阅读笔记:
理解LLM
deepseek创新了什么
什么是多模态
什么是token
- 定义:Token是LLM处理文本的最小单位,相当于语言的"原子"
- 类比:
中文:1个token ≈ 1个汉字或常见词(如"模型"可能为1个token)
英文:1个token ≈ 4个字母(如"apple"可能拆为"app"+“le”)
每个token都会在模型中生成三个核心向量
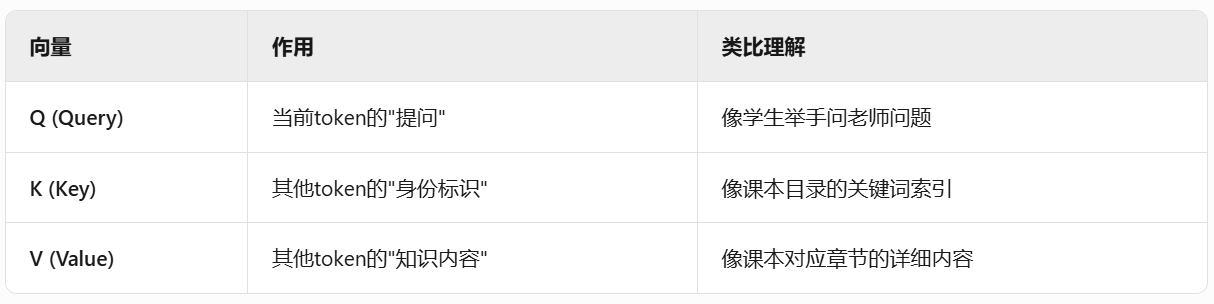
○ Q 是查询向量
○ K 是线索向量
○ V 是答案向量
候选token:在自注意力机制中,候选token 是指当前token在计算注意力权重时,所有可能与之发生交互的其他token。
api
大语言模型的 本质就是文字接龙 , 相对应的使用大模型也比较简单. 可以参见deepseek的文字接龙 api 请求:
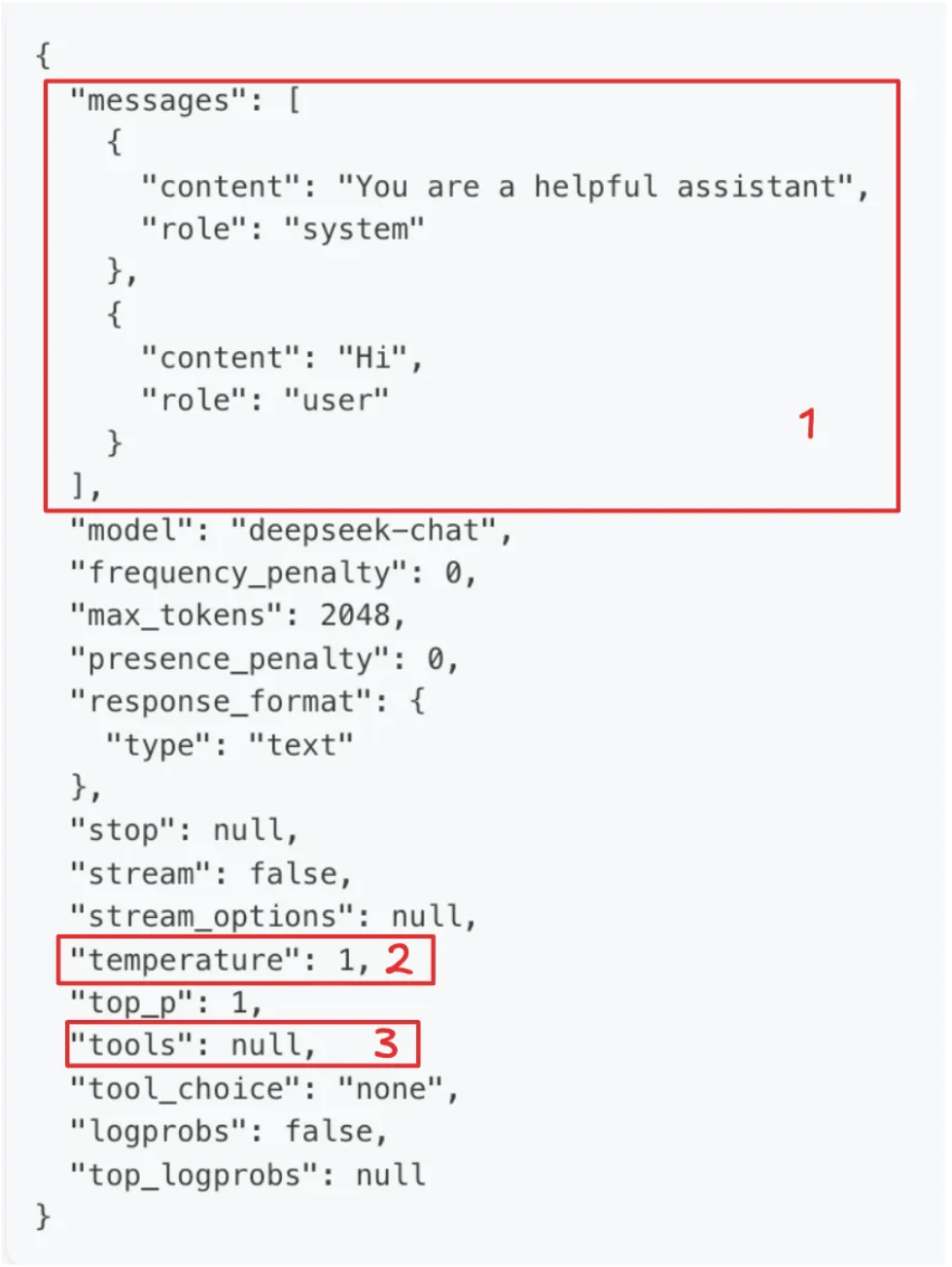
tools 工具支持:
大模型对 function calling 的支持,即大模型可以调用各种外部工具
为什么说LLM是无状态的
LLM有自注意力机制能动态关联上下文(通过Q/K/V向量),但LLM却被认为无状态。这看似矛盾,实则反映了不同层级的特性:

这时候就有一个问题,既然LLM是无状态的,不能记住跨序列的多次输入,那么LLM是如何持续关联一个对话的上下文的?——增加一个外部记忆库(传统方案是增大一个序列的max_length)
Java学习-5.14(注册,盐值加密,模糊查询))











空间))



)
su7登场)

