- 查看环境
- 确定安装版本
- 安装CUDA12.8
- 安装Anaconda
- 安装Visual Studio C++桌面开发环境(编译llama.cpp需要)
- 安装cmake(编译llama.cpp需要)
- 安装llama.cpp(用于量化)
- 安装huggingface-cli
- 安装llama-factory
- 安装PyTorch2.7.0
- 安装bitsandbytes
- 安装flash-attention加速(减少内存的)
- 安装unsloth加速(减少显存的)
- 安装deepspeed加速(分布式训练)
- 测试环境
- 准备数据集
- 修改配置以适配多显卡
- 训练
参考链接
查看环境
CPU:R7 9800X3D
RAM:96GB(5600)
GPU:5060Ti 16GB * 2
nvidia-smi

我的显卡是5060Ti,CUDA版本为12.9,理论上有11.8、12.6、12.8三个版本可以以使用,但是在实际中,11.8、12.6是不支持50系显卡的,所以需要使用12.8
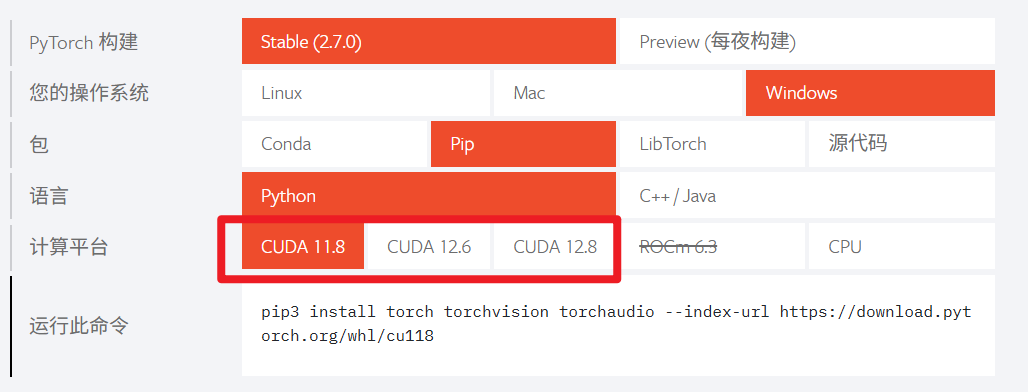
安装环境
根据硬件环境确定了软件环境
选择环境为Python3.12.10+CUDA12.8+PyTorch2.7.0
在安装之前需要先安装Anaconda、python和Visual Studio的C++桌面开发环境
安装llama.cpp
下载(需要先安装 CUDA 和 python ):
安装 curl(使用联网下载模型,可选)
git clone https://github.com/microsoft/vcpkg.git
cd vcpkg
.\bootstrap-vcpkg.bat
.\vcpkg install curl:x64-windows
需手动新建模型下载目录C:\Users\Administrator\AppData\Local\llama.cpp
git clone https://github.com/ggerganov/llama.cpp.gitcd llama.cpp
cmake -B build -DGGML_CUDA=ON -DLLAMA_CURL=OFF
cmake --build build --config Release
-B build:指定构建目录为 ./build。
-DGGML_CUDA=ON:启用 CUDA 支持(需已安装 CUDA 工具包)。
-DLLAMA_CURL=ON:启用 CURL 支持(需已安装 curl)
安装依赖:
# 也可以手动安装 torch 之后,再安装剩下的依赖
pip install -r requirements.txt
进入build\bin\Release目录开始使用llama
安装huggingface-cli
用于下载模型
pip install -U huggingface_hub
设置环境变量:

| 变量名 | 说明 |
|---|---|
| HF_HOME | 模型保存路径 |
| HF_ENDPOINT | 从什么地方下载模型:使用国内镜像站:https://hf-mirror.com |
下载指令如下:
huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1 --local-dir e:/model --local-dir-use-symlinks False
--resume-download已弃用
--local-dir保存路径
deepseek-ai/DeepSeek-R1为下载的模型
--local-dir-use-symlinks False 取消软连接,Windows中没有软链接
可以简化为:
huggingface-cli download deepseek-ai/DeepSeek-R1

下载LLaMa-factory:
git clone https://github.com/hiyouga/LLaMA-Factory.git
安装LLaMa-factory:
如果出现环境冲突,请尝试使用pip install --no-deps -e解决
conda create -n llama_factory python=3.12
conda activate llama_factory
cd LLaMA-Factory
pip install -e .[metrics]
这里指定metrics参数是安装jieba分词库等,方面后续可能要训练或者微调中文数据集。
可选的额外依赖项:torch、torch-npu、metrics、deepspeed、liger-kernel、bitsandbytes、hqq、eetq、gptq、aqlm、vllm、sglang、galore、apollo、badam、adam-mini、qwen、minicpm_v、modelscope、openmind、swanlab、quality
| 名称 | 描述 |
|---|---|
| torch | 开源深度学习框架 PyTorch,广泛用于机器学习和人工智能研究中。 |
| torch-npu | PyTorch 的昇腾设备兼容包。 |
| metrics | 用于评估和监控机器学习模型性能。 |
| deepspeed | 提供了分布式训练所需的零冗余优化器。 |
| bitsandbytes | 用于大型语言模型量化。 |
| hqq | 用于大型语言模型量化。 |
| eetq | 用于大型语言模型量化。 |
| gptq | 用于加载 GPTQ 量化模型。 |
| awq | 用于加载 AWQ 量化模型。 |
| aqlm | 用于加载 AQLM 量化模型。 |
| vllm | 提供了高速并发的模型推理服务。 |
| galore | 提供了高效全参微调算法。 |
| badam | 提供了高效全参微调算法。 |
| qwen | 提供了加载 Qwen v1 模型所需的包。 |
| modelscope | 魔搭社区,提供了预训练模型和数据集的下载途径。 |
| swanlab | 开源训练跟踪工具 SwanLab,用于记录与可视化训练过程 |
| dev | 用于 LLaMA Factory 开发维护。 |
安装好后就可以使用llamafactory-cli webui打开web页面了
如果出现找不到llamafactory-cli,是没有将该路径加入环境变量,找到程序所在路径,加入path环境变量即可
安装CUDA12.8+PyTorch2.7.0
因为上述方式似乎默认安装了一个CPU版本的pytorch,但是版本不是我们想要的,直接安装覆盖即可。具体方法根据PyTorch相应版本提供的安装方式进行安装
pip3 install torch==2.7.0 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
CUDA下载链接:https://developer.nvidia.com/cuda-toolkit-archive
选择适合的版本进行安装,安装好后通过nvcc --version查看是否安装成功,如果成功输出版本号则安装成功
nvcc --version
安装bitsandbytes
如果要在 Windows 平台上开启量化 LoRA(QLoRA),需要安装 bitsandbytes 库
使用pip安装
pip install bitsandbytes
也可以使用已经编译好的,支持 CUDA 11.1 到 12.2, 根据 CUDA 版本情况选择适合的发布版本。
https://github.com/jllllll/bitsandbytes-windows-webui/releases/tag/wheels
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl
如果上面的方法都不行,就使用源码安装
git clone https://github.com/timdettmers/bitsandbytes.git
cd bitsandbytes
set CUDA_VERSION=128
make cuda12x
python setup.py install
windows中如果无法使用make可以使用cmake
cmake -B . -DCOMPUTE_BACKEND=cuda -S .
cmake --build .
pip install .
Windows的make下载地址:https://gnuwin32.sourceforge.net/packages/make.html
加速
LLaMA-Factory 支持多种加速技术,包括:FlashAttention 、 Unsloth 、 Liger Kernel 。
三种方法选择其中一个就可以了,或者不安装。
安装flash-attention
FlashAttention 能够加快注意力机制的运算速度,同时减少对内存的使用。
检查环境:
pip debug --verbose

编译好的下载链接:https://github.com/bdashore3/flash-attention/releases

由于没有完全匹配的版本,所以选择了最接近的一个版本
使用pip安装
pip install E:\wheels\flash_attn-2.7.4.post1+cu124torch2.6.0cxx11abiFALSE-cp312-cp312-win_amd64.whl
如果无法使用可能需要源码编译安装https://huggingface.co/lldacing/flash-attention-windows-wheel
Unsloth安装
Unsloth 框架支持 Llama, Mistral, Phi-3, Gemma, Yi, DeepSeek, Qwen等大语言模型并且支持 4-bit 和 16-bit 的 QLoRA/LoRA 微调,该框架在提高运算速度的同时还减少了显存占用。
需要先安装xformers, torch, BitsandBytes 和triton,并且只支持NVIDIA显卡
pip install unsloth
显存和参数关系
| 模型参数 | QLoRA (4-bit) VRAM | LoRA (16-bit) VRAM |
|---|---|---|
| 3B | 3.5 GB | 8 GB |
| 7B | 5 GB | 19 GB |
| 8B | 6 GB | 22 GB |
| 9B | 6.5 GB | 24 GB |
| 11B | 7.5 GB | 29 GB |
| 14B | 8.5 GB | 33 GB |
| 27B | 22 GB | 64 GB |
| 32B | 26 GB | 76 GB |
| 40B | 30 GB | 96 GB |
| 70B | 41 GB | 164 GB |
| 81B | 48 GB | 192 GB |
| 90B | 53 GB | 212 GB |
| 405B | 237 GB | 950 GB |
Liger Kernel安装
Liger Kernel是一个大语言模型训练的性能优化框架, 可有效地提高吞吐量并减少内存占用。
测试
测试PyTorch和CUDA
编写一个测试程序
import os
import torchos.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
print("PyTorch Version:", torch.__version__)
print("CUDA Available:", torch.cuda.is_available())if torch.cuda.is_available():print("CUDA Version:", torch.version.cuda)print("Current CUDA Device Index:", torch.cuda.current_device())print("Current CUDA Device Name:", torch.cuda.get_device_name(0))
else:print("CUDA is not available on this system.")
运行:

测试依赖库
对基础安装的环境做一下校验,输入以下命令获取训练相关的参数指导, 否则说明库还没有安装成功
llamafactory-cli train -h

Windows中如果报libuv的错,则使用以下命令
set USE_LIBUV=0 && llamafactory-cli train -h

双显卡在Windows平台会报错,需要禁用一张显卡,或者使用以下环境变量试试
set CUDA_VISIBLE_DEVICES=0,1

测试环境是否正常
windows似乎不支持CUDA_VISIBLE_DEVICES=0指定显卡,并且也不支持”\“换行console,分别对应修改:
对于第一个问题,一种方式是修改环境变量,在用户变量或者系统变量加一行就可以。CUDA_VISIBLE_DEVICES 0
llamafactory-cli webchat --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct --template llama3
llamafactory-cli webchat E:hf\hub\LLaMA-Factory\examples\inference\llama3.yaml
训练
pip install deepspeed
Windows平台下在模型训练的过程中出现 “RuntimeError: CUDA Setup failed despite GPU being available” 的错误,导致训练中断。
处理方法1:
pip uninstall bitsandbytes
pip install bitsandbytes-windows
执行上述的命令如果没有解决问题,试一下一下方法:
pip uninstall bitsandbytes
pip install bitsandbytes-cuda128
pip uninstall bitsandbytes-cuda128
pip install bitsandbytes
在运行过程中所有的错误无非两种情况造成的。
- 情况1:安装环境出现冲突(包的依赖出现冲突或者CUDA的版本没有安装对);
- 情况2:权限不够(sudo运行或者管理员下运行即可解决,一般报错信息中会出现permission字样)
webui微调
参考链接1
参考链接2
参考链接3
代码微调
'''
需要的依赖torchtransformersdatasetspeftbitsandbytes
'''# 测试模型是否可用
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments
# 加载模型 Hugging face提前下载
model_name = r'E:\hf\DeepSeekR1DistillQwen1.5B'
tokenizer = AutoTokenizer.from_pretrained(model_name)# 模型加载成功之后注释model代码,否则每次都占用内存 (如果内存不够,可以使用device_map='auto')
model = AutoModelForCausalLM.from_pretrained(model_name,device_map='auto',trust_remote_code=True)for name, param in model.named_parameters():if param.is_meta:raise ValueError(f"Parameter {name} is in meta device.")print('---------------模型加载成功-------------')# 制作数据集
from data_prepare import samples
import json
with open('datasets.jsonl','w',encoding='utf-8') as f:for s in samples:json_line = json.dumps(s,ensure_ascii=False)f.write(json_line + '\n')else:print('-------数据集制作完成------')# 准备训练集和测集
from datasets import load_dataset
dataset = load_dataset('json',data_files={'train':'datasets.jsonl'},split='train')
print('数据的数量',len(dataset))train_test_split = dataset.train_test_split(test_size=0.1)
train_dataset = train_test_split['train']
eval_dataset = train_test_split['test']
print('训练集的数量',len(train_dataset))
print('测试集的数量',len(eval_dataset))print('--------完成训练数据的准备工作--------')# 编写tokenizer处理工具
def tokenize_function(examples):texts = [f"{prompt}\n{completion}" for prompt , completion in zip(examples['prompt'],examples['completion'])]tokens = tokenizer(texts,truncation=True,max_length=512,padding="max_length")tokens["labels"] = tokens["input_ids"].copy()return tokenstokenized_train_dataset = train_dataset.map(tokenize_function,batched=True)
tokenized_eval_dataset = eval_dataset.map(tokenize_function,batched=True)print('---------完成tokenizer-------------')
# print(tokenized_eval_dataset[0])# 量化设置import torch
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype=torch.bfloat16,device_map="auto"
)
print('-----------完成量化模型的加载-----------------')# lora设置
from peft import LoraConfig,get_peft_model,TaskType
lora_config = LoraConfig(r=8,lora_alpha=16,target_modules=["q_proj","v_proj"],lora_dropout=0.05,bias="none",task_type=TaskType.CAUSAL_LM
)
model = get_peft_model(model,lora_config)
model.print_trainable_parameters()
print('-----------完成lora模型的加载-----------------')# 设置训练参数
training_args = TrainingArguments(output_dir="./results",num_train_epochs=3,per_device_train_batch_size=8,per_device_eval_batch_size=8,gradient_accumulation_steps=4,fp16=True,evaluation_strategy="steps",save_steps=100,eval_steps=10,learning_rate=3e-5,logging_dir="./logs",run_name='deepseek1.5b',# 后期增加的内容label_names=["labels"], # 必须显式指定remove_unused_columns=False, # 确保不自动删除标签字段
)
print('--------训练参数设置完毕----------')# 定义训练器
from transformers import Trainer
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_train_dataset,eval_dataset=tokenized_eval_dataset
)print('--------训练器定义完毕----------')
print('----------开始训练-------------')
trainer.train()
print('----------训练完成-------------')
微调原理
数据处理
dataset_info.json包含了所有经过预处理的 本地数据集 以及 在线数据集。如果使用自定义数据集,在 dataset_info.json文件中添加对数据集及其内容的定义。
目前 LLaMA Factory支持 Alpaca格式和 ShareGPT格式的数据集。
Alpaca
针对不同任务,数据集格式要求如下:
- 指令监督微调
- 预训练
- 偏好训练
- KTO
- 多模态
指令监督微调数据集
样例数据集: 指令监督微调样例数据集
指令监督微调(Instruct Tuning)通过让模型学习详细的指令以及对应的回答来优化模型在特定指令下的表现。
instruction 列对应的内容为人类指令, input 列对应的内容为人类输入, output 列对应的内容为模型回答。下面是一个例子
{"instruction": "计算这些物品的总费用。 ","input": "输入:汽车 - $3000,衣服 - $100,书 - $20。","output": "汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。"
},
在进行指令监督微调时, instruction 列对应的内容会与 input 列对应的内容拼接后作为最终的人类输入,即人类输入为 instruction\input。而 output 列对应的内容为模型回答。 在上面的例子中,人类的最终输入是:
计算这些物品的总费用。
输入:汽车 - $3000,衣服 - $100,书 - $20。
模型的回答是:
汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。
如果指定, system 列对应的内容将被作为系统提示词。
history 列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
指令监督微调数据集 格式要求 如下:
[{"instruction": "人类指令(必填)","input": "人类输入(选填)","output": "模型回答(必填)","system": "系统提示词(选填)","history": [["第一轮指令(选填)", "第一轮回答(选填)"],["第二轮指令(选填)", "第二轮回答(选填)"]]}
]
下面提供一个 alpaca 格式 多轮 对话的例子,对于单轮对话只需省略 history 列即可。
[{"instruction": "今天的天气怎么样?","input": "","output": "今天的天气不错,是晴天。","history": [["今天会下雨吗?","今天不会下雨,是个好天气。"],["今天适合出去玩吗?","非常适合,空气质量很好。"]]}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","system": "system","history": "history"}
}
预训练数据集
样例数据集: 预训练样例数据集
大语言模型通过学习未被标记的文本进行预训练,从而学习语言的表征。通常,预训练数据集从互联网上获得,因为互联网上提供了大量的不同领域的文本信息,有助于提升模型的泛化能力。 预训练数据集文本描述格式如下:
[{"text": "document"},{"text": "document"}
]
在预训练时,只有 text 列中的 内容 (即document)会用于模型学习。
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {"file_name": "data.json","columns": {"prompt": "text"}
}
偏好数据集
偏好数据集用于奖励模型训练、DPO 训练和 ORPO 训练。对于系统指令和人类输入,偏好数据集给出了一个更优的回答和一个更差的回答。
一些研究 表明通过让模型学习“什么更好”可以使得模型更加迎合人类的需求。 甚至可以使得参数相对较少的模型的表现优于参数更多的模型。
偏好数据集需要在 chosen 列中提供更优的回答,并在 rejected 列中提供更差的回答,在一轮问答中其格式如下:
[{"instruction": "人类指令(必填)","input": "人类输入(选填)","chosen": "优质回答(必填)","rejected": "劣质回答(必填)"}
]
对于上述格式的数据,dataset_info.json 中的 数据集描述 应为:
"数据集名称": {"file_name": "data.json","ranking": true,"columns": {"prompt": "instruction","query": "input","chosen": "chosen","rejected": "rejected"}
}
KTO 数据集
KTO数据集与偏好数据集类似,但不同于给出一个更优的回答和一个更差的回答,KTO数据集对每一轮问答只给出一个 true/false 的 label。 除了 instruction 以及 input 组成的人类最终输入和模型回答 output ,KTO 数据集还需要额外添加一个 kto_tag 列(true/false)来表示人类的反馈。
在一轮问答中其格式如下:
[{"instruction": "人类指令(必填)","input": "人类输入(选填)","output": "模型回答(必填)","kto_tag": "人类反馈 [true/false](必填)"}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","kto_tag": "kto_tag"}
}
多模态数据集
LLaMA Factory 目前支持多模态图像数据集、 视频数据集 以及 音频数据集 的输入。
图像数据集
多模态图像数据集需要额外添加一个 images 列,包含输入图像的路径。 注意图片的数量必须与文本中所有 <image> 标记的数量严格一致。
[{"instruction": "人类指令(必填)","input": "人类输入(选填)","output": "模型回答(必填)","images": ["图像路径(必填)"]}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","images": "images"}
}
视频数据集
多模态视频数据集需要额外添加一个 videos 列,包含输入视频的路径。 注意视频的数量必须与文本中所有 <video> 标记的数量严格一致。
[{"instruction": "人类指令(必填)","input": "人类输入(选填)","output": "模型回答(必填)","videos": ["视频路径(必填)"]}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","videos": "videos"}
}
音频数据集
多模态音频数据集需要额外添加一个 audio 列,包含输入图像的路径。 注意音频的数量必须与文本中所有 <audio> 标记的数量严格一致。
[{"instruction": "人类指令(必填)","input": "人类输入(选填)","output": "模型回答(必填)","audios": ["音频路径(必填)"]}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","audios": "audios"}
}
ShareGPT
针对不同任务,数据集格式要求如下:
指令监督微调偏好训练OpenAI格式
ShareGPT格式中的 KTO数据集(样例)和多模态数据集(样例) 与Alpaca格式的类似。
预训练数据集不支持ShareGPT格式。
指令监督微调数据集
样例数据集: 指令监督微调样例数据集
相比 alpaca 格式的数据集, sharegpt 格式支持 更多 的角色种类,例如 human、gpt、observation、function 等等。它们构成一个对象列表呈现在 conversations 列中。 下面是 sharegpt 格式的一个例子:
{"conversations": [{"from": "human","value": "你好,我出生于1990年5月15日。你能告诉我我今天几岁了吗?"},{"from": "function_call","value": "{\"name\": \"calculate_age\", \"arguments\": {\"birthdate\": \"1990-05-15\"}}"},{"from": "observation","value": "{\"age\": 31}"},{"from": "gpt","value": "根据我的计算,你今天31岁了。"}],"tools": "[{\"name\": \"calculate_age\", \"description\": \"根据出生日期计算年龄\", \"parameters\": {\"type\": \"object\", \"properties\": {\"birthdate\": {\"type\": \"string\", \"description\": \"出生日期以YYYY-MM-DD格式表示\"}}, \"required\": [\"birthdate\"]}}]"
}
注意其中 human 和 observation 必须出现在奇数位置,gpt 和 function 必须出现在偶数位置。
[{"conversations": [{"from": "human","value": "人类指令"},{"from": "function_call","value": "工具参数"},{"from": "observation","value": "工具结果"},{"from": "gpt","value": "模型回答"}],"system": "系统提示词(选填)","tools": "工具描述(选填)"}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {"file_name": "data.json","formatting": "sharegpt","columns": {"messages": "conversations","system": "system","tools": "tools"}
}
偏好数据集
样例数据集: 偏好数据样例数据集
Sharegpt 格式的偏好数据集同样需要在 chosen 列中提供更优的消息,并在 rejected 列中提供更差的消息。 下面是一个例子:
{"conversations": [{"from": "human","value": "老虎会吃哪一个,草还是树叶?"}],"chosen": {"from": "gpt","value": "我很高兴能帮助你解答问题!不过,我必须指出,这个问题本身可能没有意义。老虎是食肉动物,通常不吃草或树叶。它们的饮食主要包括大型有蹄动物、小型哺乳动物和鸟类。\n\n如果你提出这个问题是出于好奇或有特定原因,我很乐意帮助你找到更多关于老虎饮食习惯的信息,或者建议资源让你更多了解这些壮丽的生物。请告诉我如何进一步协助你!"},"rejected": {"from": "gpt","value": "一只老虎是食肉动物,这意味着它的饮食主要是肉类。老虎主要猎捕和吃其他动物,如鹿和野猪。它们不会选择吃草或树叶,因为这些不是它们自然饮食的一部分。"}
}
其格式为:
[{"conversations": [{"from": "human","value": "人类指令"},{"from": "gpt","value": "模型回答"},{"from": "human","value": "人类指令"}],"chosen": {"from": "gpt","value": "优质回答"},"rejected": {"from": "gpt","value": "劣质回答"}}
]
对于上述格式的数据,dataset_info.json 中的 数据集描述 应为:
"数据集名称": {"file_name": "data.json","formatting": "sharegpt","ranking": true,"columns": {"messages": "conversations","chosen": "chosen","rejected": "rejected"}
}
OpenAI格式
OpenAI 格式仅仅是 sharegpt 格式的一种特殊情况,其中第一条消息可能是系统提示词。
[{"messages": [{"role": "system","content": "系统提示词(选填)"},{"role": "user","content": "人类指令"},{"role": "assistant","content": "模型回答"}]}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {"file_name": "data.json","formatting": "sharegpt","columns": {"messages": "messages"},"tags": {"role_tag": "role","content_tag": "content","user_tag": "user","assistant_tag": "assistant","system_tag": "system"}
}
加速
如果使用 FlashAttention,在启动训练时在训练配置文件中添加以下参数:
flash_attn: fa2
如果使用 Unsloth, 在启动训练时在训练配置文件中添加以下参数:
use_unsloth: True
如果使用 Liger Kernel,在启动训练时在训练配置文件中添加以下参数:
enable_liger_kernel: True
分布训练
LLaMA-Factory 支持单机多卡和多机多卡分布式训练。同时也支持 DDP , DeepSpeed 和 FSDP 三种分布式引擎。
DDP (DistributedDataParallel) 通过实现模型并行和数据并行实现训练加速。 使用 DDP 的程序需要生成多个进程并且为每个进程创建一个 DDP 实例,他们之间通过 torch.distributed 库同步。
DeepSpeed 是微软开发的分布式训练引擎,并提供ZeRO(Zero Redundancy Optimizer)、offload、Sparse Attention、1 bit Adam、流水线并行等优化技术。 您可以根据任务需求与设备选择使用。
FSDP 通过全切片数据并行技术(Fully Sharded Data Parallel)来处理更多更大的模型。在 DDP 中,每张 GPU 都各自保留了一份完整的模型参数和优化器参数。而 FSDP 切分了模型参数、梯度与优化器参数,使得每张 GPU 只保留这些参数的一部分。 除了并行技术之外,FSDP 还支持将模型参数卸载至CPU,从而进一步降低显存需求。
| 引擎 | 数据切分 | 模型切分 | 优化器切分 | 参数卸载 |
|---|---|---|---|---|
| DDP | 支持 | 不支持 | 不支持 | 不支持 |
| DeepSpeed | 支持 | 支持 | 支持 | 支持 |
| FSDP | 支持 | 支持 | 支持 | 支持 |
NativeDDP
NativeDDP 是 PyTorch 提供的一种分布式训练方式,您可以通过以下命令启动训练:
单机多卡
llamafactory-cli
使用 llamafactory-cli 启动 NativeDDP 引擎。
FORCE_TORCHRUN=1 llamafactory-cli train examples/train_full/llama3_full_sft_ds3.yaml
如果 CUDA_VISIBLE_DEVICES 没有指定,则默认使用所有GPU。如果需要指定GPU,例如第0、1个GPU,可以使用:
FORCE_TORCHRUN=1 CUDA_VISIBLE_DEVICES=0,1 llamafactory-cli train config/config1.yaml
torchrun
使用 torchrun 指令启动 NativeDDP 引擎进行单机多卡训练。下面提供一个示例:
torchrun --standalone --nnodes=1 --nproc-per-node=8 src/train.py \
--stage sft \
--model_name_or_path meta-llama/Meta-Llama-3-8B-Instruct \
--do_train \
--dataset alpaca_en_demo \
--template llama3 \
--finetuning_type lora \
--output_dir saves/llama3-8b/lora/ \
--overwrite_cache \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--logging_steps 100 \
--save_steps 500 \
--learning_rate 1e-4 \
--num_train_epochs 2.0 \
--plot_loss \
--bf16
accelerate
使用 accelerate 指令启动进行单机多卡训练。
首先运行以下命令,根据需求回答一系列问题后生成配置文件:
accelerate config
下面提供一个示例配置文件:
# accelerate_singleNode_config.yaml
compute_environment: LOCAL_MACHINE
debug: true
distributed_type: MULTI_GPU
downcast_bf16: 'no'
enable_cpu_affinity: false
gpu_ids: all
machine_rank: 0
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 8
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
通过运行以下指令开始训练:
accelerate launch \
--config_file accelerate_singleNode_config.yaml \
src/train.py training_config.yaml
多机多卡
llamafactory-cli
FORCE_TORCHRUN=1 NNODES=2 NODE_RANK=0 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 \
llamafactory-cli train examples/train_lora/llama3_lora_sft.yamlFORCE_TORCHRUN=1 NNODES=2 NODE_RANK=1 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 \
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
| 变量名 | 介绍 |
|---|---|
| FORCE_TORCHRUN | 是否强制使用torchrun |
| NNODES | 节点数量 |
| NODE_RANK | 各个节点的rank。 |
| MASTER_ADDR | 主节点的地址。 |
| MASTER_PORT | 主节点的端口。 |
torchrun
使用 torchrun 指令启动 NativeDDP 引擎进行多机多卡训练。
torchrun --master_port 29500 --nproc_per_node=8 --nnodes=2 --node_rank=0 \
--master_addr=192.168.0.1 train.py
torchrun --master_port 29500 --nproc_per_node=8 --nnodes=2 --node_rank=1 \
--master_addr=192.168.0.1 train.py
accelerate
使用 accelerate 指令启动进行多机多卡训练。
首先运行以下命令,根据需求回答一系列问题后生成配置文件:
accelerate config
下面提供一个示例配置文件:
# accelerate_multiNode_config.yaml
compute_environment: LOCAL_MACHINE
debug: true
distributed_type: MULTI_GPU
downcast_bf16: 'no'
enable_cpu_affinity: false
gpu_ids: all
machine_rank: 0
main_process_ip: '192.168.0.1'
main_process_port: 29500
main_training_function: main
mixed_precision: fp16
num_machines: 2
num_processes: 16
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
您可以通过运行以下指令开始训练:
accelerate launch \
--config_file accelerate_multiNode_config.yaml \
train.py llm_config.yaml
DeepSpeed
DeepSpeed 是由微软开发的一个开源深度学习优化库,旨在提高大模型训练的效率和速度。在使用 DeepSpeed 之前,需要先估计训练任务的显存大小,再根据任务需求与资源情况选择合适的 ZeRO 阶段。
ZeRO-1: 仅划分优化器参数,每个GPU各有一份完整的模型参数与梯度。ZeRO-2: 划分优化器参数与梯度,每个GPU各有一份完整的模型参数。ZeRO-3: 划分优化器参数、梯度与模型参数。
简单来说:从 ZeRO-1 到 ZeRO-3,阶段数越高,显存需求越小,但是训练速度也依次变慢。此外,设置 offload_param=cpu 参数会大幅减小显存需求,但会极大地使训练速度减慢。因此,如果有足够的显存, 应当使用 ZeRO-1,并且确保 offload_param=none。
LLaMA-Factory 提供了使用不同阶段的 DeepSpeed 配置文件的示例。包括:
- ZeRO-0 (不开启)
- ZeRO-2
- ZeRO-2+offload
- ZeRO-3
- ZeRO-3+offload
备注: https://huggingface.co/docs/transformers/deepspeed 提供了更为详细的介绍。
单机多卡
llamafactory-cli
使用 llamafactory-cli 启动 DeepSpeed 引擎进行单机多卡训练。
FORCE_TORCHRUN=1 llamafactory-cli train examples/train_full/llama3_full_sft_ds3.yaml
为了启动 DeepSpeed 引擎,配置文件中 deepspeed 参数指定了 DeepSpeed 配置文件的路径:
deepspeed: examples/deepspeed/ds_z3_config.json
deepspeed
使用 deepspeed 指令启动 DeepSpeed 引擎进行单机多卡训练。
deepspeed --include localhost:1 your_program.py <normal cl args> --deepspeed ds_config.json
下面是一个例子:
deepspeed --num_gpus 8 src/train.py \
--deepspeed examples/deepspeed/ds_z3_config.json \
--stage sft \
--model_name_or_path meta-llama/Meta-Llama-3-8B-Instruct \
--do_train \
--dataset alpaca_en \
--template llama3 \
--finetuning_type full \
--output_dir saves/llama3-8b/lora/full \
--overwrite_cache \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 500 \
--learning_rate 1e-4 \
--num_train_epochs 2.0 \
--plot_loss \
--bf16
备注:
使用 deepspeed 指令启动 DeepSpeed 引擎时无法使用 CUDA_VISIBLE_DEVICES 指定GPU。而需要:
deepspeed --include localhost:1 your_program.py <normal cl args> --deepspeed ds_config.json
--include localhost:1 表示只是用本节点的gpu1。
多机多卡
LLaMA-Factory 支持使用 DeepSpeed 的多机多卡训练,通过以下命令启动:
FORCE_TORCHRUN=1 NNODES=2 NODE_RANK=0 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 llamafactory-cli train examples/train_lora/llama3_lora_sft_ds3.yaml
FORCE_TORCHRUN=1 NNODES=2 NODE_RANK=1 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 llamafactory-cli train examples/train_lora/llama3_lora_sft_ds3.yaml
deepspeed
使用 deepspeed 指令来启动多机多卡训练。
deepspeed --num_gpus 8 --num_nodes 2 --hostfile hostfile --master_addr hostname1 --master_port=9901 \
your_program.py <normal cl args> --deepspeed ds_config.json
备注
关于hostfile:
hostfile的每一行指定一个节点,每行的格式为<hostname> slots=<num_slots>, 其中 <hostname> 是节点的主机名, <num_slots> 是该节点上的GPU数量。下面是一个例子: … code-block:
worker-1 slots=4
worker-2 slots=4
在 https://www.deepspeed.ai/getting-started/ 了解更多。
如果没有指定 hostfile 变量, DeepSpeed 会搜索 /job/hostfile 文件。如果仍未找到,那么 DeepSpeed 会使用本机上所有可用的GPU。
accelerate
使用 accelerate 指令启动 DeepSpeed 引擎。 首先通过以下命令生成 DeepSpeed 配置文件:
accelerate config
下面提供一个配置文件示例:
# deepspeed_config.yaml
compute_environment: LOCAL_MACHINE
debug: false
deepspeed_config:deepspeed_multinode_launcher: standardgradient_accumulation_steps: 8offload_optimizer_device: noneoffload_param_device: nonezero3_init_flag: falsezero_stage: 3
distributed_type: DEEPSPEED
downcast_bf16: 'no'
enable_cpu_affinity: false
machine_rank: 0
main_process_ip: '192.168.0.1'
main_process_port: 29500
main_training_function: main
mixed_precision: fp16
num_machines: 2
num_processes: 16
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
随后,您可以使用以下命令启动训练:
accelerate launch \
--config_file deepspeed_config.yaml \
train.py llm_config.yaml
DeepSpeed 配置文件
ZeRO-0
### ds_z0_config.json
{"train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","gradient_accumulation_steps": "auto","gradient_clipping": "auto","zero_allow_untested_optimizer": true,"fp16": {"enabled": "auto","loss_scale": 0,"loss_scale_window": 1000,"initial_scale_power": 16,"hysteresis": 2,"min_loss_scale": 1},"bf16": {"enabled": "auto"},"zero_optimization": {"stage": 0,"allgather_partitions": true,"allgather_bucket_size": 5e8,"overlap_comm": true,"reduce_scatter": true,"reduce_bucket_size": 5e8,"contiguous_gradients": true,"round_robin_gradients": true}
}
ZeRO-2
只需在 ZeRO-0 的基础上修改 zero_optimization 中的 stage 参数即可。
### ds_z2_config.json
{..."zero_optimization": {"stage": 2,...}
}
ZeRO-2+offload
只需在 ZeRO-0 的基础上在 zero_optimization 中添加 offload_optimizer 参数即可。
### ds_z2_offload_config.json
{..."zero_optimization": {"stage": 2,"offload_optimizer": {"device": "cpu","pin_memory": true},...}
}
ZeRO-3
只需在 ZeRO-0 的基础上修改 zero_optimization 中的参数。
### ds_z3_config.json
{..."zero_optimization": {"stage": 3,"overlap_comm": true,"contiguous_gradients": true,"sub_group_size": 1e9,"reduce_bucket_size": "auto","stage3_prefetch_bucket_size": "auto","stage3_param_persistence_threshold": "auto","stage3_max_live_parameters": 1e9,"stage3_max_reuse_distance": 1e9,"stage3_gather_16bit_weights_on_model_save": true}
}
ZeRO-3+offload
只需在 ZeRO-3 的基础上添加 zero_optimization 中的 offload_optimizer 和 offload_param 参数即可。
### ds_z3_offload_config.json
{..."zero_optimization": {"stage": 3,"offload_optimizer": {"device": "cpu","pin_memory": true},"offload_param": {"device": "cpu","pin_memory": true},...}
}
备注
https://www.deepspeed.ai/docs/config-json/ 提供了关于deepspeed配置文件的更详细的介绍。
FSDP
PyTorch 的全切片数据并行技术 FSDP (Fully Sharded Data Parallel)能处理更多更大的模型。LLaMA-Factory支持使用 FSDP 引擎进行分布式训练。
FSDP 的参数 ShardingStrategy 的不同取值决定了模型的划分方式:
FULL_SHARD: 将模型参数、梯度和优化器状态都切分到不同的GPU上,类似ZeRO-3。SHARD_GRAD_OP: 将梯度、优化器状态切分到不同的GPU上,每个GPU仍各自保留一份完整的模型参数。类似ZeRO-2。NO_SHARD: 不切分任何参数。类似ZeRO-0。
llamafactory-cli
只需根据需要修改 examples/accelerate/fsdp_config.yaml 以及 examples/extras/fsdp_qlora/llama3_lora_sft.yaml ,文件然后运行以下命令即可启动 FSDP+QLoRA 微调:
bash examples/extras/fsdp_qlora/train.sh
accelerate
此外,也可以使用 accelerate启动 FSDP引擎, 节点数与 GPU数可以通过 num_machines 和 num_processes 指定。对此,Huggingface 提供了便捷的配置功能。 只需运行:
accelerate config
根据提示回答一系列问题后,我们就可以生成 FSDP 所需的配置文件。
当然也可以根据需求自行配置 fsdp_config.yaml 。
### /examples/accelerate/fsdp_config.yaml
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAPfsdp_backward_prefetch: BACKWARD_PREfsdp_forward_prefetch: falsefsdp_cpu_ram_efficient_loading: truefsdp_offload_params: true # offload may affect training speedfsdp_sharding_strategy: FULL_SHARDfsdp_state_dict_type: FULL_STATE_DICTfsdp_sync_module_states: truefsdp_use_orig_params: true
machine_rank: 0
main_training_function: main
mixed_precision: fp16 # or bf16
num_machines: 1 # the number of nodes
num_processes: 2 # the number of GPUs in all nodes
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
备注
请确保 num_processes 和实际使用的总GPU数量一致
随后,可以使用以下命令启动训练:
accelerate launch \
--config_file fsdp_config.yaml \
src/train.py llm_config.yaml
警告
不要在 FSDP+QLoRA 中使用 GPTQ/AWQ 模型
量化
PTQ
后训练量化(PTQ, Post-Training Quantization)一般是指在模型预训练完成后,基于校准数据集 (calibration dataset)确定量化参数进而对模型进行量化。
GPTQ
GPTQ(Group-wise Precision Tuning Quantization)是一种静态的后训练量化技术。”静态”指的是预训练模型一旦确定,经过量化后量化参数不再更改。GPTQ 量化技术将 fp16 精度的模型量化为 4-bit ,在节省了约 75% 的显存的同时大幅提高了推理速度。 为了使用GPTQ量化模型,您需要指定量化模型名称或路径,例如 model_name_or_path: TechxGenus/Meta-Llama-3-8B-Instruct-GPTQ
QAT
在训练感知量化(QAT, Quantization-Aware Training)中,模型一般在预训练过程中被量化,然后又在训练数据上再次微调,得到最后的量化模型。
AWQ
AWQ(Activation-Aware Layer Quantization)是一种静态的后训练量化技术。其思想基于:有很小一部分的权重十分重要,为了保持性能这些权重不会被量化。 AWQ 的优势在于其需要的校准数据集更小,且在指令微调和多模态模型上表现良好。 为了使用 AWQ 量化模型,您需要指定量化模型名称或路径,例如 model_name_or_path: TechxGenus/Meta-Llama-3-8B-Instruct-AWQ
AQLM
AQLM(Additive Quantization of Language Models)作为一种只对模型权重进行量化的PTQ方法,在 2-bit 量化下达到了当时的最佳表现,并且在 3-bit 和 4-bit 量化下也展示了性能的提升。 尽管 AQLM 在模型推理速度方面的提升并不是最显著的,但其在 2-bit 量化下的优异表现意味着您可以以极低的显存占用来部署大模型。
OFTQ
OFTQ(On-the-fly Quantization)指的是模型无需校准数据集,直接在推理阶段进行量化。OFTQ是一种动态的后训练量化技术。 在使用OFTQ量化方法时,需要指定预训练模型、指定量化方法 quantization_method 和指定量化位数 quantization_bit 下面提供了一个使用bitsandbytes量化方法的配置示例:
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
quantization_bit: 4
quantization_method: bitsandbytes # choices: [bitsandbytes (4/8), hqq (2/3/4/5/6/8), eetq (8)]
bitsandbytes
区别于 GPTQ, bitsandbytes 是一种动态的后训练量化技术。bitsandbytes 使得大于 1B 的语言模型也能在 8-bit 量化后不过多地损失性能。 经过bitsandbytes 8-bit 量化的模型能够在保持性能的情况下节省约50%的显存。
HQQ
依赖校准数据集的方法往往准确度较高,不依赖校准数据集的方法往往速度较快。HQQ(Half-Quadratic Quantization)希望能在准确度和速度之间取得较好的平衡。作为一种动态的后训练量化方法,HQQ无需校准阶段, 但能够取得与需要校准数据集的方法相当的准确度,并且有着极快的推理速度。
EETQ
EETQ(Easy and Efficient Quantization for Transformers)是一种只对模型权重进行量化的PTQ方法。具有较快的速度和简单易用的特性。
配置修改
// TODO
)



智能体在测试时的计算量)

)







--Linux安装RabbitMQ)




