提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 摘要
- Abstract
- 一、方法介绍
- 2.Rainbow Memory(RM)
- 2.1多样性感知内存更新
- 2.2通过数据增强增强样本多样性(DA)
- 二、使用步骤
- 1.实验概况
- 2.RM核心代码
- 总结
摘要
本博客概述了文章《Rainbow Memory: Continual Learning with a Memory of Diverse Samples》聚焦于任务边界模糊的持续学习场景,提出基于样本分类不确定性和数据增强的Rainbow Memory (RM)记忆管理策略。多数研究在任务不共享类别的较人为的设置下评估相关方法,但在现实世界应用场景中,任务之间的类分布是不断变化的,更现实和实用的是任务共享类别的模糊CIL设置。在这种设置下,之前存储少量旧数据的方法虽在缓解灾难性遗忘方面有成果,但也引出了如何管理记忆(memory)的最优策略问题。基于该问题,研究者在新定义的模糊CIL设置下更好地持续学习的两个因素:记忆的采样和记忆中的数据增强,进而提出Rainbow Memory(RM)方法。通过在MNIST、CIFAR10、CIFAR100和ImageNet数据集上的实证验证,RM在模糊持续学习设置中显著提高了准确性,大幅超越现有技术。
文章链接
Abstract
This blog summarizes the article “Rainbow Memory: Continual Learning with a Memory of Diverse Samples”, which focuses on the continuous learning scenario with fuzzy task boundaries, and proposes a Rainbow Memory (RM) memory management strategy based on sample classification uncertainty and data augmentation. Most studies evaluate the relevant methods in a more artificial setting where tasks do not share categories, but in real-world application scenarios, the class distribution between tasks is constantly changing, and it is more realistic and practical to see the fuzzy CIL settings of task sharing categories. In this setting, the previous method of storing a small amount of old data has been successful in mitigating catastrophic forgetting, but it also raises the question of the optimal strategy for managing memory. Based on this problem, the researchers proposed a rainbow memory (RM) method for better continuous learning under the newly defined fuzzy CIL setting: memory sampling and data enhancement in memory. Through empirical verification on MNIST, CIFAR10, CIFAR100, and ImageNet datasets, RM significantly improves accuracy in fuzzy continuous learning settings, significantly outperforming existing technologies.
一、方法介绍
模糊类增量学习的设置要求如下:1)每个任务作为流顺序地给出,(2)大多数(分配的)任务类别彼此不同,以及(3)模型只能利用先前任务的非常小的一部分数据。 如下图所示,在模糊CIL中,任务共享类,与传统的不相交CIL相反。建议的记忆管理策略更新的情景记忆与当前任务的样本,以保持不同的样本在内存中。数据扩充(DA)进一步增强了内存中样本的多样性。
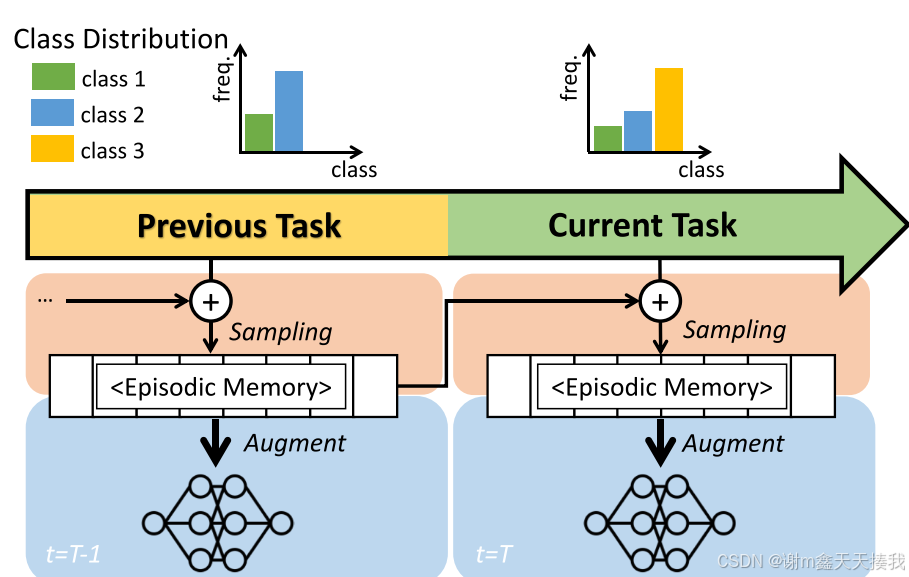
2.Rainbow Memory(RM)
在模糊类增量学习的场景中,现有方法因样本多样性不足导致模型易过拟合或遗忘严重。为了解决该问题,研究者提出了Rainbow Memory(RM),RM提出通过多样性记忆管理和数据增强解决 Blurry-CIL 问题。
2.1多样性感知内存更新
研究者认为,被选择存储在内存中的样本应该不仅是代表其相应的类,还要识别其他类。为了选择这样的样本,研究者认为,在分类边界附近的样本是最具鉴别力的,靠近分布中心的样本是最具代表性的。为了满足这两个特点,研究者建议抽样的样本是不同的特征空间。
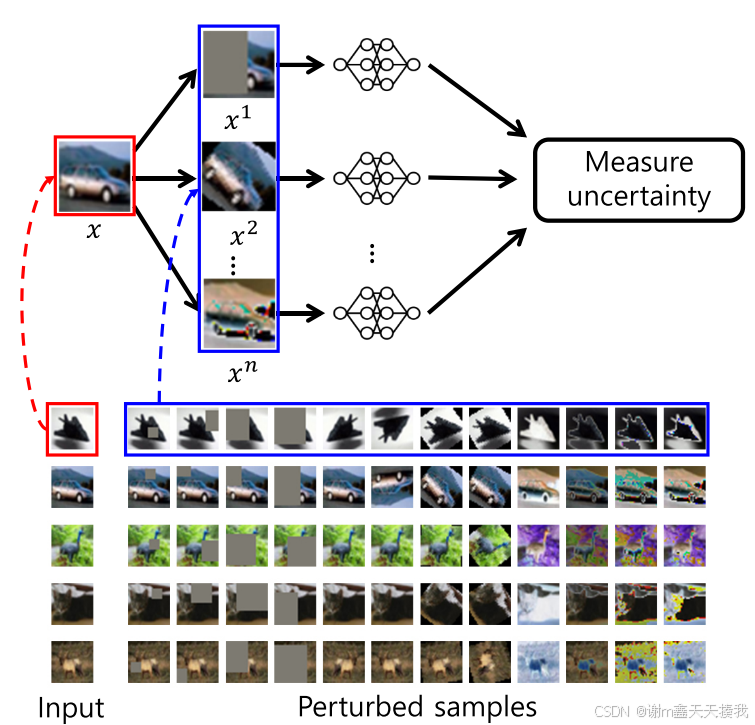
由于计算样本与样本之间的距离O(N2)较为复杂和昂贵,研究者通过分类模型估计的样本的不确定性来估计相对位置,即假设模型的更确定的样本将位于更靠近类分布的中心,通过测量扰动样本的模型输出方差来计算样本的不确定性,扰动样本通过各种数据增强转换方法进行:包括颜色抖动、剪切和剪切,如下图所示:
通过蒙特-卡罗(MC)法近似计算分布p(y = c)的不确定度|x),当给定扰动样本x的先验时,即p(x| x)的情况下,推导过程可以写成:
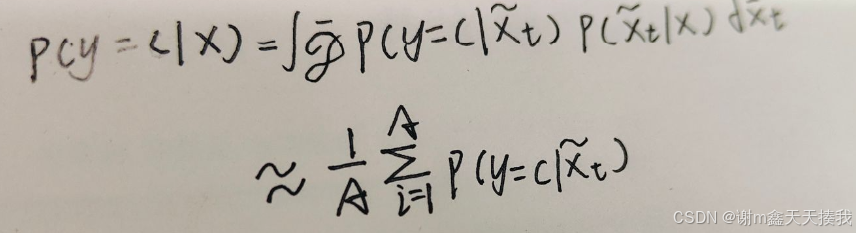
其中,x、x^~、y和A分别表示样本、扰动样本、样本的标签和扰动方法的数量。分布D * 表示由扰动样本λ x定义的数据分布。特别地,扰动样本λ x由随机函数fr(·)绘制,如下:
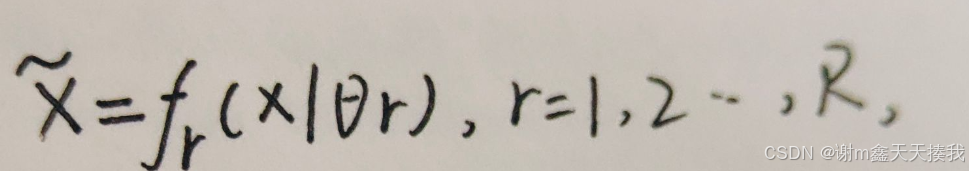
其中θr是表示第r次扰动的随机因子的超参数。
测量样品相对于扰动的不确定性为:
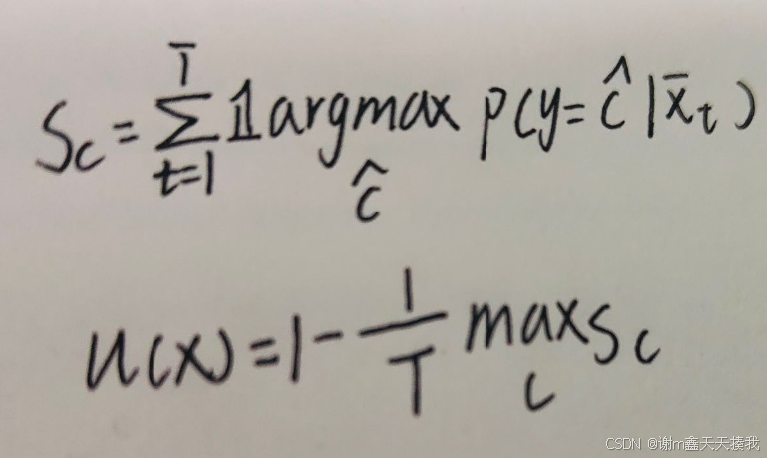
其中u(x)表示样本x的不确定性,Sc是类别c是预测的前1类别的次数。1c表示二进制类索引向量。较低的u(x)值对应于扰动上更一致的top-1类,表明x位于模型强置信的区域.
2.2通过数据增强增强样本多样性(DA)
为了进一步增强记忆中的示例的多样性,研究者采用了数据增强(DA)。 DA的通过图像级或特征扰动使给定的样本多样化,这对应于通过确保多样性来更新内存的理念。
随着任务迭代的进行,新任务中的样本可能会遵循与情节内存中的样本(即,从以前的任务中)遵循不同的分布。 研究者在新任务的类别和内存中旧类的示例中采用混合标记的DA来“混合”图像。 这种混合标签DA减轻了由类分布在任务上的变化引起的副作用,并改善了表现。
混合标记的DA方法之一,CutMix 生成了混合样品和平滑标签,鉴于一组监督样品(X1,Y1)和(X2,Y2),其公式如下:
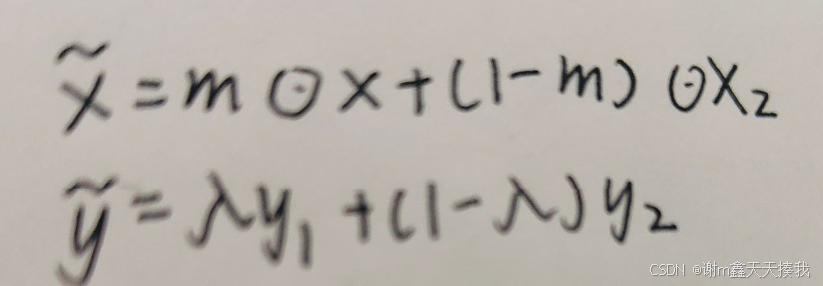
二、使用步骤
1.实验概况
研究者通过将RM与各种实验设置中的艺术状态进行比较,从经验上验证了RM的功效。 基准测试的CIL任务设置,情节内存的内存大小和性能指标。在MNIST、CIFAR10、CIFAR100和ImageNet数据集上进行实验。采用多种CIL任务设置、不同的记忆大小和性能指标评估RM方法。将RM与EWC、Rwalk、iCaRL等标准CIL方法对比 ,比较不同方法在各种设置下的Last Accuracy(A5)、Last Forgetting(F5)和Intransigence(I5)等指标。分析RM在不同模糊水平(如Blurry0、Blurry10、Blurry30)下的性能,还探究了不确定性测量方法、记忆更新算法、数据增强方法等对性能的影响。
2.RM核心代码
RM部分的完整核心代码如下:
import logging
import randomimport numpy as np
import pandas as pd
import torch
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterfrom methods.finetune import Finetune
from utils.data_loader import cutmix_data, ImageDatasetlogger = logging.getLogger()
writer = SummaryWriter("tensorboard")def cycle(iterable):# iterate with shufflingwhile True:for i in iterable:yield iclass RM(Finetune):def __init__(self, criterion, device, train_transform, test_transform, n_classes, **kwargs):super().__init__(criterion, device, train_transform, test_transform, n_classes, **kwargs)self.batch_size = kwargs["batchsize"]self.n_worker = kwargs["n_worker"]self.exp_env = kwargs["stream_env"]if kwargs["mem_manage"] == "default":self.mem_manage = "uncertainty"def train(self, cur_iter, n_epoch, batch_size, n_worker, n_passes=0):if len(self.memory_list) > 0:mem_dataset = ImageDataset(pd.DataFrame(self.memory_list),dataset=self.dataset,transform=self.train_transform,)memory_loader = DataLoader(mem_dataset,shuffle=True,batch_size=(batch_size // 2),num_workers=n_worker,)stream_batch_size = batch_size - batch_size // 2else:memory_loader = Nonestream_batch_size = batch_size# train_list == streamed_list in RMtrain_list = self.streamed_listtest_list = self.test_listrandom.shuffle(train_list)# Configuring a batch with streamed and memory data equally.train_loader, test_loader = self.get_dataloader(stream_batch_size, n_worker, train_list, test_list)logger.info(f"Streamed samples: {len(self.streamed_list)}")logger.info(f"In-memory samples: {len(self.memory_list)}")logger.info(f"Train samples: {len(train_list)+len(self.memory_list)}")logger.info(f"Test samples: {len(test_list)}")# TRAINbest_acc = 0.0eval_dict = dict()self.model = self.model.to(self.device)for epoch in range(n_epoch):# initialize for each taskif epoch <= 0: # Warm start of 1 epochfor param_group in self.optimizer.param_groups:param_group["lr"] = self.lr * 0.1elif epoch == 1: # Then set to maxlrfor param_group in self.optimizer.param_groups:param_group["lr"] = self.lrelse: # Aand go!self.scheduler.step()train_loss, train_acc = self._train(train_loader=train_loader, memory_loader=memory_loader,optimizer=self.optimizer, criterion=self.criterion)eval_dict = self.evaluation(test_loader=test_loader, criterion=self.criterion)writer.add_scalar(f"task{cur_iter}/train/loss", train_loss, epoch)writer.add_scalar(f"task{cur_iter}/train/acc", train_acc, epoch)writer.add_scalar(f"task{cur_iter}/test/loss", eval_dict["avg_loss"], epoch)writer.add_scalar(f"task{cur_iter}/test/acc", eval_dict["avg_acc"], epoch)writer.add_scalar(f"task{cur_iter}/train/lr", self.optimizer.param_groups[0]["lr"], epoch)logger.info(f"Task {cur_iter} | Epoch {epoch+1}/{n_epoch} | train_loss {train_loss:.4f} | train_acc {train_acc:.4f} | "f"test_loss {eval_dict['avg_loss']:.4f} | test_acc {eval_dict['avg_acc']:.4f} | "f"lr {self.optimizer.param_groups[0]['lr']:.4f}")best_acc = max(best_acc, eval_dict["avg_acc"])return best_acc, eval_dictdef update_model(self, x, y, criterion, optimizer):optimizer.zero_grad()do_cutmix = self.cutmix and np.random.rand(1) < 0.5if do_cutmix:x, labels_a, labels_b, lam = cutmix_data(x=x, y=y, alpha=1.0)logit = self.model(x)loss = lam * criterion(logit, labels_a) + (1 - lam) * criterion(logit, labels_b)else:logit = self.model(x)loss = criterion(logit, y)_, preds = logit.topk(self.topk, 1, True, True)loss.backward()optimizer.step()return loss.item(), torch.sum(preds == y.unsqueeze(1)).item(), y.size(0)def _train(self, train_loader, memory_loader, optimizer, criterion):total_loss, correct, num_data = 0.0, 0.0, 0.0self.model.train()if memory_loader is not None and train_loader is not None:data_iterator = zip(train_loader, cycle(memory_loader))elif memory_loader is not None:data_iterator = memory_loaderelif train_loader is not None:data_iterator = train_loaderelse:raise NotImplementedError("None of dataloder is valid")for data in data_iterator:if len(data) == 2:stream_data, mem_data = datax = torch.cat([stream_data["image"], mem_data["image"]])y = torch.cat([stream_data["label"], mem_data["label"]])else:x = data["image"]y = data["label"]x = x.to(self.device)y = y.to(self.device)l, c, d = self.update_model(x, y, criterion, optimizer)total_loss += lcorrect += cnum_data += dif train_loader is not None:n_batches = len(train_loader)else:n_batches = len(memory_loader)return total_loss / n_batches, correct / num_datadef allocate_batch_size(self, n_old_class, n_new_class):new_batch_size = int(self.batch_size * n_new_class / (n_old_class + n_new_class))old_batch_size = self.batch_size - new_batch_sizereturn new_batch_size, old_batch_size1.内存管理与数据混合(对应论文 Section 4.1)
将内存中的旧任务样本(memory_loader)与当前任务的流数据(train_loader)按比例混合(默认各占50%)。
使用cycle(memory_loader)循环读取内存数据,避免内存样本因容量限制被忽略。
实现多样性记忆回放,通过混合新旧任务样本缓解灾难性遗忘,确保模型同时学习新任务和巩固旧任务知识。
def train(self, cur_iter, n_epoch, batch_size, n_worker, n_passes=0):# 加载内存数据(旧任务样本)和流数据(新任务样本)if len(self.memory_list) > 0:mem_dataset = ImageDataset(self.memory_list, transform=self.train_transform)memory_loader = DataLoader(mem_dataset, batch_size=(batch_size // 2), ...)stream_batch_size = batch_size - batch_size // 2else:memory_loader = Nonestream_batch_size = batch_size# 混合流数据和内存数据data_iterator = zip(train_loader, cycle(memory_loader)) # 循环迭代内存数据x = torch.cat([stream_data["image"], mem_data["image"]])y = torch.cat([stream_data["label"], mem_data["label"]])数据增强:CutMix
以50%概率应用CutMix,将两张图像局部区域混合,并生成对应的混合标签(labels_a和labels_b)。
计算混合损失(lam * loss_a + (1-lam) * loss_b),鼓励模型学习更鲁棒的特征,实现标签混合增强(Section 4.2),通过生成边界复杂的样本提升记忆库多样性,增强模型泛化能力。
def update_model(self, x, y, criterion, optimizer):# CutMix增强:混合图像和标签do_cutmix = self.cutmix and np.random.rand(1) < 0.5if do_cutmix:x, labels_a, labels_b, lam = cutmix_data(x=x, y=y, alpha=1.0)logit = self.model(x)loss = lam * criterion(logit, labels_a) + (1 - lam) * criterion(logit, labels_b)else:logit = self.model(x)loss = criterion(logit, y)动态学习率与批量调整
# Warm start学习率调整
if epoch <= 0:for param_group in self.optimizer.param_groups:param_group["lr"] = self.lr * 0.1 # 初始低学习率
elif epoch == 1:param_group["lr"] = self.lr # 恢复基准学习率
else:self.scheduler.step() # 后续按计划调整# 动态调整新旧任务批量大小
def allocate_batch_size(self, n_old_class, n_new_class):new_batch_size = int(self.batch_size * n_new_class / (n_old_class + n_new_class))old_batch_size = self.batch_size - new_batch_sizereturn new_batch_size, old_batch_size初始阶段使用低学习率(10%基准值)进行预热(Warm-up),避免训练初期不稳定。
根据新旧类别比例动态分配批量大小,平衡新旧任务的学习强度,防止新任务数据主导学习过程。
4. 训练流程与评估
# 训练与评估循环
for epoch in range(n_epoch):train_loss, train_acc = self._train(...) # 训练eval_dict = self.evaluation(...) # 评估logger.info(f"Task {cur_iter} | Epoch {epoch+1} | train_acc {train_acc:.4f} | test_acc {eval_dict['avg_acc']:.4f}")3.实验结果
研究者将提出的RM与各种数据集的“ Blurry10-Online”设置中的其他方法进行了比较,并总结了如下表的结果,如表所示,RM始终优于所有其他方法,并且当类(| C |)增加时,增益会更大。但是,在MNIST上,没有DA的RM表现最好。 研究者认为,DA会干扰模型培训,因为示例足以避免忘记。
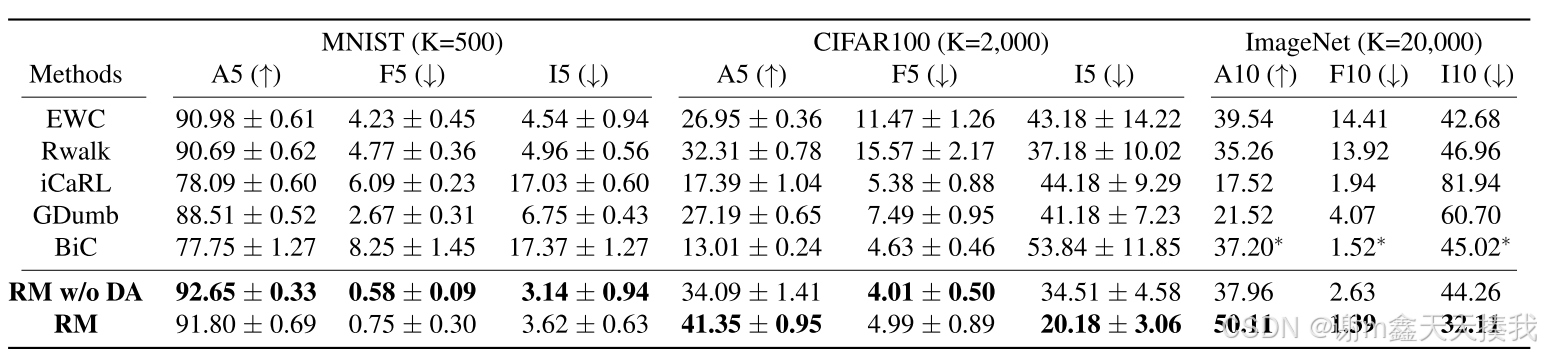
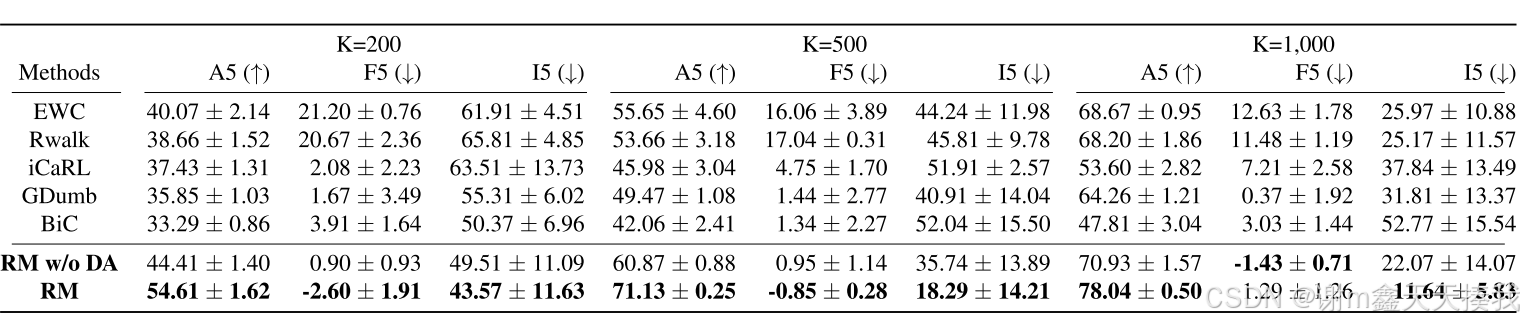
下表列出了三个情节记忆大小(K)的CIFAR10-Blurry10Online的比较; 200、500和1,000。结果表明,这些方法在最终任务中保留了有效的示例,足以恢复以前任务中发生的遗忘。 ICARL,GDUMB和BIC对于不固定(i5)的有效性较小,并且与EWC和RWALK相比,它们在忘记方面的表现较大,作为权衡。
研究者进一步比较了任务流的准确性轨迹; 由随机分配的函数ψ(c)生成的三个流,具有不同的随机种子,用于Imagenet和单个流,用Imagenet,并总结了下图中的结果:
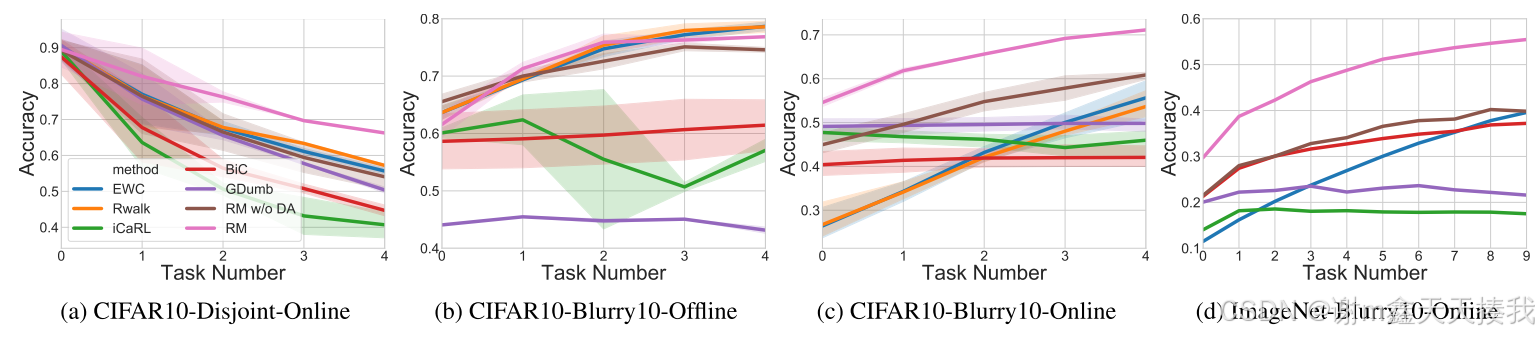
RM在整个任务流中始终优于其他基线。
总结
研究结论:研究者提出一种名为彩虹记忆(RM)的方法,用于处理任务共享类别(模糊 - CIL)的现实持续学习场景。通过基于样本分类不确定性的新的多样性增强采样方法和多种数据增强技术,在CIFAR10、CIFAR100和ImageNet的模糊 - CIL场景中,RM大幅优于现有方法,在不连续和离线CIL设置中也有可比性能。
研究的创新性:一是提出基于样本扰动不确定性的多样性增强采样方法管理有限容量记忆;二是采用多种数据增强技术提高样本多样性,增强记忆中样本的代表性和判别性。
研究展望:可研究基于不确定性的记忆更新和数据增强在训练时的关系,及其对不同CIL任务的影响。还可探索RM在更多类型数据集或其他领域持续学习场景中的应用效果。

题解)





)




![[吾爱出品] 网文提取精灵_4.0](http://pic.xiahunao.cn/[吾爱出品] 网文提取精灵_4.0)






![[面试]SoC验证工程师面试常见问题(三)](http://pic.xiahunao.cn/[面试]SoC验证工程师面试常见问题(三))