第一部分:引言与背景——为什么需要知识提炼?
一、模型压缩的背景
随着深度学习的发展,模型变得越来越大(如 ResNet152、BERT、ViT、GPT 等),其参数量动辄数亿甚至上百亿。这些大模型虽然性能强大,但也带来以下问题:
| 问题 | 描述 |
|---|---|
| 存储成本高 | 占用大量内存、存储资源 |
| 推理速度慢 | 计算量大,难以部署到边缘设备 |
| 能耗高 | 大模型耗电多,部署在移动端不可行 |
| 工业部署难 | 需要简化模型以适应生产场景 |
为了解决上述问题,人们提出了模型压缩技术(Model Compression),主要包括:
-
网络剪枝(Pruning)
-
量化(Quantization)
-
知识提炼(Knowledge Distillation)
其中,知识提炼是一种高效且易于实现的方法,能够让一个“小模型(学生)”在大模型(教师)的指导下学习,从而保持性能的同时大幅减少计算资源消耗。
二、知识提炼的核心思想
知识提炼(Knowledge Distillation)最早由 Hinton 等人于 2015 年提出,其核心思想如下:
-
构建一个性能强的大模型,作为“教师模型(Teacher Model)”;
-
训练一个轻量的小模型,作为“学生模型(Student Model)”;
-
学生模型不仅学习真实标签(hard label),还要模仿教师模型的输出(soft label);
-
教师模型输出的 soft label 包含了样本间的“类间关系”等隐藏知识。
通俗理解:
教师模型输出的概率分布包含了更多的“知识”,学生模型模仿这种分布,就像学生不只学习考试答案,还要理解老师是如何思考的。
三、图示理解
真实标签 y↓+----------+| Teacher | => soft label z_T+----------+↓+----------+| Student | => 模拟 z_T + y+----------+
学生模型的目标是同时:
-
拟合真实标签(监督学习常规)
-
模拟教师模型的输出(提取知识)
四、知识提炼的优势
| 优势 | 描述 |
|---|---|
| 性能提升 | 在模型尺寸不变的前提下,准确率通常显著提升 |
| 参数更少 | 学生模型通常更小、更轻便 |
| 训练更快 | 学生模型收敛更快,因为学习目标更具体 |
| 迁移能力强 | 可以用于跨结构的迁移,例如 CNN → Transformer |
第二部分(加强版):Hinton 知识提炼机制的深入解析
1. 背景复盘:为什么用教师模型的输出?
传统监督学习里,我们用one-hot标签训练模型,比如猫狗分类,标签向量是:
y=[0,1,0,0,0](假设第2类是正确类别)
但这其实只告诉模型:
-
“正确类别是第2类”;
-
“其他类别都不对”。
它没有告诉模型:
-
第3类和第4类与第2类有多相似;
-
哪些类别容易混淆,哪些完全不同。
教师模型输出的是一个概率分布:
q=[0.1,0.7,0.1,0.05,0.05]
这表示它认为第2类最可能,但第1类和第3类也有一定可能,带来了更多“类别间的关系信息”,这就是暗知识(Dark Knowledge)。
学生模型学习这个概率分布,能学到:
-
类别间相似性的知识;
-
更丰富的语义结构。
2. Softmax 函数与温度调节的数学细节
2.1 标准 Softmax
假设某输入样本,模型输出 logits(未归一化的得分向量):
z=[z1,z2,…,zn]
Softmax 转换成概率:
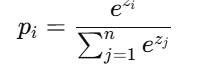
这保证所有 pi 之和为 1,且最大值对应预测类别。
2.2 引入温度系数 TTT
温度调节是通过除以温度参数 TTT 来调整 logits 的“平滑度”:
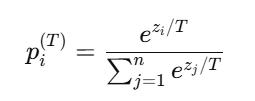
-
当 T=1 时,是正常 softmax;
-
当 T>1时,所有概率趋向均匀分布,分布更“软化”;
-
当 T<1时,分布更“尖锐”,趋近 one-hot。
2.3 数学意义
温度调节后的 softmax 的梯度尺度和概率分布的形状都会变化:
-
分布更平滑,教师输出中小概率类别的信息更明显;
-
梯度变小,因此需要在损失函数中乘以 T2T^2T2 保持梯度大小。
3. KL 散度作为相似度度量
知识提炼中用来衡量学生和教师预测概率分布差异的主要指标是 KL 散度(Kullback-Leibler Divergence)。
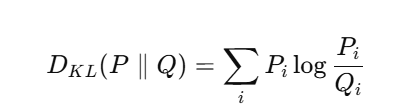
-
P通常是教师模型的软标签分布 qteacher(T)
-
Q 是学生模型的软标签分布 qstudent(T)
KL 散度越小,说明两分布越接近,学生更好地“模仿”教师。
4. 完整损失函数推导
训练学生模型的目标是最小化:
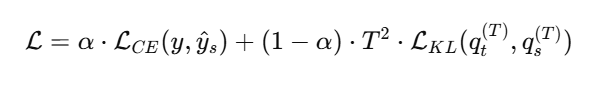
-
第一项是学生对真实标签的交叉熵损失,确保学习基础知识;
-
第二项是学生模仿教师软标签的 KL 散度损失,提取暗知识;
-
T2 是梯度缩放因子;
-
α 控制两部分权重,通常 0.5~0.9。
5. 为什么要结合真实标签和软标签?
-
仅用真实标签训练,学生模型效果差,学习不到类别间信息;
-
仅用软标签训练,软标签虽然包含暗知识,但有噪声,可能导致欠拟合;
-
两者结合,既保证模型对真是标签的准确学习,也能从教师软标签中获取更多细节和类别关系。
6. 举个具体的数值例子
假设某样本的教师 logits 是:
z=[10,2,1]
温度 T=2T = 2T=2 时,计算 softmax 概率:

具体计算:
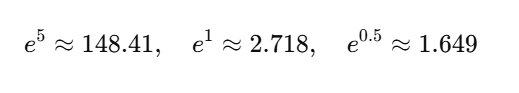
总和约为:
148.41+2.718+1.649=152.78148.41 + 2.718 + 1.649 = 152.78148.41+2.718+1.649=152.78
所以对应的概率:
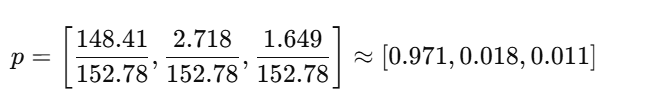
相比温度为1时,概率分布更“平滑”,其他类别概率增加,暗含类别相似度信息。
7. 为什么乘以 T2 调整梯度?
从梯度角度看,softmax 输出中分母含有 T,梯度规模会缩小,直接训练效果变差。
论文中证明,乘以 T2 能使梯度大小恢复到合理水平,防止温度增大时梯度过小影响收敛。
第三部分:Soft Label 与 Temperature 的数学原理、可视化和调参技巧
1. Soft Label 的数学原理
1.1 什么是 Soft Label?
-
硬标签(Hard Label) 是传统的 one-hot 标签,比如:
y=[0,0,1,0] -
软标签(Soft Label) 是教师模型经过 softmax(尤其是带温度调节的 softmax)后产生的概率分布:
q=[0.1,0.3,0.5,0.1]它不仅告诉模型“哪个类别是对的”,还告诉模型“对每个类别的置信度”。
1.2 Soft Label 的优势
-
包含类别之间的相似性信息,模型学习更细致的决策边界;
-
有利于提升学生模型的泛化能力,减少过拟合;
-
传递教师模型的“暗知识”。
2. Temperature 的数学原理与影响
2.1 Softmax 函数带温度 T 的定义
对于 logits 向量 z=[z1,...,zn],softmax with temperature:
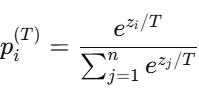
2.2 温度对概率分布的影响
-
T=1 :标准 softmax,正常概率分布;
-
T>1 :概率分布更平滑,降低最大类别概率,增加其他类别概率,信息更丰富;
-
T<1 :概率分布更尖锐,趋近 one-hot。
2.3 可视化示意(假设3类 logits)
| 类别 | logits | Softmax T=1 | Softmax T=3 |
|---|---|---|---|
| A | 3 | 0.84 | 0.53 |
| B | 1 | 0.11 | 0.24 |
| C | 0 | 0.05 | 0.23 |
随着 T 增大,概率趋向均匀,更“软”。
3. Temperature 调节的梯度效应
-
当 T 增大时,softmax 输出趋于均匀分布,导致输出概率对 logits 的梯度变小;
-
为了补偿梯度变小的影响,训练时损失项中乘以 T2,保持梯度量级;
-
这个乘法的数学证明在 Hinton 论文中详细说明。
4. 实际调参建议
| 参数 | 说明 | 建议范围 | 作用 |
|---|---|---|---|
| 温度 T | 控制 softmax 平滑程度 | 2 ~ 5 | 提取教师更多暗知识,平滑输出 |
| 权重 α | 真实标签损失和软标签损失权重 | 0.5 ~ 0.9 | 平衡硬标签监督和软标签监督 |
-
先选 T=3,α=0.7 作为默认值;
-
若学生学习缓慢,尝试调大 T;
-
若学生效果偏差大,尝试调小 T;
-
权重 α 可根据学生模型容量调节。
5. Soft Label 在训练中的作用示例
-
训练初期,学生模型受软标签引导,更快学到类别间相似关系;
-
训练后期,硬标签保证学生收敛到正确分类;
-
整体提高模型的鲁棒性和泛化能力。
第四部分:知识提炼的主要策略与发展分支
1. 输出层蒸馏(Response-Based Distillation)
核心理念:
输出层蒸馏是最基础、最经典的一种知识提炼方式。它的核心思想是:
用**教师模型输出的 soft label(概率分布)**去训练学生模型,而不是传统的 one-hot label。
数学形式:
-
软标签定义(带温度 softmax):
对于教师模型的输出 logits z,引入温度参数 T,得到 soft label
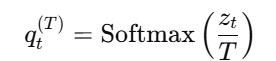
-
同理,学生模型输出 logits 为 zs,其 softmax 为:

-
损失函数:
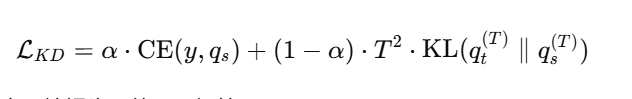
-
第一项是普通的交叉熵损失,使用硬标签;
-
第二项是 soft label 的 KL 散度损失;
-
T2 是梯度缩放因子(因为 softmax 的梯度在高温度下会缩小)。
-
代表方法:
-
Hinton 等人 2015 年的经典论文《Distilling the Knowledge in a Neural Network》。
-
适用于大多数分类任务,尤其是图像分类、文本分类等。
优点:
-
实现简单,适用于任何网络结构;
-
尤其适合做模型压缩;
-
适用于 CNN、MLP、Transformer 等模型。
缺点:
-
不适用于教师/学生模型结构差异特别大的情况;
-
只蒸馏了输出,忽略了教师的中间层“过程知识”;
-
对复杂任务(如检测、分割、强化学习)信息量不足。
PyTorch 实现核心片段:
import torch.nn.functional as Fdef distillation_loss(student_logits, teacher_logits, labels, T=4.0, alpha=0.7):hard_loss = F.cross_entropy(student_logits, labels) # 硬标签损失soft_loss = F.kl_div(F.log_softmax(student_logits / T, dim=1),F.softmax(teacher_logits / T, dim=1),reduction='batchmean') * (T * T) # soft 标签损失return alpha * hard_loss + (1 - alpha) * soft_loss
适用场景:
-
轻量模型训练(MobileNet、ResNet18);
-
需要压缩部署的大模型;
-
模型蒸馏初学者优选方案;
-
医学图像中的分类任务(病灶判断、异常检测)中也可用。
2. 特征层蒸馏(Feature-Based Distillation)
核心理念
输出层蒸馏只关注最终的 soft label,但一个深度模型在前向传播过程中会在多个中间层提取到大量结构化的信息。特征层蒸馏的目标就是让学生模型模仿教师模型中间层产生的特征图或激活图(activation maps),从而学习“如何处理信息”,而不只是“最终决策”。
数学原理
设:
-
教师模型某一中间层输出特征图为
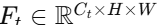
-
学生模型对应层输出为
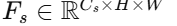
由于 Ct≠Cs,一般需要加入对齐层(1×1卷积)使得维度一致,再计算 L2 损失或MSE 损失:
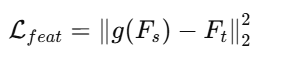
其中 g(⋅)g(\cdot)g(⋅) 是一个通道匹配层(linear 或 conv)。
代表方法:FitNet(Romero et al., 2014)
-
这是第一个系统性使用中间层作为知识来源的 KD 方法;
-
引入了“hint layer”(教师)和“guided layer”(学生);
-
通过加入 MSE 损失监督学生模仿中间层特征。
优点:
-
提取更多“过程知识”;
-
对于视觉任务(分类、分割、检测)具有明显提升;
-
对于教师输出信息不够丰富的任务(如 softmax 输出接近 one-hot)特别有效。
缺点:
-
对教师和学生结构匹配要求较高(中间层需要对齐);
-
通道维度不一致时需要额外适配;
-
大模型中 feature map 通常非常大,训练显存消耗增加。
PyTorch 实现示意
# 假设学生输出为 F_s,教师输出为 F_t
# 维度:B×C×H×W,需要 reshape/conv 对齐通道维度import torch.nn as nnconv_proj = nn.Conv2d(in_channels=F_s.shape[1], out_channels=F_t.shape[1], kernel_size=1)def feature_loss(F_s, F_t):F_s_proj = conv_proj(F_s)return F.mse_loss(F_s_proj, F_t)
可以使用多个中间层,每层都加蒸馏损失再求和或加权求和。
适用场景
-
图像分类任务(特别是轻量化学生模型);
-
目标检测任务(如 Faster R-CNN, YOLO)中的 backbone 提炼;
-
图像分割任务(如 UNet、DeepLab)中用于 encoder 层蒸馏;
-
医学图像分割中的跨模型迁移(教师为大ResNet,学生为轻量CNN)尤其常见。
实战建议
| 策略 | 建议 |
|---|---|
| 特征提取层选择 | 教师中靠近输出的深层最优 |
| 特征对齐方式 | 使用 1x1 卷积或全连接层 |
| 蒸馏损失类型 | L2(MSE)、Smooth L1、Cosine |
| 特征归一化 | 可以加 BN 或 LayerNorm |
3. 关系蒸馏(Relational Knowledge Distillation,RKD)
核心理念:
前两种知识提炼方式都要求学生模型模仿教师模型的具体输出或中间特征,这在教师和学生结构差异较大时会非常困难。
关系蒸馏的核心思想是:
不再直接学习特征,而是学习样本之间的相对关系(如距离、角度、相似性等)。
即:如果教师模型认为样本 xi和 xj 距离近、而 xi和 xk 距离远,那么学生模型也应当有类似的“感知”。
数学形式与构造:
(1)距离保持(Distance-wise Loss):
计算教师模型中,样本 i,j的欧氏距离:
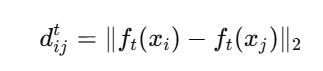
学生模型也计算相应的距离:
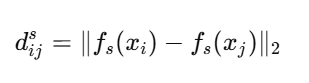
然后最小化两者的差异:
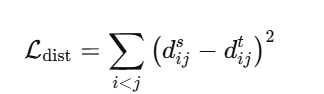
(2)角度保持(Angle-wise Loss):
构建三元组 i,j,ki, ,定义教师模型中两向量的夹角:
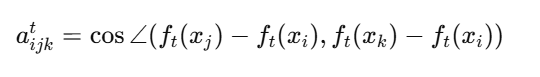
同理学生计算角度 aijksa,损失为:
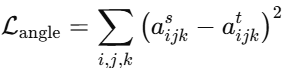
代表方法:
-
RKD(Relational Knowledge Distillation, CVPR 2019):提出了上述两类距离/角度关系;
-
CRD(Contrastive Representation Distillation, ICLR 2020):用对比学习方式提炼关系信息;
-
PKD(Patient KD):提炼教师多个层之间的信息传递关系。
优点:
-
不依赖教师和学生特征结构是否一致;
-
适用于异构架构(如 CNN 教师 → Transformer 学生);
-
能表达更多“任务内结构性”。
缺点:
-
计算复杂度高(关系对数随样本数量平方增长);
-
蒸馏信号间接、泛化效果受限于关系设计;
-
对 batch size 较小的训练不太友好(因 pair/triplet 关系较少)。
PyTorch 实现示意:
以下是基于距离关系的 RKD 实现:
def pairwise_dist(features):n = features.size(0)dist = torch.cdist(features, features, p=2) # B×B 距离矩阵return distdef distance_loss(student_feat, teacher_feat):with torch.no_grad():d_t = pairwise_dist(teacher_feat)mean_t = d_t[d_t > 0].mean()d_t = d_t / mean_td_s = pairwise_dist(student_feat)mean_s = d_s[d_s > 0].mean()d_s = d_s / mean_sloss = F.smooth_l1_loss(d_s, d_t)return loss
可选扩展:加入角度损失、图结构约束等。
适用场景
| 场景 | 原因/建议 |
|---|---|
| 结构差异大的模型(如 ViT ⇄ CNN) | 无需层对齐、特征维度相同 |
| 小样本学习 / 数据不均衡 | 学习样本间的关系信息可以缓解 overfitting |
| 医学图像中“相对特征分布”重要的任务 | 如分类器分不清具体区域,但能感知病灶间的相关性 |
实战技巧:
-
构造 triplet 时要注意采样策略(Hard negative mining 会提升效果);
-
对高维特征做降维或归一化有助于稳定蒸馏;
-
可以与 feature-based 方法联合使用(并行优化)。
4. 注意力蒸馏(Attention-Based Distillation)
核心理念:
注意力蒸馏的主要思想是:
与其直接蒸馏特征本身,不如蒸馏模型关注的位置/区域/通道信息,也就是注意力信息。
教师模型中往往对特定空间区域或通道更关注(如病灶区域、边缘区域),这些关注信息可以帮助学生模型更好地聚焦于关键区域,从而提升性能。
注意力的提取方式(多种):
方法一:激活图的注意力(Activation-based Attention)
来源论文:Attention Transfer (Zagoruyko and Komodakis, CVPR 2017)
-
将中间层特征图做绝对值平方后再求和:
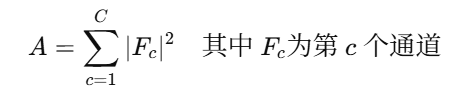
-
得到一个二维 attention map,再进行归一化处理:
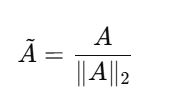
-
对比教师和学生的 attention:
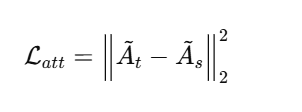
方法二:通道注意力(Channel-based Attention)
-
对每个通道做平均池化得到通道权重;
-
使用 cosine 相似度、KL 散度 或 MSE 计算损失;
-
用于模型结构差异较大的情况(如学生层通道较少)时需通道映射。
方法三:Transformer 中的注意力权重(Self-Attention)
适用于 ViT、Swin Transformer 等结构:
-

-
对多个 head 的注意力进行平均;
-
计算对应的学生注意力损失:
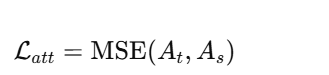
代表方法:
| 名称 | 简介 |
|---|---|
| AT(Attention Transfer) | 最早系统化地使用注意力图进行知识提炼 |
| A2KD(Adaptive Attention KD) | 对 attention 蒸馏进行动态加权 |
| ViTKD、Swin-KD | 将 attention 蒸馏扩展至 Transformer 架构 |
优点:
-
更轻量,蒸馏信号提取成本低;
-
更易于解释,关注区域可视化;
-
在医学图像分割/检测任务中常有较大提升(尤其对边界关注);
-
和 feature-based 可组合使用(feature loss + attention loss)。
缺点:
-
attention map 的质量依赖于教师网络设计;
-
不同结构之间的 attention 定义不一致(CNN vs Transformer);
-
蒸馏信号相对较弱(只有注意力而没有语义细节)。
PyTorch 示例:空间注意力蒸馏
def compute_attention_map(feat): # feat: B x C x H x Watt = feat.pow(2).mean(dim=1, keepdim=True) # 空间 attentionnorm_att = att / (att.sum(dim=(2, 3), keepdim=True) + 1e-6)return norm_attdef attention_loss(student_feat, teacher_feat):att_s = compute_attention_map(student_feat)att_t = compute_attention_map(teacher_feat)return F.mse_loss(att_s, att_t)
适用场景
| 场景 | 说明 |
|---|---|
| 医学图像分割任务 | 注意力能精准定位病灶区域,适合蒸馏 |
| Transformer 模型蒸馏 | 自注意力矩阵能自然被蒸馏 |
| 脑出血边缘区域学习 | 利用注意力提高学生网络对边缘区域的辨识度 |
实战建议
-
可用于中间层或每个 stage 输出;
-
结合输出层蒸馏更有效(总损失 = output loss + attention loss);
-
attention 可视化对调试训练非常有帮助(可以看模型学到了什么)。
5. 多教师蒸馏(Multi-Teacher Distillation)
核心理念:
现实中我们可能拥有多个优秀的预训练模型(例如在不同数据上训练的模型,或结构不同的高性能模型)。
**多教师蒸馏(MTD)**的目标是:
学生模型不仅学习单一教师模型的知识,而是融合多个教师的知识,共同引导学生学习更丰富、更泛化的表示。
基本策略结构
设有 N 个教师模型,输出为 T1,T2,...,TN,学生输出为 S,有以下策略:
策略一:平均融合(Logits Averaging)
直接将多个教师输出的 soft logits 平均,作为学生的监督目标:
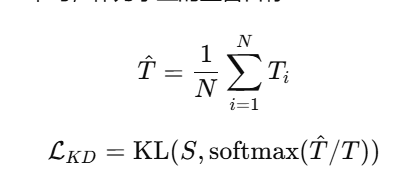
优点:简单直接
缺点:忽略不同教师之间的能力差异
策略二:加权融合(Weighted Averaging)
为不同教师分配不同权重 αi(手动设定或训练得到):
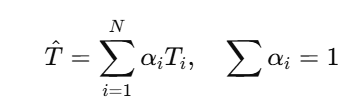
适合教师质量差异明显、或模型结构差异较大的情况。
策略三:自蒸馏与教师选择(Online Multi-Teacher)
来源:DML(Deep Mutual Learning, CVPR 2018)
多个学生模型互为教师,轮流提取彼此知识:
-
每个学生在训练过程中学习来自其他学生的输出;
-
每一步中都更新彼此的参数,相当于双向蒸馏、三角蒸馏。
适用于:
-
无强教师模型的场景;
-
多模型协同训练,提升全体性能。
策略四:图蒸馏(Graph-Based Distillation)
-
构建教师之间的图结构,建模教师间“知识传递”的路径;
-
使用图卷积或图注意力聚合所有教师输出;
-
输出聚合后传给学生学习。
代表方法:
| 方法 | 简介 |
|---|---|
| DML | 学生互为教师的双向蒸馏(CVPR 2018) |
| TRKD | 基于 transformer 的多教师蒸馏框架 |
| GKT | 图结构下的教师蒸馏方式 |
| AKD | 自适应选择最优教师的注意力蒸馏方法 |
优点:
-
能够获得多个模型的综合表达能力;
-
提升学生的泛化能力,特别是不同领域知识融合;
-
适合 ensemble 压缩和异构教师蒸馏场景。
缺点:
-
实现较复杂(特别是动态加权和图建模);
-
多模型推理成本高(训练初期需多个教师并行推理);
-
教师间冲突时,融合策略可能降低性能(需设计教师筛选机制)。
PyTorch 实现示意:平均融合型多教师 KD
def multi_teacher_kd_loss(student_logits, teacher_logits_list, temperature=4.0):# 平均多个教师输出teacher_avg = sum(teacher_logits_list) / len(teacher_logits_list)kd_loss = F.kl_div(F.log_softmax(student_logits / temperature, dim=1),F.softmax(teacher_avg / temperature, dim=1),reduction='batchmean') * (temperature ** 2)return kd_loss
适用场景
| 应用场景 | 推荐理由 |
|---|---|
| 多数据集/多任务知识迁移 | 不同教师在不同任务上训练,合并效果佳 |
| 医学图像多模态融合 | 如 CT、MRI、PET 模型合成统一学生 |
| 结构差异教师合成 | CNN、Transformer 教师模型合一,产出轻量学生 |
| 模型压缩或部署优化 | 将多个大模型集成压缩为一个轻量学生 |
实战建议:
-
如果多个教师性能相差大,建议加权或筛选;
-
教师输出之间差异大时,可用 attention 或 gating 函数融合;
-
可与 feature distillation 或 attention distillation 联合使用。
6. 自蒸馏(Self-Distillation)
核心理念:
前面讲的知识蒸馏方法都依赖一个**“外部教师模型”**。
但在实际情况中,我们有时没有预训练好的大模型可用,或者不方便部署多个模型。
**自蒸馏(Self-Distillation)**的核心思想是:
在一个模型内部进行知识提炼,当前模型的部分输出(或早期训练状态)作为“教师”引导“学生”部分(或后续状态)学习。
主要实现方式
方式一:同一模型不同层之间蒸馏(Intermediate Self-Distillation)
-
把模型的深层输出作为“教师”;
-
把浅层输出作为“学生”;
-
让浅层特征或输出尽量靠近深层输出。
例如,在一个分类网络中:
-
将第4个卷积块的输出作为教师;
-
将第2个卷积块的输出映射成同样维度;
-
然后用 MSE 损失函数约束两者相似。
损失函数形式:
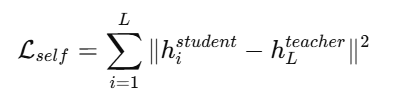
其中 hi是第 i 层的输出,L是最深层。
方式二:不同 epoch 的模型蒸馏(Temporal Self-Distillation)
-
把当前 epoch 模型的输出当作学生;
-
把之前 epoch 的模型(固定权重)当作教师;
-
学生模仿过去某一状态的模型行为。
这种方式有点类似“学生向自己请教”,让当前模型别忘了之前学到的好知识,避免过拟合。
方式三:多头输出自蒸馏(Multi-head Self-Distillation)
-
为同一模型添加多个分支(auxiliary heads),例如在不同位置添加分类器;
-
主分支作为“教师”,辅助分支为“学生”,彼此互相引导学习;
-
提高整个模型训练稳定性和特征共享能力。
代表方法:
| 方法 | 简介 |
|---|---|
| BYOT (Bring Your Own Teacher, NeurIPS 2020) | 模型内部多个预测头互为师生 |
| DEKD (Deep Embedding KD, CVPR 2021) | 不同层输出相互约束,辅助深层学习 |
| Revisit KD | 利用同一模型多个阶段输出做训练信号的反向传播 |
优点:
-
不需要外部教师模型,部署简单;
-
无额外推理成本;
-
提高模型收敛速度与性能;
-
提升浅层特征的表达能力(→ 提高中小模型的性能);
-
能配合 Mixup、数据增强、Dropout 进一步提升效果。
缺点:
-
蒸馏信号可能不够强,需配合设计辅助机制;
-
若模型结构过于简单,蒸馏效果不明显;
-
多头/多层输出时,可能引入训练不稳定性。
PyTorch 示例:中间层自蒸馏
def self_distillation_loss(features_list):teacher_feat = features_list[-1].detach() # 最深层作为teacherloss = 0.0for i in range(len(features_list) - 1):student_feat = features_list[i]loss += F.mse_loss(student_feat, teacher_feat)return loss
适用场景
| 场景 | 应用理由 |
|---|---|
| 没有教师模型 | 自蒸馏可作为轻量级替代 |
| 单模型部署限制 | 不增加推理复杂度 |
| 医学图像训练数据小 | 模型内结构间互相学习,缓解过拟合 |
| Transformer 微调(如 ViT) | 自蒸馏对不同 block 输出进行一致性约束效果显著 |
实战技巧
-
尽量配合辅助损失(如分类 loss + 自蒸馏 loss);
-
模型结构需支持多输出或中间层抽取;
-
可结合 warmup 阶段控制蒸馏信号引入节奏。
7. 对比蒸馏(Contrastive Distillation)
核心理念:
对比蒸馏结合了对比学习(Contrastive Learning)与知识蒸馏的优点。
传统 KD 往往要求学生输出模仿教师某个具体的目标(如 softmax、特征图),
但对比蒸馏的目标是:
保持学生模型在表示空间中与教师模型的结构一致性:即相似样本之间的距离近,不相似样本之间的距离远。
这种方式不直接模仿具体输出,而是模仿教师在表示空间中的“相对关系”。
举个例子:
-
给定一张医学图像 x,
-
教师提取特征 fT(x),学生提取特征 fS(x),
-
对于同类别样本 xi,应有:
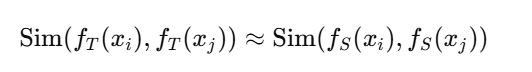
-
而不同类别样本的相似性应尽可能低。
这种方式本质上是用教师的“结构性表示”来指导学生。
实现方式概览:
方法一:Teacher-Guided Contrastive Loss
典型公式(以 InfoNCE 为基础):
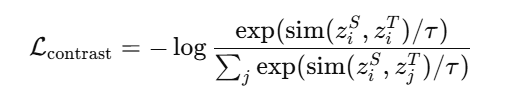
其中:
-
ziS:学生模型提取的 anchor 特征;
-
ziT:教师模型中 anchor 的正样本(正对);
-
其他 zjT:教师模型中的负样本;
-
τ:温度系数。
方法二:Relational Knowledge Distillation (RKD)
来源:ECCV 2018
使用特征之间的距离关系(欧式距离/角度)进行对比:
-
计算样本对之间的距离差异:
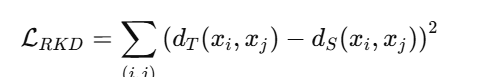
-
保持角度方向一致性(可选):
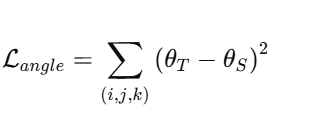
方法三:CRD(Contrastive Representation Distillation)
来源:ICLR 2021
-
使用大型特征字典(memory bank),采样正负样本;
-
引入投影头将学生特征映射到与教师相同维度;
-
在投影空间中进行对比。
优势在于:可以更稳定地学习“结构知识”,比直接 mimick 更鲁棒。
PyTorch 示例(InfoNCE形式)
import torch.nn.functional as Fdef contrastive_kd_loss(student_feat, teacher_feat, temperature=0.07):# 假设特征 shape: B x D,归一化student_feat = F.normalize(student_feat, dim=1)teacher_feat = F.normalize(teacher_feat, dim=1)logits = torch.matmul(student_feat, teacher_feat.T) / temperaturelabels = torch.arange(student_feat.size(0)).to(logits.device)return F.cross_entropy(logits, labels)
优点:
-
不依赖具体标签,适合无监督或自监督任务;
-
更关注样本之间的结构表示,对分类边界更敏感;
-
在特征蒸馏中表现优越;
-
对图像检索、医学图像嵌入任务尤其有效。
缺点:
-
训练成本较高(需负样本对比/内存字典);
-
需要对比学习框架支持,代码实现复杂;
-
温度超参数 τ\tauτ 较为敏感;
-
与数据增强策略关系紧密,需谨慎设计。
适用场景
| 场景 | 理由 |
|---|---|
| 无监督学习 | 不依赖标签,直接使用对比关系进行知识提取 |
| 医学图像检索、嵌入式特征学习 | 保留语义关系更重要 |
| 图神经网络、Transformer 等高维结构蒸馏 | 表征空间关系更关键 |
| 高分辨率图像处理任务 | 对特征表示结构敏感,提升泛化能力 |
总结
对比蒸馏强调结构性、相对性,是目前较先进的一种蒸馏方式,特别适合与自监督、对比学习结合使用。


)






repeater详解)

)
版本发布情况)
)





