引言:文档智能处理的新范式
在数字化时代,企业和个人每天都面临着海量文档的处理需求,从产品手册到学术论文,从合同条款到医疗报告,非结构化文档的高效处理一直是技术痛点。2025年8月,腾讯正式开源了基于大语言模型的文档理解与检索框架WeKnora(维娜拉),为这一领域带来了革命性的解决方案。
WeKnora专为处理结构复杂、内容异构的文档场景设计,通过模块化架构和多模态融合技术,实现了从文档解析到智能问答的全流程优化。作为腾讯在企业级AI领域的重要开源成果,WeKnora不仅体现了腾讯在大模型应用领域的技术积累,更为开发者提供了一个功能完备、易于部署的文档智能处理工具链。
一、项目概述:重新定义文档理解
1.1 核心定位
WeKnora是一套端到端的文档理解与语义检索框架,基于大语言模型构建,融合了多模态预处理、语义向量索引、智能召回与大模型生成推理等技术,打造了高效、可控的文档问答流程。
1.2 关键特性
- 多模态处理能力:支持PDF、Word、图片等多种格式文档的结构化提取
- 模块化架构设计:从解析、嵌入、召回到生成全流程解耦,灵活扩展
- 企业级安全保障:支持本地化部署与私有云环境,数据完全自主可控
- 微信生态集成:通过微信对话开放平台实现零代码部署,无缝对接公众号、小程序
1.3 开源信息
- 开源协议:MIT协议
- 项目地址:https://github.com/Tencent/WeKnora
- 官方网站:https://weknora.weixin.qq.com
- 发布时间:2025年8月
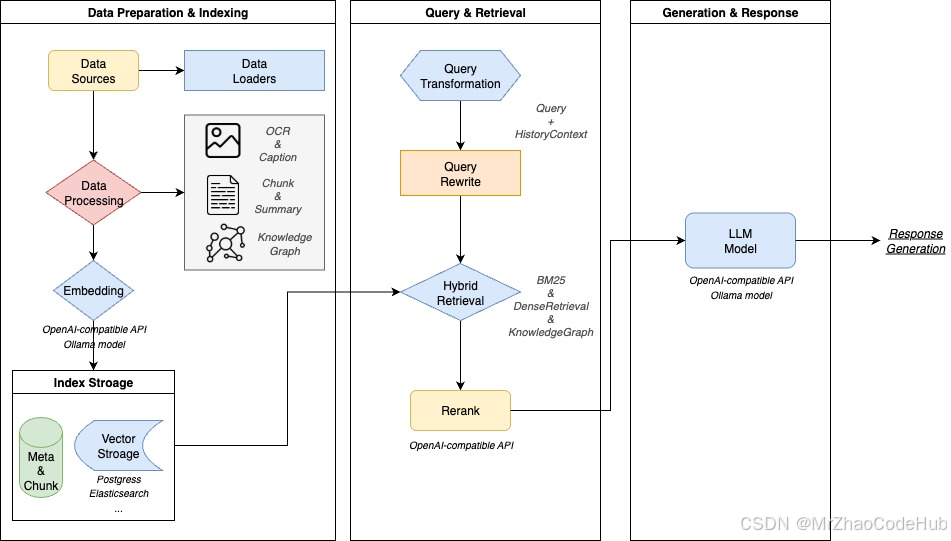
二、技术架构:五维协同的模块化流水线
WeKnora采用精心设计的五层架构,各模块既独立封装又协同联动,形成完整的文档处理闭环。
2.1 文档处理层:多模态数据入口
作为数据处理的第一道关卡,文档处理层展现了强大的多模态解析能力:
- 自适应解析引擎:根据文档类型动态调整处理策略,扫描版PDF启用高精度OCR,可编辑文档直接提取文本流
- 格式支持:覆盖PDF、Word、TXT、Markdown及图片等多种格式
- 表格与图像处理:自动识别表格结构并转换为结构化数据,提取图片中的文本信息
- 预处理效率:较传统工具提升300%以上,支持多线程并行处理
# 文档解析示例代码
from weknora import DocumentProcessor# 初始化处理器,支持多线程解析
processor = DocumentProcessor(thread_num=4)# 解析本地PDF文档,返回结构化内容
doc = processor.process_file(file_path="technical_manual.pdf",output_format="json", # 支持json/markdown/htmlextract_images=True # 同时提取文档中的图片
)# 打印解析结果中的表格数据
for table in doc.tables:print(f"表格标题: {table.title}")print(f"表格内容: {table.data}") # 二维列表形式的结构化数据
2.2 知识建模层:从文本到知识的转化
知识建模层是实现智能检索的核心枢纽:
- 文本分块策略:采用滑动窗口分块算法,默认512token窗口,支持动态调整
- 向量表示:使用Sentence-BERT等模型生成768维向量嵌入
- 知识图谱构建:自动识别文档中的实体关系,构建"产品-参数-价格"等三元组关系
- 语义增强:通过上下文理解优化实体识别和关系抽取准确性
2.3 检索引擎层:高效精准的信息召回
检索引擎层采用创新的混合检索策略,实现了高效精准的信息召回:
- 多策略融合:结合BM25关键词匹配、向量检索和知识图谱检索
- 动态权重调整:根据查询类型智能调整各检索策略权重
- 重排序优化:交叉注意力重排序模型提升结果相关性,Top10准确率达89%
- 存储兼容:支持Milvus、Qdrant等主流向量数据库,灵活扩展
# 自定义检索策略配置示例
retrieval:strategies:- name: "hybrid" # 混合检索策略params:keyword_weight: 0.3 # 关键词检索权重vector_weight: 0.7 # 向量检索权重rerank: true # 启用重排序vector_db:type: "milvus"host: "localhost"port: 19530collection_name: "company_kb"
2.4 推理生成层:可控可信的智能问答
推理生成层赋予系统类人的理解与生成能力:
- 大模型集成:兼容Qwen、DeepSeek等主流大模型,支持本地部署与API调用
- RAG增强:检索增强生成技术确保回答的事实一致性
- 多轮对话:上下文深度理解,支持多轮交互追问
- 防幻觉机制:采用"分段摘要-交叉验证"机制,显著降低幻觉率
2.5 交互展示层:人性化的用户体验
交互展示层兼顾技术与非技术用户需求:
- Web界面:直观易用的操作界面,支持拖拽上传和可视化管理
- 知识图谱可视化:展示文档内部语义关联网络
- API接口:提供RESTful API,方便集成到现有系统
- 微信生态集成:通过对话开放平台实现零代码部署,快速接入公众号、小程序
三、核心技术亮点解析
3.1 多模态认知引擎:突破格式限制
WeKnora的多模态认知引擎突破了传统文档处理的格式限制:
- LayoutLMv3模型:精准解析文档布局结构
- CLIP模型:实现图文语义关联,如识别财报图表与说明文字的对应关系
- OCR纠错模块:通过上下文语义校验,将识别错误率降低至0.3%以下
- 表格识别:支持复杂表格结构提取,包括合并单元格和多层表头
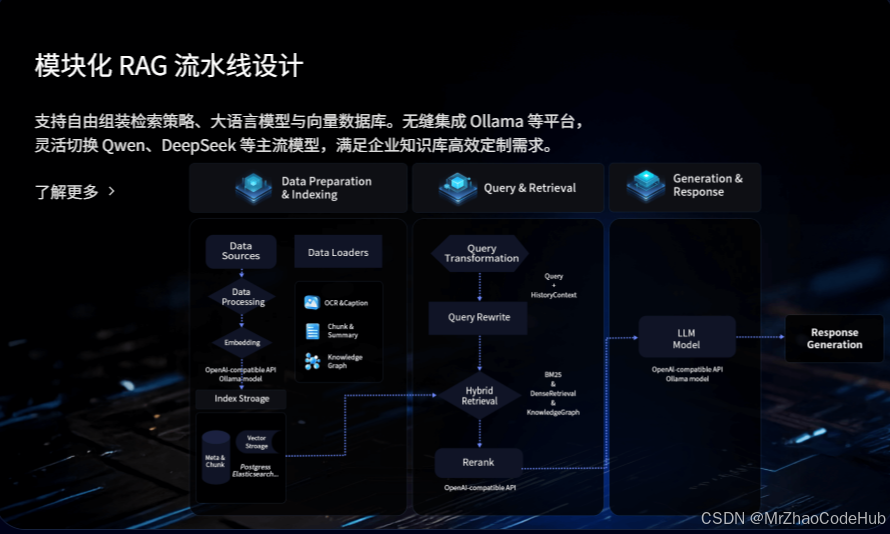
3.2 模块化RAG流水线:灵活定制的检索增强生成
模块化RAG流水线设计带来了前所未有的灵活性:
- 组件化设计:各环节解耦,支持按需组合
- 模型无关:不绑定特定大模型,支持灵活切换
- 部署多样:支持私有化部署、混合云和纯云端等多种模式
- 扩展性强:方便添加自定义检索策略和生成逻辑
3.3 企业级安全与可观测性
WeKnora专为企业级应用设计,提供全面的安全保障和可观测性:
- 私有化部署:数据完全本地化存储,满足高敏感场景需求
- 全链路监控:内置日志与链路追踪(Jaeger),实时监控关键指标
- 可视化评估:提供BLEU、ROUGE等指标评估工具
- 权限控制:细粒度的访问权限管理,保障数据安全
3.4 微信生态无缝集成
作为腾讯开源项目,WeKnora与微信生态深度融合:
- 零代码部署:通过微信对话开放平台快速部署智能问答服务
- 多场景覆盖:支持公众号、小程序等微信生态场景
- 高效问题管理:高频问题独立分类管理,提供丰富的数据工具
- 即问即答体验:用户无需编程即可构建专属知识库
四、快速上手:从部署到使用
4.1 本地部署步骤
WeKnora提供了完整的Docker化部署方案,只需三步即可快速启动:
# 1. 克隆代码仓库
git clone https://github.com/Tencent/WeKnora.git
cd WeKnora# 2. 配置环境
cp .env.example .env# 3. 启动服务
./scripts/start_all.sh
启动后,通过浏览器访问 http://localhost 即可使用Web界面,体验文档上传、知识库构建与智能问答功能。
4.2 微信对话开放平台部署
对于非技术用户,通过微信对话开放平台部署更加简便:
- 访问微信对话开放平台:https://chatbot.weixin.qq.com/login
- 创建新的智能问答应用
- 上传知识库文档
- 配置问答规则和回复样式
- 发布至公众号或小程序
五、应用场景与实际案例
WeKnora广泛适用于多种企业级文档问答场景:
5.1 企业知识管理
- 内部文档检索:快速查找规章制度、操作手册等内部资料
- 知识沉淀:将分散的专家知识结构化存储,便于共享和传承
- 培训支持:新员工自助学习,降低培训成本
案例:某大型制造企业部署WeKnora后,技术手册查询时间从平均30分钟缩短至1分钟,新员工培训周期缩短40%。
5.2 科研文献分析
- 论文检索:快速定位相关研究,提取关键发现
- 跨文献对比:分析多篇论文的研究方法和结论异同
- 学术写作辅助:自动生成文献综述初稿,辅助科研写作
5.3 法律合规审查
- 合同条款提取:自动识别关键条款,降低人工审查成本
- 法规查询:快速定位相关法律法规,辅助合规决策
- 案例分析:检索类似案例,为法律策略提供参考
行动建议:法务团队可利用WeKnora自动提取合同关键条款,审查效率提升70%以上;金融机构部署年报数据智能分析系统,人工复核时间减少90%。
5.4 医疗知识辅助
- 医学文献检索:快速查找相关研究和临床指南
- 诊疗支持:辅助医生获取最新治疗方案和药物信息
- 病例分析:对比类似病例,优化诊疗方案
六、与同类框架对比分析
| 特性 | WeKnora | LangChain | Haystack |
|---|---|---|---|
| 核心定位 | 文档理解与检索框架 | LLM应用开发框架 | 信息检索系统 |
| 多模态支持 | ★★★★★ | ★★★☆☆ | ★★☆☆☆ |
| 知识图谱 | 内置支持 | 需要扩展 | 有限支持 |
| 部署便捷性 | ★★★★★ | ★★★☆☆ | ★★★☆☆ |
| 企业级特性 | ★★★★☆ | ★★★☆☆ | ★★★★☆ |
| 微信生态集成 | 原生支持 | 无 | 无 |
| 上手难度 | 低 | 中 | 中 |
| 定制灵活性 | 高 | 极高 | 中 |
WeKnora在文档理解与检索这一垂直领域展现出明显优势,特别是在多模态处理、知识图谱构建和部署便捷性方面表现突出。与通用LLM框架相比,WeKnora提供了更专业、更完整的文档智能处理解决方案。
七、未来展望与社区贡献
WeKnora的开源生态正在快速扩展,未来将重点探索以下方向:
- 多语言支持:增强对中文以外语言的解析与检索能力
- AI Agent集成:结合Agent技术实现自动化知识更新与交互优化
- 性能优化:进一步提升大文档处理速度和检索响应时间
- 生态扩展:丰富插件系统,支持更多专业领域的定制化需求
WeKnora采用MIT协议开源,欢迎社区用户参与贡献:
- 贡献方向:Bug修复、功能开发、文档改进、用户体验优化
- 社区交流:GitHub Issues、Discord社区、腾讯云开发者论坛
- 贡献指南:详见项目仓库中的CONTRIBUTING.md文件
结语:重新定义文档智能处理
腾讯开源的WeKnora框架,以其创新的五层架构设计、强大的多模态处理能力和灵活的模块化设计,重新定义了文档智能处理的技术标准。无论是企业知识管理、科研文献分析还是专业领域的文档处理,WeKnora都展现出巨大的应用潜力。
随着WeKnora的开源和生态发展,我们有理由相信,文档智能处理将进入一个新的时代,帮助企业和个人更高效地管理和利用知识资产,释放非结构化数据的巨大价值。
立即访问WeKnora GitHub仓库,开始探索文档智能处理的新可能!
)

















)
)