目录
- Kafka入门
- 消息引擎系统ABC
- 快速搞定Kafka术语
- kafka三层消息架构
- 名词术语
- Kafka基础
- Kafka部署参考
- 重要配置参数
- Broker端参数
- Topic级别参数
- JVM参数
Kafka是消息引擎系统,也是分布式流处理平台
Kafka入门
消息引擎系统ABC
民间版:系统 A 发送消息给消息引擎系统,系统 B 从消息引擎系统中读取 A 发送的消息。
消息引擎是用于在不同系统之间传输消息的,那么如何设计待传输消息的格式从来都是一等一的大事。Kafka使用的是纯二进制的字节序列。当然消息还是结构化的,只是在使用之前都要将其转换成二进制的字节序列。
点对点模型:也叫消息队列模型。如果拿上面那个“民间版”的定义来说,那么系统 A发送的消息只能被系统 B 接收,其他任何系统都不能读取 A 发送的消息。日常生活的例子比如电话客服就属于这种模型:同一个客户呼入电话只能被一位客服人员处理,第二个客服人员不能为该客户服务。
发布 / 订阅模型:与上面不同的是,它有一个主题(Topic)的概念,你可以理解成逻辑语义相近的消息容器。该模型也有发送方和接收方,只不过提法不同。发送方也称为发布者(Publisher),接收方称为订阅者(Subscriber)。和点对点模型不同的是,这个模型可能存在多个发布者向相同的主题发送消息,而订阅者也可能存在多个,它们都能接收到相同主题的消息。生活中的报纸订阅就是一种典型的发布 / 订阅模型。
我们不禁要问,为什么系统 A 不能直接发送消息给系统 B,中间还要隔一个消息引擎呢?
答案就是“削峰填谷”。
通常来说,两个进程进行数据流交互的方式一般有三种:
- 通过数据库:进程1写入数据库;进程2读取数据库
- 通过服务调用:比如REST或RPC,而HTTP协议通常就作为REST方式的底层通讯协议
- 通过消息传递的方式:进程1发送消息给名为broker的中间件,然后进程2从该broker中读取消息。消息传输协议属于这种模式
快速搞定Kafka术语
kafka三层消息架构
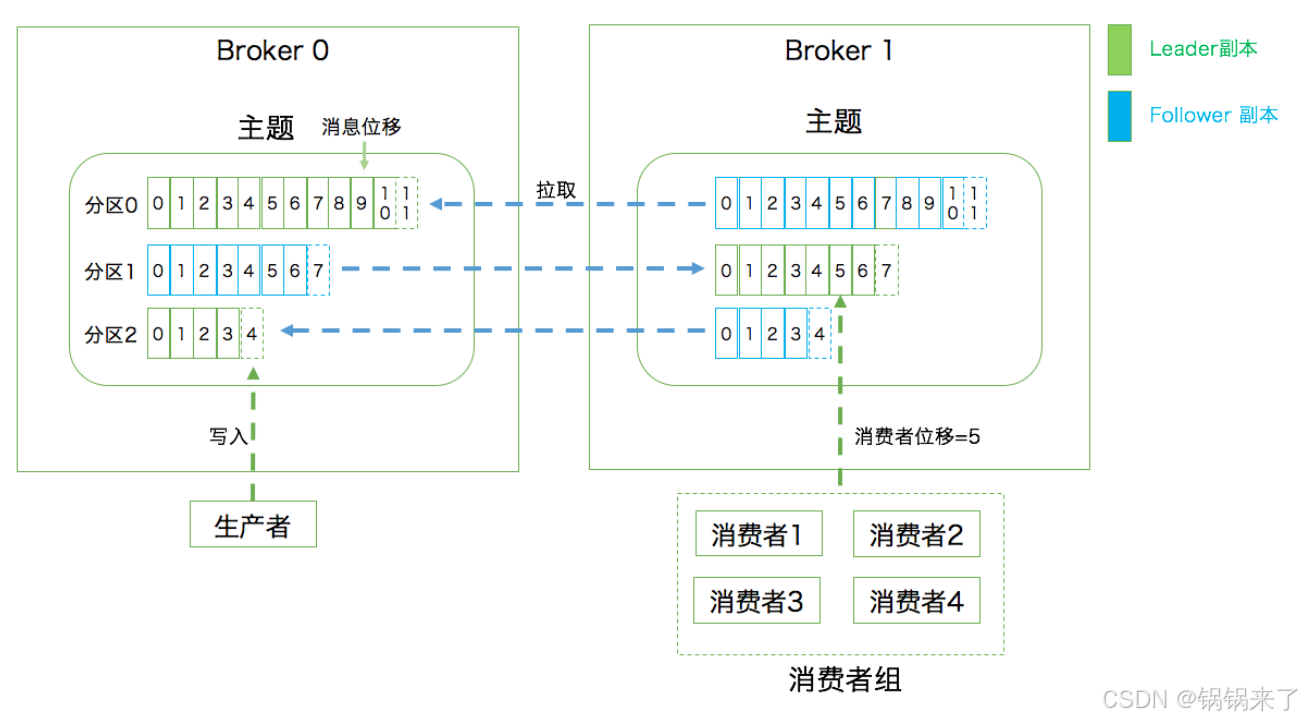
- 第一层是主题层,每个主题可以配置 M 个分区,而每个分区又可以配置 N 个副本。
- 第二层是分区层,每个分区的 N 个副本中只能有一个充当领导者角色,对外提供服务;其他 N-1 个副本是追随者副本,只是提供数据冗余之用。
- 第三层是消息层,分区中包含若干条消息,每条消息的位移从 0 开始,依次递增。最后,客户端程序只能与分区的领导者副本进行交互。
名词术语
消息:Record。Kafka 是消息引擎嘛,这里的消息就是指 Kafka 处理的主要对象。
主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
分区:Partition。一个有序不变的消息序列。每个主题下可以有多个分区。
消息位移:Offset。表示分区中每条消息的位置信息,是一个单调递增且不变的值。
副本:Replica。Kafka 中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。副本还分为领导者副本和追随者副本,各自有不同的角色划分。副本是在分区层级下的,即每个分区可配置多个副本实现高可用。
生产者:Producer。向主题发布新消息的应用程序。消费者:Consumer。从主题订阅新消息的应用程序。消费者位移:Consumer Offset。表征消费者消费进度,每个消费者都有自己的消费者位移。
消费者组:Consumer Group。多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
Kafka监控工具:
kafka manager kafka eagle JMXTrans + InfluxDB + Grafana
Kafka基础
Kafka部署参考
重要配置参数
Broker端参数
log.dirs: 指定了Broker需要使用的若干个文件目录路径。在线上生产环境中一定要为log.dirs配置多个路径,具体格式是一个 CSV 格式,也就是用逗号分隔的多个路径,比如/home/kafka1,/home/kafka2,/home/kafka3这样。如果有条件的话你最好保证这些目录挂载到不同的物理磁盘上。
zookeeper.connect:
这也是一个 CSV 格式的参数,比如我可以指定它的值为zk1:2181,zk2:2181,zk3:2181。2181 是 ZooKeeper的默认端口。
如果我让多个 Kafka 集群使用同一套ZooKeeper 集群,那么这个参数应该怎么设置呢?这时候chroot 就派上用场了。这个 chroot 是 ZooKeeper 的概念,类似于别名。
如果你有两套 Kafka 集群,假设分别叫它们 kafka1 和kafka2,那么两套集群的zookeeper.connect参数可以这样指定:zk1:2181,zk2:2181,zk3:2181/kafka1和zk1:2181,zk2:2181,zk3:2181/kafka2。切记 chroot只需要写一次,而且是加到最后的。
zookeeper.connect=172.20.38.137:34983,172.20.38.148:34983,172.20.38.125:34983
listeners:
listeners:学名叫监听器,其实就是告诉外部连接者要通过什么协议访问指定主机名和端口开放的 Kafka 服务。
监听器的概念,从构成上来说,它是若干个逗号分隔的三元组,每个三元组的格式为<协议名称,主机名,端口号>。这里的协议名称可能是标准的名字,比如PLAINTEXT 表示明文传输、SSL 表示使用 SSL 或 TLS 加密传输等;也可能是你自己定义的协议名字
listeners=PLAINTEXT://172.20.38.148:34984
advertised.listeners:
和 listeners 相比多了个advertised。Advertised 的含义表示宣称的、公布的,就是说这组监听器是 Broker 用于对外发布的。
advertised.listeners主要是为外网访问用的。如果clients在内网环境访问Kafka不需要配置这个参数。
log.retention.{hour|minutes|ms}
log.retention.hour=168
自动删除 7 天前的数据
log.retention.bytes:这是指定 Broker 为消息保存的总磁盘容量大小
message.max.bytes:
message.max.bytes=10485760(10M)
auto.create.topics.enable:是否允许自动创建Topic。
unclean.leader.election.enable:是否允许Unclean Leader 选举。
auto.leader.rebalance.enable:是否允许定期进行 Leader 选举。
Topic级别参数
Topic级别参数会覆盖全局Broker参数的值,可以通过kafka-configs自带脚本修改Topic级别参数。
retention.ms:规定了该 Topic 消息被保存的时长。默认是 7 天,即该 Topic 只保存最近 7 天的消息。一旦设置了这个值,它会覆盖掉 Broker 端的全局参数值。
retention.bytes:规定了要为该 Topic 预留多大的磁盘空间。和全局参数作用相似,这个值通常在多租户的Kafka 集群中会有用武之地。当前默认值是 -1,表示可以无限使用磁盘空间。
JVM参数
- KAFKA_HEAP_OPTS:指定堆大小。(一般设置6G)
- KAFKA_JVM_PERFORMANCE_OPTS:指定 GC 参数
VNetStack 深度技术解析)


)

:Cookie与会话)



失败用例截图与重试)

)






技术)
)