目录
一、前言
二、Docker 搭建kafka介绍
2.1 Docker 命令部署
2.2 使用Docker Compose 部署
2.3 使用 Docker Swarm
2.4 使用 Kubernetes
2.5 部署建议
三、Docker 搭建kafka操作方式一
3.1 前置准备
3.2 完整操作过程
3.2.1 创建docker网络
3.2.2 启动zookeeper容器
3.3 启动kafka容器
3.4 效果测试与验证
四、Docker 搭建kafka操作方式二
4.1 前置说明
4.2 KRaft 模式部署kafka操作过程
4.2.1 前置准备
4.2.2 获取镜像
4.2.3 创建数据目录
4.2.4 启动 Kafka Broker
4.2.5 验证生产消费是否可用
五、写在文末
一、前言
kafka作为一款性能强劲且经过各类大型项目考验过的消息中间件,在全世界的知名度和认可度非常高,也是很多处理高并发、大数据量场景下的首选。随着Docker容器化的发展越加成熟,基于Docker部署各类中间件时间成本越越来越低,本文介绍下基于Docker部署kafka的两种操作方式。
二、Docker 搭建kafka介绍
Docker 是一个开源的应用容器引擎,让开发者可以打包、分发和运行应用程序在任何环境上。使用 Docker 部署 Kafka 可以简化配置和管理,特别是在需要快速搭建开发和测试环境时非常有用。下面介绍几种 Docker 搭建 Kafka 的一些常用方案及其与传统部署方式的对比。
2.1 Docker 命令部署
使用纯粹的 Docker 命令(docker run)来部署 Kafka。这种方式更直接,便于理解容器运行的细节,也非常适合快速启动单个容器进行测试。这种方式通常需要搭配zookeeper一起部署使用。
2.2 使用Docker Compose 部署
这是最简单、最快速的启动方式,通过一个 YAML 文件定义和运行多个容器(ZooKeeper 和 Kafka)。参考下面的示例。
优点:一键部署、配置即代码、易于版本控制和分享。
缺点:单机部署,无法充分利用 Docker Swarm 或 Kubernetes 的集群能力。
version: '3.8'
services:zookeeper:image: confluentinc/cp-zookeeper:7.4.0hostname: zookeepercontainer_name: zookeeperports:- "2181:2181"environment:ZOOKEEPER_CLIENT_PORT: 2181ZOOKEEPER_TICK_TIME: 2000volumes:- ./zk-data:/var/lib/zookeeper/data- ./zk-logs:/var/lib/zookeeper/logkafka:image: confluentinc/cp-kafka:7.4.0hostname: kafkacontainer_name: kafkadepends_on:- zookeeperports:- "9092:9092"- "29092:29092" # 用于容器内网络访问的监听器environment:KAFKA_BROKER_ID: 1KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT# 外部客户端(宿主机或其他机器)通过这个地址连接KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1KAFKA_AUTO_CREATE_TOPICS_ENABLE: "true"KAFKA_PROCESS_ROLES: "broker"KAFKA_CONTROLLER_LISTENER_NAMES: "CONTROLLER"volumes:- ./kafka-data:/var/lib/kafka/data2.3 使用 Docker Swarm
这种方式适用于简单的集群部署,Docker Compose 的集群模式版本。它可以在一组主机上部署服务,并提供简单的服务发现和负载均衡。特点:
-
使用
docker stack deploy -c docker-compose.yml kafka_stack命令部署。 -
需要配置共享存储(如 NFS、Ceph)以便所有 Swarm 节点都能访问 Kafka 和 ZooKeeper 的数据卷,复杂度较高。
-
对于有状态且需要稳定网络标识的服务 like Kafka,Swarm 的管理不如 Kubernetes 成熟。
2.4 使用 Kubernetes
这是部署生产级、高可用 Kafka 集群最强大和最推荐的方式。
-
Operator 模式:这是最主流的方式。Operator 是一种自定义 Kubernetes 控制器,它封装了管理 Kafka 集群的专业知识(如部署、配置、扩缩容、升级、故障转移)。
-
Strimzi Operator:目前最流行、功能最全面的 Kafka Kubernetes Operator。它提供了极其丰富的 CRD(自定义资源)来定义 Kafka 集群、Topic、用户等。
-
Confluent Operator:Confluent 公司官方提供的 Operator,与 Confluent 平台的其他组件(如 Connect、Schema Registry)集成更好,但部分高级功能需要商业许可。
-
2.5 部署建议
-
开发与测试环境:强烈推荐使用 Docker Compose。它是搭建本地和测试环境的事实标准,能极大提升效率。
-
生产环境:
-
如果追求敏捷、弹性、云原生,并且技术团队具备相应能力,使用 Kubernetes + Strimzi Operator 是最佳选择。
-
如果对性能有极致要求,或者运维体系基于传统物理机/虚拟机且非常稳定,传统部署方式仍然是可靠的选择。许多大规模互联网公司依然采用物理机部署核心消息队列集群。
-
最终,选择哪种方式取决于你的团队技术栈、业务需求和对运维模式的规划。
三、Docker 搭建kafka操作方式一
3.1 前置准备
-
服务器环境:Linux操作系统
-
服务器配置:2核4G
-
Docker环境,提前安装好Docker环境;
3.2 完整操作过程
搭配zookeeper进行使用,这个是部署kafka比较经典的方式,参考下面的完整操作过程。
3.2.1 创建docker网络
为了更好的让kafka与zookeeper交互,提前创建一个docker网络
docker network create kafka-net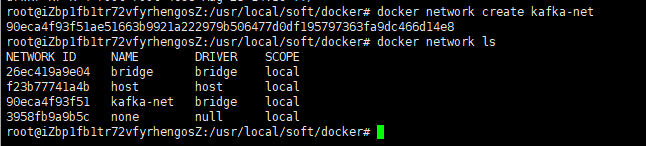
3.2.2 启动zookeeper容器
使用下面的命令启动zk容器
docker run -d \--name zookeeper_01 \--network kafka-net \-p 12179:2181 \-e ZOO_TICK_TIME=2000 \zookeeper:latest
参数解释:
-
-d: 后台运行容器。 -
--name: 为容器指定一个名称。 -
--network: 加入创建的kafka-net网络。 -
-p 12179:2181: 将容器的12179端口映射到宿主机的 2181 端口。 -
-e ZOO_TICK_TIME=2000: 设置 ZooKeeper 的基本时间单位(毫秒)。
3.3 启动kafka容器
使用下面的命令启动kafka容器
docker run -d \
--name kafka_01 \
-p 19091:9092 \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ZOOKEEPER_CONNECT=服务器公网IP:12179 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://服务器公网IP:19091 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
wurstmeister/kafka:latest
docker 参数说明:
-
KAFKA_ADVERTISED_LISTENERS: 非常重要。Broker 发布给客户端(生产者、消费者)的连接地址。如果客户端在宿主机外,需替换localhost为宿主机 IP。 -
KAFKA_LISTENERS: Broker 实际监听的地址和协议,0.0.0.0表示监听所有网络接口。 -
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 设置内部偏移量主题的副本因子,单机设为 1 即可。
3.4 效果测试与验证
kafka的服务搭建完成之后,接下来验证下是否可以先通过客户端操作命令正常使用topic进行收发消息。
1)进入 Kafka 容器:
docker exec -it kafka_01 /bin/bash2)创建一个topic
# 传统模式
kafka-topics.sh --create --zookeeper 公网IP:12179 --replication-factor 1 --partitions 1 --topic test-topic
3)启动生产者窗口
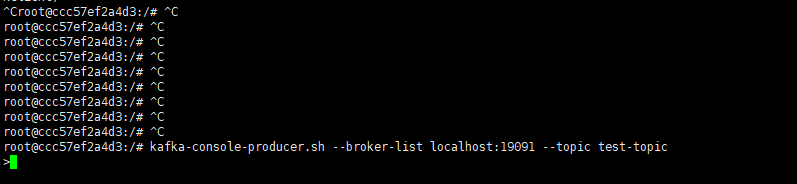
开启一个生产者窗口,尝试往上面的topic中发送消息
kafka-console-producer.sh --broker-list 公网IP:19091 --topic test-topic看到下面的效果说明生产端连接上了
4)启动消费者窗口
开启一个新的消费者窗口,尝试从上面的topic中接收消息
kafka-console-consumer.sh --bootstrap-server 公网IP:19091 --topic test-topic --from-beginning看到下面的效果说明消费端接收消息就绪了

5)发送消息
接下来从生产者窗口发送一条消息,可以看到消息能够正常的发送出去,同时消费端也能接收到消息

四、Docker 搭建kafka操作方式二
4.1 前置说明
基于Docker部署kafka目前有两种主流的方式,一是使用ZooKeeper 的模式,另一种则是无需zk的KRaft 模式,两种模式的区别如下:
| 特性 | 传统 ZooKeeper 模式 | KRaft 模式 (无需 ZooKeeper) |
| 架构 | Kafka Broker 依赖外部的 ZooKeeper 集群进行元数据管理 | Kafka 使用内置的 Raft 协议进行元数据管理,无需额外组件 |
| 资源占用 | 较高(需运行 ZooKeeper 容器) | 较低(只需运行 Kafka 容器) |
| 复杂度 | 相对较高(需管理两个容器及它们之间的配置) | 相对较低(配置集中于单个容器) |
| 推荐场景 | 学习、测试兼容旧版本 | 希望部署更简单、资源占用更少的新版本环境 |
4.2 KRaft 模式部署kafka操作过程
接下来演示基于KRaft 模式部署kafka完整过程。
4.2.1 前置准备
确保你的系统已安装 Docker。可以通过以下命令检查:
docker --version
4.2.2 获取镜像
我们将使用广泛认可的 wurstmeister/kafka 和 zookeeper 镜像(用于传统模式)或 apache/kafka 镜像(用于 KRaft 模式)。这里使用KRaft 的方式获取安装的镜像(无需zookeeper)。
docker pull apache/kafka:3.9.0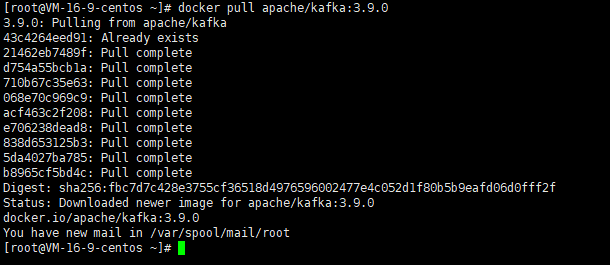
4.2.3 创建数据目录
可选,用于数据持久化
mkdir -p /data/kafka/data
mkdir -p /data/kafka/config
mkdir -p /data/kafka/secrets4.2.4 启动 Kafka Broker
使用下面的命令启动kafka容器
# 运行容器
sudo docker run --privileged=true \
--net=bridge \
-d --name=kafka-kraft \
-v /data/kafka/data:/var/lib/kafka/data \
-v /data/kafka/config:/mnt/shared/config \
-v /data/kafka/secrets:/etc/kafka/secrets \
-p 9092:9092 -p 9093:9093 \
-e TZ=Asia/Shanghai \
-e LANG=C.UTF-8 \
-e KAFKA_NODE_ID=1 \
-e CLUSTER_ID=kafka-cluster \
-e KAFKA_PROCESS_ROLES=broker,controller \
-e KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT \
-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-e KAFKA_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://公网IP:9092 \
-e KAFKA_CONTROLLER_QUORUM_VOTERS=1@localhost:9093 \
apache/kafka:3.9.0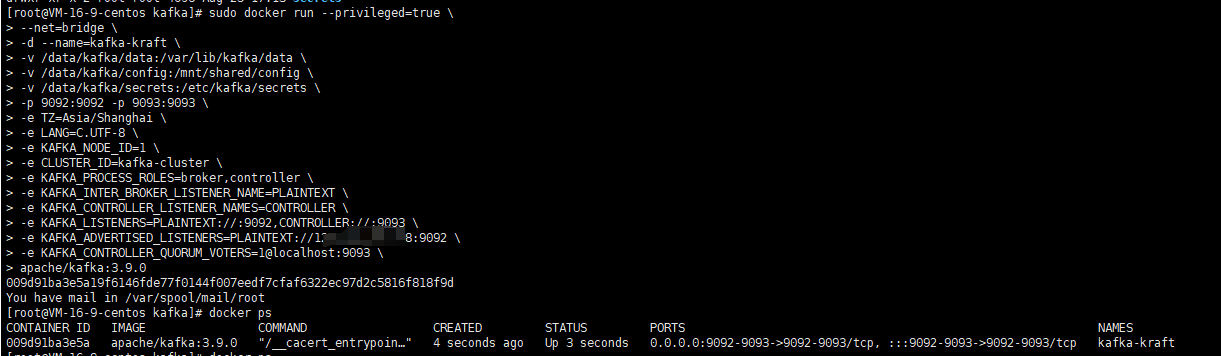
| 参数 | 参数说明 |
| docker run | 运行 Docker 容器 |
| -d | 容器将在后台运行,而不是占用当前的终端会话 |
| --privileged=true | Docker会赋予容器几乎与宿主机相同的权限 |
| --net=bridge | 网络模式配置,默认是bridge,bridge表示使用容器内部配置网络 |
| --name kafka-kraft | 给容器命名为 kafka-kraft,以便于管理和引用该容器 |
| -p 9092:9092 -p 9093:9093 | 映射 kafka 的客户端通信端口和控制器端口 |
| -e KAFKA_NODE_ID=1 | 节点ID,用于标识每个集群中的节点,需要是不小于1的整数,同一个集群中的节点ID不可重复 |
| -e CLUSTER_ID=kafka-cluster | 集群ID,可以自定义任何字符串作为集群ID,同一个集群中所有节点的集群ID必须配置为一样 |
| -e KAFKA_PROCESS_ROLES=broker,controller | 节点类型,broker,controller表示该节点是混合节点,通常单机部署时需要配置为混合节点 |
| -e KAFKA_INTER_BROKER_LISTENER_NAME= PLAINTEXT | Kafka的Broker地址前缀名称,固定为PLAINTEXT即可 |
| -e KAFKA_CONTROLLER_LISTENER_NAMES= CONTROLLER | Kafka的Controller地址前缀名称,固定为CONTROLLER即可 |
| -e KAFKA_LISTENERS= PLAINTEXT://:9092,CONTROLLER://:9093 | 表示Kafka要监听哪些端口,PLAINTEXT://:9092,CONTROLLER://:9093表示本节点作为混合节点,监听本机所有可用网卡的9092和9093端口,其中9092作为客户端通信端口,9093作为控制器端口 |
| -e KAFKA_ADVERTISED_LISTENERS= PLAINTEXT://192.168.3.9:9092 | 配置Kafka的外网地址,需要是PLAINTEXT://外网地址:端口的形式,当客户端连接Kafka服务端时,Kafka会将这个外网地址广播给客户端,然后客户端再通过这个外网地址连接,除此之外集群之间交换数据时也是通过这个配置项得到集群中每个节点的地址的,这样集群中节点才能进行交互。需要修改为对应的Kafka的外网地址。 |
| -e KAFKA_CONTROLLER_QUORUM_VOTERS= 1@localhost:9093 | 投票节点列表,通常配置为集群中所有的Controller节点,格式为节点id@节点外网地址:节点Controller端口,多个节点使用逗号,隔开,由于是混合节点,因此配置自己就行了 |
| -v /data/docker/kafka-kraft/data: /var/lib/kafka/data | 持久化数据文件夹,如果运行出现问题可以清空该数据卷文件重启再试 |
| -v /data/docker/kafka-kraft/config: /mnt/shared/config | 持久化配置文件目录 |
| -v /data/docker/kafka-kraft/secrets: /etc/kafka/secrets | 持久化秘钥相关文件夹 |
4.2.5 验证生产消费是否可用
参考上面的方式,分别创建一个生产者和一个消费者,查看消费者是否能够收到生产者生产的消息
# 1.进入kafka容器内
sudo docker exec -it kafka-kraft /bin/bash# 2.进入kafka安装目录
cd /opt/kafka/bin# 3、创建一个测试的topic
./kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test01 # 4、查询主题列表
./kafka-topics.sh --bootstrap-server localhost:9092 --list# 5.生产消息
./kafka-console-producer.sh --topic test01 --bootstrap-server localhost:9092# 6.消费消息
./kafka-console-consumer.sh --topic test01 --from-beginning --bootstrap-server localhost:9092 --partition 0# 查询消费组列表
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list1)创建一个topic

2)查看topic 列表

3)开启一个生产者窗口

发送2条消息

4)开启一个消费者窗口

五、写在文末
本文通过案例操作演示了基于Docker环境部署单节点kafka服务的完整操作过程,更多深入的点有兴趣的同学可以基于研究,本篇到此介绍,感谢观看。



![for in+逻辑表达式 生成迭代对象,最后转化为列表 ——注意list是生成器转化为列表,但[生成器]得到的就是一个列表,其中包含一个生成器元素](http://pic.xiahunao.cn/for in+逻辑表达式 生成迭代对象,最后转化为列表 ——注意list是生成器转化为列表,但[生成器]得到的就是一个列表,其中包含一个生成器元素)


:融合FSATFusion的医学图像分割)







)

TCP并发服务器构建)


