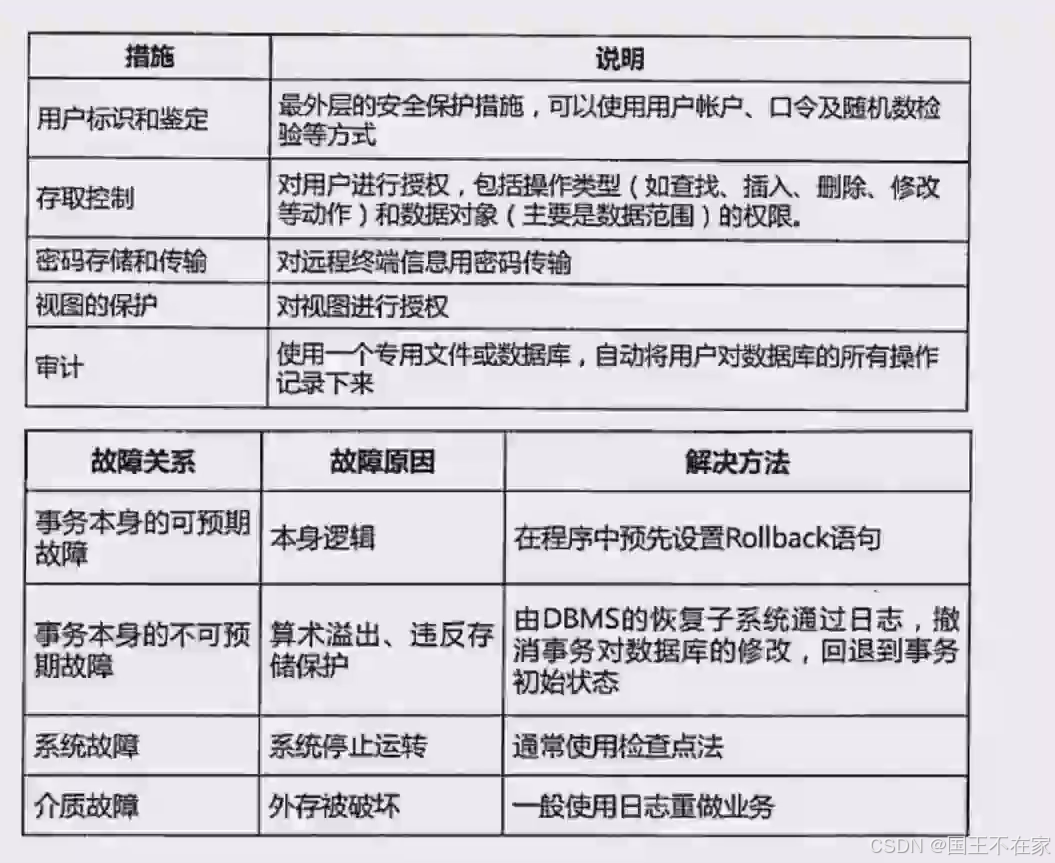
一、数据库的安全
数据库里面的安全措施:
- 用户标识和鉴定:用户的账户口令等
- 存取控制:对用户操作进行控权,有对应权限码才能操作。
- 密码存储和传输:加密存储。
- 视图的保护:视图需要授权
- 审计:专门的文件或者数据库记录所有操作记录。
数据库里面的故障:看下图
数据库备份
数据库备份的形式如下:
1、冷备份(静态转储):转储期间不能对数据库进行任何操作,优点是快速备份,容易存档(直接物理复制)
2、热备份(动态转储):转储期间允许对数据库进行存取、修改操作。此时转储和用户事务是并发执行。
优点是表空间或者数据库文件级别备份,数据库仍然可以使用,可达到秒级恢复;
缺点:不能出错
3、完全备份:备份所有数据
4、差量备份:仅备份上一次完全备份之后变化的数据
5、增量备份:备份上一次备份之后变化的数据。(不管上一次是什么备份 )
6、日志文件:事务每一次对数据库的操作写入日志文件,发生故障,利用日志文件撤销事务对数据库的改变,回退到四五的初始状态。

数据故障恢复
数据库故障恢复的技术:
- 事务故障的恢复:由系统自动完成,对用户是透明的(不需要DBA的参与)。步骤就是把更新操作全部还原回去,直到事务的开始标记。
- 系统故障的恢复:系统重新启动时自动完成,不需要用户的干预。扫描日志文件,已提交的时候加入重做队列,未完成的事务家务撤销队列。
- 介质故障与病毒破坏的恢复。硬盘坏了,装入最新的数据库副本,已提交的事务进入重做队列,不用管未提交的事务
- 有检查点的恢复技术:检查点记录的内容可包括建立检查点时刻所有正在执行的事务清单,以及这些事务最近一个日志记录的地址。类似ctrl+S。


数据库性能优化
性能优化:
- 硬件升级:涉及处理器、内存、磁盘子系统和网络
- 数据库设计:从逻辑设计和物理设计入手
逻辑设计:常用的计算属性(平均值、最大值)存储到数据库实体中。重新定义实体减少外部数据数据的开支
物理设计:给数据分配合适的存储空间。频繁使用的表分割开,这样可以并行使用。文本和图像存储在单独的物理设备上。 - 索引优化:索引类似目录,索引能提高数据库查询速度,建立索引时应该选用不常更新经常查询的属性作为索引。索引过多会影响到增删改。
- 查询优化:sql语句优化,建立物化视图(已经查好的数据),减少多表查询;只检索需要的属性;用带IN的条件子句等价替换OR;经常commit 释放锁。


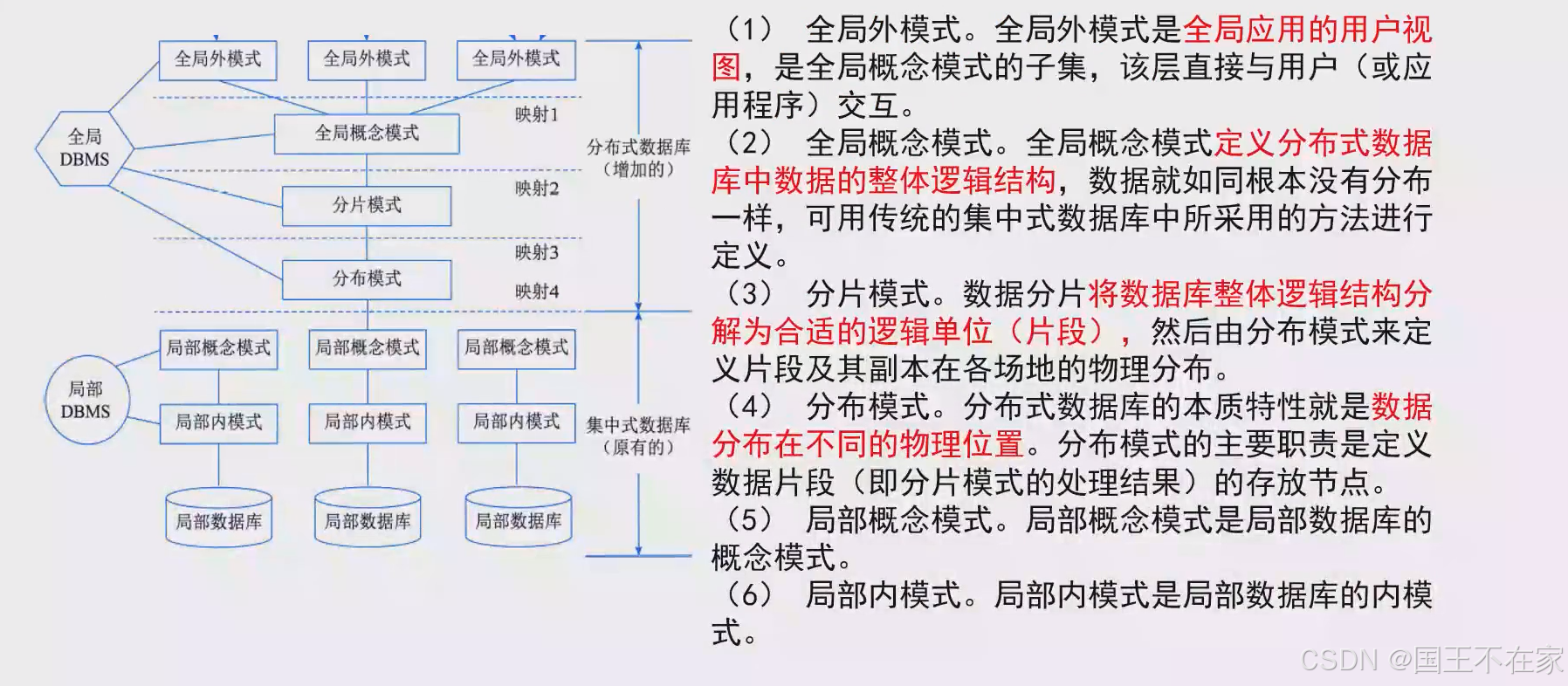
二、分布式数据库
局部数据库位于不用的物理位置,使用一个全局DBMS(数据库管理系统)将所有局部数据库联网管理,这就是分布式数据库
分布式数据库特点
- 数据独立性
- 集中于自治共享结合的控制结构:
- 适当增加数据冗余度
- 全局的一致性、可串行和可恢复性

分布式数据库各个模式
图示:
分片方式

优点
- 解决企业部门分散而数据需要相互联系的问题。
- 灵活增加新的相对自主的部门。
- 灵活组建全局应用下的多数据库系统。
- 故障仅影响局部应用,可靠性更高。

数据仓库
概要
数据仓库是:面相主题的、集成的、非易失的、且随时间变化的数据集合,用于管理决策(大数据决策)。
- 面相主题:用于特定品类大数据。
- 集成的:对分散数据库数据抽取、清理、加工等操作。消除数据的不一致性,保证信息的主题性。
- 相对稳定:长期保留,包含大量的查询操作,只需定义的加载、刷新。
- 反映历史变化:包含历史信息,是各个阶段的信息,通过这些信息进行定量分析与预测。

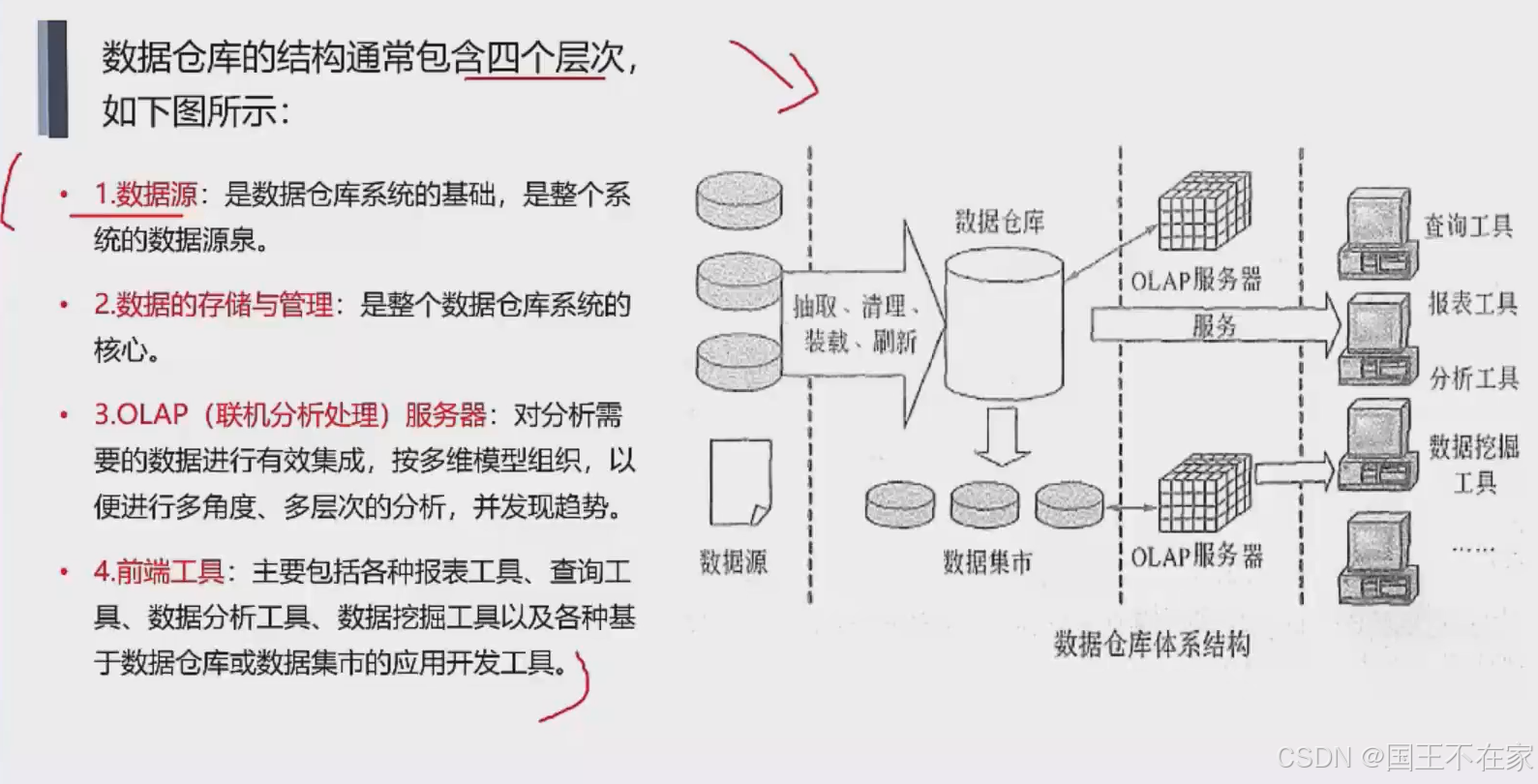
四个层次(重要)
层次
- 数据源:数据仓库的基础,整个系统的数据源泉。
- 数据的存储和管理:数仓的核心。
- OLAP(联机分析处理)服务器:
将原本不可能实时完成的深度分析变为可行——如同用天文望远镜替代肉眼观星 - 前端工具:报表工具等,呈现olap的结果。
商业智能
BI系统的4个阶段:数据预处理、建立数据仓库、数据分析、数据展现。

数据仓库分类
数据仓库的分类:企业仓库、数据集市、虚拟仓库

数据仓库设计方法
数据仓库的设计方法:
- 自顶向下:用于企业级,建立数据仓库后,各个部分再从数据仓库中获取部门所需的数据,形成数据集市。
- 自底向上:从企业中最关键的部门开始,最少投资完成当前需求,最先产生独立数据集市。
- 混合.

数据挖掘
结构
发现非直觉的信息。
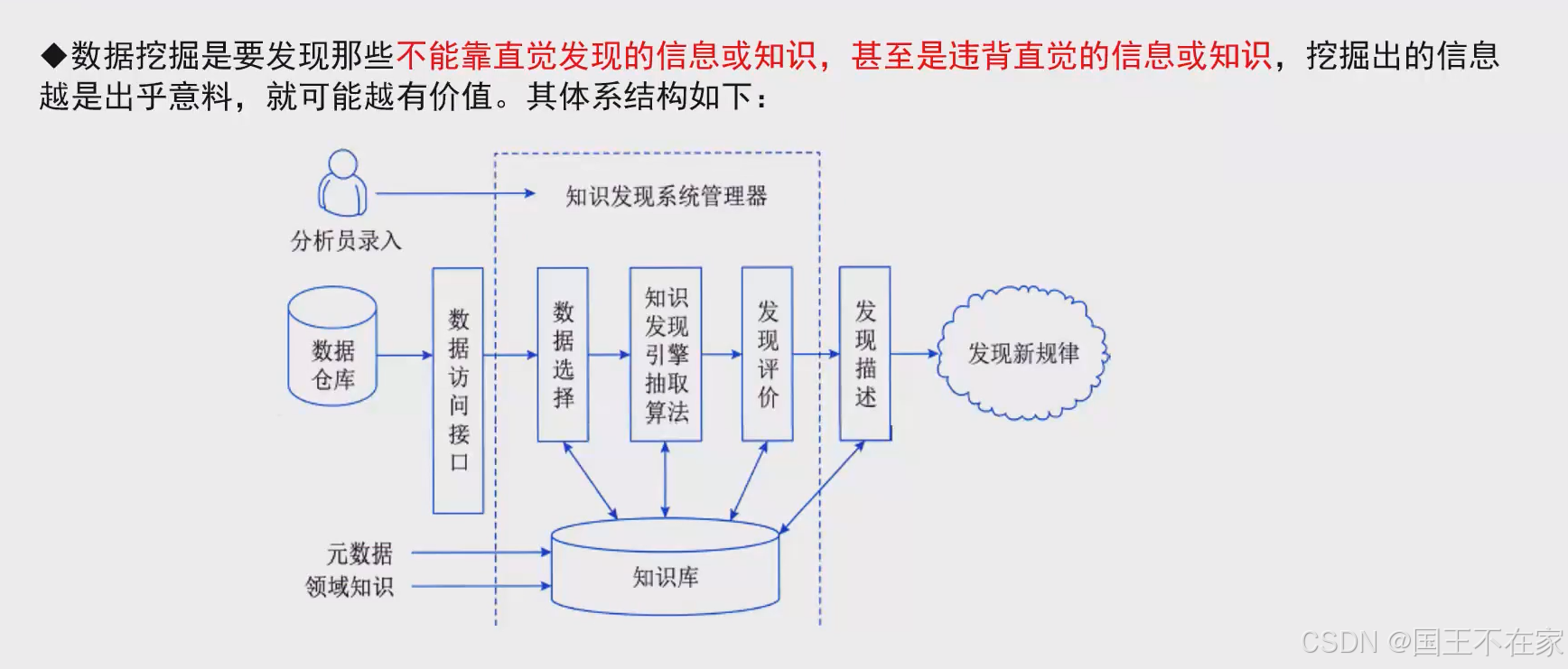

流程

数据挖掘常用技术(记住)
数据挖掘的常用技术
- 决策树:利用信息论中互信息(信息增益)寻找数据库中具有最大信息量的属性,建立决策树的节点,再根据属性的不同取值建立树的分支。
- 分类:按照翻译划分成组
- 粗糙集:基于分类,一种类别对应于一个概念,知识由概念组成。粗糙集通过近似概念表示不精确的概念。
- 神经网络:神经网络通过学习待分析数据中的模式来构建模型。
- 关联规则:搜索业务系统中所有细节和事务,找出重复出现的模式。
- 概念树方法:按归类的方式进行抽象,放大建立起来的层次结构称为概念树。
- 遗传算法:模拟生物进化过程
- 依赖性分析:在数据仓库的条目和对象之间抽取依赖性。
- 公式发现:进行数学运算
- 统计分析方法:找出数据库属性的函数关系和相关关系
- 模糊论:模糊性是客观存在的,系统越复杂,精确度越低,越模糊
- 可视化分析:通过图形化分析数据。


数据挖掘分析方法(了解)
- 关联分析
- 序列分析
- 分类分析:首先为每个记录设置一个标记,然后对这个分类进行分析,有监督。
- 聚类分析:对无标记的记录进行相似性聚合,划分、分析,属于无监督。
- 预测分析
- 时间序列分析


![[NLP]多电源域设计的仿真验证方法](http://pic.xiahunao.cn/[NLP]多电源域设计的仿真验证方法)
的执行方式)
如何使用全文索引?)

)













