复习日
作业:day43的时候我们安排大家对自己找的数据集用简单cnn训练,现在可以尝试下借助这几天的知识来实现精度的进一步提高
还是继续用上次的街头食物分类数据集,既然已经统一图片尺寸到了140x140,所以这次选用轻量化模型 MobileNetV3 ,问就是这个尺寸的图片可以直接进入这个模型训练,而且轻量化训练参数还更少,多是一件美事啊(
前面预处理和数据加载还是和之前一样的
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import torchvision.models as models
from torch.utils.data import Dataset, DataLoader, random_split
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import os# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
# 图像尺寸统一成140x140
class PhotoResizer:def __init__(self, target_size=140, fill_color=114): # target_size: 目标正方形尺寸,fill_color: 填充使用的灰度值self.target_size = target_sizeself.fill_color = fill_color# 预定义转换方法self.to_tensor = transforms.ToTensor()self.normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])def __call__(self, img):"""智能处理流程:1. 对小图像进行填充,对大图像进行智能裁剪2. 保持长宽比的情况下进行保护性处理"""w, h = img.sizeif w == h == self.target_size: # 情况1:已经是目标尺寸pass # 无需处理elif min(w, h) < self.target_size: # 情况2:至少有一个维度小于目标尺寸(需要填充)img = self.padding_resize(img)else: # 情况3:两个维度都大于目标尺寸(智能裁剪)img = self.crop_resize(img)# 最终统一转换return self.normalize(self.to_tensor(img))def padding_resize(self, img): # 等比缩放后居中填充不足部分w, h = img.sizescale = self.target_size / min(w, h)new_w, new_h = int(w * scale), int(h * scale)img = img.resize((new_w, new_h), Image.BILINEAR)# 等比缩放 + 居中填充# 计算需要填充的像素数(4个值:左、上、右、下)pad_left = (self.target_size - new_w) // 2pad_top = (self.target_size - new_h) // 2pad_right = self.target_size - new_w - pad_leftpad_bottom = self.target_size - new_h - pad_topreturn transforms.functional.pad(img, [pad_left, pad_top, pad_right, pad_bottom], self.fill_color)def crop_resize(self, img): # 等比缩放后中心裁剪w, h = img.sizeratio = w / h# 计算新尺寸(保护长边)if ratio < 0.9: # 竖图new_size = (self.target_size, int(h * self.target_size / w))elif ratio > 1.1: # 横图new_size = (int(w * self.target_size / h), self.target_size)else: # 近似正方形new_size = (self.target_size, self.target_size)img = img.resize(new_size, Image.BILINEAR)return transforms.functional.center_crop(img, self.target_size)# 训练集测试集预处理
train_transform = transforms.Compose([PhotoResizer(target_size=140), # 自动处理所有情况transforms.RandomHorizontalFlip(), # 随机水平翻转图像(概率0.5)transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), # 随机颜色抖动:亮度、对比度、饱和度和色调随机变化transforms.RandomRotation(15), # 随机旋转图像(最大角度15度)
])test_transform = transforms.Compose([PhotoResizer(target_size=140)
])# 2. 创建dataset和dataloader实例
class StreetFoodDataset(Dataset):def __init__(self, root_dir, transform=None):self.root_dir = root_dirself.transform = transformself.image_paths = []self.labels = []self.class_to_idx = {}# 遍历目录获取类别映射classes = sorted(entry.name for entry in os.scandir(root_dir) if entry.is_dir())self.class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}# 收集图像路径和标签for class_name in classes:class_dir = os.path.join(root_dir, class_name)for img_name in os.listdir(class_dir):if img_name.lower().endswith(('.png', '.jpg', '.jpeg')):self.image_paths.append(os.path.join(class_dir, img_name))self.labels.append(self.class_to_idx[class_name])def __len__(self):return len(self.image_paths)def __getitem__(self, idx):img_path = self.image_paths[idx]image = Image.open(img_path).convert('RGB')label = self.labels[idx]if self.transform:image = self.transform(image)return image, label# 数据集路径(Kaggle路径示例)
dataset_path = '/kaggle/input/popular-street-foods/popular_street_foods/dataset'# 创建数据集实例
# 先创建基础数据集
full_dataset = StreetFoodDataset(root_dir=dataset_path)# 分割数据集
train_size = int(0.8 * len(full_dataset))
test_size = len(full_dataset) - train_size
train_dataset, test_dataset = random_split(full_dataset, [train_size, test_size])
train_dataset.dataset.transform = train_transform
test_dataset.dataset.transform = test_transform# 创建数据加载器
train_loader = DataLoader(train_dataset,batch_size=32,shuffle=True,num_workers=2,pin_memory=True
)test_loader = DataLoader(test_dataset,batch_size=32,shuffle=False,num_workers=2,pin_memory=True
)CBAM模块定义
# 3. CBAM模块定义
# 定义通道注意力
class ChannelAttention(nn.Module):def __init__(self, in_channels, ratio=16):"""通道注意力机制初始化参数:in_channels: 输入特征图的通道数ratio: 降维比例,用于减少参数量"""super().__init__()# 全局平均池化,将每个通道的特征图压缩为1x1,保留通道间的平均值信息self.avg_pool = nn.AdaptiveAvgPool2d(1)# 全局最大池化,将每个通道的特征图压缩为1x1,保留通道间的最显著特征self.max_pool = nn.AdaptiveMaxPool2d(1)# 共享全连接层,用于学习通道间的关系# 先降维(除以ratio),再通过ReLU激活,最后升维回原始通道数self.ratio = max(4, in_channels // ratio) # 确保至少降维到4self.fc = nn.Sequential(nn.Linear(in_channels, self.ratio, bias=False), # 降维层nn.ReLU(), # 非线性激活函数nn.Linear(self.ratio, in_channels, bias=False) # 升维层)# Sigmoid函数将输出映射到0-1之间,作为各通道的权重self.sigmoid = nn.Sigmoid()def forward(self, x):"""前向传播函数参数:x: 输入特征图,形状为 [batch_size, channels, height, width]返回:调整后的特征图,通道权重已应用"""# 获取输入特征图的维度信息,这是一种元组的解包写法b, c, h, w = x.shape# 对平均池化结果进行处理:展平后通过全连接网络avg_out = self.fc(self.avg_pool(x).view(b, c))# 对最大池化结果进行处理:展平后通过全连接网络max_out = self.fc(self.max_pool(x).view(b, c))# 将平均池化和最大池化的结果相加并通过sigmoid函数得到通道权重attention = self.sigmoid(avg_out + max_out).view(b, c, 1, 1)# 将注意力权重与原始特征相乘,增强重要通道,抑制不重要通道return x * attention #这个运算是pytorch的广播机制# 空间注意力模块
class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super().__init__()self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):# 通道维度池化avg_out = torch.mean(x, dim=1, keepdim=True) # 平均池化:(B,1,H,W)max_out, _ = torch.max(x, dim=1, keepdim=True) # 最大池化:(B,1,H,W)pool_out = torch.cat([avg_out, max_out], dim=1) # 拼接:(B,2,H,W)attention = self.conv(pool_out) # 卷积提取空间特征return x * self.sigmoid(attention) # 特征与空间权重相乘# CBAM模块
class CBAM(nn.Module):def __init__(self, in_channels, ratio=16, kernel_size=7):super().__init__()self.channel_attn = ChannelAttention(in_channels, ratio)self.spatial_attn = SpatialAttention(kernel_size) def forward(self, x):x = self.channel_attn(x)x = self.spatial_attn(x)return x在模型修改这一部分,原先构想的是在每一个残差块后面都加入CBAM模块,但是 MobileNetV3 有十五个残差块啊,当时没有想到这样操作铁定会造成过拟合,训练集准确旅奇高但测试集准确率简直一坨
最后是考虑在第3、6、9、12、15个残差块后面插入CBAM模块,情况确实改善了很多
# 4. 插入CBAM的MobileNetV3-large模型定义修改
from torchvision.models.mobilenetv3 import InvertedResidual
class MobileNetV3_CBAM(nn.Module):def __init__(self, num_classes=20, pretrained=True, cbam_ratio=None, cbam_kernel=7):super().__init__()# 加载预训练模型self.backbone = models.mobilenet_v3_large(pretrained=True)# 首层输入不用改,这个网络本就匹配140x140# 残差块太多了,在3、6、9、12、15个残差块后面插入CBAM模块self.cbam_layers = nn.ModuleDict()self.cbam_positions = [3, 6, 9, 12, 15]cbam_count = 0for idx, layer in enumerate(self.backbone.features):if isinstance(layer, InvertedResidual):if cbam_count in self.cbam_positions:# 获取当前层的实际输出通道数out_channels = layer.block[-1].out_channels # 取最后一个卷积的输出通道self.cbam_layers[f"cbam_{idx}"] = CBAM(out_channels)cbam_count += 1# 修改分类头self.backbone.classifier = nn.Sequential(nn.Linear(960, 1280), # MobileNetV3-Large的倒数第二层维度nn.Hardswish(),nn.Dropout(0.2),nn.Linear(1280, num_classes))def forward(self, x):# 提取特征cbam_count = 0for idx, layer in enumerate(self.backbone.features):x = layer(x)if isinstance(layer, InvertedResidual):if cbam_count in self.cbam_positions:x = self.cbam_layers[f"cbam_{idx}"](x)cbam_count += 1# 全局池化和分类x = torch.mean(x, dim=[2, 3]) # 替代AdaptiveAvgPool2dx = self.backbone.classifier(x)return x训练部分依旧采用之前的分段微调和学习率调整
import time# ======================================================================
# 5. 结合了分阶段策略和详细打印的训练函数
# ======================================================================
def set_trainable_layers(model, trainable_parts):print(f"\n---> 解冻以下部分并设为可训练: {trainable_parts}")for name, param in model.named_parameters():param.requires_grad = Falsefor part in trainable_parts:if part in name:param.requires_grad = Truebreakdef train_staged_finetuning(model, criterion, train_loader, test_loader, device, epochs):optimizer = None# 初始化历史记录列表,与你的要求一致all_iter_losses, iter_indices = [], []train_acc_history, test_acc_history = [], []train_loss_history, test_loss_history = [], []for epoch in range(1, epochs + 1):epoch_start_time = time.time()# --- 动态调整学习率和冻结层 ---if epoch == 1:print("\n" + "="*50 + "\n **阶段 1:训练注意力模块和分类头**\n" + "="*50)set_trainable_layers(model, ["cbam_layers", "backbone.classifier"])optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=1e-4, weight_decay=1e-4)elif epoch == 6:print("\n" + "="*50 + "\n **阶段 2:解冻高层特征提取层**\n" + "="*50)set_trainable_layers(model, ["cbam_layers", "backbone.classifier", "backbone.features.16", "backbone.features.17"])optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=5e-5, weight_decay=1e-4)elif epoch == 21:print("\n" + "="*50 + "\n **阶段 3:解冻所有层,进行全局微调**\n" + "="*50)for param in model.parameters(): param.requires_grad = Trueoptimizer = optim.Adam(model.parameters(), lr=1e-5, weight_decay=1e-4)# --- 训练循环 ---model.train()running_loss, correct, total = 0.0, 0, 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 记录每个iteration的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append((epoch - 1) * len(train_loader) + batch_idx + 1)running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 按你的要求,每100个batch打印一次if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_loss_history.append(epoch_train_loss)train_acc_history.append(epoch_train_acc)# --- 测试循环 ---model.eval()test_loss, correct_test, total_test = 0, 0, 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testtest_loss_history.append(epoch_test_loss)test_acc_history.append(epoch_test_acc)# 打印每个epoch的最终结果print(f'Epoch {epoch}/{epochs} 完成 | 耗时: {time.time() - epoch_start_time:.2f}s | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 训练结束后调用绘图函数print("\n训练完成! 开始绘制结果图表...")plot_iter_losses(all_iter_losses, iter_indices)plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)# 返回最终的测试准确率return epoch_test_acc# ======================================================================
# 6. 绘图函数定义
# ======================================================================
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch number)')plt.ylabel('Loss')plt.title('Every Iteration Loss')plt.legend()plt.grid(True)plt.tight_layout()plt.show()def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='train_accuracy')plt.plot(epochs, test_acc, 'r-', label='test_accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy (%)')plt.title('Accuracy for train and test')plt.legend(); plt.grid(True)plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='train_loss')plt.plot(epochs, test_loss, 'r-', label='test_loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.title('Loss for train and test')plt.legend(); plt.grid(True)plt.tight_layout()plt.show()# ======================================================================
# 7. 执行训练
# ======================================================================
model = MobileNetV3_CBAM().to(device)
criterion = nn.CrossEntropyLoss()
epochs = 50print("开始使用带分阶段微调策略的MobileNetV3+CBAM模型进行训练...")
final_accuracy = train_staged_finetuning(model, criterion, train_loader, test_loader, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")结果也还将就吧
开始使用带分阶段微调策略的MobileNetV3+CBAM模型进行训练...==================================================**阶段 1:训练注意力模块和分类头**
==================================================---> 解冻以下部分并设为可训练: ['cbam_layers', 'backbone.classifier']
Epoch 1/50 完成 | 耗时: 7.65s | 训练准确率: 11.98% | 测试准确率: 5.17%
Epoch 2/50 完成 | 耗时: 4.51s | 训练准确率: 25.72% | 测试准确率: 5.17%
Epoch 3/50 完成 | 耗时: 4.55s | 训练准确率: 30.76% | 测试准确率: 6.39%
Epoch 4/50 完成 | 耗时: 4.53s | 训练准确率: 35.69% | 测试准确率: 20.00%
Epoch 5/50 完成 | 耗时: 4.56s | 训练准确率: 39.64% | 测试准确率: 34.15%==================================================**阶段 2:解冻高层特征提取层**
==================================================---> 解冻以下部分并设为可训练: ['cbam_layers', 'backbone.classifier', 'backbone.features.16', 'backbone.features.17']
Epoch 6/50 完成 | 耗时: 4.53s | 训练准确率: 43.93% | 测试准确率: 35.92%
Epoch 7/50 完成 | 耗时: 4.49s | 训练准确率: 45.25% | 测试准确率: 39.32%
Epoch 8/50 完成 | 耗时: 4.57s | 训练准确率: 47.16% | 测试准确率: 39.05%
Epoch 9/50 完成 | 耗时: 4.48s | 训练准确率: 48.35% | 测试准确率: 41.09%
Epoch 10/50 完成 | 耗时: 4.59s | 训练准确率: 48.62% | 测试准确率: 40.54%
Epoch 11/50 完成 | 耗时: 4.61s | 训练准确率: 49.61% | 测试准确率: 43.13%
Epoch 12/50 完成 | 耗时: 4.55s | 训练准确率: 51.62% | 测试准确率: 41.22%
Epoch 13/50 完成 | 耗时: 4.59s | 训练准确率: 52.81% | 测试准确率: 42.18%
Epoch 14/50 完成 | 耗时: 4.70s | 训练准确率: 53.25% | 测试准确率: 43.40%
Epoch 15/50 完成 | 耗时: 5.03s | 训练准确率: 54.13% | 测试准确率: 43.27%
Epoch 16/50 完成 | 耗时: 4.64s | 训练准确率: 55.84% | 测试准确率: 43.95%
Epoch 17/50 完成 | 耗时: 4.68s | 训练准确率: 57.26% | 测试准确率: 44.63%
Epoch 18/50 完成 | 耗时: 4.61s | 训练准确率: 57.54% | 测试准确率: 44.90%
Epoch 19/50 完成 | 耗时: 4.41s | 训练准确率: 57.81% | 测试准确率: 45.85%
Epoch 20/50 完成 | 耗时: 4.50s | 训练准确率: 58.46% | 测试准确率: 45.71%==================================================**阶段 3:解冻所有层,进行全局微调**
==================================================
Epoch 21/50 完成 | 耗时: 5.95s | 训练准确率: 61.62% | 测试准确率: 48.44%
Epoch 22/50 完成 | 耗时: 6.09s | 训练准确率: 65.67% | 测试准确率: 50.07%
Epoch 23/50 完成 | 耗时: 5.87s | 训练准确率: 68.46% | 测试准确率: 52.11%
Epoch 24/50 完成 | 耗时: 5.92s | 训练准确率: 70.60% | 测试准确率: 53.61%
Epoch 25/50 完成 | 耗时: 5.95s | 训练准确率: 72.88% | 测试准确率: 55.37%
Epoch 26/50 完成 | 耗时: 6.02s | 训练准确率: 74.72% | 测试准确率: 55.92%
Epoch 27/50 完成 | 耗时: 5.94s | 训练准确率: 75.64% | 测试准确率: 56.87%
Epoch 28/50 完成 | 耗时: 5.96s | 训练准确率: 77.58% | 测试准确率: 56.87%
Epoch 29/50 完成 | 耗时: 5.81s | 训练准确率: 79.86% | 测试准确率: 57.55%
Epoch 30/50 完成 | 耗时: 5.89s | 训练准确率: 79.93% | 测试准确率: 58.64%
Epoch 31/50 完成 | 耗时: 5.87s | 训练准确率: 81.29% | 测试准确率: 58.23%
Epoch 32/50 完成 | 耗时: 6.00s | 训练准确率: 84.04% | 测试准确率: 58.64%
Epoch 33/50 完成 | 耗时: 5.88s | 训练准确率: 84.55% | 测试准确率: 60.00%
Epoch 34/50 完成 | 耗时: 5.98s | 训练准确率: 86.36% | 测试准确率: 59.05%
Epoch 35/50 完成 | 耗时: 5.88s | 训练准确率: 87.41% | 测试准确率: 60.41%
Epoch 36/50 完成 | 耗时: 5.93s | 训练准确率: 88.53% | 测试准确率: 60.68%
Epoch 37/50 完成 | 耗时: 6.10s | 训练准确率: 89.42% | 测试准确率: 60.41%
Epoch 38/50 完成 | 耗时: 5.95s | 训练准确率: 91.22% | 测试准确率: 60.82%
Epoch 39/50 完成 | 耗时: 5.87s | 训练准确率: 91.05% | 测试准确率: 61.50%
Epoch 40/50 完成 | 耗时: 6.01s | 训练准确率: 91.94% | 测试准确率: 61.50%
Epoch 41/50 完成 | 耗时: 6.04s | 训练准确率: 92.82% | 测试准确率: 61.90%
Epoch 42/50 完成 | 耗时: 6.04s | 训练准确率: 93.60% | 测试准确率: 61.50%
Epoch 43/50 完成 | 耗时: 6.07s | 训练准确率: 92.72% | 测试准确率: 62.31%
Epoch 44/50 完成 | 耗时: 6.02s | 训练准确率: 94.93% | 测试准确率: 62.86%
Epoch 45/50 完成 | 耗时: 5.89s | 训练准确率: 96.19% | 测试准确率: 62.72%
Epoch 46/50 完成 | 耗时: 6.03s | 训练准确率: 96.09% | 测试准确率: 62.59%
Epoch 47/50 完成 | 耗时: 5.98s | 训练准确率: 96.33% | 测试准确率: 61.90%
Epoch 48/50 完成 | 耗时: 6.08s | 训练准确率: 97.52% | 测试准确率: 62.99%
Epoch 49/50 完成 | 耗时: 5.94s | 训练准确率: 97.11% | 测试准确率: 62.99%
Epoch 50/50 完成 | 耗时: 5.94s | 训练准确率: 97.38% | 测试准确率: 62.59%训练完成! 开始绘制结果图表...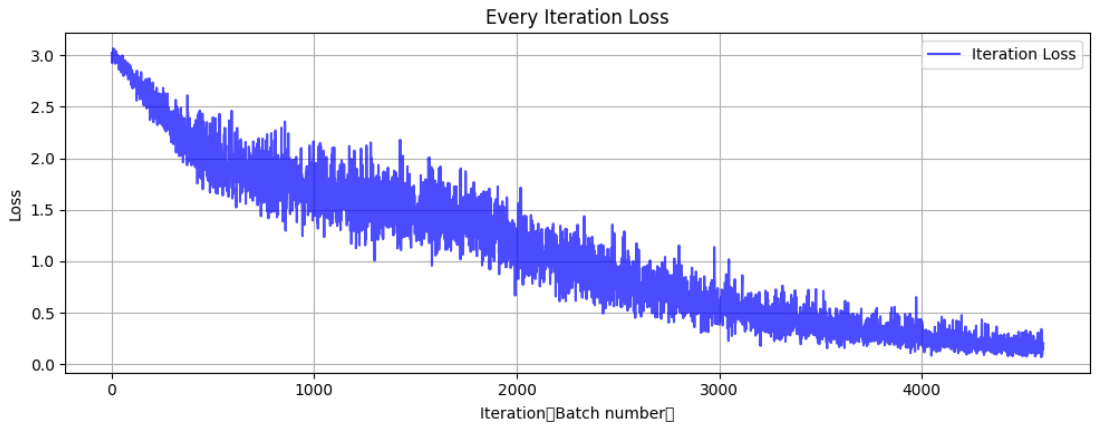
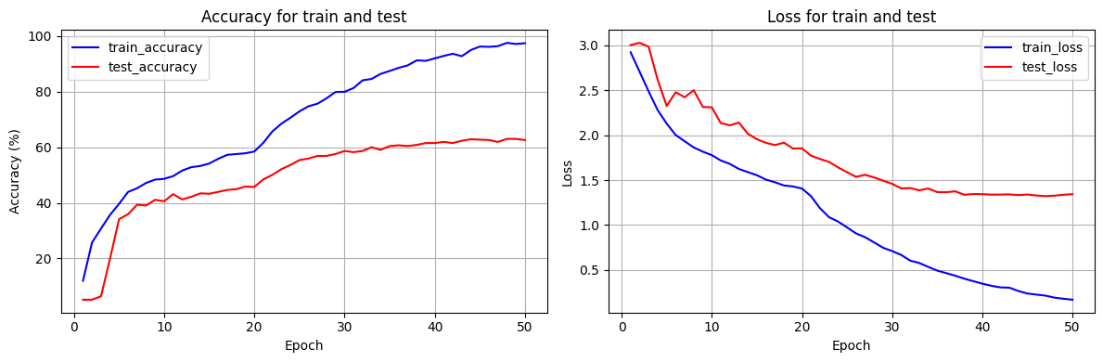
也不算太高,但至少比之前用自定义CNN网络训练来的效果好(突然想到之前效果不好可能也是网络构造复杂过拟合了,当时没有可视化细看,遗憾)
和之前一样,用Grad-CAM可视化,改了点细节
import torch.nn.functional as F
model.eval()# Grad-CAM实现
class GradCAM:def __init__(self, model, target_layer):self.model = modelself.target_layer = target_layerself.gradients = Noneself.activations = None# 支持直接传入层对象或层名称(字符串)if isinstance(target_layer, str):self.target_layer = self._find_layer_by_name(target_layer)else:self.target_layer = target_layer # 假设已经是层对象 # 注册钩子,用于获取目标层的前向传播输出和反向传播梯度self.register_hooks()def _find_layer_by_name(self, layer_name):"""根据名称查找层对象"""for name, layer in self.model.named_modules():if name == layer_name:return layerraise ValueError(f"Target layer '{layer_name}' not found in model.") def register_hooks(self):# 前向钩子函数,在目标层前向传播后被调用,保存目标层的输出(激活值)def forward_hook(module, input, output):self.activations = output.detach()# 反向钩子函数,在目标层反向传播后被调用,保存目标层的梯度def backward_hook(module, grad_input, grad_output):self.gradients = grad_output[0].detach()# 在目标层注册前向钩子和反向钩子self.target_layer.register_forward_hook(forward_hook)self.target_layer.register_backward_hook(backward_hook)def generate_cam(self, input_image, target_class=None):# 前向传播,得到模型输出model_output = self.model(input_image)if target_class is None:# 如果未指定目标类别,则取模型预测概率最大的类别作为目标类别target_class = torch.argmax(model_output, dim=1).item()# 清除模型梯度,避免之前的梯度影响self.model.zero_grad()# 反向传播,构造one-hot向量,使得目标类别对应的梯度为1,其余为0,然后进行反向传播计算梯度one_hot = torch.zeros_like(model_output)one_hot[0, target_class] = 1model_output.backward(gradient=one_hot)# 获取之前保存的目标层的梯度和激活值gradients = self.gradientsactivations = self.activations# 对梯度进行全局平均池化,得到每个通道的权重,用于衡量每个通道的重要性weights = torch.mean(gradients, dim=(2, 3), keepdim=True)# 加权激活映射,将权重与激活值相乘并求和,得到类激活映射的初步结果cam = torch.sum(weights * activations, dim=1, keepdim=True)# ReLU激活,只保留对目标类别有正贡献的区域,去除负贡献的影响cam = F.relu(cam)# 调整大小并归一化,将类激活映射调整为与输入图像相同的尺寸(140x140),并归一化到[0, 1]范围cam = F.interpolate(cam, size=(140, 140), mode='bilinear', align_corners=False)cam = cam - cam.min()cam = cam / cam.max() if cam.max() > 0 else camreturn cam.cpu().squeeze().numpy(), target_class# 选择一个随机图像
idx = np.random.randint(len(test_dataset))
image, label = test_dataset[idx]
classes = sorted(os.listdir('/kaggle/input/popular-street-foods/popular_street_foods/dataset'))
print(f"选择的图像类别: {classes[label]}")# 转换图像以便可视化
def tensor_to_np(tensor):img = tensor.cpu().numpy().transpose(1, 2, 0)mean = np.array([0.485, 0.456, 0.406])std = np.array([0.229, 0.224, 0.225])img = std * img + meanimg = np.clip(img, 0, 1)return img# 添加批次维度并移动到设备
input_tensor = image.unsqueeze(0).to(device)# 初始化Grad-CAM(选择最后一个卷积层)
target_layer_name = "cbam_layers.cbam_13"
grad_cam = GradCAM(model, target_layer_name)# 生成热力图
heatmap, pred_class = grad_cam.generate_cam(input_tensor)# 可视化
plt.figure(figsize=(12, 4))# 原始图像
plt.subplot(1, 3, 1)
plt.imshow(tensor_to_np(image))
plt.title(f"Original Picture: {classes[label]}")
plt.axis('off')# 热力图
plt.subplot(1, 3, 2)
plt.imshow(heatmap, cmap='jet')
plt.title(f"Grad-CAM HeatMap: {classes[pred_class]}")
plt.axis('off')# 叠加的图像
plt.subplot(1, 3, 3)
img = tensor_to_np(image)
heatmap_resized = np.uint8(255 * heatmap)
heatmap_colored = plt.cm.jet(heatmap_resized)[:, :, :3]
superimposed_img = heatmap_colored * 0.4 + img * 0.6
plt.imshow(superimposed_img)
plt.title("Original Picture + Grad-CAM HeatMap")
plt.axis('off')plt.tight_layout()
plt.show()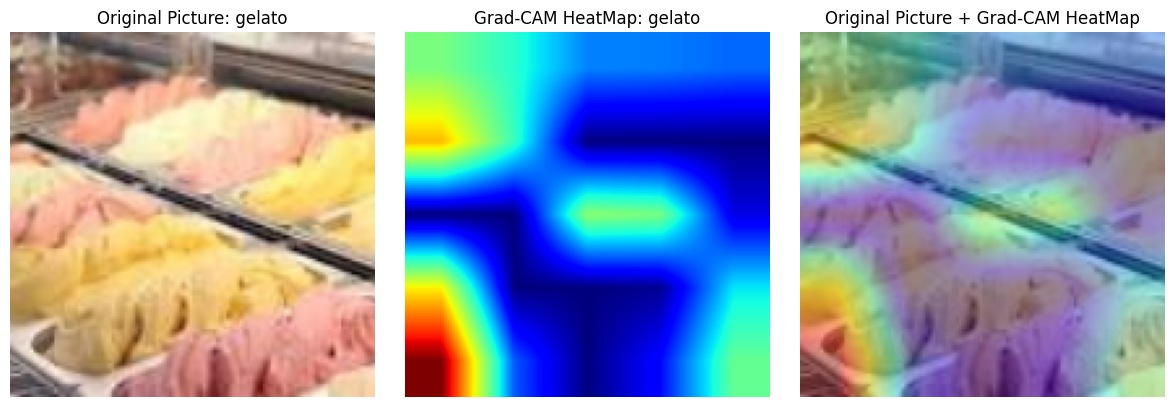
讲实话整个结构改进下来,CBAM和通道数匹配才是最恼火的,最先是直接设定CBAM输入通道,一直报错都快放弃了,最后无脑遍历😈
@浙大疏锦行








)

)



排序)




)