输出数据OutputFormat
案例:

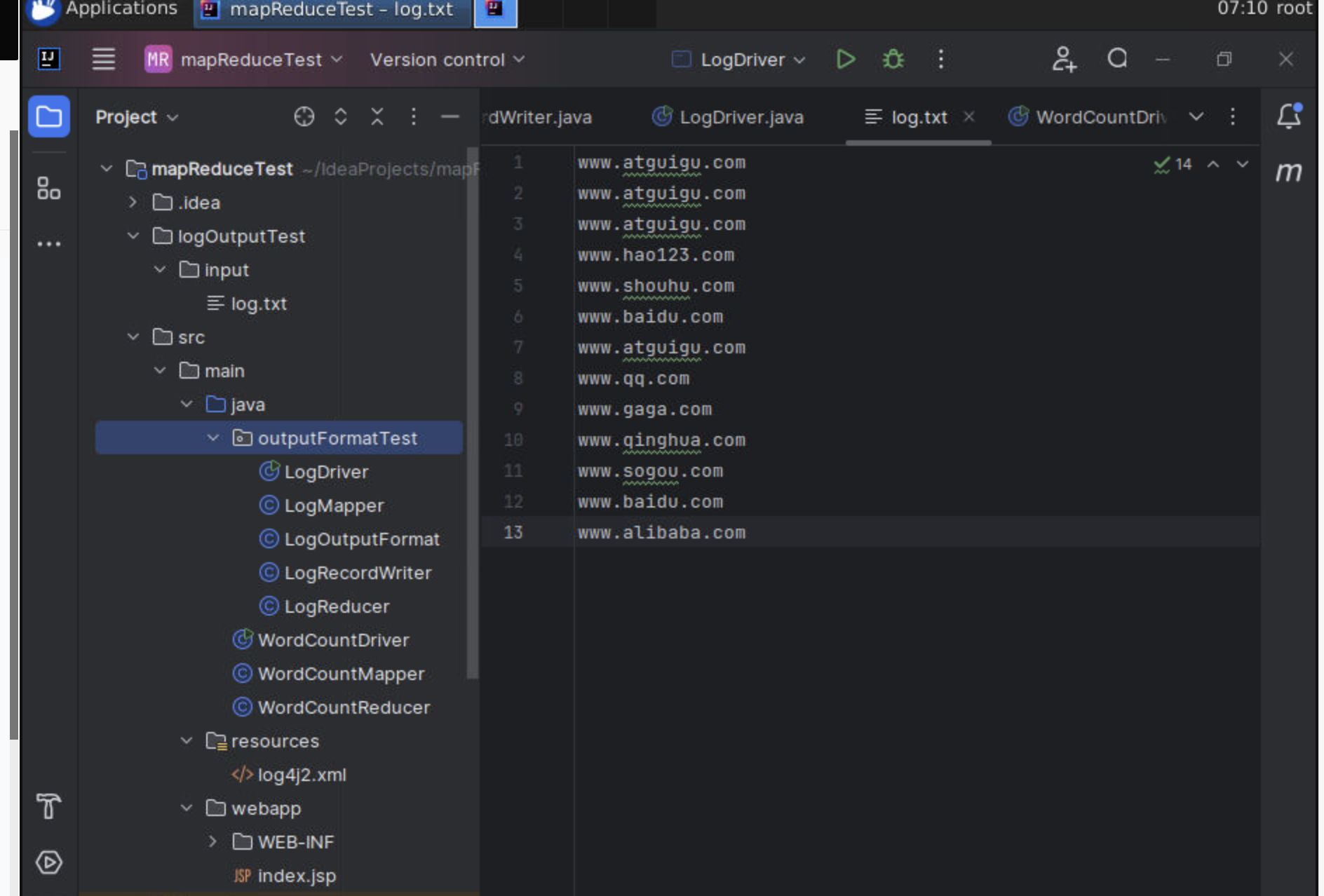
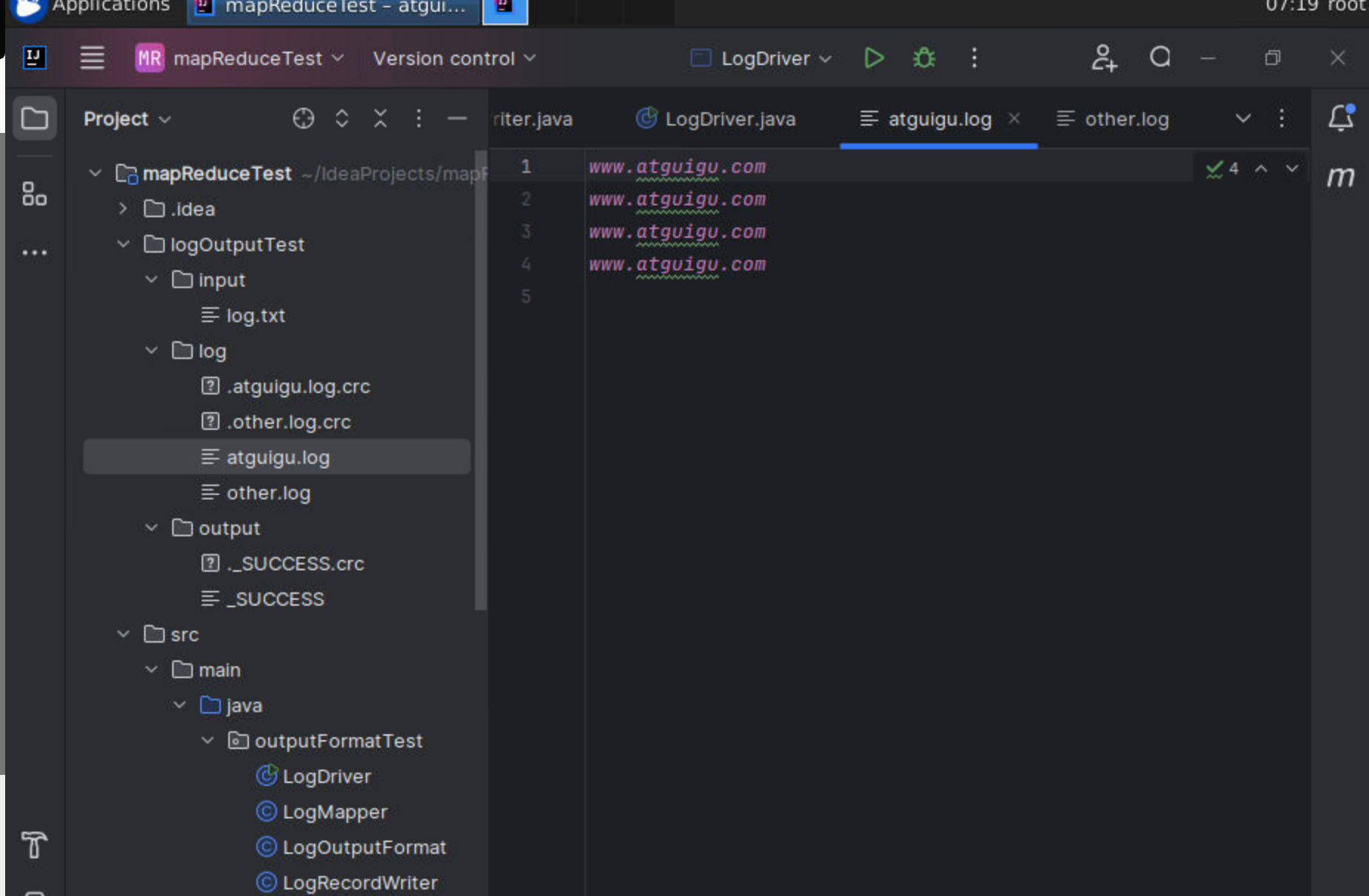
www.atguigu.com
www.atguigu.com
www.atguigu.com
www.hao123.com
www.shouhu.com
www.baidu.com
www.atguigu.com
www.qq.com
www.gaga.com
www.qinghua.com
www.sogou.com
www.baidu.com
www.alibaba.com 1.创建一个文件在log.txt
如下图:
2.在java目录下创建一个outputFormatTest文件夹
在文件夹下面创建相应的类
3.LogMapper的代码如下:
package outputFormatTest;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable> {@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {context.write(value,NullWritable.get());}
}
4.LogReducer的代码如下
package outputFormatTest;import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class LogReducer extends Reducer<Text, NullWritable,Text,NullWritable> {@Overrideprotected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {for (NullWritable value : values) {context.write(key,NullWritable.get());}}
}
5.LogOutputFormat代码为
package outputFormatTest;import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class LogOutputFormat extends FileOutputFormat<Text, NullWritable> {@Overridepublic RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {LogRecordWriter logRecordWriter=new LogRecordWriter(job);return logRecordWriter;}
}
5.LogRecordWriter的代码如下
package outputFormatTest;import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;import java.io.IOException;public class LogRecordWriter extends RecordWriter<Text, NullWritable> {private FSDataOutputStream atguiguOut;private FSDataOutputStream otherOut;public LogRecordWriter(TaskAttemptContext job) {try {FileSystem fs=FileSystem.get(job.getConfiguration());atguiguOut=fs.create(new Path("/root/IdeaProjects/mapReduceTest/logOutputTest/log/atguigu.log"));otherOut=fs.create(new Path("/root/IdeaProjects/mapReduceTest/logOutputTest/log/other.log"));} catch (IOException e) {throw new RuntimeException(e);}}@Overridepublic void write(Text key, NullWritable value) throws IOException, InterruptedException {String log=key.toString();if(log.contains("atguigu")){atguiguOut.writeBytes(log+"\n");}else{otherOut.writeBytes(log+"\n");}}@Overridepublic void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {IOUtils.closeStream(atguiguOut);IOUtils.closeStream(otherOut);}
}
6.LogDriver的代码如下
package outputFormatTest;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class LogDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {//1.Configuration configuration=new Configuration();Job job=Job.getInstance(configuration);//2.job.setJarByClass(LogDriver.class);//3.job.setMapperClass(LogMapper.class);job.setReducerClass(LogReducer.class);//4.job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(NullWritable.class);//5.job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);//6.job.setOutputFormatClass(LogOutputFormat.class);FileInputFormat.setInputPaths(job,new Path("/root/IdeaProjects/mapReduceTest/logOutputTest/input"));FileOutputFormat.setOutputPath(job,new Path("/root/IdeaProjects/mapReduceTest/logOutputTest/output"));
// FileInputFormat.setInputPaths(job,new Pathhadoop fs -put /usr/local/hadoop/lotus.txt /WordCountTest/input"));
// FileOutputFormat.setOutputPath(job,new Path("/root/IdeaProjects/mapReduceTest/WordCountoutput"));//7.boolean result=job.waitForCompletion(true);System.exit(result?0:1);}
}
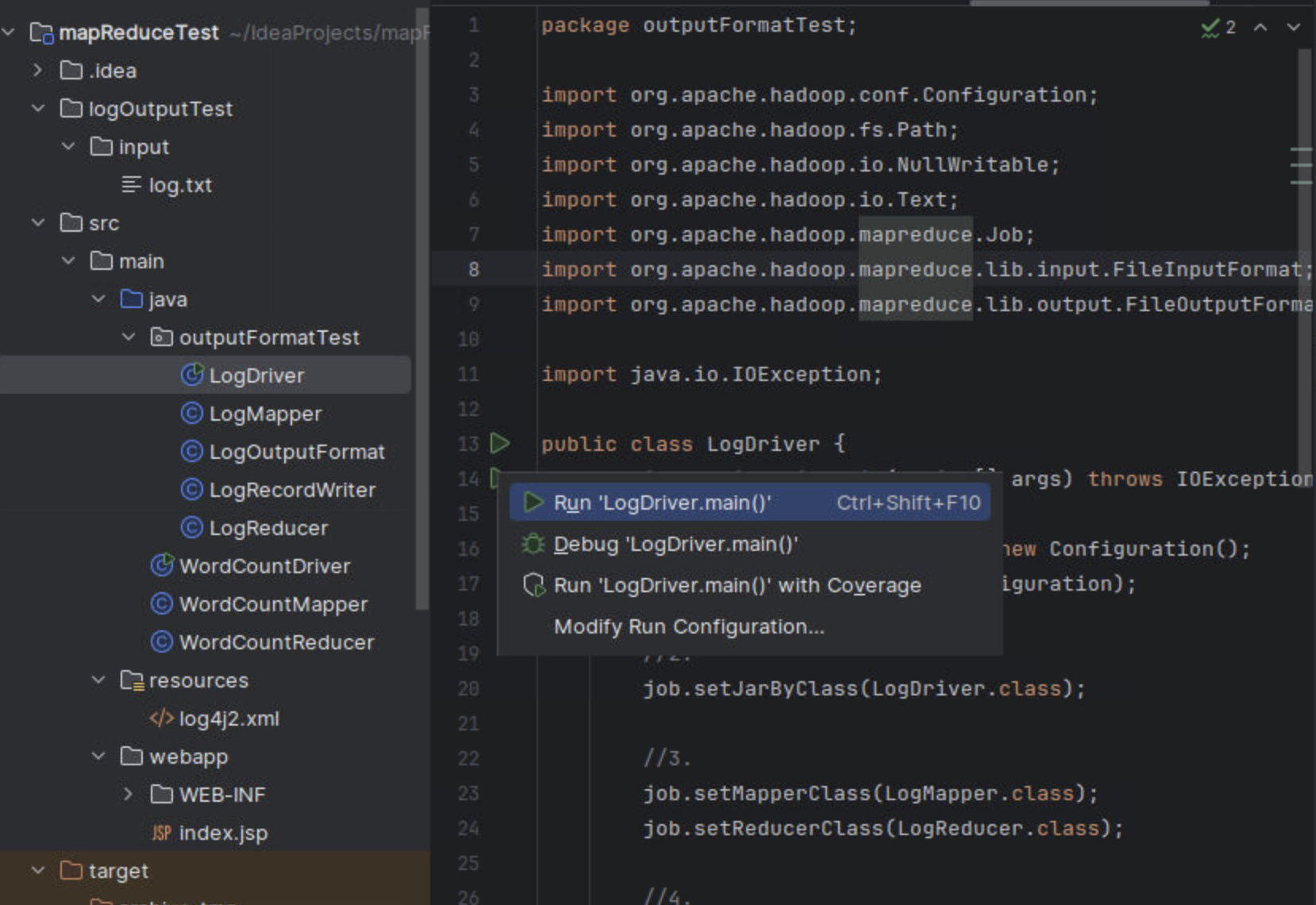
7.运行代码
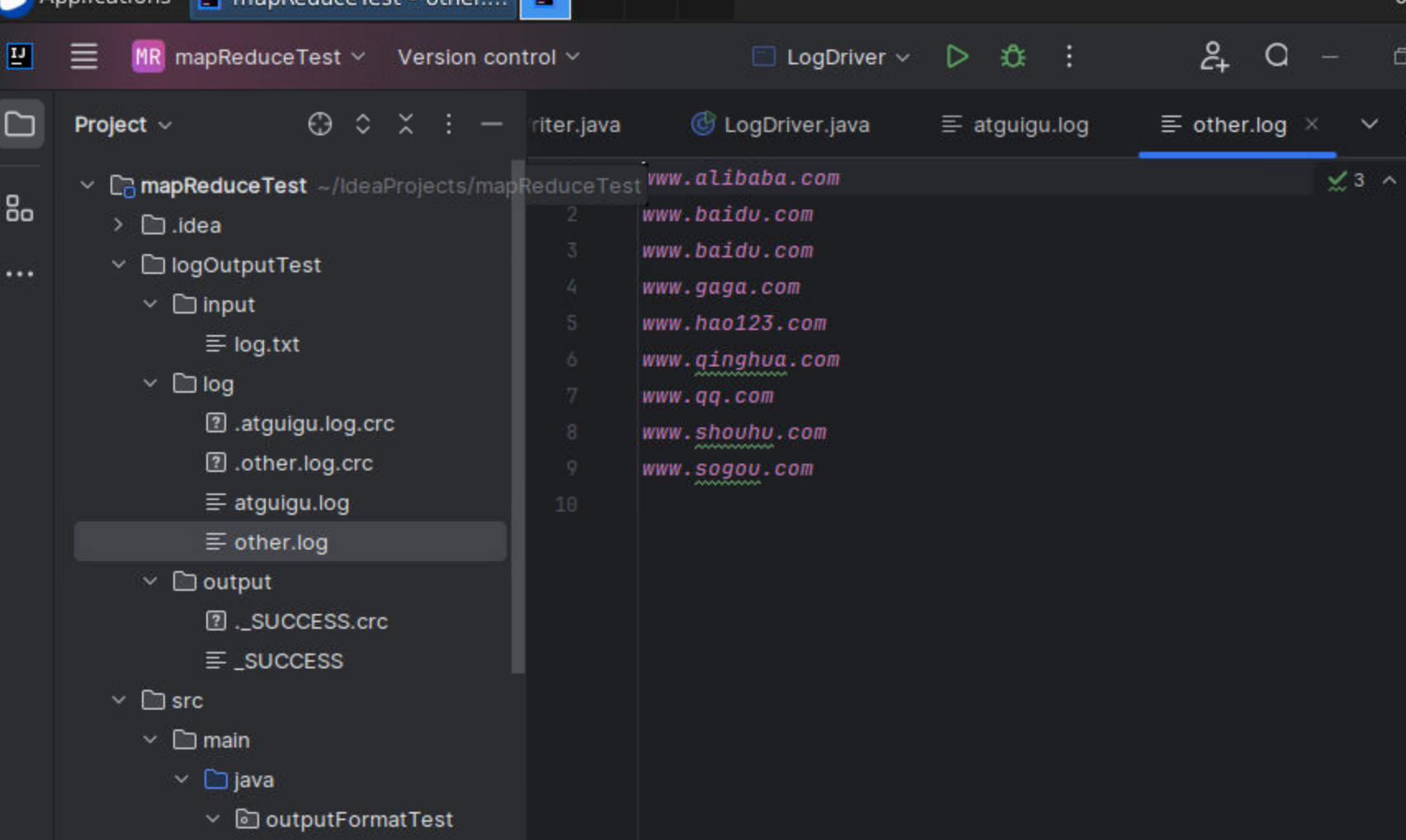
8.结果如下
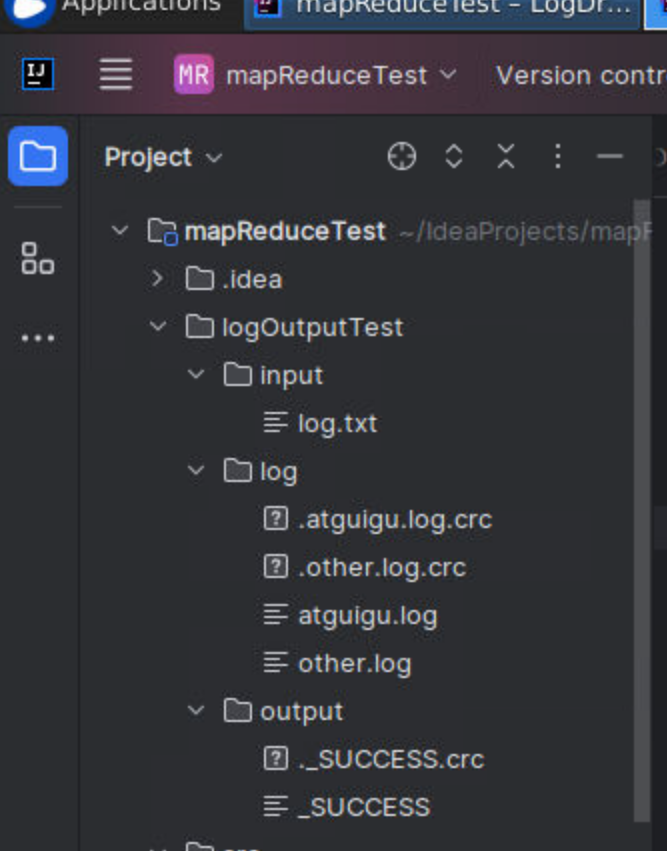
会多两个文件夹,分别是log和output



 瞬态仿真)

)

)







 - 使用Python操作Redis详解)



