相关爬虫专栏:JS逆向爬虫实战 爬虫知识点合集 爬虫实战案例
引言:爬虫与HTTP的不解之缘
- 爬虫作用:模拟浏览器请求网页
- 为何要懂HTTP:http是网络通信的基石,爬虫抓取数据就是通过HTTP协议进行的,了解http有助于我们更好的构筑爬虫,解决问题。
一、什么是HTTP协议
- HTTP (HyperText Transfer Protocol) 超文本传输协议,是互联网上应用最为广泛的一种网络协议。所有 WWW 文件都必须遵守这个标准。
- 特点:
- 客户端-服务器端间建立通讯连接:请求-响应
- 无状态:每次请求独立,服务器不保留连接状态(需要cookie/session来保存信息)
- 灵活简单:支持多种数据类型。
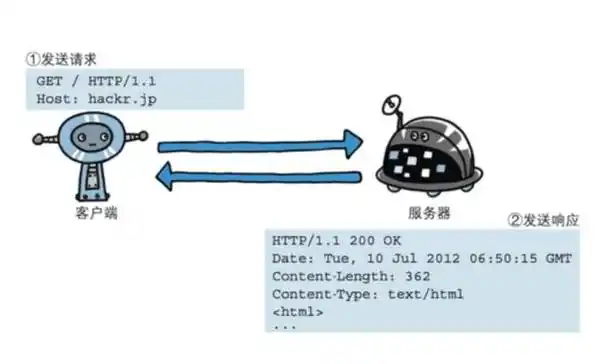
二、请求与响应机制
1. 客户端发送请求:
-
请求行
- 请求方法 (Method): GET、POST、PUT、DELETE、HEAD、OPTIONS 等,重点讲解爬虫常用的 GET 和 POST。
- 请求 URL (Uniform Resource Locator): 要访问的资源路径。
- HTTP 版本: 如 HTTP/1.1,HTTP/2.0。
-
请求头
User-Agent: 标识客户端类型,爬虫伪装浏览器最常用的头信息。Referer: 防盗链,此条请求的来源页面。Cookie: 保持会话状态的关键。Host: 目标服务器的主机名。Accept: 客户端可接受的媒体类型。Accept-Encoding: 客户端接受的编码方式(如 gzip, deflate)。Connection: 连接状态(如 Keep-Alive)。Content-Type: 请求体的数据类型和长度,常用来检查数据是json型还是text型。- 自定义请求头: 爬虫中可能添加的自定义头。
-
请求体
- 主要用于POST请求,携带提交的数据(表单数据,JSON数据等) -- 载荷中写着请求载荷/表单数据:
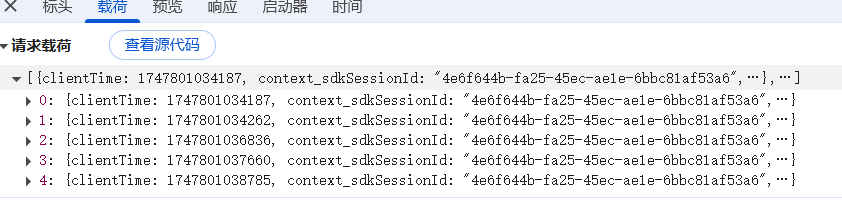
- 主要用于POST请求,携带提交的数据(表单数据,JSON数据等) -- 载荷中写着请求载荷/表单数据:
2. 服务器端返回响应:
-
状态行
- HTTP 版本。
- 状态码 (Status Code):
2xx(成功):200 OK(最常见)。3xx(重定向--即跳转访问到另一个页面):301(永久),302(临时),304(未修改)。4xx(客户端错误):400(请求错误),403(禁止访问),404(未找到)。5xx(服务器错误):500(内部错误),502(网关错误)。
- 状态信息: 对状态码的文字描述。
-
响应头
Set-Cookie: 服务器设置 Cookie 给客户端。Location: 重定向 URL。Server: 服务器软件信息。Content-Type: 响应体的数据类型(如 text/html, application/json)。Content-Length: 响应体的长度。Vary: 告知缓存机制哪些请求头会影响响应。
-
响应体
- 实际返回的数据,如 HTML、JSON、图片等。

- 实际返回的数据,如 HTML、JSON、图片等。
三、HTTP协议与反爬机制的攻防战
在爬虫上,HTTP协议不光是信息传输的通道,更是爬虫与反爬双方攻防的主战场。网站会通过检查HTTP请求各个访问信息来确定其是正常或爬虫访问。而理解这些反爬策略与HTTP的关系就成了我们学习进阶爬虫的必修课。
1. 身份识别:User-Agent与Referer的伪装
UA与Referer是常见的请求头中检查的对象:前者为身份识别,后者为防盗链(访问该请求前是从哪个链接跳转过来的)
二者处理都是设置一个合法真实的对象即可。其中UA在遭遇更高级别的反爬检查时,可能需要备一个UA池。
2. 会话保持:Cookie/Seesion的设置
HTTP 协议本身是无状态的,这意味着服务器不会记住每次请求之间的信息。但为了实现用户登录、购物车、个性化推荐等功能,网站会使用 Cookie 和 Session 来维持会话状态。
详情了解见爬虫知识之Cookie与Session。通过requests.session的方式可以有效管理相关会话并规避吸纳检测请求频率的反爬。
3. 访问频率限制:IP限制与HTTP频率限制
网站为了防止服务器过载/资源滥用,一般会限制同IP/同用户的请求数量。
- IP限制:服务器记录当前请求的IP地址,如果短时间访问量过大,就会暂时或永久封禁该ip。
- HTTP请求频率限制:不仅ip,也有可能看用户id,cookie等分析来限制。
- 爬虫应对方法:
- 延时:每次请求时加一个固定或随机的的延时(time.sleep),模拟人类浏览行为,降低请求频率。
- 代理IP池:使用大量的代理IP地址,分散请求来源,避免单一IP封禁。适用于大型爬虫项目。
- 分布式爬虫:利用多台机器与多个IP同时爬取,进一步分散请求压力。
- 爬虫应对方法:
四、总结
HTTP协议的特性与爬虫紧密相关,对HTTP协议了解足够深入,能更有效的帮助我们爬取各个网站内容。


】:使用 Django REST Framework 构建项目与模块 CRUD API)








)





算法?)

