文章目录
- 简介
- 使用场景
- Apache Doris 主要应用于以下场景:
- 实时数据分析:
- 湖仓融合分析:
- 半结构化数据分析:
- Apache Doris 的核心特性
详细请看官方文档: Apache Doris介绍
简介
Apache Doris 是一款基于 MPP 架构的高性能、实时分析型数据库。它以高效、简单和统一的特性著称,能够在亚秒级的时间内返回海量数据的查询结果。Doris 既能支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。
基于这些优势,Apache Doris 非常适合用于报表分析、即席查询、统一数仓构建、数据湖联邦查询加速等场景。用户可以基于 Doris 构建大屏看板、用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
使用场景
数据源经过各种数据集成和加工处理后,通常会进入实时数据仓库 Doris 和离线湖仓(如 Hive、Iceberg 和 Hudi),广泛应用于 OLAP 分析场景,如下图所示:
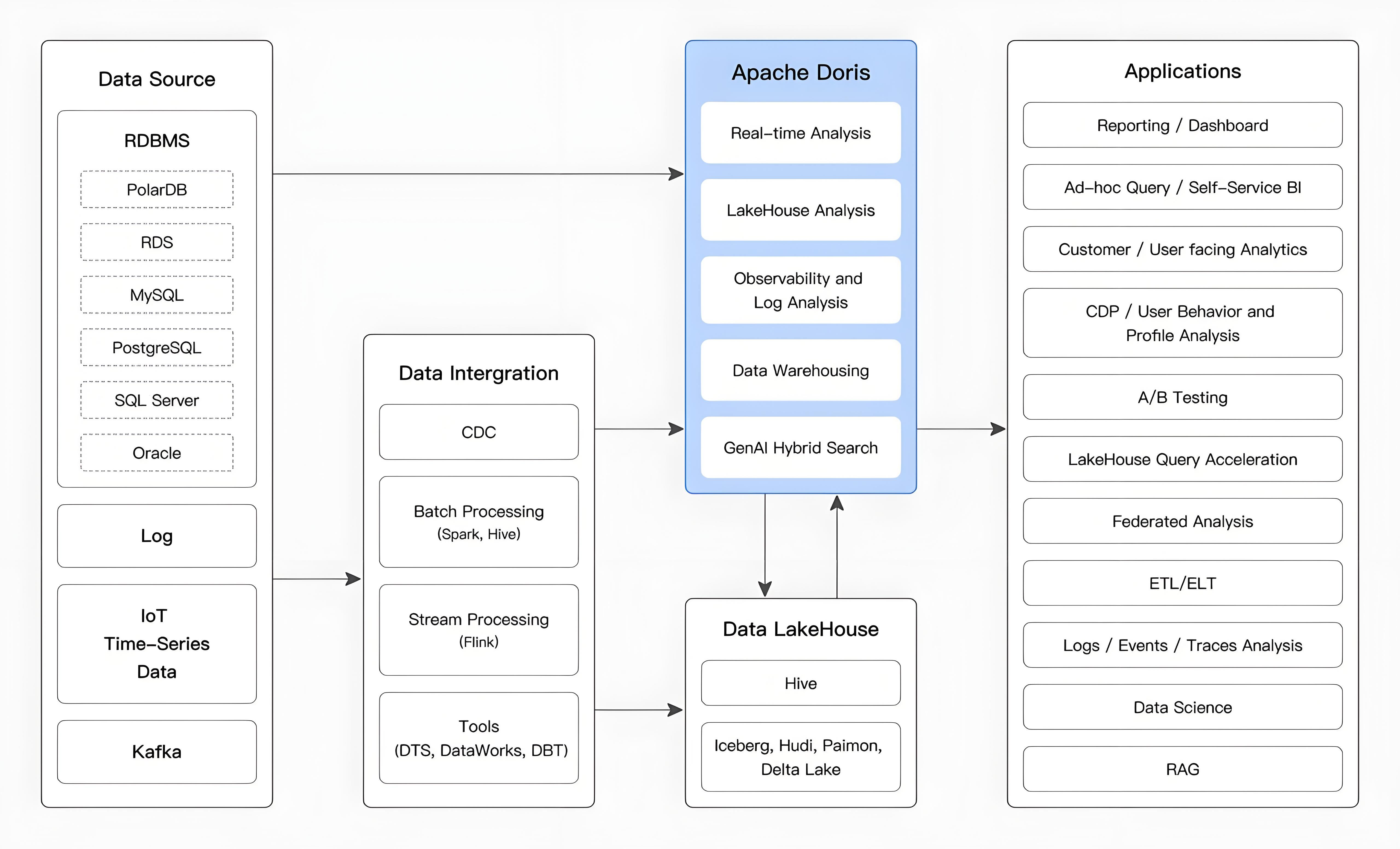
Apache Doris 主要应用于以下场景:
实时数据分析:
实时报表与实时决策: 为企业内外部提供实时更新的报表和仪表盘,支持自动化流程中的实时决策需求。
交互式探索分析: 提供多维数据分析能力,支持对数据进行快速的商业智能分析和即席查询(Ad Hoc),帮助用户在复杂数据中快速发现洞察。
用户行为与画像分析: 分析用户参与、留存、转化等行为,支持人群洞察和人群圈选等画像分析场景。湖仓融合分析:
湖仓查询加速: 通过高效的查询引擎加速湖仓数据的查询。
多源联邦分析: 支持跨多个数据源的联邦查询,简化架构并消除数据孤岛。
实时数据处理: 结合实时数据流和批量数据的处理能力,满足高并发和低延迟的复杂业务需求。半结构化数据分析:
日志与事件分析: 对分布式系统中的日志和事件数据进行实时或批量分析,帮助定位问题和优化性能。
Apache Doris 的核心特性
高可用: Apache Doris 的元数据和数据均采用多副本存储,并通过 Quorum 协议同步数据日志。当大多数副本完成写入后,即认为数据写入成功,从而确保即使少数节点发生故障,集群仍能保持可用性。Apache Doris 支持同城和异地容灾,能够实现双集群主备模式。当部分节点发生异常时,集群可以自动隔离故障节点,避免影响整体集群的可用性。
高兼容: Apache Doris 高度兼容 MySQL 协议,支持标准 SQL 语法,涵盖绝大部分 MySQL 和 Hive 函数。通过这种高兼容性,用户可以无缝迁移和集成现有的应用和工具。Apache Doris 支持 MySQL 生态,用户可以通过 MySQL 客户端工具连接 Doris,使得操作和维护更加便捷。同时,可以使用 MySQL 协议对 BI 报表工具与数据传输工具进行兼容适配,确保数据分析和数据传输过程中的高效性和稳定性。
实时数仓: 基于 Apache Doris 可以构建实时数据仓库服务。Apache Doris 提供了秒级数据入库能力,上游在线联机事务库中的增量变更可以秒级捕获到 Doris 中。依靠向量化引擎、MPP 架构及 Pipeline 执行引擎等加速手段,可以提供亚秒级数据查询能力,从而构建高性能、低延迟的实时数仓平台。
湖仓一体: Apache Doris 可以基于外部数据源(如数据湖或关系型数据库)构建湖仓一体架构,从而解决数据在数据湖和数据仓库之间无缝集成和自由流动的问题,帮助用户直接利用数据仓库的能力来解决数据湖中的数据分析问题,同时充分利用数据湖的数据管理能力来提升数据的价值。
灵活建模: Apache Doris 提供多种建模方式,如宽表模型、预聚合模型、星型/雪花模型等。数据导入时,可以通过 Flink、Spark 等计算引擎将数据打平成宽表写入到 Doris 中,也可以将数据直接导入到 Doris 中,通过视图、物化视图或实时多表关联等方式进行数据的建模操作。

)


:自定义实现一个自增的StatefulWidget组件)
![[AI8051U入门第十三步]W5500实现MQTT通信](http://pic.xiahunao.cn/[AI8051U入门第十三步]W5500实现MQTT通信)


![linux81 shell通配符:[list],‘‘ ``““](http://pic.xiahunao.cn/linux81 shell通配符:[list],‘‘ ``““)










 Server (Hardware) Architecture)