目录
- 基本转换算子
- 映射(map)
- 过滤(filter)
- 扁平映射
- 聚合算子
- 按键分区(keyBy)
- 简单聚合(sum/min/max/minBy/maxBy)
- 规约聚合(reduce)
基本转换算子
有如下POJO类用来做测试使用
package transform;import java.util.Objects;public class WaterSensor {public String id;public Long ts;public Integer vc;public WaterSensor() {}public WaterSensor(String id, Long ts, Integer vc) {this.id = id;this.ts = ts;this.vc = vc;}public String getId() {return id;}public void setId(String id) {this.id = id;}public Long getTs() {return ts;}public void setTs(Long ts) {this.ts = ts;}public Integer getVc() {return vc;}public void setVc(Integer vc) {this.vc = vc;}@Overridepublic String toString() {return "WaterSensor{" +"id='" + id + '\'' +", ts=" + ts +", vc=" + vc +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;WaterSensor that = (WaterSensor) o;return Objects.equals(id, that.id) &&Objects.equals(ts, that.ts) &&Objects.equals(vc, that.vc);}@Overridepublic int hashCode() {return Objects.hash(id, ts, vc);}
}映射(map)
map是大家非常熟悉的大数据操作算子,主要用于将数据流中的数据进行转换,形成新的数据流。简单来说,就是一个“一一映射”,消费一个元素就产出一个元素。
我们只需要基于DataStream调用map()方法就可以进行转换处理。方法需要传入的参数是接口MapFunction的实现;返回值类型还是DataStream,不过泛型(流中的元素类型)可能改变。
下面的代码用不同的方式,实现了提取WaterSensor中的id字段的功能。
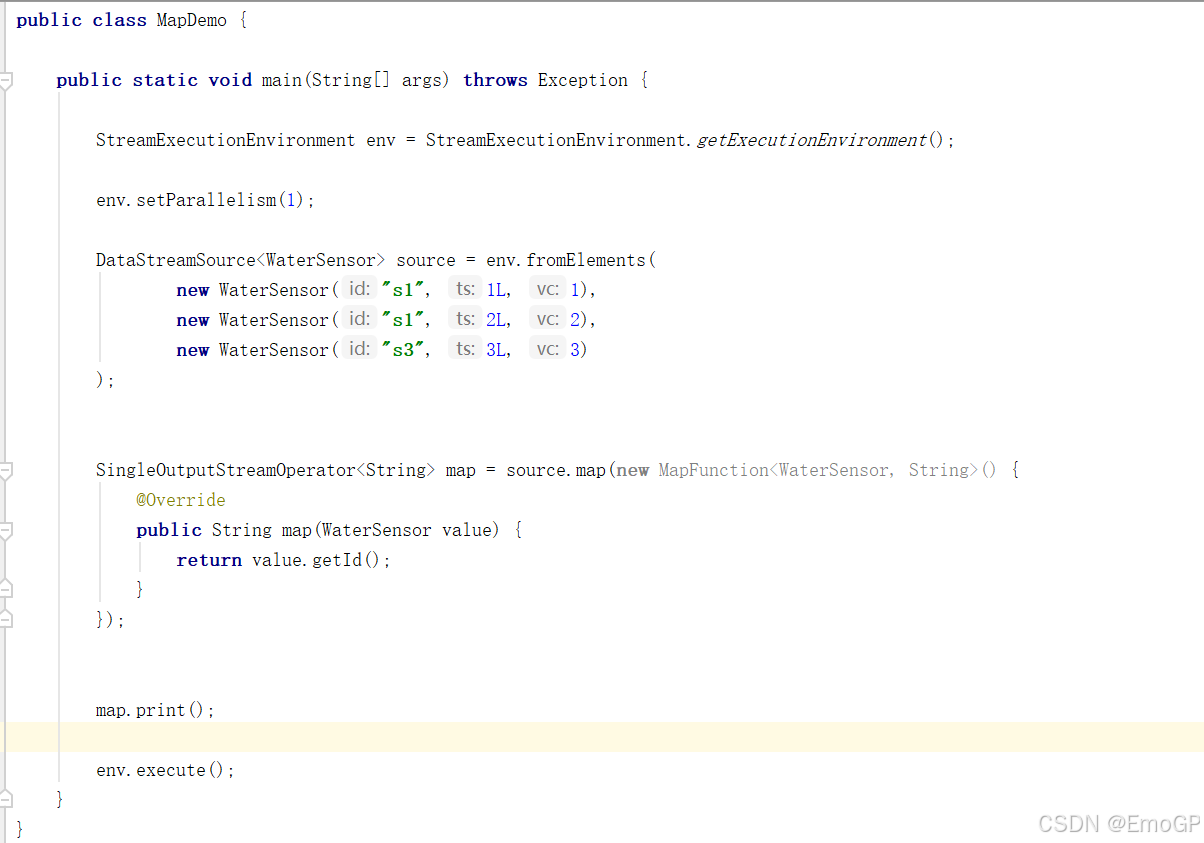
package transform;
import env.WaterSensor;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class MapDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<WaterSensor> source = env.fromElements(new WaterSensor("s1", 1L, 1),new WaterSensor("s1", 2L, 2),new WaterSensor("s3", 3L, 3));SingleOutputStreamOperator<String> map = source.map(new MapFunction<WaterSensor, String>() {@Overridepublic String map(WaterSensor value) {return value.getId();}});map.print();env.execute();}
}

过滤(filter)
filter转换操作,顾名思义是对数据流执行一个过滤,通过一个布尔条件表达式设置过滤条件,对于每一个流内元素进行判断,若为true则元素正常输出,若为false则元素被过滤掉。
进行filter转换之后的新数据流的数据类型与原数据流是相同的。filter转换需要传入的参数需要实现FilterFunction接口,而FilterFunction内要实现filter()方法,就相当于一个返回布尔类型的条件表达式。
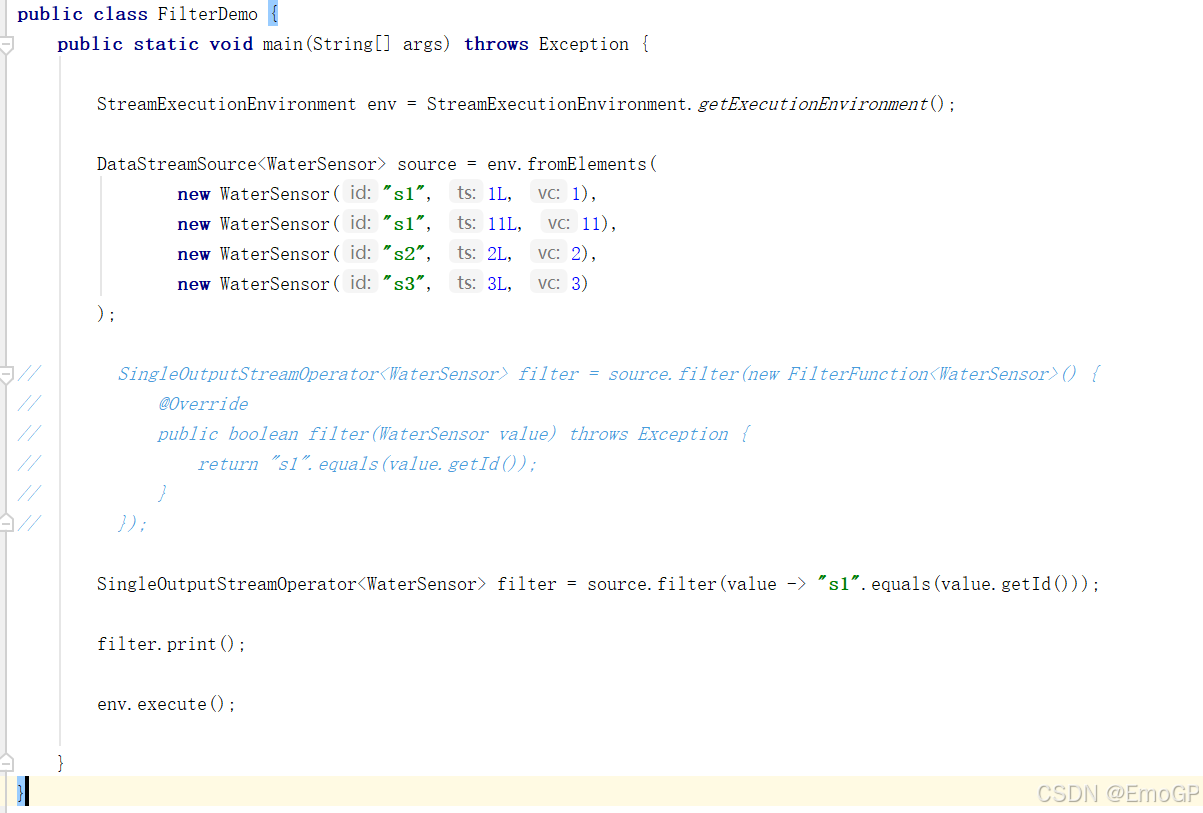
package transform;import env.WaterSensor;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class FilterDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<WaterSensor> source = env.fromElements(new WaterSensor("s1", 1L, 1),new WaterSensor("s1", 11L, 11),new WaterSensor("s2", 2L, 2),new WaterSensor("s3", 3L, 3));// SingleOutputStreamOperator<WaterSensor> filter = source.filter(new FilterFunction<WaterSensor>() {
// @Override
// public boolean filter(WaterSensor value) throws Exception {
// return "s1".equals(value.getId());
// }
// });SingleOutputStreamOperator<WaterSensor> filter = source.filter(value -> "s1".equals(value.getId()));filter.print();env.execute();}
}扁平映射
flatMap操作又称为扁平映射,主要是将数据流中的整体(一般是集合类型)拆分成一个一个的个体使用。消费一个元素,可以产生0到多个元素。flatMap可以认为是“扁平化”(flatten)和“映射”(map)两步操作的结合,也就是先按照某种规则对数据进行打散拆分,再对拆分后的元素做转换处理。
同map一样,flatMap也可以使用Lambda表达式或者FlatMapFunction接口实现类的方式来进行传参,返回值类型取决于所传参数的具体逻辑,可以与原数据流相同,也可以不同。
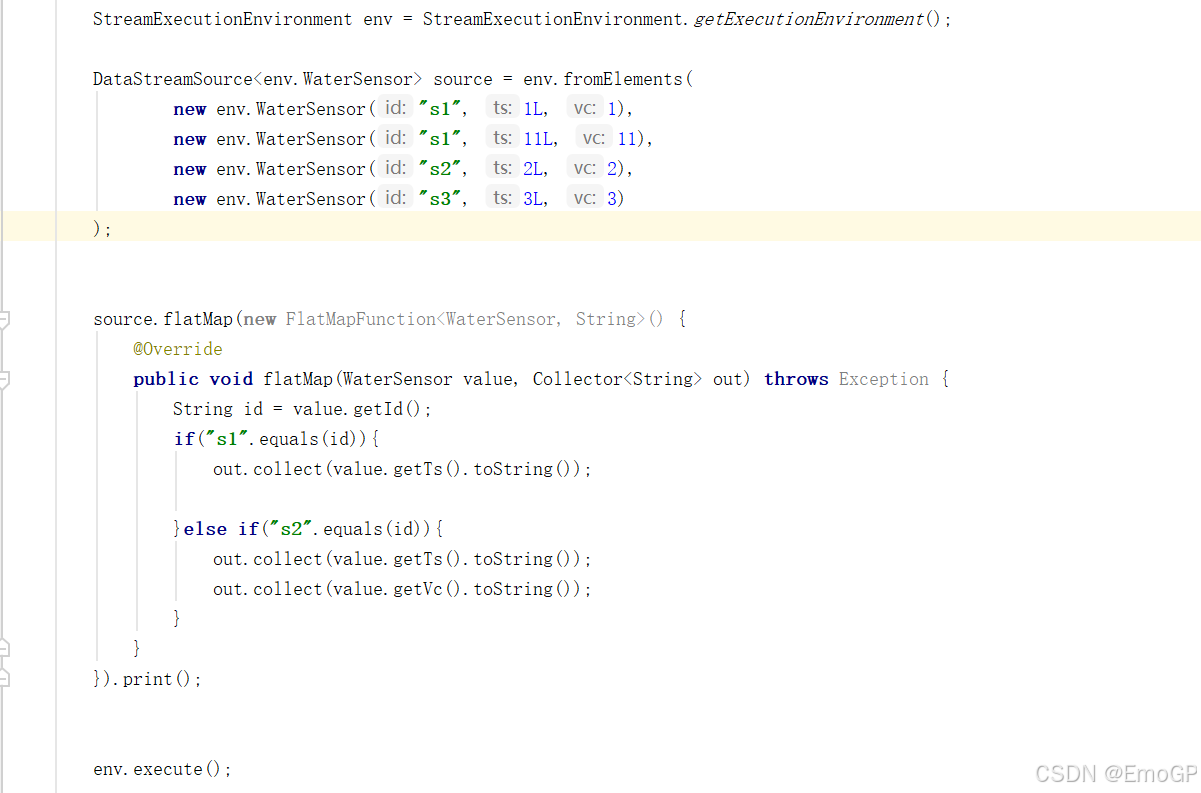
package transform;import env.WaterSensor;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class FlatMapDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<env.WaterSensor> source = env.fromElements(new env.WaterSensor("s1", 1L, 1),new env.WaterSensor("s1", 11L, 11),new env.WaterSensor("s2", 2L, 2),new env.WaterSensor("s3", 3L, 3));source.flatMap(new FlatMapFunction<WaterSensor, String>() {@Overridepublic void flatMap(WaterSensor value, Collector<String> out) throws Exception {String id = value.getId();if("s1".equals(id)){out.collect(value.getTs().toString());}else if("s2".equals(id)){out.collect(value.getTs().toString());out.collect(value.getVc().toString());}}}).print();env.execute();}
}

聚合算子
按键分区(keyBy)
对于Flink而言,DataStream是没有直接进行聚合的API的。因为我们对海量数据做聚合肯定要进行分区并行处理,这样才能提高效率。所以在Flink中,要做聚合,需要先进行分区;这个操作就是通过keyBy来完成的。
keyBy是聚合前必须要用到的一个算子。keyBy通过指定键(key),可以将一条流从逻辑上划分成不同的分区(partitions)。这里所说的分区,其实就是并行处理的子任务。
基于不同的key,流中的数据将被分配到不同的分区中去;这样一来,所有具有相同的key的数据,都将被发往同一个分区。
在内部,是通过计算key的哈希值(hash code),对分区数进行取模运算来实现的。所以这里key如果是POJO的话,必须要重写hashCode()方法
keyBy()方法需要传入一个参数,这个参数指定了一个或一组key。有很多不同的方法来指定key:比如对于Tuple数据类型,可以指定字段的位置或者多个位置的组合;对于POJO类型,可以指定字段的名称(String);另外,还可以传入Lambda表达式或者实现一个键选择器(KeySelector),用于说明从数据中提取key的逻辑。
我们可以以id作为key做一个分区操作,代码实现如下:
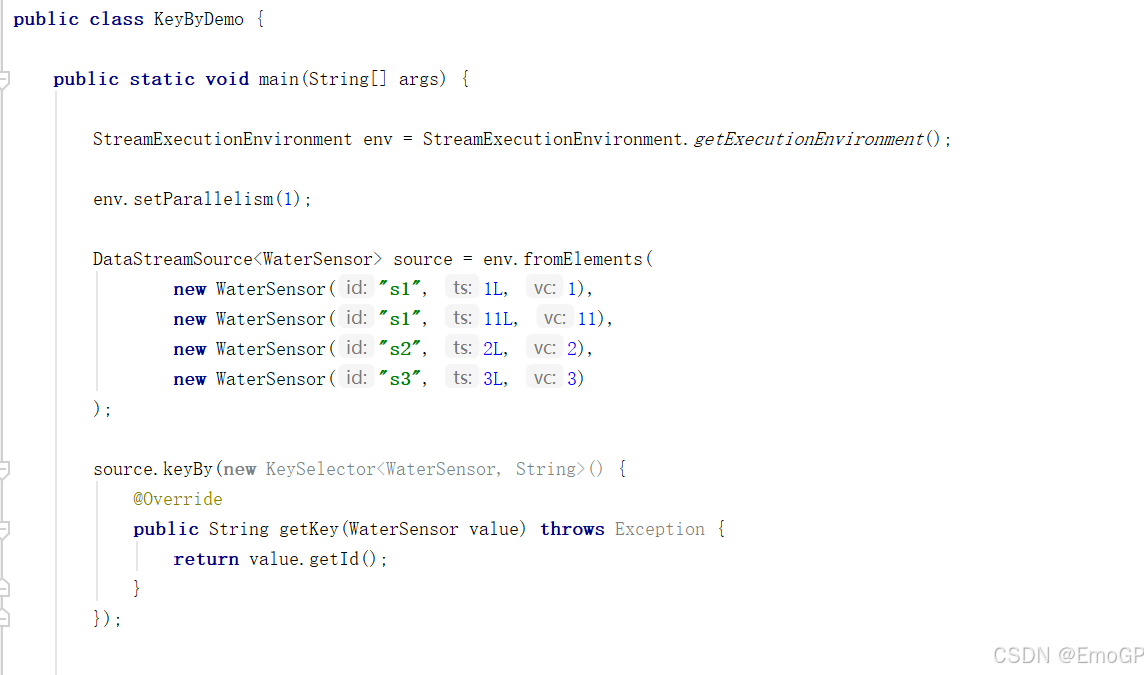
package aggregate;import env.WaterSensor;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class KeyByDemo {public static void main(String[] args) {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<WaterSensor> source = env.fromElements(new WaterSensor("s1", 1L, 1),new WaterSensor("s1", 11L, 11),new WaterSensor("s2", 2L, 2),new WaterSensor("s3", 3L, 3));source.keyBy(new KeySelector<WaterSensor, String>() {@Overridepublic String getKey(WaterSensor value) throws Exception {return value.getId();}});}
}需要注意的是,keyBy得到的结果将不再是DataStream,而是会将DataStream转换为KeyedStream。KeyedStream可以认为是“分区流”或者“键控流”,它是对DataStream按照key的一个逻辑分区,所以泛型有两个类型:除去当前流中的元素类型外,还需要指定key的类型。
KeyedStream也继承自DataStream,所以基于它的操作也都归属于DataStream API。但它跟之前的转换操作得到的SingleOutputStreamOperator不同,只是一个流的分区操作,并不是一个转换算子。KeyedStream是一个非常重要的数据结构,只有基于它才可以做后续的聚合操作(比如sum,reduce)。
简单聚合(sum/min/max/minBy/maxBy)
有了按键分区的数据流KeyedStream,我们就可以基于它进行聚合操作了,Flink为我们内置实现了一些最基本,最简单的聚合API,主要有以下几种:
- sum():在输入流上,对指定的字段做叠加求和的操作
- min():在输入流上,对指定的字段求最小值
- max():在输入流上,对指定的字段求最大值
- minBy():与min()类似,在输入流上针对指定字段求最小值,不同的是,min()只计算指定字段最小值,其他字段会保留最初第一个数据的值,而minBy()则会返回包含字段最小值的整条数据
max和maxby区别:
max:只取比较字段最大值,非比较字段保留第一次的值
maxby:取比较字段的最大值,同时非比较字段取最大值这条数据的值
简单聚合算子:
keyby之后才能调用
分组内的聚合:对同一个key的数据进行聚合
规约聚合(reduce)
reduce可以对已有的数据进行归约处理,把每一个新输入的数据和当前已经归约出来的值,再做一个聚合计算。
reduce操作也会将KeyedStream转换为DataStream。它不会改变流的元素数据类型,所以输出类型和输入类型是一样的。
调用KeyedStream的reduce方法时,需要传入一个参数,实现ReduceFunction接口。接口在源码中的定义如下:
public interface ReduceFunction<T> extends Function, Serializable {T reduce(T value1, T value2) throws Exception;
}
ReduceFunction接口里需要实现reduce()方法,这个方法接收两个输入事件,经过转换处理之后输出一个相同类型的事件。在流处理的底层实现过程中,实际上是将中间“合并的结果”作为任务的一个状态保存起来的;之后每来一个新的数据,就和之前的聚合状态进一步做归约。
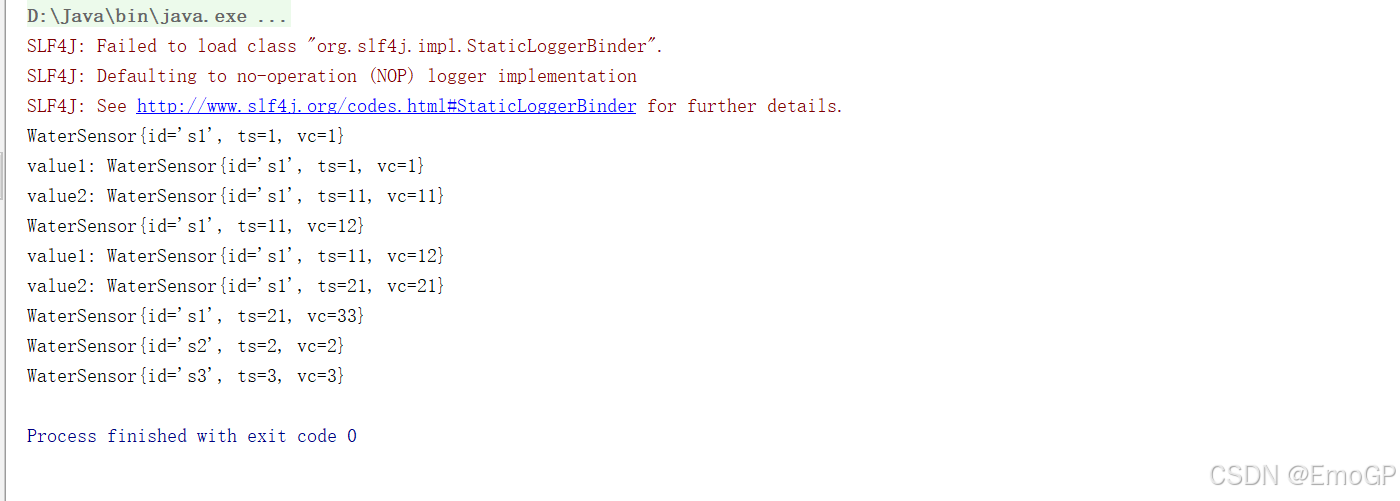
keyby之后调用
输入类型 = 输出类型,类型不能变
每个key的第一条数据来的时候,不会执行reduce方法,存起来,直接输出
reduce方法中的两个参数:
value1:之前的计算结果,存状态
value2:现在来的数据
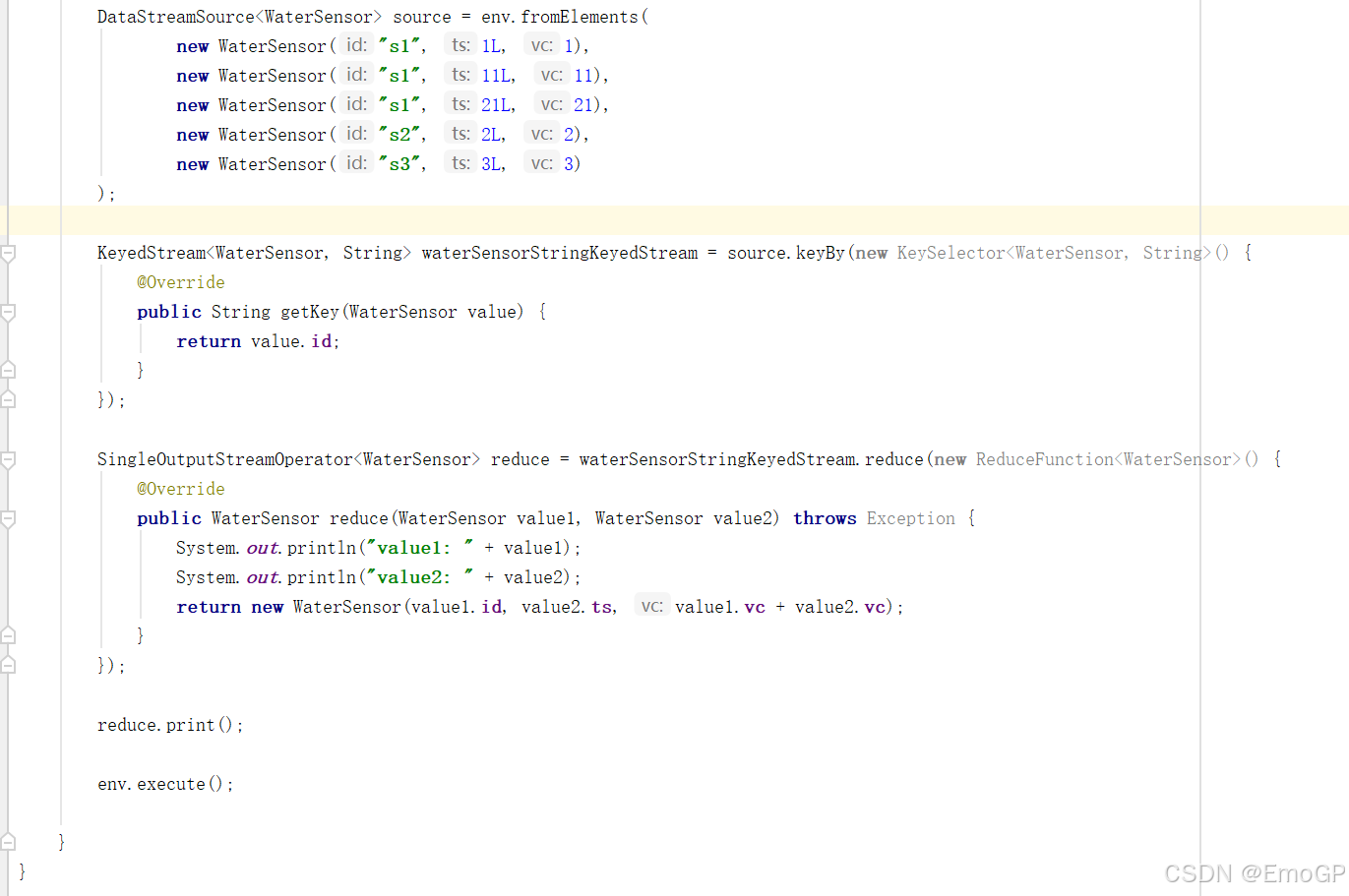
package aggregate;import env.WaterSensor;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class ReduceDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<WaterSensor> source = env.fromElements(new WaterSensor("s1", 1L, 1),new WaterSensor("s1", 11L, 11),new WaterSensor("s1", 21L, 21),new WaterSensor("s2", 2L, 2),new WaterSensor("s3", 3L, 3));KeyedStream<WaterSensor, String> waterSensorStringKeyedStream = source.keyBy(new KeySelector<WaterSensor, String>() {@Overridepublic String getKey(WaterSensor value) {return value.id;}});SingleOutputStreamOperator<WaterSensor> reduce = waterSensorStringKeyedStream.reduce(new ReduceFunction<WaterSensor>() {@Overridepublic WaterSensor reduce(WaterSensor value1, WaterSensor value2) throws Exception {System.out.println("value1: " + value1);System.out.println("value2: " + value2);return new WaterSensor(value1.id, value2.ts, value1.vc + value2.vc);}});reduce.print();env.execute();}
}








实战:图像识别模型搭建指南)






-------- 集群搭建)


