在英伟达官网,我们可以清晰地看到其从1999年Celsius到2024年Blackwell的20+代架构演进。这一历程犹如一部波澜壮阔的科技史诗,见证了英伟达在GPU领域的卓越创新与持续引领。

NVIDIA GPU架构变迁路线:
| 年份 | NV GPU架构变迁 |
| 2025 | Blackwell 2.0 |
| 2024 | Blackwell |
| 2023-2024 | Hopper |
| 2022-2024 | Ada Lovelace |
| 2020-2024 | Ampere |
| 2018-2022 | Turing |
| 2017-2020 | Volta |
| 2016-2021 | Pascal |
| 2014-2019 | Maxwell 2.0 |
| 2014-2017 | Maxwell |
| 2013-2015 | Kepler 2.0 |
| 2012-2018 | Kepler |
| 2010-2016 | Fermi 2.0 |
| 2010-2013 | VLIW Vec4 |
| 2010-2016 | Fermi |
| 2007-2013 | Tesla 2.0 |
| 2006-2010 | Tesla |
| 2003-2013 | Curie |
| 2003-2005 | Rankine |
| 2001-2003 | Kelvin |
| 1999-2005 | Celsius |
1999年:Celsius(NV1x)——开启GPU时代
Celsius架构的代表产品GeForce 256横空出世,它首次提出了“GPU(图形处理器)”的概念,堪称具有划时代意义的创举。以往,图形处理任务主要由CPU承担,效率较低。而GeForce 256具备硬件T&L(变换和光照)功能,能够将图形处理从CPU中解放出来,实现了图形加速,大大提升了运算效率,其运算能力达到当时CPU的5倍之多,就此开启了GPU作为独立计算核心的崭新时代。

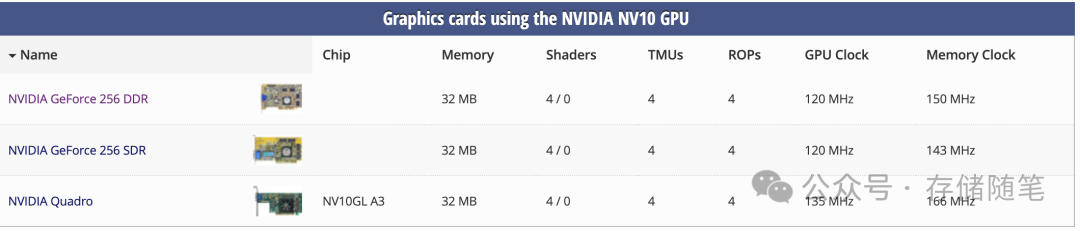
Database参考:https://www.techpowerup.com/gpu-specs/nvidia-nv10.g165
2000年:Kelvin(NV2x)——多显示器支持的先驱
Kelvin 架构(NV20 核心)是英伟达在 2000 年代初推出的关键图形架构。它最初应用于搭载NV2A GPU的XBOX游戏主机,之后GeForce 2系列GPU也基于此架构发布。GeForce 2成为首个支持多显示器的GPU产品。其代表产品GeForce3于 2001 年 2 月 27 日发布,基于 150nm 工艺制造,核心面积 128mm²,集成 5700 万个晶体管。作为首款支持DirectX 8.1的消费级 GPU,GeForce3 标志着图形计算从固定管线向可编程渲染的重大跃迁,彻底改变了游戏开发的技术范式。

Database参考:https://www.techpowerup.com/gpu-specs/geforce3.c738
2001年:Rankine(NV3x)——图形功能增强的探索
Rankine架构作为Kelvin微架构的后续版本,主要应用于NVIDIA GPU的GeForce 5系列产品。在这一系列中,Rankine微架构引入了对顶点和片段程序的支持,丰富了图形处理的功能。同时,将显存(VRAM)大小扩展至256MB,为GPU性能提升和图形处理能力增强提供了有力支撑,进一步提升了图形渲染的质量与效率。
Rankine 架构(NV34 核心)是英伟达在 2003 年推出的入门级图形架构,其代表产品GeForce FX 5100于 2003 年 3 月 6 日发布,基于 150nm 工艺制造,核心面积 124mm²,集成 4500 万个晶体管。作为 GeForce FX 系列的低端型号,该架构主打 DirectX 9.0a 支持,试图在入门级市场延续可编程渲染的技术红利,但受限于硬件规格,成为英伟达架构迭代中的过渡性产品。

Database参考:https://www.techpowerup.com/gpu-specs/geforce-fx-5100.c1834
2004年:Curie(NV4x)——显存与视频解码的革新
Curie 架构(NV40 核心)是英伟达在 2004 年推出的旗舰级图形架构,其代表产品GeForce 6800 XT于 2005 年 9 月 30 日发布,基于 130nm 工艺制造,核心面积 287mm²,集成 2.22 亿个晶体管。作为首款支持DirectX 9.0c的消费级 GPU,该架构标志着英伟达在独立 Shader 架构时代的性能巅峰,同时为后续统一渲染架构的转型埋下伏笔。

Database参考:https://www.techpowerup.com/gpu-specs/geforce-6800-xt.c176
2006年:Tesla(G80、G92)——通用计算的开拓者
2006 年推出的Tesla 架构(G80 核心)是英伟达发展史上的分水岭 —— 它首次引入统一渲染架构(Unified Shader Architecture),将顶点着色器、像素着色器和几何着色器合并为通用的CUDA 核心(Compute Unified Device Architecture),彻底解决了独立管线时代的资源分配难题。这一架构不仅重塑了图形计算范式,更开启了 GPU 通用计算(GPGPU)的新纪元。

Database参考:https://www.techpowerup.com/gpu-specs/geforce-8400-se.c3779
2009年:Fermi(GF100)——制程与功能的双重升级
Fermi架构是第一款采用40nm制程的GPU。它带来了诸多重大改进,引入L1/L2快速缓存,加速了数据的读取与存储;具备错误修复功能,提高了系统的稳定性;采用GPUDirect技术,允许GPU在无需访问CPU的情况下相互通信,无论是在同一台计算机内部还是通过网络进行通信,大大提升了数据传输效率。Fermi GTX 480拥有480个流处理器,带宽达到177.4GB/s,计算能力相比Tesla架构大幅提升。

Database参考:https://www.techpowerup.com/gpu-specs/geforce-gtx-480.c268
2009 年推出的Fermi 架构(GF100 核心)是英伟达首次专为通用计算(GPGPU)设计的架构,其核心目标是在保持图形性能的同时,构建可扩展的计算平台。关键创新包括:
-
统一计算架构:
引入流式多处理器(SM,Streaming Multiprocessor),每个 SM 包含 32 个 CUDA 核心、16 个纹理单元和 4 个 ROP 单元,支持动态分配图形计算与通用计算任务。 -
计算可靠性:
首次支持ECC 内存纠错,满足医疗、金融等工业场景对数据准确性的需求;引入动态并行(Dynamic Parallelism),允许 GPU 直接生成子任务,减少 CPU 介入。 -
双精度计算:
GF100 核心双精度浮点性能达 1 TFLOPS,是同期 ATI Radeon HD 5870 的 2 倍,成为超级计算机的核心组件(如美国橡树岭国家实验室的 “美洲豹” 超算)。
2012年:Kepler(GK104、GK110)——高性能计算的新起点
Kepler架构采用28nm制程,是首个支持超级计算和双精度计算的GPU架构。其拥有全新的流式多处理器架构SMX,带来了多方面的提升,完整支持TXAA(一种抗锯齿方法),CUDA核心数显著增加,如GK110B具有2880个流处理器,带宽高达288GB/s,计算能力比Fermi架构提高3 - 4倍。Kepler架构的出现,使GPU在高性能计算领域受到广泛关注,为科学研究、大数据分析等领域提供了强大的计算支持。
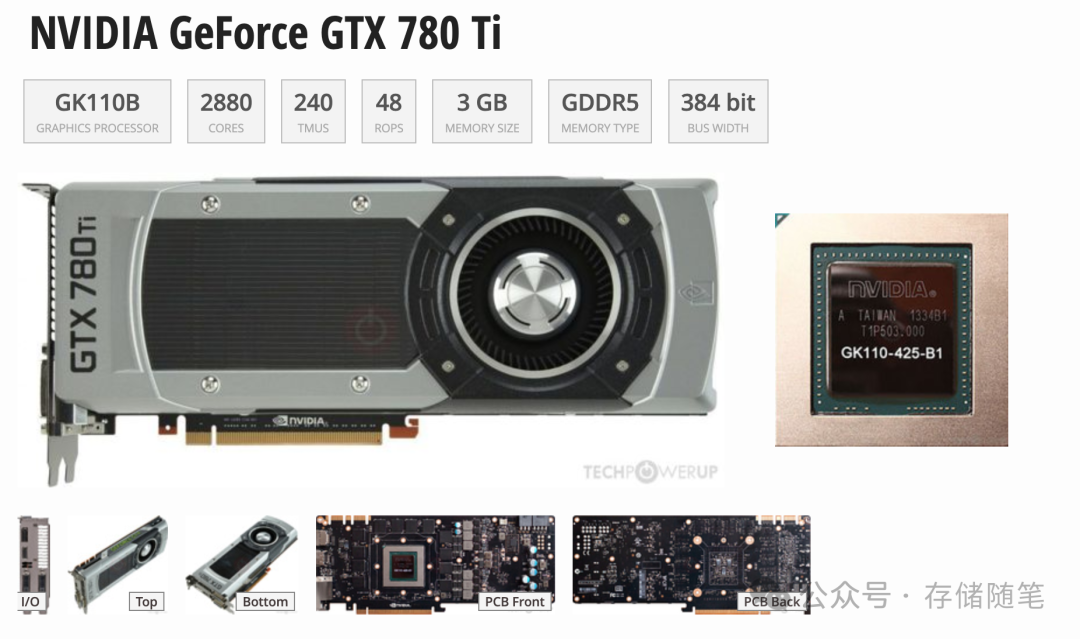
2012 年推出的Kepler 架构(GK104/GK110 核心)是英伟达在统一计算架构下的集大成之作,其设计目标是 “让 GPU 成为并行计算的超级计算机”。核心创新包括:
- 第三代 CUDA 核心:
每个 SMX 单元包含 192 个 CUDA 核心(较 Fermi 架构的 SM 增加 50%),支持动态指令调度和分支预测,计算效率提升 40%。 - 异构计算支持:
引入Hyper-Q技术,支持同时处理 32 个 CPU 线程请求,多任务并行效率提升 2 倍;集成Dynamic Parallelism 2.0,允许 GPU 自主生成子任务树,减少 CPU 介入延迟。 - 图形渲染强化:
首次支持自适应细分曲面(Adaptive Tessellation),配合FXAA 抗锯齿,在《孤岛危机 3》中实现曲面细节提升 50% 的同时,性能损耗控制在 15% 以内。
GeForce GTX 660 和 780 TI是 Kepler 架构的缩影 —— 前者以主流性能定义性价比标杆,后者以旗舰规格探索硬件极限。它们不仅巩固了英伟达在图形市场的统治力,更将 GPU 从 “游戏硬件” 升级为 “通用计算平台”。Kepler 架构的成功,本质是英伟达对 “摩尔定律 +


的漏洞特征流量特征)









)






