引言
想了好久,还是觉得这个标题才配得上printk!^_^
我相信,不管做什么开发,使用最多的调试手段应该就是打印了,从我们学习编程语言第一课开始,写的第一段代码,就是打印"Hello, world"。
内核也不例外,到处都有打印语句,只不过在内核中的打印函数是printk,printk作为内核中不可或缺的基础工具,几乎可以在内核的任何上下文中都可以使用,正应了那句话,它明明是那么普通,却又那么强大~~
关于printk的内容还挺多,所以分多篇深入介绍,这是第一篇,介绍printk的基本用法,后面介绍printk的进阶用法。
如果本篇你已经熟悉,可以直接阅读后面的内容,快捷跳转:
Linux Kernel调试:强大的printk(二):pr_xxx相关的内容
Linux Kernel调试:强大的printk(三):dev_xxx相关的内容,以及限制打印速率
printk的特性
printk是一个在内核中使用的打印函数,用于向内核日志系统输出信息,其通过将消息写入内核日志缓冲区,然后由不同的工具读取,比如 dmesg 命令或者查看 /var/log/syslog 文件(根据系统配置不同而有所变化)。
它对于调试和报告错误很有用,并且可以在中断上下文中使用,但是使用时要小心:如果机器的控制台中充斥着printk消息则会无法使用。
相比于用户空间的printf,printk 有一些独特的特性和用途:
-
日志级别:printk 允许你指定日志级别,这可以控制该消息是否显示到控制台。例如,紧急错误可能需要立即显示,而调试信息则不一定。
-
缓冲区:printk 的输出首先被写入一个环形缓冲区(ring buffer)中。这意味着即使没有控制台,或者控制台驱动程序尚未初始化,也可以记录消息。你可以通过读取 /proc/kmsg 或者使用 dmesg 命令来查看这些消息。
-
时间戳:每个 printk 消息都会附带一个时间戳,这个时间戳是从系统启动开始计算的时间,单位是秒和微秒。这对于调试非常有用,因为它可以帮助确定事件发生的顺序和间隔。
-
异步行为:与 printf 不同,printk 并不保证消息会立刻出现在控制台上。这是因为内核代码不能阻塞等待 I/O 完成,所以 printk 实际上将消息放入了一个队列中,稍后由另一个内核线程负责将其实际输出到控制台或其他目标。
printk的函数原型
printk定义于include/linux/printk.h文件中,原型如下:
#define printk(fmt, ...) printk_index_wrap(_printk, fmt, ##__VA_ARGS__)#define printk_index_wrap(_p_func, _fmt, ...) \({ \__printk_index_emit(_fmt, NULL, NULL); \_p_func(_fmt, ##__VA_ARGS__); \})int _printk(const char *fmt, ...);printk的用法
printk的调用方法如下:
printk(KERN_INFO "My printk message\n");这里的 KERN_INFO 是一个宏,它实际上只是一个字符串常量,用来表示这条消息的日志级别。其他可用的日志级别稍后会讲。我们可以使用dmesg(1)之类的查看日志的工具根据日志级别进行过滤。
尽管 printk 很方便,但在性能关键的路径中应谨慎使用,因为即使是简单的日志记录操作也可能引入显著的开销。另外,在一些时序要求严格的场合,一定要在关闭日志的情况下充分测试,因为有时打印日志会改变时序,会出现关闭log时,程序反而不能正常工作。
日志级别
日志级别在include/linux/kern_levels.h文件中定义:
#define KERN_SOH "\001" /* ASCII Start Of Header */
#define KERN_SOH_ASCII '\001'#define KERN_EMERG KERN_SOH "0" /* system is unusable */
#define KERN_ALERT KERN_SOH "1" /* action must be taken immediately */
#define KERN_CRIT KERN_SOH "2" /* critical conditions */
#define KERN_ERR KERN_SOH "3" /* error conditions */
#define KERN_WARNING KERN_SOH "4" /* warning conditions */
#define KERN_NOTICE KERN_SOH "5" /* normal but significant condition */
#define KERN_INFO KERN_SOH "6" /* informational */
#define KERN_DEBUG KERN_SOH "7" /* debug-level messages */#define KERN_DEFAULT "" /* the default kernel loglevel *//** Annotation for a "continued" line of log printout (only done after a* line that had no enclosing \n). Only to be used by core/arch code* during early bootup (a continued line is not SMP-safe otherwise).*/
#define KERN_CONT KERN_SOH "c"-
可以看到,日志级别有0~7种,从名称也可以看得出来,数值越小越紧急,优先级越高
-
KERN_SOH是一个控制字符,用于标记日志级别的开始,当解析到KERN_SOH后,其后的一个字符就是日志级别,或者KERN_CONT
-
KERN_CONT的意思是这是前一条消息的续行消息,不会添加时间戳、日志级别等新行信息,也不会换行
-
如果没有解析到KERN_SOH则使用默认级别,KERN_DEFAULT定义为空,这就可以通过编译时配置或者运行时设置默认的日志级别了
printk输出到哪里
以下是 printk 输出信息可能到达的设备或位置:
内核日志缓冲区
printk 首先将消息写入内核日志缓冲区,这是一个环形缓冲区,用于临时存储内核消息,直到它们被用户空间的工具(如 dmesg 或日志守护进程)读取。
控制台(Console)
根据内核的配置和日志级别,printk 输出的消息可能会直接显示在控制台上。
-
虚拟控制台(TTY):在本地终端(如 /dev/tty1 或 /dev/ttyS0)上显示消息。
-
串行控制台:通过串行端口(如 COM 端口)输出消息,常用于服务器或嵌入式设备的调试。
-
图形控制台:在图形界面的终端窗口中显示消息(如 X 终端)。
通过内核启动参数(如 console=ttyS0,115200)或运行时配置(如 dmesg 的日志级别设置)来控制哪些消息会显示在控制台上。
日志文件
用户空间的日志守护进程(如 systemd-journald 或 rsyslogd)会从内核日志缓冲区读取消息,并将它们写入日志文件。
常见日志文件:
-
/var/log/syslog 或 /var/log/messages:系统日志文件,存储内核消息和其他系统日志。
-
/var/log/dmesg:专门存储内核日志的文件,通常由 dmesg 命令更新。
日志守护进程的配置文件(如 /etc/rsyslog.conf 或 /etc/systemd/journald.conf)决定了日志的存储位置和格式。
网络日志服务器
在某些配置下,内核日志可以通过网络发送到远程日志服务器,便于集中管理和监控。
实现方式:通过日志守护进程(如 rsyslogd)配置网络日志功能,将日志消息发送到指定的远程服务器。
其他输出目标
-
串行端口:除了作为控制台外,串行端口也可以被配置为单独的日志输出目标,用于调试或日志备份。
-
USB 调试接口:在一些嵌入式设备中,printk 输出可以通过 USB 调试接口发送到连接的主机。
-
自定义设备:通过内核模块或驱动程序,可以将 printk 输出重定向到其他自定义设备(如存储设备或专用的调试接口)。
用户空间程序
用户空间程序可以通过 /dev/kmsg 或 dmesg 等接口直接读取内核日志,并进行进一步处理或显示。
-
dmesg:用于显示内核日志的命令行工具。
-
journalctl(systemd 系统):用于查看和管理内核日志的工具。
Ubuntu控制台日志级别配置
我们在ubuntu上,有时会发现,有些log不会显示到控制台上,通过dmesg命令才可以看到,这是因为内核向控制台输出的信息取决于其日志级别,通过 /proc/sys/kernel/printk 文件控制,我们查看该文件内容如下:

这4个数字的含义如下:
第一个数字是控制台日志级别(console_loglevel),表示只有严重程度高于或等于这个级别的内核消息会被打印到控制台上。
第二个数字是默认的消息日志级别(default_message_loglevel),它设定了当调用内核函数
printk()而没有明确指定优先级时,给消息分配的默认优先级。第三个数字是最低的控制台日志级别(minimum_console_loglevel),系统允许的最小控制台日志级别。例如,如果这个值为
1,则控制台日志级别不能设置为0(KERN_EMERG)。第四个数字是默认的控制台日志级别(default_console_loglevel),代表启动时的默认控制台日志级别。它是一个参考值,在某些情况下,系统可能会重置控制台日志级别回到这个默认值。
所以第一个数字是4,就表示比KERN_WARNING级别高的打印信息才会出现在控制台上。这在一定程度上过滤了一些并不是很重要的信息。
printk格式占位符
一些常见的printk格式占位符:
-
对于size_t和ssize_t类型(分别表示有符号和无符号整数),请分别使用%zu和%zd格式说明符
-
在打印内核空间中的地址(指针)时:
-
非常重要:出于安全考虑,请使用%pK(它只会输出哈希值,有助于防止信息泄露,这是一个严重的安全问题)
-
对于实际的指针,请使用%px查看实际地址(不要在生产环境中这样做!)
-
对于物理地址,请使用%pa
-
-
若要将原始缓冲区打印为十六进制字符串,请使用%*ph(其中*由字符数量代替;对于少于65个字符的缓冲区使用此方法,对于更多字符的缓冲区则使用print_hex_dump_bytes()函数)。有多种变体可用(参见随后的内核文档链接)
完整的printk格式占位符列表,包括使用示例,请查阅内核文档:
中文:Documentation/translations/zh_CN/core-api/printk-formats.rst
英文:Documentation/core-api/printk-formats.rst
内核模块中使用printk
虽然在内核模块中使用printk显得很low(一般都是使用pr_xxx或者dev_xxx),但是由于我们这一篇就是讲printk的,所以还是以printk为例写一个内核模块,来实际使用一下printk,关于写内核模块的知识这里不会讲解,后面看看,如有必要,会补上这部分知识,现在缺少这部分知识的同学需要自己学习一下
下面是代码,共有两个文件printk_usage.c和Makefile文件,可到这里获取https://gitee.com/coolloser/linux-kerenl-debug:
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>// 定义模块加载函数
static int __init printk_module_init(void)
{printk(KERN_INFO "====printk模块加载成功!====\n");printk(KERN_DEBUG "这是一个DEBUG级别的信息\n");printk(KERN_INFO "这是一个INFO级别的信息\n");printk(KERN_WARNING "这是一个WARNING级别的信息\n");printk(KERN_ERR "这是一个ERROR级别的信息\n");printk(KERN_CRIT "这是一个CRITICAL级别的信息\n");printk(KERN_ALERT "这是一个ALERT级别的信息\n");printk(KERN_EMERG "这是一个EMERGENCY级别的信息\n");// 使用KERN_CONT继续上一条日志消息printk(KERN_INFO "这是一条需要继续的信息...");printk(KERN_CONT "...这是继续的部分\n");// 使用KERN_DEFAULT设置默认日志级别printk(KERN_DEFAULT "这是默认日志级别的信息\n");return 0; // 返回0表示模块加载成功
}// 定义模块卸载函数
static void __exit printk_module_exit(void)
{printk(KERN_INFO "====printk模块卸载成功!====\n");
}// 注册模块加载和卸载函数
module_init(printk_module_init);
module_exit(printk_module_exit);// 模块信息
MODULE_LICENSE("GPL");
MODULE_AUTHOR("your_name");
MODULE_DESCRIPTION("一个简单的printk内核模块示例");
MODULE_VERSION("0.1");# 定义模块名称
MODULE_NAME := printk_usage# 定义内核构建目录,替换成你自己的路径
KERNEL_BUILD_DIR := /home/leo/debug_kernel/linux-6.12.28# 定义目标文件
obj-m += $(MODULE_NAME).o# 默认目标
all:@echo "Building the $(MODULE_NAME) kernel module..."$(MAKE) -C $(KERNEL_BUILD_DIR) M=$(PWD) modules# 清理目标
clean:@echo "Cleaning up the build environment..."$(MAKE) -C $(KERNEL_BUILD_DIR) M=$(PWD) clean直接执行make命令进行编译:
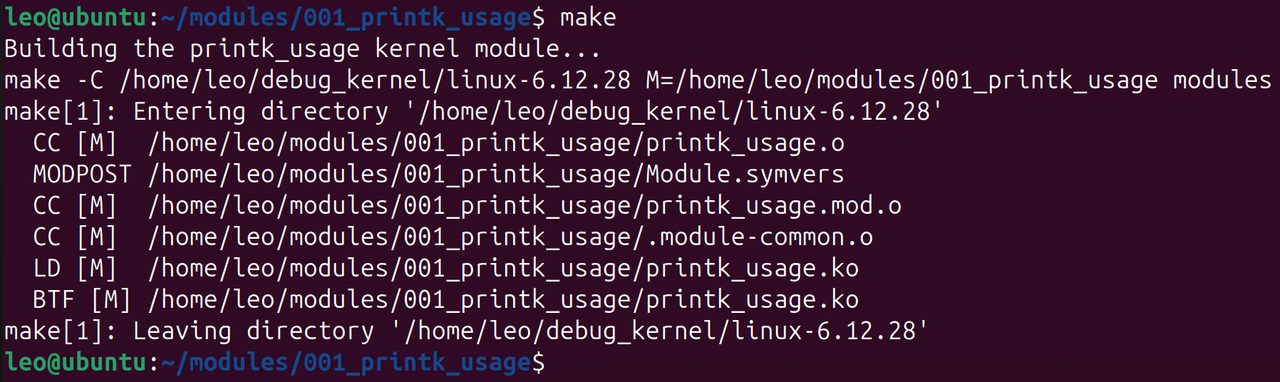
会生成printk_usage.ko
为了测试哪些log会直接显示到终端上,我们需要输入ctrl+alt+F3打开一个虚拟终端(tty3),然后登录
执行如下命令加载模块:
cd modules/001_printk_usage
sudo insmod printk_usage.ko会显示如下内容:
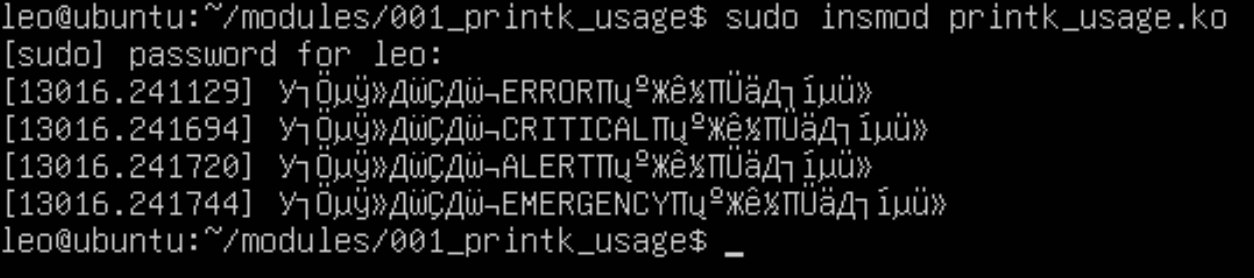
忽略中文乱码问题^_^,还是能看到ERROR,CRITICAL,ALERT,EMERGENCY级别的log直接显示到终端上了,这符合/proc/sys/kernel/printk文件控制的log级别
然后我们回到图形界面(ctrl+alt+F1),输入如下命令:
sudo dmesg可以看到如下内容:

模块中打印的所有内容都可以看到,可以看到KERN_CONT对应的log接续在上一条的后面
总结
本篇介绍了printk的基础知识和基本用法,最后通过一个内核模块演示了printk的级别等用法,以及如何查看这些log,由于printk篇幅较长,一篇写完太长,阅读起来比较累,所以分多篇进行介绍,后面会介绍printk的进阶用法,如pr_xxx和dev_xxx,还有printk_ratelimited等等的
请继续阅读下一篇:
Linux Kernel调试:强大的printk(二)


:渐进式分层提取模型PLE(Progressive Layered Extraction))






SVIn2声呐模块分析)




![[特殊字符] 使用增量同步+MQ机制将用户数据同步到Elasticsearch](http://pic.xiahunao.cn/[特殊字符] 使用增量同步+MQ机制将用户数据同步到Elasticsearch)




