6.1 数据介绍
直接打开集算器运行 createEventsAndUsers.splx 文件,就可以得到如下两张表(也可以根据代码中的注释,修改起止日期以及每天的数据量):
电商数据表 events.csv
| 字段名 | 含义 |
|---|---|
| eventID | 事件编号, 从 1 开始流水号 |
| userID | 用户编号 |
| eTime | 事件的发生时间 |
| eType | 事件类型,取值 login,viewProduct,placeOrder,completePayment |
数据同时按 eTime 和 eventID 分别有序,因为数据是按发生时间追加的,所以始终按 eTime 有序,又 eventID 是流水号,所以也是天然有序
用户表 user.csv
| 字段名 | 含义 |
|---|---|
| userID | 用户编号,从 1 开始流水号 |
| userName | 用户姓名 |
| city | 所在城市 |
表间关系:
6.2 选出 24 年国庆假期发生的所有记录
由于事件表很大,全内存无法放下,所以采用游标的方式,SPL 提供了文件游标,可以对着游标进行过滤、分组、汇总等各种运算。
| A | |
|---|---|
| 1 | =file(“events.csv”).iselect@tc(date("2024-10-01"):datetime("2024-10-07 23:59:59"),eTime ; userID,eTime,eType) |
A1 由于事件表按时间有序,所以采用 iselect 函数,直接对着数据文件按时间过滤,这样可以采用二分法,提高读数的效率,不满足过滤条件的数据直接跳过不读了。
分号前面的参数date("2024-10-01"):datetime("2024-10-07 23:59:59"),eTime表示选出 eTime 的值位于区间date("2024-10-01"):datetime("2024-10-07 23:59:59")之间的数据,两端均是闭区间。
分号后面的参数userID,eTime,eType表示选出字段,不需要用到的字段不选出,可以节约内存。iselect 函数返回结果是游标,可以直接进行下一步的运算,如果需要输出数据,可以 fetch 操作。
A1 的运行结果:

从上图可以看出,A1 返回的结果是个游标。
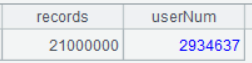
6.3 统计 24 年国庆假期发生的记录数、用户数
| A | |
|---|---|
| 1 | =file(“events.csv”).iselect@tc(date(“2024-10-01”):datetime(“2024-10-07 23:59:59”),eTime ; userID,eTime,eType) |
| 2 | =A1.groups(; count(1):records,icount(userID):userNum) |
A2 分组汇总,groups 函数可以直接对着游标操作,返回统计结果。特别注意:分号前面不写分组表达式,表示全集汇总。
A2 的运行结果如下:
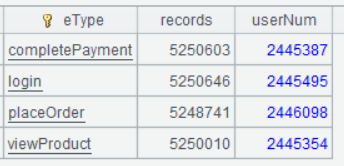
6.4 按事件类型分组统计 24 年国庆假期的发生次数和用户数
| A | |
|---|---|
| 1 | =file(“events.csv”).iselect@tc(date(“2024-10-01”):datetime(“2024-10-07 23:59:59”),eTime;userID,eTime,eType) |
| 2 | =A1.groups(eType;count(1):records,icount(userID):userNum) |
A2 的运行结果如下:
6.5 统计 24 年国庆假期每天的总用户数、下单用户数、付款用户数
| A | |
|---|---|
| 1 | =file(“events.csv”).iselect@tc(date(“2024-10-01”):datetime(“2024-10-07 23:59:59”),eTime;userID,eTime,eType) |
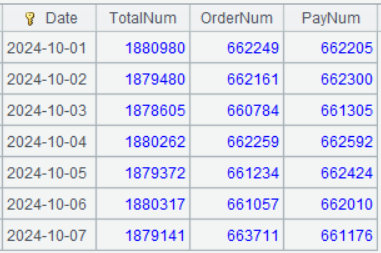
| 2 | =A1.group(date(eTime):Date; ~.icount(userID):TotalNum, ~.select(eType==“placeOrder”).icount(userID):OrderNum, ~.select(eType==“completePayment”).icount(userID):PayNum) |
| 3 | =A2.fetch() |
A2 对着游标 A1 进行分组,group 函数表示分组过程中保留分组的组集;~.icount(userID) 表达式中的 ~ 表示当前的组集,整个表达式意思是对着当前组集统计 userID 的去重个数;~.select(eType==“placeOrder”).icount(userID) 表示对着当前组集先过滤出 eType 为 placeOrder 的记录,再对其统计 userID 的去重个数。
cs.group 函数的返回结果依旧是游标,A2 的运行结果如下:

A3 从游标 A2 中读出结果数据。
A3 的运行结果如下:
6.6 按天统计 24 年国庆假期北京地区的下单用户数
| A | |
|---|---|
| 1 | =file(“events.csv”).iselect@tc(date(“2024-10-01”):datetime(“2024-10-07 23:59:59”),eTime;userID,eTime,eType) |
| 2 | =file(“user.csv”).cursor@tc(userID,city).select(city==“Beijing”).fetch() |
| 3 | =A1.select(eType==“placeOrder”).join@i(userID,A2:userID) |
| 4 | =A3.groups(date(eTime):Date;icount(userID):userNum) |
A2 用户表数据量也非常大,本例只需要读取北京地区的用户,因此可以用游标的方式过滤后再 fetch(),这样非北京地区的用户数据就不会占用内存了。
A3 将 A1 先过滤出下单的数据,然后和 A2 关联,@i选项表示只保留关联上的记录,关联不上的记录直接删除(如果希望只保留关联不上的记录,删除关联上的记录,比如统计非北京地区的用户,那么可以把@i选项换成@d选项,其余不变即可)。因为 A1 是游标,所以 A3 的返回结果依旧是游标。
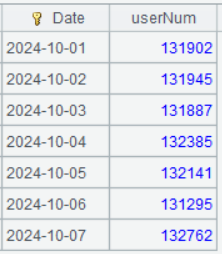
A4 将 A3 进行分组汇总。
A4 的运行结果:
知识点:先过滤后关联
上例的 A3 中关联的两个对象都是先分别进行了过滤,然后才进行关联,这样可以减少关联的次数,提升关联效率。
6.7 将事件表拆成一个月一张表,表内按 userID 排序
由于事件表数据量大,无法全内存放下,因此需要用游标排序:
| A | |
|---|---|
| 1 | =file(“events.csv”).iselect@tc(date(“2024-10-01”):datetime(“2024-10-31 23:59:59”),eTime).sortx(userID) |
| 2 | =file(“events202410.csv”).export@tc(A1) |
| 3 | =file(“events.csv”).iselect@tc(date(“2024-11-01”):datetime(“2024-11-30 23:59:59”),eTime).sortx(userID) |
| 4 | =file(“events202411.csv”).export@tc(A3) |
| 5 | =file(“events.csv”).iselect@tc(date(“2024-12-01”):datetime(“2024-12-31 23:59:59”),eTime).sortx(userID) |
| 6 | =file(“events202412.csv”).export@tc(A5) |
A1 sortx 函数专门用于游标排序,参数 userID 是排序字段。sortx 返回值依旧是游标。
A2 将游标 A1 中的数据读出直接写入文件 events202410.csv。export 和 import 的选项规则一致,是 import 函数的逆操作。
知识点:sort 函数和 sortx 函数的区别
1.sort 函数
特点:
- 立即执行:调用sort时会直接对当前序表(或排列)进行排序,生成一个新的有序结果。
- 内存排序:数据在内存中完成排序,适合处理中小规模数据。
- 返回新序列:原序列不变,返回排序后的新序列。
适用场景:
数据量较小(可完全装入内存),且需要直接获取排序结果的场景。
2.sortx 函数
特点:
- 立即执行:排序结果存入一个或多个临时文件,返回这些文件的归并游标。
- 外存排序:支持大数据量的排序,通过临时外存文件处理超出内存的数据。
- 返回游标:返回排序结果的游标,适合下一步的输出或运算。
适用场景:
数据量较大(无法完全装入内存),或需要与其他延迟计算操作(如流式处理)结合时。
6.8 按用户统计每月的下单个数
需完成如下统计:
10 月下单的用户,10 月、11 月下单的个数
10 月 11 月均下单的用户,10 月、11 月下单的个数
按用户统计 10 月 11 月下单个数
第一步:产生游标
| A | |
|---|---|
| 1 | =file(“events202410.csv”).cursor@tc() |
| 2 | =file(“events202411.csv”).cursor@tc() |
第二步:分别汇总统计订单数
| A | |
|---|---|
| 3 | =A1.select(eType==“placeOrder”).group(userID;~.count(1):10Num) |
| 4 | =A2.select(eType==“placeOrder”).group(userID;~.count(1):11Num) |
A3 由于 A1 是游标,因此,select 函数返回的是游标,group 函数返回的依旧是游标。
第三步:关联
1. 10 月下单的用户,10 月、11 月下单的个数
| A | |
|---|---|
| 5 | =joinx@1(A3:oct,userID;A4:nov,userID) |
| 6 | =A5.new(oct.userID,oct.10Num,nov.11Num) |
| 7 | =file(“result.csv”).export@tc(A6) |
A5 joinx@1 为左连接,joinx 函数专门用于两个或多个游标之间的关联,要求参与关联的游标数据均按关联字段有序。参数规则和 join() 一致。
A6 因为 joinx 和 join 一样,关联的结果是指引字段,所以需要再次 new,产生结果序表,此时 A6 依旧是游标
A7 将结果输出到文件,由于结果集太大内存依旧放不下,因此可以直接将游标中的数据输出到文件。
2. 10 月 11 月均下单的用户,10 月、11 月下单的个数
| A | |
|---|---|
| 5 | =joinx(A3:oct,userID;A4:nov,userID) |
| 6 | =A5.new(oct.userID,oct.10Num,nov.11Num) |
| 7 | =file(“result.csv”).export@tc(A6) |
A5 joinx 为内连接。
3. 按用户统计 10 月 11 月下单个数
| A | |
|---|---|
| 5 | =joinx@f(A3:oct,userID;A4:nov,userID) |
| 6 | =A5.new(oct.userID,oct.10Num,nov.11Num) |
| 7 | =file(“result.csv”).export@tc(A6) |
A5 joinx@f 为全连接。
知识点: join()函数和 joinx() 函数的区别
1.join() 函数
特点
- 立即执行: 调用 join() 时会直接执行连接操作,生成一个新的结果序表。
- 内存连接: 数据在内存中完成连接,适合中小规模数据。
- 返回完整结果: 连接后的数据会完全加载到内存中。
- 语法灵活: 支持多种连接类型(如内连接、左连接、全连接等)。
- 数据可以无序: 不要求数据按关联字段有序。
适用场景
- 数据量较小(可完全装入内存)。
- 需要立即获取连接结果的场景。
2.joinx() 函数
特点
- 延迟执行: joinx() 仅生成一个连接游标,不会立即计算,实际连接操作会延迟到后续遍历或聚合时触发。
- 外存连接: 支持大数据量的连接,可处理超出内存的数据。
- 惰性求值: 适合流式处理,可与其他函数(如 groups、select)结合使用。
- 返回游标: 不直接返回完整数据,而是返回一个可迭代的游标对象。
- 数据有序: 要求数据按关联字段有序。
适用场景
- 数据量较大(无法完全装入内存)。
- 需要与其他延迟计算操作(如流式处理)结合时。






)
)




】)
)


)


