线程池
线程诞生的意义:因为进程的创建/销毁,太重量了(比较慢)
但如果近一步提高创建/销毁的频率,线程的开销也不容忽视。
有两种方法可以提高效率:
1.协程(轻量级线程):相对于线程,把系统调度的过程省略了。
使用协程更多的是go和python
不知道协程能提升多少,防止出现bug,java一般使用线程
2.线程池:帮线程兜底,不至于很慢(就像现实生活中的“海王”)
(内存池、线程池、进程池含义类似)
在使用第一个线程的时候,提前把2,3,4,5(其余)线程创建好;
后续如果想要使用新的线程,不必重新创建,直接调用即可,没有真正的频繁创建销毁,只是从线程池里面取线程使用,等使用完了在还给线程池,这样的话创建线程的开销就减少了。
调用线程比创建新线程效率更高
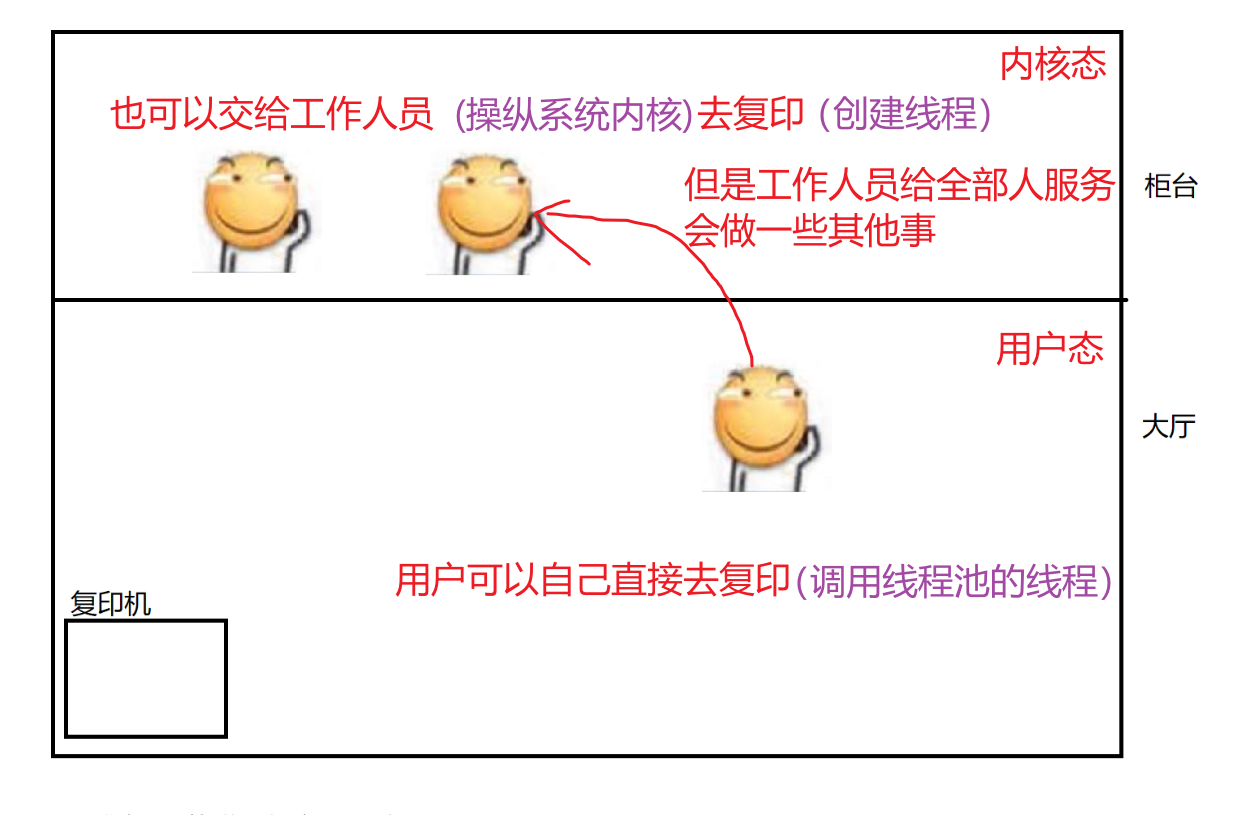
1.调用线程是纯粹“用户态”的操作
2.创建新的线程 是需要“用户态+内核态”共同完成的
内核态和用户态:
一段程序在系统内核执行 -> 内核态;
反之,用户态。
官方文档
在java标准库里面,ThreadPoolExecutor类表示线程池。
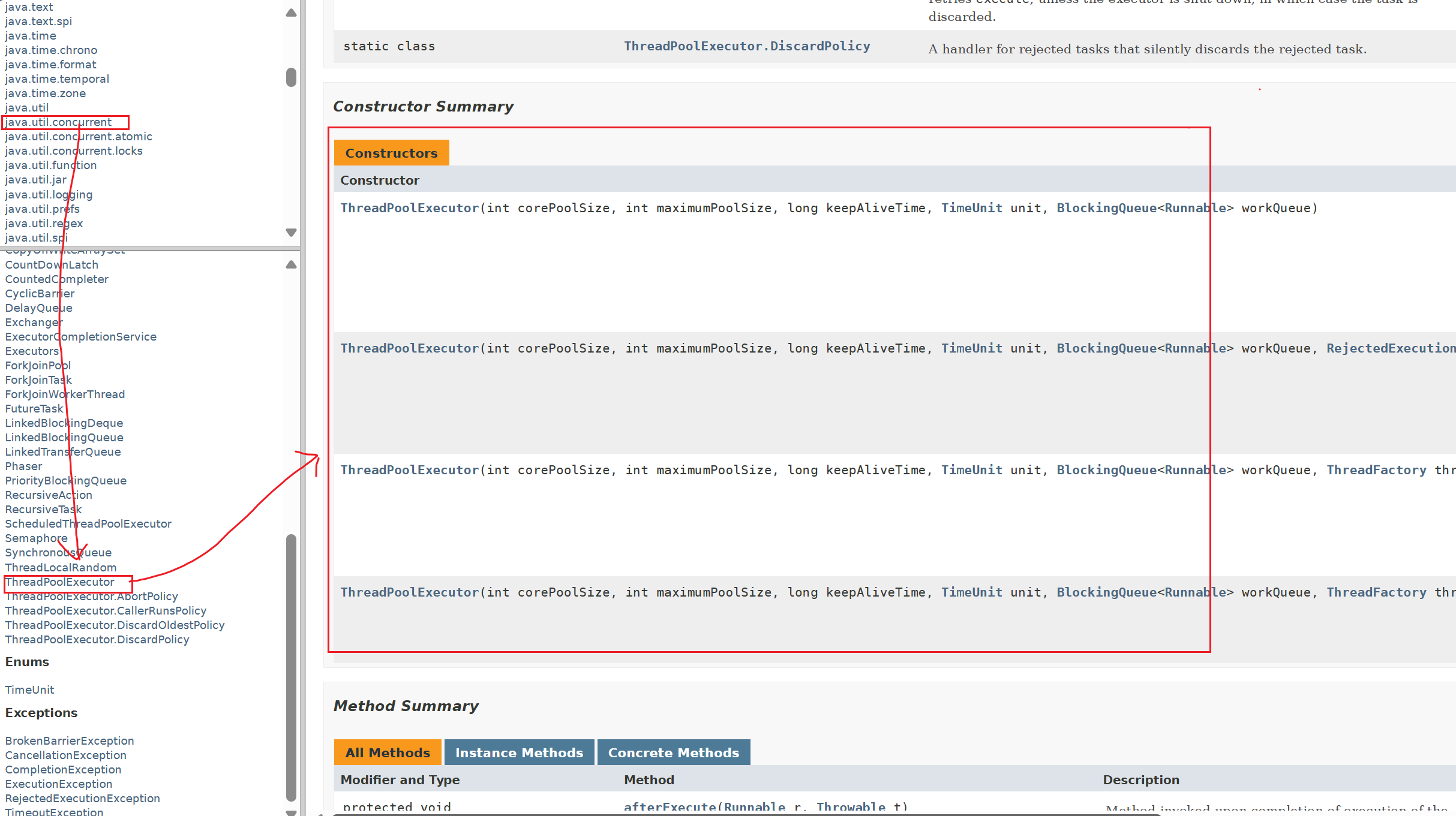
ThreadPoolExecutor类的构造方法

参数具体含义:
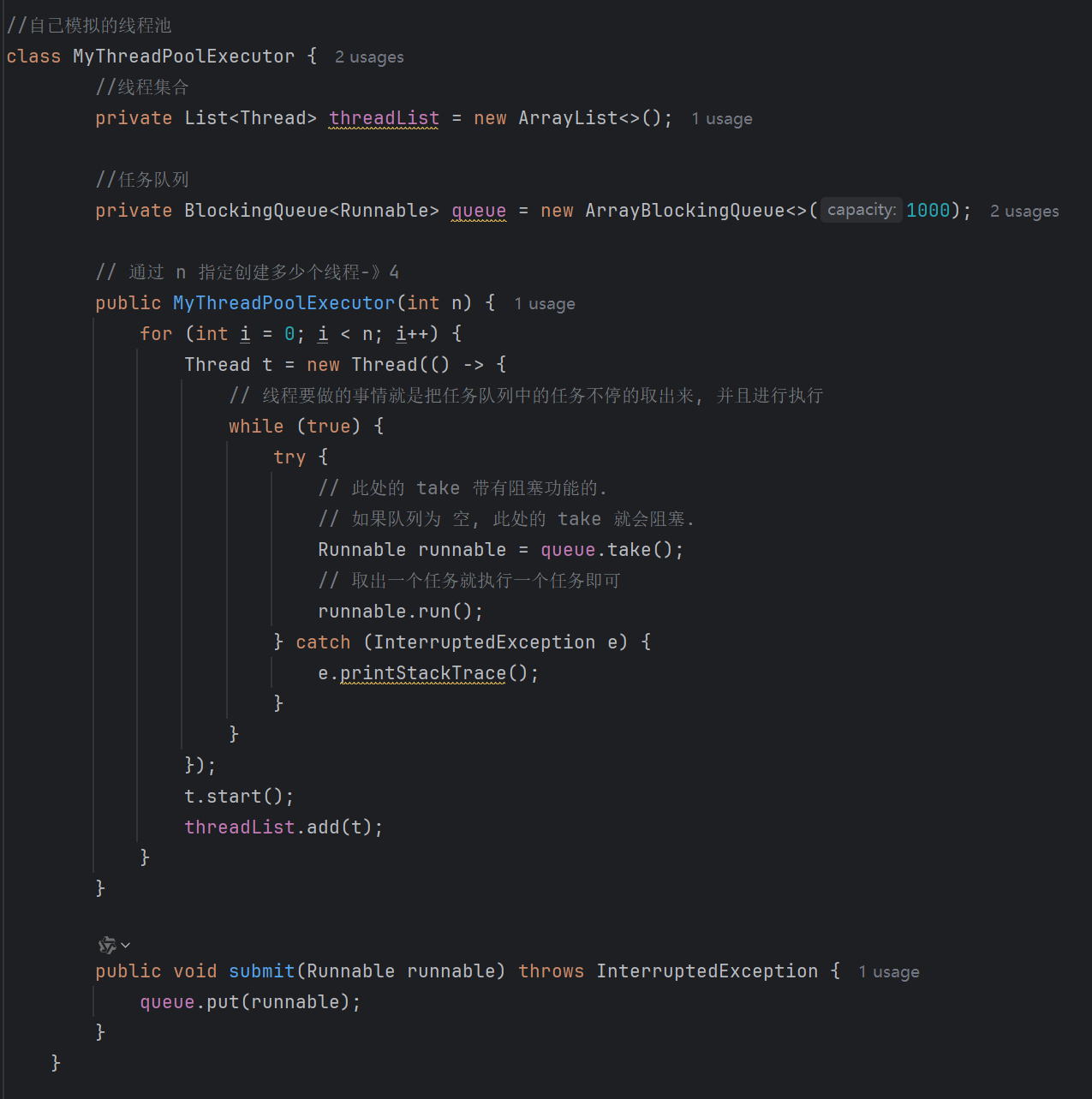
1. 线程数:int corePoolSize, int maximumPoolSize(核心线程数和最大线程数)
corePoolSize -> 核心线程数 -> 正式员工数
maximumPoolSize -> 最大线程数 -> 正式员工数 + 实习员工数
- 线程池允许创建的最大线程数量。
- 当工作队列满了,并且当前线程数小于最大线程数时,线程池会创建新的线程来处理任务
eg:
当核心线程处于忙碌中且有大量新的任务需要处理时,会创建实习员工线程,来帮核心线程处理;当任务数量变少时且持续一段时间,核心线程可以闲着(摸鱼),但实习员工线程全部销毁,提高了效率且节省了系统开销。
2. long keepAliveTime, TimeUnit unit(保持存活时间和存活时间的单位)
keepAliveTime:当线程池中的线程数量超过核心线程数时,多余的空闲线程在等待任务的时间超过这个值后,就会被销毁
unit:hour、min、s、ms
3. BlockingQueue<Runnable> workQueue
用来存放线程池中的任务的队列,使用Runnable来描述任务主体。
根据需要设置:
需要优先级:设置PriorityBlockingQueue
不需要优先级,并且任务数目相对恒定:使用ArrayBlockingQueue
不需要优先级,并且任务数目变动大:使用LinkedBlockingQueue
4.ThreadFactory threadFactory(线程工厂)
通过这个工厂类创建线程(Thread)对象,工厂类里面有方法封装了new Thread的操作,同时给Thread设置了一些属性,我们想要创建线程的时候可以直接使用工厂类的方法创建。
eg:


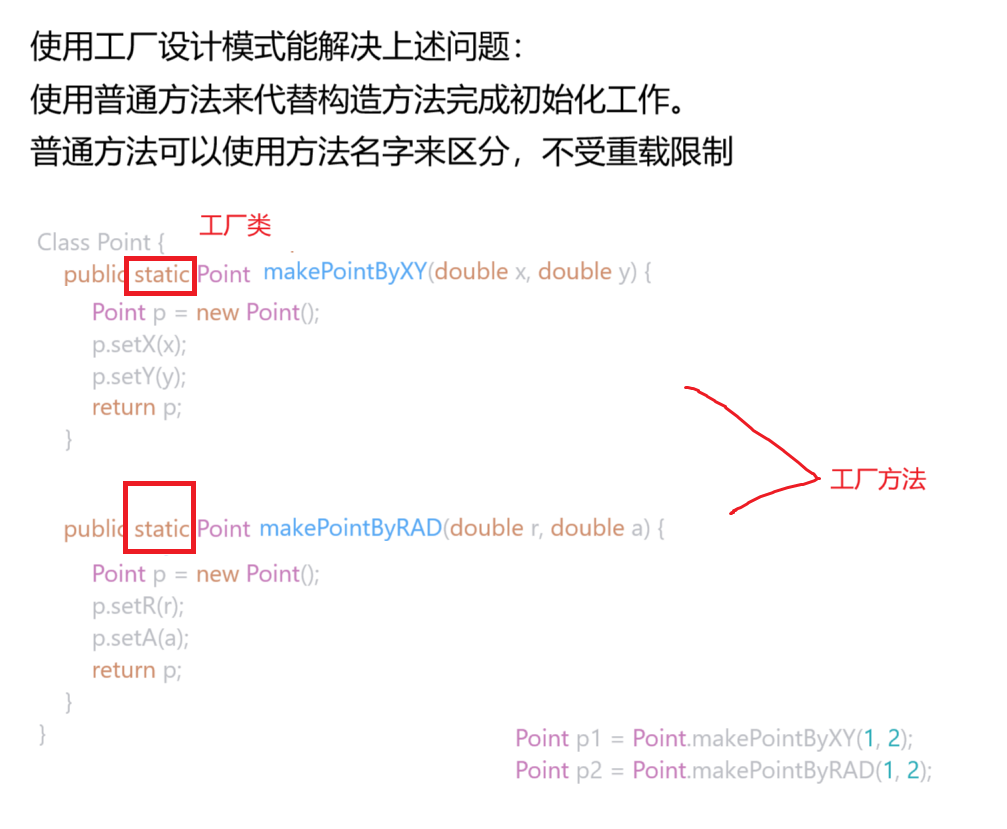
通过静态方法来封装new操作,在这个静态方法设置不同的属性,构造对象的过程,就称为工厂模式。
5.RejectedExecutionHandler handler(拒绝策略)
当workQueue满了,并且线程池中的线程数量已经达到最大线程数时,新的任务将会被拒绝线程池会采用拒绝策略。

Executors类:工厂类
ThreadPoolExecutor使用较复杂,所以通过封装,创建了工厂类Executors;
通过这个类可以创建出不同的线程池对象,内部已经把ThreadPoolExecutor创建好并设置好参数。
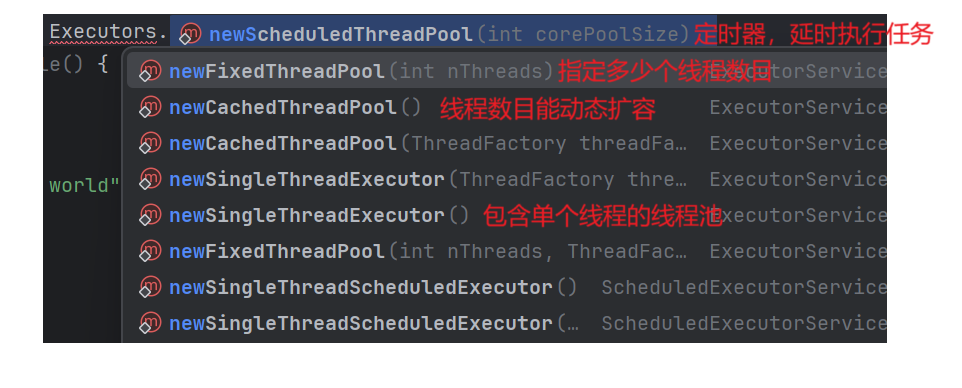
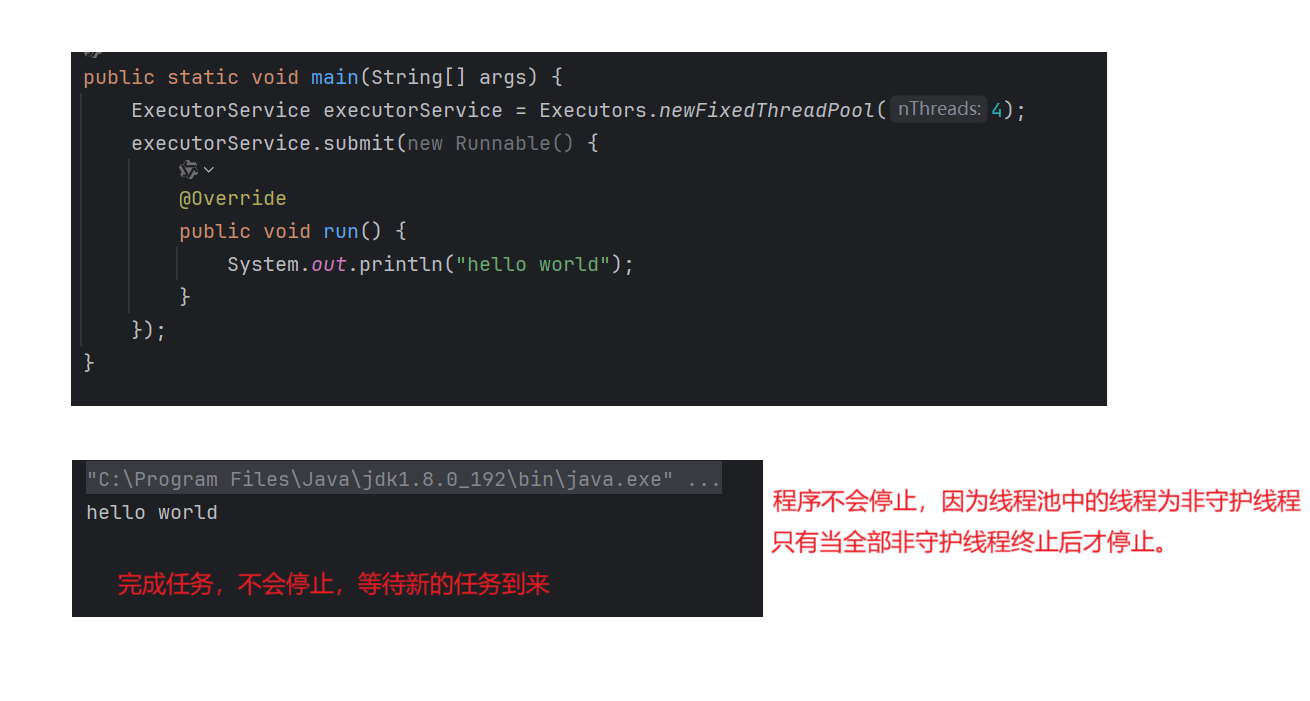
eg;使用newFixedThreadPool(4)创建了固定线程数目为4的线程池,往里面添加任务。
线程池的执行流程
线程池如何设置线程数目
我们将任务分为CPU密集型和I/O密集型
CPU密集型:在cpu上执行,当线程数超过CPU核心数时,线程需要竞争CPU时间片,这会带来额外的开销,降低效率。
所以线程数目不应超过N(CPU核心数)
I/O密集型:涉及大量I/O操作,大部分都是在等I/O完成,不是执行CPU,(当一个线程在执行I/O操作时,它会阻塞,释放CPU。此时,CPU可以去执行其他线程的任务)。
I/O密集型任务的线程数可以设置得比CPU核心数多,超过N。
在实际应用中,任务往往是CPU密集型和I/O密集型的混合体。更好的方法是通过实验/测试的方法,找出合适的线程数目。
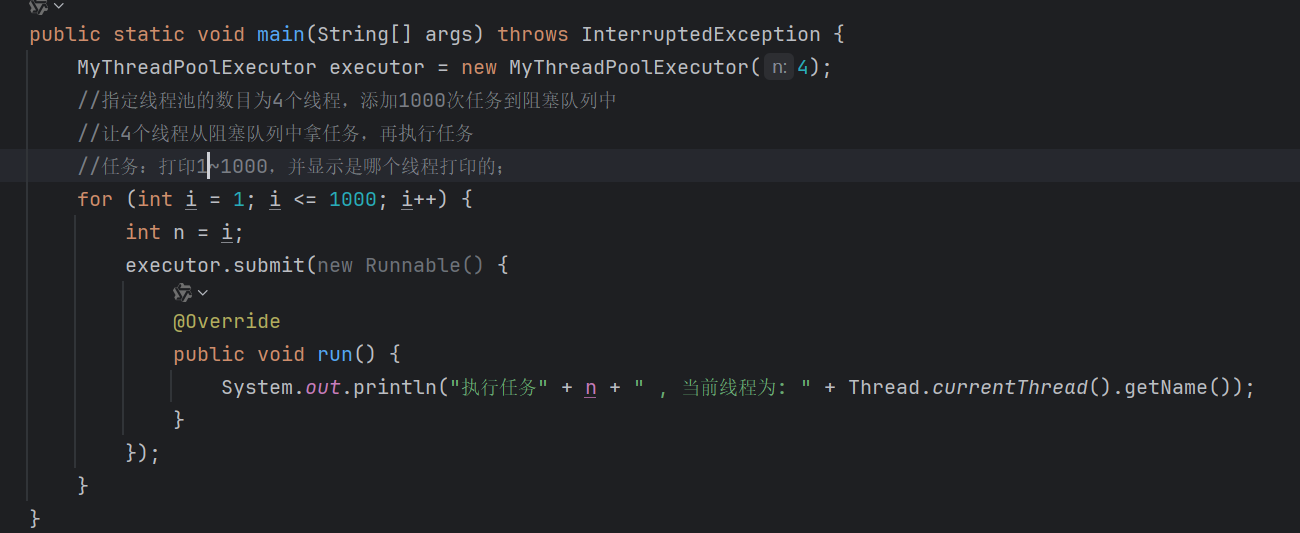
线程池的模拟实现

设计与实现细节(完整版))

智能化弱电系统解决方案)




)




Day13)

)

)

