简历描述
· 收集并制作军事伪装目标数据集,包含真实与伪装各种类型军事目标共计60余类。其中,包含最新战场充气伪装军事装备30余类,并为每一张图片制作了详细的标注。
· 针对军事伪装目标的特点,在YOLOv8的Backbone与Neck部分分别加入分组动态感知注意力、跨通道信息交互模块,显著提升了军事伪装目标的识别精度。
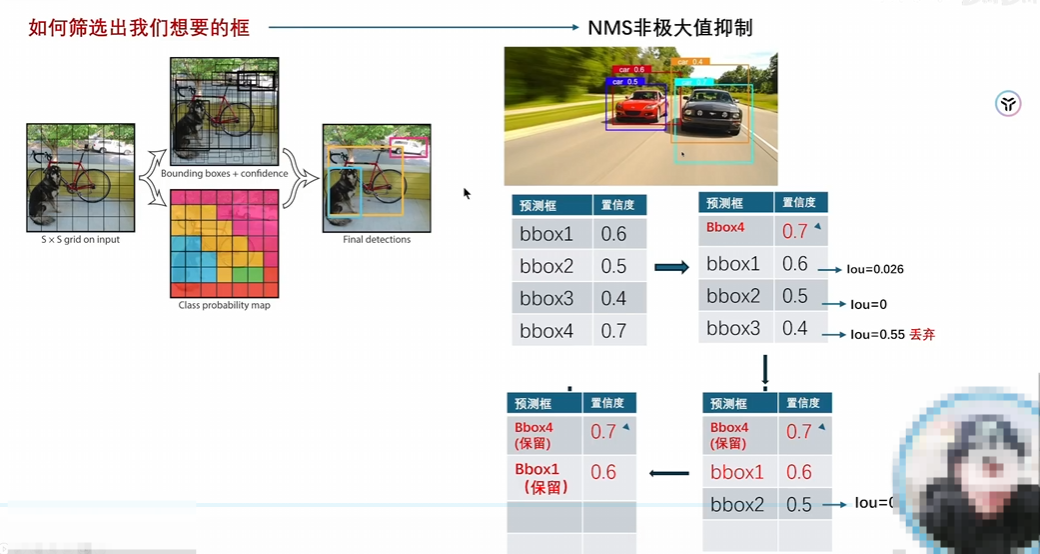
YOLO
YOLOv1
2016cvpr
作者在v3之后由于军方用不干了,后续由别人开发

YOLOv2

- 高分辨率如图
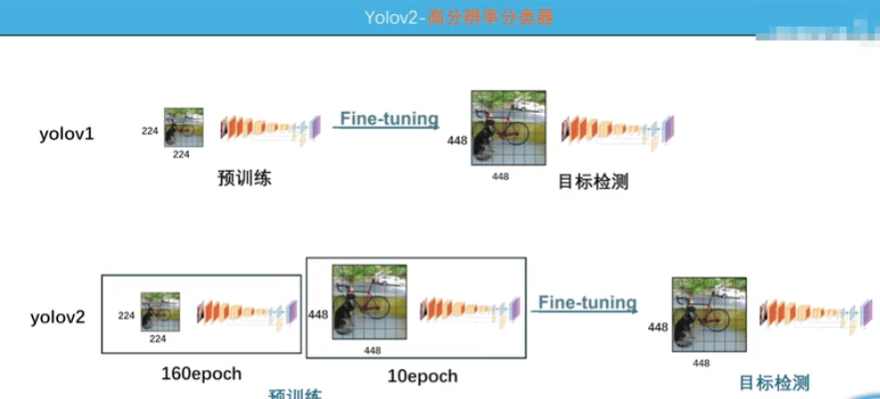
- 加了BN
- 引入锚框
中心点偏移权重来算长宽,让他不全图乱跑
锚框中心点双重约束使得收敛变快
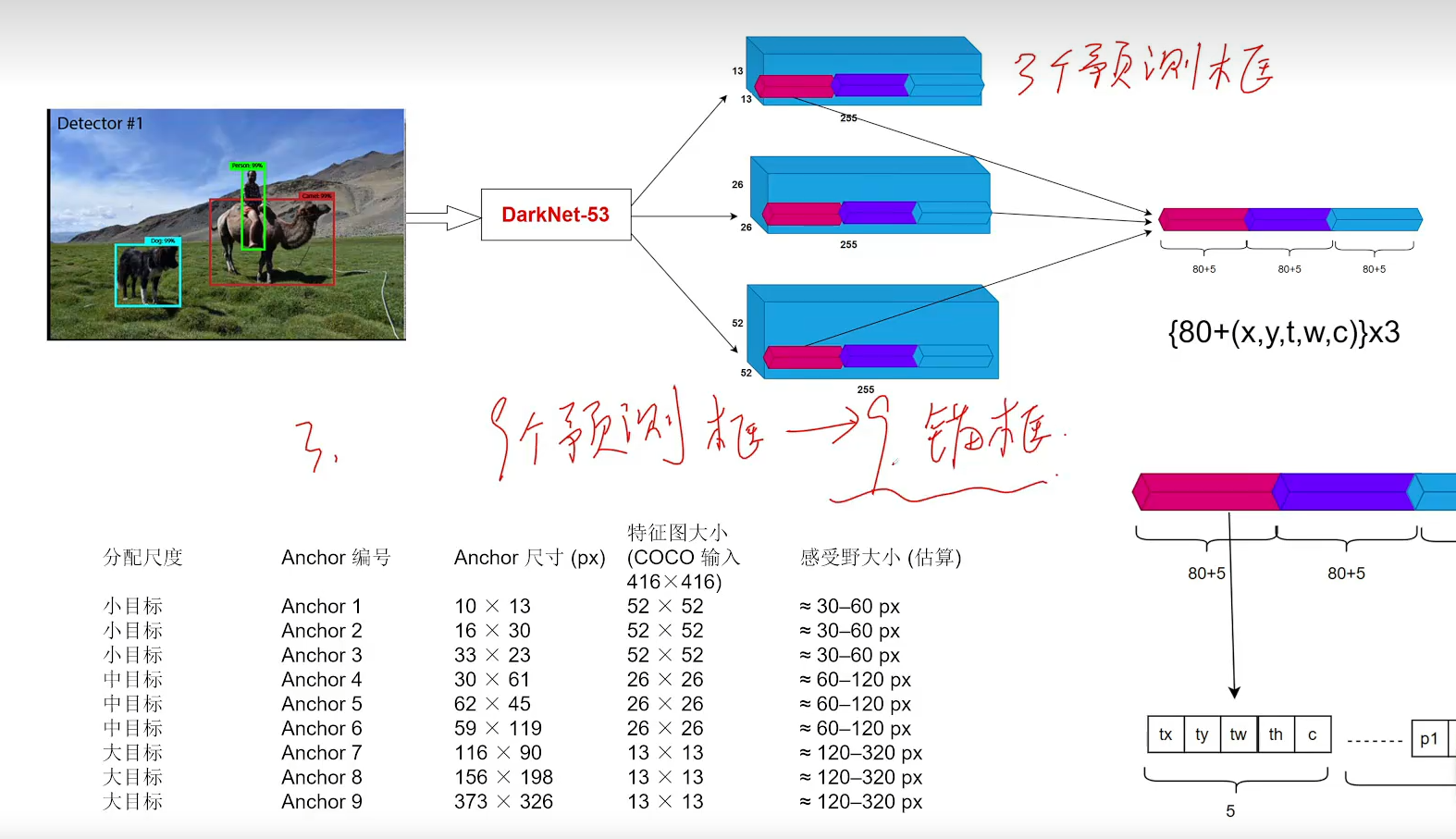
锚框是针对每个图像网格单元(grid cell)定义的,而不是针对整个图像。具体来说,YOLOv2(以及YOLO系列的其他版本)在训练时,对于每个网格单元,会使用多个锚框来预测目标的边界框。
具体解释:
每个网格单元有多个锚框:在YOLOv2中,目标图像被分成一个S x S的网格,每个网格单元负责检测某个区域内的目标。每个网格单元上会预测多个边界框(通常是5个),这些框的初始形状(宽高)是由预定义的锚框确定的。
锚框的数量与每个网格单元的预测数目:每个网格单元会用5个锚框来做预测,这些锚框是根据训练数据中目标的尺度和宽高比预先确定的(通常通过K-means聚类)。因此,每个网格单元的5个锚框是针对该网格位置的不同尺度和不同宽高比的预测框。
举个例子:
假设你有一个416x416的图像,并且网络将其划分为13x13的网格(即每个网格的大小为32x32像素)。那么:
图像的每个网格单元都有5个锚框(这5个锚框的尺寸是根据聚类或其他方法确定的)。
每个网格单元会预测5个边界框,每个框对应一个锚框。网络会根据实际物体的位置、尺寸以及锚框的预设位置来进行回归调整。
锚框和目标物体匹配:
目标物体与网格单元的锚框之间会根据**IoU(Intersection over Union)**来进行匹配。
对于每个物体,选择与其匹配度最高的锚框。
该锚框会预测物体的边界框。实际预测的边界框会根据锚框的位置、宽高进行调整(回归)。
为什么每个网格单元有多个锚框?
不同的目标物体具有不同的尺寸、形状(宽高比),单一的锚框无法涵盖所有物体的特征。因此,YOLOv2设计了每个网格单元使用多个锚框来应对这些变化。多个锚框可以有效地覆盖不同尺度和不同形状的物体,从而提高目标检测的准确性。
总结:
每个网格单元都有多个锚框(通常是5个)。
这些锚框是根据数据集中的目标物体的尺寸和宽高比来预定义的,目的是帮助模型更好地预测不同尺度和形状的物体。
- 采用特征融合,A+B,残差连接类似于resnet
- 把图像缩放不同尺寸输入训练
YOLOv3

maxpoll换成卷积,加残差连接
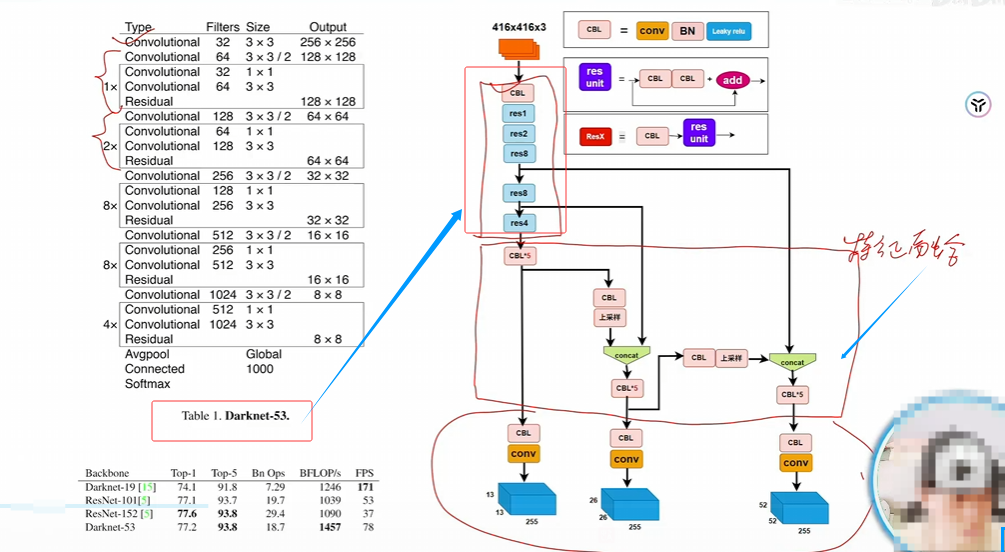
多个检测头,针对大、中、小物体

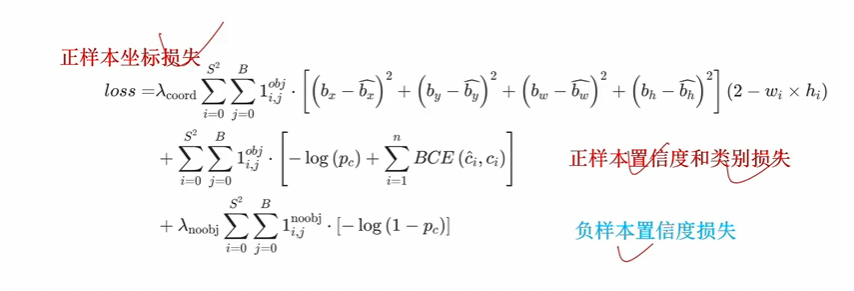
YOLOv4
- 改进
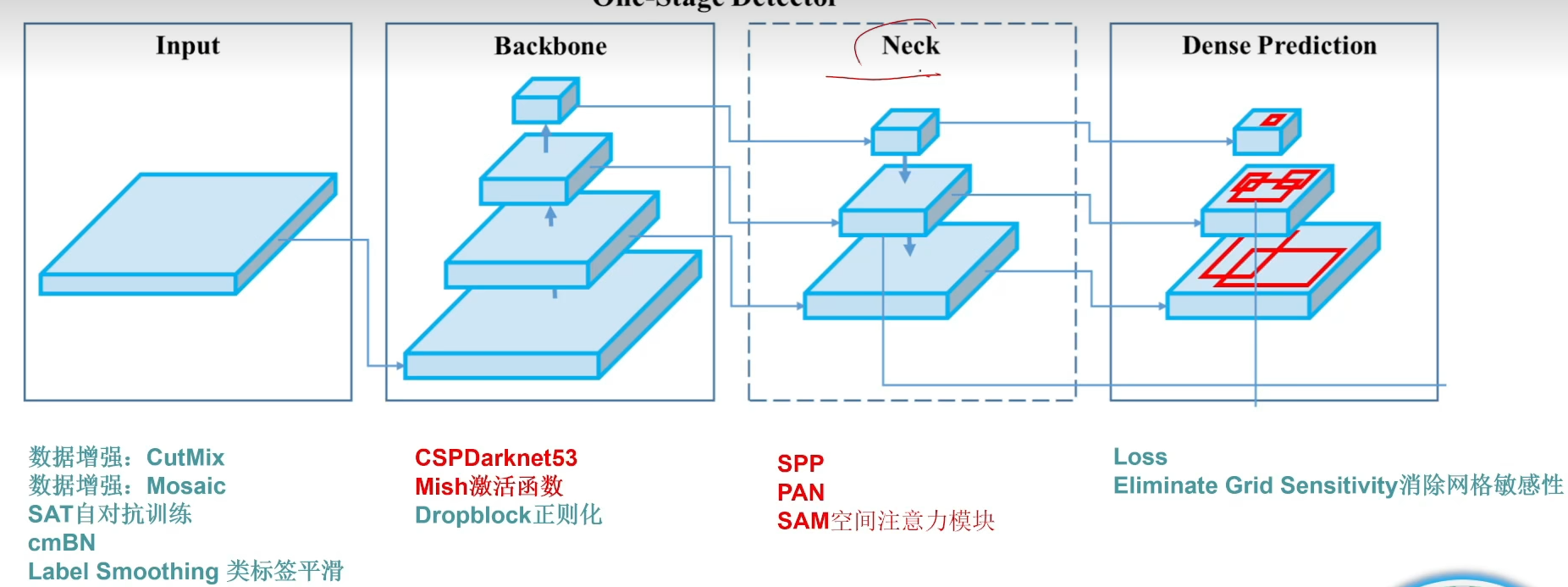
- spp、pan
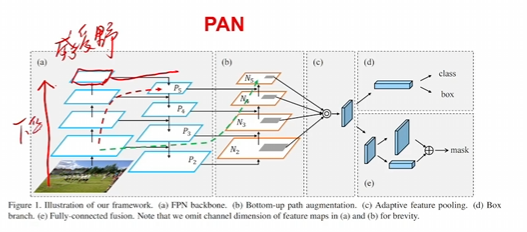
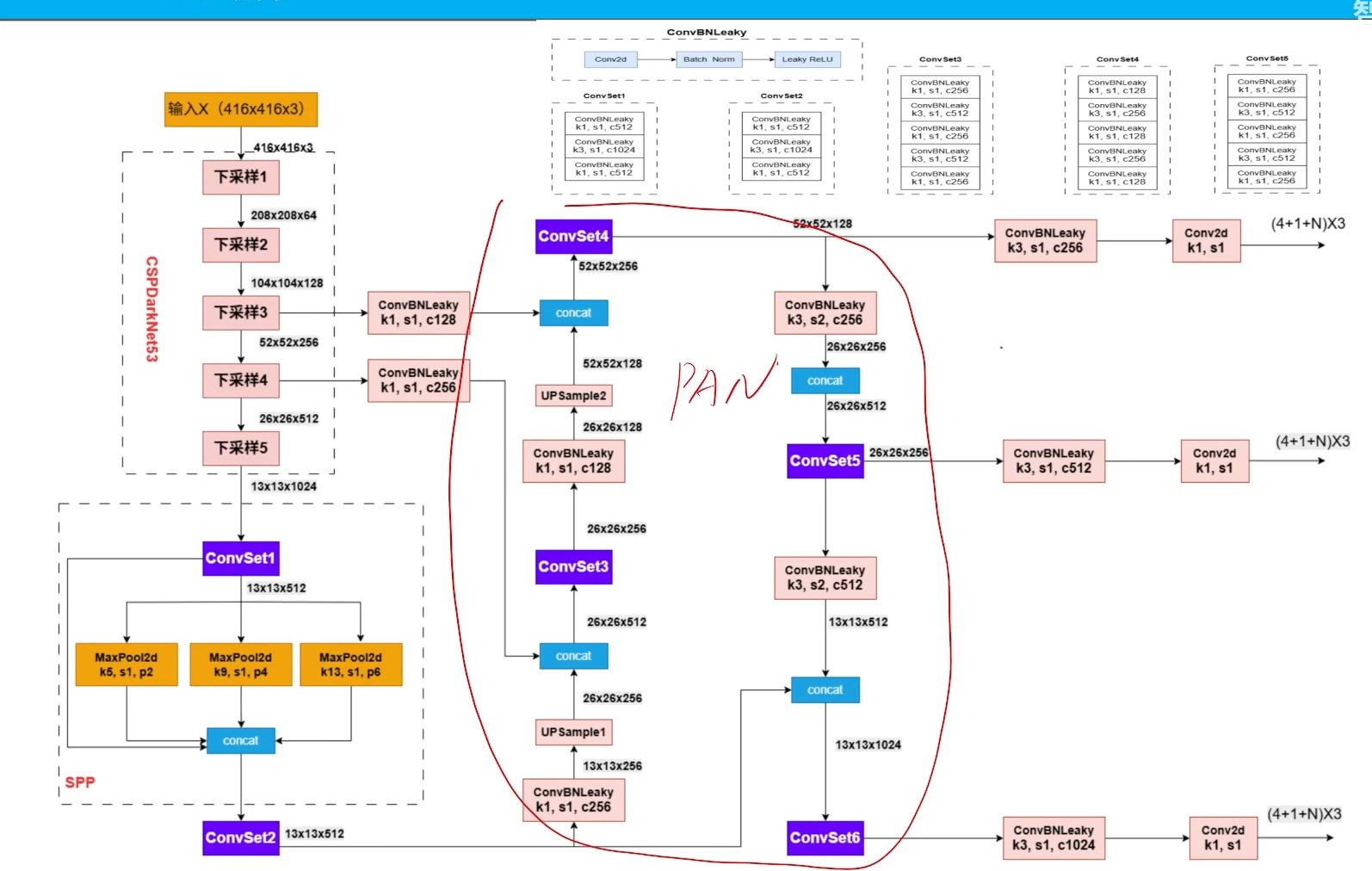
pan就是一个思想,深层和主干网络的融合
spp就是多感受野一个模块
- 数据增强
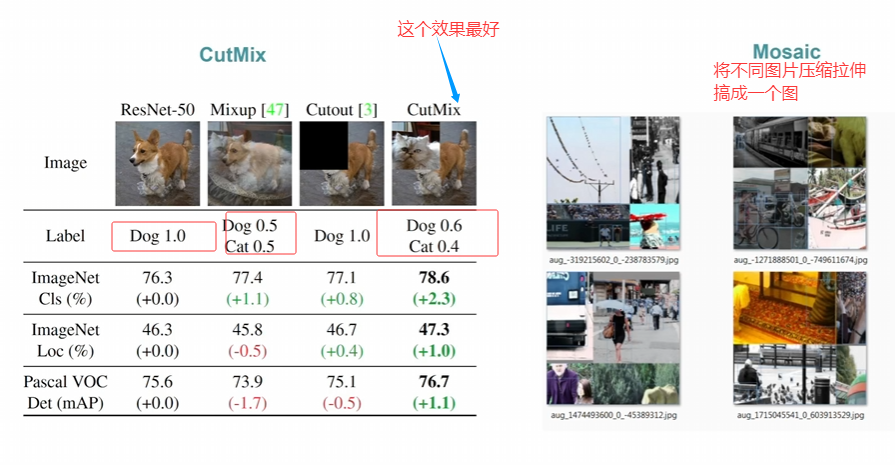
图示已经很清楚的说明了两个图像增强策略是什么

相当于在正向的时候给图片加噪声,提升鲁棒性

改进了归一化方法,这里不赘述
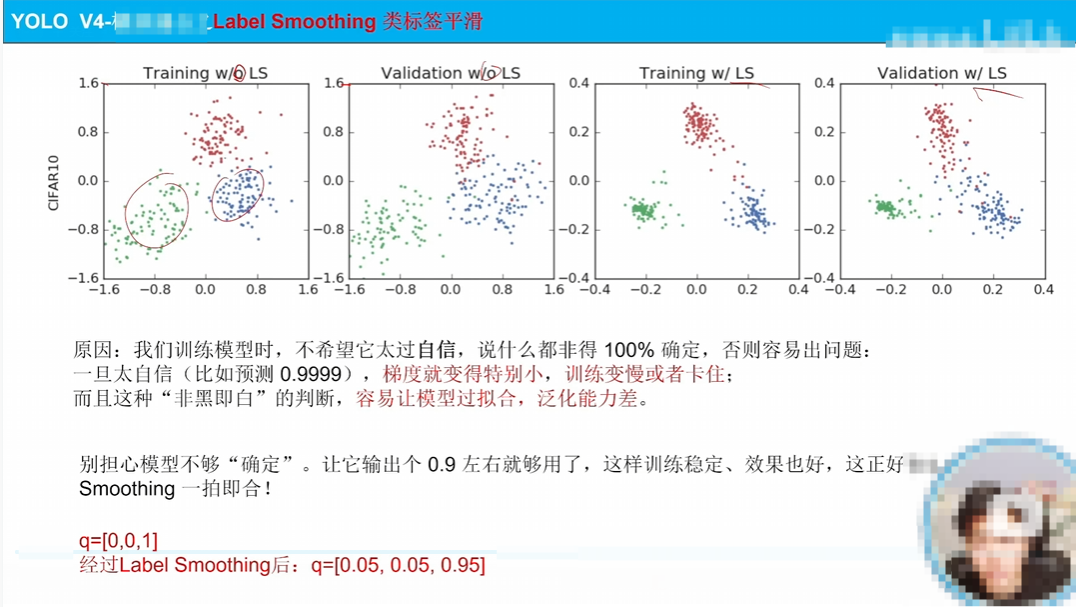
将标签变成软平滑标签,解决梯度问题
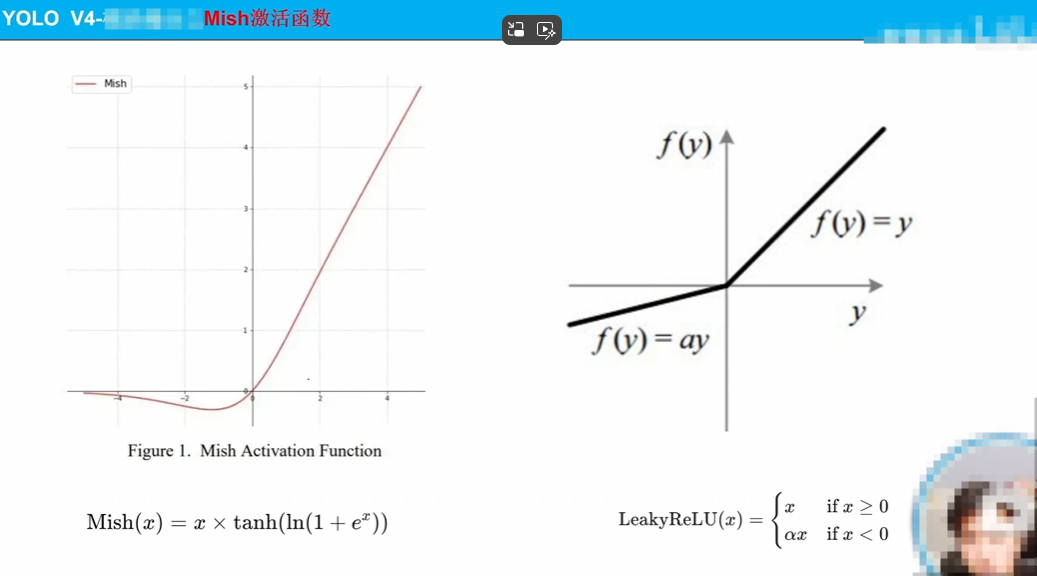
换了激活函数,如图详细说明了他更平滑
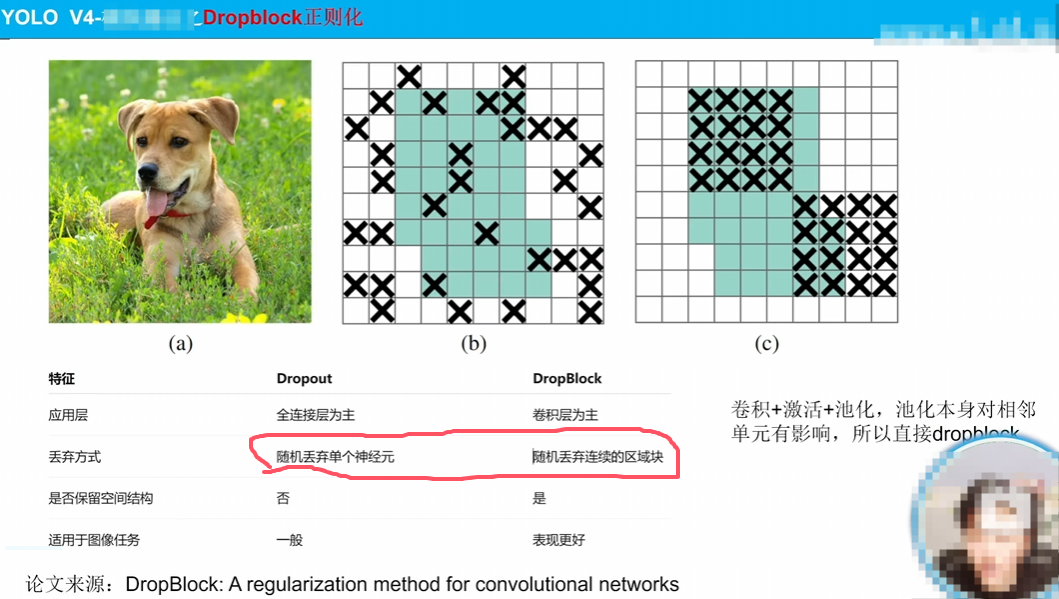
如图很详细说明了一些原因,不赘述
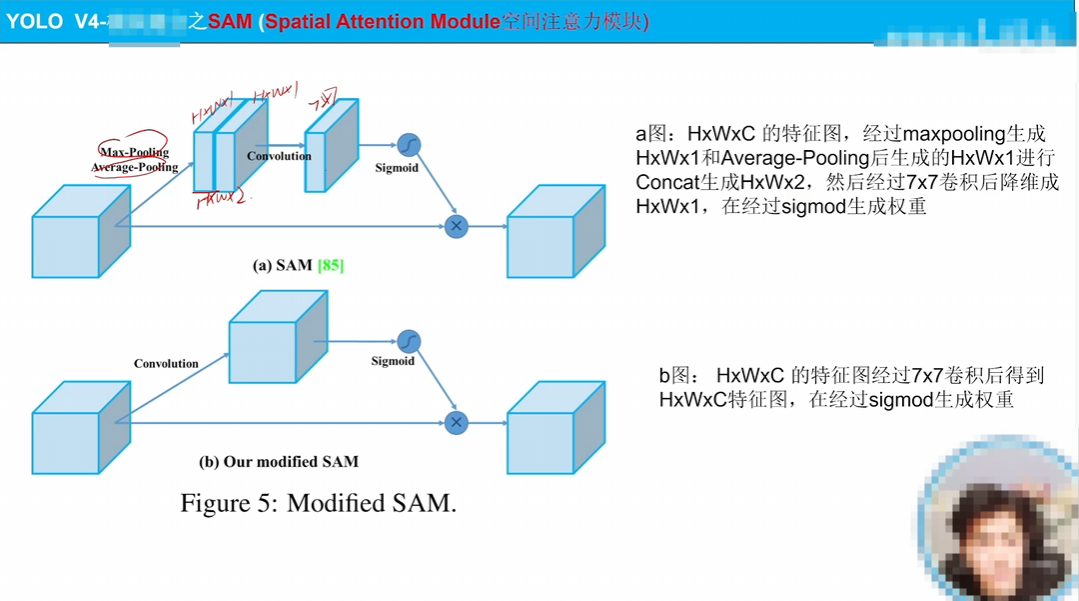
如图说明很清楚
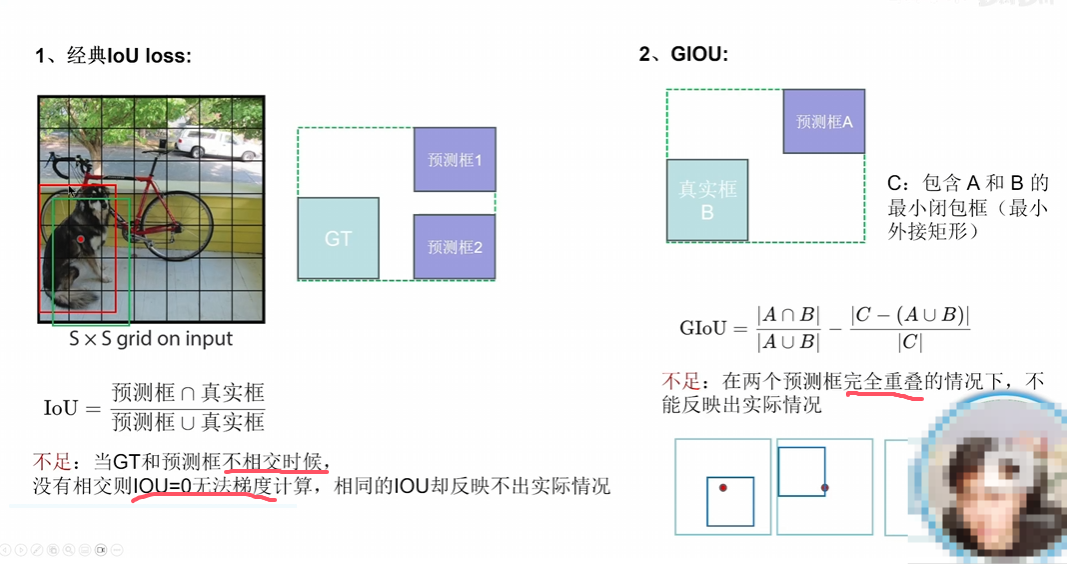
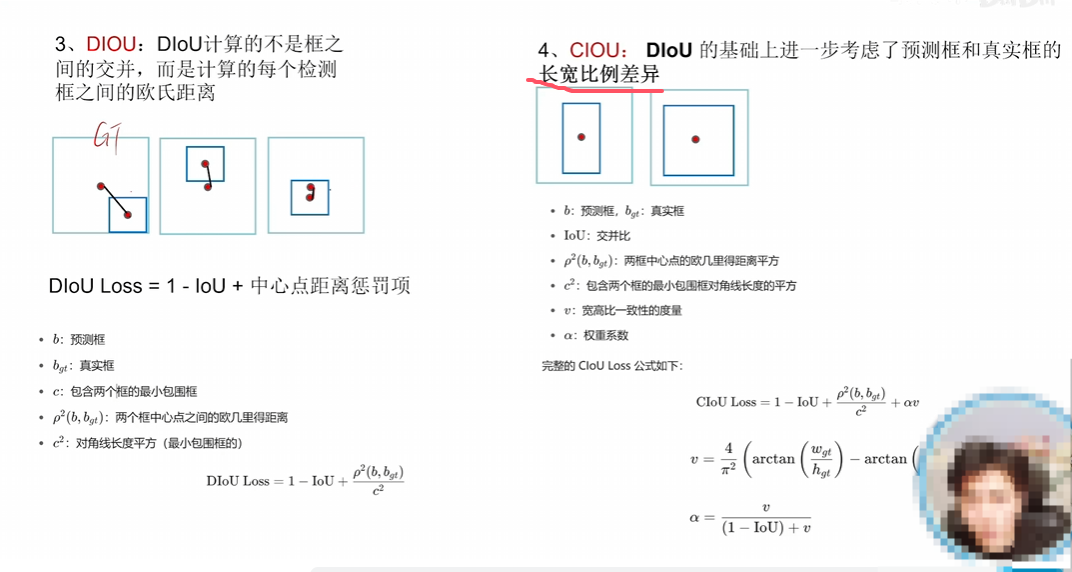
Iou、GIou、DIou属于不断解决原有loss的问题
CIou(DIou pro)属于在原有的loss上加功能
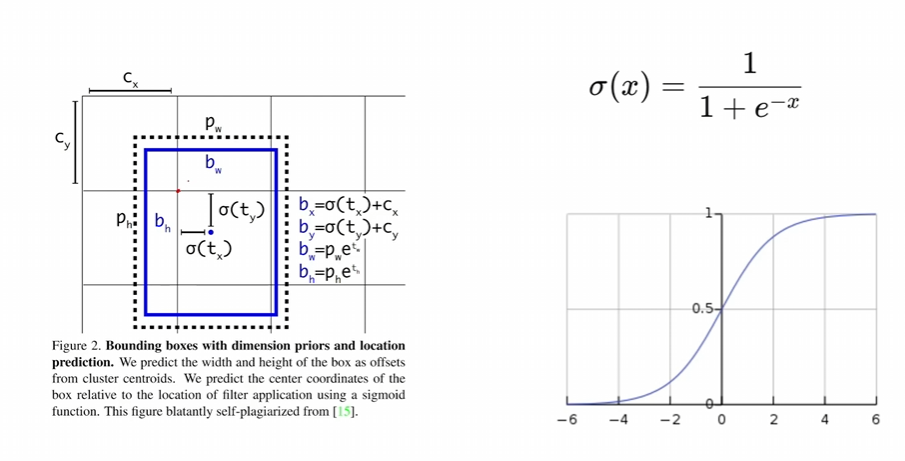
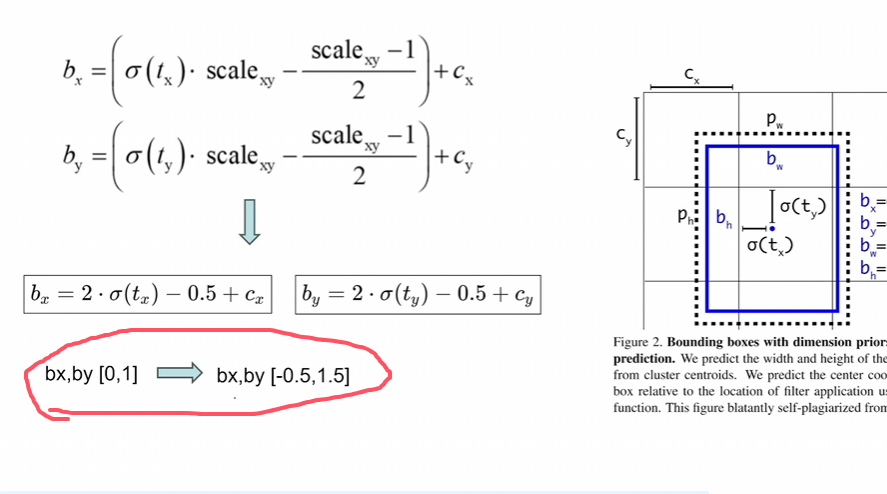
消除网格敏感性:让bx,by的范围变大,然后会出现如下情况
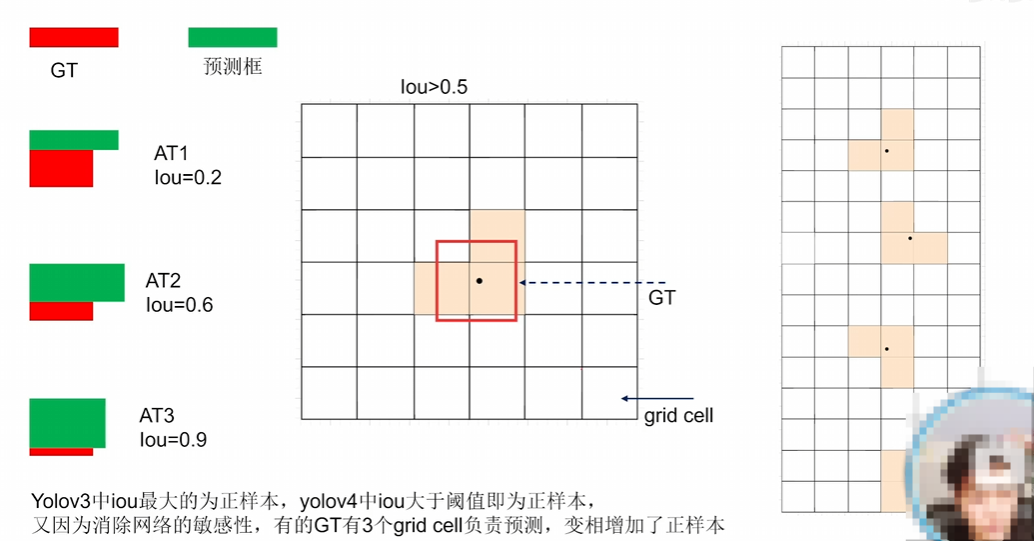
中心点不再限制在一个格子里,相当于三个格子做预测,又有正样本 阈值去筛选,所以就正样本变多了
YOLOv5
无论文
只有代码
但是代码很具备工业可用性
yolov5 有 n、s、m、l、x不同大小的版本

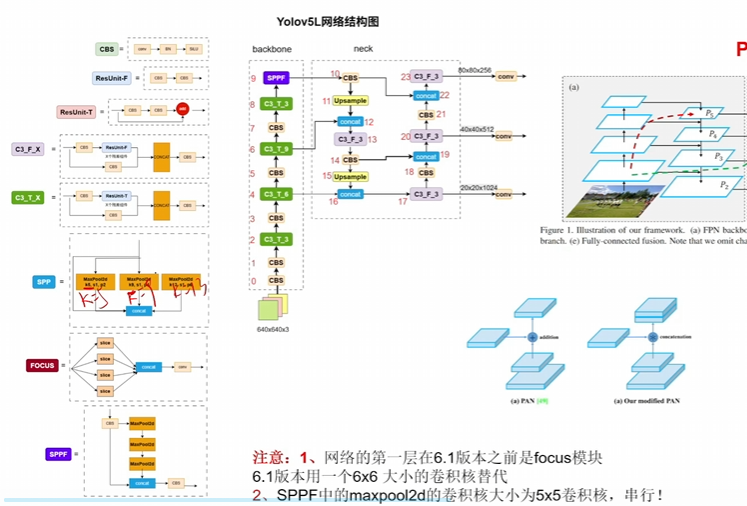
- 整体概述:
上来肯定是backbone提取不同层级的这个特征,至于backbone肯定是自己选
neck就是一个融合的模块罢了,他的策略就是一条贪吃蛇
先不断下采样再不断上采样,其中不断上采样涉及到解码
不断下采样也是通过一些模块就行堆叠,这其中可以控制网络深度
其次就是引入pan思想,也可理解为是一个不同层级特征去进行重组(在neck中融合 的一种方法),其实是很普遍的方法。 - 数据增强变成用Mixup、另外一个方法还是用Mosaic
- 加入一些训练策略
- 损失函数
用的CIoU - 同v4有消除网格敏感性,但正样本锚框筛选不用IoU了,用他自己的方法,如下图
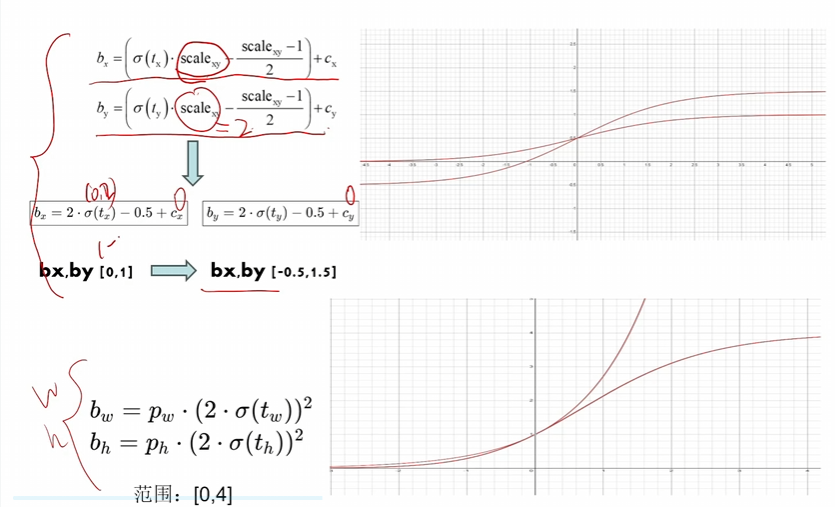
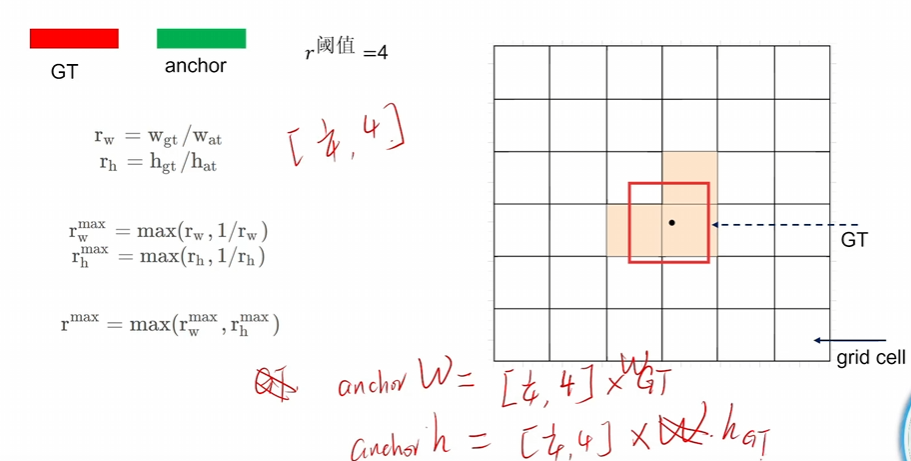
根据GT的长宽的比例倍数去筛选锚框,不能太大也不能太小
YOLOv8
无论文,只有代码
由Ultralytics公司2023年1.10发布
支持obb任务(无人机图像斜着框如下图,这是我们项目中旋转的重要原因)
 yolov8
yolov8
yolov8创新点

yolov8结构图与改进思路
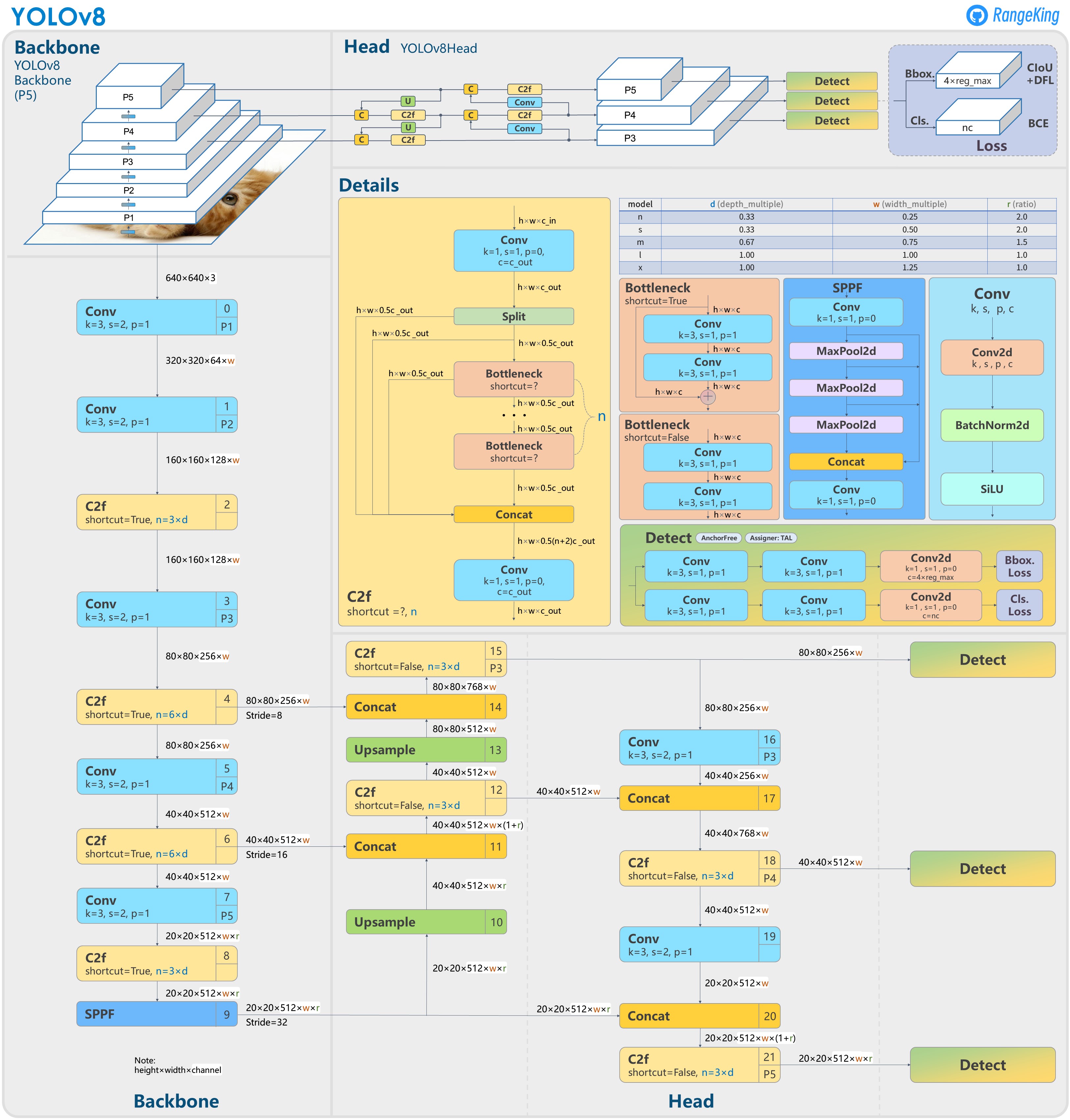
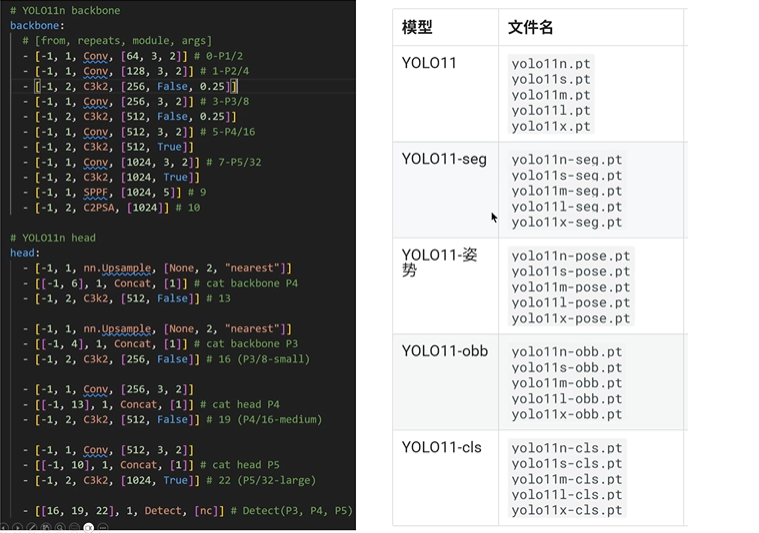
在yolov8.yaml文件中,网络尺寸大小是是和depth_multiple 和width_multiple 参数控制的!
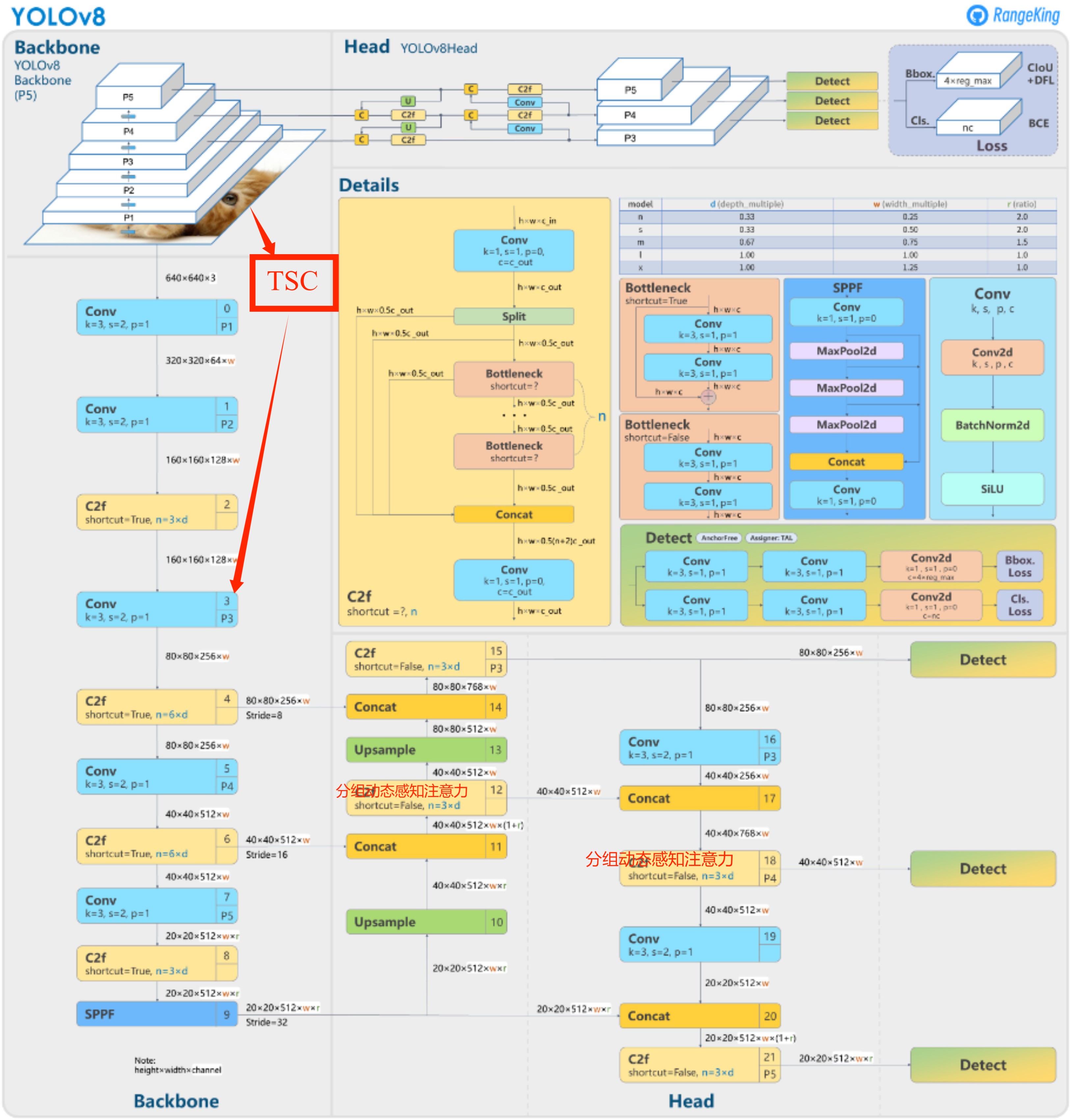
换neck部分的两个中间的c2f模块为分组动态感知注意力
在backbone里面加入TSC挖掘模块并融合
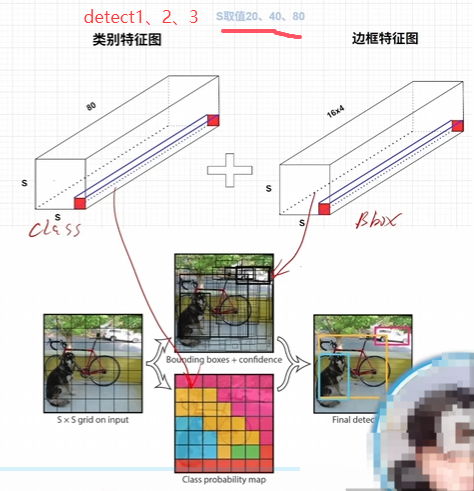
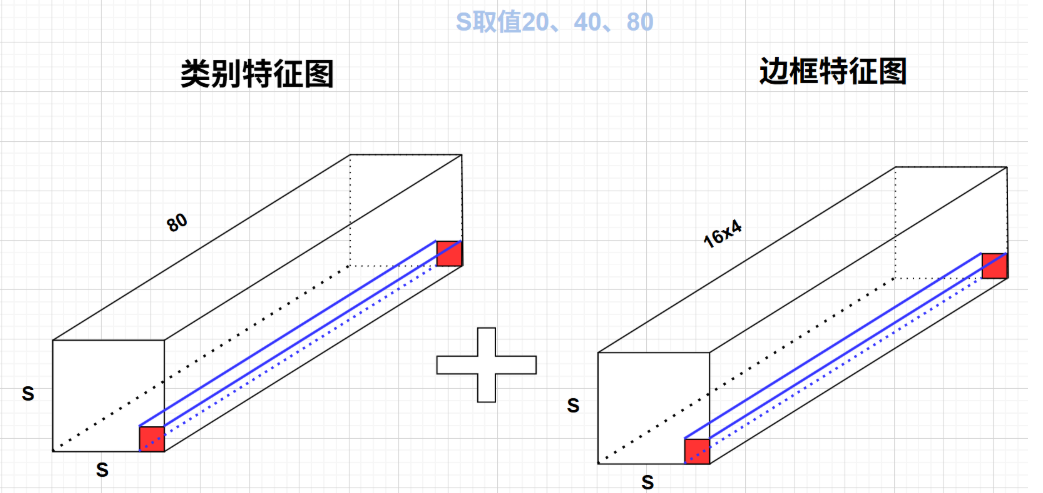
yolov8重大特点之解耦头Decoupled Head设计
最后的输出是两个特征图,一个是分类特征图对应着cls_loss,一个是回归特征图box_loss
yolov8重大特点之Anchor-Free设计
传统的先搞一堆锚框,一个中心点三个,然后生成很多样本去筛选
现在,不撒锚框、不做匹配,模型直接“看图说话”,你在哪、你多大、你是谁,全都由网络自己学。
- Anchor-Based的Anchor数量:(80x80+40x40+20x20)x3=25200 检测头数量:9个
- Anchor-Free的预测框数量:80x80+40x40+20x20=8400 (一个grid cell的中心点就对应一个预测框)
检测头数量:3个
筛选的话人家自创了一套方法
筛选步骤:
1、获取三个检测头的输出结果(预测框、概率值)
2、将三个检测头的结果映射到同一原图(640x640),同时将(l,t,r,b)坐标转化为左上坐标(X_min ,Y_min)和右下坐标(X_max,Y_max)
3、初筛:所有的grid cell的中心点(anchor point)在GT框内的即为初始正样本
4、提取对应类别的pred_score,计算CIOU计算align_matric=pred_score^0.5 * CIoU^6根据align_matric的值,筛选出top-N作为正样本
5、处理一个中心点可能匹配到多个GT框的情况,仅保留最大的CIoU的值对应的预测框
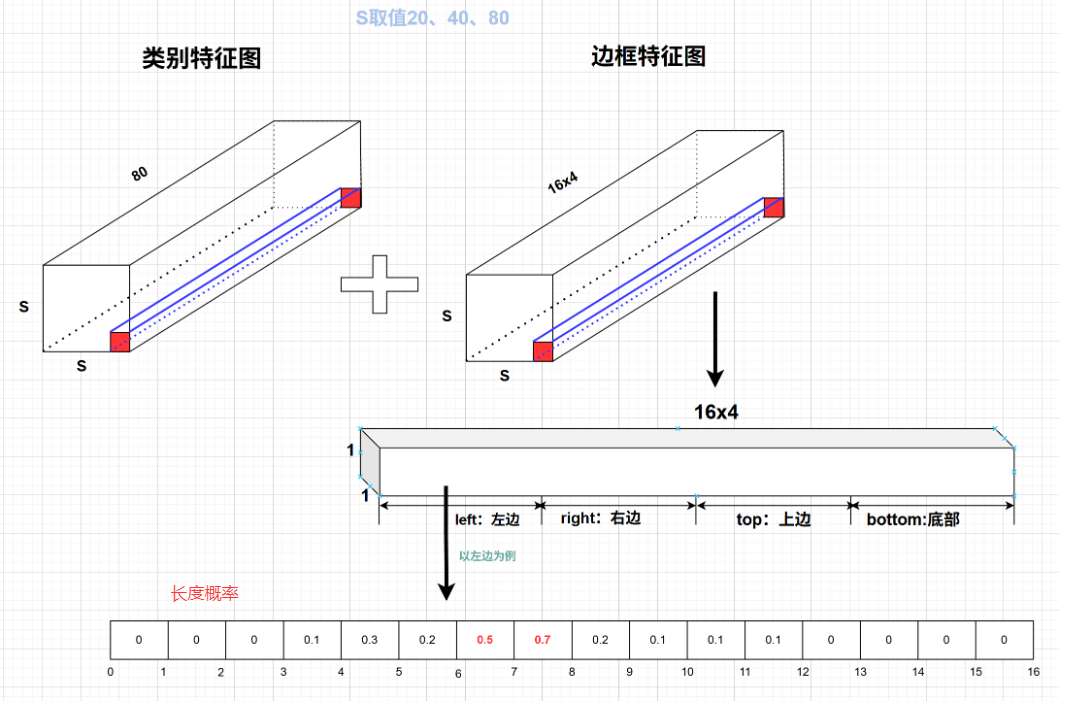
其中pred_score 是类别特征图中对应的最大类别的概率
yolov8重大特点之DFL LOSS设计

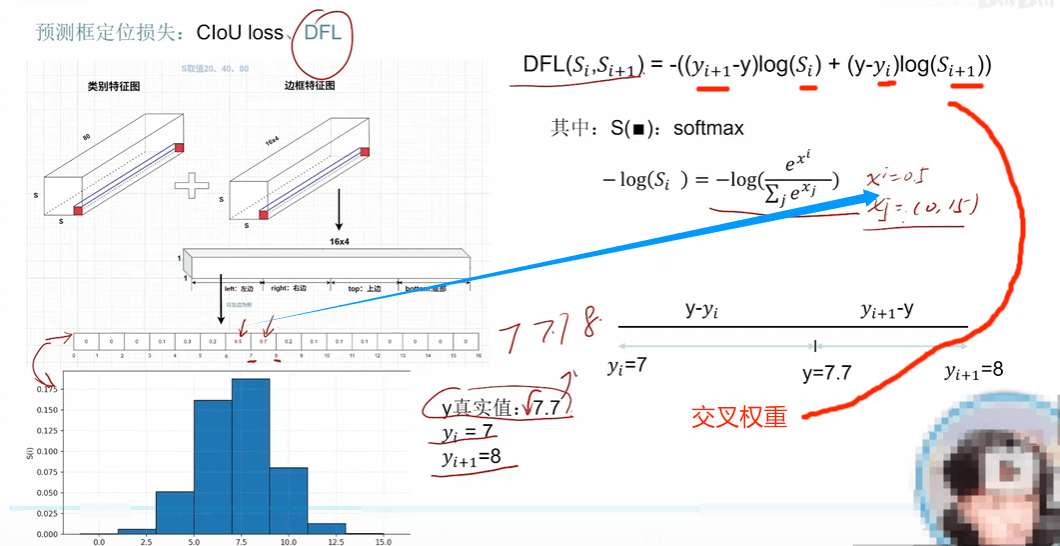
主要是为了消除平峰,,得到尖峰
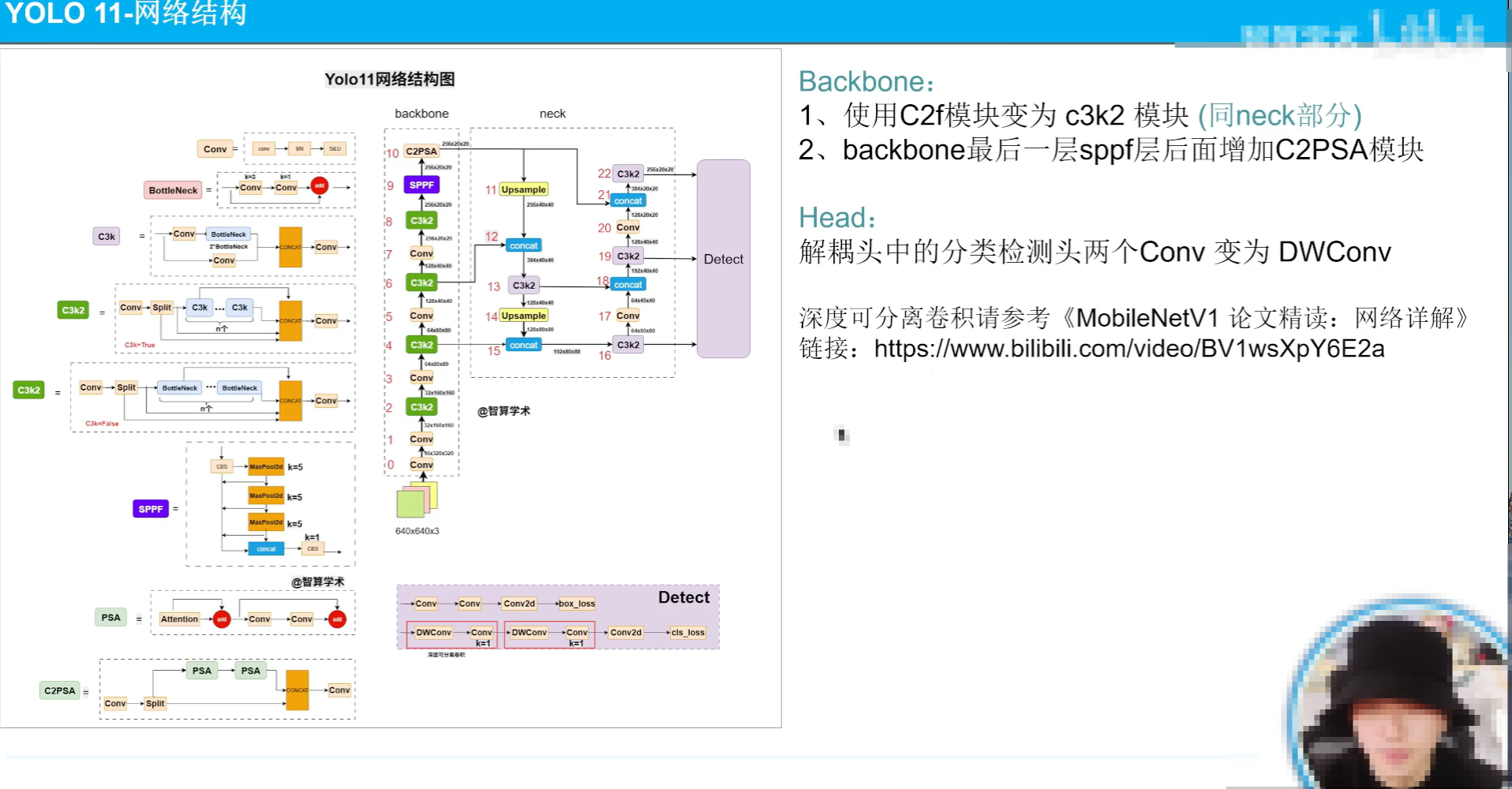
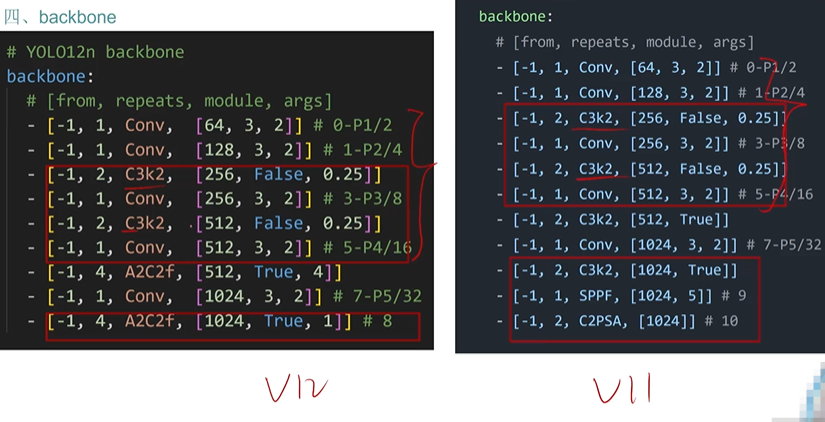
yolov11
主要是网络结构改的比较大
backbone的c2k换成c3k2
sppf后面加了一个c2psa
yolov12
中科院改的
创新的融入注意力机制

- 网络图
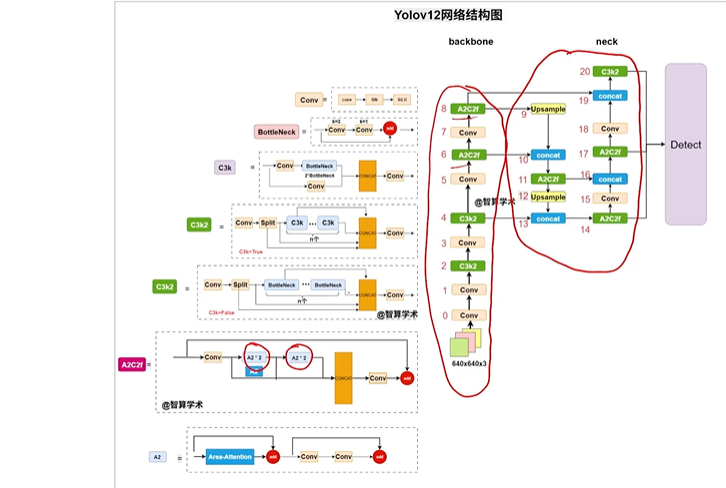
可见A2C2f被广泛使用,A2C2f是A2组成的
保留部分C3k2
- A2的思想,FlashAttention是一个常用的库

- A2

- R-ELAN
图示说的很清楚了
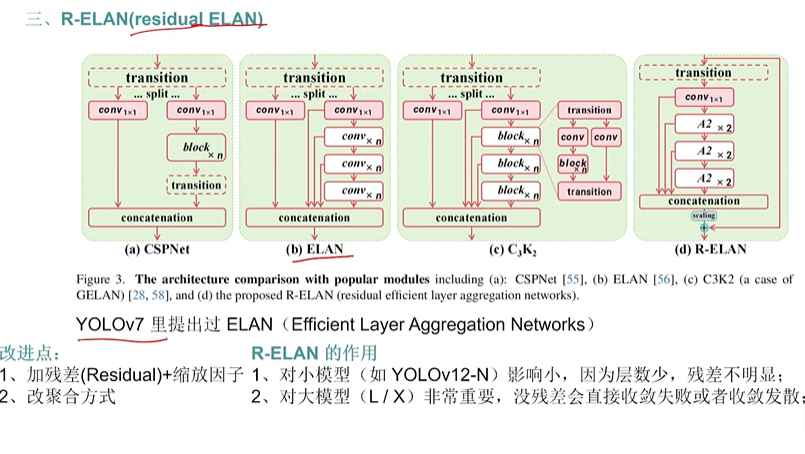
- backbone对比
总结就是前面都一样后面变了,C3k2被A2C2f广泛的替换了
- 其他的微调
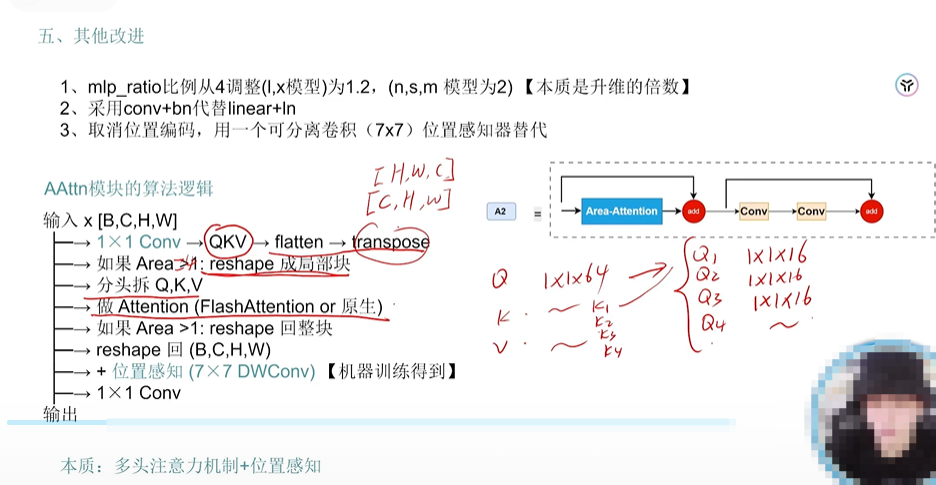










)








