数据集包含2149名患者的广泛健康信息,每名缓则的ID范围从4751到6900不等,该数据集包含人口统计详细信息,生活方式因素、病史、临床测量、认知和功能评估、症状以及阿尔兹海默症的诊断。
一、准备工作
1、硬件准备
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import torch
import torch.nn as nn
import torch.nn.functional as F# 设置GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
2、导入数据
df = pd.read_csv('./alzheimers_disease_data.csv')
# 删除最后一列和第一列
df = df.iloc[:, 1:-1]
df.head()

二、构建数据集
1、标准化
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScalerX = df.iloc[:, :-1]
y = df.iloc[:, -1]# 将每一列特征标准化为标准正态分布,注意,标准化是针对每一列而言的
scaler = StandardScaler()
X = scaler.fit_transform(X)
2、划分数据集
X = torch.tensor(np.array(X), dtype=torch.float32)
y = torch.tensor(np.array(y), dtype=torch.int64)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=1)X_train.shape, y_train.shape
3、构建数据加载器
from torch.utils.data import TensorDataset, DataLoadertrain_dl = DataLoader(TensorDataset(X_train, y_train), batch_size=32, shuffle=False)
test_dl = DataLoader(TensorDataset(X_test, y_test), batch_size=32, shuffle=False)
三、模型训练
1、构建模型
class model_rnn(nn.Module):def __init__(self):super(model_rnn, self).__init__()self.rnn0 = nn.RNN(input_size=32, hidden_size=200, num_layers=1, batch_first=True)self.fc0 = nn.Linear(200, 50)self.fc1 = nn.Linear(50, 2)def forward(self, x):out, hidden1 = self.rnn0(x)out = self.fc0(out)out = self.fc1(out)return outmodel = model_rnn().to(device)
model

2、定义训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
3、测试函数
def test (dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss
4、正式训练
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 5e-5
opt = torch.optim.Adam(model.parameters(), lr= learn_rate)epochs = 50train_loss = []
train_acc = []
test_loss = []
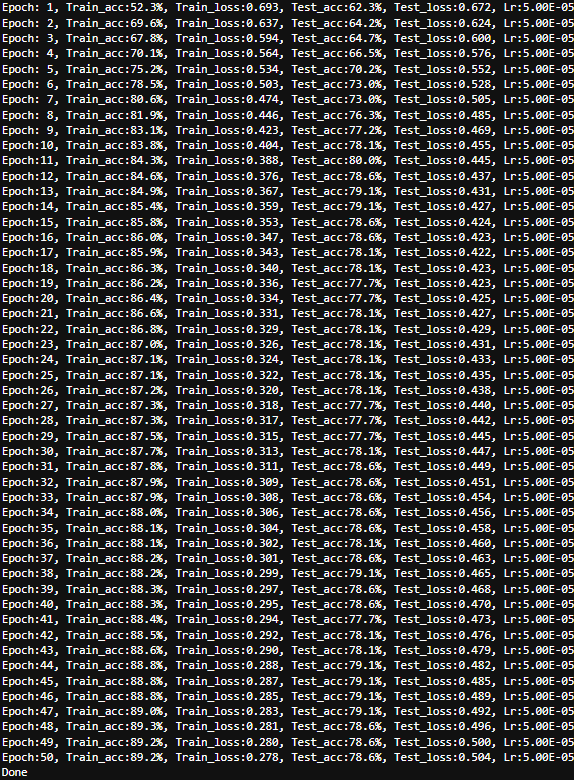
test_acc = []for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率lr = opt.state_dict()['param_groups'][0]['lr']template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss,epoch_test_acc*100, epoch_test_loss, lr))print('Done')
四、模型评估
1.Loss与Accuracy图
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率from datetime import datetime
current_time = datetime.now()epochs_range = range(epochs)plt.figure(figsize=(12, 3))
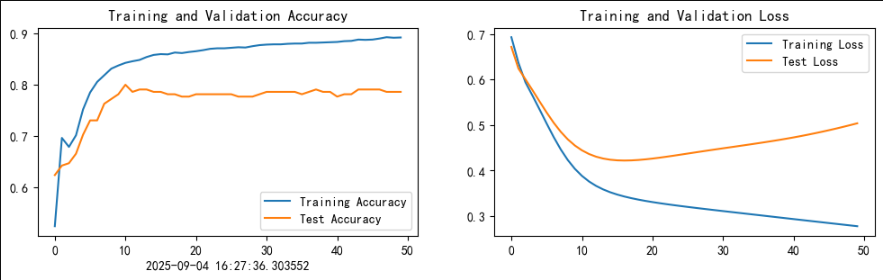
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time)plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
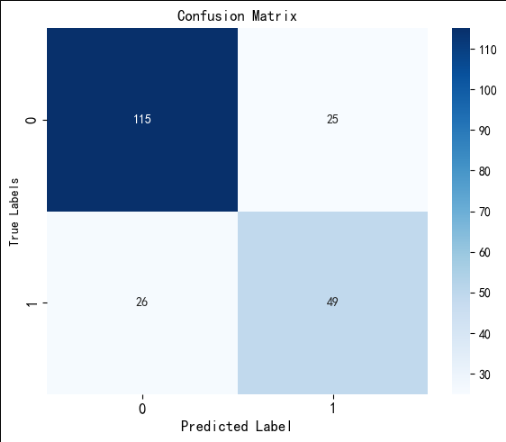
2、混沌矩阵
print("====================输入数据Shape为====================")
print("X_test.shape: ",X_test.shape)
print("y_test.shape: ",y_test.shape)pred = model(X_test.to(device)).argmax(1).cpu().numpy()
print("====================输出数据Shape为====================")
print("pred.shape: ",pred.shape)

import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay# 计算混淆矩阵
cm = confusion_matrix(y_test, pred)plt.figure(figsize=(6,5))
# plt.suptitle('Confusion Matrix')
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')# 修改字体大小
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.title('Confusion Matrix', fontsize=12)
plt.xlabel('Predicted Label', fontsize=12)
plt.ylabel('True Labels', fontsize=10)# 调整布局防止重叠
plt.tight_layout()# 显示图形
plt.show()
五、预测
六、总结
当然,在学习完RNN及其演进模型(如LSTM、GRU)后,对“如何处理序列数据”进行总结是非常有价值的。这能帮你建立起一个清晰的知识框架。
以下是一个系统性的总结,涵盖了从核心思想、关键挑战到解决方案和现代最佳实践。
处理序列数据的核心思想与总结
- 核心目标:处理带有“顺序依赖”的数据
序列数据的根本特征是数据点之间的顺序关系蕴含重要信息。例如,一句话中单词的顺序、一段音乐中音符的先后、股票价格随时间的变化等。模型的目标是学习这种顺序依赖关系,并做出预测、分类或生成。 - 基础架构:循环神经网络 (RNN)
RNN提供了处理序列数据的基本范式:
核心机制: 循环连接。网络为每个时间步的输入进行处理,并将一个“隐藏状态(Hidden State)”传递给下一个时间步。这个隐藏状态作为“记忆”,承载了之前所有时间步的摘要信息。
h_t = f(W * h_{t-1} + U * x_t + b)
优势: 参数共享(所有时间步共用同一组参数),理论上可以处理任意长度的序列。
典型结构:
一对一: 单个输入 -> 单个输出(例如,图像分类)
一对多: 单个输入 -> 序列输出(例如,图像字幕生成)
多对一: 序列输入 -> 单个输出(例如,情感分析)
多对多: 序列输入 -> 序列输出(例如,机器翻译、股票预测)
3. 核心挑战与致命缺陷:梯度消失/爆炸
问题: 当序列很长时,RNN在反向传播(BPTT)过程中,梯度需要连续乘以相同的权重矩阵,导致梯度呈指数级缩小(消失)或增大(爆炸)。
后果: 模型无法学习长期依赖关系。它变得“健忘”,只能记住近期信息,而难以利用序列早期的重要信息。这严重限制了基础RNN在长序列任务上的应用。
4. 解决方案:门控机制 (Gating Mechanism)
为了解决长期依赖问题,引入了更为强大的循环单元,其核心思想是使用“门”来精确控制信息的流动。
LSTM (长短期记忆网络):
核心: 引入了细胞状态(Cell State) 作为“信息高速公路”和三个门(输入门、遗忘门、输出门)。
工作方式: 门(Sigmoid函数)决定让多少信息通过(0~1)。遗忘门决定从细胞状态中丢弃什么信息;输入门决定添加什么新信息。这使得LSTM可以长期保存和传递关键信息。
GRU (门控循环单元):
核心: LSTM的简化版,将LSTM的三个门合并为两个:更新门和重置门。
特点: 参数更少,训练速度更快,但在大多数任务上的效果与LSTM相当。它成为了一个非常流行且高效的默认选择。
小结:RNN -> LSTM/GRU 的演进,是为了解决基础RNN的“短期记忆”问题,其核心技术创新是“门控”。
5. 更深与更广:架构的扩展
深度RNN: 将多个RNN层堆叠起来,底层处理低级特征(如字符、音素),高层处理高级特征(如语义、意图),以增强模型的表达能力。
双向RNN (Bi-RNN/Bi-LSTM/Bi-GRU): 同时运行两个独立的RNN,一个从序列开头到结尾(正向),一个从结尾到开头(反向),然后将它们的输出合并。
优势: 对于任何一个时间点,模型都拥有完整的上下文信息(过去和未来)。这在自然语言处理(如阅读理解、命名实体识别)中极其重要。
现代范式:注意力机制与Transformer
尽管LSTM/GRU解决了长期依赖,但仍存在序列计算无法并行、信息压缩丢失等问题。这催生了更革命的架构:
注意力机制 (Attention Mechanism):
核心思想: 允许模型在生成输出时,直接“关注”并加权输入序列中的任何部分,而不是强制将所有信息压缩到最后一個隐藏状态。
优势: 极大地改善了长序列性能,提供了更好的可解释性(可以看到模型在关注哪里)。
Transformer:
核心: 完全基于自注意力机制(Self-Attention),彻底抛弃了循环结构。
优势:
1.极高的并行化能力: 训练速度远超RNN/LSTM。
2.全局建模能力: 一步计算即可捕捉序列中任意两个元素之间的关系,无论距离多远。
影响: Transformer及其衍生模型(如BERT, GPT)已成为当前NLP乃至跨模态领域(视觉、音频)的绝对主流架构。
在学完循环神经网络RNN后,同时学习完门控机制后,GRU的优势(相对于RNN)解决了核心缺陷,极大缓解了梯度消失问题,具有强大的长序列建模能力。收敛更快: 训练过程更稳定,收敛速度通常更快。
性能卓越: 在绝大多数任务上的性能远超传统RNN。
GRU的劣势(相对于RNN):
结构更复杂,参数更多,计算量稍大。
过拟合风险稍高。那么,GRU和LSTM又如何选择呢?(你可能会问的下一个问题)
GRU通常被认为是LSTM的一个更轻量、更快的替代品。它们的性能在大多数任务上非常接近,没有绝对的赢家。
优先选择GRU:当计算资源受限、训练速度是关键因素,或者数据集较小时,GRU是一个很好的选择,因为它用更少的参数达到了与LSTM相似的性能。
优先选择LSTM:在一些非常长和复杂的序列任务上(如语音识别、音乐生成),LSTM凭借其更精细的门控控制(三个独立的门),可能拥有微弱的优势,但这并非绝对。
最佳实践是: 在你的特定数据集上同时试验GRU和LSTM,选择表现更好的那个。
GRU是对传统RNN的一次重大升级。它通过巧妙的门控设计,以可接受的计算成本为代价,成功解决了RNN的核心痛点,使其成为处理序列数据的强大而高效的模型。在学习上,从RNN到GRU/LSTM的演进,是理解如何通过设计更复杂的细胞结构来优化梯度流和信息保存的关键一步。


)







![[C/C++学习] 7.“旋转蛇“视觉图形生成](http://pic.xiahunao.cn/[C/C++学习] 7.“旋转蛇“视觉图形生成)








