本次通过对双十一淘宝美妆数据的分析实践,我系统掌握了数据处理与分析的完整流程,从数据初步认知到深度挖掘,再到可视化呈现与结论提炼,收获颇丰。以下是具体的学习总结:
一、数据初步了解:奠定分析基础
在分析初期,我们首先对数据进行了全面 “扫描”。通过df.head()查看前五行数据,直观了解了每条数据包含的 7 个特征:update_time(更新时间)、id(商品 ID)、title(商品标题)、price(价格)、sale_count(销量)、comment_count(评论数)、店名(店铺名称)。
借助df.info()和df.shape,明确了数据规模为 27598 条记录,且发现sale_count和comment_count存在缺失值,其他特征无缺失,这为后续的数据清洗指明了方向。而df.describe()则提供了数值型特征的统计量,如价格均值为 362.83 元,销量均值为 12301.77 件等,让我们对数据的分布有了初步判断。
二、数据清洗:保障数据质量
数据清洗是分析的关键环节,直接影响后续结果的准确性,主要完成了以下工作:
- 重复值处理:使用
drop_duplicates删除了 86 条重复数据,得到 27512 条有效数据,并通过reset_index重置行索引,确保数据结构规范。 - 缺失值处理:观察发现
sale_count和comment_count的缺失值可能代表销量或评论数为 0,因此采用fillna(0)用 0 填补缺失值,经检查后确认无空值残留。 - 新特征挖掘:这是本次分析的亮点之一。首先用
jieba对商品标题进行分词,生成subtitle列,为后续分类做准备;然后基于自定义的分类字典,将商品划分为 “护肤品”“化妆品” 等主类别和 “乳液类”“口红类” 等子类别,新增main_type和sub_type列;此外,根据标题是否含 “男士”“男生” 等关键词,新增是否男士专用列;最后,通过price * sale_count计算出销售额列,丰富了分析维度。
三、数据分析及可视化:洞察数据规律
借助matplotlib和seaborn工具,我们对数据进行了多维度分析与可视化呈现,得出了诸多有价值的结论:
1. 品牌维度分析
- 商品数量:悦诗风吟的商品数量遥遥领先,但销量和销售额并非顶尖,说明商品数量多并不一定等同于市场表现好。
- 销量与销售额:相宜本草在销量和销售额上均位居第一,且销量约为第二名的两倍,但销售额远不到两倍,反映出其商品均价较低的特点。
- 平均单价:将品牌按平均单价分为 A(0-100 元)、B(100-200 元)、C(200-300 元)、D(300 元以上)四类,发现 A 类品牌销售额占比最高,D 类最低,且定价越低的品牌平均销售额越高,印证了 “价格亲民的品牌更易获得高销售额” 的推测。
2. 类别维度分析
- 大类表现:护肤品的销量和销售额占比远高于化妆品及其他类别,是美妆市场的主力。
- 小类表现:清洁类和补水类护肤品销量领先,且各类别的销量与销售额占比基本正相关,符合市场常识。
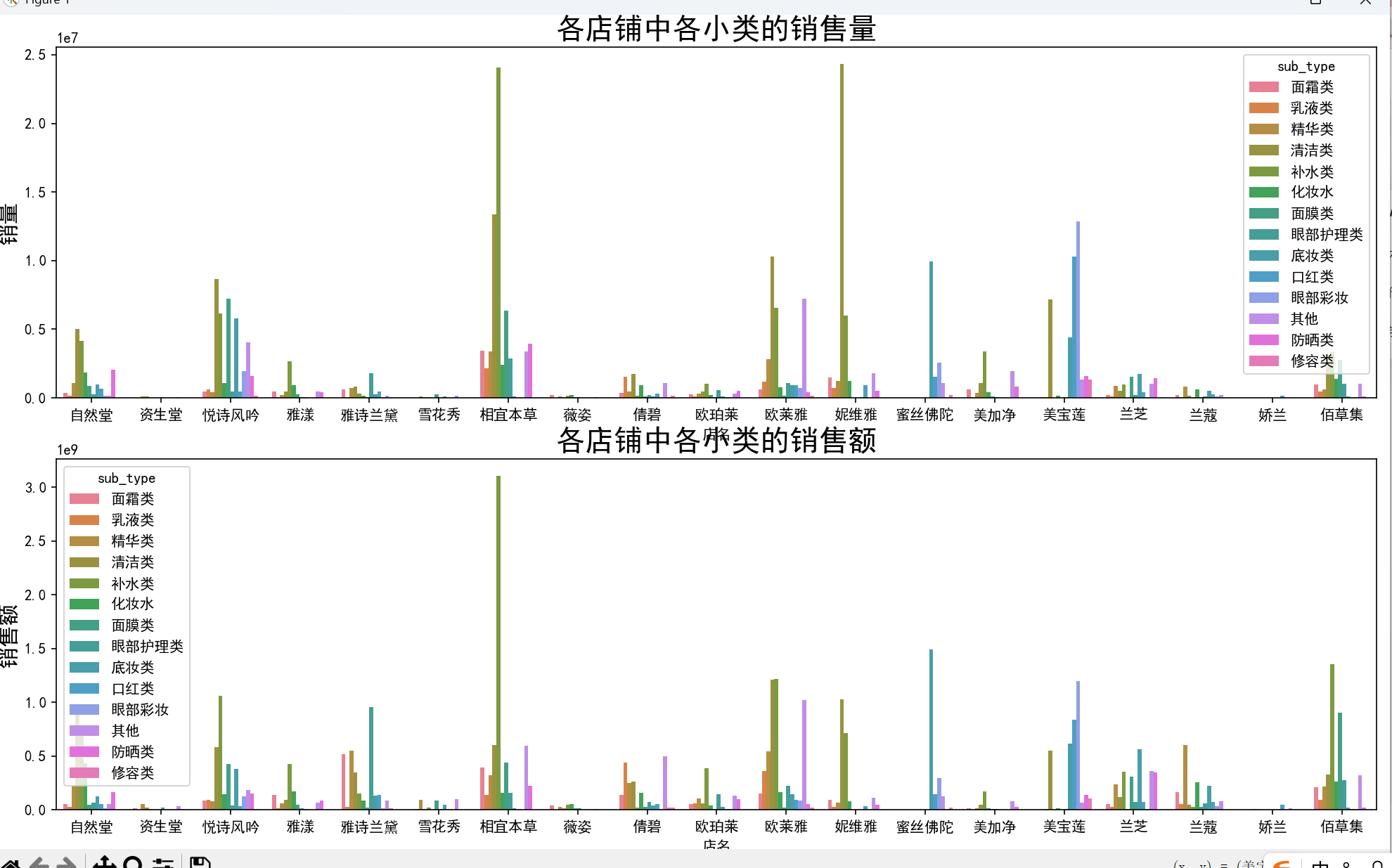
- 品牌与类别结合:相宜本草在面霜、乳液、补水等多个小类中销量最高,美宝莲在口红、眼部彩妆类表现突出,妮维雅则在清洁类中占据绝对优势。
3. 性别维度分析
- 男士专用商品占比:男士专用商品的销量和销售额占比均较低,说明美妆市场仍以女性消费者为主。
- 男士商品类别偏好:男士专用商品中,清洁类和补水类销量占比较高,反映出男性在美妆消费上更注重基础清洁和保湿需求。
四 、代码及图片
import numpy as np
import pandas as pd
import jieba
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文显示
plt.rcParams['font.sans-serif'] = [u'SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1. 数据读取与初步了解
df = pd.read_csv('双十一淘宝美妆数据.csv')
print("数据前五行:")
print(df.head())
print("\n数据特征信息:")
print(df.info())
print("\n数据形状:", df.shape)
print("\n数值型特征统计量:")
print(df.describe())
# 2. 数据清洗
# 2.1 重复值处理
data = df.drop_duplicates(inplace=False)
data.reset_index(inplace=True, drop=True)
print("\n去重后数据形状:", data.shape)
# 2.2 缺失值处理
print("\n缺失值填补前情况:")
print(data.loc[data['sale_count'].isnull()].head())
print(data.loc[data['comment_count'].isnull()].tail())
data = data.fillna(0)
print("\n缺失值填补后是否还有空值:")
print(data.isnull().any())
# 2.3 数据挖掘与新特征生成
# 对标题进行分词
subtitle = []
for each in data['title']:
k = jieba.lcut_for_search(each) # 搜索引擎模式分词
subtitle.append(k)
data['subtitle'] = subtitle
print("\n标题分词结果示例:")
print(data[['title', 'subtitle']].head())
# 商品分类(主类别与子类别)
basic_data = """护肤品 乳液类 乳液 美白乳 润肤乳 凝乳 柔肤液 亮肤乳 菁华乳 修护乳
护肤品 眼部护理类 眼霜 眼部 眼膜
护肤品 面膜类 面膜
护肤品 清洁类 洗面 洁面 清洁 卸妆 洁颜 洗颜 去角质 磨砂
护肤品 化妆水 化妆水 爽肤水 柔肤水 补水露 凝露 柔肤液 精粹水 亮肤水 润肤水 保湿水 菁华水 保湿喷雾 舒缓喷雾
护肤品 面霜类 面霜 日霜 晚霜 柔肤霜 滋润霜 保湿霜 凝霜 日间霜 晚间霜 乳霜 修护霜 亮肤霜 底霜 菁华霜
护肤品 精华类 精华液 精华水 精华露 精华素 精华
护肤品 防晒类 防晒
护肤品 补水类 补水
化妆品 口红类 唇釉 口红 唇彩 唇膏
化妆品 底妆类 散粉 蜜粉 粉底液 定妆粉 气垫 粉饼 BB CC 遮瑕 粉霜 粉底膏 粉底霜
化妆品 眼部彩妆 眉粉 染眉膏 眼线 眼影 睫毛膏 眉笔
化妆品 修容类 鼻影 修容粉 高光 腮红"""
# 构建分类字典
dcatg = {}
catg = basic_data.split('\n')
for i in catg:
parts = i.strip().split('\t')
if len(parts) >= 3:
main_cat = parts[0]
sub_cat = parts[1]
keywords = parts[2:]
for j in keywords:
if j: # 跳过空字符串
dcatg[j] = (main_cat, sub_cat)
# 生成主类别和子类别特征
sub_type = []
main_type = []
for i in range(len(data)):
exist = False
for j in data['subtitle'][i]:
if j in dcatg:
sub_type.append(dcatg[j][1])
main_type.append(dcatg[j][0])
exist = True
break
if not exist:
sub_type.append('其他')
main_type.append('其他')
data['sub_type'] = sub_type
data['main_type'] = main_type
print("\n分类为'其他'的商品数量:", data.loc[data['sub_type'] == '其他'].shape[0])
# 生成"是否男士专用"特征
sex = []
for i in range(len(data)):
subtitle = data['subtitle'][i]
if '男士' in subtitle or '男生' in subtitle:
sex.append('是')
elif '男' in subtitle and '女' not in subtitle and '斩男' not in subtitle:
sex.append('是')
else:
sex.append('否')
data['是否男士专用'] = sex
print("\n男士专用商品数量统计:")
print(data['是否男士专用'].value_counts())
# 生成"销售额"特征
data['销售额'] = data['price'] * data['sale_count']
print("\n添加销售额后的数据示例:")
print(data.head())
# 3. 数据分析及可视化
# 3.1 各店铺基本情况分析
plt.figure(figsize=(12, 10))
# 各店铺商品数量
plt.subplot(2, 2, 1)
plt.tick_params(labelsize=15)
data['店名'].value_counts().sort_values().plot.bar()
plt.title('各品牌商品数', fontsize=20)
plt.ylabel('商品数量', fontsize=15)
plt.xlabel('店名')
# 各店铺总销量
plt.subplot(2, 2, 2)
plt.tick_params(labelsize=15)
data.groupby('店名')['sale_count'].sum().sort_values().plot.bar()
plt.title('各品牌所有商品的销量', fontsize=20)
plt.ylabel('商品总销量', fontsize=15)
# 各店铺总销售额
plt.subplot(2, 2, 3)
plt.tick_params(labelsize=15)
data.groupby('店名')['销售额'].sum().sort_values().plot.bar()
plt.title('各品牌总销售额', fontsize=20)
plt.ylabel('商品总销售额', fontsize=15)
# 各品牌平均每单单价
plt.subplot(2, 2, 4)
plt.tick_params(labelsize=15)
avg_price = data.groupby('店名')['销售额'].sum() / data.groupby('店名')['sale_count'].sum().replace(0, np.nan)
avg_price.sort_values().plot.bar()
plt.title('各品牌平均每单单价', fontsize=20)
plt.ylabel('售出商品的平均单价', fontsize=15)
plt.tight_layout()
plt.show(block=True)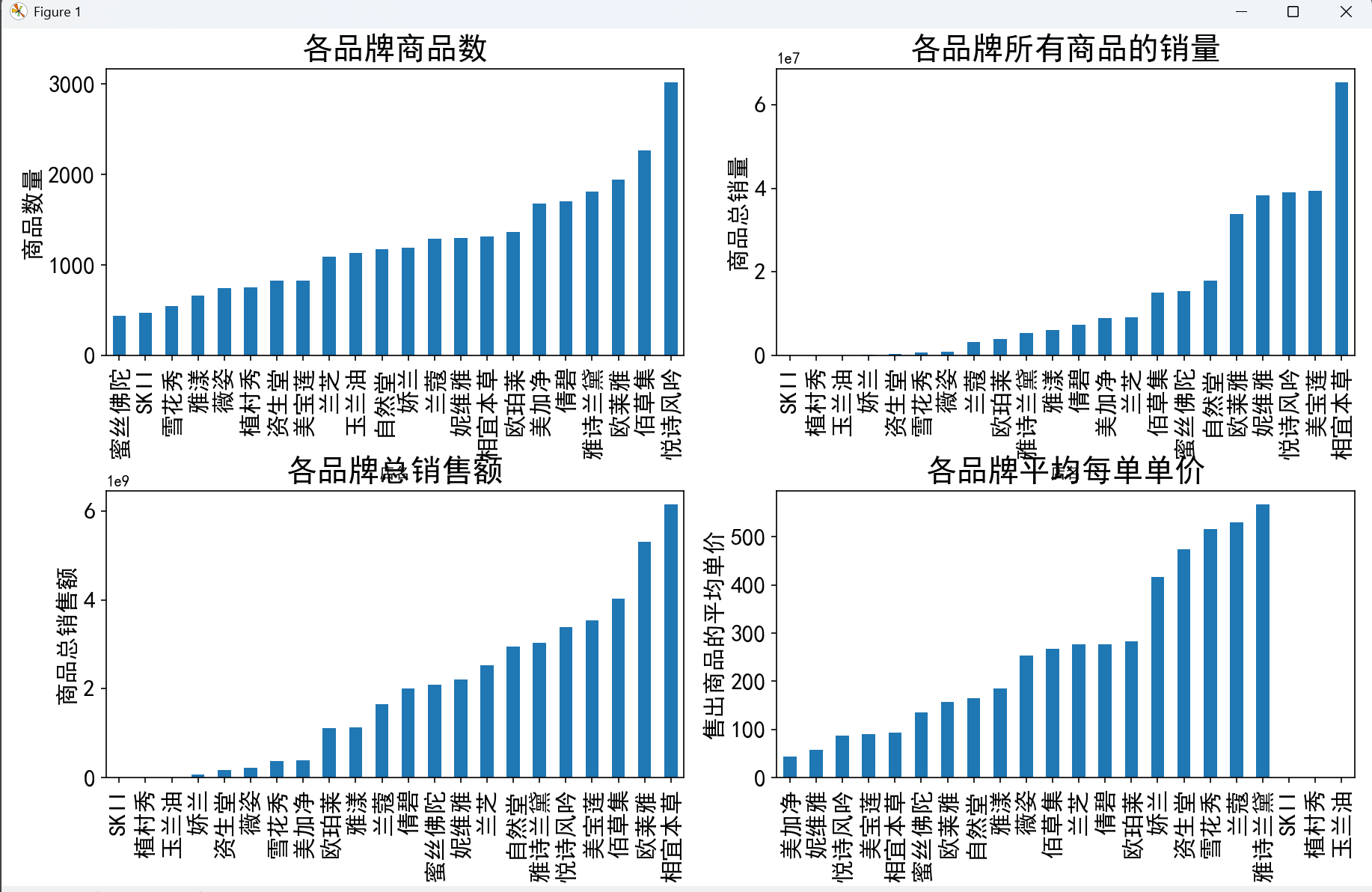
# 3.2 不同价格区间品牌的销售情况
A = avg_price[(avg_price <= 100) & (avg_price > 0)].index
B = avg_price[(avg_price <= 200) & (avg_price > 100)].index
C = avg_price[(avg_price <= 300) & (avg_price > 200)].index
D = avg_price[avg_price > 300].index
sum_sale = data.groupby('店名')['销售额'].sum()
plt.figure(figsize=(16, 8))
# 各类别品牌销售额占比
plt.subplot(1, 2, 1)
sum_sale_byprice = pd.concat([sum_sale[A].sort_values(),
sum_sale[B].sort_values(),
sum_sale[C].sort_values(),
sum_sale[D].sort_values()])
colors = ['grey'] * len(A) + ['g'] * len(B) + ['y'] * len(C) + ['m'] * len(D)
plt.pie(x=sum_sale_byprice, labels=sum_sale_byprice.index, colors=colors,
autopct='%0f%%', pctdistance=0.9)
plt.title('不同均价区间品牌的销售额占比')
# 各类别平均每个店销售额
plt.subplot(1, 2, 2)
plt.tick_params(labelsize=15)
plt.bar('均价0-100元', np.mean(sum_sale[A]) if not A.empty else 0, color='grey')
plt.bar('均价100-200元', np.mean(sum_sale[B]) if not B.empty else 0, color='g')
plt.bar('均价200-300元', np.mean(sum_sale[C]) if not C.empty else 0, color='y')
plt.bar('均价300元以上', np.mean(sum_sale[D]) if not D.empty else 0, color='m')
plt.title('不同类别的平均每个店销售额', fontsize=20)
plt.ylabel('平均销售额', fontsize=20)
plt.tight_layout()
plt.show(block=True)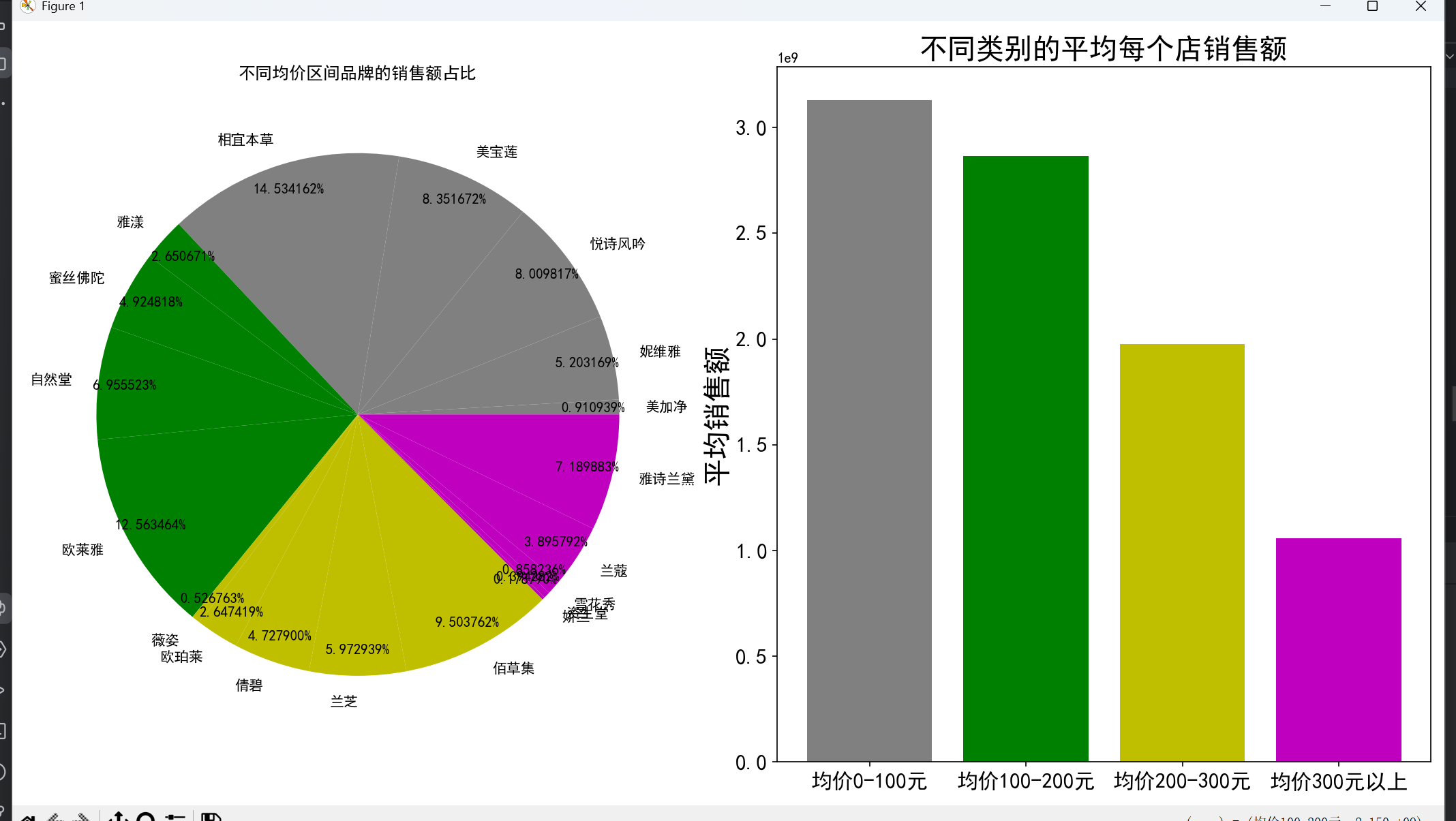
# 3.3 各类别销售情况分析
plt.figure(figsize=(12, 12))
# 大类销售量占比
plt.subplot(2, 2, 1)
data.groupby('main_type')['sale_count'].sum().plot.pie(autopct='%0f%%', title='各大类销售量占比')
# 大类销售额占比
plt.subplot(2, 2, 2)
data.groupby('main_type')['销售额'].sum().plot.pie(autopct='%0f%%', title='各大类销售额占比')
# 小类销售量占比
plt.subplot(2, 2, 3)
data.groupby('sub_type')['sale_count'].sum().plot.pie(autopct='%0f%%', title='各小类销售量占比')
# 小类销售额占比
plt.subplot(2, 2, 4)
data.groupby('sub_type')['销售额'].sum().plot.pie(autopct='%0f%%', title='各小类销售额占比')
plt.tight_layout()
plt.show(block=True)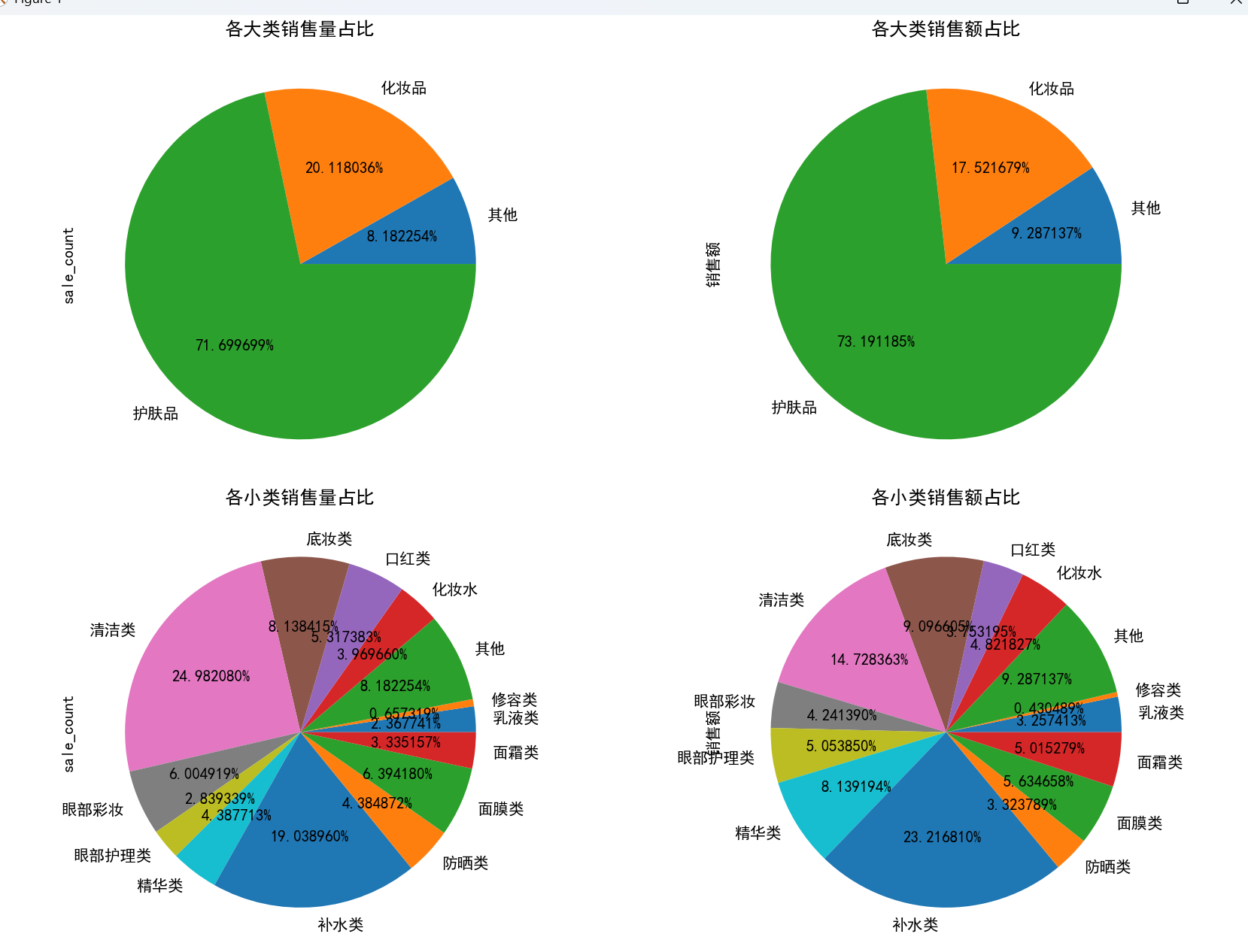
# 3.4 各店铺不同类别销售情况(去除销量为0的店铺)
data1 = data.drop(index=data[data['店名'].isin(
data.groupby('店名')['sale_count'].sum()[data.groupby('店名')['sale_count'].sum() == 0].index
)].index)
# 各店铺中各大类的销量与销售额
plt.figure(figsize=(16, 12))
plt.subplot(2, 1, 1)
plt.tick_params(labelsize=10)
sns.barplot(x='店名', y='sale_count', hue='main_type', estimator=np.sum, data=data1, ci=0)
plt.title('各店铺中各大类的销售量', fontsize=20)
plt.ylabel('销量', fontsize=15)
plt.subplot(2, 1, 2)
plt.tick_params(labelsize=10)
sns.barplot(x='店名', y='销售额', hue='main_type', estimator=np.sum, data=data1, ci=0)
plt.title('各店铺中各大类的销售额', fontsize=20)
plt.tight_layout()
plt.show(block=True)
# 各店铺中各小类的销量与销售额
plt.figure(figsize=(16, 12))
plt.subplot(2, 1, 1)
plt.tick_params(labelsize=10)
sns.barplot(x='店名', y='sale_count', hue='sub_type', estimator=np.sum, data=data1, ci=0)
plt.title('各店铺中各小类的销售量', fontsize=20)
plt.ylabel('销量', fontsize=15)
plt.subplot(2, 1, 2)
plt.tick_params(labelsize=10)
sns.barplot(x='店名', y='销售额', hue='sub_type', estimator=np.sum, data=data1, ci=0)
plt.title('各店铺中各小类的销售额', fontsize=20)
plt.ylabel('销售额', fontsize=15)
plt.tight_layout()
plt.show(block=True)
# 各小类中各店铺的销量与销售额
plt.figure(figsize=(16, 12))
plt.subplot(2, 1, 1)
plt.tick_params(labelsize=10)
sns.barplot(x='sub_type', y='sale_count', hue='店名', estimator=np.sum, data=data1, ci=0)
plt.title('各小类中各店铺的销售量', fontsize=20)
plt.ylabel('销量', fontsize=15)
plt.subplot(2, 1, 2)
plt.tick_params(labelsize=10)
sns.barplot(x='sub_type', y='销售额', hue='店名', estimator=np.sum, data=data1, ci=0)
plt.title('各小类中各店铺的销售额', fontsize=20)
plt.ylabel('销售额', fontsize=15)
plt.tight_layout()
plt.show(block=True)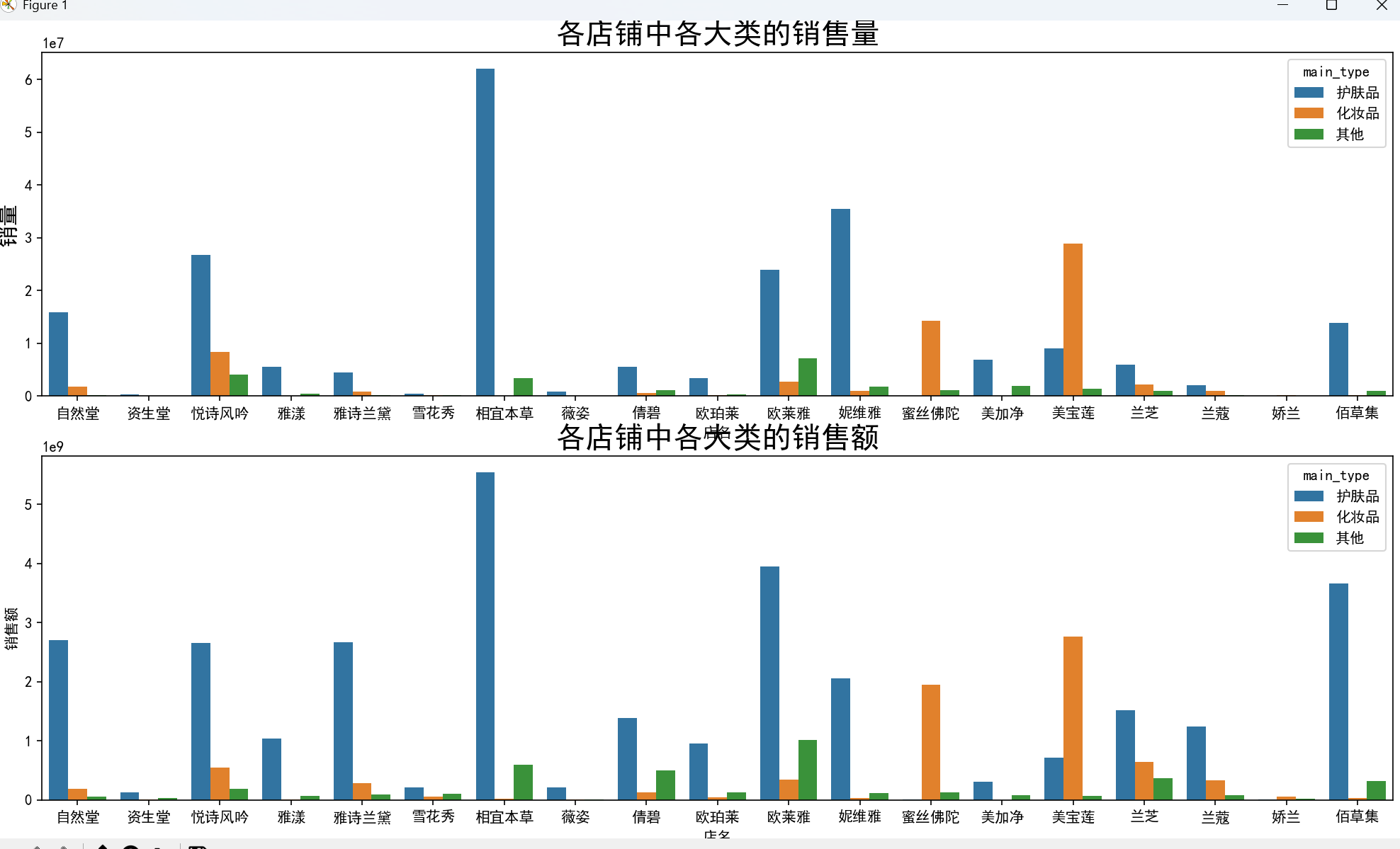
# 3.5 性别因素对销售的影响
plt.figure(figsize=(16, 16))
# 男士专用各小类销售量占比
plt.subplot(2, 2, 1)
data.loc[data['是否男士专用'] == '是'].groupby('sub_type')['sale_count'].sum().plot.pie(
autopct='%0f%%', title='男士各小类销售量占比', pctdistance=0.8)
# 非男士专用各小类销售量占比
plt.subplot(2, 2, 2)
data.loc[data['是否男士专用'] == '否'].groupby('sub_type')['sale_count'].sum().plot.pie(
autopct='%0f%%', title='非男士专用各小类销售量占比', pctdistance=0.8)
# 男士专用销售量占总销售量比例
plt.subplot(2, 2, 3)
data.groupby('是否男士专用')['sale_count'].sum().plot.pie(
autopct='%0f%%', title='男士专用销售量占比', pctdistance=0.8)
# 男士专用销售额占总销售额比例
plt.subplot(2, 2, 4)
data.groupby('是否男士专用')['销售额'].sum().plot.pie(
autopct='%0f%%', title='男士专用销售额占比', pctdistance=0.8)
plt.tight_layout()
plt.show(block=True)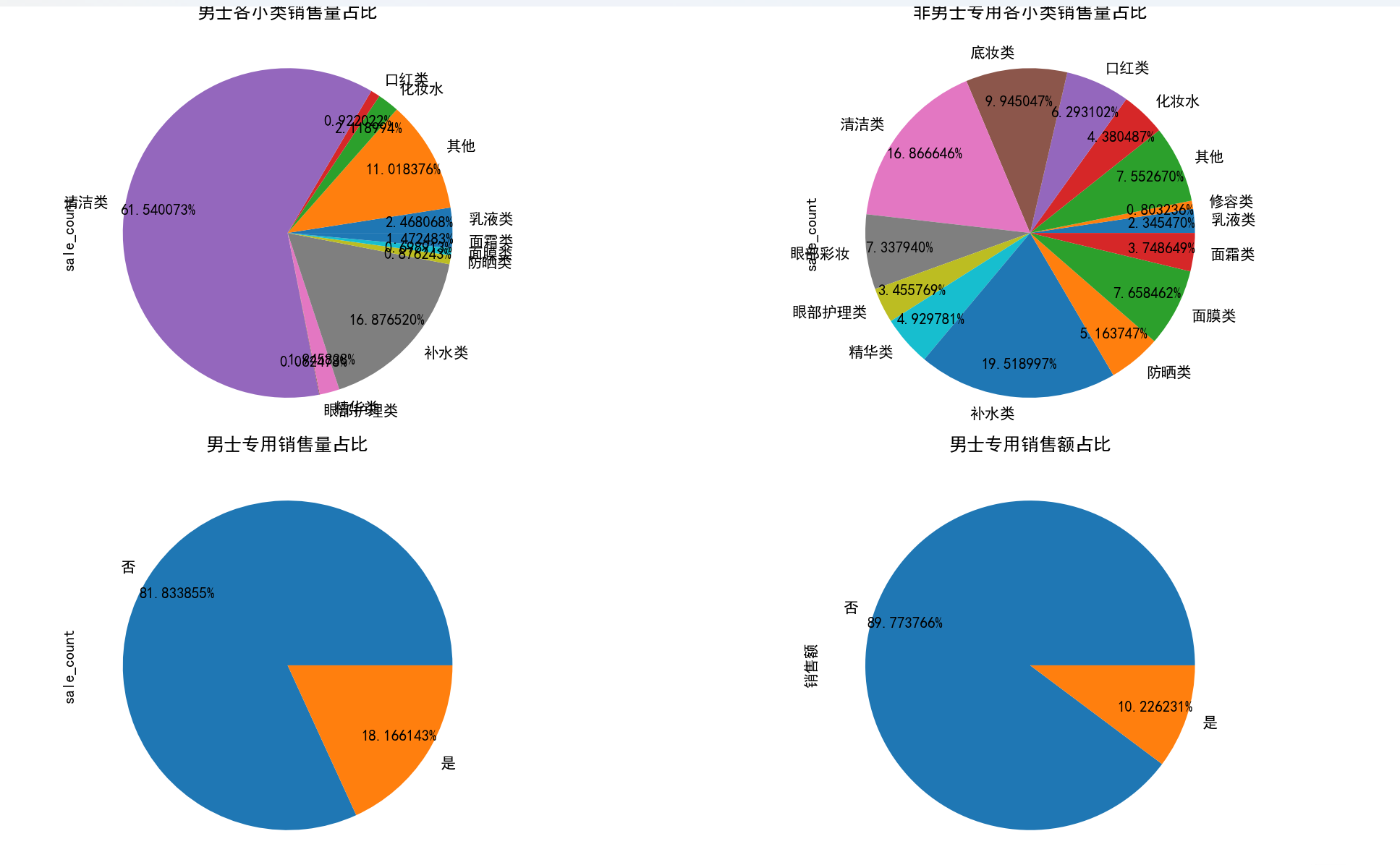
五、学习收获与反思
通过本次实践,我不仅熟练掌握了pandas的数据处理方法(如去重、填补缺失值、新增特征等)和matplotlib、seaborn的可视化技巧,更重要的是学会了从数据中挖掘有价值的信息,形成分析思路。
同时也认识到,数据分析需要结合业务场景进行合理推测,例如对缺失值的处理逻辑、商品类别的划分标准等,都需要基于对美妆行业的基本认知。此外,可视化图表的选择应服务于分析目的,清晰、直观地呈现结论是关键。
未来,在数据分析中可进一步引入更多维度(如时间对销量的影响、评论情感分析等),使分析更加全面深入。






![[4.2-2] NCCL新版本的register如何实现的?](http://pic.xiahunao.cn/[4.2-2] NCCL新版本的register如何实现的?)




读书笔记 23)

;declare -i /-x)





