p; 上篇文章分享了如何使用GPT-SoVITS实现一个HTTP服务器,并通过该服务器提供文本到语音(TTS)服务。今天,我们将进一步探讨如何部署另一个强大的TTS模型——f5-tts。这个模型在自然语音生成方面表现出色,具有高度的可定制性和灵活性。通过这篇文章,我们将详细介绍如何搭建f5-tts模型的环境,进行模型的配置,并通过HTTP服务器提供文本到语音服务,助力用户更高效地集成到各种应用场景中。
1 部署及启动F5-TTS服务器
1.1 项目下载及根据来源
这里就不赘述咋下载F5-TTS这个项目了,如果有不知道的兄弟可以看我上一篇文章:
TTS语音合成|盘点两款主流TTS模型,F5-TTS和GPT-SoVITS
需要注意的是,这里f5-tts官方并没有给我们实现api接口的http服务器,需要基于另一个项目去实现HTTP服务器的搭建,另一个项目地址在:f5-tts-api
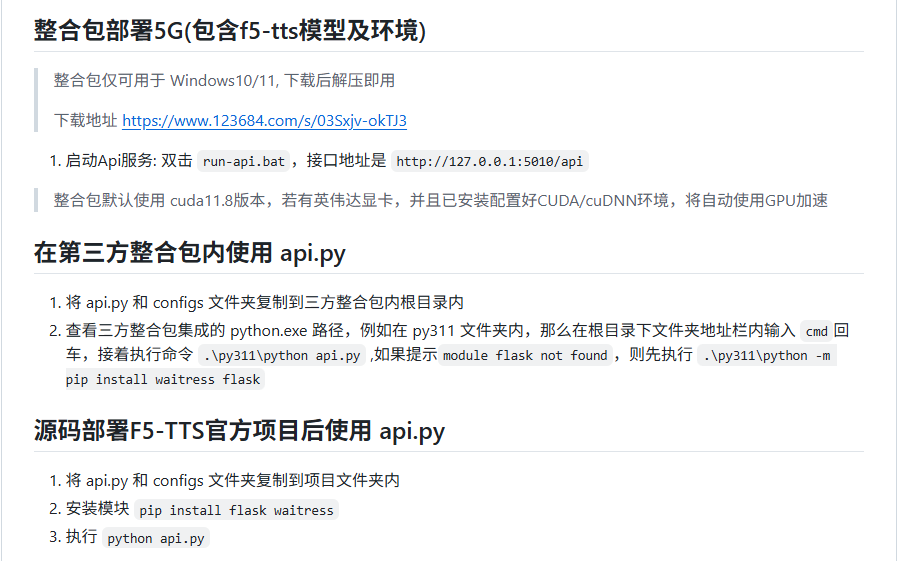
可以看到,f5-tts-api这个项目提供了三种部署方式,实际上只有两种部署方式。前两种方式都使用了整合包里面的Python环境和模型,而第三种则是使用f5-tts官网的Python环境和模型。我尝试过这三种方式,发现由于模型版本的差异,前两种方式合成的语音中会出现杂音,而使用官网提供的环境和模型合成的语音则非常清晰,没有杂音。这可能是由于整合包中的模型版本与官网最新版本存在一定的差异,影响了语音的质量,所以这里重点介绍第三种部署方式。
1.2 需要文件及代码
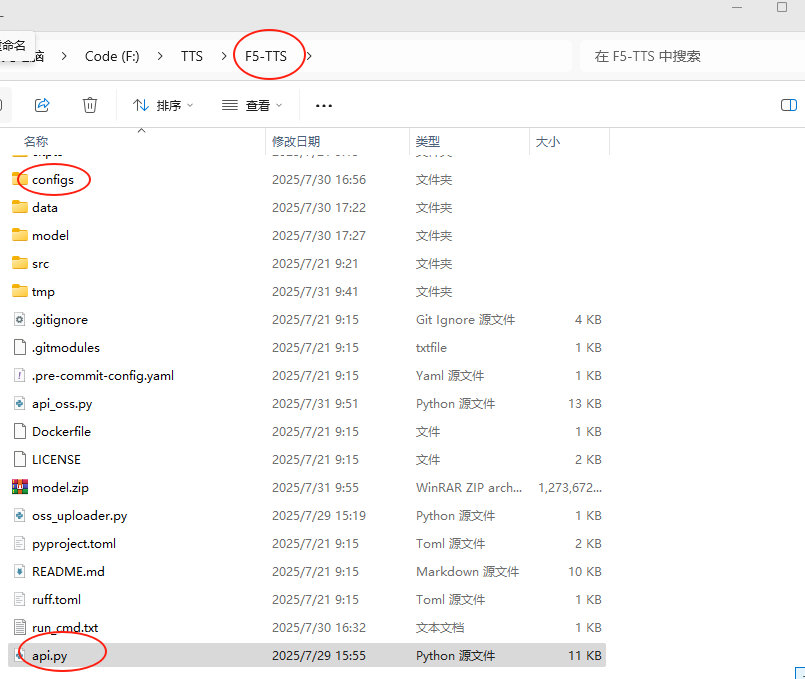
这里的项目F5-TTS是官网项目,configs和api.py是f5-tts-api这个项目中的文件。
1.3 启动服务命令
# 这个环境是f5-tts官网环境
conda activate f5-tts
pip install flask waitress
pip install Flask-Cors
cd F:\TTS\F5-TTS
python api.py
启动起来大概是这样的:
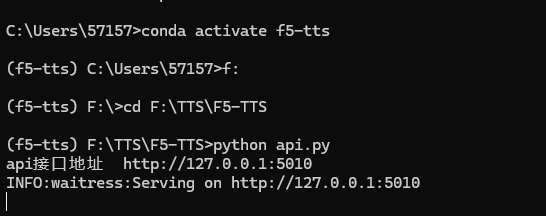
可以看到IP是127.0.0.1,只允许本地访问,如果想要局域网内访问这个服务,或者映射出去,需要到api.py里面修改ip,如下图所示:
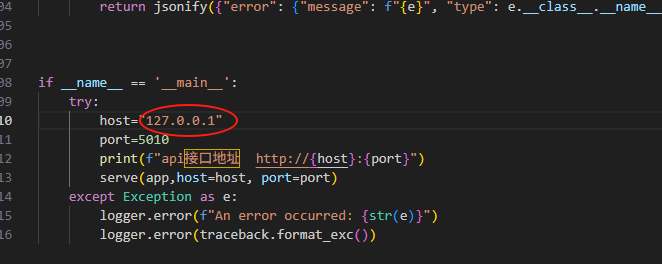
将ip改为0.0.0.0即可。
2 客户端请求部署的TTS服务器
关于请求,f5-tts-api这个项目给了两种请求方式,分别是API 使用示例接口和 兼容openai tts接口
2.1 API 使用示例
import requestsres=requests.post('http://127.0.0.1:5010/api',data={"ref_text": '这里填写 1.wav 中对应的文字内容',"gen_text": '''这里填写要生成的文本。''',"model": 'f5-tts'
},files={"audio":open('./1.wav','rb')})if res.status_code!=200:print(res.text)exit()with open("ceshi.wav",'wb') as f:f.write(res.content)
2.2 兼容openai tts接口
import requests
import json
import os
import base64
import structfrom openai import OpenAIclient = OpenAI(api_key='12314', base_url='http://127.0.0.1:5010/v1')
with client.audio.speech.with_streaming_response.create(model='f5-tts',voice='1.wav###你说四大皆空,却为何紧闭双眼,若你睁开眼睛看看我,我不相信你,两眼空空。',input='你好啊,亲爱的朋友们',speed=1.0) as response:with open('./test.wav', 'wb') as f:for chunk in response.iter_bytes():f.write(chunk)2.3 测试
使用API 使用示例,可以看到,不出所料的报错了😴:
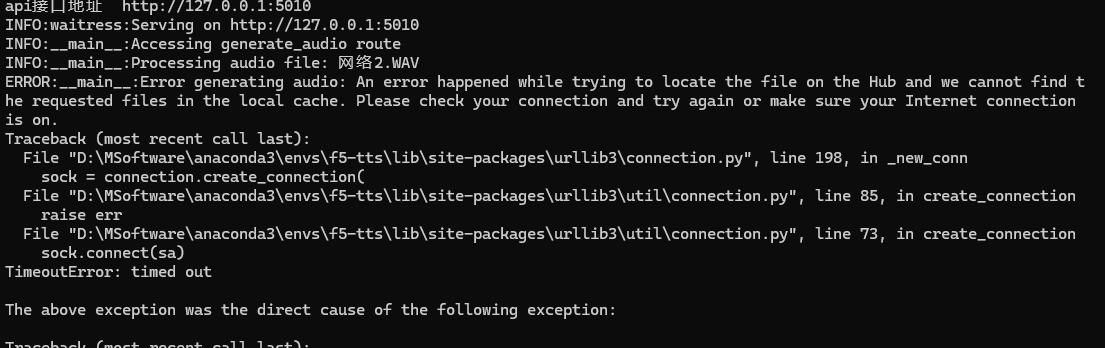
原因很简单,你没科学上网,Hugging Face被墙了,继续往下看解决办法。
3 下载模型及修改api.py
3.1 查看需要模型
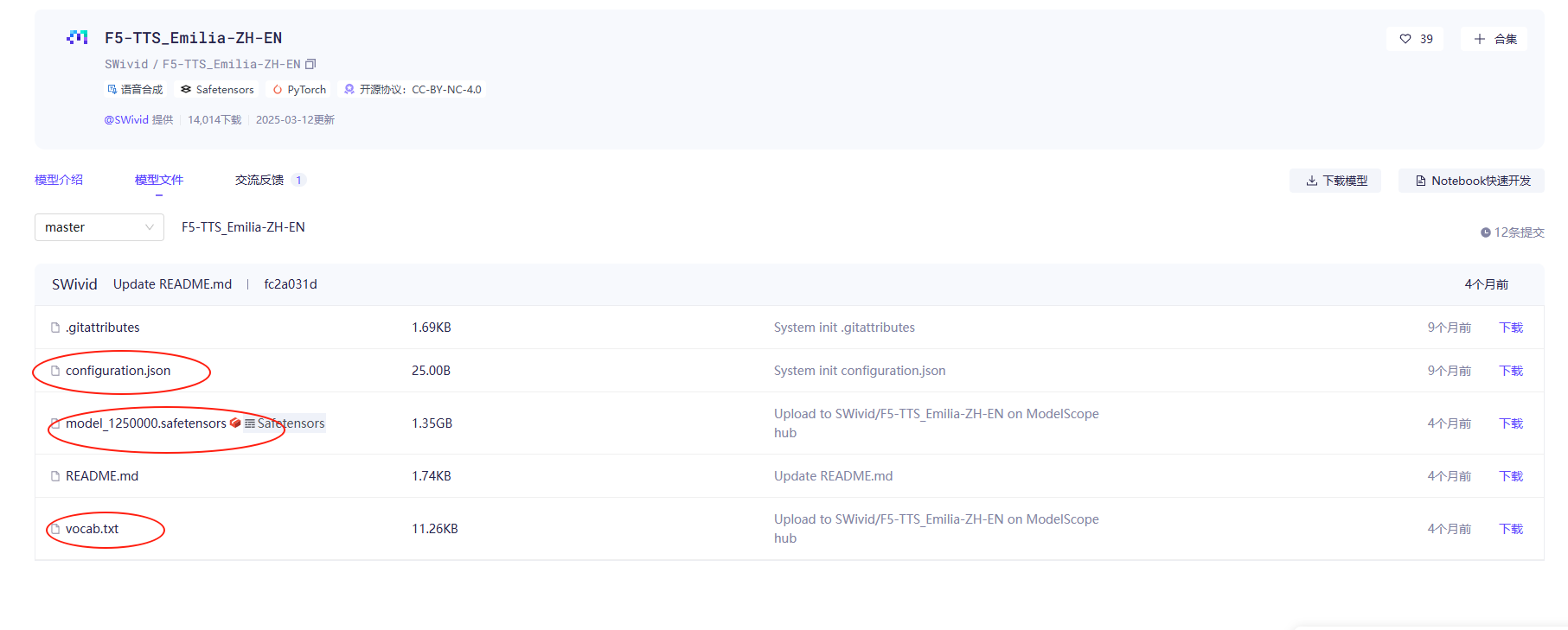
这里直接给你掠过,有兴趣的兄弟们可以自行查看api.py,直接说结论,需要两个模型,一个是TTS模型(F5-TTS_Emilia-ZH-EN
),一个是频谱合成模型(vocos-mel-24khz)。
F5-TTS_Emilia-ZH-EN下载位置在:
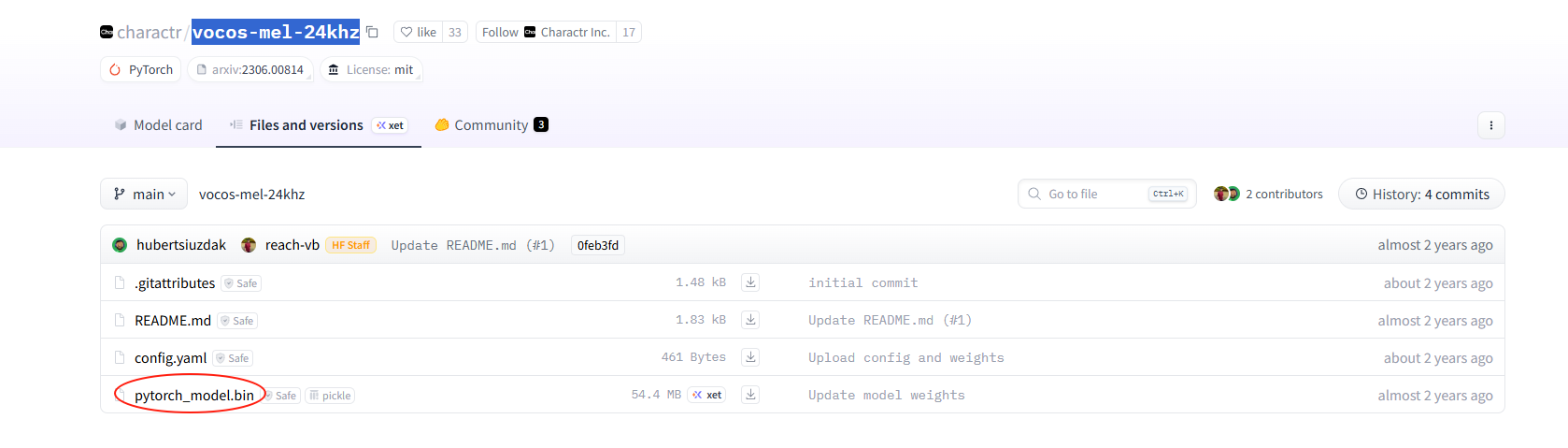
*vocos-mel-24khz我在modelscope没有找到,Hugging Face上倒是有:
3.2 api.py代码修改位置
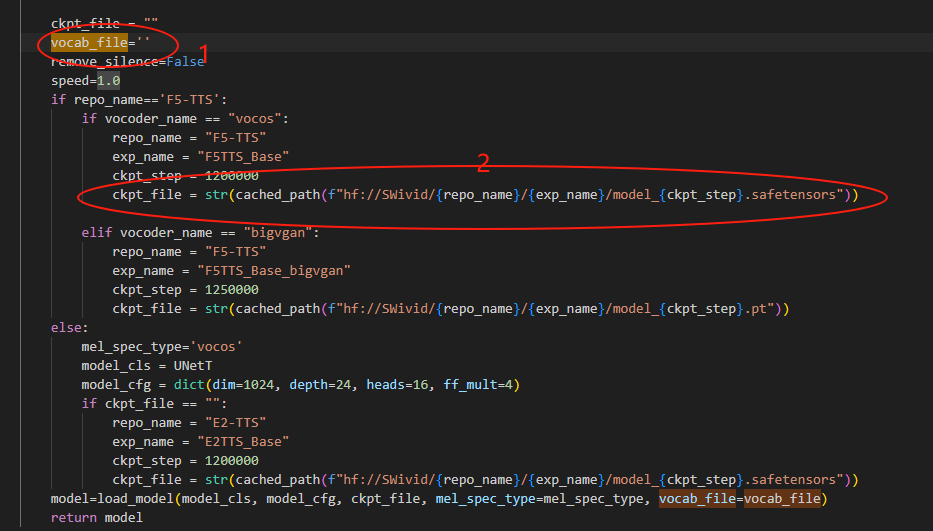
上图位置1改成vocab.txt位置,位置2改成F5-TTS_Emilia-ZH-EN模型位置。

上图改成vocos-mel-24khz模型位置。
4 代码优化
我发现每次推理时,都需要加载一遍模型,可能是为了节省资源:
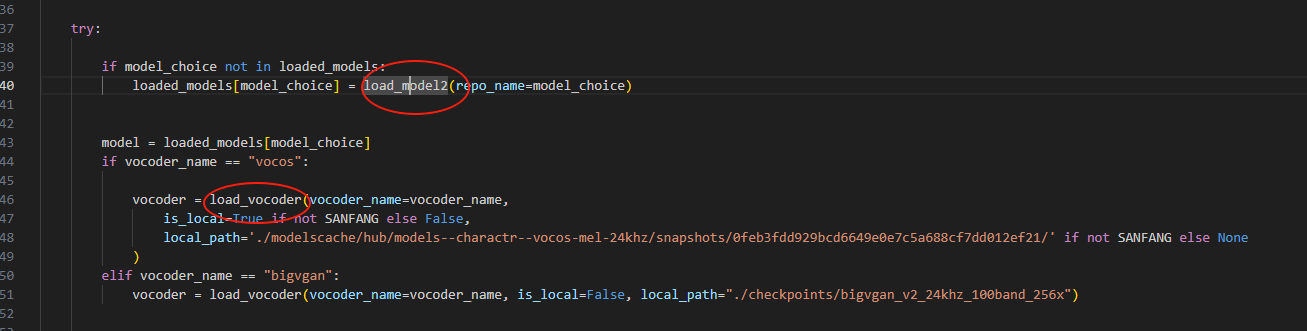
我这里先把模型加载进来,避免每次都加载一遍模型,并且将参考音频和参考文字都放在了服务端,并且将生成的音频上传到oss服务器,做成网络音频流。
具体代码实现:
import os,time,sys
from pathlib import Path
ROOT_DIR=Path(__file__).parent.as_posix()# ffmpeg
if sys.platform == 'win32':os.environ['PATH'] = ROOT_DIR + f';{ROOT_DIR}\\ffmpeg;' + os.environ['PATH']
else:os.environ['PATH'] = ROOT_DIR + f':{ROOT_DIR}/ffmpeg:' + os.environ['PATH']SANFANG=True
if Path(f"{ROOT_DIR}/modelscache").exists():SANFANG=Falseos.environ['HF_HOME']=Path(f"{ROOT_DIR}/modelscache").as_posix()import re
import torch
from torch.backends import cudnn
import torchaudio
import numpy as np
from flask import Flask, request, jsonify, send_file, render_template
from flask_cors import CORS
from einops import rearrange
from vocos import Vocos
from pydub import AudioSegment, silencefrom cached_path import cached_pathimport soundfile as sf
import io
import tempfile
import logging
import traceback
from waitress import serve
from importlib.resources import files
from omegaconf import OmegaConffrom f5_tts.infer.utils_infer import (infer_process,load_model,load_vocoder,preprocess_ref_audio_text,remove_silence_for_generated_wav,
)
from f5_tts.model import DiT, UNetT
from oss_uploader import upload_to_oss
import requests
TMPDIR=(Path(__file__).parent/'tmp').as_posix()
Path(TMPDIR).mkdir(exist_ok=True)# Set up logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)app = Flask(__name__, template_folder='templates')
CORS(app)# --------------------- Settings -------------------- #audio_info = { # 字典定义26: {"audio_name": "data/cqgyq.wav", "ref_text": "111" ,"audio_speed": 1.3},25: {"audio_name": "data/shwd.wav", "ref_text": "222","audio_speed": 1.1},24: {"audio_name": "data/network8.wav", "ref_text": "333","audio_speed": 1},23: {"audio_name": "data/network4.wav", "ref_text": "444","audio_speed": 1.1},22: {"audio_name": "data/network2.wav", "ref_text": "555","audio_speed": 0.9},
}def get_audio_info(audio_id):# 判断 audio_id 是否是整数if not isinstance(audio_id, int):try:# 尝试将 audio_id 转换为整数audio_id = int(audio_id)except ValueError:# 如果转换失败,输出错误信息并返回默认值print(f"音频ID {audio_id} 不是有效的整数,无法转换。")return None, None, None# 判断 audio_id 是否在字典中if audio_id in audio_info:audio_data = audio_info[audio_id]return audio_data["audio_name"], audio_data["ref_text"], audio_data["audio_speed"]else:print(f"音频ID {audio_id} 在字典中没有找到。")return None, None, None# Add this near the top of the file, after other imports
UPLOAD_FOLDER = 'data'
if not os.path.exists(UPLOAD_FOLDER):os.makedirs(UPLOAD_FOLDER)def get_model_and_vocoder(model_dir, vocab_dir, vcoder_dir):# mel_spec_type = vocoder_namemodel_cfg = f"{ROOT_DIR}/configs/F5TTS_Base_train.yaml"model_cfg = OmegaConf.load(model_cfg).model.archmodel = load_model(DiT, model_cfg, model_dir, mel_spec_type='vocos', vocab_file=vocab_dir)vocoder = load_vocoder(vocoder_name='vocos',is_local=True,local_path=vcoder_dir)return model, vocodermodel, vocoder = get_model_and_vocoder(f"{ROOT_DIR}/model/model_1250000.safetensors", f'{ROOT_DIR}/model/vocab.txt',f'{ROOT_DIR}/model/models--charactr--vocos-mel-24khz/snapshots/0feb3fdd929bcd6649e0e7c5a688cf7dd012ef21/')@app.route('/api', methods=['POST'])
def api():logger.info("Accessing generate_audio route")# 打印所有请求数据if request.is_json:data = request.get_json()gen_text = data['text']voice_id = data['anchor_id']ref_audio_path = data['ref_audio_path']logger.info("Received JSON data: %s", data)else:data = request.form.to_dict() logger.info("Received form data: %s", data)gen_text = request.form.get('text')voice_id = request.form.get('anchor_id')ref_audio_path = request.form.get('ref_audio_path')remove_silence = int(request.form.get('remove_silence',0))# 自定义speed# speed = float(request.form.get('speed',1.0))print("===========voice_id: ", voice_id, type(voice_id))audio_name, ref_text, audio_speed = get_audio_info(voice_id)print("================get audio_name: ",audio_name)print("================get ref_text :",ref_text)print("================get audio_speed :",audio_speed)print("================get ref_audio_path :",ref_audio_path)if not all([audio_name, ref_text, gen_text]): # Include audio_filename in the checkreturn jsonify({"error": "Missing required parameters"}), 400speed = audio_speed# 调用接口查询是否存在记录check_url = "xxx/existVoice"try:response = requests.post(check_url, data={"voice_text": gen_text, 'anchor_id': voice_id})if response.status_code == 200:result = response.json()if result.get("code") == 200 and result.get("data"):# 如果接口返回 code 为 200 且 data 有值,表示有记录return {"code": 200, "oss_url": result.get("data")}except Exception as e:return {"code": 400, "message": "Request error", "Exception": str(e)}print("=======================================Check Success!!!")try:main_voice = {"ref_audio": audio_name, "ref_text": ref_text}voices = {"main": main_voice}for voice in voices:voices[voice]["ref_audio"], voices[voice]["ref_text"] = preprocess_ref_audio_text(voices[voice]["ref_audio"], voices[voice]["ref_text"])print("Voice:", voice)print("Ref_audio:", voices[voice]["ref_audio"])print("Ref_text:", voices[voice]["ref_text"])generated_audio_segments = []reg1 = r"(?=\[\w+\])"chunks = re.split(reg1, gen_text)reg2 = r"\[(\w+)\]"for text in chunks:if not text.strip():continuematch = re.match(reg2, text)if match:voice = match[1]else:print("No voice tag found, using main.")voice = "main"if voice not in voices:print(f"Voice {voice} not found, using main.")voice = "main"text = re.sub(reg2, "", text)gen_text = text.strip()ref_audio = voices[voice]["ref_audio"]ref_text = voices[voice]["ref_text"]print(f"Voice: {voice}")# 语音生成audio, final_sample_rate, spectragram = infer_process(ref_audio, ref_text, gen_text, model, vocoder, mel_spec_type='vocos', speed=speed)generated_audio_segments.append(audio)# if generated_audio_segments:final_wave = np.concatenate(generated_audio_segments)# 使用BytesIO在内存中处理音频文件with io.BytesIO() as audio_buffer:# 将音频写入内存缓冲区sf.write(audio_buffer, final_wave, final_sample_rate, format='wav')if remove_silence == 1:# 如果需要去除静音,需要先将数据加载到pydub中处理audio_buffer.seek(0) # 回到缓冲区开头sound = AudioSegment.from_file(audio_buffer, format="wav")# 去除静音sound = remove_silence_from_audio(sound) # 假设有这个函数# 将处理后的音频重新写入缓冲区audio_buffer.seek(0)audio_buffer.truncate()sound.export(audio_buffer, format="wav")# 上传到OSSaudio_buffer.seek(0) # 回到缓冲区开头以便读取oss_url = upload_to_oss(audio_buffer.read(), "wav") # 上传到 OSSprint(f"Uploaded to OSS: {oss_url}")# 将返回的 oss_url 插入数据库insert_url = "xxx/insertVoice"try:insert_response = requests.post(insert_url, data={"voice_text": gen_text,"voice_type": 1,"oss_url": oss_url,"anchor_id": voice_id,"type": 1})if insert_response.status_code == 200:# 插入成功,返回生成的 oss_urlreturn {"code": 200, "oss_url": oss_url}else:# 如果插入失败,返回错误信息return {"code": 400, "message": "Failed to insert oss_url into database"}except Exception as e:return {"code": 500, "message": "Error during TTS processing", "Exception": str(e)}# 返回 OSS URL# return {"code": 200, "oss_url": oss_url}# print("==========audio_file.filename: ",audio_file.filename)# return send_file(wave_path, mimetype="audio/wav", as_attachment=True, download_name="aaa.wav")except Exception as e:logger.error(f"Error generating audio: {str(e)}", exc_info=True)return jsonify({"error": str(e)}), 500 if __name__ == '__main__':try:# host="127.0.0.1"host="0.0.0.0"port=5010print(f"api接口地址 http://{host}:{port}")serve(app,host=host, port=port)except Exception as e:logger.error(f"An error occurred: {str(e)}")logger.error(traceback.format_exc())
总结
本篇文章主要分享了如何使用F5-TTS实现一个HTTP服务器,并通过该服务器提供文本到语音(TTS)服务。通过搭建这个服务器,用户可以方便地通过API接口进行文本转语音的请求。文章详细介绍了如何配置和运行该服务器,如何处理API请求,并展示了如何利用该服务将文本转换为自然流畅的语音输出。此外,文中还探讨了如何优化服务器的性能,确保高效的文本转语音处理,同时提供了相关的错误处理机制,确保用户体验的稳定性与可靠性。通过实现这个TTS服务,用户能够轻松将文本信息转化为语音形式,广泛应用于语音助手、自动化客户服务以及各类语音交互系统中。





)
:Memory)




:组合数据类型——元组类型:创建元组)


)



网络协议封装)
)