1.设计目标与适用场景
Kafka:专注于高吞吐量的分布式流处理平台,适合处理大数据流(如日志收集、实时数据分析),强调消息的顺序性和扩展性。
RabbitMQ:作为消息中间件,侧重于消息的可靠传递和复杂的路由机制,适用于需要低延迟和事务性保证的场景(如任务队列)。
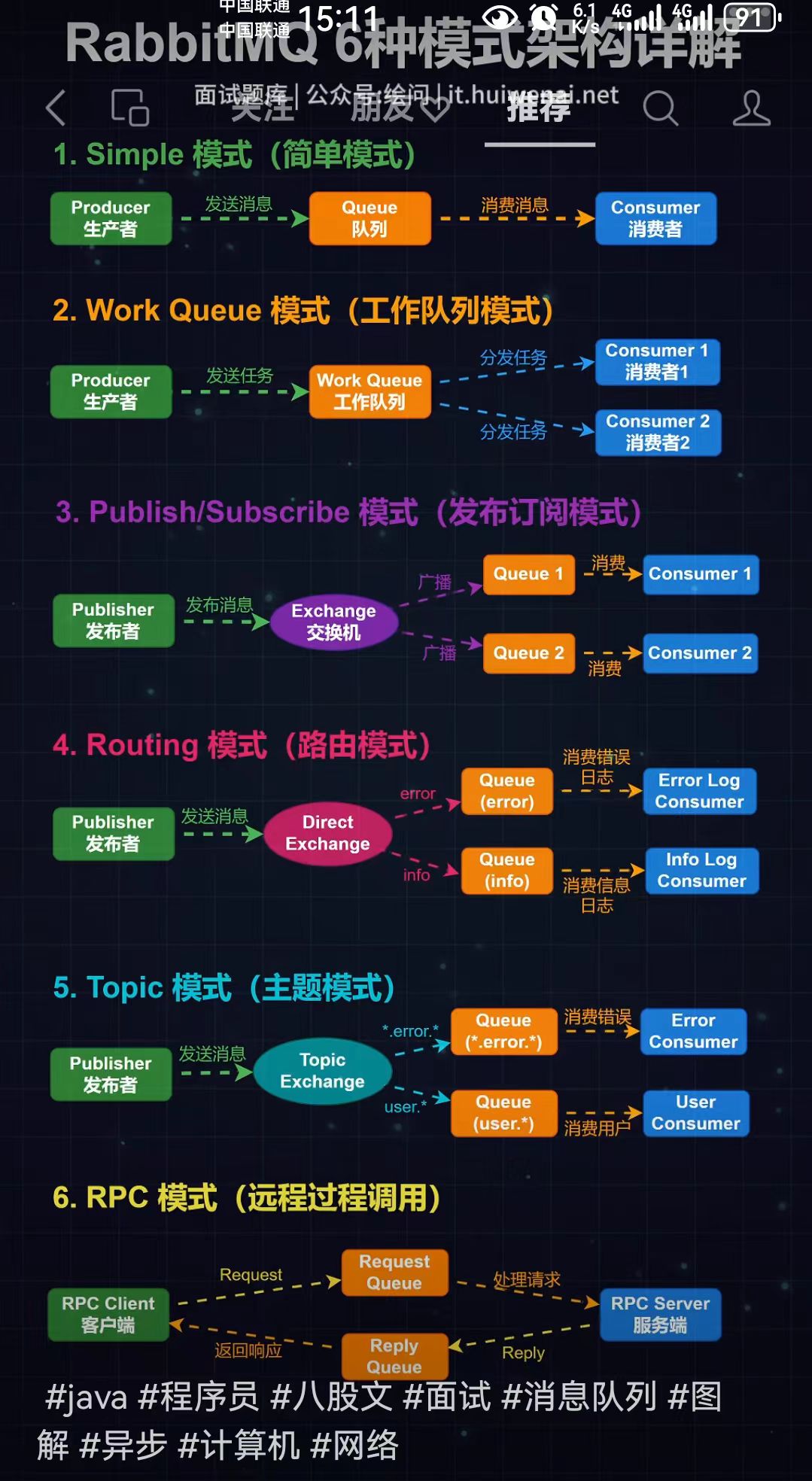
2.数据模型与消息传递
Kafka采用发布-订阅模型(Pub/Sub),消息以主题(Topic)形式发布,消费者组独立消费,支持严格顺序性(同一分区内)。
RabbitMQ基于队列模型(Queue),支持点对点(P2P)和发布-订阅模式,通过交换机(Exchange)实现路由,但默认不保证消息顺序性。
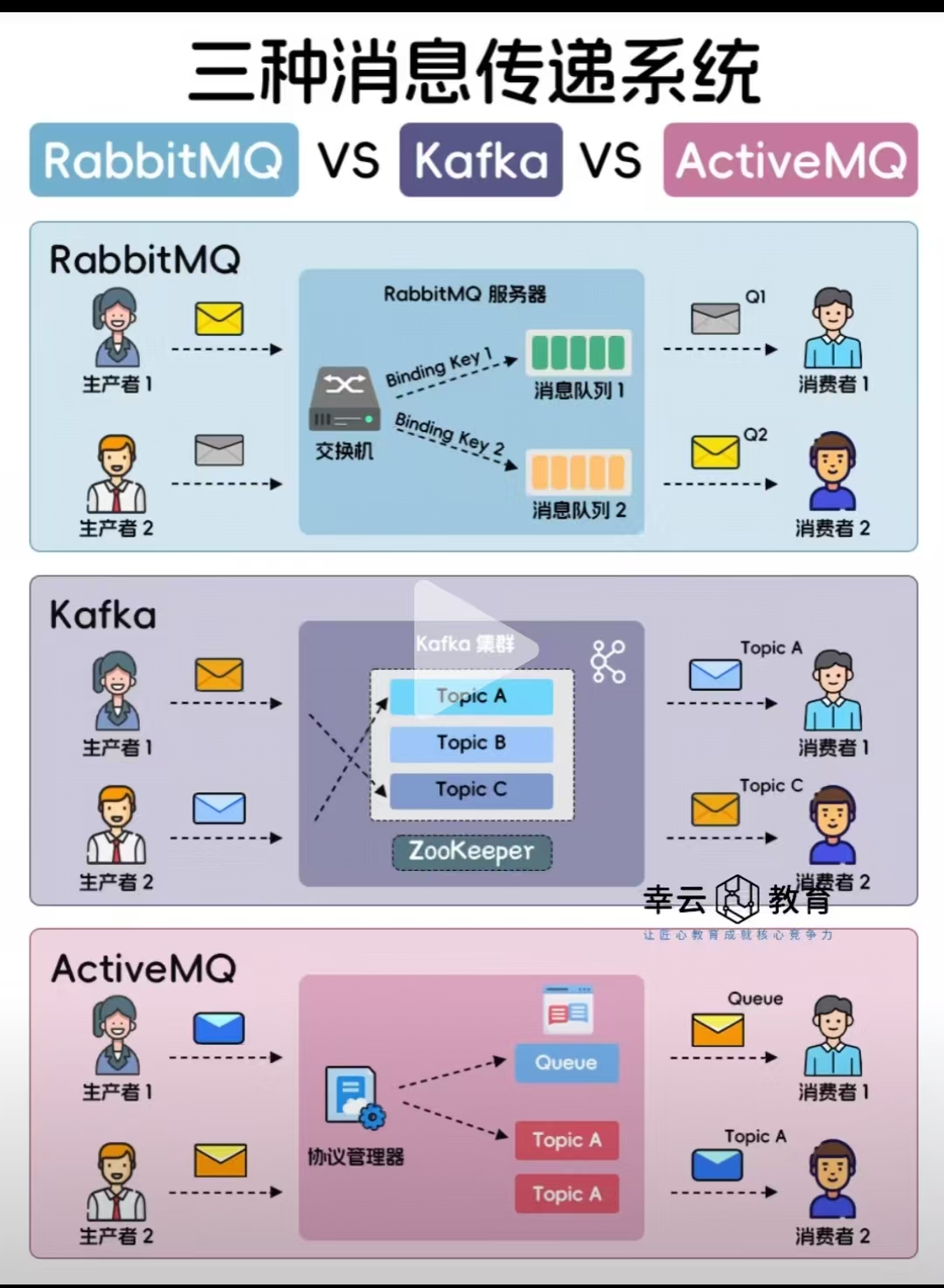
3. 性能与吞吐量
Kafka通过批量发送、零拷贝和顺序写入磁盘优化性能,适合每秒处理百万级消息,延迟较高(几十到几百毫秒)。1
RabbitMQ单节点吞吐量较低(每秒数千至数万条),但延迟低(毫秒级),适合低延迟场景。
4. 持久化与可靠性
Kafka将所有消息持久化到磁盘,通过副本机制保障高可用性;消费者组偏移量管理支持消息回溯。
RabbitMQ支持消息持久化但需显式配置,通过镜像队列实现高可用性;事务机制确保消息可靠性。
5. 生态与社区
Kafka与Hadoop、Spark等大数据工具深度集成,社区活跃;RabbitMQ也有广泛支持但生态较小。
总结:
若需处理高吞吐量的流数据且可接受较高延迟,选择Kafka;若强调实时性、事务性和复杂路由需求,RabbitMQ更合适。

)


与提示词撰写)




 语言原理介绍)







)
实战)
