文章目录
- 一、Dataset 与 DataLoader 功能介绍
- 抽象类Dataset的作用
- DataLoader 作用
- 两者关系
- 二、`torch.utils.data.DataLoader`
- 代码示例
- 常用参数图示
- num_workers
- 设置多少合适
- 数据加载子进程如何并行的
- pin_memory
- sampler
- 两种sampler
- 顺序采样 SequentialSampler
- 随机采样 RandomSampler
- sampler 与 shuffle 的互斥
- RandomSampler 与 shuffle=True 的区别
- batch_sampler
- `BatchSampler` 与其他参数的互斥
- 使用举例:
- collate_fn
- `collate_fn` 函数的作用
- 默认 collate_fn 函数
- 自定义 collate_fn 函数
一、Dataset 与 DataLoader 功能介绍
抽象类Dataset的作用
简单来说,就是将原始数据(可能是图片、文本、音频等各种格式)整理成模型可以处理的格式,为后续的数据加载和处理做准备。功能是定义数据集的基本属性和数据获取方式。
- 初始化数据路径:在
Dataset类的__init__方法中,通常会初始化数据存放的路径,以及一些数据预处理的操作,比如指定图片数据集图片所在文件夹路径,文本数据集文本文件路径等 。包含 加载数据/读取数据、预处理数据、图像增强 等一系列操作 - 获取单个样本及其标签:通过实现
__getitem__方法,根据给定的索引(dataloader返回的),返回相应的数据样本和对应的标签。例如在图片分类任务中,给定索引后,返回该索引对应的图片数据(经过预处理,如调整尺寸、归一化等)以及图片的类别标签。 - 统计样本数量:通过实现
__len__方法,返回数据集中样本的总数,方便在训练和评估过程中知道数据规模 。
DataLoader 作用
DataLoader是在Dataset的基础上,提供了一种更加高效、便捷地加载数据的方式,它可以将Dataset返回的单个样本,按照指定的方式进行打包(如组成batch)、打乱顺序等操作,从而满足模型训练和评估的需求。
-
创建数据批次,指定数据打包输出规则:通过
batch_size参数,将Dataset中的单个样本打包成一个个批次(batch)的数据。collate_fn指定如何从NNN张训练集选出一个batch的Nbatch_size\frac{N}{batch\_size}batch_sizeN张图片。- 例如
batch_size=32,那么DataLoader每次会从Dataset中取出32个样本组成一个batch。每次迭代,返回的是 一个batch 的数据
-
自定义数据采样,指定数据迭代读取规则:
- 一般使用自定义的采样器(
Sampler),实现对数据的特殊采样方式,比如分层采样(在类别不均衡的数据集中,保证每个batch中各类别的样本比例与原始数据集相似)等。 - dataset对象是dataloader的一个参数,通过dataset让dataloader知道训练集一共多少图片,从而知道共跌代多少次。
- 一般使用自定义的采样器(
-
数据打乱:通过
shuffle参数设置是否在每个epoch开始时打乱数据顺序,这样可以避免模型在训练时对数据产生特定的依赖,有助于模型学习到更通用的特征,提高模型的泛化能力 。 -
多进程加载:通过
num_workers参数设置多进程加载数据,从而加快数据加载速度,尤其是在数据量较大、数据预处理较为复杂的情况下,多进程可以充分利用CPU资源,减少数据加载时间,避免数据加载成为训练过程中的瓶颈 。
两者关系
-
Dataset是数据的基础容器,定义了如何获取数据集中的单个样本; -
而
DataLoader则是Dataset的上层应用,负责按照特定规则(如批量处理、打乱顺序等)从Dataset中高效地加载数据,供模型进行训练、验证和测试等操作。 -
可以说,
Dataset是数据的来源和基本操作接口,DataLoader则是为了更好地适配模型训练需求,对Dataset的数据进行进一步处理和组织的工具。
二、torch.utils.data.DataLoader
torch.utils.data.DataLoader类有很多参数,可查看Pytorch官方文档:torch.utils.data.DataLoader
代码示例
from torch.utils.data import DataLoaderdata_loader = DataLoader(dataset, batch_size=1, shuffle=None, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False,timeout=0)
dataset:加载数据的数据集batch_size:每批返回的数据量,默认值是 1shuffle:是否在每个 epoch 内将数据打乱顺序。默认值为Falsesampler:从数据集中提取的样本序列。可以用来自定义样本的采样策略。默认值为Nonebatch_sampler:与sampler类似,但是一次返回一个 batch 的索引,用于自定义 batch。它与batch_size、shuffle、sampler和drop_last互斥num_workers:用于数据加载的子进程数。0 表示主进程加载。默认值为0collate_fn:用于指定如何组合样本数据。如果为None,那么将默认使用默认的组合方法drop_last:如果数据集的大小不能被batch_size整除,那么是否丢弃最后一个数据批次。默认值为Falsepin_memory:将数据固定在内存的锁页内存中,加速数据读取的速度。默认值为Falsetimeout:等待 collect 一个 batch 的数据的超时时间。默认为 0,表示一直等待
常用参数图示
对于常用的参数,见这个数据流向的流程图:
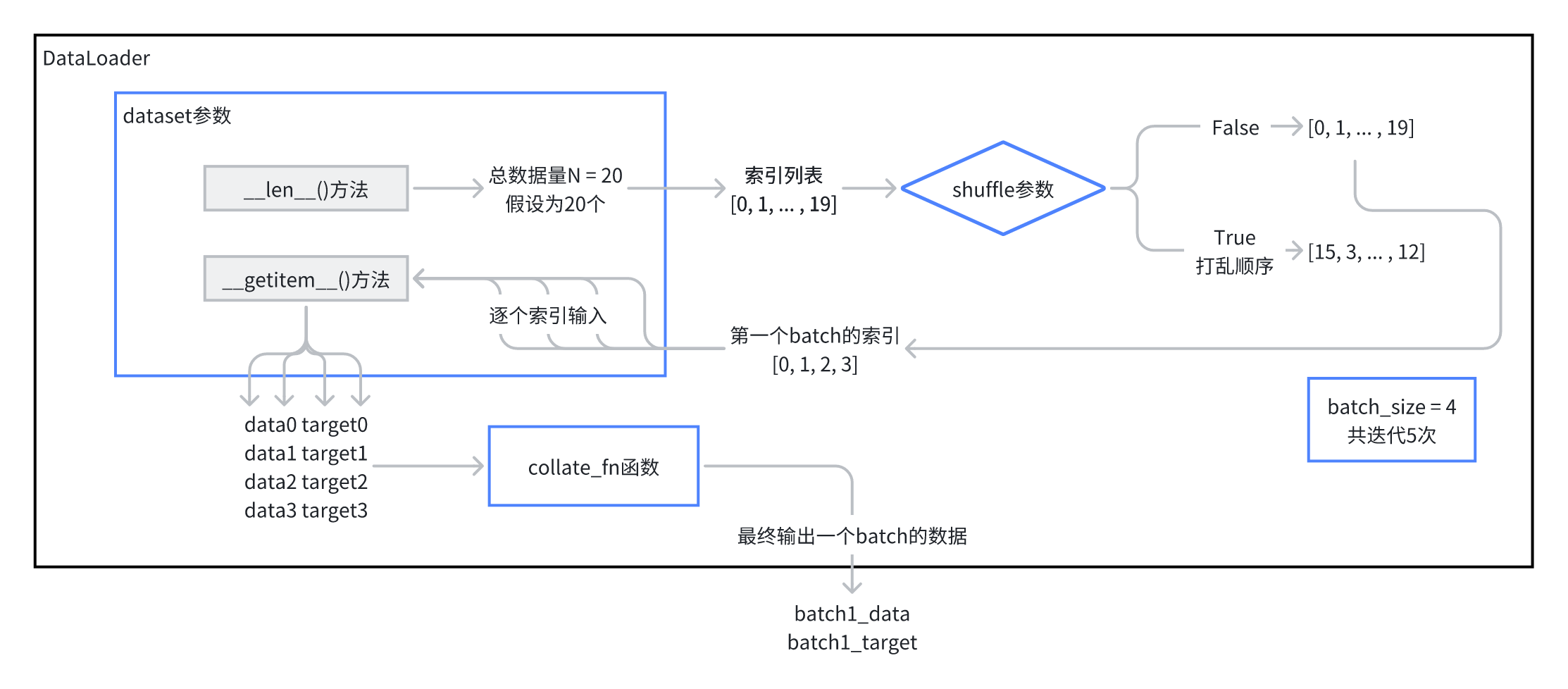
dataset是Dataset类的对象,在Dataloader中有 2个作用 :
- 通过
dataset的__len__方法,dataloader可以知道数据量,从而根据数据量生成相应的索引列表 - dataloader 会将索引,传给
dataset的__getitem__方法,__getitem__方法会对数据进行处理,并返回处理好的数据
Dataset 与 Dataloader 的内部交互细节 举例
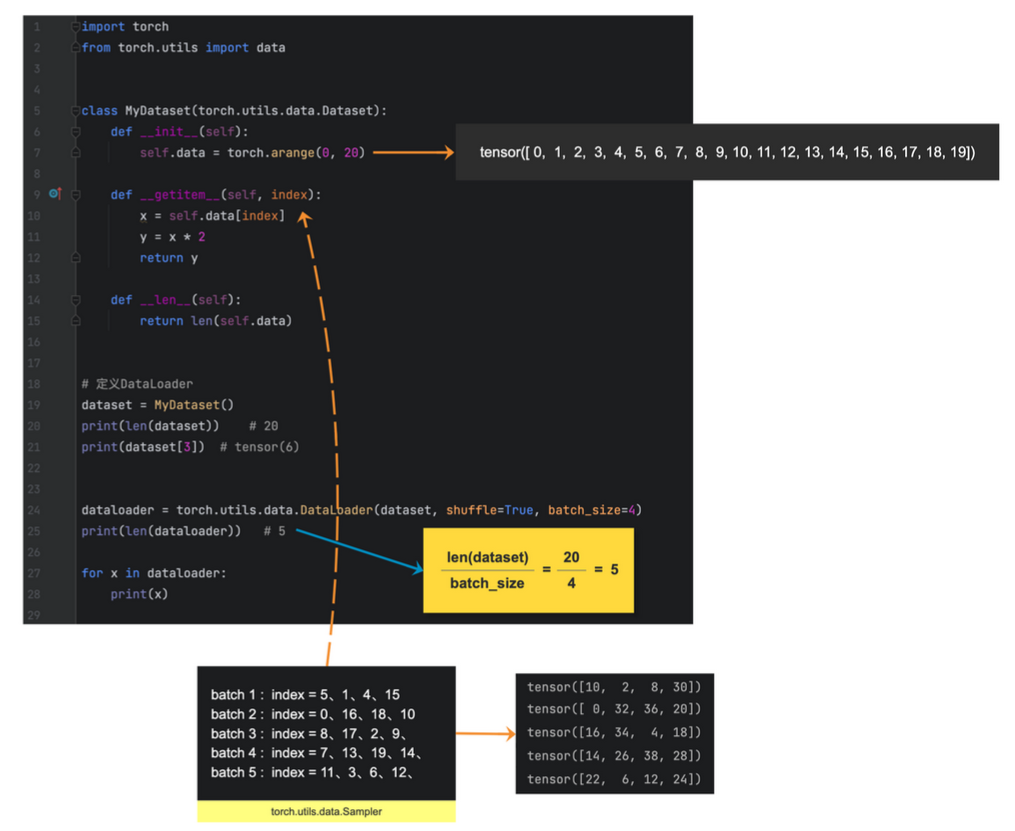
num_workers
设置多少合适
参数 num_workers 参数用于指定加载数据的子进程的数量,这些子进程可以并行地加载数据。
num_workers=0:(默认值) 表示只有主进程去加载batch数据,这个可能会是一个瓶颈,处理比较慢。num_workers=1:表示只有一个子进程加载数据,主进程不参与,这仍可能导致速度慢。num_workers>0:表示指定数量的子进程并行加载数据,且主进程不参与。
增加 num_workers 可以提高加载速度,但也会增加 CPU 和 内存的使用。
通常建议将 num_workers 参数设置为等于或小于 CPU 核心数,以有效平衡数据加载效率和系统资源占用率。
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
batch_size = 16
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
train_dataloader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,num_workers=nw,shuffle=True,pin_memory=True,collate_fn=collate_fn)
数据加载子进程如何并行的
一个进程仅处理一个 batch 的数据,假设设置 num_workers=2 ,则 进程1 处理一个 batch 的数据,进程2 处理另一个 batch 的数据。

并行工作流程:
- 初始化:创建
DataLoader实例时,通过参数num_workers指定并行加载的子进程数量 - 子进程加载数据:子进程独立于主进程运行,每个子进程的拿着一个
batch的索引列表,并行地到dataset的getitem中预处理数据 - 数据准备:处理好的数据,放入缓冲区以备主进程请求
- 数据请求:主进程在
for循环中请求下一个batch - 数据传输:主进程请求数据时,从缓冲区获取已经准备好的
batch - 循环迭代:主进程不断请求数据,子进程并行的处理后续的
batch数据
pin_memory
-
若设置
pin_memory=True,数据会被加载到CPU的内存(Pinned Memory)中,从而提高数据从 CPU 到 GPU 的传输效率。这是因为**锁定的内存(pinned memory)**可以更快地被复制到GPU,因为它是连续的,并且已经准备好被传输。 -
若设置
pin_memory=False,则数据是被存放在**可分页内存(pageable memory)**中,当我们想要把数据从 cpu 移动到 gpu 上(执行.to('cuda')的时候), 需要先将数据从分页内存中移动到锁页内存中,然后再传输到 GPU 上
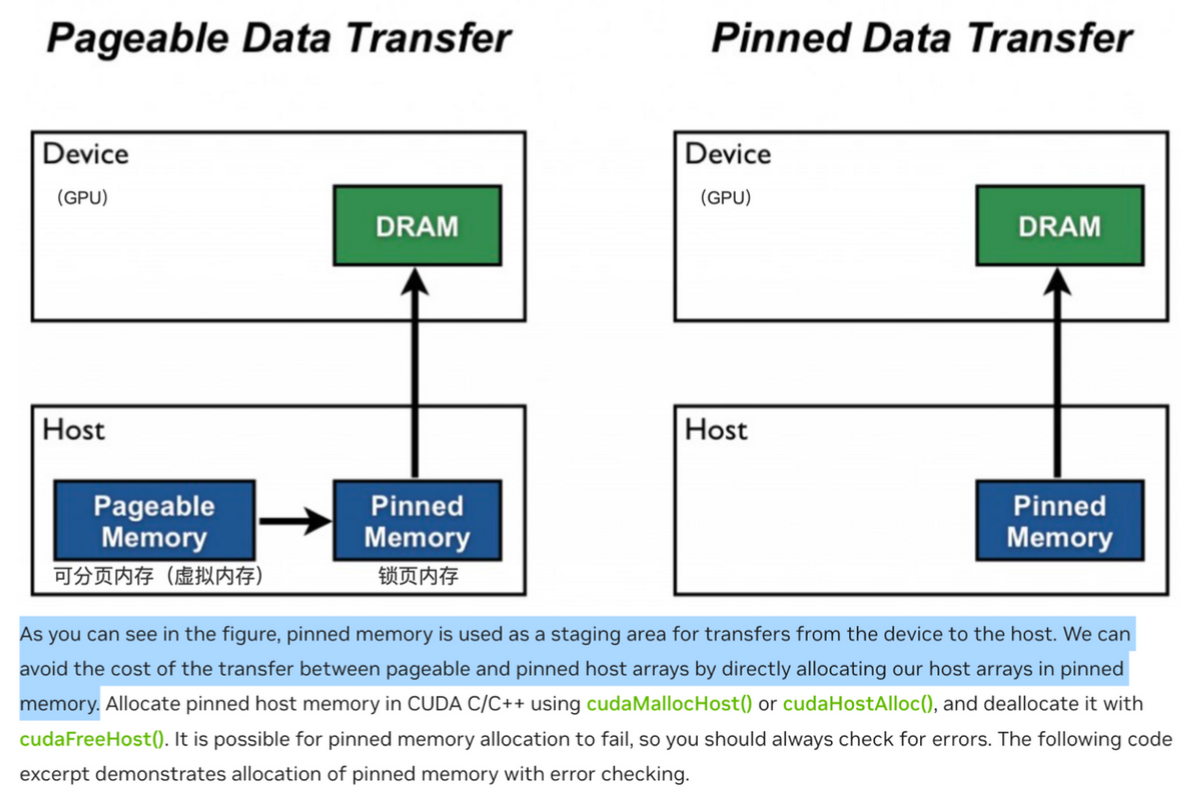
参数设置建议
- 设置
pin_memory=True,节省的是 将数据从 分页内存移动到锁页内存中 的这段时间。 - 如果你的训练完全在CPU上进行,不涉及GPU,那就没有必要设置
pin_memory=True。 - 因为在这种情况下,数据不需要被传输到GPU,因此不需要使用锁定内存来加速这一过程。可以将
pin_memory设置为False,以简化内存管理。
sampler
采样器sampler,控制数据集索引顺序。
torch.utils.data.DataLoader 的参数 sampler 参数接收的通常是一个实现了 Sampler 接口的对象,比如 :
sampler = SequentialSampler(dataset) # 使用 SequentialSampler
dataloader = DataLoader(dataset, batch_size=8, sampler=sampler)
通过 sampler 对象来控制数据集的索引顺序,从而影响数据从数据集中的抽取方式。
两种sampler
第一种为pytorch 提供的,可以直接使用的几种 sampler,
顺序和随机比较常用。
# 顺序抽样,按照数据集的顺序逐个抽取样本
torch.utils.data.sampler.SequentialSampler()# 随机抽样,数据集中的样本以随机顺序被抽取
torch.utils.data.sampler.RandomSampler()# 从指定的样本索引子集内进行随机抽样
torch.utils.data.sampler.SubsetRandomSampler()# 根据样本的权重随机抽样,不同样本有不同的抽样概率
torch.utils.data.sampler.WeightedRandomSampler()
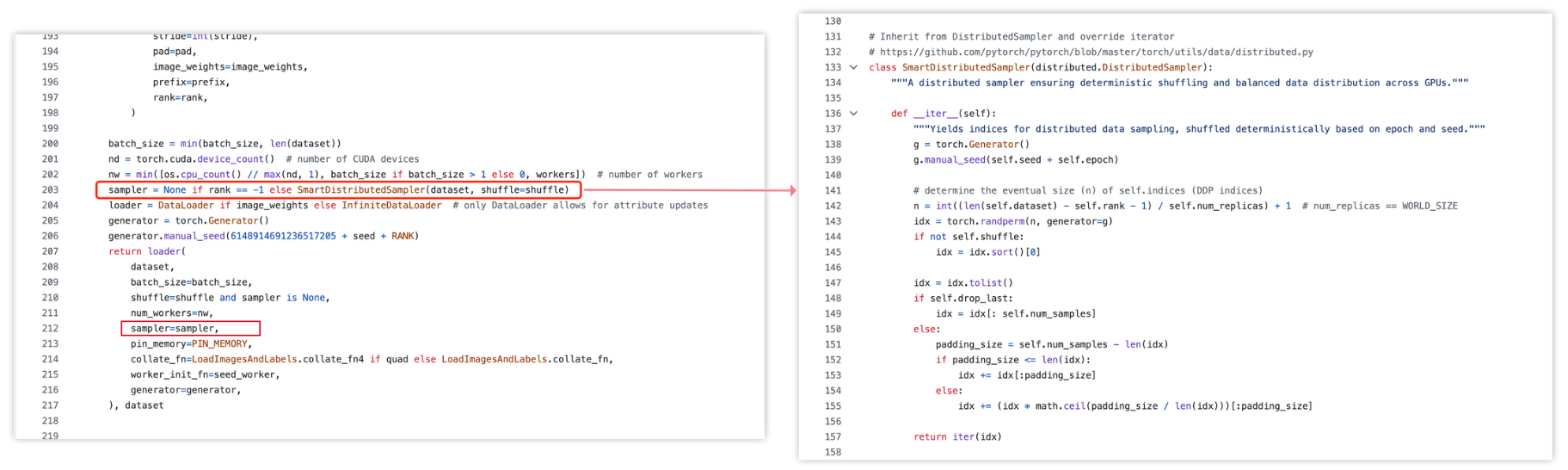
可以自定义 sampler,比如以下是 yolov5 中自定义的 SmartDistributedSampler的sampler类
参数 sampler 有一部分功能,是和参数 shuffle 是重叠的,这时用shuffle简单:
- 顺序采样
SequentialSampler效果等价于shuffle=False,不打乱顺序。 - 随机采样
RandomSampler效果等价于shuffle=True
Pytorch 提供 sampler 参数,主要是为提升灵活性,支持用户更灵活地自定义,设计数据加载的方式
下面我们主要介绍 SequentialSampler 和 RandomSampler ,只要大家通过 SequentialSampler 、 RandomSampler 掌握了 sampler 的工作原理,便可以愉快的自定义的去设计 sampler 了。
顺序采样 SequentialSampler
作用 :接收一个 Dataset 对象,输出数据包中样本量的顺序索引,代码小测试:
import torch.utils.data.sampler as sampler# 模拟真实数据
data = list([17, 22, 3, 41, 8])# 实例化sampler对象
seq_sampler = sampler.SequentialSampler(data_source=data)for index in seq_sampler:print("index: {}".format(index))
seq_sampler为一个索引列表,每一次迭代都返回一个索引值。
Pytorch内部源码实现:
class SequentialSampler(Sampler):data_source: Sizeddef __init__(self, data_source: Sized) -> None:self.data_source = data_sourcedef __iter__(self) -> Iterator[int]:return iter(range(len(self.data_source)))def __len__(self) -> int:return len(self.data_source)
__init__接收参数:Dataset对象__iter__调用len方法获取数据集大小,再用range方法生成索引列表,返回一个可迭代对象(返回的是索引值),因为SequentialSampler是顺序采样,所以返回的索引是顺序数值序列。__len__返回dataset中数据个数
这里再给一个Sampler和Dataset,DataLoader结合使用的例子:
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.sampler import SequentialSamplerclass myDataset(Dataset):def __init__(self, data):self.data = datadef __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]# 示例数据 :0 到 19 的整数,所以数据值和索引值一样。
data = [i for i in range(20)]
dataset = myDataset(data)# 使用 SequentialSampler 实例化对象
sampler = SequentialSampler(dataset)# 创建 DataLoader
dataloader = DataLoader(dataset, batch_size=8, sampler=sampler)# 使用 DataLoader 迭代数据
for data in dataloader:print(data)

随机采样 RandomSampler
作用 :接收一个 Dataset 对象,输出数据包中样本量的随机索引 (可指定是否可重复)
import torch.utils.data.sampler as samplerdata = list([17, 22, 3, 41, 8])
seq_sampler = sampler.RandomSampler(data_source=data)for index in seq_sampler:print("index: {}".format(index))
Pytorch源码(删减版本):
class RandomSampler(Sampler):def __init__(self, data_source, replacement=False, num_samples=None):self.data_source = data_sourceself.replacement = replacementself._num_samples = num_samplesdef num_samples(self):if self._num_samples is None:return len(self.data_source)return self._num_samplesdef __len__(self):return self.num_samplesdef __iter__(self):n = len(self.data_source)if self.replacement:# 生成的随机数是可能重复的return iter(torch.randint(high=n, size=(self.num_samples,), dtype=torch.int64).tolist())# 生成的随机数是不重复的return iter(torch.randperm(n).tolist())
__init__参数:data_source(Dataset):采样的Dataset对象replacement(bool):如果为True,则抽取的样本是有放回的。默认为Falsenum_samples(int):抽取样本的数量,默认是len(dataset)。当replacement是True时,应被实例化
__iter__返回一个可迭代对象(返回的是索引),因为RandomSampler是随机采样,所以返回的索引是随机的数值序列(当replacement=False时,生成的排列是无重复的)__len__返回dataset中样本量
从源码中可以看到,随机采样和顺序采样的区别在于生成索引时用了torch.randperm(n)方法。
举例:
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.sampler import RandomSamplerclass myDataset(Dataset):def __init__(self, data):self.data = datadef __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]# 示例数据 :0 到 19 的整数
data = [i for i in range(20)]
dataset = myDataset(data)# 使用 SequentialSampler
sampler = RandomSampler(dataset)# 创建 DataLoader
dataloader = DataLoader(dataset, batch_size=8, sampler=sampler)# 使用 DataLoader 迭代数据
for data in dataloader:print(data)

sampler 与 shuffle 的互斥
参数 sampler 与参数 shuffle 是互斥的,不要同时使用 sampler 和 shuffle
- 当同时设置了
shuffle与sampler,且shuffle=True,会报错 - 当同时设置了
shuffle与sampler,且shuffle=False(就是默认值),具体逻辑按照sampler
因为 shuffle 的默认值为 False,所以代码会兼容 shuffle 等于默认值 False 的情况
RandomSampler 与 shuffle=True 的区别
效果完全没有区别,只是实现方式不一样。
shuffle=True的实现方式:在每个epoch开始时将整个数据集打乱,然后按照打乱后的顺序划分batch,再按照batch_size个数依次提取数据sampler.BatchSampler(random_sampler)的实现方式:(数据不会打乱)- step 1、
RandomSampler会生成随机的索引。 - step 2、
BatchSampler根据上面随机出来的索引生成batch组。 - step 3、拿着每个
batch组的索引去取数据
- step 1、
相同点
- 每个
epoch都会重新打乱 - 都不会重复采样,除非你通过参数指定了可以重复采样
其他说明
3. shuffle=True 的性能更高一些,而 BatchSampler 灵活性更高,因为你可以通过 BatchSampler 设计更复杂的采样方式
4. 在 Dataloader 中使用 batch_sampler 的常见目的之一,是为了兼容 DistributedSampler,比如:
if args.distributed:sampler_train = DistributedSampler(dataset_train)sampler_val = DistributedSampler(dataset_val, shuffle=False)
else:sampler_train = torch.utils.data.RandomSampler(dataset_train)sampler_val = torch.utils.data.SequentialSampler(dataset_val)batch_sampler_train = torch.utils.data.BatchSampler(sampler_train, args.batch_size, drop_last=True)data_loader_train = DataLoader(dataset_train,batch_sampler=batch_sampler_train,collate_fn=utils.collate_fn,)
data_loader_val = DataLoader(dataset_val,args.batch_size,sampler=sampler_val,drop_last=False,collate_fn=utils.collate_fn,)
跑个小例子,看一下两者都是随机的效果:
import torch
import torch.utils.data.sampler as sampler
from torch.utils.data import Dataset, DataLoaderclass MyDataset(Dataset):def __init__(self):self.data = [1, 2, 3, 4, 5]def __len__(self):return len(self.data)def __getitem__(self, index):return self.data[index]dataset = MyDataset()# =============================================
random_sampler = sampler.RandomSampler(data_source=dataset)
batch_sampler = sampler.BatchSampler(random_sampler, batch_size=2, drop_last=False)
dataloader1 = DataLoader(dataset, batch_sampler=batch_sampler)for epoch in range(3):for index, data in enumerate(dataloader1):print(index, data)
print('*'*30)# =============================================
dataloader2 = DataLoader(dataset, batch_size=2, shuffle=True)for epoch in range(3):for index, data in enumerate(dataloader2):print(index, data)
batch_sampler
torch.utils.data.DataLoaderde 的参数 batch_sample, 接收的一般是 torch.utils.data.BatchSampler 对象,
torch.utils.data.BatchSampler 的作用 : 包装另一个采样器,生成一个小批量索引采样器
torch.utils.data.BatchSampler(sampler, batch_size, drop_last)
接收三个参数,和DataLoader参数重叠了,所以在实例化BatchSampler时,指定了 batch_size和 drop_last,就不需要再在DataLoader中指定,如果重复指定会报错。
sampler: 其他采样器实例batch_size:批量大小drop_last:为True时,如果最后一个batch 采样得到的数据个数小于batch_size,则抛弃最后一个batch的数据
BatchSampler 与其他参数的互斥
如果你在 DataLoader(dataset, batch_sampler=batch_sampler) 中指定了参数 batch_sampler,那么就不能再指定参数 batch_size、shuffle、sampler、和 drop_last 了,他们互斥。
因为:
- 你在生成
torch.utils.data.sampler.BatchSampler()的时候,就已经制定过batch_size、sampler、和drop_last这些参数了, batch_sampler与shuffle作用一致,所以也互斥
比如,如下代码就会报错,因为在 DataLoader 中重复指定了 batch_size
random_sampler = sampler.RandomSampler(data_source=dataset)batch_sampler = sampler.BatchSampler(random_sampler, batch_size=2, drop_last=False)dataloader = DataLoader(dataset, batch_size=2, batch_sampler=batch_sampler)
使用举例:
import torch.utils.data.sampler as sampler
# 用list模拟数据
data = list([17, 22, 3, 41, 8])seq_sampler = sampler.SequentialSampler(data_source=data)
batch_sampler = sampler.BatchSampler(seq_sampler, 2, False )for index in batch_sampler:print(index)
每次迭代获得的是一个batch的索引列表。
Pytorch源码(删减版)
class BatchSampler(Sampler):def __init__(self, sampler, batch_size, drop_last):、self.sampler = samplerself.batch_size = batch_sizeself.drop_last = drop_lastdef __iter__(self):batch = []for idx in self.sampler:batch.append(idx)# 如果采样个数和batch_size相等则本次采样完成if len(batch) == self.batch_size:yield batchbatch = []# for 结束后在不需要剔除不足batch_size的采样个数时返回当前batch if len(batch) > 0 and not self.drop_last:yield batchdef __len__(self):# 在不进行剔除时,数据的长度就是采样器索引的长度if self.drop_last:return len(self.sampler) // self.batch_sizeelse:return (len(self.sampler) + self.batch_size - 1) // self.batch_size
例子:
import torch
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.sampler import SequentialSampler, BatchSamplerclass myDataset(Dataset):def __init__(self, data):self.data = datadef __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]# 示例数据 :# 生成 0 到 19 的整数
data = [i for i in range(20)]
dataset = myDataset(data)# 使用 SequentialSampler 顺序采样
sequential_sampler = SequentialSampler(dataset)# 使用 BatchSampler 将 SequentialSampler 和 batch_size 结合
batch_sampler = BatchSampler(sequential_sampler, batch_size=8, drop_last=False)# 创建 DataLoader,使用 BatchSampler
dataloader = DataLoader(dataset, batch_sampler=batch_sampler)# 使用 DataLoader 迭代数据
for data in dataloader:print(data)

collate_fn
在使用 torch.utils.data.dataset 时,参数 collate_fn 接受一个函数,该函数的函数名通常就为collate_fn
collate_fn 函数的作用
将多个 经过 dataset.getitem() 处理好的 样本数据,组合成一个 batch 的数据。
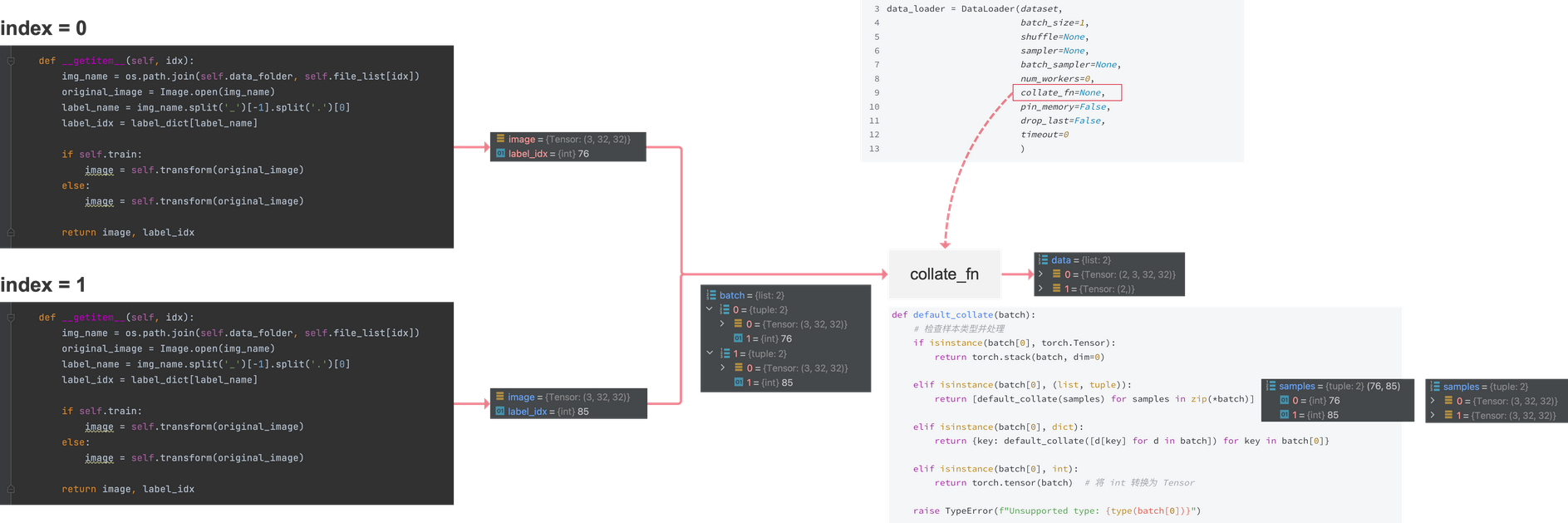
注 :更换 cifar-100 在你本地的路径
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import ostorch.manual_seed(121)
torch.cuda.manual_seed(121)label_dict = {'apple': 0,'aquarium_fish': 1,'baby': 2,'bear': 3,'beaver': 4,'bed': 5,'bee': 6,'beetle': 7,'bicycle': 8,'bottle': 9,'bowl': 10,'boy': 11,'bridge': 12,'bus': 13,'butterfly': 14,'camel': 15,'can': 16,'castle': 17,'caterpillar': 18,'cattle': 19,'chair': 20,'chimpanzee': 21,'clock': 22,'cloud': 23,'cockroach': 24,'couch': 25,'crab': 26,'crocodile': 27,'cup': 28,'dinosaur': 29,'dolphin': 30,'elephant': 31,'flatfish': 32,'forest': 33,'fox': 34,'girl': 35,'hamster': 36,'house': 37,'kangaroo': 38,'keyboard': 39,'lamp': 40,'lawn_mower': 41,'leopard': 42,'lion': 43,'lizard': 44,'lobster': 45,'man': 46,'maple_tree': 47,'motorcycle': 48,'mountain': 49,'mouse': 50,'mushroom': 51,'oak_tree': 52,'orange': 53,'orchid': 54,'otter': 55,'palm_tree': 56,'pear': 57,'pickup_truck': 58,'pine_tree': 59,'plain': 60,'plate': 61,'poppy': 62,'porcupine': 63,'possum': 64,'rabbit': 65,'raccoon': 66,'ray': 67,'road': 68,'rocket': 69,'rose': 70,'sea': 71,'seal': 72,'shark': 73,'shrew': 74,'skunk': 75,'skyscraper': 76,'snail': 77,'snake': 78,'spider': 79,'squirrel': 80,'streetcar': 81,'sunflower': 82,'sweet_pepper': 83,'table': 84,'tank': 85,'telephone': 86,'television': 87,'tiger': 88,'tractor': 89,'train': 90,'trout': 91,'tulip': 92,'turtle': 93,'wardrobe': 94,'whale': 95,'willow_tree': 96,'wolf': 97,'woman': 98,'worm': 99
}def default_collate(batch):# 检查样本类型并处理if isinstance(batch[0], torch.Tensor):return torch.stack(batch, dim=0)elif isinstance(batch[0], (list, tuple)):return [default_collate(samples) for samples in zip(*batch)]elif isinstance(batch[0], dict):return {key: default_collate([d[key] for d in batch]) for key in batch[0]}elif isinstance(batch[0], int):return torch.tensor(batch) # 将 int 转换为 Tensorraise TypeError(f"Unsupported type: {type(batch[0])}")class CustomDataset(Dataset):def __init__(self, data_folder, train, transform=None):self.data_folder = data_folderself.transform = transformself.file_list = os.listdir(data_folder)self.train = traindef __getitem__(self, idx):img_name = os.path.join(self.data_folder, self.file_list[idx])original_image = Image.open(img_name)label_name = img_name.split('_', 1)[-1].split('.')[0]label_idx = label_dict[label_name]if self.train:image = self.transform(original_image)else:image = self.transform(original_image)return image, label_idxdef __len__(self):return len(self.file_list)images_dir = "/Users/enzo/Documents/GitHub/dataset/CIFAR/cifar-100-images/train"
dataset = CustomDataset(images_dir, train=True, transform=transforms.ToTensor())data_loader = DataLoader(dataset,batch_size=2,shuffle=True,collate_fn=default_collate)data_loader = iter(data_loader)
image, label = next(data_loader)
print(image.shape)
print(label)
默认 collate_fn 函数
简易实现版本,实际更复杂 :
def default_collate(batch):# 检查样本类型并处理# 判断batch第0个元素数据类型,根据不同类型分别返回不同的打包结果。if isinstance(batch[0], torch.Tensor):return torch.stack(batch, dim=0)elif isinstance(batch[0], (list, tuple)):return [default_collate(samples) for samples in zip(*batch)]elif isinstance(batch[0], dict):return {key: default_collate([d[key] for d in batch]) for key in batch[0]}elif isinstance(batch[0], int):return torch.tensor(batch) # 将 int 转换为 Tensorraise TypeError(f"Unsupported type: {type(batch[0])}")
default_collate 函数通过递归处理不同类型的样本(张量、列表、元组、字典、整数等),将零散的单个样本组合成统一的批量数据格式,确保批量数据能被模型正确接收和处理,同时处理不同类型的数据结构。。
-
处理张量(Tensor)类型
if isinstance(batch[0], torch.Tensor):return torch.stack(batch, dim=0)如果样本是
torch.Tensor(如图像的像素数据),则使用torch.stack沿着第 0 维度拼接,形成一个包含批量数据的新张量。
例如:32 个形状为(3, 224, 224)的图像张量,会被拼接成(32, 3, 224, 224)的批量张量。 -
处理列表/元组(list/tuple)类型
elif isinstance(batch[0], (list, tuple)):return [default_collate(samples) for samples in zip(*batch)]如果样本是列表或元组(如包含多个输入特征的情况),则通过
zip(*batch)按位置拆分批量数据,再递归调用default_collate处理每个位置的子数据。
例如:每个样本是(图像张量, 标签)的元组,批量处理后会得到(批量图像张量, 批量标签)的元组。 -
处理字典(dict)类型
elif isinstance(batch[0], dict):return {key: default_collate([d[key] for d in batch]) for key in batch[0]}如果样本是字典(如包含
{"image": 图像张量, "label": 标签}的结构),则按字典的键(key)分组,对每个键对应的所有样本值递归调用default_collate,最终返回一个包含批量数据的新字典。 -
处理整数(int)类型
elif isinstance(batch[0], int):return torch.tensor(batch) # 将 int 转换为 Tensor如果样本是整数(如分类任务的标签),则将整个批量的整数转换为
torch.Tensor,方便后续计算。 -
不支持的类型
raise TypeError(f"Unsupported type: {type(batch[0])}")若遇到上述类型之外的数据,会抛出类型错误,提示不支持该类型。
自定义 collate_fn 函数
常用需要自定义的场景:一个 batch 中的 多张图片,经过 dataset.getitem() 方法,得到的图像输出尺寸不一样。(可能因为 图像增强 使用 的 transforms ,设计的 最后一步处理方式是范围内的随机裁剪)
又因为网络要求输入数据的尺寸形式为 (batch_size, channel, high,width), 为了将多张图像数据打包成一个batch 的数据形式:
- 对比一个batch中所有图片的宽高,找到最长的值。
- 根据最大的作为标准给图像加上padding,保证所有图像尺寸一致。
- 处理得出masks数据,记录每一个图片有效像素和padding像素的位置
- 进而组成 batch 的数据形式,进行返回。

Deformable-DETR/main.py有这个场景的代码实现:
data_loader_train = DataLoader(dataset_train, batch_sampler=batch_sampler_train,collate_fn=utils.collate_fn, num_workers=args.num_workers,pin_memory=True)data_loader_val = DataLoader(dataset_val, args.batch_size, sampler=sampler_val,drop_last=False, collate_fn=utils.collate_fn, num_workers=args.num_workers,pin_memory=True)
Deformable-DETR/util/misc.py
def collate_fn(batch):batch = list(zip(*batch))batch[0] = nested_tensor_from_tensor_list(batch[0])return tuple(batch)def _max_by_axis(the_list):# type: (List[List[int]]) -> List[int]maxes = the_list[0]for sublist in the_list[1:]:for index, item in enumerate(sublist):maxes[index] = max(maxes[index], item)return maxesdef nested_tensor_from_tensor_list(tensor_list: List[Tensor]):# TODO make this more generalif tensor_list[0].ndim == 3:# TODO make it support different-sized imagesmax_size = _max_by_axis([list(img.shape) for img in tensor_list])# min_size = tuple(min(s) for s in zip(*[img.shape for img in tensor_list]))batch_shape = [len(tensor_list)] + max_sizeb, c, h, w = batch_shapedtype = tensor_list[0].dtypedevice = tensor_list[0].devicetensor = torch.zeros(batch_shape, dtype=dtype, device=device)mask = torch.ones((b, h, w), dtype=torch.bool, device=device)for img, pad_img, m in zip(tensor_list, tensor, mask):pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)m[: img.shape[1], :img.shape[2]] = Falseelse:raise ValueError('not supported')return NestedTensor(tensor, mask)
、Eden区和Survivor区概念介绍)






)


:vi/vim)






:PWM(脉冲宽度调制))
)
