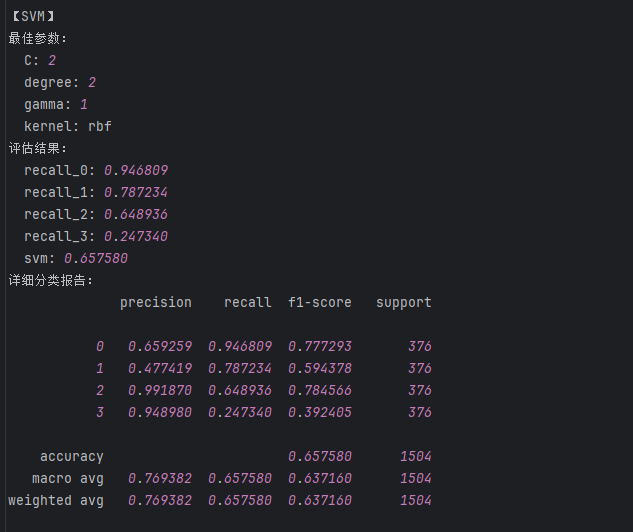
print(grid_search.best_params_)# """建立最优模型"""
svm_result= {}#用来保存训练之后的结果。
svm = SVC(C = 2, degree = 2,gamma = 1,kernel='rbf')
svm.fit(train_data_x, train_data_y)'''测试结果【含训练数据集的测试 + 测试数据集的测试】'''
train_predicted = svm.predict(train_data_x)
print('svm的train:\n',metrics.classification_report(train_data_y, train_predicted))
test_predicted = svm.predict(test_data_x)
print('svm的test:\n',metrics.classification_report(test_data_y, test_predicted))
a = metrics.classification_report(test_data_y, test_predicted,digits=6)
b = a.split()
svm_result['recall_0'] = float(b[6]) #添加类别为0的召回率
svm_result['recall_1'] = float(b[11]) #添加类别为1的召回率
svm_result['recall_2'] = float(b[16]) #添加类别为2的召回率
svm_result['recall_3'] = float(b[21]) #添加类别为3的召回率
svm_result['svm'] = float(b[25]) #添加accuracy的结果
介绍思路,详细讲解一下网格这段代码主要实现了使用支持向量机 (SVM) 进行分类任务,并通过网格搜索 (Grid Search) 寻找最优参数的过程。下面我将详细讲解其思路和网格搜索的原理。
整体思路
- 模型选择:选择支持向量机 (SVM) 作为分类模型,它在处理高维空间和小样本数据集时表现优异
- 参数优化:通过网格搜索对 SVM 的关键参数进行组合测试,找到性能最佳的参数组合
- 模型训练:使用最优参数构建 SVM 模型并在训练集上进行训练
- 模型评估:分别在训练集和测试集上评估模型性能,记录关键指标
网格搜索 (Grid Search) 详解
网格搜索是一种暴力搜索方法,它会遍历所有可能的参数组合,通过交叉验证来评估每个组合的性能,最终选择表现最好的参数组合。
在这段代码中:
-
参数空间定义:
param_grid = {'kernel': ['linear', 'poly', 'rbf', 'sigmoid'], # 核函数类型'C': [0.1, 1, 1.5, 2], # 正则化参数'gamma': ['scale', 'auto', 0.001, 0.01, 0.1, 1], # 核系数'degree': [2, 3, 4] # 多项式核的阶数 }这里定义了 4 个参数及其可能的取值,网格搜索会尝试所有这些值的组合。
-
网格搜索的执行:
grid_search = GridSearchCV(svm, param_grid, cv=5) grid_search.fit(train_data_x, train_data_y)GridSearchCV中的cv=5表示使用 5 折交叉验证- 交叉验证的作用是将训练集分成 5 份,轮流用其中 4 份训练,1 份验证,最后取平均性能
- 这种方式可以更稳健地评估模型性能,避免因数据划分方式导致的评估偏差
-
参数组合数量:
这里总共有 4×4×6×3 = 288 种参数组合,网格搜索会对每种组合都进行训练和评估 -
最佳参数获取:
print(grid_search.best_params_)这行代码会输出表现最好的参数组合,例如代码中后续使用的
C=2, degree=2, gamma=1, kernel='rbf'
为什么需要网格搜索
- SVM 对参数敏感:SVM 的性能很大程度上依赖于参数选择
- 参数之间存在交互:不同参数的组合可能产生不同的效果,单独调整一个参数难以找到最优解
- 自动化优化:省去了人工尝试不同参数组合的繁琐过程
- 提高模型性能:通过系统地搜索参数空间,往往能找到比经验值更好的参数组合
后续步骤
找到最优参数后,代码使用这些参数重新构建 SVM 模型,并分别在训练集和测试集上进行预测和评估,最后将关键指标(各类别的召回率和整体准确率)保存到结果字典中,便于后续分析和比较。
这种参数优化方法虽然计算成本较高(需要训练大量模型),但在数据集不是特别大的情况下,是提高模型性能的有效手段。
后面的代码均使用网格搜索,思路完全相同,将这个代码理解了后面就是修改参数的事了
2、逻辑回归算法
因为逻辑回归的参数之间会发生冲突,所以采用多字典的形式来训练,网格搜索支持大量字典一起运行
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV#网格搜索param_grid = [# liblinear求解器的参数组合(支持l1和l2正则化,但不支持multinomial多类模式){'penalty': ['l1', 'l2'],'C': [0.001, 0.01, 0.1, 1, 10, 100],'solver': ['liblinear'],'max_iter': [100, 200, 500],},# saga求解器的参数组合(支持所有正则化类型){'penalty': ['l1', 'l2', 'elasticnet', 'none'],'C': [0.001, 0.01, 0.1, 1, 10, 100],'solver': ['saga'],'max_iter': [100, 200, 500],},# 其他求解器的参数组合(不支持l1和elasticnet正则化){'penalty': ['l2', 'none'],'C': [0.001, 0.01, 0.1, 1, 10, 100],'solver': ['newton-cg', 'lbfgs', 'sag'],'max_iter': [100, 200, 500],}
]# 多分类策略(注意:'none' 惩罚时不支持 'multinomial')
...
logreg = LogisticRegression()
# 创建GridSearchCV对象
grid_search = GridSearchCV(logreg, param_grid, cv=5)
# 在训练集上执行网格搜索
grid_search.fit(train_data_x, train_data_y)
# 输出最佳参数
print("Best parameters set found on development set:")
print(grid_search.best_params_)
####{'C': 0.001, 'max_iter': 100, 'penalty': 'l1', 'solver': 'liblinear'}# """建立最优模型"""
LR_result= {}#用来保存训练之后的结果。
lr = LogisticRegression(C = 0.001, max_iter = 100,penalty='none',solver='newton-cg')
lr.fit(train_data_x, train_data_y)'''测试结果【含训练数据集的测试 + 测试数据集的测试】'''
train_predicted = lr.predict(train_data_x)
print('LR的train:\n',metrics.classification_report(train_data_y, train_predicted))
test_predicted = lr.predict(test_data_x) #训练数据集的预测结果 test_predicted: [2 0 1 0 0 0 0 1 0 1 2 0 0
print('LR的test:\n',metrics.classification_report(test_data_y, test_predicted)) #打印训练数据集的测试结果
a = metrics.classification_report(test_data_y, test_predicted,digits=6)#digits表示保留有效位数 a:
b = a.split() # b: ['precision', 'recall', 'f1-score', 'support', '0', '0.960784', '0.835227', '0.893617',
LR_result['recall_0'] = float(b[6]) #添加类别为0的召回率
LR_result['recall_1'] = float(b[11]) #添加类别为1的召回率
LR_result['recall_2'] = float(b[16]) #添加类别为2的召回率
LR_result['recall_3'] = float(b[21]) #添加类别为3的召回率
LR_result['acc'] = float(b[25]) #添加accuracy的结果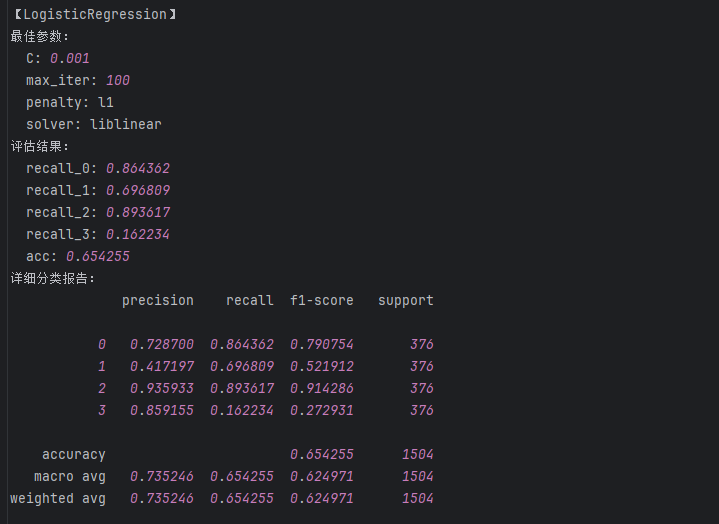
3、随机森林算法
RF算法实现代码##############################'''
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV#网格搜索# param_grid = {
# # 决策树的数量
# 'n_estimators': [50, 100, 200, 300],
# # 每棵树的最大深度,控制过拟合
# 'max_depth': [None, 10, 20, 30, 40],
# # 分裂节点时需要考虑的最小样本数
# 'min_samples_split': [2, 5, 10],
# # 叶节点所需的最小样本数
# 'min_samples_leaf': [1, 2, 4],
# # 构建树时考虑的最大特征数
# 'max_features': ['sqrt', 'log2', None],
# }
#
# rf = RandomForestClassifier()
# # 创建GridSearchCV对象
# grid_search = GridSearchCV(rf, param_grid, cv=5)
# # 在训练集上执行网格搜索
# grid_search.fit(train_data_x, train_data_y)
# # 输出最佳参数
# print("Best parameters set found on development set:")
# print(grid_search.best_params_)
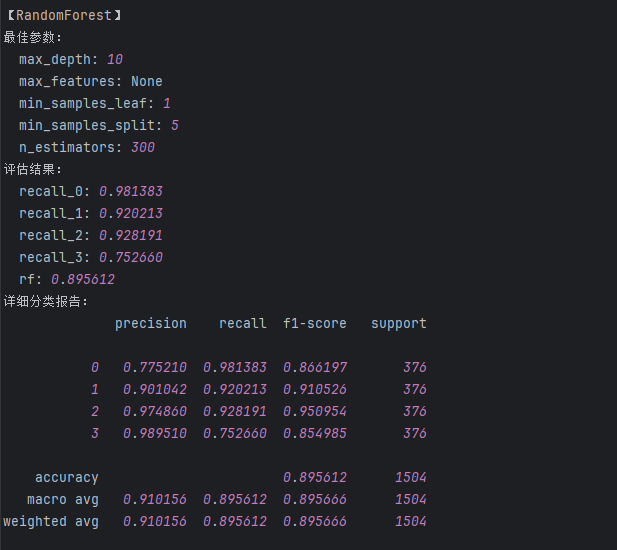
# #{'max_depth': 10, 'max_features': None, 'min_samples_leaf': 1, 'min_samples_split': 5, 'n_estimators': 300}# # """建立最优模型"""
rf_result= {}#用来保存训练之后的结果。
rf = RandomForestClassifier(max_features=None,max_depth=10,min_samples_leaf=1,min_samples_split=5,n_estimators=300)
rf.fit(train_data_x, train_data_y)'''测试结果【含训练数据集的测试 + 测试数据集的测试】'''
train_predicted = rf.predict(train_data_x)
print('RF的train:\n',metrics.classification_report(train_data_y, train_predicted))
test_predicted = rf.predict(test_data_x)
print('RF的test:\n',metrics.classification_report(test_data_y, test_predicted))
a = metrics.classification_report(test_data_y, test_predicted,digits=6)
b = a.split()
rf_result['recall_0'] = float(b[6]) #添加类别为0的召回率
rf_result['recall_1'] = float(b[11]) #添加类别为1的召回率
rf_result['recall_2'] = float(b[16]) #添加类别为2的召回率
rf_result['recall_3'] = float(b[21]) #添加类别为3的召回率
rf_result['rf'] = float(b[25]) #添加accuracy的结果
4、xgboost算法
import xgboost as xgb
from sklearn.model_selection import GridSearchCV#网格搜索# param_grid = {
# # 决策树的数量
# 'n_estimators': [50, 100, 200, 300],
# # 每棵树的最大深度,控制过拟合
# 'max_depth': [None, 10, 20, 30, 40],
# # 分裂节点时需要考虑的最小样本数
# 'min_samples_split': [2, 5, 10],
# # 叶节点所需的最小样本数
# 'min_samples_leaf': [1, 2, 4],
# }
#
# xgb = xgb.XGBClassifier()
# # 创建GridSearchCV对象
# grid_search = GridSearchCV(xgb, param_grid, cv=5)
# # 在训练集上执行网格搜索
# grid_search.fit(train_data_x, train_data_y)
# # 输出最佳参数
# print("Best parameters set found on development set:")
# print(grid_search.best_params_)
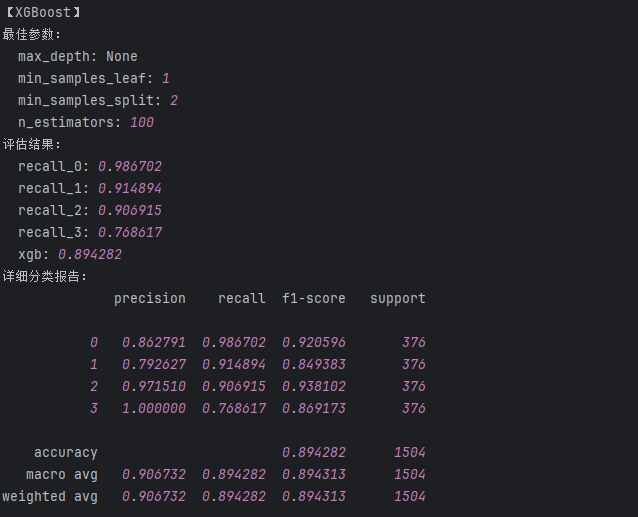
# {'max_depth': None, 'min_samples_leaf': 1, 'min_samples_split': 2, 'n_estimators': 100}# # """建立最优模型"""
xgb_result= {}#用来保存训练之后的结果。
xgb = xgb.XGBClassifier(max_depth=None,min_samples_leaf=1,min_samples_split=2,n_estimators=100)
xgb.fit(train_data_x, train_data_y)'''测试结果【含训练数据集的测试 + 测试数据集的测试】'''
train_predicted = xgb.predict(train_data_x)
print('xgboost的train:\n',metrics.classification_report(train_data_y, train_predicted))
test_predicted = xgb.predict(test_data_x)
print('xgboost的test:\n',metrics.classification_report(test_data_y, test_predicted))
a = metrics.classification_report(test_data_y, test_predicted,digits=6)
b = a.split()
xgb_result['recall_0'] = float(b[6]) #添加类别为0的召回率
xgb_result['recall_1'] = float(b[11]) #添加类别为1的召回率
xgb_result['recall_2'] = float(b[16]) #添加类别为2的召回率
xgb_result['recall_3'] = float(b[21]) #添加类别为3的召回率
xgb_result['xgb'] = float(b[25]) #添加accuracy的结果
5、adaboost算法
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import GridSearchCV#网格搜索# param_grid = {
# # 基础估计器的数量(迭代次数)
# 'n_estimators': [50, 100, 200, 300],
# # 学习率,控制每个弱学习器的贡献
# 'learning_rate': [0.01, 0.1, 0.5, 1.0],
# # 基础分类器(默认是决策树桩)
# 'base_estimator': [
# DecisionTreeClassifier(max_depth=1), # 决策树桩(默认)
# DecisionTreeClassifier(max_depth=2), # 更深一点的决策树
# DecisionTreeClassifier(max_depth=3) # 稍复杂的决策树
# ]
# }
#
# ada = AdaBoostClassifier()
# # 创建GridSearchCV对象
# grid_search = GridSearchCV(ada, param_grid, cv=5)
# # 在训练集上执行网格搜索
# grid_search.fit(train_data_x, train_data_y)
# # 输出最佳参数
# print("Best parameters set found on development set:")
# print(grid_search.best_params_)
# ##{'base_estimator': DecisionTreeClassifier(max_depth=3), 'learning_rate': 0.01, 'n_estimators': 300}# # """建立最优模型"""
ada_result= {}#用来保存训练之后的结果。
ada = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=3),learning_rate=0.01,n_estimators=300)
ada.fit(train_data_x, train_data_y)'''测试结果【含训练数据集的测试 + 测试数据集的测试】'''
train_predicted = ada.predict(train_data_x)
print('adaboost的train:\n',metrics.classification_report(train_data_y, train_predicted))
test_predicted = ada.predict(test_data_x)
print('adaboost的test:\n',metrics.classification_report(test_data_y, test_predicted))
a = metrics.classification_report(test_data_y, test_predicted,digits=6)
b = a.split()
ada_result['recall_0'] = float(b[6]) #添加类别为0的召回率
ada_result['recall_1'] = float(b[11]) #添加类别为1的召回率
ada_result['recall_2'] = float(b[16]) #添加类别为2的召回率
ada_result['recall_3'] = float(b[21]) #添加类别为3的召回率
ada_result['ada'] = float(b[25]) #添加accuracy的结果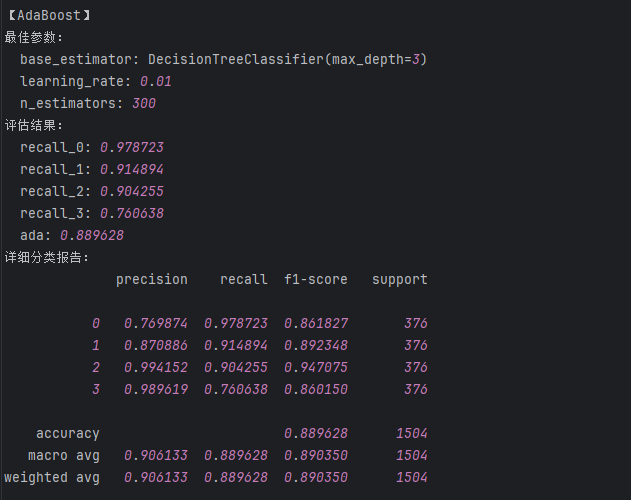
6、高斯贝叶斯算法
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import GridSearchCV#网格搜索# param_grid = {
# # 用于数值稳定性的平滑参数,防止概率为0
# 'var_smoothing': [1e-10, 1e-9, 1e-8, 1e-7, 1e-6, 1e-5]
# }
# gnb = GaussianNB()
# # 创建GridSearchCV对象
# grid_search = GridSearchCV(gnb, param_grid, cv=5)
# # 在训练集上执行网格搜索
# grid_search.fit(train_data_x, train_data_y)
# # 输出最佳参数
# print("Best parameters set found on development set:")
# print(grid_search.best_params_)
# #{'var_smoothing': 1e-10}# # """建立最优模型"""
gnb_result= {}#用来保存训练之后的结果。
gnb = GaussianNB(var_smoothing=1e-10)
gnb.fit(train_data_x, train_data_y)'''测试结果【含训练数据集的测试 + 测试数据集的测试】'''
train_predicted = gnb.predict(train_data_x)
print('GaussianNB的train:\n',metrics.classification_report(train_data_y, train_predicted))
test_predicted = gnb.predict(test_data_x)
print('GaussianNB的test:\n',metrics.classification_report(test_data_y, test_predicted))
a = metrics.classification_report(test_data_y, test_predicted,digits=6)
b = a.split()
gnb_result['recall_0'] = float(b[6]) #添加类别为0的召回率
gnb_result['recall_1'] = float(b[11]) #添加类别为1的召回率
gnb_result['recall_2'] = float(b[16]) #添加类别为2的召回率
gnb_result['recall_3'] = float(b[21]) #添加类别为3的召回率
gnb_result['gnb'] = float(b[25]) #添加accuracy的结果7、日式生成
import datetime
import os# 创建日志目录(如果不存在)
log_dir = './model_logs'
if not os.path.exists(log_dir):os.makedirs(log_dir)# 生成带时间戳的日志文件名
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
log_file = os.path.join(log_dir, f'model_results_{timestamp}.log')# 收集各算法的最佳参数(根据网格搜索结果手动填写或从网格搜索对象获取)
best_params = {'LogisticRegression': {'C': 0.001, 'max_iter': 100, 'penalty': 'l1', 'solver': 'liblinear'},'SVM': {'C': 2, 'degree': 2, 'gamma': 1, 'kernel': 'rbf'},'RandomForest': {'max_depth': 10, 'max_features': None, 'min_samples_leaf': 1,'min_samples_split': 5, 'n_estimators': 300},'XGBoost': {'max_depth': None, 'min_samples_leaf': 1, 'min_samples_split': 2, 'n_estimators': 100},'AdaBoost': {'base_estimator': 'DecisionTreeClassifier(max_depth=3)', 'learning_rate': 0.01, 'n_estimators': 300},'GaussianNB': {'var_smoothing': 1e-10}
}# 收集各算法的评估结果
results = {'LogisticRegression': LR_result,'SVM': svm_result,'RandomForest': rf_result,'XGBoost': xgb_result,'AdaBoost': ada_result,'GaussianNB': gnb_result
}# 写入日志文件
with open(log_file, 'w', encoding='utf-8') as f:f.write(f"模型训练与评估日志 - {datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")f.write("=" * 80 + "\n\n")for model_name in best_params.keys():f.write(f"【{model_name}】\n")f.write("最佳参数:\n")for param, value in best_params[model_name].items():f.write(f" {param}: {value}\n")f.write("评估结果:\n")result = results[model_name]for metric, value in result.items():f.write(f" {metric}: {value:.6f}\n")# 写入详细分类报告if model_name == 'LogisticRegression':test_predicted = lr.predict(test_data_x)elif model_name == 'SVM':test_predicted = svm.predict(test_data_x)elif model_name == 'RandomForest':test_predicted = rf.predict(test_data_x)elif model_name == 'XGBoost':test_predicted = xgb.predict(test_data_x)elif model_name == 'AdaBoost':test_predicted = ada.predict(test_data_x)else: # GaussianNBtest_predicted = gnb.predict(test_data_x)f.write("详细分类报告:\n")f.write(metrics.classification_report(test_data_y, test_predicted, digits=6))f.write("\n" + "-" * 80 + "\n\n")print(f"日志已保存至:{log_file}")


)
)

FedViT:边缘视觉转换器的联邦持续学习)
研究利用PBFT中的动态视图变换机制,实现区块链系统高效运转)
—— 分组、子查询与窗口函数全攻略)








)

