作为一个程序员,假设我们要在a电脑的进程里发一段数据到b电脑,一般使用socket编程,可选项也就tcp,udp二选一
socket本质上就是一个代码库
tcp有粘包问题(字节流),纯裸tcp不能之际拿来使用
所以我们需要加入一些自定义的规则,用来区分消息边界,比如加入消息头(消息头里写清除一个完整的包长度是多少,还可以放消息体是否被压缩过,消息体格式之类的)
自定义的规则就是所谓的协议,每个使用tcp的项目都可能会定义一套这样的协议,基于tcp衍生了非常多的协议,比如http,rpc。tcp是传输层协议,而基于tcp造出来的http和各类rpc协议只是定义了不同消息格式的应用层协议
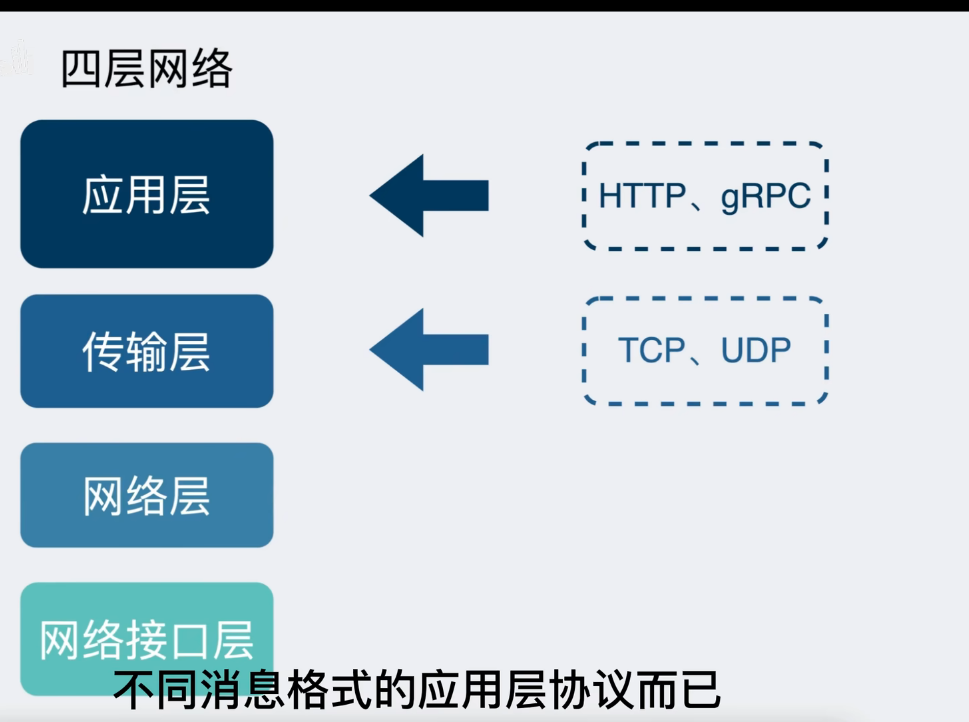
http协议
http协议又叫作超文本传输协议
rpc
远程过程调用,本身并不是一个具体的协议,而是一种调用方式,就是希望像调用本地方法那样调用远程方法
一般的软件,客户但需要跟服务端建立连接收发消息,此时都会用到应用层协议,在这种cs架构下,可以使用自家造的rpc协议
但是浏览器,不仅要能访问自家公司的服务器,还需要访问其他公司的网站服务器,所以需要http统一标准。所以多年前,http主要用于bs架构,但是现在已经分的没那么清除。
要向某个服务器发起请求,得先建立连接,所以得先知道ip地址和端口,找到服务对应的ip和端口的过程就是服务发现。http中你知道服务的域名即可通过dns服务去解析。rpc一般会有专门的中间服务去报仇服务名和ip信息
Http 1.1
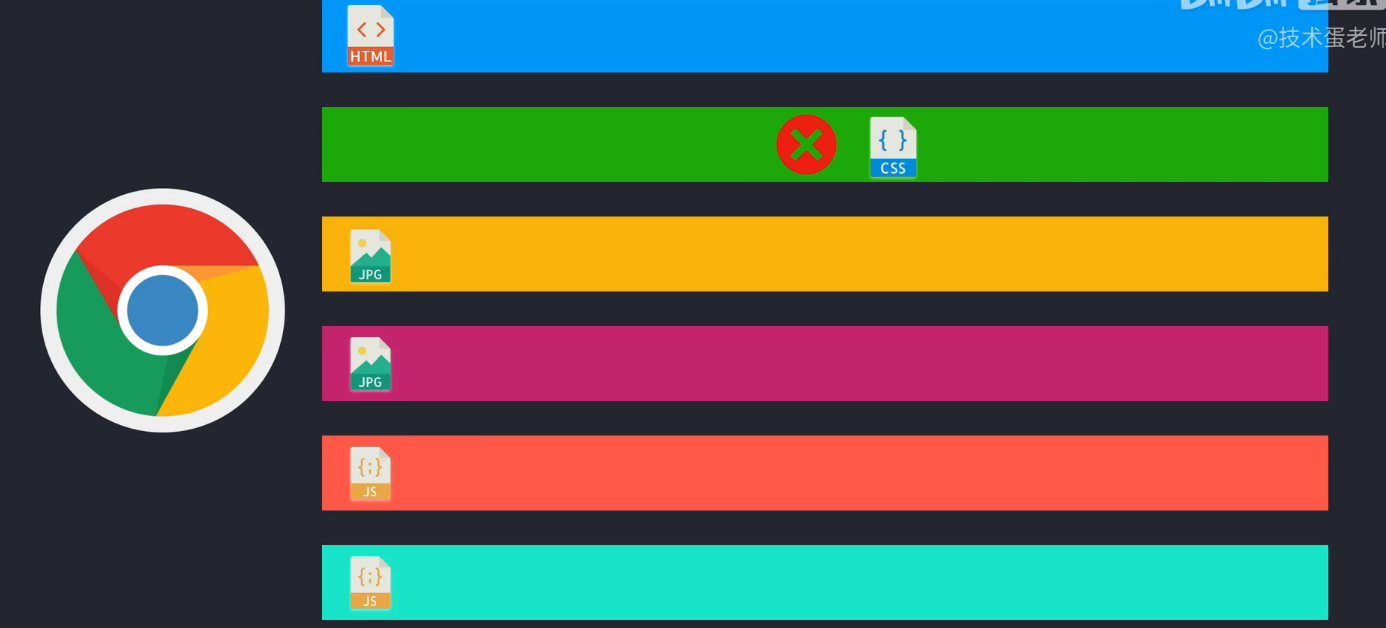
一次一份是核心,因为发送一个http请求的时候,是需要等收到Http响应才可以发送下一个Http请求。一个网页一般由多个文件组成,最基本的就是html css js和图片文件。对于http协议来说,我们打开一个网页需要进行tcp三次握手,建立起tcp连接,才正式进行请求,服务器会先发送html文件给我们,其他文件不会发送给我们,我们的浏览器在收到html文件以后根据html里面的内容,再向服务器以此请求css js等文件,整个过程都是浏览器在帮我们完成,所以对用户的直接感受就是只有一次请求,如果在请求队伍里,有一个文件没有收到,后面的文件也没法接收了,这就会造成http队头阻塞。对于http1.1来说默认是持久连接的,即保持这个tcp连接,不需要对每个请求再来一轮tcp握手,请求和响应都放在同一个连接里面,但是只有一个连接肯定太慢了,连接太多又怕会造成DDos攻击,因此各家浏览器允许的持久连接数都不太相同
浏览器会限制同一连接的请求数,限制每个域的连接数











![daily notes[44]](http://pic.xiahunao.cn/daily notes[44])

)





介绍及使用)