
🙋♀️ 博主介绍:颜颜yan_
⭐ 本期精彩:深入浅出Python函数:参数传递、作用域与案例详解
🏆 热门专栏:零基础玩转Python爬虫:手把手教你成为数据猎人
🚀 专栏亮点:零基础友好 | 实战案例丰富 | 循序渐进教学 | 代码详细注释
💡 学习收获:掌握爬虫核心技术,成为数据采集高手,开启你的数据科学之旅!
🔥 如果觉得文章有帮助,别忘了点赞👍 收藏⭐ 关注🚀,你的支持是我创作的最大动力!
文章目录
- 前言
- 什么是函数
- 为什么要使用自定义函数
- 函数定义语法
- 基本示例
- 定义函数的注意事项
- def关键字的重要性
- 函数命名规范
- 参数列表的灵活性
- 返回值的处理
- 函数参数
- 带有默认值的参数
- 多参数函数
- 位置参数:基于参数位置传递
- 关键字参数:基于参数名传递
- 参数传递的重要规则
- 可变参数:处理不确定数量的输入
- 函数变量作用域
- 局部变量:函数内部的私有空间
- 全局变量:程序的公共资源
- 作用域
- 使用global关键字:突破局部限制
- 嵌套函数中的作用域:nonlocal的力量
- 作用域查找顺序(LEGB规则)
- 函数的高级特性
- 函数作为参数
- Lambda函数:简洁的匿名函数
- 总结
前言
函数是Python编程中最重要的概念之一,它们帮助我们组织代码、提高代码复用性并让程序更加模块化。本文将深入探讨Python中的用户自定义函数、参数传递以及变量作用域等核心概念。
什么是函数
在深入讲解用户自定义函数之前,我们先来理解什么是函数。从数学的角度来看,函数是一种映射关系,给定输入值,会产生对应的输出值。在编程中,函数的概念也是如此——它接收一些输入(称为参数),执行特定的操作,然后可能返回一个结果。
Python中的函数大致可以分为两类:
- 内置函数(Built-in Function,缩写BIF):这些是Python官方提供的函数,如
print()用于输出、len()用于获取长度、max()用于找最大值等。这些函数是Python语言的一部分,可以直接使用。 - 用户自定义函数:这些是我们根据自己的需求创建的函数,可以封装特定的业务逻辑或算法。
为什么要使用自定义函数
在实际编程中,我们经常会遇到需要重复执行某些操作的情况。比如,在一个学生管理系统中,我们可能需要多次计算学生的平均成绩。如果每次都重新写一遍计算逻辑,不仅代码冗余,而且容易出错。这时候,函数就发挥了巨大的作用:
- 代码复用:一次编写,多次使用,避免重复劳动
- 模块化编程:将复杂的问题分解为小的、易于管理的部分
- 提高可维护性:当需要修改某个功能时,只需要修改函数内部的代码
- 增强可读性:通过函数名就能大致了解代码的功能
- 便于测试:可以单独对函数进行测试,确保其正确性
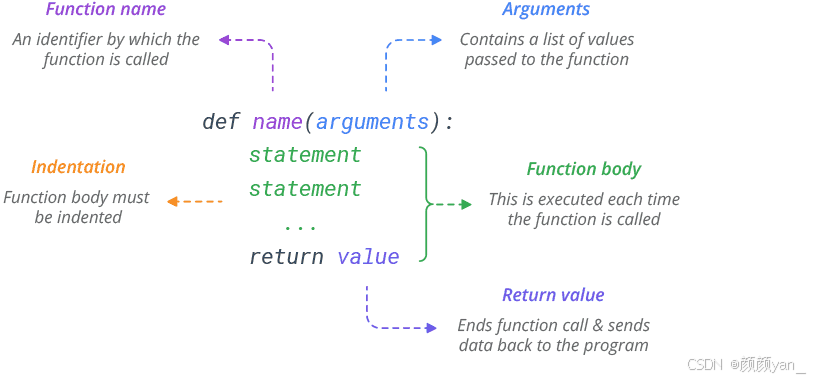
函数定义语法
自定义函数的语法格式:
def 函数名(参数列表):"""函数文档字符串(可选)"""函数体return 返回值 # 可选
这个语法看起来简单,但每个部分都有其重要作用:
- def关键字:告诉Python解释器我们要定义一个函数
- 函数名:函数的标识符,应该具有描述性,让人一看就知道函数的作用
- 参数列表:函数接收的输入,可以为空
- 文档字符串:用三引号包围的字符串,用于描述函数的用途、参数和返回值
- 函数体:函数的核心逻辑,实现具体功能
- return语句:指定函数的返回值,如果没有return,函数默认返回None
基本示例
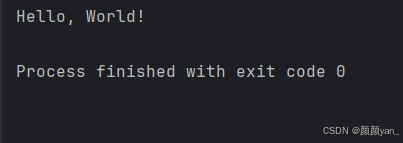
# 无参数函数
def greet():print("Hello, World!")
# 调用函数
greet()
这是最基本的函数示例。这个函数没有参数,也没有返回值,它的唯一作用就是打印一句问候语。虽然简单,但它展示了函数的基本结构。当我们调用greet()时,程序会执行函数内部的代码,输出"Hello, World!"。
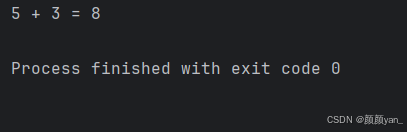
# 有参数和返回值的函数
def add_numbers(a, b):"""计算两个数的和"""result = a + breturn result# 调用函数
sum_result = add_numbers(5, 3)
print(f"5 + 3 = {sum_result}") # 输出: 5 + 3 = 8
这个函数接收两个参数a和b,计算它们的和,并通过return语句返回结果。注意几个要点:
- 参数
a和b是函数的输入接口 - 函数内部可以进行任意的计算和处理
return语句不仅结束函数的执行,还将结果传递给调用者- 调用函数时,我们可以将返回值赋给一个变量
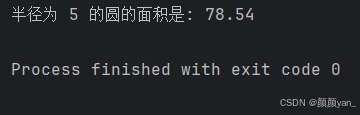
# 计算圆的面积
import mathdef calculate_circle_area(radius):"""计算圆的面积参数: radius - 圆的半径返回值: 圆的面积"""if radius < 0:return None # 半径不能为负数area = math.pi * radius ** 2return round(area, 2)# 测试函数
radius = 5
area = calculate_circle_area(radius)
print(f"半径为 {radius} 的圆的面积是: {area}")
这个函数展现了更多的实际编程技巧:
- 输入验证:检查半径是否为负数
- 使用标准库:导入math模块使用圆周率π
- 数值处理:使用
round()函数保留两位小数,提高结果的可读性 - 文档字符串:详细描述了函数的用途、参数和返回值
定义函数的注意事项
def关键字的重要性
def是Python中定义函数的唯一关键字,不能省略,也不能替换为其他词汇。这是Python语法的硬性规定。
函数命名规范
函数名应该遵循Python的命名规范:
- 只能包含字母、数字和下划线
- 不能以数字开头
- 应该使用小写字母,单词间用下划线分隔(蛇形命名法)
- 名称应该具有描述性,能够表达函数的功能
参数列表的灵活性
参数列表可以为空,也可以包含多个参数。参数之间用逗号分隔,每个参数都可以有默认值。
返回值的处理
- 如果函数需要返回数据,使用
return语句 - 如果没有显式的
return语句,函数会默认返回None return语句会立即结束函数的执行,后续代码不会被执行
好的函数名应该是一个动词短语,清楚地表达函数的功能。
# 函数命名示例
def good_function_name(): # 好的命名方式passdef calculate_student_average(): # 描述性命名pass# 避免这样的命名
def func(): # 太简单pass
函数参数
带有默认值的参数
在现实生活中,许多操作都有一些"默认设置"。比如,你去咖啡店点咖啡,如果不特别说明,店员可能会给你中杯、正常糖分的咖啡。在编程中,默认参数就是这样的概念——当用户没有提供某个参数时,函数会使用预设的默认值。
默认参数的优势在于:
- 提高易用性:调用者不需要为每个参数都提供值
- 向后兼容性:添加新参数时不会破坏现有代码
- 减少代码重复:常用的参数值可以作为默认值
def create_profile(name, age, city="未知", profession="学生"):"""创建用户档案name: 姓名(必需参数)age: 年龄(必需参数)city: 城市(默认值: "未知")profession: 职业(默认值: "学生")"""profile = f"姓名: {name}, 年龄: {age}, 城市: {city}, 职业: {profession}"return profile# 不同的调用方式
print(create_profile("张三", 25))
print(create_profile("李四", 30, "北京"))
print(create_profile("王五", 28, "上海", "工程师"))
在这个例子中,name和age是必需参数,而city和profession有默认值。这样设计的好处是:
- 最简调用:只需提供姓名和年龄
- 部分定制:可以指定城市,职业使用默认值
- 完全定制:所有参数都可以自定义

多参数函数
如果函数有多个参数,在调用时可以有两种传递参数的方式。
位置参数:基于参数位置传递
位置参数是最直观的参数传递方式,参数的值按照定义时的顺序传递给函数。这就像排队一样,第一个值给第一个参数,第二个值给第二个参数,以此类推。
def calculate_rectangle_info(length, width, height=1):"""计算矩形信息"""area = length * widthperimeter = 2 * (length + width)volume = length * width * heightreturn {'area': area,'perimeter': perimeter,'volume': volume}# 使用位置参数
result = calculate_rectangle_info(10, 5, 2)
print(f"面积: {result['area']}, 周长: {result['perimeter']}, 体积: {result['volume']}")
在这个例子中,10传给length,5传给width,2传给height。位置参数的优点是简洁明了,缺点是必须记住参数的顺序。
关键字参数:基于参数名传递
关键字参数允许我们通过参数名来传递值,这样就不需要记住参数的顺序了。这种方式特别适合参数较多或者参数含义不够直观的情况。
关键字参数的优势:
- 提高可读性:代码自文档化,参数的含义一目了然
- 顺序无关:不需要记住参数的顺序
- 部分指定:可以只为某些参数使用关键字形式
# 使用关键字参数
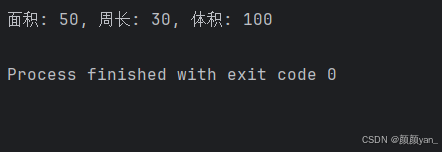
result = calculate_rectangle_info(width=8, length=12, height=3)
print(f"面积: {result['area']}, 周长: {result['perimeter']}, 体积: {result['volume']}")
# 输出: 面积: 96, 周长: 40, 体积: 288# 混合使用位置参数和关键字参数
result = calculate_rectangle_info(15, width=6) # length=15 (位置), width=6 (关键字)
print(f"面积: {result['area']}") # 输出: 面积: 90
参数传递的重要规则
一旦使用了关键字参数,后续的所有参数都必须使用关键字形式。如果允许关键字参数后面跟位置参数,Python解释器将无法确定参数的正确对应关系。
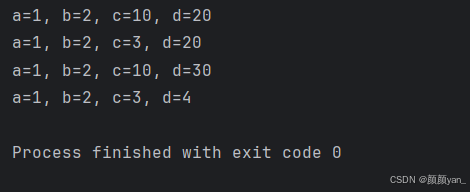
def demo_function(a, b, c=10, d=20):return f"a={a}, b={b}, c={c}, d={d}"# 正确的调用方式
print(demo_function(1, 2)) # a=1, b=2, c=10, d=20
print(demo_function(1, 2, 3)) # a=1, b=2, c=3, d=20
print(demo_function(1, 2, d=30)) # a=1, b=2, c=10, d=30
print(demo_function(1, b=2, c=3, d=4)) # a=1, b=2, c=3, d=4# 错误的调用方式
# demo_function(a=1, 2) # SyntaxError: 位置参数不能跟在关键字参数后面
可变参数:处理不确定数量的输入
在实际编程中,我们经常遇到不知道会有多少个参数的情况。比如,计算多个数字的平均值,数字的个数可能是2个,也可能是10个。这时候,可变参数就派上用场了。
Python提供了两种可变参数:
*args:接收任意数量的位置参数,存储为元组**kwargs:接收任意数量的关键字参数,存储为字典
可变参数的强大之处在于:
- 灵活性:可以处理任意数量的参数
- 扩展性:添加新的参数不需要修改函数定义
- 通用性:同一个函数可以处理不同场景的需求
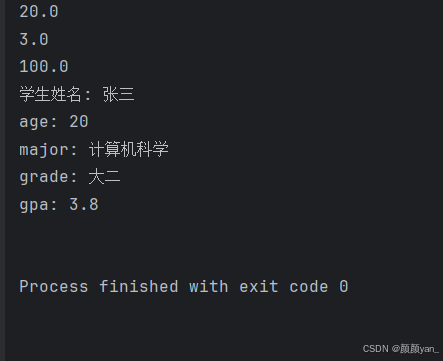
def calculate_average(*numbers):"""计算任意数量数字的平均值"""if not numbers:return 0total = sum(numbers)average = total / len(numbers)return round(average, 2)# 测试可变参数
print(calculate_average(10, 20, 30))
print(calculate_average(1, 2, 3, 4, 5))
print(calculate_average(100))
def create_student_info(name, **kwargs):"""创建学生信息,接受任意关键字参数"""info = f"学生姓名: {name}\n"for key, value in kwargs.items():info += f"{key}: {value}\n"return info# 测试关键字参数
student = create_student_info("张三",age=20,major="计算机科学",grade="大二",gpa=3.8
)
print(student)
在这个例子中,*numbers接收了所有传入的数字,函数内部可以像处理元组一样处理这些数字。第二个例子中,**kwargs接收了除name之外的所有关键字参数,这样我们可以为学生添加任意的额外信息,而不需要修改函数定义。
函数变量作用域
变量作用域是编程中一个既基础又容易混淆的概念。如果把程序比作一个大楼,那么作用域就像是楼层和房间——不同楼层的房间可能有相同的房间号,但它们是完全独立的空间。
局部变量:函数内部的私有空间
局部变量是在函数内部定义的变量,它们的"生命周期"仅限于函数执行期间。就像是你在酒店房间里放置的物品,只有在你住在这个房间的时候才能使用,一旦退房,这些物品就不再属于你了。
局部变量的特点:
- 生命周期短:函数开始执行时创建,函数结束时销毁
- 作用域有限:只能在定义它的函数内部使用
- 互不干扰:不同函数中的同名局部变量是完全独立的
- 优先级高:当局部变量和全局变量同名时,函数内部优先使用局部变量
全局变量:程序的公共资源
全局变量是在函数外部(模块级别)定义的变量,它们可以被程序中的任何函数访问。这就像是大楼的公共设施,所有住户都可以使用,但需要遵循一定的使用规则。
全局变量的特点:
- 生命周期长:从定义开始,直到程序结束
- 作用域广:整个模块中的所有函数都可以访问
- 共享性:多个函数可以共享同一个全局变量
- 需谨慎修改:修改全局变量会影响所有使用它的地方
作用域
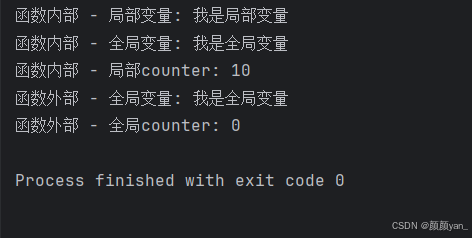
让我们通过一个详细的例子来理解局部变量和全局变量的区别:
# 全局变量
global_var = "我是全局变量"
counter = 0def scope_demo():# 局部变量local_var = "我是局部变量"counter = 10 # 这是局部变量,不会影响全局的counterprint(f"函数内部 - 局部变量: {local_var}")print(f"函数内部 - 全局变量: {global_var}")print(f"函数内部 - 局部counter: {counter}")# 调用函数
scope_demo()
print(f"函数外部 - 全局变量: {global_var}")
print(f"函数外部 - 全局counter: {counter}") # 仍然是0,没有被函数内部的赋值影响# 尝试访问局部变量(会报错)
# print(local_var) # NameError: name 'local_var' is not defined
使用global关键字:突破局部限制
有时候,我们确实需要在函数内部修改全局变量。这时候,global关键字就派上用场了。它告诉Python:“我要修改的是全局变量,不是创建新的局部变量”。
使用global的注意事项:
- 只有在需要修改全局变量时才使用
global - 过多的全局变量会让程序难以维护
- 考虑使用类或者传递参数来替代全局变量
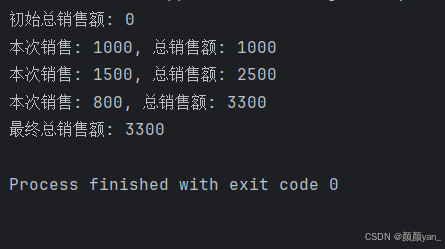
total_sales = 0 # 全局变量def add_sale(amount):global total_sales # 声明要修改全局变量total_sales += amountprint(f"本次销售: {amount}, 总销售额: {total_sales}")def get_total_sales():return total_sales# 测试全局变量修改
print(f"初始总销售额: {get_total_sales()}") # 输出: 0add_sale(1000)
add_sale(1500)
add_sale(800) print(f"最终总销售额: {get_total_sales()}")
嵌套函数中的作用域:nonlocal的力量
Python支持嵌套函数(函数内部定义的函数),这创造了更复杂但也更灵活的作用域层次。在嵌套函数中,有时我们需要修改外层函数的局部变量,这时候nonlocal关键字就发挥作用了。
嵌套函数的特性:
- 闭包特性:内层函数可以访问外层函数的变量
- 状态修改:通过
nonlocal可以修改外层函数的局部变量 - 数据封装:外层函数的变量对外部是不可见的,实现了良好的封装
def outer_function(x):"""外层函数"""outer_var = "外层变量"def inner_function(y):"""内层函数"""inner_var = "内层变量"nonlocal outer_var # 声明要修改外层函数的变量outer_var = "修改后的外层变量"print(f"内层函数 - 参数y: {y}")print(f"内层函数 - inner_var: {inner_var}")print(f"内层函数 - outer_var: {outer_var}")print(f"内层函数 - 参数x: {x}")return inner_varprint(f"外层函数 - 调用前outer_var: {outer_var}")result = inner_function(20)print(f"外层函数 - 调用后outer_var: {outer_var}")return result# 测试嵌套函数
returned_value = outer_function(10)
print(f"返回值: {returned_value}")

作用域查找顺序(LEGB规则)
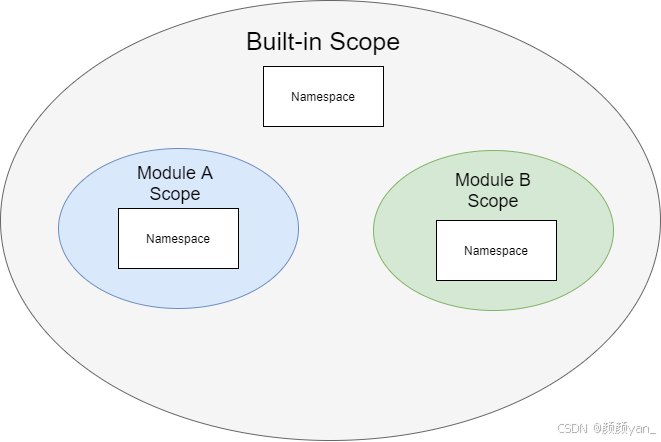
当Python解释器遇到一个变量名时,它会按照特定的顺序查找这个变量。这个顺序被称为LEGB规则:
- L (Local):局部作用域,函数内部的变量
- E (Enclosing):嵌套作用域,外层函数的局部变量
- G (Global):全局作用域,模块级别的变量
- B (Built-in):内置作用域,Python内置的变量和函数
LEGB规则的重要意义:
- 查找效率:Python会从最近的作用域开始查找,提高效率
- 变量屏蔽:内层作用域的同名变量会"屏蔽"外层的变量
- 预测性:理解这个规则可以帮助我们预测变量的值
builtin_name = len # 使用内置函数len
global_name = "全局作用域"def enclosing_function():enclosing_name = "嵌套作用域"def local_function():local_name = "局部作用域"# Python按照LEGB顺序查找变量print(f"局部变量: {local_name}") # L - Localprint(f"嵌套变量: {enclosing_name}") # E - Enclosingprint(f"全局变量: {global_name}") # G - Globalprint(f"内置函数: {builtin_name([1,2,3])}") # B - Built-inlocal_function()enclosing_function()
合理使用不同作用域的变量,可以让我们的代码更加清晰、安全和易于维护。
函数的高级特性
函数作为参数
在Python中,函数是"一等公民",这意味着函数可以像变量一样被传递、赋值和操作。函数作为参数传递给其他函数的特性,被称为高阶函数,这是函数式编程的重要特征。
def apply_operation(numbers, operation_func):"""将操作函数应用到数字列表上"""return [operation_func(x) for x in numbers]def square(x):return x ** 2def cube(x):return x ** 3# 测试
numbers = [1, 2, 3, 4, 5]
print(f"原始数字: {numbers}")
print(f"平方结果: {apply_operation(numbers, square)}")
print(f"立方结果: {apply_operation(numbers, cube)}")
这个例子展现了高阶函数的强大之处:
- 代码复用:
apply_operation可以应用任何单参数函数 - 逻辑分离:数据处理逻辑和具体操作逻辑分开
- 扩展性强:添加新的操作只需要定义新函数,不需要修改主逻辑
Lambda函数:简洁的匿名函数
对于简单的操作,定义完整的函数可能会显得冗余。Lambda函数提供了一种创建小型匿名函数的方式,特别适合在高阶函数中使用。
Lambda函数的特点:
- 语法简洁:一行代码就能定义函数
- 即用即抛:通常用于一次性的简单操作
- 功能限制:只能包含表达式,不能包含语句
# 使用lambda函数
numbers = [1, 2, 3, 4, 5]
print(f"双倍结果: {apply_operation(numbers, lambda x: x * 2)}")
print(f"平方根结果: {apply_operation(numbers, lambda x: x ** 0.5)}")# 排序中使用lambda
students = [("Alice", 85),("Bob", 92),("Charlie", 78),("Diana", 96)
]# 按成绩排序
sorted_by_score = sorted(students, key=lambda x: x[1], reverse=True)
print(f"按成绩排序: {sorted_by_score}")
总结
编程是一门需要实践的技艺。理论固然重要,但唯有在真实项目中不断磨砺应用,才能真正融会贯通。愿你在这条Python编程之路上不断精进,写出更优雅高效的代码!
我是颜颜yan_,期待与您交流探讨。



深度解析:从战略目标到数据字典)
- Models模型之ORM操作)



)











