领域LLM九讲——第4讲 构建可测评、可优化的端到端商业AI Agent 系统
以 OpenAI Cookbook 的《receipt_inspection》示例为基础,探讨如何设计一个可测试、可优化的端到端 AI Agent 系统。整体流程分为三个阶段:
(1) 端到端 Agent 构建(基线测试),
(2) 拆分中间任务与评分系统(可解释性与对齐),
(3) 构建收益/成本框架(系统优化)。
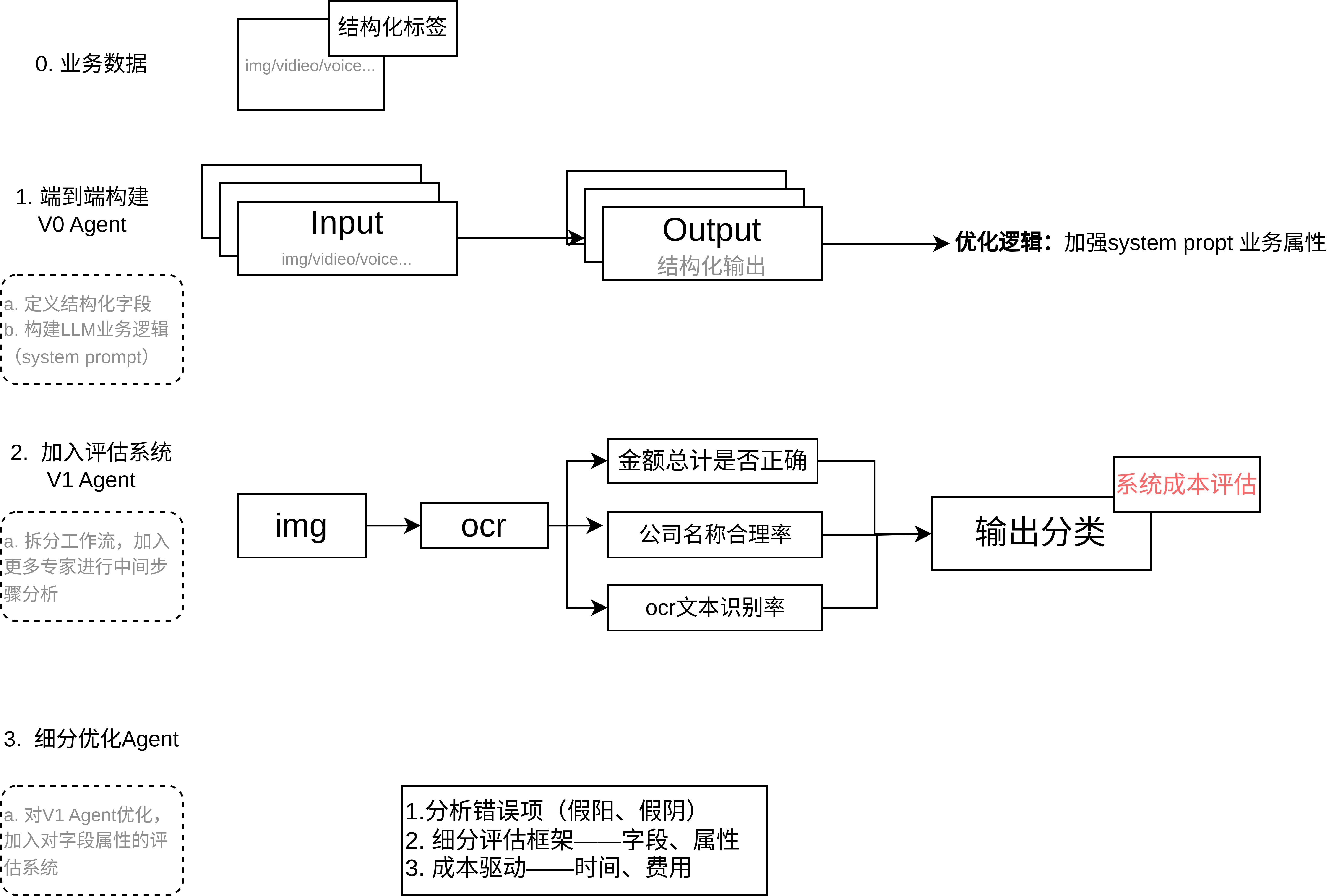
文章目录
- 领域LLM九讲——第4讲 构建可测评、可优化的端到端商业AI Agent 系统
- 1. 构建端到端系统 —— V0 Agent(基线)
- 2. 拆分中间任务与评分系统 —— V1 Agent(可解释性与对齐)
- 3. 构建收益/成本框架 —— V2 Agent(系统优化)
- 附录
1. 构建端到端系统 —— V0 Agent(基线)
- 构建最简化系统
首先搭建一个最基础的 Agent:直接使用一个 LLM 通过单次提示(或调用)完成整体任务。例如在收据解析场景中,可使用大模型对收据图片进行文字识别,并一次性输出所有字段信息与审核决策。示例中使用了 Pydantic 定义结构化输出模型(包含商户名称、地点、时间、条目列表等字段),并调用 LLM 填充这些字段。该阶段的目标是快速获得一个粗粒度的可行解,并建立性能基准。此时可记录关键指标(如整体识别准确率、误判率等)作为后续优化的对比基线。 - 优点与风险
端到端设计简单直接,开发迭代速度快。但也存在风险:缺乏内部可观察性,一旦结果错误很难定位原因,容易出现“碰运气”式的盲目迭代。没有中间检查点的系统可能隐藏关键错误,对复杂任务或高风险场景(如医疗诊断)欠妥。正如 OpenAI 所言,如果没有将评估内置于流程核心,开发往往陷入“拍脑袋”的猜测和印象式判断。因此该阶段仅作为起点,一方面需要对输出结果进行初步人工或规则验证,另一方面需意识到端到端方案的局限。
2. 拆分中间任务与评分系统 —— V1 Agent(可解释性与对齐)
-
任务拆解
在基线验证后,将复杂任务拆分为可管理的子任务或步骤,增强系统可解释性。例如,可按逻辑阶段分别处理:先用 OCR 获取文本,再让 LLM 提取字段、计算总额,最后再让 LLM 给出审核判定。示例中通过 Pydantic 模型来定义每个子任务的输出(如交易项目列表、总金额等)。分解后,每个子任务的输出都成为可独立评估的中间结果,这有助于理解整体过程并针对性优化某一步。 -
引入 Grader 评分
针对每个中间输出,引入一个Grader(评判器)来自动评估其质量,即“LLM 作为评判者”的思路。具体做法是设计多个评分模块,对不同子输出进行检查:可以是简单的相等检查、文本相似度计算,或再次调用 LLM 作为评判模型。例如,收据示例定义了几类 grader:字符串严格匹配检查(如总额是否一致)、文本相似度检查(如商户名称相似度)、以及基于模型的评分(如判断提取的条目是否缺漏)。这些 grader 分别针对输出的不同部分进行验证(有的只看输出本身,有的则需要对照正确答案)。Databricks 的 Agent Evaluation 也采用类似方法,使用一组 LLM 评判器分别对答案的正确性、相关性等方面进行评估。 -
控制节点与瓶颈定位
引入 grader 后,系统就有了“中控节点”,可以在每一步检测失败并采取措施。多个 Grader 评分后可合并结果,总结整体质量。如果整体评估失败,系统能指出是哪一个子任务的 grader 首先未通过。比如若“总额检查”未通过,就说明金额提取有问题;若“缺失条目检查”未通过,就说明提取遗漏条目。这样一方面提高了可解释性,另一方面可针对性地调整模型或提示,形成闭环改进。使用 LLM-作为评判者的做法在实践中被广泛采用,它能自动化评估文本质量并提供明确评分指标,是人工评估的可扩展替代方案。综上,在拆分任务并引入 Grader 后,我们可定位并修复 Agent 的弱点,从而对齐业务需求并逐步提升可靠性。
3. 构建收益/成本框架 —— V2 Agent(系统优化)
- 多维度成本度量
除准确率外,引入成本度量是优化的关键。首先要明确定义成本项:例如每张收据的处理成本(包含模型调用和基础设施开销)、低置信输出的人力校验成本、系统开发维护成本,以及因为错误带来的业务损失(如漏检或错判的罚款等)。在 Agent 层面,可量化的成本指标包括:调用模型所用的 token 数(直接对应 API 费用)、端到端响应延迟(影响用户体验或业务处理速率)、人工干预频率等。Databricks Agent Evaluation 就自动统计了整个任务过程中的总 token 数(含输入、输出)作为成本近似,也计算总时延。这些指标汇总到每次请求的评估报告中,帮助开发者了解资源消耗。 - 性能/成本权衡
系统优化即在多维指标上做权衡:精度、成本、延迟之间往往需要平衡。正如相关指导所指出的,需要权衡模型规模与延迟、质量与成本等因素。例如,可以先使用最强大的模型验证正确性,再尝试用更小模型或分步调用来降低成本;也可接受小幅度精度下降以换取大幅度的时间和费用节省。业务方可能愿意为降低延迟或费用而牺牲一定的准确率,反之亦然。因此需要明确量化:如每增加多少 token 花费多少美元、响应延迟对用户体验的影响,以及人工干预一次的成本等。通过这些量化指标,可以建立收益/成本模型,判断在何种改进措施下投入产出比最高。例如,如果某个子模块的 grader 失败率很高,就算投入更大模型减少错误,增加的成本是否值得?这样的分析需要具体计算错误降低带来的收益和新增成本。综合考虑后,可制定策略:如对重点子任务使用高质量模型,对一般子任务用小模型,或只对 grader 评分未通过的例外场景启用人工复核,将资源聚焦到最需要的环节上。
如在文章中,作者建立的成本体系:
公司每年处理 100 万张收据,基准成本为每张收据 0.20 美元, 审计收据的成本约为 2 美元
未能审计我们应该审计的收据,平均成本为 30 美元,5% 的收据需要审计
现有流程
- 识别 97% 情况下需要审计的收据
- 2% 的情况下错误识别不需要审计的收据
这给了我们两个基准比较:
- 如果我们正确识别每张收据,我们将花费 100,000 美元进行审计
- 我们目前的流程在审计上花费了 135,000 美元,并因未审计的费用损失了 45,000 美元
除此之外,人工驱动的过程还需额外花费 20 万美元。
这里只是构建了审核系统中构建节约成本的高效Agent,但本质上没有带来利润。如果在成本基础上添加利润,如生图框架、广告视频生成等,首先要考虑整个工作流pipeline的节点构造(结果为导向);然后考虑生成过程中的稳定可控性(结果为导向);其次考虑成本(LLM选择)与利润(生成时间与效果),利润这块还可以通过增加用户复用率(如生成视频的精修)。
附录
本人github项目地址:https://github.com/oncecoo
欢迎关注!
:MySQL目录与启动配置全解析)

)


强化学习专题(1))



 的变化导致的影响(那部分被分给了链式项))

 类,加深对拷贝构造函数的理解)
)



语音/字幕标注 通过via(via_subtitle_annotator))


