布隆过滤器
问题前景:
之前学习了位图,我们知道位图在大量数据查找时候是很方便的。但位图的缺陷在于只能用于整型数据。而在实际中,我们的数据更多的是更复杂的字符串或者自定义类型。那么此时位图就显得有点无力,所以就诞生了叫布隆过滤器的数据结构。
布隆过滤器:
布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构,主要用于快速判断一个元素是否“可能存在于”一个集合中,或者“绝对不存在于”集合中。
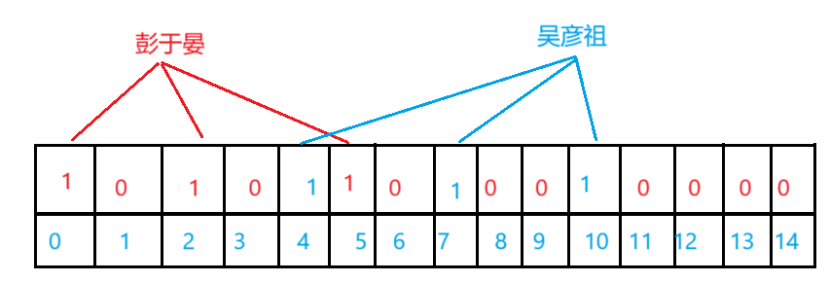
那可能会有疑问,为什么布隆过滤器需要映射多个值,而不只映射单个值呢?

假设我们现在需要查找名字为胡歌,此时就存在Hash冲突,胡歌明明没有插入数据,但显示已经在布隆过滤器里了,存在误判。

而我们使用多个Hash函数进行分别插入,虽然不能完全解决这个问题,但是可以大大降低误判率。
在映射的K个位置里,只要有其中一个不在,该元素就是不存在。
只有映射的K个位置里,全部在,才可能在(存在误判风险)。
布隆过滤器理论结论:
布隆过滤器的推到,这里小编就不细讲了,大家有兴趣可以自行搜索。小编就简单说下结论
当哈希函数固定时,插入的数据增加,误判率增加。开的比特位增加,误判率就减少。
判断一个数不在是准确的,判断一个数在是不准确的。
布隆过滤器代码实现:
#pragma once
#include<iostream>
#include<vector>
#include<string>using namespace std;template<size_t size>
class BitMap
{
public:BitMap(){_bm.resize(size);}void set(size_t x){int i = x / 32;int j = x % 32;_bm[i] |= (1 << j);}bool test(size_t x){int i = x / 32;int j = x % 32;return _bm[i]&(1 << j);}private:vector<size_t> _bm;
};struct HashFuncBKDR
{size_t operator()(const string& s){size_t hash = 0;for (auto ch : s){hash *= 31;hash += ch;}return hash;}
};
struct HashFuncAP
{size_t operator()(const string& s){size_t hash = 0;for (size_t i = 0; i < s.size(); i++){if ((i & 1) == 0) {hash ^= ((hash << 7) ^ (s[i]) ^ (hash >> 3));}else {hash ^= (~((hash << 11) ^ (s[i]) ^ (hash >>5)));}}return hash;}
};
struct HashFuncDJB
{size_t operator()(const string & s){size_t hash = 5381;for (auto ch : s){hash = hash * 33 ^ ch;}return hash;}
};template<size_t N, size_t X = 5, class K=string,class Hash1= HashFuncBKDR,class Hash2= HashFuncAP,class Hash3= HashFuncDJB>
class Blomm_fiter
{
public:void set(const K&key){size_t hash1 = Hash1()(key) % M;size_t hash2 = Hash2()(key) % M;size_t hash3 = Hash3()(key) % M;_bm.set(hash1);_bm.set(hash2);_bm.set(hash3);}bool test(const K&key){size_t hash1 = Hash1()(key) % M;size_t hash2 = Hash2()(key) % M;size_t hash3 = Hash3()(key) % M;if(!_bm.test(hash1)){return false;}if (!_bm.test(hash2)){return false;}if (!_bm.test(hash3)){return false;}return true;//不一定准确}// 获取公式计算出的误判率double getFalseProbability(){double p = pow((1.0 - pow(2.71, -3.0 / X)), 3.0);return p;}private:static const size_t M = N * X; //M为实际需要开的数据BitMap<M> _bm;
};代码解释:
类模板定义:
N为传入的数据大小,X为倍数,用于求出M,K为模板类型,剩下的就是哈希函数。这里为了简单实现,就写死哈希函数,在实际实现中,哈希函数可以进行动态调整多少。
成员变量:
M需要开多少个比特位
_bm就是普通位图,因为布隆过滤器或许还是会转成int类型进行映射。我们这里直接套用即可。
Set(size_t x)
使用多个哈希函数求出映射的位置,并调用_bm的函数set进行置1
Test(size_t x)
该函数为布隆过滤器核心,当有一个不在就是不在,这个是准确的。当全部在的时候可能在,这个是不准确的。
测试代码:

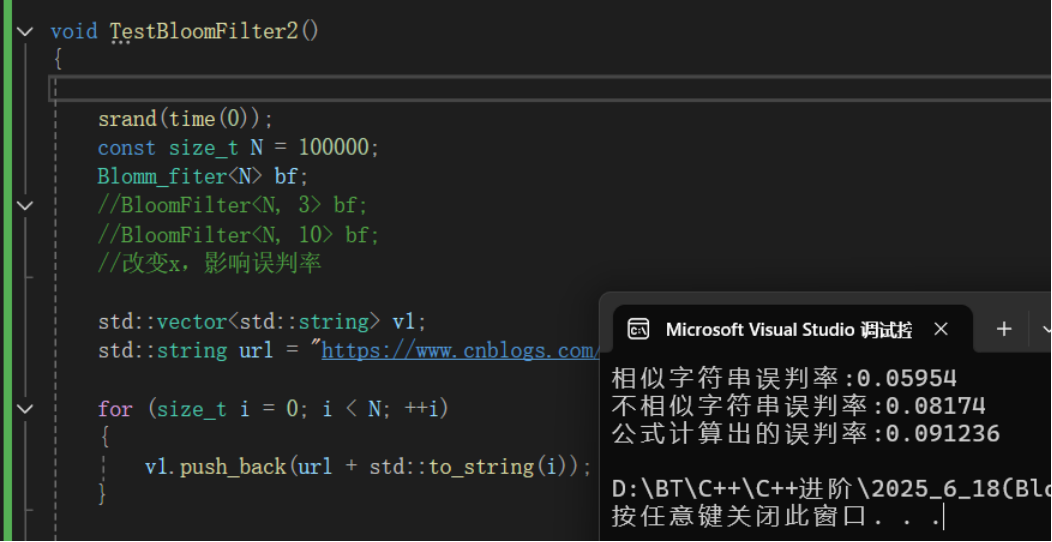

通过测试代码,就能很直观的看出,我们可以通过控制X(倍数)的大小,进行控制误判率。X越小误判率越大,X越大误判率越小。
布隆过滤器的实际应用:
布隆过滤器的优势(空间小、查询快、“不存在”判断准)使其非常适合用于需要快速过滤掉大量“肯定不存在”的请求的场景,尤其当数据量巨大且对少量误判可以容忍时:
缓存穿透防护:
问题:查询一个不存在的数据,导致请求绕过缓存直接冲击底层数据库(如Redis、MySQL)。
解决:将所有可能存在的缓存键(或数据库主键)放入布隆过滤器。查询时先查布隆过滤器:
若返回“不存在”,则直接返回空或错误,避免查数据库。
若返回“可能存在”,再去查缓存/数据库。即使有少量误判(查了数据库但没结果),也比所有不存在请求都查数据库要好得多。
网络爬虫的URL去重:
问题:避免重复抓取同一个URL。
解决:将已抓取或计划抓取的URL放入布隆过滤器。
新URL来临时:
查布隆过滤器:若返回“不存在”,则一定是新URL,加入抓取队列并添加到过滤器。
若返回“可能存在”,则大概率是重复URL(即使有小概率误判是新URL,放弃抓取也是可以接受的代价)。











)


:移动应用核心指标解析与用户分层营收策略)



)
