一、算力网-DNS
1.1、核心架构设计
1.1.1 设计框架
基于SRv6的智能DNS算法设计框架,结合IPv6路由可编程性、动态路径优化及业务感知能力,实现网络性能与用户体验的双重提升:
- SRv6-DNS融合架构
- 控制平面:
- DNS服务器集成SRv6控制器功能,通过BGP-LS实时采集全网拓扑和链路状态(时延、带宽、负载)。
- 业务感知模块解析DNS请求类型(视频/游戏/网页),匹配预设SLA策略。
- 数据平面:
- DNS响应中嵌入SRv6 SID列表(如
2001:db8::1:End.X),指导终端或网关按指定路径访问服务。 - 采用USID(微段标识)压缩报头,减少协议开销(原128位SID压缩至16位)。
- DNS响应中嵌入SRv6 SID列表(如
- 控制平面:
在算力网络中,基于DNS增强算力内容请求和调度能力,需通过协议扩展、智能调度算法与网络协同实现资源的最优匹配。
1.1.2、DNS协议扩展与算力信息嵌入
-
算力资源标识化
- 统一度量标准:为算力资源(CPU/GPU/存储)建立类似“千瓦时”的量化体系(如TFLOPS·h),嵌入DNS响应报文。
- SID扩展:在DNS OPT字段中携带SRv6 SID链(如
2001:db8::GPU:100T),指示目标算力节点及路径。
示例DNS响应结构:
Type: SRV6_SID Data: [SID1=算力节点, SID2=低时延路径, SID3=存储服务] -
动态资源感知
- BGP-LS增强:DNS控制器实时获取全网算力状态(负载、带宽、时延),通过BGP-LS协议同步至调度系统。
- 业务类型识别:解析请求特征(如AI训练/实时推理),动态匹配SID策略(如视频渲染需高GPU算力)。
1.1.3、智能调度算法设计
1. 多因子决策模型
- 优化目标:
\text{Minimize } \alpha \cdot \text{Delay} + \beta \cdot \text{Jitter} + \gamma \cdot \frac{1}{\text{ComputingPower}}
权重根据业务类型调整(如云游戏侧重低抖动,AI训练侧重高算力)。 - 拓扑裁剪:
结合Geohash预筛区域节点(如用户位于wx4g0仅选择同哈希前缀节点),降低90%计算量。
2. 调度策略分类
| 场景 | 算法选择 | 应用案例 |
|---|---|---|
| 突发高并发 | 加权最小连接 (Weighted Least Connections) | 电商大促时优先分配高算力节点 |
| 长时任务 | 源IP哈希 (IP Hash) | 保障同一用户任务绑定固定算力节点 |
| 跨域协同 | SRv6策略路由 | 云边端协同推理(如电网缺陷检测) |
1.1.4、与SRv6网络的深度协同
-
路径可编程
- DNS返回的SID链指导SRv6报文按需路径转发:
- 低时延路径:
End.AS指令保障关键业务(如直播流)。 - 算力优先路径:
End.DT4绑定高GPU算力节点。
- 低时延路径:
- 案例:中国电信骨干网部署SRv6时延通道,业务时延从16ms降至14ms。
- DNS返回的SID链指导SRv6报文按需路径转发:
-
网络切片隔离
- 为不同算力需求划分独立切片:
- AI训练切片:高带宽保障 + 无损传输
- 实时交互切片:确定性低时延(<5ms抖动)。
- 为不同算力需求划分独立切片:
1.1.5、应用场景与实效
-
云边协同推理
- 流程:
graph LR A[端侧数据采集] --> B[边缘节点预处理] B -->|轻量计算| C[DNS调度至边缘算力] B -->|复杂分析| D[DNS调度至云中心] - 效果:国家电网缺陷识别场景,边侧筛选样本+云侧深度分析,效率提升40%。
- 流程:
-
全局算力调度
- 中国电信“息壤”平台通过DNS+控制器对接,整合异构算力:
- 跨省调度AI训练任务,资源利用率提升25%。
- 支持“东数西算”工程,优化东西部算力均衡。
- 中国电信“息壤”平台通过DNS+控制器对接,整合异构算力:
通过DNS与算力网络的深度耦合,将域名解析升级为“资源-路径”联合调度枢纽,实现从连接可达到服务最优的质变。
1.2、智能路由算法流程
graph LR
A[DNS请求] --> B{业务类型识别}
B -->|视频流| C[计算低时延路径]
B -->|游戏| D[选择低抖动路径]
B -->|网页| E[默认负载均衡]
C & D & E --> F[生成SRv6 SID列表]
F --> G[返回DNS响应携带SID链]
G --> H[终端按SID路径访问服务]-
动态路径决策算法
- 强化学习模型(参考PPO算法):
- 状态空间:链路利用率、时延矩阵、丢包率。
- 动作空间:SID路径组合选择(如
[SID1, SID2, SID3])。 - 奖励函数:最大化
1/(时延×丢包率) + 权重×剩余带宽。
- 实时优化:每5分钟更新策略网络参数,适应网络波动。
- 强化学习模型(参考PPO算法):
-
业务感知SID生成
业务类型 SID功能指令 优化目标 视频直播 End.DT4+End.AS低时延(<50ms),绑定边缘节点 云游戏 End.DX6+End.AD低抖动(<5ms),路径冗余 普通网页 End.B6负载均衡,成本优先
1.3、关键技术实现
-
协议扩展
- DNS响应报文扩展:
- 新增
OPT字段携带SID链(如Type=SRV6, Data=[SID1,SID2])。 - 兼容传统解析:非SRv6终端忽略扩展字段,返回标准A/AAAA记录。
- 新增
- BGP-LS增强:
- 发布节点SID能力(如支持
End.AS抗丢包指令),供DNS控制器调用。
- 发布节点SID能力(如支持
- DNS响应报文扩展:
-
路径优化引擎
- 多目标决策模型:
\text{Minimize } \alpha \cdot \text{Delay} + \beta \cdot \text{Jitter} + \gamma \cdot (1/\text{Bandwidth})
权重\alpha,\beta,\gamma根据业务类型动态调整。 - 拓扑裁剪:
- 基于Geohash预筛区域节点(如用户位于
wx4g0仅选择同哈希前缀节点)。 - 减少90%计算复杂度。
- 基于Geohash预筛区域节点(如用户位于
- 多目标决策模型:
1.4、部署场景与性能
| 场景 | 技术方案 | 性能增益 |
|---|---|---|
| 跨域云服务 | DNS返回跨域SID链(如[DC1,骨干网,DC2]) | 时延降低40%,带宽利用率提升25% |
| 5G边缘计算 | 绑定End.AS指令保障UDP流可靠性 | 游戏丢包率降至0.1%以下 |
| 全球直播调度 | 动态切换SID路径规避拥塞节点 | 卡顿率减少70% |
1.5、未来演进方向
- AI-原生路由:
- 结合GNN(图神经网络)预测流量突变,提前生成SID备用路径。
- 量子安全DNS:
- SID链增加量子密钥分发(QKD)字段,防中间人攻击。
- 跨层优化:
- 应用层反馈QoE指标(如MOS分),闭环调整SID权重。
部署建议:
- 增量升级:DNS服务器优先支持SRv6 OPT解析,逐步替换传统负载均衡设备。
- 协议栈优化:Linux内核启用SRv6 USID压缩模块(
modprobe srv6_usid)。
该架构通过SRv6将DNS从“地址解析器”升级为“业务调度器”,实现从“域名到最优路径”的质变。
二、算力网中的RDMA
2.1、RDMA在算力网络中的核心作用
-
硬件级加速机制
- 零拷贝传输:RDMA绕过操作系统内核,直接读写远程内存,减少CPU开销与数据拷贝延迟(时延降至2–5μs)。
- 协议卸载:将TCP/IP协议栈处理卸载至网卡硬件,释放CPU算力用于计算任务,提升集群整体吞吐量。
- 典型场景:千卡GPU集群训练大模型时,RDMA降低通信延迟,使GPU计算效率提升30%以上。
-
资源动态复用技术
- 连接池化(DC模式):共享发送/接收队列,减少多应用并发时的QP(Queue Pair)资源占用(资源消耗降低30–40%)。
- 内存注册优化:
- 静态模型:预注册固定内存块,实现零拷贝(适用于迭代传输量固定的AI训练)。
- 动态模型:内存池技术动态分配注册内存,兼顾灵活性与效率(支持动态形状数据)。
2.2、分布式请求驱动的资源调度框架
1. 集中式 vs 分布式调度
| 类型 | 优势 | 局限 | 适用场景 |
|---|---|---|---|
| 集中式 | 全局资源视图,策略一致性高 | 单点瓶颈,扩展性差 | 中小规模集群(<100节点) |
| 分布式 | 无中心瓶颈,支持动态扩缩容 | 状态同步延迟影响调度实时性 | 大规模跨域算力网络(如“东数西算”) |
2. 调度流程关键步骤
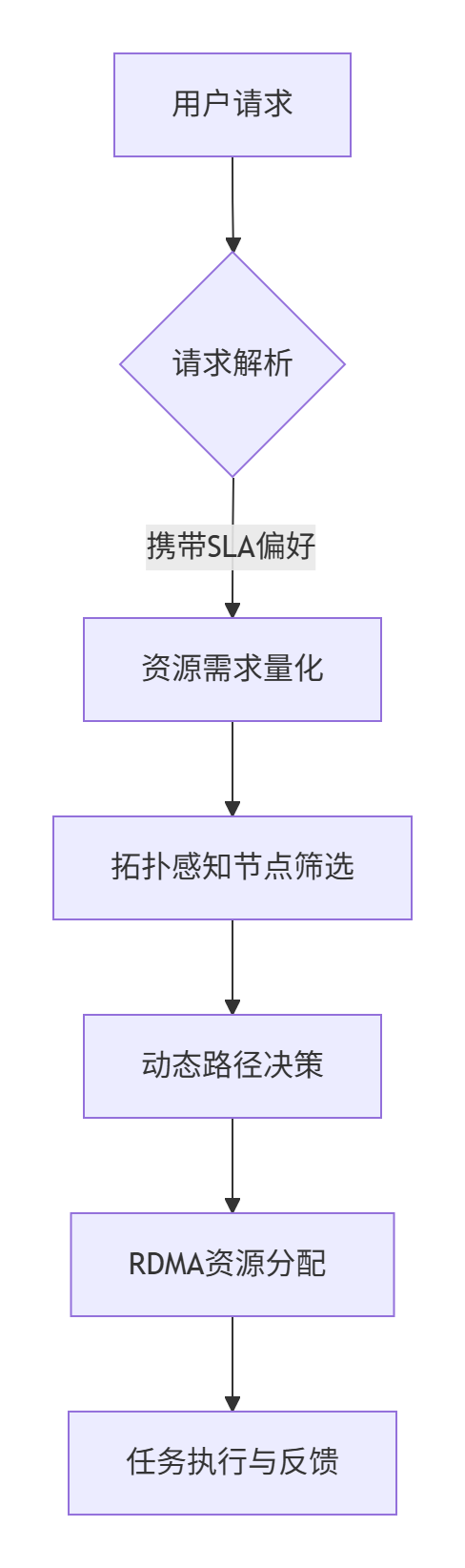
- 请求解析:提取算力类型(CPU/GPU)、时延要求(如<5ms)、带宽需求(如100Gbps)。
- 拓扑感知:基于Geohash或BGP-LS获取节点位置与链路状态,预筛低时延区域节点。
- 路径决策:SRv6 SID链指定传输路径(如
End.AS抗丢包指令保障游戏流)。
2.3、网络资源调度优化关键技术
-
拥塞控制算法
- DCQCN(数据中心量化拥塞通知):
Rate_{new} = Rate_{current} \times (1 - \alpha) + \alpha \times \frac{B_{target}}{1 + Q_{depth}}
根据ECN标记动态调整发送速率,平衡带宽利用率与公平性(α=0.8为平滑因子)。 - 硬件卸载实现:在智能网卡上运行DCQCN,实时响应拥塞信号(微秒级调控)。
- DCQCN(数据中心量化拥塞通知):
-
长距离传输优化
- 虚拟流水线(VPP):
- 将端到端传输分解为虚拟阶段(发送缓冲→传输确认→重传控制),减少长RTT导致的空泡率(从18%降至10%)。
- 跨域场景下,通过OTN设备反馈光链路误码率,动态切换冗余路径。
- 消息大小自适应:根据距离动态调整RDMA消息大小(>1000公里推荐1MB以上),平衡有效载荷与误码重传成本。
- 虚拟流水线(VPP):
-
多租户资源隔离
- 网络切片:为AI训练、实时交互等场景划分独立虚拟网络,保障SLA。
- 权重矩阵调度:按租户SLA分配带宽权重,例如:
租户类型 带宽权重 时延要求 高优先级AI 60% <1ms 普通计算 30% <10ms 备份任务 10% 无要求
2.4、典型应用场景与实效
-
跨域AI训练
- 挑战:东西部算力节点间长距离传输(>2000公里)导致高时延(>30ms)。
- 方案:
- RDMA + SRv6路径编程(如
[东部节点, 骨干网, 西部节点])。 - VPP分阶段流水线传输,空泡率降至8%。
- RDMA + SRv6路径编程(如
- 成效:千卡集群训练ResNet-50,迭代时间缩短40%。
-
边缘协同推理
- 动态调度流程:
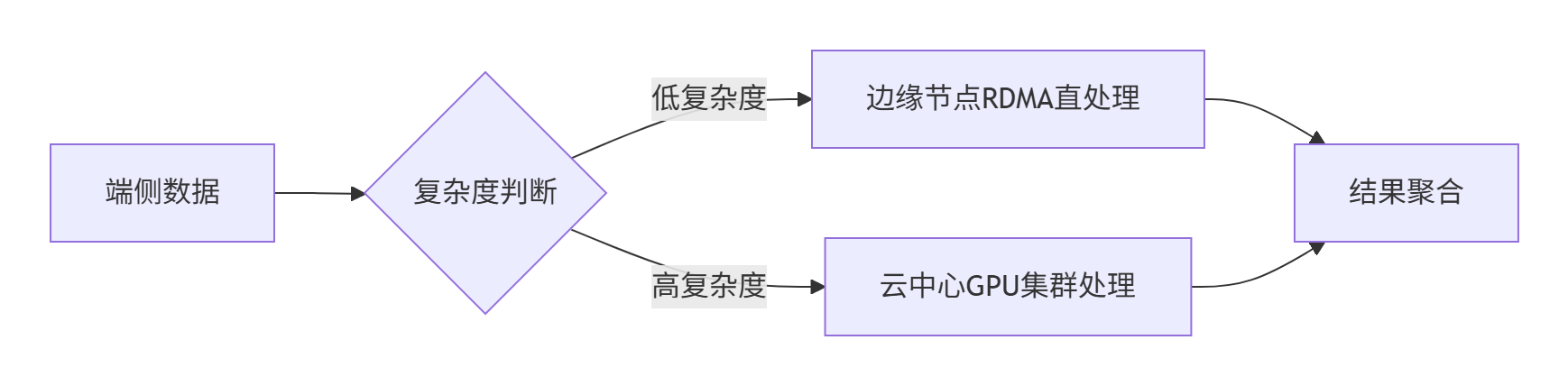
- 资源调度:边缘节点通过轻量级QP池处理实时请求,复杂任务卸载至云中心。
- 案例:电网缺陷识别系统,边缘预处理过滤90%无效数据,整体效率提升50%。
- 动态调度流程:
总结与趋势
RDMA与分布式调度的融合核心在于:
- 硬件加速:通过零拷贝、协议卸载突破传统网络瓶颈;
- 动态协同:分布式调度框架实现算力-网络资源联合优化;
- 场景适配:长距传输(VPP)、多租户(切片)等定制化策略。
未来方向:
- AI原生调度:GNN预测流量突变,动态生成备用SID路径。
- 量子安全增强:RDMA传输层集成QKD密钥分发,防中间人攻击。
- 存算一体:CXL协议扩展内存池,与RDMA协同优化数据就地计算。
通过RDMA与分布式调度的深度耦合,算力网络从“连接可达”迈向“服务最优”,为泛在算力提供底层支撑。









-----删除链表中指定值的节点)






自动曝光中Lv值的计算方式实现猜想)
![[docker]镜像操作:关于docker pull、save、load一些疑惑解答](http://pic.xiahunao.cn/[docker]镜像操作:关于docker pull、save、load一些疑惑解答)

