GenAttack:利用无梯度优化的实用黑盒攻击
Moustafa Alzantot
UCLA
Los Angeles, U.S.A
malzantot@ucla.edu
Yash Sharma
Cooper Union
New York, U.S.A
sharma2@cooper.edu
Supriyo Chakraborty
IBM Research
New York, U.S.A
supriyo@us.ibm.com
Huan Zhang
UCLA
Los Angeles, U.S.A
huanzhang@ucla.edu
Cho-Jui Hsieh
UCLA
Los Angeles, U.S.A
chohsieh@cs.ucla.edu
Mani B. Srivastava
UCLA
Los Angeles, U.S.A
mbs@ucla.edu
摘要
深度神经网络容易受到对抗样本的攻击,即使在黑盒设置下(攻击者仅被限制为查询访问)也是如此。现有的生成对抗样本的黑盒方法通常需要大量查询,无论是用于训练替代网络还是执行梯度估计。我们提出了 GenAttack,一种利用遗传算法在黑盒设置下合成对抗样本的无梯度优化技术。我们在不同数据集(MNIST、CIFAR-10 和 ImageNet)上的实验表明,GenAttack 能够成功生成视觉上难以察觉的对抗样本,以攻击最先进的图像识别模型,且所需查询量比先前方法少几个数量级。针对 MNIST 和 CIFAR-10 模型,GenAttack 所需的查询量分别比先前最先进的黑盒攻击方法 ZOO 减少了约 2126 倍 和 2568 倍。为了将攻击扩展到大规模高维的 ImageNet 模型,我们进行了一系列优化,进一步提高了攻击的查询效率,使得针对 Inception-v3 模型的查询量比 ZOO 少了 237 倍。此外,我们还展示了 GenAttack 能够成功攻击一些最先进的 ImageNet 防御机制,包括集成对抗训练(ensemble adversarial training)和不可微分或随机化的输入变换(randomized input transformations)。我们的结果表明,进化算法为研究有效的黑盒攻击开辟了一个充满前景的领域。
对抗样本、深度学习、遗传算法、计算机视觉
1. 引言
深度神经网络(DNNs)在机器学习和人工智能的各个任务中已取得最先进的性能。尽管其效果显著,但最近的研究揭示了 DNNs 对对抗样本的脆弱性[11, 29]。例如,对图像施加一个几乎无法察觉的扰动,就能导致训练良好的 DNN 错误分类。有目标的对抗样本甚至能导致模型错误分类到攻击者选定的类别。此外,研究人员已经证明这些对抗样本在物理世界[4, 16]中仍然有效,并且可以在不同的数据模态中生成,例如自然语言[2]和语音[1]领域。DNNs 在对抗样本面前表现出的鲁棒性不足,对安全关键应用引发了严重担忧。
几乎所有先前关于对抗攻击的工作[7, 8, 11, 12, 16, 21]都使用基于梯度的优化来寻找成功的对抗样本。然而,梯度计算只能在攻击者完全了解模型架构和权重的情况下进行。因此,这些方法仅适用于白盒(white-box) 设置,即攻击者拥有对目标 DNN 的完全访问和控制权。然而,在攻击现实世界系统时,需要考虑在黑盒(black-box) 设置下执行对抗攻击的问题,即不透露任何关于网络架构、参数或训练数据的信息。在这种情况下,攻击者只能访问分类器的输入-输出对。在这种设置下,一种流行的方法是攻击训练好的替代网络(substitute networks),并希望生成的样本能迁移(transfer)到目标模型[22]。这种方法受到替代模型与目标模型之间固有的模型失配(model mismatch)以及训练替代网络所需的高计算成本的困扰。最近的工作使用基于坐标的有限差分法(coordinate-based finite difference methods)直接从置信度分数估计梯度[9],但这些攻击在计算上仍然非常昂贵,需要依赖优化技巧才能保持可行性。这两种方法都是查询密集型的,从而限制了它们在现实场景中的实用性。
基于上述动机,我们提出了 GenAttack,一种无需计算甚至无需近似梯度即可生成对抗样本的新方法,使得在黑盒情况下进行高效对抗攻击成为可能。为了执行无梯度优化(gradient-free optimization),我们采用了一种基于种群的遗传算法方法,迭代地进化一组可行解直至成功。我们还提出了一些技巧,使得 GenAttack 在攻击基于大规模高维数据集(如ImageNet[10])训练的模型时,仍能保持其查询效率。
由于其无梯度的特性,GenAttack 对执行梯度掩码(gradient masking)或混淆(obfuscation)的防御具有鲁棒性[3]。因此,与许多当前的黑盒攻击方法不同,GenAttack 可以在黑盒设置中高效地构建扰动,以绕过一些最近提出的操纵梯度的防御方法。
我们使用最先进的图像分类模型评估了 GenAttack,发现该算法能够以比当前方法少得多的查询量成功执行 有目标(targeted) 的黑盒攻击。在我们的 MNIST、CIFAR-10 和 ImageNet 实验中,GenAttack 所需的查询量分别比当前最先进的黑盒攻击方法少约 2126 倍、2568 倍 和 237 倍。此外,我们还展示了 GenAttack 对最先进 ImageNet 防御机制的成功攻击,例如集成对抗训练[30]以及随机化、不可微分的输入变换防御[13]。这些结果说明了 GenAttack 查询效率高和无梯度特性的强大之处。
总而言之,我们的贡献如下:
- 我们提出了 GenAttack,一种利用基于种群的优化(population-based optimization)生成对抗样本的新型无梯度方法。我们的实现已开源¹,以促进对抗鲁棒性研究的进一步发展。
(脚注¹: https://github.com/nesl/adversarial_genattack) - 我们证明,在受限的黑盒设置下,结合遗传优化、降维和自适应参数缩放的 GenAttack,能够生成对抗样本,迫使在 MNIST、CIFAR-10 和 ImageNet 上训练的最先进图像分类模型将样本错误分类到选定的目标标签,且所需的查询量显著少于先前的方法。
- 我们通过展示 GenAttack 对几种最先进 ImageNet 防御机制(即集成对抗训练和随机化、不可微分的输入变换)的成功攻击,进一步强调了其有效性。 据我们所知,我们是第一个展示成功对抗这些防御的黑盒攻击的工作。
本文其余部分组织如下:第 2 节总结了相关工作。第 3 节正式定义了我们攻击的威胁模型。第 4 节讨论 GenAttack 的细节。第 5 节描述了我们的评估实验及其结果。最后,第 6 节总结了论文,并讨论了进化算法在生成对抗样本方面的效用。
2. 相关工作
在下文中,我们总结了最近在生成对抗样本(包括白盒和黑盒情况)以及防御对抗样本方面的方法。更多细节请参阅所引用的工作。
2.1 白盒攻击与可迁移性(Transferability)
在 白盒(white-box) 情况下,攻击者完全了解并拥有对目标 DNN 的完全访问权限。在这种情况下,攻击者能够使用反向传播进行梯度计算,从而实现高效的基于梯度的攻击。我们简要总结以下几种重要的白盒攻击公式。
-
L-BFGS。[29] 使用带盒约束(box-constrained)的 L-BFGS 来最小化添加的对抗噪声的 ℓ2\ell_{2}ℓ2 范数 ∣∣δ∣∣2||\delta||_{2}∣∣δ∣∣2,约束条件为f(x+δ)=lf(x+\delta)=lf(x+δ)=l(预测为类别 lll) 和 x+δ∈[0,1]mx+\delta\in[0,1]^{m}x+δ∈[0,1]m(输入在有效像素范围内)。
其中 f:Rm→{1,...,k}f:\mathbb{R}^{m}\rightarrow\{1,...,k\}f:Rm→{1,...,k} 是分类器,将数据样本映射到离散标签,l∈{1,...,k}l\in\{1,...,k\}l∈{1,...,k} 是目标输出标签,δ\deltaδ 是添加的噪声。 -
FGSM & I-FGSM。[11] 提出了快速梯度符号方法(FGSM)来快速生成对抗样本。在 L∞L_{\infty}L∞ 失真约束 ∥δ∥∞≤ϵ\|\delta\|_{\infty}\leq\epsilon∥δ∥∞≤ϵ 下,FGSM 使用训练损失 JJJ 相对于原始输入 x0\mathbf{x}_{0}x0 和真实标签lll 的梯度的符号来生成对抗样本:x=x0+ϵ⋅sign(∇J(x0,l))\mathbf{x}=\mathbf{x}_{0}+\epsilon\cdot\text{sign}(\nabla J(\mathbf{x}_{0},l))x=x0+ϵ⋅sign(∇J(x0,l))。
类似地,可以通过计算相对于指定目标类别 ttt 的损失,并沿负梯度方向移动来实现有目标攻击。
在[16]中,提出了 FGSM 的迭代版本(I-FGSM),其中 FGSM 在更精细的失真约束下迭代使用,然后进行 ϵ\epsilonϵ-球裁剪(ϵ\epsilonϵ-ball clipping)。在[20]中,引入了投影梯度下降(PGD),对 I-FGSM 进行修改以包含随机起点(random starts)。 -
C&W & EAD。与利用训练损失不同,C&W[7] 设计了一个基于 DNN 中 logit 层表示的 L2L_{2}L2 正则化损失函数来制作对抗样本。通过变量变换处理盒约束 x∈[0,1]p\mathbf{x}\in[0,1]^{p}x∈[0,1]p,他们使用 Adam[15] 来最小化 ϵ⋅f(x,t)+∣∣x−x0∣∣22\epsilon\cdot f(\mathbf{x},t)+||\mathbf{x}-\mathbf{x}_{0}||_{2}^{2}ϵ⋅f(x,t)+∣∣x−x0∣∣22。
其中 f(x,t)f(x,t)f(x,t) 是一个依赖于 logit 层值和目标类别 ttt 的损失函数。EAD[8] 通过最小化额外的 L1L_{1}L1惩罚项推广了该攻击,并已被证明能生成更鲁棒和可迁移的对抗样本[19, 24, 25]。
白盒攻击也可以通过利用可迁移性(transferability)[18] 在黑盒设置中使用。可迁移性指的是使用一个模型生成的对抗样本通常会被另一个模型错误分类的特性[27]。替代模型方法进行黑盒攻击就是利用这一特性来生成成功的对抗样本,我们将在下一小节中讨论。
2.2 黑盒攻击
在文献中, 黑盒(black-box) 攻击设置指的是攻击者可以自由访问目标 DNN 的输入和输出,但无法在网络上执行反向传播的情况。提出的方法依赖于可迁移性和梯度估计,总结如下。
-
替代网络(Substitute Networks)。早期的黑盒攻击方法利用自由查询的能力来训练一个替代模型(substitute model),作为目标 DNN 的代表[22]。然后可以使用任何白盒技术攻击该替代 DNN,并将生成的对抗样本用于攻击目标 DNN。由于替代模型被训练成在分类规则上代表目标 DNN,因此替代模型的对抗样本预期与相应目标 DNN 的对抗样本相似。然而,这种方法依赖于可迁移性属性,而不是直接攻击目标 DNN,这并不完美,从而限制了攻击者的强度。此外,训练替代模型在计算上非常昂贵,在攻击大型模型(如 Inception-v3[28])时几乎不可行。
-
零阶优化(Zeroth Order Optimization, ZOO)。零阶优化(ZOO)攻击建立在 C&W 攻击的基础上执行黑盒攻击[9],通过修改损失函数使其仅依赖于 DNN 的输出,并使用通过有限差分获得的梯度估计进行优化。然而,ZOO 需要巨大的查询量,因为每个坐标的梯度估计需要 222 次查询。因此,在 ImageNet 数据集上攻击 Inception-v3[28] 需要 299×299×3×2=536,406299\times 299\times 3\times 2=536,406299×299×3×2=536,406 次查询(每个优化步骤)。为了解决这个问题,使用了随机坐标下降(SCD),每个步骤只需要 222 次查询。尽管如此,当坐标数量很大时,SCD 的收敛可能很慢,因此降低扰动的维度和使用重要性采样也至关重要。应用这些技术后,与替代模型方法不同,攻击 Inception-v3 在计算上变得可行。然而,正如我们在实验中所展示的,梯度估计过程仍然相当查询低效,因此对于攻击现实世界系统来说不切实际。
在并行的工作中,[6, 14, 31] 也研究了黑盒对抗攻击的效率和强度问题,但我们的工作在目标和方法上仍然是独特的。[6] 侧重于攻击仅能部分访问查询结果的黑盒模型。值得注意的是,他们的方法在攻击未防御的 ImageNet 模型时,平均需要的查询量大约是我们的 72 倍。[14] 和 [31] 研究了与我们考虑的相同威胁模型下黑盒攻击的效率,然而,两者都依赖于梯度估计(gradient estimation),而不是无梯度优化(gradient-free optimization)。[14] 估计参数化搜索分布下损失期望值的梯度,这可以看作是在随机高斯基上的有限差分估计。[31] 则摒弃了 ZOO 的逐坐标估计,采用了缩放的随机全梯度估计器(scaled random full gradient estimator)。尽管我们将这两项工作视为并行工作,但为了完整性,我们在结果中提供了我们的“无梯度”方法与其他查询高效的“梯度估计”方法之间的比较。
2.3 防御对抗攻击
-
对抗训练(Adversarial Training)。对抗训练通常通过使用标签修正后的对抗样本增强原始训练数据集来重新训练网络来实现。在[20]中,一个高容量网络被训练来对抗 L∞L_{\infty}L∞ 约束的 PGD(带随机起点的 I-FGSM),在 L∞L_{\infty}L∞ 球内获得了强大的鲁棒性,但已被证明对基于其他鲁棒性指标优化的攻击鲁棒性较低[23, 24, 32]。在[30]中,训练数据通过从其他模型迁移过来的扰动进行增强,并被证明对迁移的对抗样本具有强大的鲁棒性。我们在实验结果中证明,它对查询高效的黑盒攻击(如 GenAttack)的鲁棒性较低。
-
梯度混淆(Gradient Obfuscation)。已经发现,许多最近提出的防御通过操纵梯度(使其不存在或不正确、依赖于测试时的随机性,或根本无法使用)来提供对强对抗攻击的表观鲁棒性。具体来说,在分析 ICLR 2018 声称具有白盒鲁棒性的未认证防御时,发现 9 个中有 7 个依赖于这种现象[3]。研究还表明,基于 FGSM 的对抗训练通过使梯度指向错误的方向来学习成功[30]。
一种依赖梯度混淆的防御是利用不可微分的输入变换(non-differentiable input transformations),例如位深度缩减(bit-depth reduction)、JPEG 压缩和总方差最小化(total variance minimization)[13]。在**白盒(white-box)情况下,这种防御可以通过在反向传播过程中用恒等函数替换不可微分的变换,成功地被基于梯度的技术攻击[3]。虽然有效,但这种方法不适用于黑盒(black-box)情况,因为攻击者需要了解不可微分组件的信息。我们在实验结果中证明,GenAttack 由于是无梯度的,因此不受所述梯度操纵的影响,可以自然地在黑盒(black-box)**情况下处理此类过程。请注意,许多需要梯度估计的黑盒攻击(包括[9, 14, 31])在存在不可微分输入变换时无法直接应用。
3. 威胁模型
我们考虑以下攻击场景。攻击者不了解网络架构、参数或训练数据。攻击者只能将目标模型作为黑盒函数进行查询:
f:Rd→[0,1]Kf:\mathbb{R}^{d}\rightarrow[0,1]^{K}f:Rd→[0,1]K
其中 ddd 是输入特征的数量,KKK 是类别数量。函数 fff 的输出是模型预测分数的集合。请注意,攻击者无法访问在网络隐藏层(包括 logits)中计算的中间值。
攻击者的目标是执行 有目标(targeted) 攻击。正式地说,给定一个被模型正确分类的良性输入样本 x\mathbf{x}x,攻击者试图找到一个扰动样本xadv\mathbf{x}_{adv}xadv,使得网络将产生攻击者从标签集 {1..K}\{1..K\}{1..K} 中选择的期望目标预测ttt。此外,攻击者还试图最小化 LpL_{p}Lp距离,以保持 xorig\mathbf{x}_{orig}xorig 和xadv\mathbf{x}_{adv}xadv 之间的感知相似性。即:
arg maxc∈{1..K}f(xadv)c=t满足 ∣∣x−xadv∣∣p≤δ\operatorname*{arg\,max}_{c\in\{1..K\}}f(\mathbf{x}_{adv})_{c}=t\quad\text{满足 }||\mathbf{x}-\mathbf{x}_{adv}||_{p}\leq\deltac∈{1..K}argmaxf(xadv)c=t满足 ∣∣x−xadv∣∣p≤δ
其中距离范数函数 LpL_{p}Lp 通常选择为 L2L_{2}L2 或 L∞L_{\infty}L∞。
此威胁模型等同于先前黑盒攻击工作[9, 22]中的模型,类似于密码学中的选择明文攻击(CPA),即攻击者向受害者提供任何选定的明文消息并观察其加密密码输出。
4. GenAttack 算法
GenAttack 依赖于遗传算法(genetic algorithms),这是一种基于种群的无梯度优化策略。遗传算法受自然选择过程的启发,迭代地进化候选解的种群 P\mathcal{P}P 以趋向更好的解。每次迭代中的种群称为一代(generation)。在每一代中,使用**适应度(fitness)函数评估种群成员的质量。“适应度更高”的解更有可能被选择用于繁殖下一代。下一代通过交叉(crossover)和变异(mutation)的组合产生。交叉是取多个父代解并从中产生子代解的过程;它类似于生物繁殖和交叉。变异根据用户定义的小概率变异概率(mutation probability)**对种群成员施加小的随机扰动。
这样做是为了增加种群成员的多样性,并更好地探索搜索空间。
算法 1 描述了 GenAttack 的操作。算法输入是原始样本 xorig\mathbf{x}_{orig}xorig 和攻击者选择的目标分类标签 ttt。算法计算一个对抗样本 xadv\mathbf{x}_{adv}xadv,使得模型将 xadv\mathbf{x}_{adv}xadv 分类为 ttt 且 ∣∣xorig−xadv∣∣∞≤δmax||\mathbf{x}_{orig}-\mathbf{x}_{adv}||_{\infty}\leq\delta_{max}∣∣xorig−xadv∣∣∞≤δmax。我们定义种群大小为 NNN,“变异概率” 为ρ\rhoρ, “变异范围” 为 α\alphaα。
GenAttack 通过在原始样本 xorig\mathbf{x}_{orig}xorig 为中心的球体(半径 =δmax=\delta_{max}=δmax)上定义的均匀分布中随机选取样本来初始化围绕给定输入样本 xorig\mathbf{x}_{orig}xorig 的种群。这是通过向输入向量 xorig\mathbf{x}_{orig}xorig 的每个维度添加范围在(−δmax,δmax-\delta_{max},\delta_{max}−δmax,δmax) 内的随机噪声来实现的。然后,重复以下步骤直到找到成功的样本:评估每个种群成员的适应度,选择父代,执行交叉和变异以形成下一代。
-
适应度函数(Fitness function):子程序
ComputeFitness评估每个种群成员的适应度(即质量)。由于适应度函数应反映优化目标,一个合理的选择是直接使用分配给目标类别标签的输出分数。然而,我们发现同时激励其他类别概率的降低会更有效。我们还发现使用对数(log)有助于避免数值不稳定性问题。因此,我们选择以下函数:
ComputeFitness(x)=logf(x)t−log∑j=0,j≠tj=kf(x)cComputeFitness(\mathbf{x})=\log f(\mathbf{x})_{t}-\log \sum_{j=0,j\neq t}^{j=k}f(\mathbf{x})_{c}ComputeFitness(x)=logf(x)t−logj=0,j=t∑j=kf(x)c -
选择(Selection):每次迭代中的种群成员根据其适应度值进行排序。适应度较高的成员更有可能成为下一代的一部分,而适应度较低的成员更有可能被替换。我们通过计算适应度值的 Softmax 将其转换为概率分布,从而计算每个种群成员的选择概率。然后,我们根据该分布独立地在种群成员中随机选择父代对。我们还发现应用 精英保留(elitism) 技术[5]很重要,即当前代的 精英(elite) 成员(适应度最高的成员)保证成为下一代的一员。
-
交叉操作(Crossover operation):选择后,父代进行交配以产生下一代成员。子代通过根据选择概率 ((p,1-p)) 从 parent1parent_{1}parent1 或parent2parent_{2}parent2 中选择每个特征值来生成,其中 ppp 定义为:
p=fitness(parent_1)fitness(parent_1)+fitness(parent_2)p=\frac{fitness(parent\_1)}{fitness(parent\_1)+fitness(parent\_2)}p=fitness(parent_1)+fitness(parent_2)fitness(parent_1) -
变异操作(Mutation operation):为了促进种群成员之间的多样性和对搜索空间的探索,在每次迭代结束时,种群成员可以根据概率 ρ\rhoρ 进行变异。将从范围(−αδmax,αδmax-\alpha\,\delta_{\max},\alpha\,\delta_{\max}−αδmax,αδmax) 均匀采样的随机噪声应用于交叉操作结果的各个特征。最后,执行裁剪算子 Πδmax\Pi_{\delta_{max}}Πδmax 以确保像素值在距离良性样本xorig\mathbf{x}_{orig}xorig 允许的 L∞L_{\infty}L∞ 距离范围内。
4.1 提高查询效率
在本节中,我们介绍了在 GenAttack 算法中采用的几个优化措施,这些措施显著提高了查询效率。
4.1.1 降维(Dimensionality Reduction)
一方面,扩展遗传算法以高效探索高维搜索空间(如 ImageNet 模型)需要在每一代使用较大的种群规模。另一方面,评估每个成员的适应度意味着以新查询的形式增加成本。因此,我们将 GenAttack 限制为使用相对较小的(例如,小于 10)种群规模。我们在第 5.3 节中提供了关于种群规模与查询次数之间权衡的更多讨论。
此外,受[31]工作的启发,我们试图通过执行搜索空间的降维并在低维空间中定义对抗噪声来解决扩展遗传算法(进而扩展 GenAttack)的挑战。为了计算对抗样本,我们应用双线性调整大小(bilinear resizing)(这是
确定性的),将噪声缩放到与输入相同的大小。因此,
xorig∈[0,1]d,eadv∈[0,1]d′,xadv=S(eadv)+xorig\mathbf{x}_{orig}\in[0,1]^{d},\quad e_{adv}\in[0,1]^{d^{\prime}},\quad\mathbf{x}_{adv}=S(e_{adv})+\mathbf{x}_{orig}xorig∈[0,1]d,eadv∈[0,1]d′,xadv=S(eadv)+xorig
其中 eadve_{adv}eadv 是学习到的对抗噪声,SSS 是双线性调整大小操作,d′d^{\prime}d′ 的选择使得 d′<dd^{\prime}<dd′<d。实际上,这导致了一个压缩的对抗噪声向量,其中 eadve_{adv}eadv 的一个值用于扰动 xorig\mathbf{x}_{orig}xorig 的多个相邻像素以产生xadv\mathbf{x}_{adv}xadv。我们注意到,这种方法显著提高了 GenAttack 针对高维模型(如 ImageNet 模型)的查询效率,同时在 L∞L_{\infty}L∞ 约束下保持了攻击成功率。
4.1.2 自适应参数缩放(Adaptive Parameter Scaling)
为了减轻遗传算法对超参数值(例如变异率、种群大小、变异范围)的敏感性,我们使用了一种退火方案(annealing scheme):如果检测到搜索算法在连续多次迭代中停滞而没有进一步改善目标函数,则逐渐减小算法参数(即变异率 ρ\rhoρ 和变异范围 α\alphaα)。自适应缩放缓解了这种情况:过高的变异率可能允许目标函数值初始快速下降,之后算法可能陷入停滞而无法取得进一步进展。
我们采用指数衰减来更新参数值:
ρ=max(ρmin,0.5×(0.9)num_plateaus)(1)\rho =\max(\rho_{\min},0.5\times(0.9)^{\text{num\_plateaus}}) \quad (1)ρ=max(ρmin,0.5×(0.9)num_plateaus)(1)
α=max(αmin,0.4×(0.9)num_plateaus)(2)\alpha =\max(\alpha_{\min},0.4\times(0.9)^{\text{num\_plateaus}}) \quad (2)α=max(αmin,0.4×(0.9)num_plateaus)(2)
其中 ρmin\rho_{\min}ρmin 和 αmin\alpha_{\min}αmin 分别选择为 0.1 和 0.15,num_plateaus 是一个计数器,每当算法连续 100 步未能改善种群精英成员(最高适应度)的适应度时递增。

5. 结果
我们通过攻击最先进的 MNIST、CIFAR-10 和 ImageNet 图像分类模型来评估 GenAttack。对于每个数据集,我们使用与 ZOO 工作[9]中相同的模型。对于 MNIST 和 CIFAR-10,模型准确率分别为 99.5% 和 80%。读者可以参考[7]了解这些模型架构的更多细节。对于 ImageNet,我们使用 Inception-v3[28],其 top-5 准确率为 94.4%,top-1 准确率为 78.8%。我们比较了 GenAttack 与 ZOO 在这些模型上的有效性,比较指标包括攻击成功率(ASR)、运行时间以及成功所需的中位数查询次数。运行时间和查询计数统计仅基于成功的攻击计算。一次查询意味着对单个输入图像评估一次目标模型输出。使用作者的代码²,我们根据作者用于生成实验结果[9]的实现为每个数据集配置 ZOO。我们还评估了最先进的白盒 C&W 攻击[7],假设直接访问模型,以提供攻击成功率的参考。
(脚注²: https://github.com/huanzhang12/ZOO-Attack)
此外,我们使用作者在以下链接³发布的模型评估了 GenAttack 对集成对抗训练[30]的有效性。集成对抗训练被认为是针对黑盒攻击的最先进 ImageNet 防御方法,被证明在托管竞赛中能有效提供对迁移攻击的鲁棒性[17, 26, 30]。最后,我们评估了最近提出的随机化、不可微分的输入变换防御[13],以测试 GenAttack 对梯度混淆的性能。我们发现,由于其无梯度的特性,GenAttack 可以原样处理此类防御。
(脚注³: 原文链接缺失,此处保留占位符)

图 1: GenAttack 生成的 MNIST 对抗样本。行标签是真实标签,列标签是目标标签。

图 2: GenAttack 生成的 CIFAR-10 对抗样本。行标签是真实标签,列标签是目标标签。
超参数(Hyperparameters)。 对于我们所有的 MNIST 和 CIFAR-10 实验,我们将 GenAttack 的最大查询次数限制为 100,000 次,并将超参数固定为以下值:变异概率 ρ=5e−2\rho=5\texttt{e}-2ρ=5e−2(0.05),种群大小 N=6N=6N=6,步长 α=1.0\alpha=1.0α=1.0。对于我们所有的 ImageNet 实验,由于图像尺寸几乎是 CIFAR-10 的 100 倍,我们使用最大 1,000,000 次查询,并根据第 4 节前面的讨论自适应更新 ρ\rhoρ 和 α\alphaα 参数。此外,我们实验了带降维和不带降维的情况(d′=96d^{\prime}=96d′=96)。为了匹配 ZOO 成功样本计算的平均 L∞L_{\infty}L∞ 失真,我们分别为 MNIST、CIFAR-10 和 ImageNet 实验设置 δmax={0.3,0.05,0.05}\delta_{max}=\{0.3,0.05,0.05\}δmax={0.3,0.05,0.05}。由于遗传算法有各种调整参数,我们在第 5.3 节进行了参数敏感性研究。
5.1 查询量比较
我们通过成功所需的查询次数比较 GenAttack 和 ZOO,并提供 C&W 白盒结果以全面看待攻击成功率(ASR)。对于 MNIST、CIFAR-10 和 ImageNet,我们分别从测试集中随机选择 1000、1000 和 100 个正确分类的图像。对于每个图像,我们选择一个随机的目标标签。
5.1.1 MNIST 和 CIFAR-10
表 1 显示了我们实验的结果。结果表明,ZOO 和 GenAttack 都可以在 MNIST 和 CIFAR-10 数据集上成功,但 GenAttack 的效率在各自数据集上分别高出 2126 倍 和 2568 倍。随机选择的一组 MNIST 和 CIFAR-10 测试图像及其针对其他标签生成的对抗样本分别显示在图 1 和图 2 中。
- ImageNet:表 2 显示了我们对正常训练的 (InceptionV3) 和集成对抗训练的 (Ens4AdvInceptionV3) ImageNet 模型的实验结果。为了展示降维和自适应参数缩放的效果,我们将没有这些技巧的 GenAttack 表示为 “GA baseline”。在 ImageNet 上,ZOO 在有目标攻击中无法持续成功,这很重要,因为它表明 GenAttack 足够高效,可以有效地扩展到 ImageNet。此外,GenAttack 的查询效率比 ZOO 高出约 237 倍,比 GA baseline 高出 9 倍。针对 Inception-v3 测试图像及其相关对抗样本的一个随机示例如图 3所示。
5.1.2 与并行工作的查询高效攻击比较
在准备本稿件时,我们注意到一些并行工作也被开发出来以解决查询高效的对抗攻击问题。为了完整性,我们也展示了我们的方法与其他贡献的比较。与执行无梯度优化的 GenAttack 不同,[31] 和 [14] 提出了比 ZOO 更高效的梯度估计程序。表 3 显示了三种方法结果的比较。我们注意到,虽然这三种方法都比之前最先进的方法(ZOO)查询效率显著提高,但在相同的 L∞L_{\infty}L∞ 距离约束下,GenAttack 比 [14] 的工作少需要 25% 的查询,代价是 L2L_{2}L2 距离略有增加,这主要是由于使用了降维。此外,即使 [31] 在 L∞L_{\infty}L∞ 和 L2L_{2}L2 失真上都更高,GenAttack 所需的查询量也比 [31] 少 15%。值得注意的是,[31] 有额外的后处理步骤来减少失真量,但这显著增加了查询成本。因此,我们报告了所有攻击在首次成功时的查询次数和失真距离。
5.2 攻击防御机制
在接下来的部分,我们展示 GenAttack 如何成功突破一组旨在提高模型对抗攻击鲁棒性的最先进防御方法。
5.2.1 攻击集成对抗训练(Ensemble Adversarial Training)
集成对抗训练将其他已训练模型上生成的对抗输入纳入模型的训练数据中,以提高其对对抗样本的鲁棒性[30]。这已被证明是在 NIPS 2017 竞赛期间提供对基于迁移的黑盒攻击鲁棒性的最有效方法。
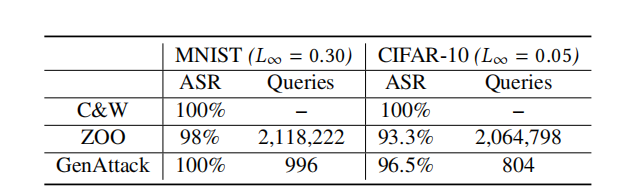
表 1: C&W(白盒)攻击、ZOO 和 GenAttack 在等效 L∞L_{\infty}L∞失真下的攻击成功率(ASR)和中位数查询次数。查询次数的中位数基于成功样本计算。白盒攻击不关心查询次数。
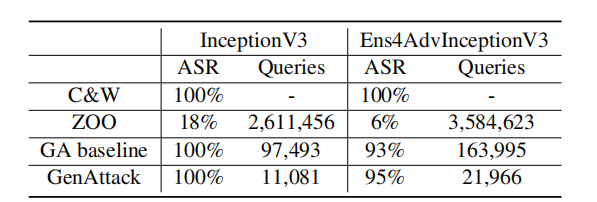
表 2: C&W(白盒)攻击、ZOO 和 GenAttack 在等效 L∞L_{\infty}L∞ 失真 (0.05) 下的攻击成功率(ASR)和中位数查询次数。查询次数的中位数基于成功样本计算。GA baseline 是不使用降维和自适应参数缩放技巧的 GenAttack。
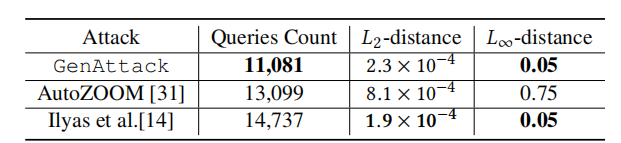
表 3: 与并行工作对抗 ImageNet Inception V3 模型的比较,包括查询次数的中位数以及原始图像与对抗图像之间的每像素 L2L_{2}L2 和 L∞L_{\infty}L∞ 距离。
我们证明该防御对查询高效的黑盒攻击(如 GenAttack)的鲁棒性要低得多。
我们进行了一项实验来评估 GenAttack 对作者[30]发布的集成对抗训练模型(即 Ens4AdvInceptionV3)的有效性。我们使用了之前 ImageNet 实验中相同的 100 个随机采样的测试图像和目标。我们发现 GenAttack 能够对这个防御强大的模型实现 95% 的成功率,显著优于 ZOO。如表 2 所示,我们比较了集成对抗训练模型和原始 Inception-v3 模型之间的成功率和查询次数的中位数。我们的比较表明,这些积极的结果仅以查询量有限的增加为代价。我们还注意到,在 NIPS 2017 竞赛中用于评估的最大 L∞L_{\infty}L∞ 失真范围在 4 到 16 之间(在 0-255 尺度上),归一化后分别等于 0.02 和 0.06。我们的 δmax\delta_{max}δmax (0.05) 落在此范围内。
5.2.2 攻击不可微分、随机化的输入变换(Non-Differentiable, Randomized Input Transformations)
不可微分的输入变换执行梯度混淆,依赖于操纵梯度来成功对抗基于梯度的攻击者[3]。此外,随机化的变换增加了攻击者保证成功的难度。可以通过修改执行梯度混淆的核心防御模块来规避此类方法,但这显然不适用于黑盒情况。
在[13]中,探索了几种输入变换,包括位深度缩减、JPEG 压缩和总方差最小化(TVM)。位深度缩减和 JPEG 压缩是不可微分的,而 TVM 引入了额外的随机化并且速度相当慢,使得难以迭代。我们证明,由于其无梯度(gradient-free)和多模态(multi-modal)的基于种群特性,GenAttack 可以在黑盒情况下成功对抗这些输入变换,使其不受梯度混淆的影响。据我们所知,我们是第一个展示能够绕过此类防御的黑盒算法的工作。我们的结果总结在表 4 中。
对于位深度缩减,减少了 3 位;对于 JPEG 压缩,质量级别设置为 75,如[13]中所述。GenAttack 能够在 CIFAR-10 和 ImageNet 数据集上对这两种不可微分变换都实现高成功率。我们针对 JPEG 压缩防御的结果的视觉示例如图 4 所示。
总方差最小化(TVM)带来了额外的挑战,因为它不仅不可微分,还引入了随机化,并且是一个非常缓慢的过程。TVM 随机丢弃原始图像中的许多像素(丢弃率为 50%,如[13]),并通过解决去噪优化问题从剩余像素重建输入图像。由于随机化,分类器对同一输入在每次运行中返回不同的分数,从而迷惑攻击者。要成功对抗随机化需要更多迭代,但由于 TVM 处理速度慢,在该防御上进行迭代很困难。
在存在随机化的设置中,ComputeFitness 函数可以推广为:
ComputeFitness(x)=Er[logf(x,r)t−logmaxc≠tf(x,r)c]ComputeFitness(x)=\mathbb{E}_{r}\left[\log f(\mathbf{x},r)_{t}-\log \max_{c\neq t}f(\mathbf{x},r)_{c}\right]ComputeFitness(x)=Er[logf(x,r)t−logc=tmaxf(x,r)c]
其中 f(x,r)f(\mathbf{x},r)f(x,r) 是带随机化防御的模型查询函数,rrr 是 TVM 函数的噪声输入,GenAttack 仍然可以在黑盒情况下处理这种防御。期望值是通过为每个种群成员查询模型 ttt 次(我们使用 t=32t=32t=32)来计算的,以在增加查询数量的代价下获得鲁棒的适应度分数。由于对每个查询应用 TVM 的计算复杂性,我们仅使用 CIFAR-10 数据集进行了 TVM 实验,并在 L∞=0.15L_{\infty}=0.15L∞=0.15 下实现了 70% 的成功率。由于 TVM 引入了较大的随机化,我们仅当对抗样本连续三次被分类为目标标签时才将其计为成功。值得注意的是,除非模型使用变换后的样本重新训练[13],否则 TVM 会显著降低模型在干净输入上的准确率(例如,在我们的 CIFAR-10实验中,准确率从 80% 下降到 40%)。
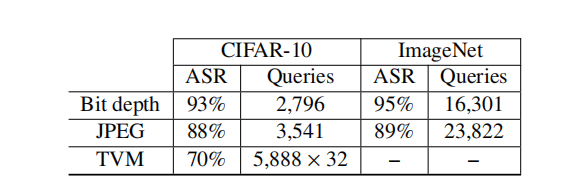
表 4: GenAttack 对不可微分和随机化输入变换防御的评估。我们使用 L∞=0.05L_{\infty}=0.05L∞=0.05 进行位深度实验,使用 L∞=0.15L_{\infty}=0.15L∞=0.15 进行 JPEG 和 TVM 实验。对于 TVM,我们通过进行 t=32t=32t=32 次查询来计算适应度函数的期望值。

图 3: GenAttack 针对 InceptionV3 模型 (L∞=0.05L_{\infty}=0.05L∞=0.05) 生成的对抗样本。左图:原始图像,右图:对抗样本。

图 4: GenAttack 针对 JPEG 压缩防御 (L∞=0.15L_{\infty}=0.15L∞=0.15) 生成的对抗样本。左图:原始图像,右图:对抗样本。
- 与 ZOO 和 C&W 的比较:由于输入变换的不可微分性质,基于梯度的攻击(如 C&W)在不操纵不可微分组件的情况下无法成功,如[3]所讨论。在**白盒(white-box)情况下,可以应用这种方法实现高成功率,但在更受限的黑盒(black-box)**情况下不适用。在黑盒设置中,ZOO 针对 ImageNet 上的不可微分位深度缩减和 JPEG 压缩防御仅实现了 8% 和 0% 的成功率,再次证明了其实用性不足。
5.3 超参数值选择
由于遗传算法传统上对超参数值的选择(例如种群大小、变异率等)敏感,我们在查询效率的背景下讨论了这种影响,这导致了我们在第 5 节列出的超参数值的选择。
- 种群大小(Population size):较大的种群大小允许增加种群多样性,从而在更少的迭代次数内改进对搜索空间的探索。然而,由于评估每个种群成员的成本是一次查询,在选择大种群大小以加速算法成功(就迭代次数而言)与花费的总查询次数之间存在权衡。图 5 展示了这种权衡。在一组 20 张图像上,我们记录了在不同种群大小选择下成功所需的平均查询次数以及迭代次数。从这个实验中,我们得出结论,相对较小的种群大小(6)是平衡收敛速度和查询次数的一个合理选择。
- 变异率(Mutation rate):对于变异率 ρ\rhoρ,我们发现如果使用根据第 4 节公式 (1) 和 (2) 逐渐衰减的自适应变异率,可以获得最佳结果。如图 6 所示,该方法优于固定值的变异率。实际上,自适应变异率通过在初始阶段鼓励探索,然后在算法接近最优解收敛时逐渐增加利用(exploitation)率,从而在探索(exploration)和利用(exploitation)之间取得平衡。
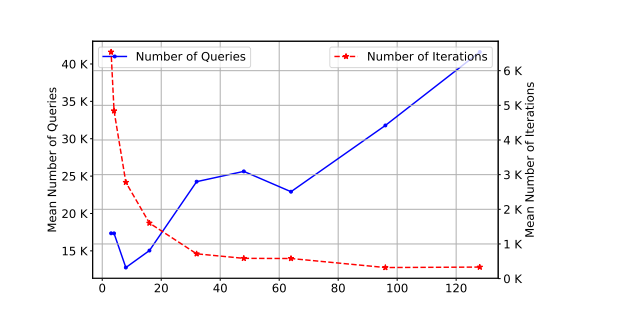
图 5: 种群大小选择对收敛速度和查询次数的影响。
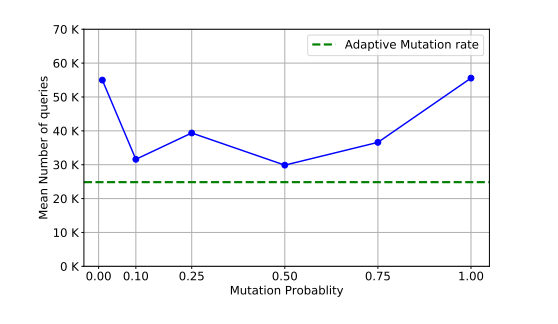
图 6: 变异概率对成功所需查询次数的影响。
6. 结论
GenAttack 是一种强大且高效的黑盒攻击方法,它通过采用基于种群的遗传算法,实现了无梯度优化方案。我们通过攻击训练良好的 MNIST、CIFAR-10 和 ImageNet 模型来评估 GenAttack,发现 GenAttack 能够以比先前最先进方法显著更少的查询量成功地对这些模型执行有目标的黑盒攻击,并且能够在 ImageNet 上实现高成功率(这是先前方法无法扩展到的)。此外,我们证明 GenAttack 可以成功地攻击集成对抗训练(最先进的 ImageNet 防御),且查询量的增加有限。最后,我们表明,由于其无梯度的特性,GenAttack 可以成功对抗梯度混淆,具体通过评估其对不可微分输入变换的有效性来证明,并且甚至可以通过将适应度函数推广为计算变换的期望来成功对抗随机化的防御。据我们所知,这是首次展示能够成功对抗这些最先进防御的黑盒攻击。我们的结果表明,基于种群的优化为研究有效的无梯度黑盒攻击开辟了一个有前景的研究方向。
致谢
本研究部分由美国陆军研究实验室(U.S. Army Research Laboratory)和英国国防部(UK Ministry of Defence)在协议号 W911NF-16-3-0001 下支持,由美国国家科学基金会(National Science Foundation)在奖项 # CNS-1705135、IIS-1719097 和 OAC-1640813 下支持,以及由美国国立卫生研究院移动传感器数据到知识中心(NIH Center of Excellence for Mobile Sensor Data-to-Knowledge, MD2K)在奖项 1-U54EB020404-01 下支持。本材料中的任何发现均为作者的观点,并不反映上述任何资助机构的观点。尽管此处有版权标记,美国和英国政府仍被授权为政府目的复制和分发再版。
参考文献
- [1] Moustafa Alzantot, Bharathan Balaji, and Mani Srivastava. 2017. Did you hear that? adversarial examples against automatic speech recognition. Machine Deception Workshop, Neural Information Processing Systems (NIPS) 2017 (2017).
- [2] Moustafa Alzantot, Yash Sharma, Ahmed Elgohary, Bo-Jhang Ho, Mani Srivastava, and Kai-Wei Chang. 2018. Generating Natural Language Adversarial Examples. EMNLP: Conference on Empirical Methods in Natural Language Processing (2018)
- [3] A. Athalye, N. Carlini, and D. Wagner. 2018. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. arXiv preprint arXiv:1802.00420 (2018).
- [4] A. Athalye, L. Engstrom, A. Ilyas, and K. Kwok. 2017. Synthesizing robust adversarial examples. arXiv preprint arXiv:1707.07397 (2017).
- [5] Dinabandhu Bhandari, CA Murthy, and Sankat K Pal. 1996. Genetic algorithm with elitist model and its convergence. International journal of pattern recognition and artificial intelligence 10, 06 (1996), 731-747.
- [6] Wichard Brendel, Jonas Raubert, and Matthias Bethge. 2018. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models. International Conference on Learning Representations (ICLR) (2018).
- [7] N. Carlini and D. Wagner. 2017. Towards evaluating the robustness of neural networks. arXiv preprint arXiv:1608.04644 (2017).
- [8] P. Y. Chen, Y. Sharma, H. Zhang, J. Yi, and C. Hsieh. 2017. EAD: Elastic-net attacks to deep neural networks via adversarial examples. arXiv preprint arXiv:1709.04114 (2017).
- [9] P. Y. Chen, H. Zhang, Y. Sharma, J. Yi, and C. Hsieh. 2017. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training sub-stitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security. ACM, 15-26.
- [10] J. Deng, W. Dong, R. Socher, J. Li, K. Li, and L. Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. IEEE, 248-255.
- [11] I. Goodfellow, J. Shlens, and C. Szegedy. 2014. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572 (2014).
- [12] S. Gu and L. Rigazio. 2014. Towards deep neural network architectures robust to adversarial examples. arXiv preprint arXiv:1412.5068 (2014).
- [13] C. Guo, M. Rana, and L. van der Maaten. 2017. Countering adversarial images using input transformations. arXiv preprint arXiv:1711.00117 (2017).
- [14] A. Ilyas, L. Engstrom, A. Athalye, and J. Lin. 2018. Black-box Adversarial Attacks with Limited Queries and Information. arXiv preprint arXiv:1804.08598 (2018).
- [15] D. Kingma and J. Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
- [16] A. Kurathri, I. Goodfellow, and S. Bengio. 2016. Adversarial examples in the physical world. arXiv preprint arXiv:1607.02535 (2016).
- [17] A. Kurathri, I. Goodfellow, S. Bengio, Y. Dong, F. Liao, M. Liang, T. Pang, J. Zhu, X. Hu, C. Xie, J. Wang, Z. Zhang, Z. Ren, A. Vidal, S. Huang, Y. Zhao, Y. Zhao, Z. Han, X. Long, Y. Berthelotzky, T. Akiba, S. Tokui, and M. Abe. 2018. Adversarial attacks and defences competition. arXiv preprint arXiv:1804.00097 (2018).
- [18] Yanpei Liu, Xinyun Chen, Chang Liu, and Dawn Song. 2018. Delving into transferable adversarial examples and black-box attacks. International Conference on Learning Representations (ICLR) (2018).
- [19] P. H. Lu, P. Y. Chen, K. C. Chen, and C. M. Yu. 2018. On the limitation of MagNet defense against L1-based adversarial examples. arXiv preprint arXiv:1805.00310 (2018).
- [20] A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu. 2017. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083 (2017).
- [21] S. Moosavi-Dezfooli, A. Fawzi, and P. Frossard. 2016. Deepfool: a simple and accurate method to fool deep neural networks. In Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- [22] N. Papernot, P. McDaniel, I. Goodfellow, S. Jin, Z. B. Celik, and A. Swami. 2017. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security. ACM, 506-519.
- [23] Lukas Schott, Jonas Rauber, Matthias Bethge, and Wichard Brendel. 2019. Towards the first adversarially robust neural network model on MNIST. International Conference on Learning Representations (ICLR) (2019).
- [24] Y. Sharma and P. Y. Chen. 2017. Attacking the Madry defense model with L1-based adversarial examples. arXiv preprint arXiv:1710.10733 (2017).
- [25] Y. Sharma and P. Y. Chen. 2018. Pypassing feature squeezing by increasing adversary strength. arXiv preprint arXiv:1803.06968 (2018).
- [26] Y. Sharma, T. Le, and M. Alzantot. 2018. CAD2.018: Generating Transferable Adversarial Examples. arXiv preprint arXiv:1810.01268 (2018).
- [27] Dong Su, Huan Zhang, Hongse Chen, Jurheng Yi, Pin-Yu Chen, and Yupeng Gao. 2018. Is Robustness the Cost of Accuracy?: A Comprehensive Study on the Robustness of 18 Deep Image Classification Models. In Proceedings of the European Conference on Computer Vision (ECCV). 631-648.
- [28] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. 2015. Going deeper with convolutions. CVPR.
- [29] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, and I. Goodfellow. 2013. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199 (2013).
- [30] F. Tramer, A. Kurathri, N. Papernot, D. Boneh, and P. McDaniel. 2017. Ensemble adversarial training: Attacks and Defenses. arXiv preprint arXiv:1705.07204 (2017).
- [31] Chun-Chen Tu, Paishun Ting, Pin-Yu Chen, Sijia Liu, Huan Zhang, Jurfeng Yi, Cho-Jui Hsieh, and Shin-Ming Cheng. 2018. AutoZOOM: Autoencoder-based Zeroth Order Optimization Method for Attacking Black-box Neural Networks. arXiv preprint arXiv:1805.11770 (2018).
- [32] Huan Zhang, Hongse Chen, Zhao Song, Duane Boning, Inderjit S Dhillon, and Cho-Jui Hsieh. 2019. The Limitations of Adversarial Training and the Blind-Spot Attack. International Conference on Learning Representations (ICLR) (2019).






![[NLP]多电源域设计的仿真验证方法](http://pic.xiahunao.cn/[NLP]多电源域设计的仿真验证方法)
的执行方式)
如何使用全文索引?)

)








