文章目录
- AI(学习笔记第六课) 使用langchain进行AI开发 load documents(csv和文件夹)
- 学习内容:
- 1.load documents(csv)
- 1.1 学习`url`
- 1.2 `load csv`文件
- 1.2.1 默认`load`
- 1.2.2 `csv`文件内容
- 1.2.2 执行`csv`文件的`load`
- 1.3 Customizing the CSV parsing and loading(自定义`loader`)
- 1.3.1 实现代码
- 1.3.2 代码执行
- 1.4 Specify a column to identify the document source(执行列来标明`source`)
- 1.4.1 实现`source`指定的代码
- 1.4.2 执行`source`指定的代码
- 1.3 使用`python`的`tempfile`
- 1.3.1 `tempfile`使用的代码
- 1.3.2 代码执行
- 2.load documents(from directory)
- 2.1 准备数据文件夹
- 2.2 文件夹`load`的代码
- 2.3 `trouble shooting`
- 2.3.1 出现的问题
- 2.3.2 使用`git bash`进行安装
- 2.4 执行文件夹`load`的代码
AI(学习笔记第六课) 使用langchain进行AI开发 load documents(csv和文件夹)
- 使用
langchain如何解析csv文件
学习内容:
- 从
csv中load文件 - 从文件夹中
loader文件
1.load documents(csv)
1.1 学习url
- langchain的load documents(csv)文档
- csv文件示例
1.2 load csv文件
1.2.1 默认load
from langchain_community.document_loaders.csv_loader import CSVLoader
import asynciofile_path = r'D:\00_study\07_python\PythonProject\src' \r'\document_loaders\examples\mlb_teams_2012.csv'async def load_csv():loader = CSVLoader(file_path=file_path)data = loader.load()for record in data[:2]:print(record)asyncio.run(load_csv())
1.2.2 csv文件内容
这里的示例csv文件
"Team", "Payroll (millions)", "Wins"
"Nationals", 81.34, 98
"Reds", 82.20, 97
"Yankees", 197.96, 95
"Giants", 117.62, 94
"Braves", 83.31, 94
"Athletics", 55.37, 94
"Rangers", 120.51, 93
"Orioles", 81.43, 93
"Rays", 64.17, 90
"Angels", 154.49, 89
"Tigers", 132.30, 88
"Cardinals", 110.30, 88
"Dodgers", 95.14, 86
"White Sox", 96.92, 85
"Brewers", 97.65, 83
"Phillies", 174.54, 81
"Diamondbacks", 74.28, 81
"Pirates", 63.43, 79
"Padres", 55.24, 76
"Mariners", 81.97, 75
"Mets", 93.35, 74
"Blue Jays", 75.48, 73
"Royals", 60.91, 72
"Marlins", 118.07, 69
"Red Sox", 173.18, 69
"Indians", 78.43, 68
"Twins", 94.08, 66
"Rockies", 78.06, 64
"Cubs", 88.19, 61
"Astros", 60.65, 55
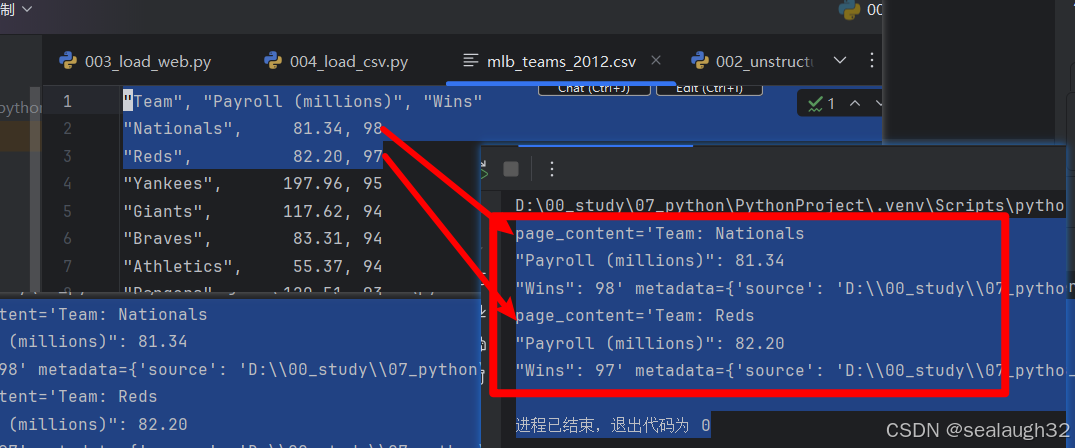
1.2.2 执行csv文件的load
对解析出来的data的前两行的输出。
1.3 Customizing the CSV parsing and loading(自定义loader)
1.3.1 实现代码
async def load_customized_csv():loader = CSVLoader(file_path=file_path,csv_args={"delimiter": ",","quotechar": '"',"fieldnames": ["MLB Team", "Payroll in millions", "Wins"],},)data = loader.load()for record in data[:2]:print(record)asyncio.run(load_customized_csv())
1.3.2 代码执行
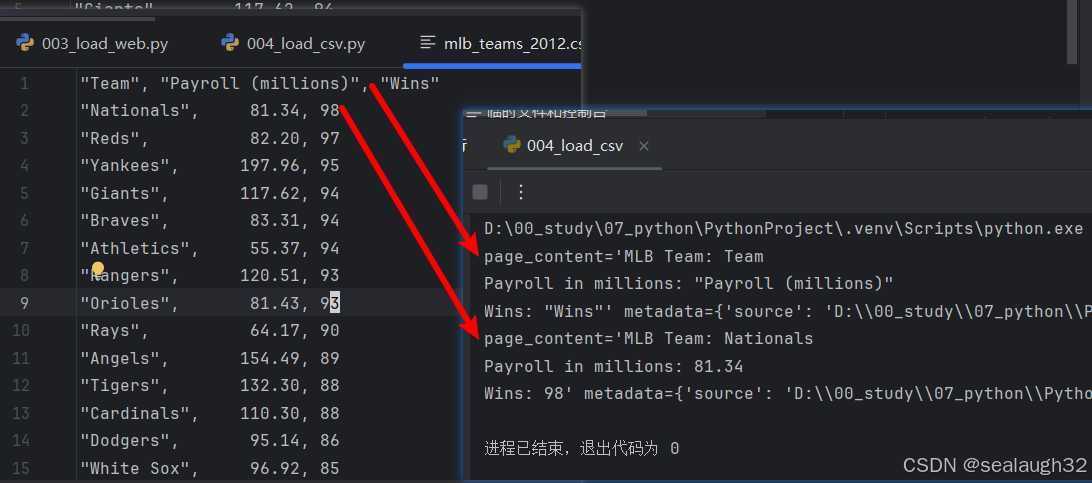
1.4 Specify a column to identify the document source(执行列来标明source)
上面的例子看出,metadata中的source都是这个csv的所在文件的绝对路径,那么如果想使用某一个column作为source也是可以的。
1.4.1 实现source指定的代码
async def load_specify_source():loader = CSVLoader(file_path=file_path,source_column="Team")data = loader.load()for record in data[:2]:print(record)asyncio.run(load_specify_source())
1.4.2 执行source指定的代码
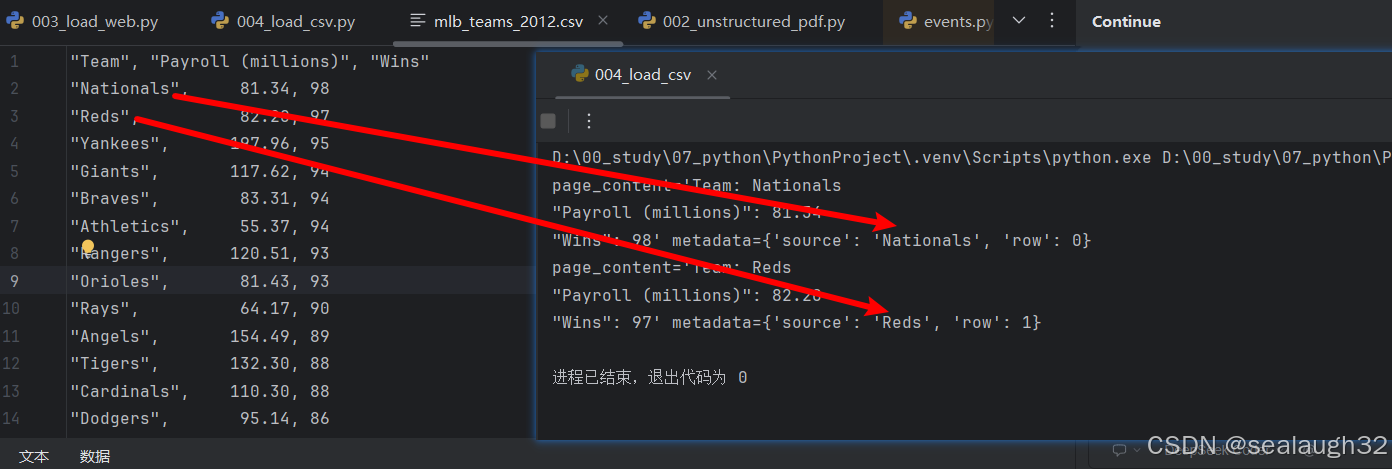
1.3 使用python的tempfile
如果没有文件,临时使用内存变量进行模拟csv文件,进行load
1.3.1 tempfile使用的代码
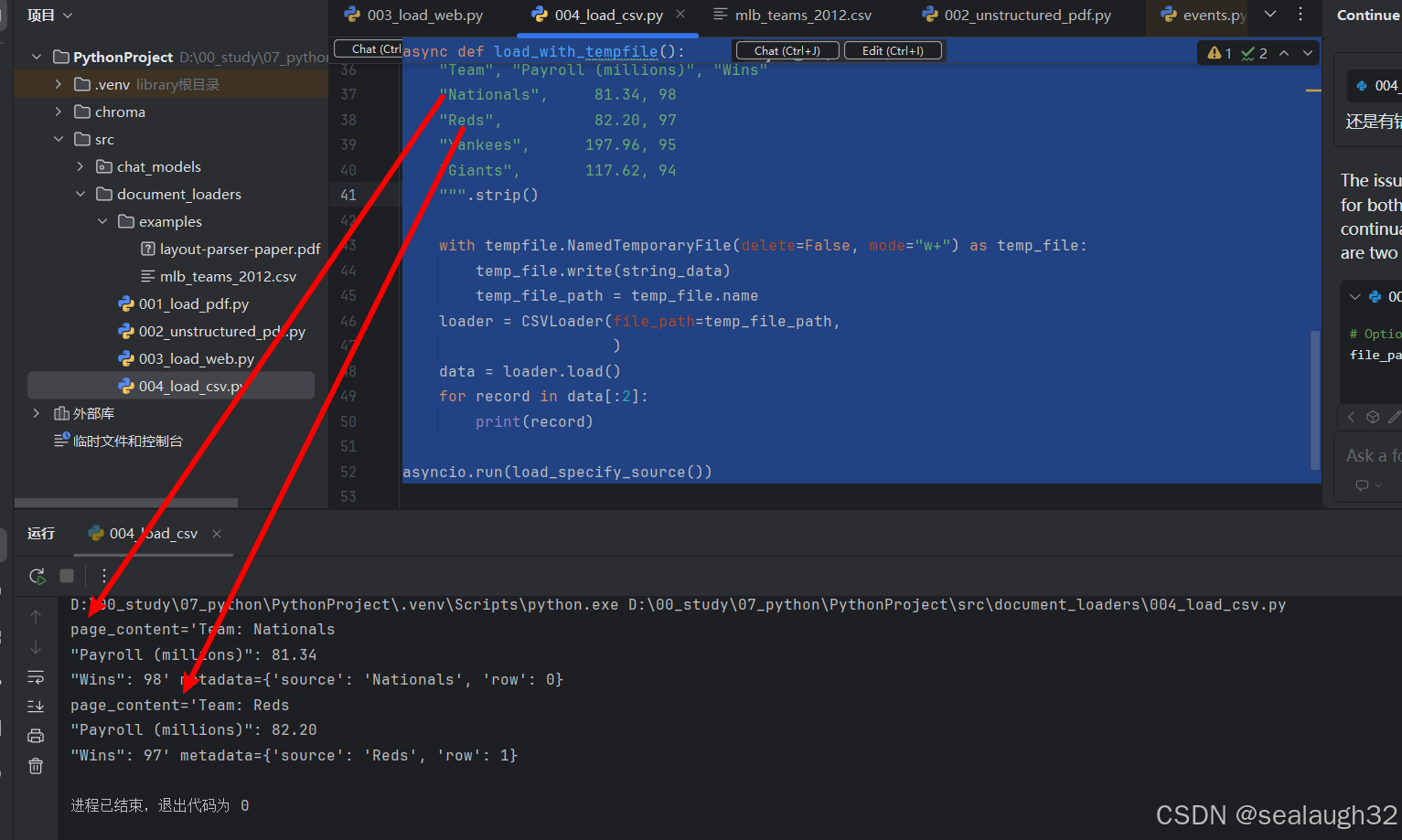
async def load_with_tempfile():string_data = """"Team", "Payroll (millions)", "Wins""Nationals", 81.34, 98"Reds", 82.20, 97"Yankees", 197.96, 95"Giants", 117.62, 94""".strip()with tempfile.NamedTemporaryFile(delete=False, mode="w+") as temp_file:temp_file.write(string_data)temp_file_path = temp_file.nameloader = CSVLoader(file_path=temp_file_path,)data = loader.load()for record in data[:2]:print(record)asyncio.run(load_specify_source())
1.3.2 代码执行
2.load documents(from directory)
2.1 准备数据文件夹
虽然这个文件夹就两个文件,但是使用这个作为练习的目标文件夹。
2.2 文件夹load的代码
from langchain_community.document_loaders import DirectoryLoaderdirectory_path = r'D:\00_study\07_python\PythonProject\src' \r'\document_loaders\examples'
loader = DirectoryLoader(directory_path,glob="**/*.md")
docs = loader.load()
print(len(docs))
2.3 trouble shooting
2.3.1 出现的问题
这里,执行的时候发现出现错误,让执行pip install "unstructured[md]",这时候通过pycharm的包管理的界面已经搜索不到了。
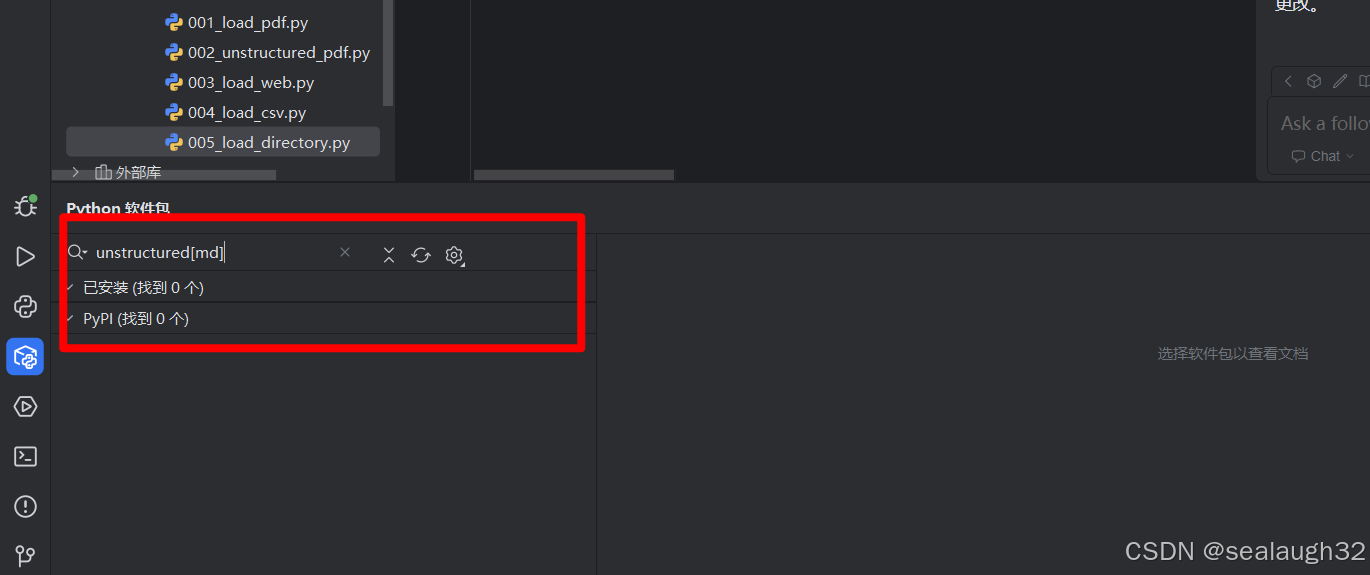
2.3.2 使用git bash进行安装
没有办法,只能进行命令行的pip install "unstructured"。注意,这里的双引号不能省略
- 进入
git bash - 激活
venvcd /d/00_study/07_python/PythonProject source ./venv/Scripts/activate - 检查是
pip还是pip3
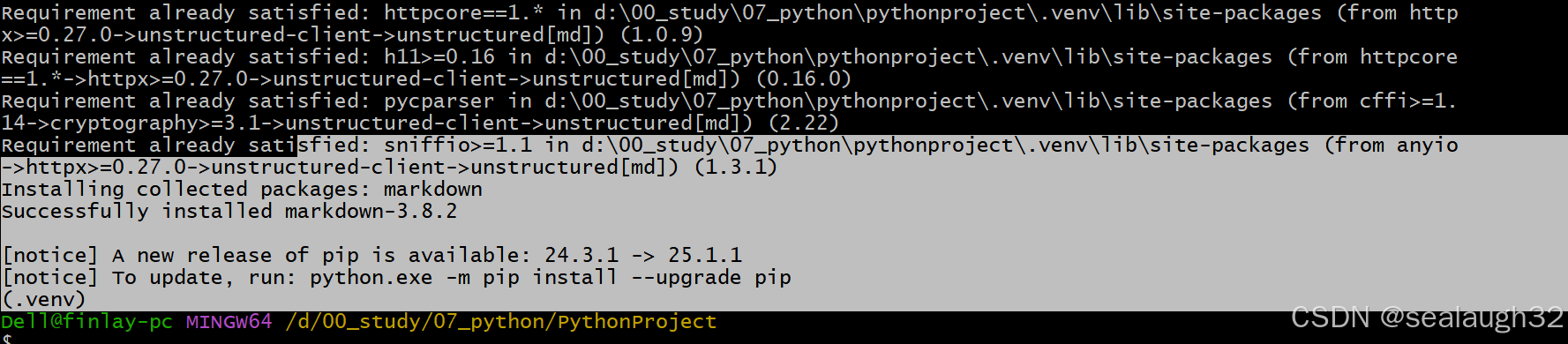
环境不同,有时候需要执行pip install,有时候需要执行pip3,所以需要检查一下。
这里很清楚,如果为虚拟$ where pip C:\Users\Dell\AppData\Local\Microsoft\WindowsApps\pip.exe (.venv) Dell@finlay-pc MINGW64 /d/00_study/07_python/PythonProject$ where pip3 D:\00_study\07_python\PythonProject\.venv\Scripts\pip3.exe C:\Users\Dell\AppData\Local\Microsoft\WindowsApps\pip3.exe (.venv)python环境venv安装需要的包,那么执行pip3 install - 执行
pip3 install
注意,安装完毕之后,切换到pip3 install "unstructured[md]"pycharm的画面,可以看到pycharm也在加载,自动进行更新
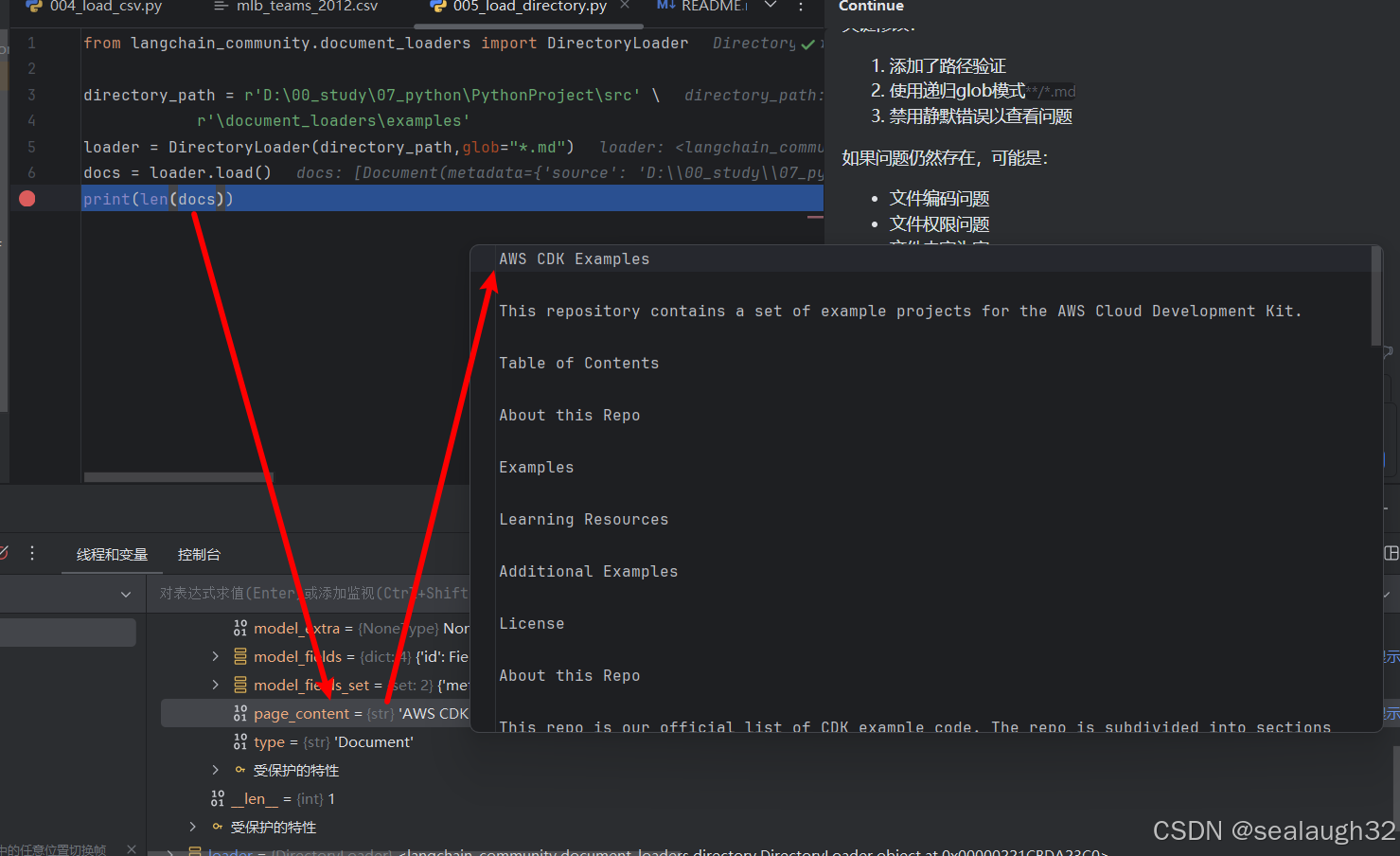
2.4 执行文件夹load的代码
debug模式执行代码,可以看到md文件已经被成功load。
)


)


![git fork的项目远端标准协作流程 仓库设置[设置成upstream]](http://pic.xiahunao.cn/git fork的项目远端标准协作流程 仓库设置[设置成upstream])
![[FFmpeg] 输入输出访问 | 管道系统 | AVIOContext 与 URLProtocol | 门面模式](http://pic.xiahunao.cn/[FFmpeg] 输入输出访问 | 管道系统 | AVIOContext 与 URLProtocol | 门面模式)




)






