一、关于产品
1.1 产品介绍
NVIDIA Nsight Deep Learning Designer 是一款面向 AI 推理开发者的可视化建模与优化工具。它支持基于 ONNX 格式的神经网络模型编辑、结构可视化、性能分析与 TensorRT 引擎导出,帮助用户更高效地设计、调优和部署高性能推理模型。该工具集成了 ONNX Runtime 和 TensorRT Profiler,能够提供从模型结构到底层 GPU 推理过程的全面洞察,简化深度学习推理工作流。
1.2 核心优势
全流程可视化模型编辑 通过拖拽式图形界面创建、编辑和优化 ONNX 格式模型,无需手写代码即可完成模型设计与调优。
深度性能剖析 内置 ONNX Runtime 和 TensorRT 推理性能分析功能,精准呈现 GPU 使用率、Tensor Core 利用率和各层执行时间,助力发现瓶颈并指导优化。
高效推理引擎导出 一键将优化后的 ONNX 模型导出为 TensorRT 引擎文件,支持多种精度(FP32、FP16、INT8、FP8),显著提升部署性能。
多平台支持与远程调优 支持本地和远程 GPU 设备,包括数据中心 GPU、RTX 桌面显卡及 Jetson 嵌入式平台,通过 SSH 无缝连接目标设备进行模型测试与分析。
与 NVIDIA 推理生态无缝集成 与 NVIDIA TensorRT、ONNX Runtime 及 NGC 平台紧密集成,支持模型快速迁移与部署,降低工程成本。
二、前期准备
3.1 软件安装
https://developer.nvidia.com/nsight-dl-designer/getting-started#下载网址

如上点击,需要登陆nvidia账号下载,登录成功后等待程序下载完成
安装完成!
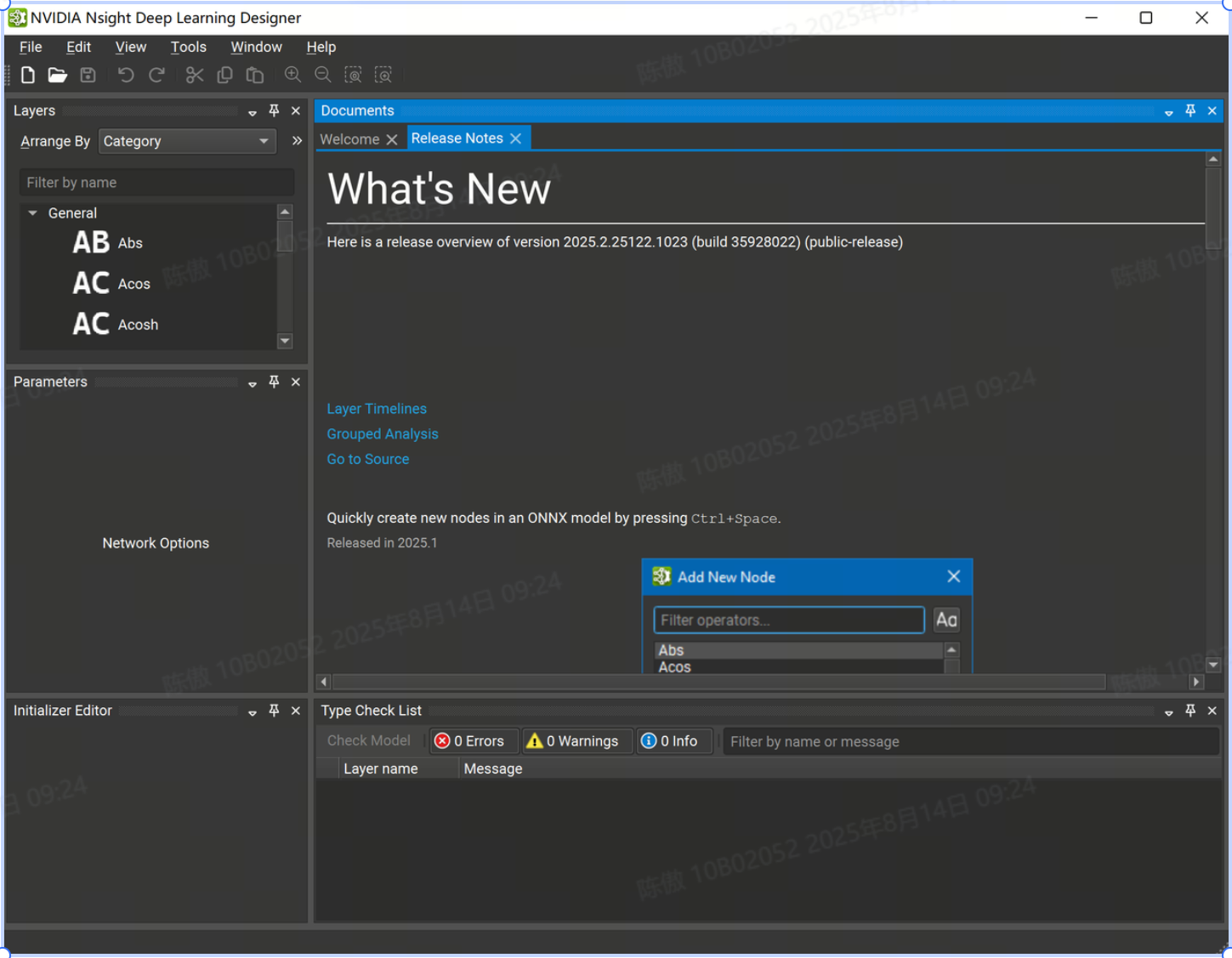
三、开始使用
创建新模型
Nsight Deep Learning Designer 既可以打开现有的 ONNX 模型,也可以从头开始创建一个新模型。可以在 File > New File 下创建新模型。
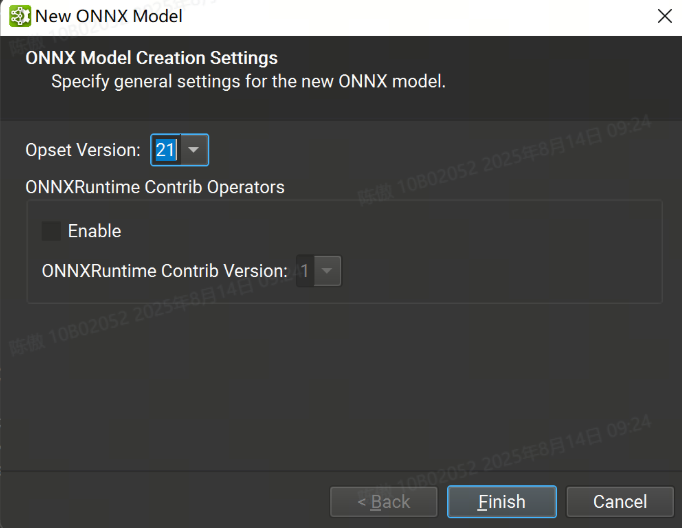
在此对话框中,可以选择新模型所需的 ONNX Opset 版本。目前支持从版本 1 到版本 21 的所有 Opset。也可以导入 ONNXRuntime Contrib 运算符集。
Workspace
每个打开的 ONNX 模型都由工作区中的文档选项卡表示。多个型号可以同时打开,并使用对接系统进行排列。工作区的中心元素是画布,可以在其中通过放置层节点并在它们之间创建连接来创建和编辑模型图。可以使用可停靠的工具窗口安排工作区。所有工具窗口都可以在 View > Windows 和 model canvas 上下文菜单下找到。可以查阅 Window (窗口) 菜单下的命令来保存、应用或重置布局。
默认工作区由 Layer Palette、Parameter 窗口、Initializer Editor 和 Type Checking 窗口组成。
首次加载模型时,画布将显示整个模型图。可以使用 Ctrl + 鼠标滚轮进行放大和缩小,也可以通过右键单击并拖动框来缩放区域。使用鼠标中键单击并拖动可向任意方向平移视图。通过单击画布右上角的齿轮图标,然后选择 Controls 选项卡,可以查看导航作的完整列表。
为了更轻松地在画布中直观地对齐节点,可以使用 View (查看) > Show Grid (显示网格) 菜单作来启用背景网格。 画布中的节点可以通过其唯一名称(如果 ONNX 模型中不存在,则自动生成)和它们的层类型来标识。
修改当前图形或模型的编辑作会将文档标记为已修改。只有在使用 File > Save 或 Ctrl + S 快捷键保存模型后,更改才会反映在磁盘上。 可以使用Ctrl + Z 和 Ctrl + Y 快捷键撤消和重做当前会话中的编辑操作。
布局
首次打开模型时,布局算法会自动将节点定位在画布上。 通过 ONNX 模型将各个节点位置保留在配套配置文件中,以便在重新打开时恢复节点位置。 可以使用 View > Arrange Nodes 菜单作在任何模型上显式运行布局算法。
导出 Canvas
可以使用 File > Export > Export Canvas As Image(将画布导出为图像)菜单作将整个模型画布导出为单个图像文件。背景颜色、网格颜色和状态以及图像保存位置可以从下图的对话框中设置。支持的图像格式为 PNG、JPEG 和 SVG。
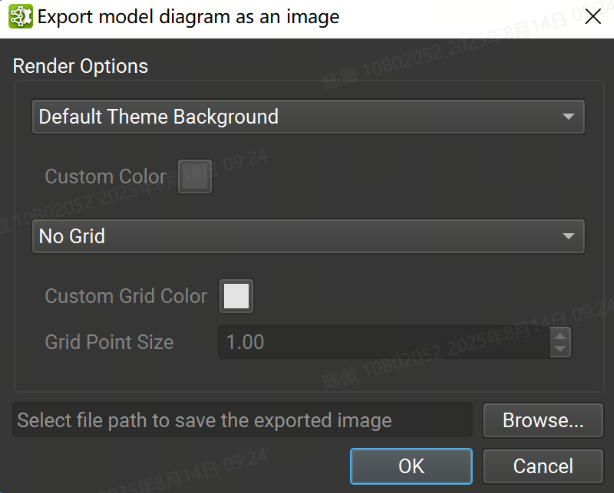
层Layers
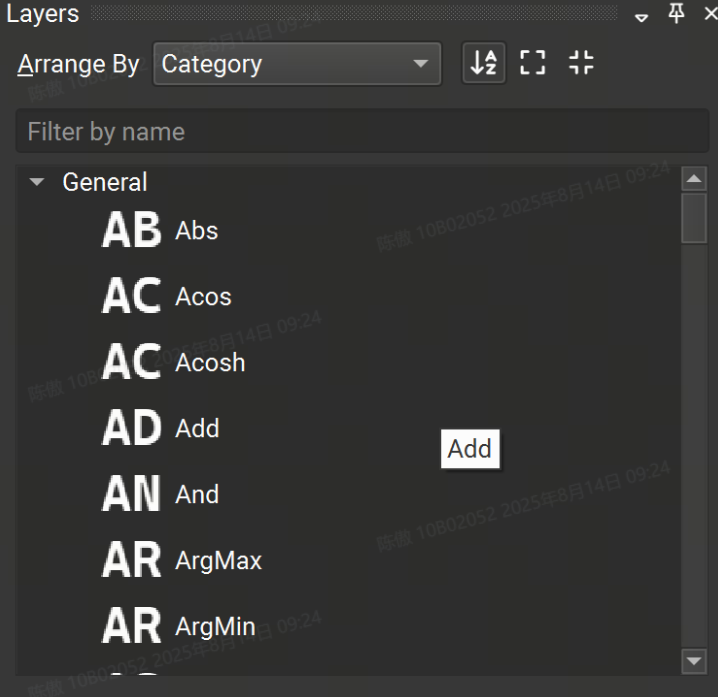
Layer Palette 包含可从其导入的运算符集添加到模型的可用运算符列表。图层可以按名称、集合或类别进行排列。还可以对 Layer 调色板进行排序或筛选。要将新的图层实例添加到画布中,只需从调色板中拖放即可。
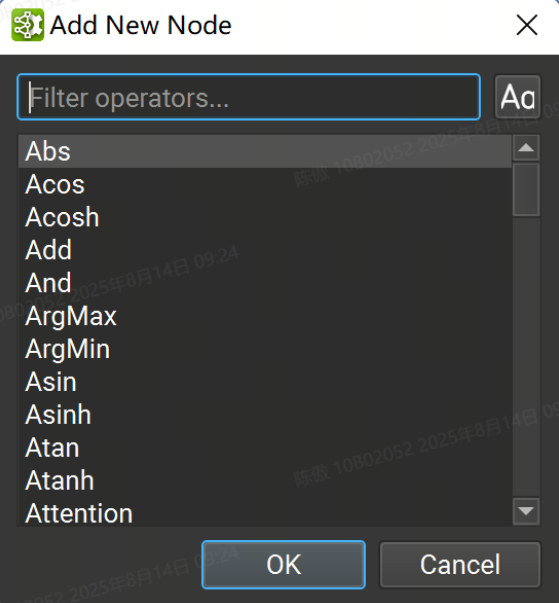
或者,将鼠标光标放在模型画布中的任意位置,然后按“Control + 空格键”打开一个快速节点添加对话框,如下图所示。在搜索框中输入将过滤可用图层列表,按“Enter”或双击列表条目会将所选图层添加到鼠标光标下的画布中。
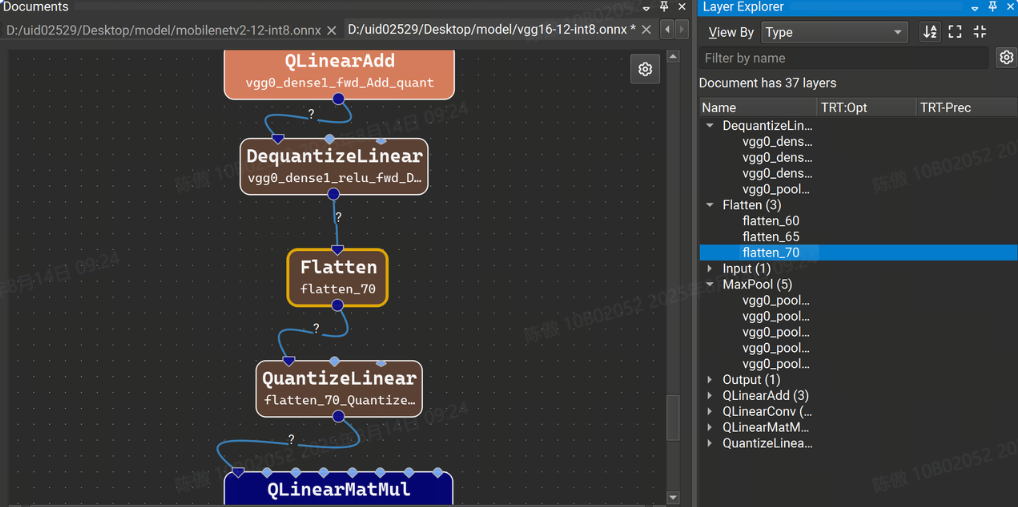
Layer Explorer 显示模型中当前层的列表。模型层可以按层类型或名称进行组织,并从“按名称筛选”搜索框中按名称进行筛选。图层的排序顺序可以在工具栏中切换。双击 Layer Explorer 中的图层可跳转到画布中的图层。
Layer Explorer 的高级过滤选项可通过单击 Filter by name 文本框旁边的齿轮图标来访问。高级筛选选项允许按层类型和分配给层的任何属性(例如 TensorRT 层精度)进行筛选。带有活动高级过滤器数量的红色徽章显示在齿轮上。
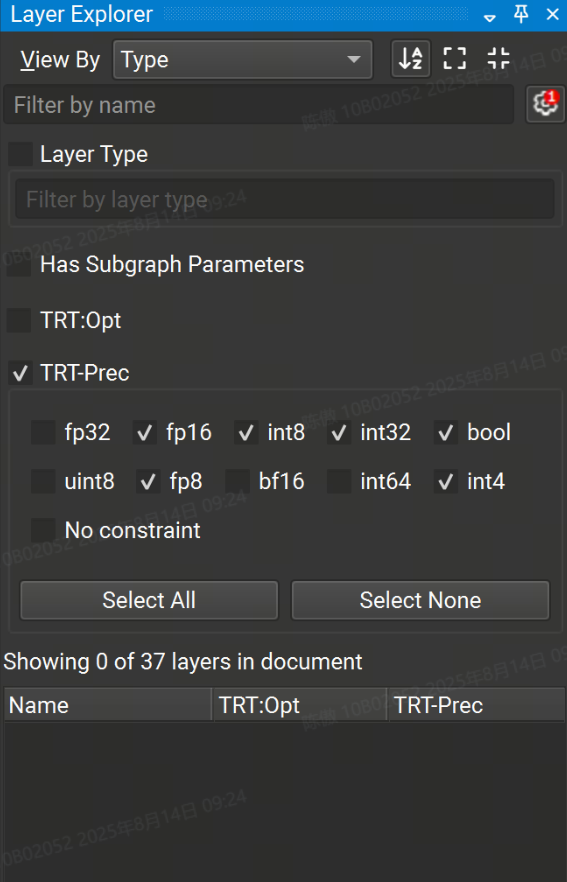
默认情况下,常量节点在 Model Canvas 和 Layer Explorer 中处于隐藏状态。要显示常量节点, View > Show All Constants。要在打开新模型时不再默认隐藏常量, Tools > Options,然后在 Model Canvas 页面下,将 Hide Constant Layers 设置为 No。
参数
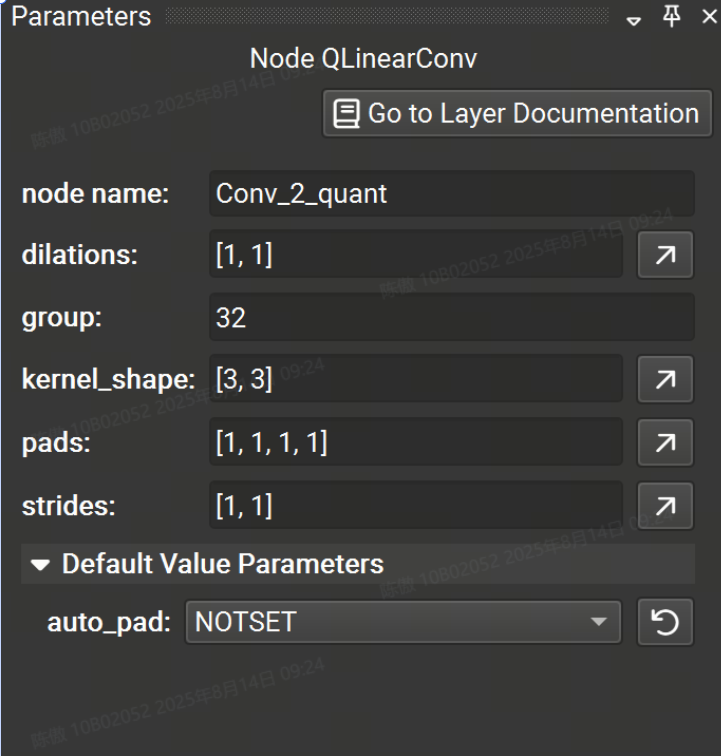
parameter 工具窗口允许对任何节点的参数进行交互式修改。从画布中选择一个节点,将列出该运算符的可用参数。节点名称也可以编辑,但它在整个图形中必须是唯一的。
具有未指定值的参数将获得 Opset 中指定的默认值,并显示在参数编辑器的可折叠的 Default Value Parameters 部分中。 修改参数时,该参数将移出 default value 部分。要将参数恢复为默认值,单击圆形箭头图标,当鼠标悬停在字段上时,该图标位于参数输入字段的右侧。
Tensor/List 值应采用以下格式:并且可以嵌套多维张量 。字符串值必须用单引号括起来, 可以使用将单引号嵌入到字符串文本中。 要获得更高级的张量或列表编辑功能,使用 Tensor Editor,方法是单击任何张量/列表类型参数最右侧的向上箭头按钮。[1, 2, 3, 4][[1, 2], [3, 4]]'Some text'\'It\'s alive!'
如果当前未选择任何层,则会显示模型信息,例如导入的 ONNX opset 版本。 可以一次选择多个图层,以便进行批量参数编辑。仅显示所选节点共有的参数。
编辑模型
将运算符拖放到画布中会创建该运算符类型的新实例,并使用自动生成的名称。所有实例都必须具有可编辑的唯一名称;名称应为有效的 C90 标识符。运算符由画布上的矩形节点表示。此节点显示运算符的名称和类型,如果类型检查器报告了任何问题,则显示一个图标。
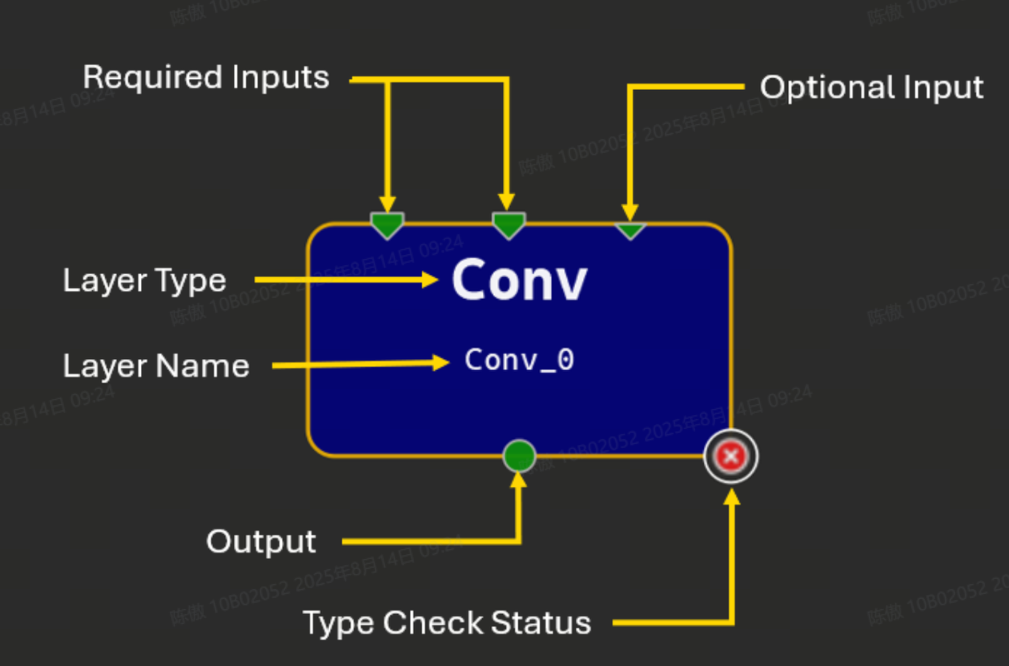
节点图示符表示使用终端的运算符的输入和输出。节点顶部的三角形表示输入,节点底部的圆圈表示输出。大多数输入端子需要连接才能使模型有效,但可选的输入端子不是必需的。可选输入在字形上用较小的三角形表示。多条链路可以从单个输出端子开始,但只能将一条链路连接到给定的输入端子。未连接的终端为绿色,带链接的终端为深蓝色,连接到初始值设定项的输入终端为浅蓝色。
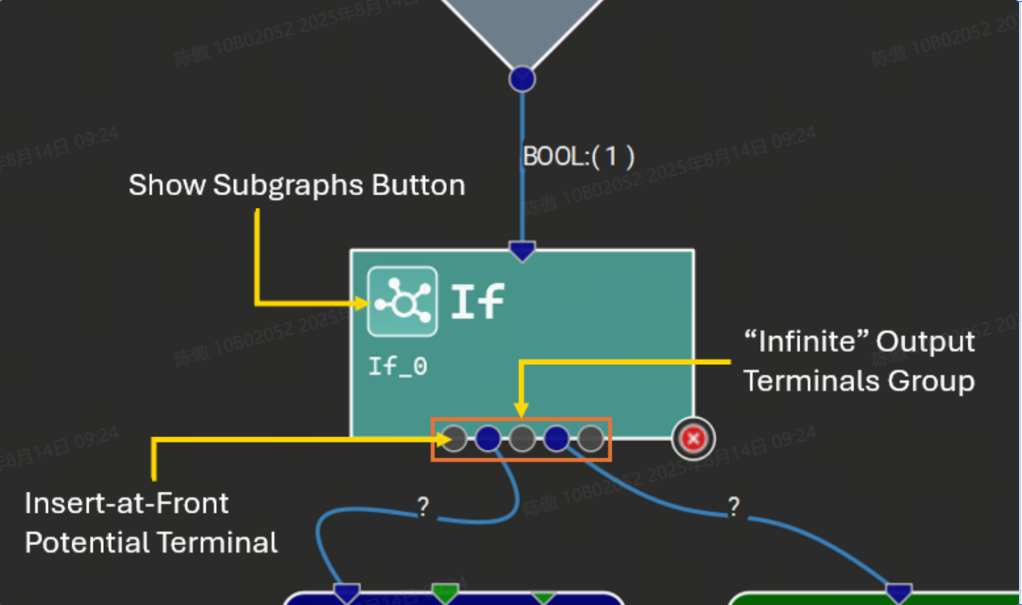
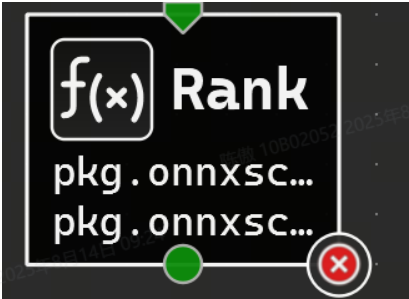
某些运算符接受给定参数的可变数量的输入张量,或者为给定的输出名称生成可变数量的输出张量。Nsight Deep Learning Designer 通过特殊的 “无限” 终端来表示这些。在连接到无限端子时,每个连接的端子之间将出现更多的灰色端子,代表潜在的新连接点。下图显示了一个具有可变输出数量的运算符示例,以及子图。
初始值设定项
初始化器在 ONNX 中用于表示常量张量值,例如权重。它们可以直接用作输入,而无需引入额外的 Constant 运算符。单个初始值设定项可以由图中的多个运算符使用。初始值设定项值可以直接嵌入到 ONNX 模型中,也可以从外部二进制文件引用。 每个初始值设定项都由模型中的唯一名称标识。
初始值设定项编辑器工具窗口允许用户查看和编辑已打开的 ONNX 模型的初始值设定项。
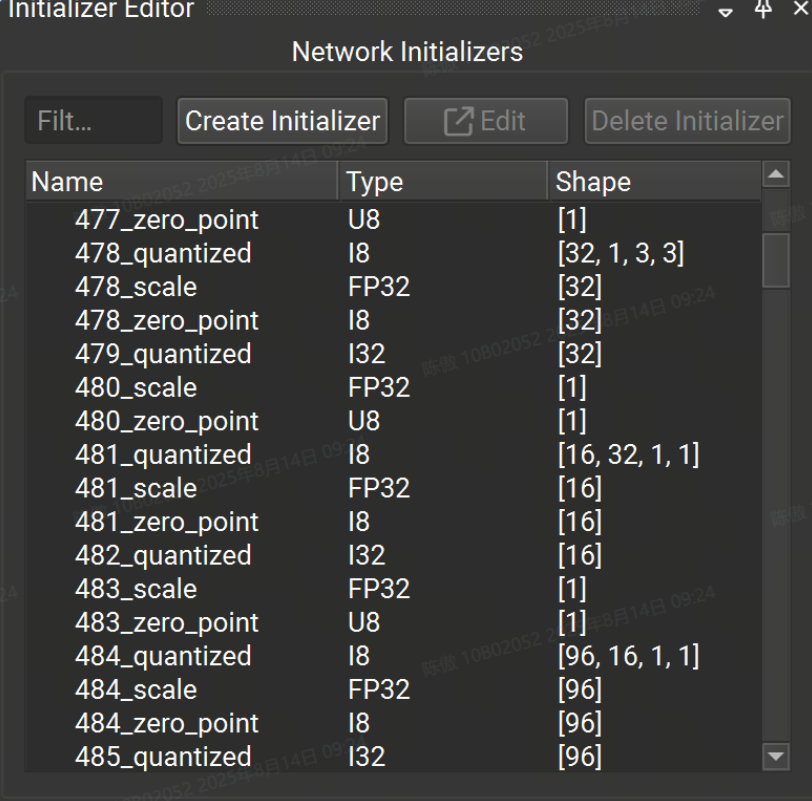
初始值设定项编辑器分为两部分:上半部分用于查看、创建、编辑和删除模型中的任何初始值设定项,下半部分用于查看和连接当前所选节点的初始值设定项。如果当前未选择任何节点,则下半部分将被隐藏。
网络初始值设定项列表可以按名称进行筛选。所选的初始值设定项可以是:
-
从模型中删除,这也将断开它们与当前使用它的任何节点的连接。
-
使用张量编辑器进行编辑。
可以使用创建初始值设定项按钮打开对话框,从头开始创建初始值设定项。
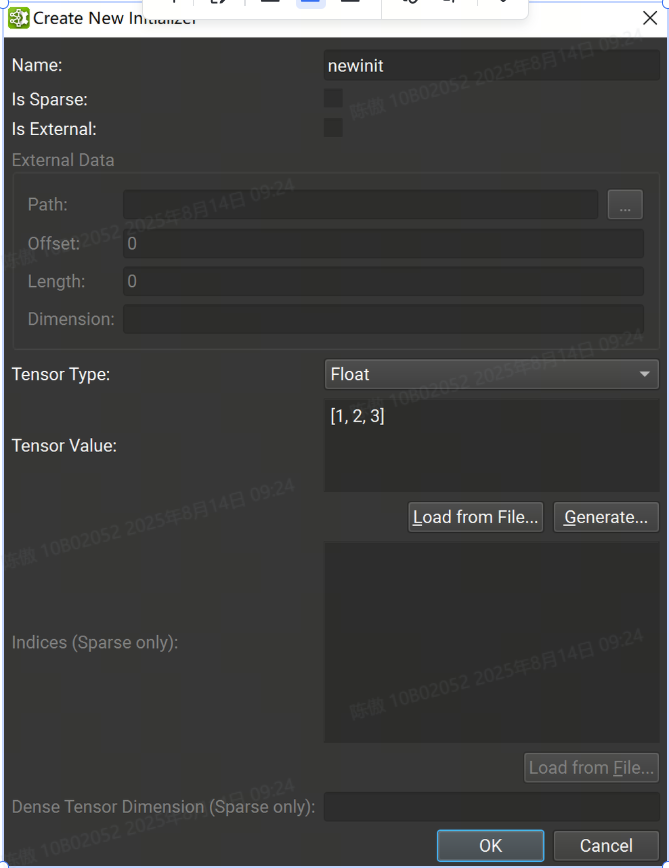
从那里,可以提供初始值设定项信息,例如名称、张量类型和张量值。字符串值必须用单引号括起来。可以从 Numpy 文件加载 Tensor 值。请注意,在加载之前,数据类型必须与 Numpy 文件中的数据类型匹配。[1, 2, 3, 4][[1, 2], [3, 4]]'Some text'\'It\'s alive!'
也可以使用随机或归零数据生成初始值设定项以用于占位符目的。从 Create New Initializer 对话框中选择张量类型,然后按 Generate... 按钮。目前并非所有张量类型都支持随机生成;如果没有可用的生成支持,则该按钮将被禁用。
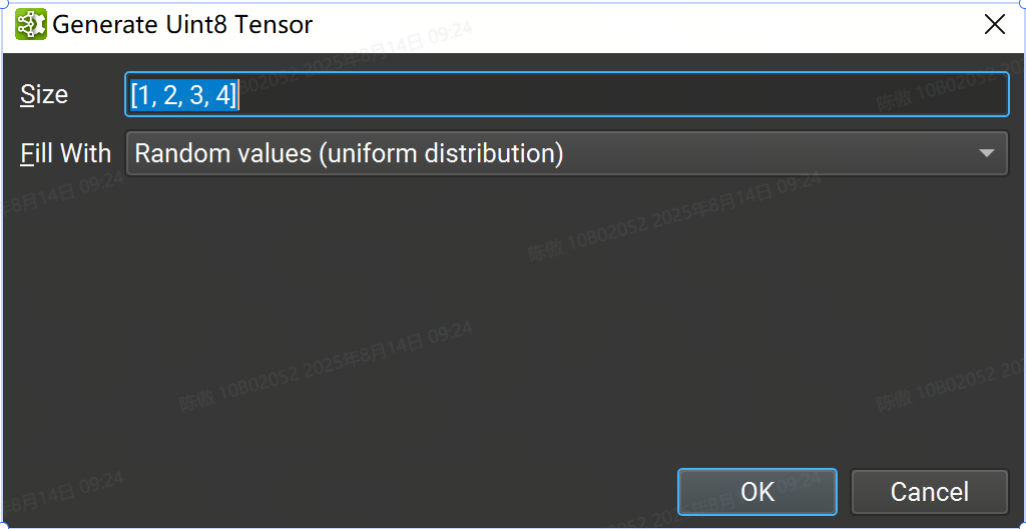
在 format 中输入张量的大小,然后选择 fill 方法:[1, 2, 3, 4]
-
随机值(标准正态分布)使用标准正态分布(均值 = 0,方差 = 1)。可用于使用多个字节进行存储的浮点类型。
-
零值将生成的张量的每个元素设置为零。适用于所有类型。
-
随机正值 (uniform distribution) 使用类型支持的所有正值的均匀分布。排除零。可用于至少使用一个字节进行存储的所有整数类型。
-
随机负值 (uniform distribution) 使用类型支持的所有负值的均匀分布。排除零。可用于至少使用一个字节进行存储的有符号整数类型。
如果初始值设定项标记为外部,则必须提供磁盘上二进制文件的路径。外部文件必须位于相对于模型存储位置。因此,在处理仅内存中的模型(例如未保存的新模型)时,无法创建外部初始值设定项。偏移量是存储数据开始的文件中的字节位置,长度是包含数据的字节数。外部初始值设定项张量数据不直接存储在 ONNX 模型中。这可以减小模型文件的大小。
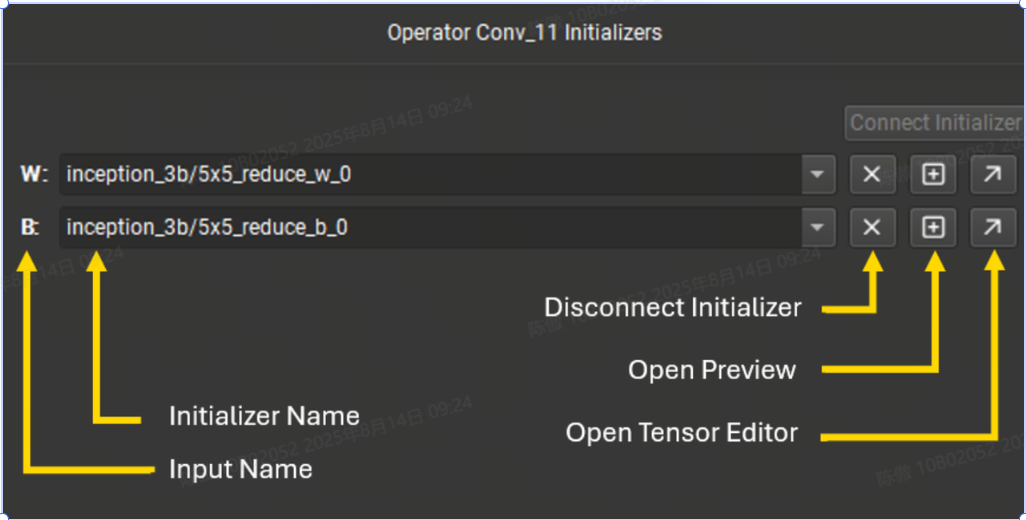
从画布中选择节点时,如果它有一个空闲终端,则启用 连接初始值设定项 按钮以允许将模型初始值设定项连接到该节点。 连接后,终端将在节点字形上变为黄色,表示它已连接到初始值设定项。将链接连接到它将断开初始值设定项与节点输入的连接。
初始值设定项编辑器的底部列出了当前所选节点的所有连接到初始值设定项的终端。可以使用下拉菜单切换终端使用的初始值设定项。下拉列表可按名称过滤。 使用十字按钮,可以断开初始值设定项与终端的连接。加号按钮打开张量值的预览,对角线箭头按钮将打开张量编辑器。
子图Subgraphs
一些 ONNX 控制流运算符,例如 Loop 和 If 将一个或多个子图作为参数。子图是与其父模型具有相同初始化器和导入操作集的ONNX图形。
子图的作用域由其父级决定,无论是运算符实例还是局部函数定义。作用域内的所有子图都必须具有唯一的名称。
可以使用Tools > Extract Model Subgraph命令将子图导出到 Nsight 深度学习设计器中的独立 ONNX 模型。在打开的对话框中,通过标识子图的父类型(运算符或局部函数)、父作用域的名称以及该作用域内的子图名称来选择子图。然后选择用于保存提取的子图的输出路径。
仅列出当前文档中的运算符。要从另一个子图或本地函数内的运算符导出子图,必须从相应的子图或本地函数文档中打开 Tools > Extract Model Subgraph 向导。
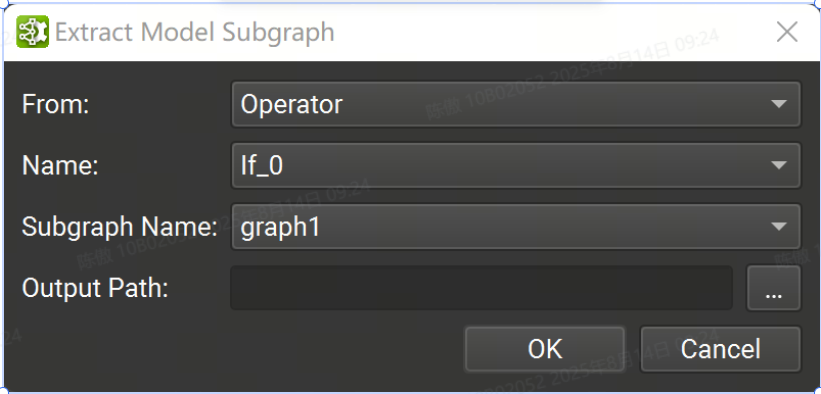
在创建对话框中,必须提供给定其范围的唯一子图名称。可以启用一些选项,以便在创建子图后打开子图,以及从运算符或局部函数子图复制现有子图。
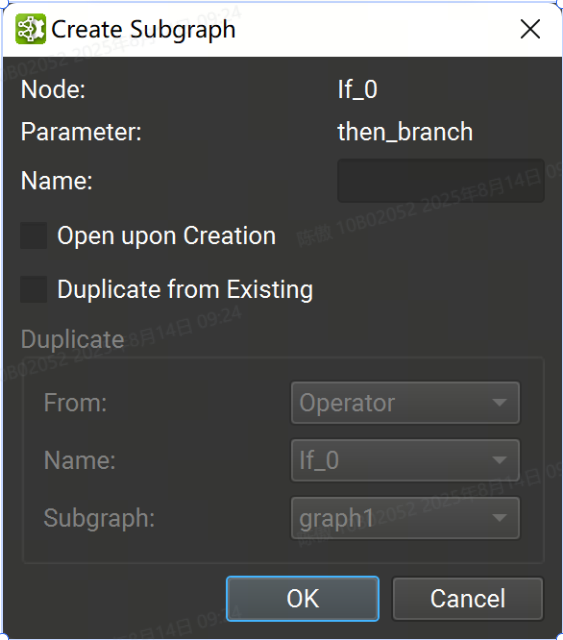
子图可以在单独的文档选项卡中可视化。要打开子图,请单击运算符字形上的子图按钮,然后从菜单中选择所需的子图,或在参数编辑器工具窗口中单击子图的链接。
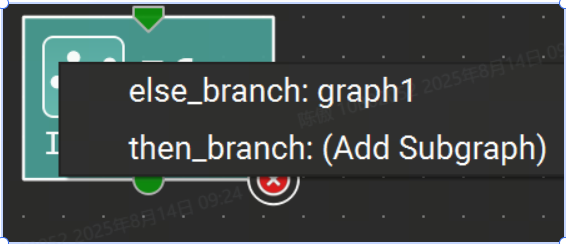
打开后,就像普通的 ONNX 模型一样编辑子图,模型初始值设定项在子图中没有模拟,因此无法编辑。使用主工具栏上的“Confirm Subgraph Edits”按钮保留封闭文档中子图中的更改。此命令更新父文档以反映对子图的更改。否则,父文档是只读的,而其子图则打开以供编辑。
本地函数
图形组件通常在模型中重复。局部函数可用于表示这些重复模式。这通过将模式抽象为单个节点来创建模型的更高级别表示。
除了创建或删除模型初始值设定项外,还可以像普通模型一样编辑本地函数。必须使用主工具栏上的 Confirm Local Function Edits 按钮来应用对本地函数所做的更改。应用后,本地函数定义将在模型中更新。
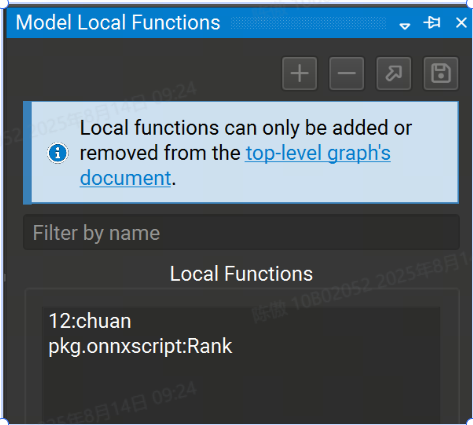
以使用 Model Local Functions (模型本地函数) 工具窗口管理本地函数。它列出了模型中当前定义的所有函数,该列表可以按名称进行过滤。
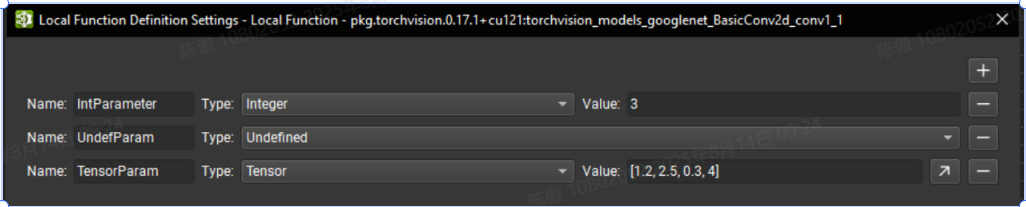
此外,还可以参数化局部函数。在 Nsight Deep Learning Designer 中编辑函数时,可以使用Tools > Local Function Settings action打开局部函数定义设置对话框。
在此对话框中,可以使用 + 按钮定义新参数。必须提供唯一的名称以及参数类型。undefined 类型的参数要求函数的每个实例在传递此参数的值时提供一种类型的信息。否则,必须为所有其他类型提供默认值。也可以通过单击相应的 - 按钮来删除参数。
可以使用 Model Local Functions (模型本地函数) 工具窗口管理本地函数。它列出了模型中当前定义的所有函数,该列表可以按名称进行过滤。可以使用箭头和保存按钮分别打开所选函数或将其提取到独立的 ONNX 模型中。
+ 按钮创建新的本地函数。提供函数名称和域。- 按钮从模型中删除本地函数。该函数的所有实例都将转换为自定义运算符。
批量修改
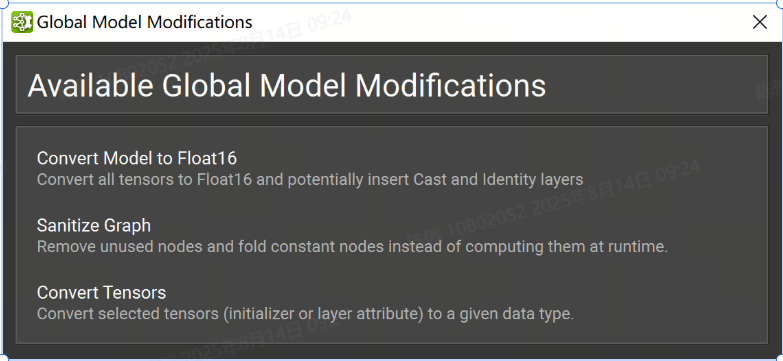
在某些工作流中,可能需要修改 ONNX 模型的大部分或对每个节点执行特定修改。可以在Tools > Global Model Modification对话框下找到该工具。
模型转为FP16
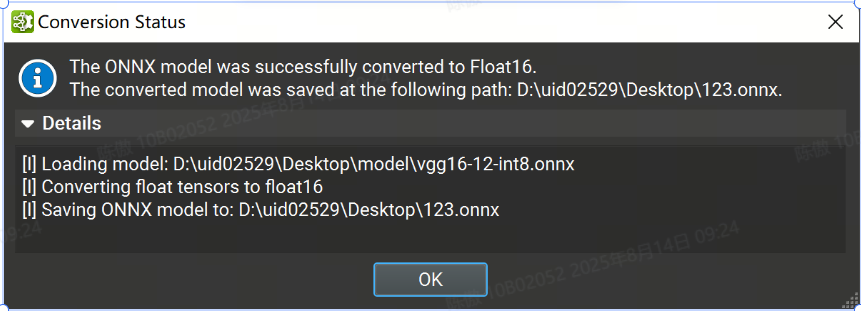
一种常见的模型优化技术是将模型权重转换为半精度格式(例如 FP16)。这可以将模型大小减少一半,并提高某些 GPU 的性能,但可能会牺牲一些精度。
在tools > Global Model Modification对话框下,可以将 ONNX 模型转换为使用 Float16。提供转换后的模型的输出路径,然后单击“完成”。执行转换时会出现一个旋转的轮子。该过程完成后,将出现一个对话框,并显示转换状态,其中包含包含详细日志的可展开部分。
Sanitize Graph
在tools > Global Model Modification对话框下的“清理图形”批量修改作可以通过执行恒定折叠和删除未使用的节点来帮助减小 ONNX 模型的大小。
要执行图形清理,请在对话框中提供清理模型的输出路径,然后单击“finish”。该过程完成后,将显示一个对话框,其中包含包含详细日志的可展开部分的状态。
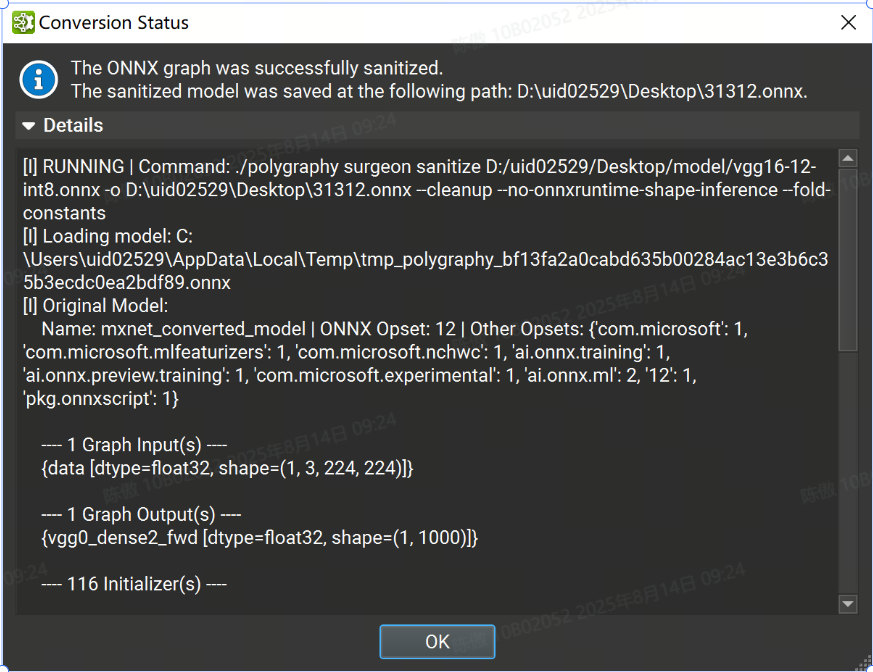
自定义选项
-
Set fold size threshold: 设定每个张量最大折叠尺寸阈值(以字节为单位),在此阈值之内的张量将进行常量折叠处理。任何生成的张量尺寸超过此阈值的节点将不会被折叠掉。
-
Number of constant folding passes: 设置恒定的折叠次数。计算张量形状的子图可能无法在单次折叠中达到要求。如果未指定,会自动计算所需的折叠次数。
转换Tensor
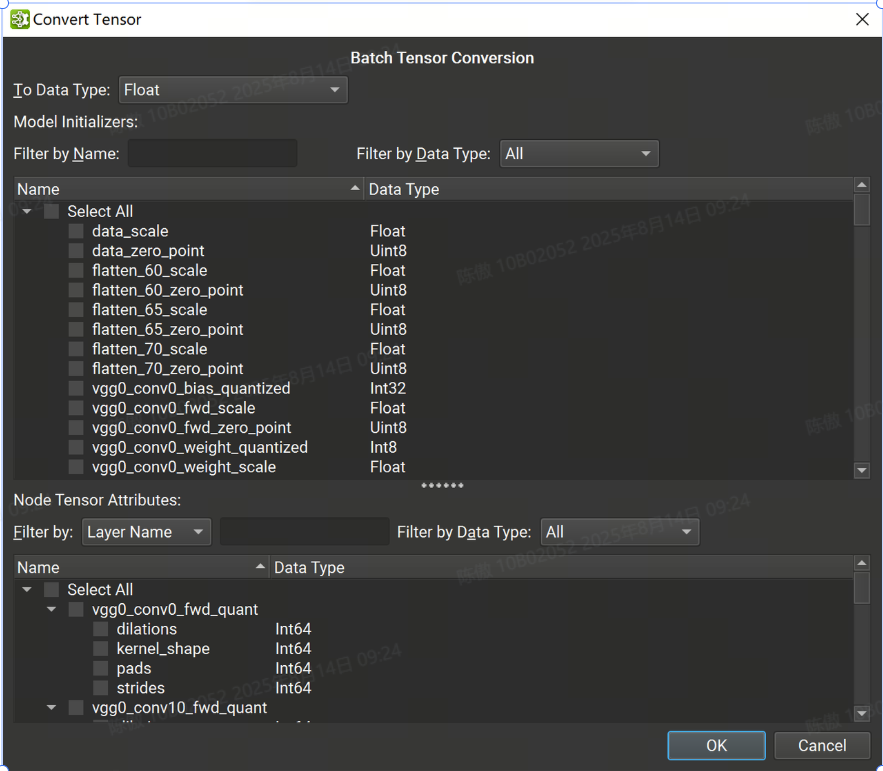
批量张量转换对话框分为两个面板:顶部列出所有模型初始值设定项,而底部包含所有张量或基于列表的节点属性。初始值设定项可以按名称和数据类型进行过滤,而节点的张量或列表可以按节点或张量名称和数据类型进行过滤。
可以使用对话框顶部的组合框选择节点张量、列表和初始值设定项的组合以转换为单个目标数据类型。选择所有必要的张量后。
根据源转化和目标转化数据类型,可能会发生数据精度丢失和/或截断。撤消批量转换会将之前转换的所有张量恢复为其原始数据类型和值。
用户工具
当用户工作流程需要处理超出全局模型修改系统提供的范围时,可以使用自定义用户工具。用户工具是一种将 ONNX 模型的自定义处理作为设计器设计工作流程的一部分的方法。
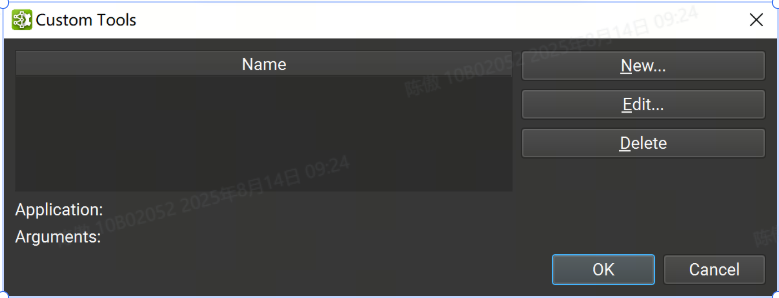
自定义工具可以通过 Tools > Custom Tools下可访问的对话框进行管理。该对话框包含用户定义的自定义工具列表。从列表中选择一个工具将在底部显示其应用程序路径和参数。 可以使用对话框右侧的相应按钮删除或编辑选定的自定义工具。
可以使用“new”按钮创建新的自定义工具,这将打开一个新的对话框窗口,其中必须提供工具信息:
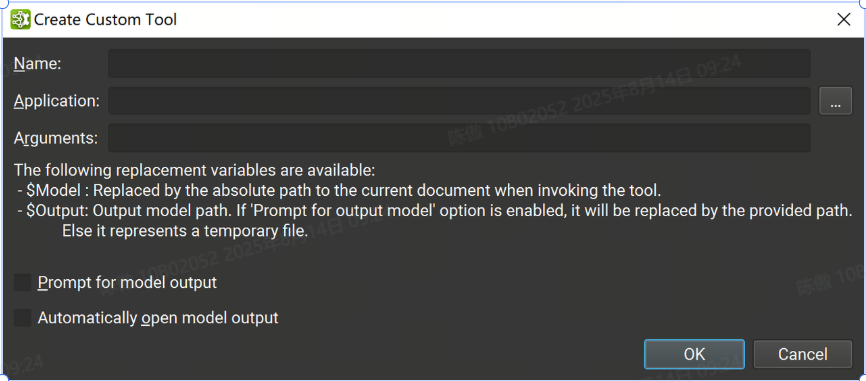
-
Name: 用于标识工具的唯一名称
-
Application: 启动该工具的可执行进程的应用程序路径
-
Arguments: 要传递给应用程序的可选参数。有两个特殊的替换参数可用:
$Model: 在启动工具时被当前 ONNX 文档绝对路径替换。
$Output:“提示输入模型输出”选项会提示输入此路径。如果禁用该选项,则这是临时文件的路径。
-
Prompt for model output: 如果打开,则在调用该工具时将打开一个对话框,询问将用于替换参数的路径。
-
Automatically open model output: 如果打开,当工具成功完成并且如果参数列表中设置了变量时,将自动打开输出文档
请注意,要运行 Python 脚本,应用程序路径应指向 Python 解释器,并且提供的第一个参数应是 Python 脚本的路径。
自定义用户工具可以在 Tools > User 子菜单下找到,从该菜单中选择一个工具将调用它,给定当前关注的 ONNX 模型。将打开一个对话框窗口,并提供运行过程的当前状态以及标准输出和错误日志。可以使用“取消”按钮取消自定义工具进程,这将导致进程被终止。 根据是否为工具设置了自动打开模型输出选项,当工具成功退出时,将打开输出模型(如果有)。
活动平台设置
活动可以在 Linux、Windows 或 NVIDIA L4T 上本地运行,也可以在 Linux 和 NVIDIA L4T 目标计算机上远程运行。对于在本地运行的活动,主机和目标计算机是相同的。(主机平台指运行Nsight设计器的计算机,目标平台指运行活动的计算机)
连接管理
在 Nsight 设计器中启动活动时,活动窗口的顶部用于选择将在哪台目标计算机上执行活动。支持本地和远程目标。 默认情况下,将选择在运行主机应用程序的平台上执行。
点击 Profile Model 可以调出 Session Settings
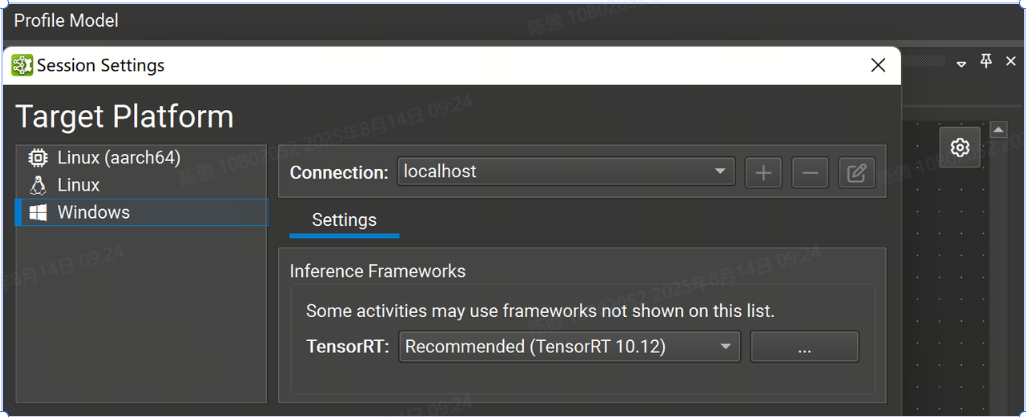
目前,Nsight 支持以下平台:
-
Windows x86_64:仅限本地。
-
Linux x86_64:本地和远程。
-
NVIDIA L4T arm64:本地和远程。
使用远程目标时,必须从顶部下拉列表中选择或创建连接。要创建新连接,选择 + 并输入远程连接详细信息。使用本地平台时,将选择 localhost 作为默认主机,无需进一步的连接设置。
远程连接
可以在“连接”对话框中将支持 SSH 的远程目标配置为目标。要配置远程设备,需要选择支持 SSH 的目标平台,然后按 + 按钮。将显示以下配置对话框。
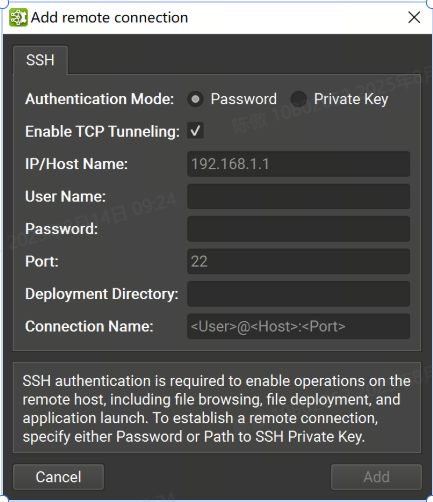
支持密码和私钥认证方式。在此对话框中,选择身份验证方法并输入以下信息:
-
密码
-
IP/Host Name:目标设备的 IP 地址或主机名。
-
User Name: SSH 连接的用户名。
-
Password: SSH 连接的用户密码。
-
Port: SSH 连接的端口。(默认值为 22)。
-
Deployment Directory:在目标设备上用于部署支持文件的目录。指定的用户必须具有对此位置的写入权限。支持相对路径。
-
Connection Name:将显示在 Connection (连接) 对话框中的远程连接的名称。如果未设置,它将默认为 。
<User>@<Host>:<Port>
-
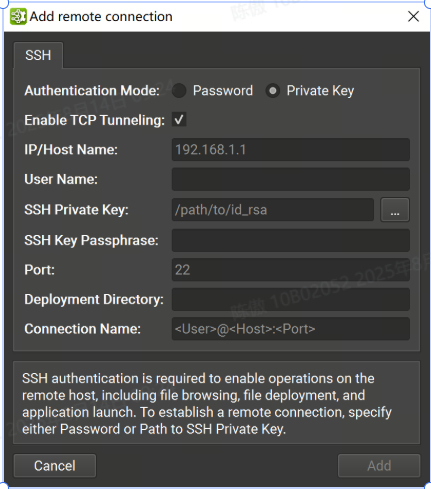
-
私钥
-
IP/Host Name:目标设备的 IP 地址或主机名。
-
User Name: SSH 连接的用户名。
-
SSH Private Key:用于向 SSH 服务器进行身份验证的私钥。
-
SSH Key Passphrase:私钥的密码。
-
Port: SSH 连接的端口。(默认值为 22)。
-
Deployment Directory:在目标设备上用于部署支持文件的目录。指定的用户必须具有对此位置的写入权限。支持相对路径。
-
Connection Name:将显示在 Connection (连接) 对话框中的远程连接的名称。如果未设置,它将默认为 。
<User>@<Host>:<Port>
-
远程启动 Activity 后,如有必要,所需的二进制文件和库将复制到远程计算机上的 Deployment Directory。
在 Linux 和 NVIDIA L4T 主机平台上,Nsight Deep Learning Designer 支持在目标计算机上进行 SSH 远程分析,这些计算机无法通过 ProxyJump 和 ProxyCommand SSH选项 从运行 UI 的计算机直接寻址。 这些选项可用于指定要连接的中间主机或要运行的实际命令,以获取连接到目标主机上的 SSH 服务器的套接字,并且可以添加到 SSH 配置文件中。
请注意,对于这两个选项,Nsight Deep Learning Designer 都会运行外部命令,并且不会实施任何机制,以使用在连接对话框中输入的凭证向中间主机进行身份验证。这些凭证将仅用于对计算机链中的最终目标进行身份验证。
使用 ProxyJump 选项时,Nsight Deep Learning Designer 使用 OpenSSH 客户端建立与中间主机的连接。这意味着,为了使用 ProxyJump 或 ProxyCommand,必须在主机上安装支持这些选项的 OpenSSH 版本。
在这种情况下,向中间主机进行身份验证的常见方法是使用 SSH 代理并使其保存用于身份验证的私钥。
由于使用了 OpenSSH SSH 客户端,因此还可以使用 SSH askpass 机制以交互方式处理这些身份验证。
部署工作流程
在开始活动之前,Nsight 深度学习设计器将检查目标机器上是否存在所有必要的依赖项;对于远程目标,Nsight 深度学习设计器将查看提供的Deployment Directory。对话框显示活动的依赖项列表和验证进度。如果某些依赖项丢失或不是最新的,则对话框中的它们条目将显示一个警告图标,并且 Nsight 深度学习设计器将开始在目标上部署它们。
在目标计算机上部署所有依赖项后,Nsight Deep Learning Designer 将继续启动活动。后续启动将更快,因为 Nsight 深度学习设计器不会重新部署依赖项,只要它们仍然符合活动要求。
Nsight 深度学习设计器将目标计算机下载的依赖项和辅助二进制文件存储在主机上,并将时序缓存和一些其他验证缓存存储在目标计算机上的本地缓存目录中。默认情况下,本地缓存目录存储在 Windows 上的HOME\AppData\ Local 中,在 Linux 上存储在 $HOME/.config 中。可以通过设置NV_DLD_CACHE_DIR环境变量来更改此目录。
使用 TensorRT
Nsight 深度学习设计器可以将 ONNX 模型导出到 TensorRT 引擎,并可选择对其进行分析。生成的引擎文件与其他 TensorRT 10.10 应用程序完全兼容。
笔记:
-
使用 Nsight 创建的 TensorRT 引擎特定于创建它们的 TensorRT 版本和创建它们的 GPU。有关详细信息,请参阅 TensorRT 文档。
-
Nsight 器在构建 TensorRT 网络时使用时序缓存。如果可能,将从缓存中加载常用层的战术计时。
-
引擎构建和分析阶段依赖于推理算法的准确时序,用于引擎优化和性能报告。为获得最佳效果,请勿将其他 GPU 工作与 TensorRT 活动并行运行,因为这会扭曲结果。
-
导出和分析活动都可以从“welcone”页面访问的“Start Activity”对话框启动。
Dynamic Shapes and TensorRT
TensorRT 在处理动态输入大小时需要优化配置文件。静态确定的输入大小不需要其他信息,但每个动态输入大小都需要优化配置文件详细信息。如果未以这种方式完全指定输入,TensorRT 将失败并出现错误,例如 .['batch', 3, 544, 960]['W', 'H']input_name: dynamic input is missing dimensions in profile 0
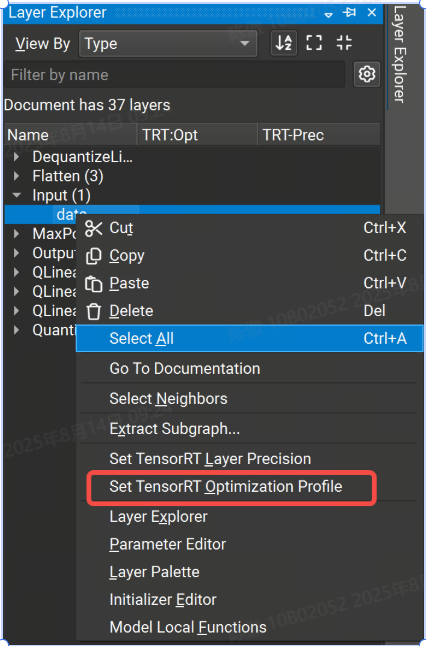
Nsight 提供了在主机 GUI 中定义优化配置文件的方法:
-
可以通过 TensorRT 优化配置文件属性设置各个层的优化配置文件。右键单击画布或图层资源管理器中的输入图层,然后选择 Set TensorRT Optimization Profile 上下文菜单项。这将打开一个对话框,您可以在其中定义输入的最小、最大和最佳大小。可选的 and 字段用于定义输入的最小和最大大小。请注意,优化配置文件只能应用于顶级图的输入,而不能应用于子图或局部函数。
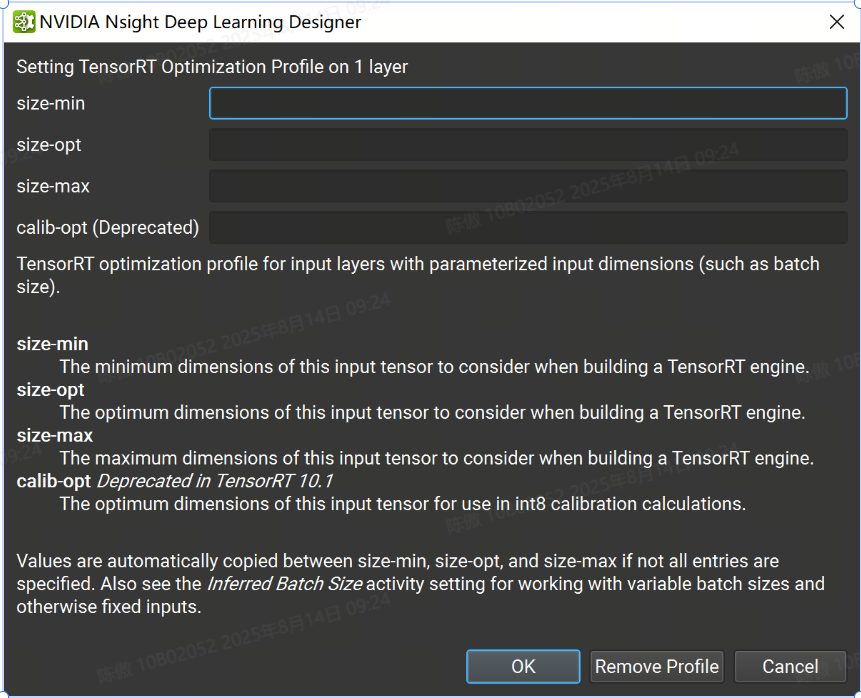
为 TensorRT 指定层精度
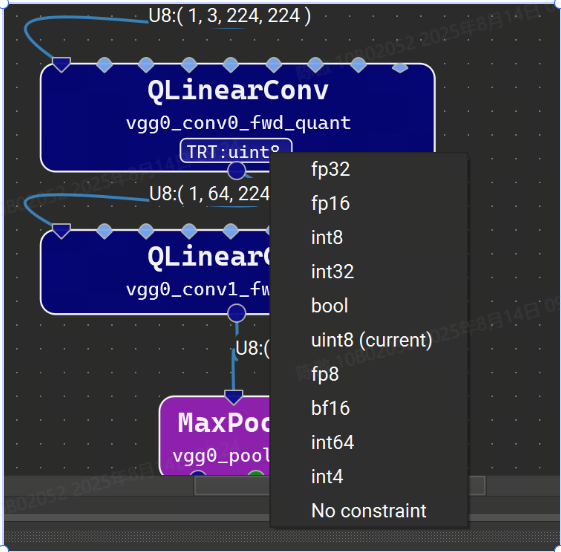
当使用默认设置运行时,TensorRT 将使用自动调整从启用的策略中选择每一层的数据类型精度,以最大限度地提高性能。但是,可以通过使用 Nsight 深度学习设计器中的 TensorRT 层精度属性在每层的基础上强制执行精度约束。可用的浮点精度选项包括:fp32、fp16、bf16 和 fp8。整数选项是 int64、int32、int8、int4、uint8 和 bool。如果未为图层分配精度,TensorRT 将使用自动调整为该图层选择最佳精度。请注意,除了指定精度约束外,还必须在活动设置中将键入模式设置为“遵守精度约束”或“首选精度约束”。
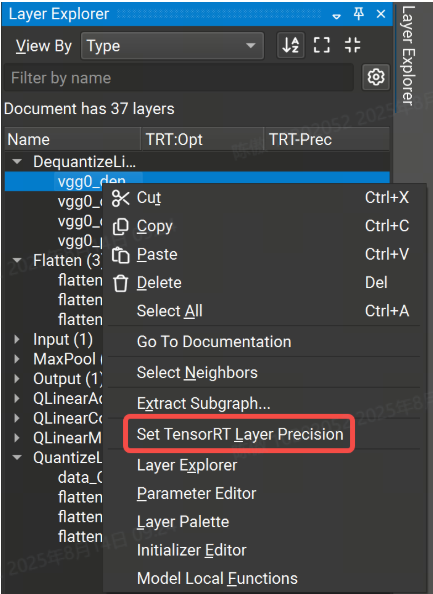
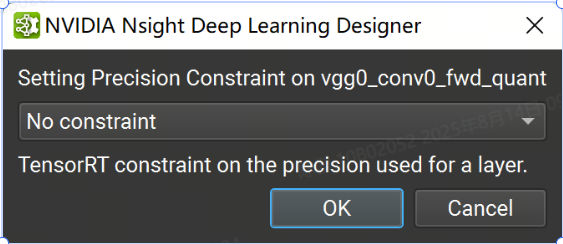
可以在 Nsight 深度学习设计器中设置层精度约束,方法是右键单击“层资源管理器”中的选定行或模型画布中的节点,然后选择“设置层精度”上下文菜单项,然后在出现的对话框中选择精度选项。要清除精度约束,请为选定层选择“无约束”选项。
具有精度约束的图层将具有显示在图层资源管理器的 TRT-Prec 列中的约束值,并且图层字形上将显示具有所选精度的小徽章。单击此标志将显示用于更改或删除约束的选项的快速菜单。
导出 TensorRT 引擎
要导出 TensorRT 引擎,请打开要导出的 ONNX 模型,然后使用 File > Export > TensorRT Engine 菜单项。ONNX 模型也可以从“开始活动”对话框中导出,而无需事先打开它们。
常用设置
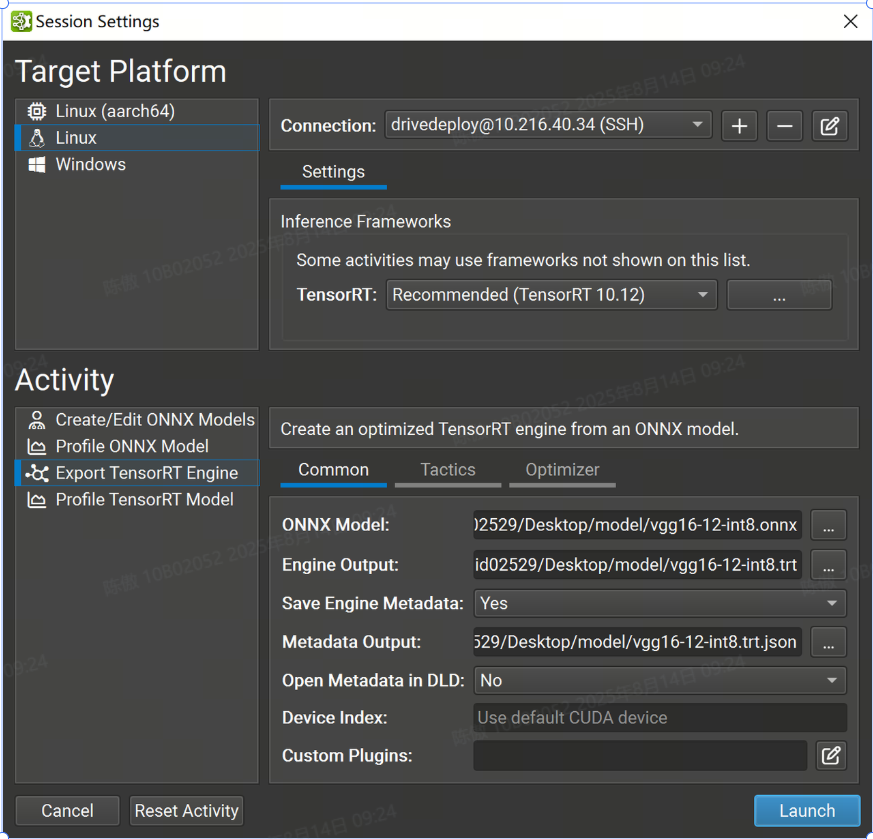
-
TensorRT:下拉选择要使用的TensorRT版本,也可以选择在目标系统上使用系统安装的 TensorRT,或指定自定义路径。如果指定自定义路径,则它必须是从目标计算机上的部署目录到 TensorRT 共享库位置的相对路径。
-
ONNX 模型:导出的模型的本地路径。如有必要,它将被复制到目标系统。
-
Engine Output :要保存导出的 TensorRT 引擎的本地目标。如有必要,将从目标系统复制它。该活动根据 ONNX 模型文件名建议此参数的默认名称。
-
Save Engine Metadata :控制存储在 TensorRT 引擎中的元数据量。当设置为 YES 时,-level 元数据(完整信息)将存储在引擎中。将此选项设置为 No 将删除所有图层信息。
-
Metadata Output:是可选的。如果为该参数提供了本地路径,则 Nsight 将在导出后创建一个 TensorRT 类的实例,并从目标系统复制其输出。如果此参数留空,则不会创建任何元数据文件。该活动根据 ONNX 模型文件名建议此参数的默认名称。
-
在DLD中打开Metadata:控制导出后是否在Nsight中打开元数据文件作为模型进行可视化。仅当生成元数据文件时,此选项才可用。
-
设备索引选项:控制在多 GPU 系统上使用的 CUDA 设备。设备零表示默认的 CUDA 设备,设备按调用中的顺序排列。如果此设置留空,则 Nsight 深度学习设计器将使用第一个 CUDA 设备。
-
自定义插件:允许在引擎构建期间将路径传递到可选的自定义TensorRT插件以加载。提供的路径必须相对于所选目标系统。插件必须与选定的 TensorRT 版本兼容。
战术设置
本部分中的大多数设置都与 TensorRT 的枚举密切相关。BuilderFlags
FP32 张量格式和策略始终可用于 TensorRT。如果 TensorRT 会导致整体运行时间缩短或不存在较低精度的实现,则仍可能选择更高精度的层格式。
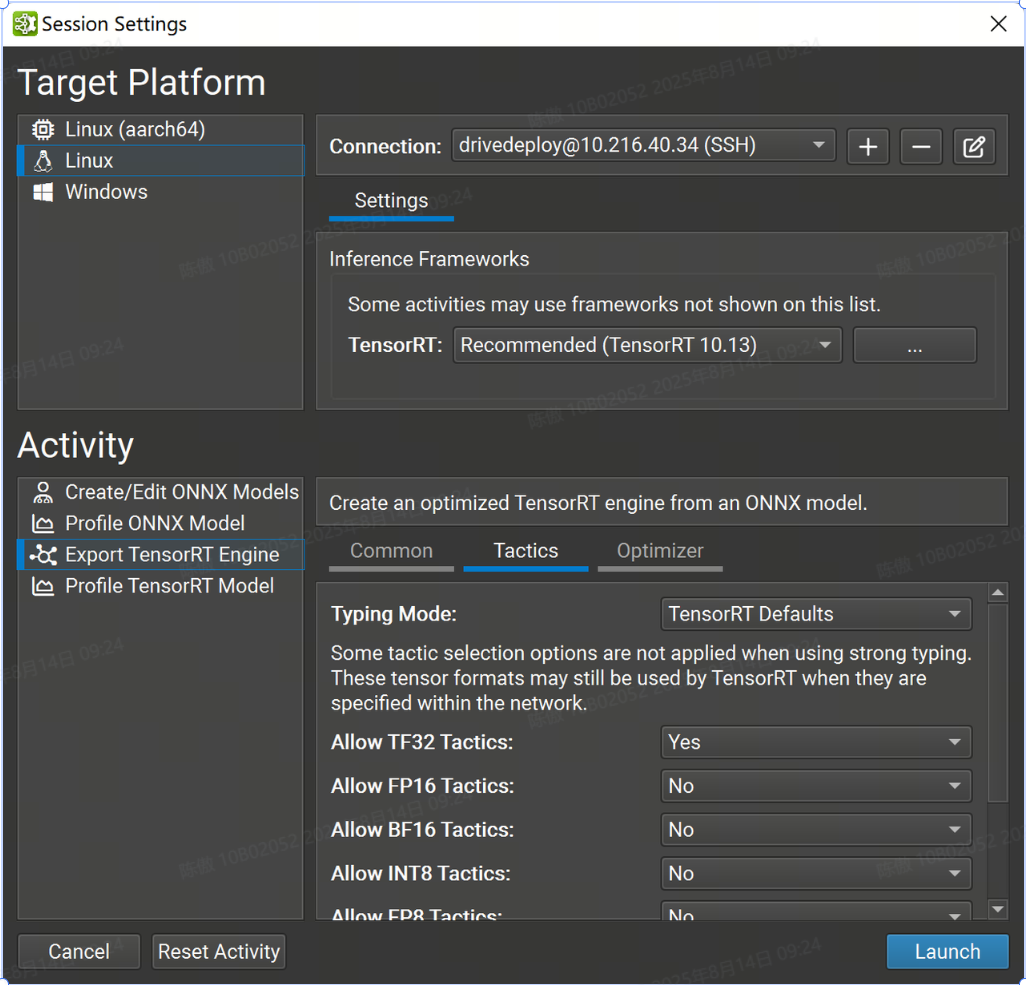
-
Typing Mode 设置控制 TensorRT 的类型系统:
-
TensorRT Defaults 指示 TensorRT 的优化器使用自动调整来确定张量类型。此选项生成最快的引擎,但当模型精度要求层以比 TensorRT 选择的更高的精度运行时,可能会导致精度损失。在此模式下,层精度约束将被忽略。
-
Strongly Typed 指示 TensorRT 的优化器使用 ONNX 运算符类型规范中的规则确定张量类型。类型不是自动调整的,可能会导致引擎比 TensorRT 选择张量类型的引擎慢,但较小的内核替代方案集可以缩短引擎构建时间。在此模式下,层精度约束和 FP16、BF16、INT8 和 FP8 策略设置将被忽略。
-
Obey Precision Constraints 使用 TensorRT 自动调整,其中尚未使用 Nsight 深度学习设计器设置层精度约束。如果特定精度约束不存在层实现,则引擎构建将失败。
-
Prefer Precision Constraints 选项类似于 Obey Precision Constraints,但如果无法观察到层精度约束或导致网络变慢,TensorRT 将发出警告消息,而不是无法构建引擎。
-
-
Allow TF32 Tactics 允许 TensorRT 的优化器选择 TensorFloat-32 精度。此格式需要 NVIDIA Ampere GPU 架构或更新版本。
-
Allow FP16 允许 TensorRT 的优化器选择 IEEE 754 半精度。
-
Allow BF16 Tactics 允许 TensorRT 的优化器选择 Bfloat16 精度。此格式需要 NVIDIA Ampere GPU 架构或更新版本。
-
Allow INT8 Tactics 允许 TensorRT 的优化器使用量化的 8 位整数精度。建议使用显式量化网络,但如果网络被隐式量化且未提供校准缓存,则 Nsight 深度学习设计器将分配占位符动态范围(类似于 )。
trtexec -
Allow FP8 Tactics 允许 TensorRT 的优化器使用量化的 8 位浮点精度。此设置与 INT8 设置互斥,通常仅对于具有插件生成的可选 FP8 张量的网络才需要。
-
Examine Weights for Sparsity 指示 TensorRT 的优化器检查权重并在权重具有合适的稀疏度时使用优化函数。
-
Allow cuDNN 和 cuBLAS Tactics 允许 TensorRT 使用 cuDNN 和 cuBLAS 库进行层实现。禁用此设置后,将仅考虑内部 TensorRT 内核。启用此设置将导致 cuDNN 下载到目标。
-
Native Instance Norm 指示 TensorRT 使用自己的实例规范化实现,而不是使用 cuDNN 的基于插件的实现。禁用此设置将导致 cuDNN 下载到目标。
优化器设置
此页面中的设置主要控制 TensorRT 界面。
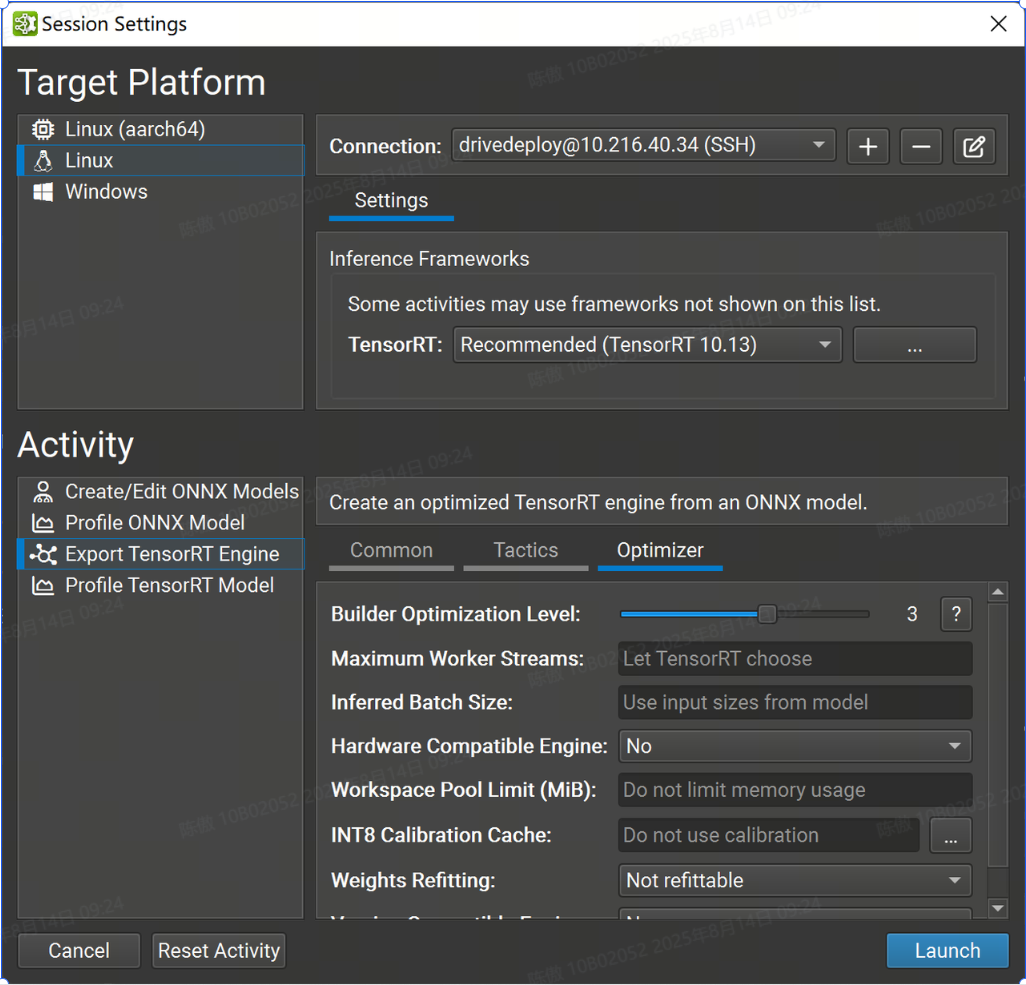
-
Builder Optimization Level 选项控制引擎构建时间和推理时间之间的权衡。更高的优化级别允许优化器花费更多时间搜索优化机会,这可能会在运行时获得更好的性能。
-
Maximum Worker Streams 控制多流推理。如果模型包含可以并行运行的运算符,TensorRT 可以在辅助流上执行它们。此设置的值定义了在构建时要提供给 TensorRT 的最大流数。如果此设置留空,TensorRT 将使用内部启发式方法来选择适当的数字。将此值设置为零以禁用流并行性。
-
Inferred Batch Size 选项允许隐式指定 TensorRT 优化配置文件
-
Hardware Compatible Engine 选项可创建一个 TensorRT 引擎,该引擎适用于所有支持 TensorRT 的具有 Ampere 架构或更高版本的独立 GPU。使用此功能可能会对性能产生影响,因为它会排除对后续 GPU 架构的优化。
-
Workspace Pool Limit (MiB) 选项控制 TensorRT 使用的工作区内存池的大小。该值应以 mibibytes 为单位指定;一个 MiB 是 2(20)字节。将此值设置得太小可能会阻止 TensorRT 找到层的有效实现。将此值留空(默认值)将消除限制并允许 TensorRT 使用 GPU 上所有可用的全局内存。
-
INT8 Calibration Cache 选项允许您为隐式量化 INT8 网络指定校准缓存文件。将此值留空(默认值)将禁用校准。校准缓存既不需要,也不用于显式量化网络或不使用 INT8 策略的网络。
-
Weights Refitting 选项控制权重是否存储在生成的 TensorRT 模型中,以及是否可以在推理时更改权重。不可调整选项是 TensorRT 的默认值。它嵌入了可能无法重新安装的重物。Refittable(包括权重)选项对应于 TensorRT 的标志;它嵌入了砝码并允许重新安装所有砝码。Refitable (Weights stripped) 选项对应于 TensorRT 的标志。此选项仅嵌入具有性能敏感优化的权重;所有其他重量都被省略并可重新调整。应用程序应在推理时将原始权重重新调整到引擎中。
kREFITkSTRIP_PLAN -
Version Compatible Engine 选项创建了一个 TensorRT 引擎,可用于对更高版本的 TensorRT 进行推理。有关详细信息,请参阅 TensorRT 文档。
分析
Nsight支持使用 TensorRT 或 ONNX Runtime 作为推理框架对网络进行分析。GPU 性能指标仅在使用 TensorRT 进行分析时可用。
要分析,请打开要分析的 ONNX 模型,然后使用 Profile Model 工具栏按钮或 Tools > Profile Model 菜单项。也可以从 Start Activity 对话框中分析 ONNX 模型,而无需事先打开它们。
当以NVIDIA L4T平台为目标时,用户(本地或远程)需要是 Debug 组的成员才能进行分析。
使用 ONNX 运行时进行分析
要使用 ONNX 运行时分析模型,请打开要分析的 ONNX 模型,然后使用 Tools > Profile Model 菜单项。ONNX 模型也可以从 Start Activity 对话框(可通过“欢迎页面访问”)进行分析,而无需事先打开它们。

Nsight Deep Learning Designer 的 ONNX Runtime 分析器基于 ONNXRuntime 测试二进制文件。ONNX 运行时分析的选项如下:
-
ONNX Model 参数是要分析的模型的本地路径。如有必要,模型文件将被复制到目标系统。
-
Iterations 控制收集数据时执行的推理迭代次数。随着采样的数据点增加,增加此值会减少计算中值推理传递时的噪声,但相应地会增加分析模型所需的时间。
-
Execution Provider 选项定义 ONNX 运行时探查器在推理期间将使用的后端。所有目标平台都支持 CPU 和 CUDA 提供程序。Windows 目标还支持 DirectML 提供程序。
-
Enable Model Optimization 选项控制探查器是否应在运行推理之前首先应用图形级转换来优化模型。如果启用,探查器将应用最高级别的优化,如 ONNX 运行时中的图形优化中所述。
-
Generate Random Input(s) Data 控制分析器是否应为模型的输入生成随机数据,而无需在模型中嵌入数据或从外部文件引用数据。自由尺寸被视为 1。如果关闭,则必须提供输入数据文件夹。
-
Input Data Folder 选项控制探查器应在何处查找模型输入的数据。生成随机输入(Generate Random Input(s)必须关闭数据才能定义数据文件夹。它应该指向一个目录,其中包含一个文件,每个模型输入都有一个 ONNX TensorProto。Protobuf 文件需要命名为其相应模型的输入,例如:。如有必要,输入数据将被复制到目标系统。
input_0.pb -
Output Profile 参数是要保存探查器报告的本地目标。如有必要,将从目标系统复制它。该活动根据 ONNX 模型文件名建议此参数的默认名称。
使用 TensorRT 进行分析
要使用 TensorRT 分析模型,请打开要分析的 ONNX 模型,然后使用工具>分析模型菜单项。ONNX 模型也可以从“开始活动”对话框(可通过“欢迎页面访问”)进行分析,而无需事先打开它们。
使用动态输入大小分析 ONNX 模型需要 TensorRT 优化配置文件。分析器在生成随机输入数据时使用输入最佳大小。
选择版本
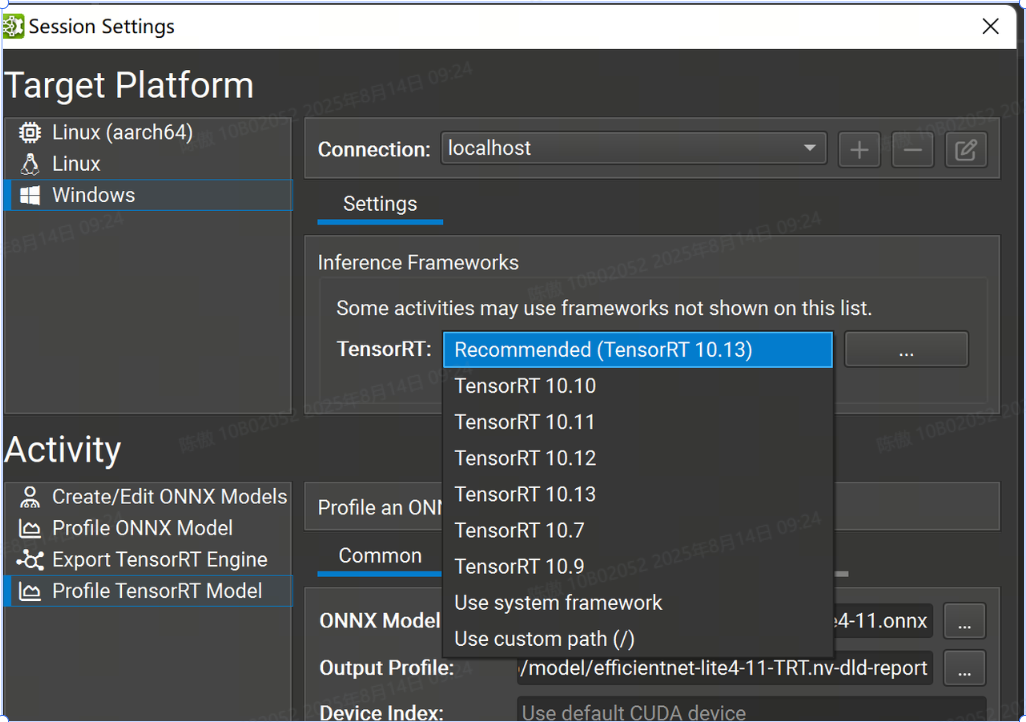
Nsight 支持多个次要版本的 TensorRT 10 进行分析。选择要使用的 TensorRT 版本。有选定的 TensorRT 版本可供自动下载和部署(以及推荐版本)。您也可以选择在目标系统上使用系统安装的 TensorRT,或指定自定义路径。如果您指定自定义路径,则它必须是从目标计算机上的部署目录到 TensorRT 共享库位置的相对路径。
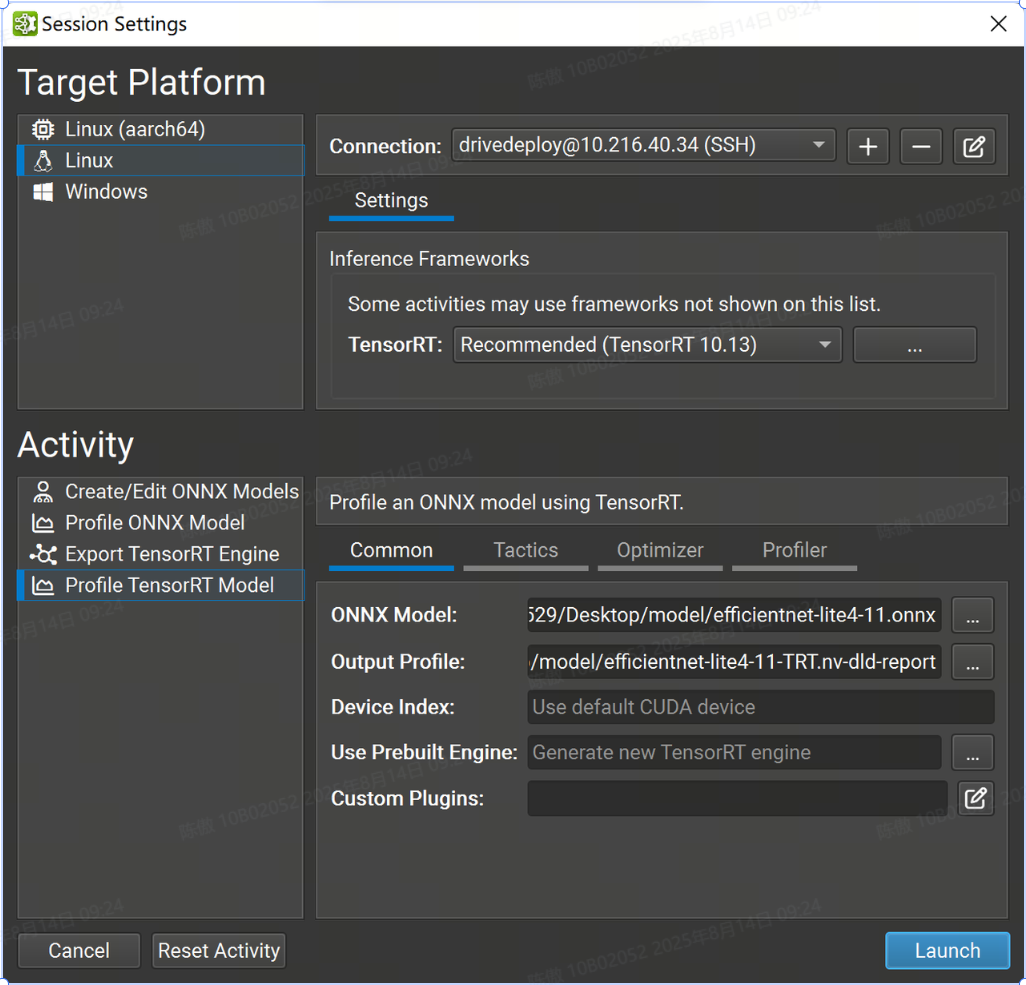
常用设置
-
ONNX Model 参数是要分析的模型的本地路径。如有必要,它将被复制到目标系统。
-
Output Profile 参数是要保存探查器报告的本地目标。如有必要,将从目标系统复制它。该活动根据 ONNX 模型文件名建议此参数的默认名称。
-
Device Index 控制在多 GPU 系统上使用的 CUDA 设备。设备 0 表示默认的 CUDA 设备,设备按调用中的顺序排列。如果此设置留空,则 Nsight 深度学习设计器将使用第一个 CUDA 设备.
-
Use Prebuilt Engine 选项允许您从 导出 TensorRT 引擎 活动或其他工作流(例如而不是构建新引擎)分析预先存在的 TensorRT 引擎。引擎文件必须是从正在分析的 ONNX 模型构建的,必须具有分析详细性,并且如果可能,将在推理之前自动重新拟合。在分析预构建引擎时,将忽略“战术”和“优化器”页面中的设置。该引擎被视为可信的,任何嵌入式主机代码(如 TensorRT 版本兼容性或插件嵌入选项)都将根据需要反序列化和执行。
-
Custom Plugins 参数允许在引擎构建期间将路径传递到可选的自定义TensorRT插件以加载。提供的路径必须相对于所选目标系统。插件必须与 TensorRT 10.10 兼容.
分析器设置
此页面中的设置控制 Nsight 分析器的行为,而不是 TensorRT。
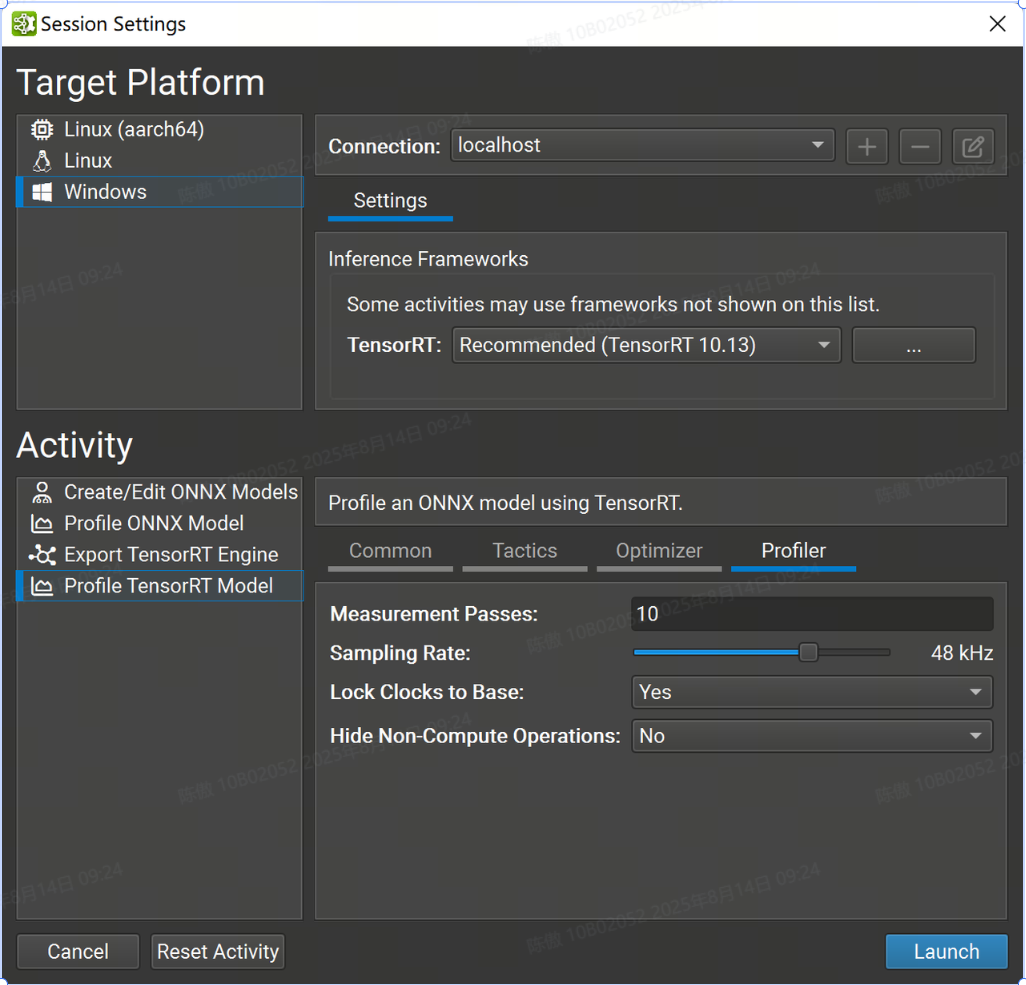
-
Measurement Passes 选项控制收集数据时执行的推理迭代次数。随着采样的数据点增加,增加此值会减少计算中值推理传递时的噪声,但相应地会增加分析模型所需的时间。
-
Sampling Rate 选项控制 GPU 性能计数器收集的频率。增加此值会为分析报告收集更多数据,但可能会溢出大型模型上的收集缓冲区。
-
Lock Clocks to Base 选项控制是否将 GPU 时钟锁定到其基本值,从而在分析期间禁用时钟提升。锁定时钟提高了测量一致性,但代价是推理性能下降。
-
Hide Non-Compute Operations 控制是否在测量循环和生成的分析器报告中包括性能分析器开销,例如主机/设备内存副本。
在对模型设计进行增量更改时,应将时钟锁定为基本值。各个层时序值将反映 GPU 的一致性能状态,并在模型的各个版本之间进行有意义的比较。在实际配置中测量端到端性能时,应解锁时钟,隐藏非计算操作,并将 Measurement Passes 值设置为较大的数字(通常 200 个就足够了)。增加通过计数可确保 GPU 保持活动状态足够长的时间以达到其最大时钟速率。从分析作中省略非计算作会进一步使 GPU 饱和,因为 SM作不会与内存副本交错。
从命令行进行分析
Nsight 包括一个轻量级命令行 TensorRT 分析器,适用于非交互式用例。从 Nsight 设计器 GUI 进行交互式分析后,可以将其复制到远程目标的部署目录。ndld-prof
可以使用该选项查看分析器接受的命令行参数的完整详细信息。使用命令行分析器时,支持“Profile TensorRT Model”活动界面中的所有选项。--help
使用命令行探查器时,无需保存完整的分析报告。探查器将在 stdout 上显示性能会审信息。
分析报告
Nsight 使用通用报告格式来存储来自 ONNX Runtime 和 TensorRT 的分析数据。可以使用 “file">“ open file”命令重新打开现有分析报告。分析 TensorRT 模型 和分析 ONNX 模型 活动将在分析运行成功后自动打开新的分析器报告。
分析报告描述了所选推理框架执行的 ONNX 模型的执行,该框架通常指网络的运行时优化版本。ONNX 模型中的节点组可以融合到单个优化层中,而其他节点可能会在优化过程中完全删除。
分析报告有四个主要部分, 包括 ONNX Runtime 和 TensorRT 分析器之间的任何差异。
)







)





--PromptPilot (助手)答问之1)
 using `TU/lmr/m/n‘ instead)
ZLG CAN卡驱动封装应用)
 算法超参数 多项式时间 朴素贝叶斯分类算法)

