本地服务器端部署基于大模型的通用OCR项目——dots.ocr
- dots.ocr相关介绍
- 本地服务器端部署
- 第一步:安装cuda12.8与CUDNN8.9.7
- 第二步:创建项目所需的依赖环境
- 第三步:启动项目
- 第四步:测试
- 第五步:文本解析相关性测试
- 第六步:利用gradio部署服务项目
dots.ocr相关介绍
dots.ocr 是一个强大的多语言文档解析器,它在一个单一的视觉-语言模型中统一了布局检测和内容识别,同时保持良好的阅读顺序。尽管其基础是紧凑的1.7B参数LLM,但它实现了最先进的(SOTA)性能。
强大的性能: dots.ocr 在OmniDocBench上实现了文本、表格和阅读顺序的SOTA性能,同时在公式识别方面达到了与Doubao-1.5和gemini2.5-pro等更大模型相当的结果。
多语言支持: dots.ocr 对低资源语言展示了强大的解析能力,在我们内部的多语言文档基准测试中,在布局检测和内容识别方面都取得了决定性的优势。
统一且简单的架构: 通过利用单一的视觉-语言模型,dots.ocr 提供了一个比依赖复杂多模型流水线的传统方法更简洁的架构。通过简单地改变输入提示即可在任务之间切换,证明VLM可以与传统的检测模型如DocLayout-YOLO相比达到有竞争力的检测结果。
高效且快速的性能: 基于紧凑的1.7B LLM构建,dots.ocr 比许多基于更大基础的高性能模型提供了更快的推理速度。
本地服务器端部署
项目先决条件:
该项目官方要求的pytroch为2.7、vllm为0.9.1,并且由于该项目依赖于flash-attn==2.8.0.post2,该包的编译安装依赖于cuda版本为12.8,所以,需要项目需要较新版本的英伟达显卡驱动与CUDA12.8(要求是12.8)
第一步:安装cuda12.8与CUDNN8.9.7
下载地址依次是:
https://developer.nvidia.com/cuda-12-8-0-download-archive?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=22.04&target_type=runfile_local
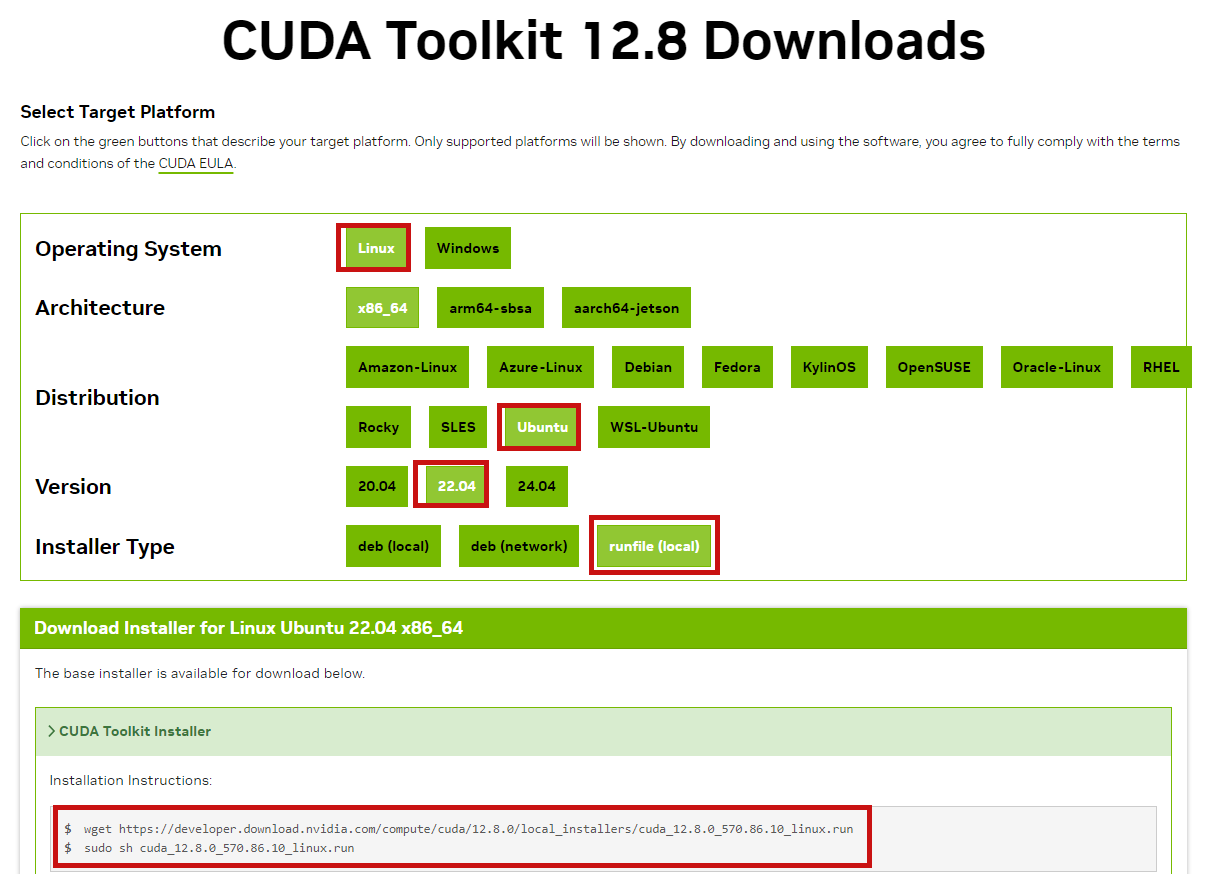
Ubutnu命令行运行如下指令:
下载cuda12.8
wget https://developer.download.nvidia.com/compute/cuda/12.8.0/local_installers/cuda_12.8.0_570.86.10_linux.run
安装cuda12.8
# 赋予权限
chmod +x cuda_12.8.0_570.86.10_linux.run
# 执行安装
./cuda_12.8.0_570.86.10_linux.run
修改~/.bashrc文件
vim ~/.bashrc
将如下内容添加到文件中
export CUDA_HOME=/usr/local/cuda-12.8
export PATH=$CUDA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH
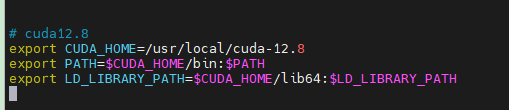
修改完后,执行如下指令以生效:
source ~/.bashrc
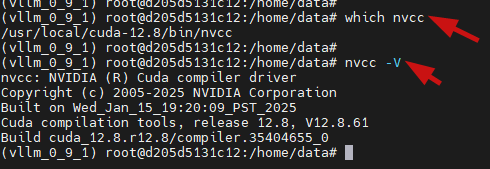
确保nvcc可以被找到
which nvcc
nvcc -V
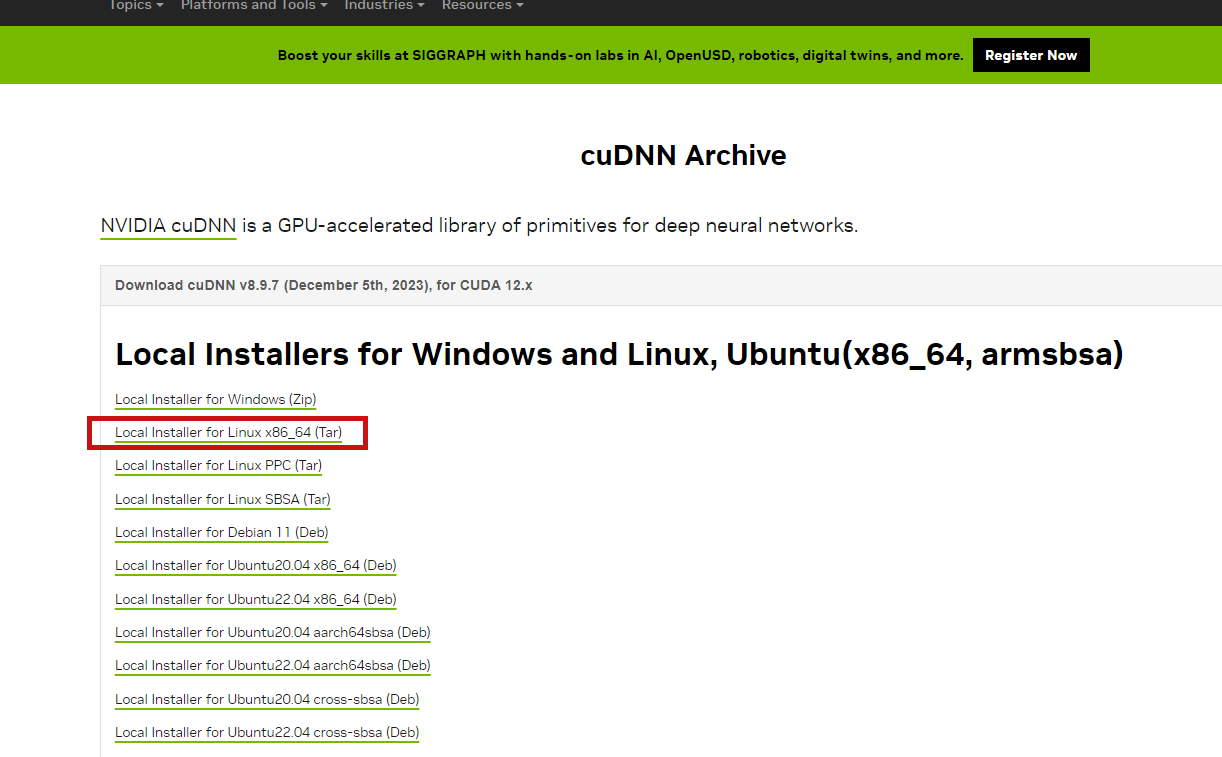
下载cudnn8.9.7
https://developer.nvidia.com/rdp/cudnn-archive
# 解压压缩包文件
tar -xvf cudnn-linux-x86_64-8.9.7.29_cuda12-archive.tar.xz
拷贝文件并授权
cd cudnn-linux-x86_64-8.9.7.29_cuda12-archivesudo cp include/cudnn*.h /usr/local/cuda-12.8/include/
sudo cp lib/libcudnn* /usr/local/cuda-12.8/lib64/
sudo chmod a+r /usr/local/cuda-12.8/include/cudnn*.h /usr/local/cuda-12.8/lib64/libcudnn*
验证是否成功
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2

第二步:创建项目所需的依赖环境
安装好Miniconda后,执行如下指令创建虚拟环境
# 创建
conda create -n vllm_0_9_1 python=3.12
# 激活
conda activate vllm_0_9_1
下载项目代码
git clone https://github.com/rednote-hilab/dots.ocr.git
安装依赖库
# 进入到项目目录内
cd dots.ocr# 执行如下语句
pip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu128 --default-timeout=100pip install vllm==0.9.1 --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simplepip install -e . --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple
模型下载
项目结构如下所示:
(vllm_0_9_1) root@d205d5131c12:/home/data/dots.ocr-master# tree -L 2
.
├── LICENSE
├── README.md
├── assets
│ ├── blog.md
│ ├── chart.png
│ ├── logo.png
│ ├── showcase
│ ├── showcase_origin
│ └── wechat.jpg
├── demo
│ ├── demo_gradio.py
│ ├── demo_gradio_annotion.py
│ ├── demo_hf.py
│ ├── demo_image1.jpg
│ ├── demo_pdf1.pdf
│ ├── demo_streamlit.py
│ ├── demo_vllm.py
│ └── launch_model_vllm.sh
├── docker
│ ├── Dockerfile
│ └── docker-compose.yml
├── dots_ocr
│ ├── __init__.py
│ ├── model
│ ├── parser.py
│ └── utils
├── dots_ocr.egg-info
│ ├── PKG-INFO
│ ├── SOURCES.txt
│ ├── dependency_links.txt
│ ├── requires.txt
│ └── top_level.txt
├── requirements.txt
├── setup.py
├── tools
│ └── download_model.py
└── weights└── DotsOCR12 directories, 26 files在项目根目录下执行如下指令下载模型:
python3 tools/download_model.py -t modelscope
第三步:启动项目
以下启动指令需要切换到项目根目录下执行
export hf_model_path=./weights/DotsOCR # Path to your downloaded model weights, Please use a directory name without periods (e.g., `DotsOCR` instead of `dots.ocr`) for the model save path. This is a temporary workaround pending our integration with Transformers.
export PYTHONPATH=$(dirname "$hf_model_path"):$PYTHONPATH
sed -i '/^from vllm\.entrypoints\.cli\.main import main$/a\
from DotsOCR import modeling_dots_ocr_vllm' `which vllm` # If you downloaded model weights by yourself, please replace `DotsOCR` by your model saved directory name, and remember to use a directory name without periods (e.g., `DotsOCR` instead of `dots.ocr`) # launch vllm server# 单张显卡
CUDA_VISIBLE_DEVICES=0 vllm serve ${hf_model_path} \--tensor-parallel-size 1 \--host 0.0.0.0 \--port 8070 \--gpu-memory-utilization 0.95 \--chat-template-content-format string \--served-model-name model \--trust-remote-code# If you get a ModuleNotFoundError: No module named 'DotsOCR', please check the note above on the saved model directory name.项目顺利启动成功:
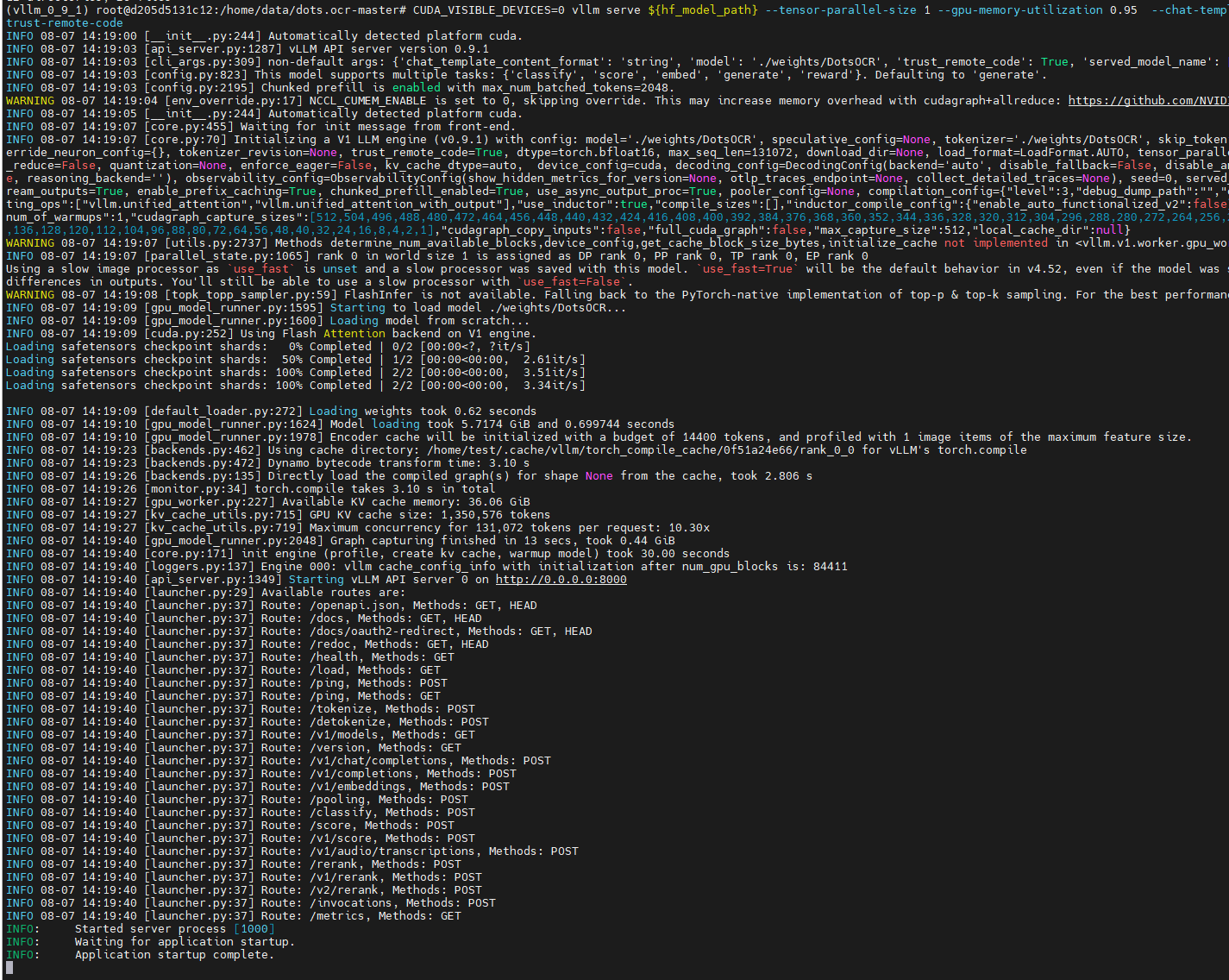
第四步:测试
上述vllm拉起项目后,便可运行官方自带的测试脚本进行测试:
在dots.ocr-master/demo目录下,有个名称为demo_vllm.py的脚本,内容如下:
import argparse
import osfrom openai import OpenAI
from transformers.utils.versions import require_version
from PIL import Image
import io
import base64
from dots_ocr.utils import dict_promptmode_to_prompt
from dots_ocr.model.inference import inference_with_vllmparser = argparse.ArgumentParser()
parser.add_argument("--ip", type=str, default="localhost")
parser.add_argument("--port", type=str, default="8000")
parser.add_argument("--model_name", type=str, default="model")
parser.add_argument("--prompt_mode", type=str, default="prompt_layout_all_en")args = parser.parse_args()require_version("openai>=1.5.0", "To fix: pip install openai>=1.5.0")def main():addr = f"http://{args.ip}:{args.port}/v1"image_path = "demo/demo_image1.jpg"prompt = dict_promptmode_to_prompt[args.prompt_mode]image = Image.open(image_path)response = inference_with_vllm(image,prompt, ip="localhost",port=8000,temperature=0.1,top_p=0.9,)print(f"response: {response}")if __name__ == "__main__":main()**注意:**如果在拉起vllm项目时修改了访问ip与端口号后,直接运行上述脚本会报错(原因是该脚本访问ip与端口号被写死)。
需要进行相应改动,修改完后的脚本如下:
import argparse
import osfrom openai import OpenAI
from transformers.utils.versions import require_version
from PIL import Image
import io
import base64
from dots_ocr.utils import dict_promptmode_to_prompt
from dots_ocr.model.inference import inference_with_vllmparser = argparse.ArgumentParser()
parser.add_argument("--ip", type=str, default="localhost")
parser.add_argument("--port", type=str, default="8070")
parser.add_argument("--model_name", type=str, default="model")
parser.add_argument("--prompt_mode", type=str, default="prompt_layout_all_en")args = parser.parse_args()require_version("openai>=1.5.0", "To fix: pip install openai>=1.5.0")def main():addr = f"http://{args.ip}:{args.port}/v1"image_path = "demo/demo_image1.jpg"prompt = dict_promptmode_to_prompt[args.prompt_mode]image = Image.open(image_path)response = inference_with_vllm(image,prompt, ip=args.ip,port=int(args.port),temperature=0.1,top_p=0.9,)print(f"response: {response}")if __name__ == "__main__":main()然后直接运行下属指令便可返回识别结果
python3 ./demo/demo_vllm.py --prompt_mode prompt_layout_all_en --ip 192.168.4.22 --port 8070
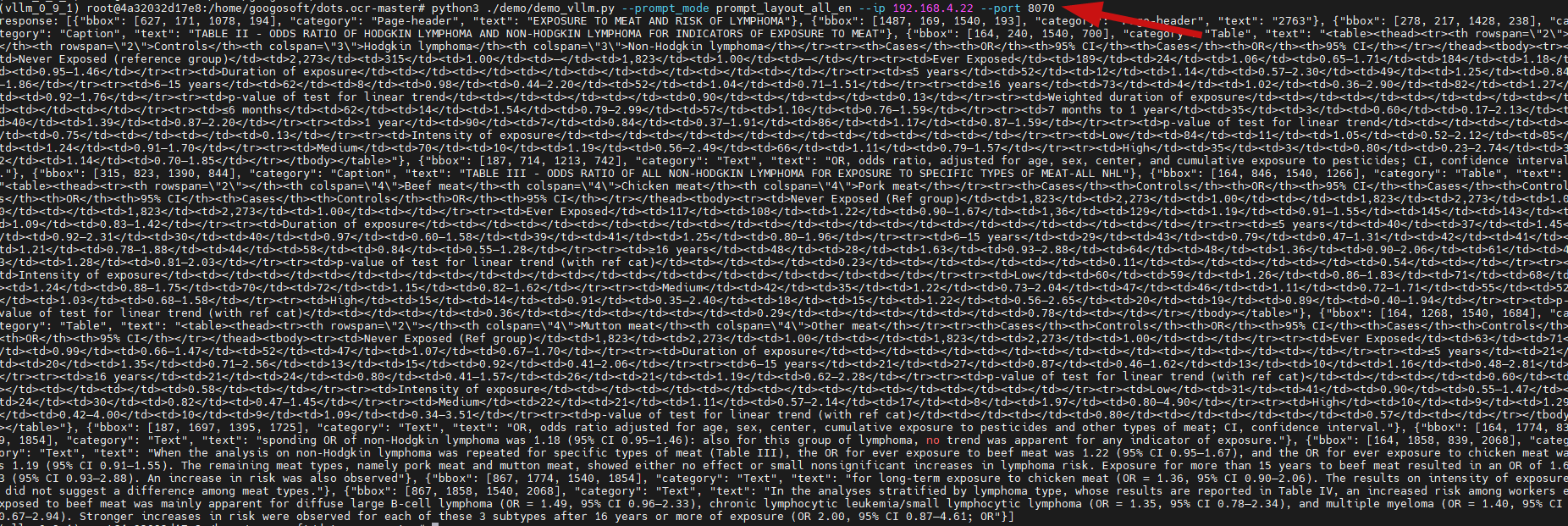
第五步:文本解析相关性测试
进入到dots.ocr-master/dots_ocr目录下,有个名为parser.py的文件,可以提供如下测试:
针对图像或 PDF 文件进行 版面分析(Layout Parsing)和文字识别(OCR)。每条命令根据不同的参数控制功能侧重。下面是详细解释:
# 基础命令:同时做版面检测 + OCR#对一张图片进行:#版面分析(如识别段落、标题、表格、图片区域等布局结构)#OCR 识别(提取其中的文字内容)
python3 dots_ocr/parser.py demo/demo_image1.jpg# -------------------------------------------------------------# 对一个 PDF 文件进行版面检测和 OCR。# 额外加了 --num_thread 64,说明:# 多线程解析 PDF 的每一页(尤其是多页 PDF),提高处理速度# 可以尝试更高线程数(如 --num_thread 128)以加速大文档处理
python3 dots_ocr/parser.py demo/demo_pdf1.pdf --num_thread 64 # try bigger num_threads for pdf with a large number of pages# 只做版面分析(不提取文字)
python3 dots_ocr/parser.py demo/demo_image1.jpg --prompt prompt_layout_only_en# 只做 OCR,不提取页眉页脚的文字 Parse text only, except Page-header and Page-footer
python3 dots_ocr/parser.py demo/demo_image1.jpg --prompt prompt_ocr# 对指定区域(bounding box)做 OCR+Layout 分析 Parse layout info by bbox
python3 dots_ocr/parser.py demo/demo_image1.jpg --prompt prompt_grounding_ocr --bbox 163 241 1536 705
如果上述vllm在启动模型时配置了相关的ip与端口,则在启动时需要加上–ip与–port
如下所示:
python3 dots_ocr/parser.py demo/demo_pdf1.pdf --num_thread 64 --ip 192.168.4.22 --port 8070
脚本代码如下所示:
import os
import json
from tqdm import tqdm
from multiprocessing.pool import ThreadPool, Pool
import argparsefrom dots_ocr.model.inference import inference_with_vllm
from dots_ocr.utils.consts import image_extensions, MIN_PIXELS, MAX_PIXELS
from dots_ocr.utils.image_utils import get_image_by_fitz_doc, fetch_image, smart_resize
from dots_ocr.utils.doc_utils import fitz_doc_to_image, load_images_from_pdf
from dots_ocr.utils.prompts import dict_promptmode_to_prompt
from dots_ocr.utils.layout_utils import post_process_output, draw_layout_on_image, pre_process_bboxes
from dots_ocr.utils.format_transformer import layoutjson2mdclass DotsOCRParser:"""parse image or pdf file"""def __init__(self, ip='localhost',port=8000,model_name='model',temperature=0.1,top_p=1.0,max_completion_tokens=16384,num_thread=64,dpi = 200, output_dir="./output", min_pixels=None,max_pixels=None,):self.dpi = dpi# default args for vllm serverself.ip = ipself.port = portself.model_name = model_name# default args for inferenceself.temperature = temperatureself.top_p = top_pself.max_completion_tokens = max_completion_tokensself.num_thread = num_threadself.output_dir = output_dirself.min_pixels = min_pixelsself.max_pixels = max_pixelsassert self.min_pixels is None or self.min_pixels >= MIN_PIXELSassert self.max_pixels is None or self.max_pixels <= MAX_PIXELSdef _inference_with_vllm(self, image, prompt):response = inference_with_vllm(image,prompt, model_name=self.model_name,ip=self.ip,port=self.port,temperature=self.temperature,top_p=self.top_p,max_completion_tokens=self.max_completion_tokens,)return responsedef get_prompt(self, prompt_mode, bbox=None, origin_image=None, image=None, min_pixels=None, max_pixels=None):prompt = dict_promptmode_to_prompt[prompt_mode]if prompt_mode == 'prompt_grounding_ocr':assert bbox is not Nonebboxes = [bbox]bbox = pre_process_bboxes(origin_image, bboxes, input_width=image.width, input_height=image.height, min_pixels=min_pixels, max_pixels=max_pixels)[0]prompt = prompt + str(bbox)return prompt# def post_process_results(self, response, prompt_mode, save_dir, save_name, origin_image, image, min_pixels, max_pixels)def _parse_single_image(self, origin_image, prompt_mode, save_dir, save_name, source="image", page_idx=0, bbox=None,fitz_preprocess=False,):min_pixels, max_pixels = self.min_pixels, self.max_pixelsif prompt_mode == "prompt_grounding_ocr":min_pixels = min_pixels or MIN_PIXELS # preprocess image to the final inputmax_pixels = max_pixels or MAX_PIXELSif min_pixels is not None: assert min_pixels >= MIN_PIXELS, f"min_pixels should >= {MIN_PIXELS}"if max_pixels is not None: assert max_pixels <= MAX_PIXELS, f"max_pixels should <+ {MAX_PIXELS}"if source == 'image' and fitz_preprocess:image = get_image_by_fitz_doc(origin_image, target_dpi=self.dpi)image = fetch_image(image, min_pixels=min_pixels, max_pixels=max_pixels)else:image = fetch_image(origin_image, min_pixels=min_pixels, max_pixels=max_pixels)input_height, input_width = smart_resize(image.height, image.width)prompt = self.get_prompt(prompt_mode, bbox, origin_image, image, min_pixels=min_pixels, max_pixels=max_pixels)response = self._inference_with_vllm(image, prompt)result = {'page_no': page_idx,"input_height": input_height,"input_width": input_width}if source == 'pdf':save_name = f"{save_name}_page_{page_idx}"if prompt_mode in ['prompt_layout_all_en', 'prompt_layout_only_en', 'prompt_grounding_ocr']:cells, filtered = post_process_output(response, prompt_mode, origin_image, image,min_pixels=min_pixels, max_pixels=max_pixels,)if filtered and prompt_mode != 'prompt_layout_only_en': # model output json failed, use filtered processjson_file_path = os.path.join(save_dir, f"{save_name}.json")with open(json_file_path, 'w') as w:json.dump(response, w, ensure_ascii=False)image_layout_path = os.path.join(save_dir, f"{save_name}.jpg")origin_image.save(image_layout_path)result.update({'layout_info_path': json_file_path,'layout_image_path': image_layout_path,})md_file_path = os.path.join(save_dir, f"{save_name}.md")with open(md_file_path, "w", encoding="utf-8") as md_file:md_file.write(cells)result.update({'md_content_path': md_file_path})result.update({'filtered': True})else:try:image_with_layout = draw_layout_on_image(origin_image, cells)except Exception as e:print(f"Error drawing layout on image: {e}")image_with_layout = origin_imagejson_file_path = os.path.join(save_dir, f"{save_name}.json")with open(json_file_path, 'w') as w:json.dump(cells, w, ensure_ascii=False)image_layout_path = os.path.join(save_dir, f"{save_name}.jpg")image_with_layout.save(image_layout_path)result.update({'layout_info_path': json_file_path,'layout_image_path': image_layout_path,})if prompt_mode != "prompt_layout_only_en": # no text md when detection onlymd_content = layoutjson2md(origin_image, cells, text_key='text')md_content_no_hf = layoutjson2md(origin_image, cells, text_key='text', no_page_hf=True) # used for clean output or metric of omnidocbench、olmbench md_file_path = os.path.join(save_dir, f"{save_name}.md")with open(md_file_path, "w", encoding="utf-8") as md_file:md_file.write(md_content)md_nohf_file_path = os.path.join(save_dir, f"{save_name}_nohf.md")with open(md_nohf_file_path, "w", encoding="utf-8") as md_file:md_file.write(md_content_no_hf)result.update({'md_content_path': md_file_path,'md_content_nohf_path': md_nohf_file_path,})else:image_layout_path = os.path.join(save_dir, f"{save_name}.jpg")origin_image.save(image_layout_path)result.update({'layout_image_path': image_layout_path,})md_content = responsemd_file_path = os.path.join(save_dir, f"{save_name}.md")with open(md_file_path, "w", encoding="utf-8") as md_file:md_file.write(md_content)result.update({'md_content_path': md_file_path,})return resultdef parse_image(self, input_path, filename, prompt_mode, save_dir, bbox=None, fitz_preprocess=False):origin_image = fetch_image(input_path)result = self._parse_single_image(origin_image, prompt_mode, save_dir, filename, source="image", bbox=bbox, fitz_preprocess=fitz_preprocess)result['file_path'] = input_pathreturn [result]def parse_pdf(self, input_path, filename, prompt_mode, save_dir):print(f"loading pdf: {input_path}")images_origin = load_images_from_pdf(input_path, dpi=self.dpi)total_pages = len(images_origin)tasks = [{"origin_image": image,"prompt_mode": prompt_mode,"save_dir": save_dir,"save_name": filename,"source":"pdf","page_idx": i,} for i, image in enumerate(images_origin)]def _execute_task(task_args):return self._parse_single_image(**task_args)num_thread = min(total_pages, self.num_thread)print(f"Parsing PDF with {total_pages} pages using {num_thread} threads...")results = []with ThreadPool(num_thread) as pool:with tqdm(total=total_pages, desc="Processing PDF pages") as pbar:for result in pool.imap_unordered(_execute_task, tasks):results.append(result)pbar.update(1)results.sort(key=lambda x: x["page_no"])for i in range(len(results)):results[i]['file_path'] = input_pathreturn resultsdef parse_file(self, input_path, output_dir="", prompt_mode="prompt_layout_all_en",bbox=None,fitz_preprocess=False):output_dir = output_dir or self.output_diroutput_dir = os.path.abspath(output_dir)filename, file_ext = os.path.splitext(os.path.basename(input_path))save_dir = os.path.join(output_dir, filename)os.makedirs(save_dir, exist_ok=True)if file_ext == '.pdf':results = self.parse_pdf(input_path, filename, prompt_mode, save_dir)elif file_ext in image_extensions:results = self.parse_image(input_path, filename, prompt_mode, save_dir, bbox=bbox, fitz_preprocess=fitz_preprocess)else:raise ValueError(f"file extension {file_ext} not supported, supported extensions are {image_extensions} and pdf")print(f"Parsing finished, results saving to {save_dir}")with open(os.path.join(output_dir, os.path.basename(filename)+'.jsonl'), 'w') as w:for result in results:w.write(json.dumps(result, ensure_ascii=False) + '\n')return resultsdef main():prompts = list(dict_promptmode_to_prompt.keys())parser = argparse.ArgumentParser(description="dots.ocr Multilingual Document Layout Parser",)parser.add_argument("input_path", type=str,help="Input PDF/image file path")parser.add_argument("--output", type=str, default="./output",help="Output directory (default: ./output)")parser.add_argument("--prompt", choices=prompts, type=str, default="prompt_layout_all_en",help="prompt to query the model, different prompts for different tasks")parser.add_argument('--bbox', type=int, nargs=4, metavar=('x1', 'y1', 'x2', 'y2'),help='should give this argument if you want to prompt_grounding_ocr')parser.add_argument("--ip", type=str, default="localhost",help="")parser.add_argument("--port", type=int, default=8000,help="")parser.add_argument("--model_name", type=str, default="model",help="")parser.add_argument("--temperature", type=float, default=0.1,help="")parser.add_argument("--top_p", type=float, default=1.0,help="")parser.add_argument("--dpi", type=int, default=200,help="")parser.add_argument("--max_completion_tokens", type=int, default=16384,help="")parser.add_argument("--num_thread", type=int, default=16,help="")# parser.add_argument(# "--fitz_preprocess", type=bool, default=False,# help="False will use tikz dpi upsample pipeline, good for images which has been render with low dpi, but maybe result in higher computational costs"# )parser.add_argument("--min_pixels", type=int, default=None,help="")parser.add_argument("--max_pixels", type=int, default=None,help="")args = parser.parse_args()dots_ocr_parser = DotsOCRParser(ip=args.ip,port=args.port,model_name=args.model_name,temperature=args.temperature,top_p=args.top_p,max_completion_tokens=args.max_completion_tokens,num_thread=args.num_thread,dpi=args.dpi,output_dir=args.output, min_pixels=args.min_pixels,max_pixels=args.max_pixels,)result = dots_ocr_parser.parse_file(args.input_path, prompt_mode=args.prompt,bbox=args.bbox,)if __name__ == "__main__":main()
输出结果
- 结构化布局数据 (demo_image1.json):包含检测到的布局元素(包括它们的边界框、类别和提取的文本)的 JSON 文件。
- 处理后的 Markdown 文件 (demo_image1.md):从所有检测到的单元格拼接文本生成的 Markdown 文件。
另提供了一个版本 demo_image1_nohf.md,它排除了页面头部和底部,以兼容如 Omnidocbench 和 olmOCR-bench 等基准测试。
- 布局可视化 (demo_image1.jpg):原始图像上绘制了检测到的布局边界框。
第六步:利用gradio部署服务项目
思路是:vllm已经加载模型启动项目,使用gradio启动一个服务,访问vllm加载的模型,返回识别结果
在dots.ocr-master/demo目录下,修改demo_gradio.py文件,配置成vllm项目的ip与端口,如下所示
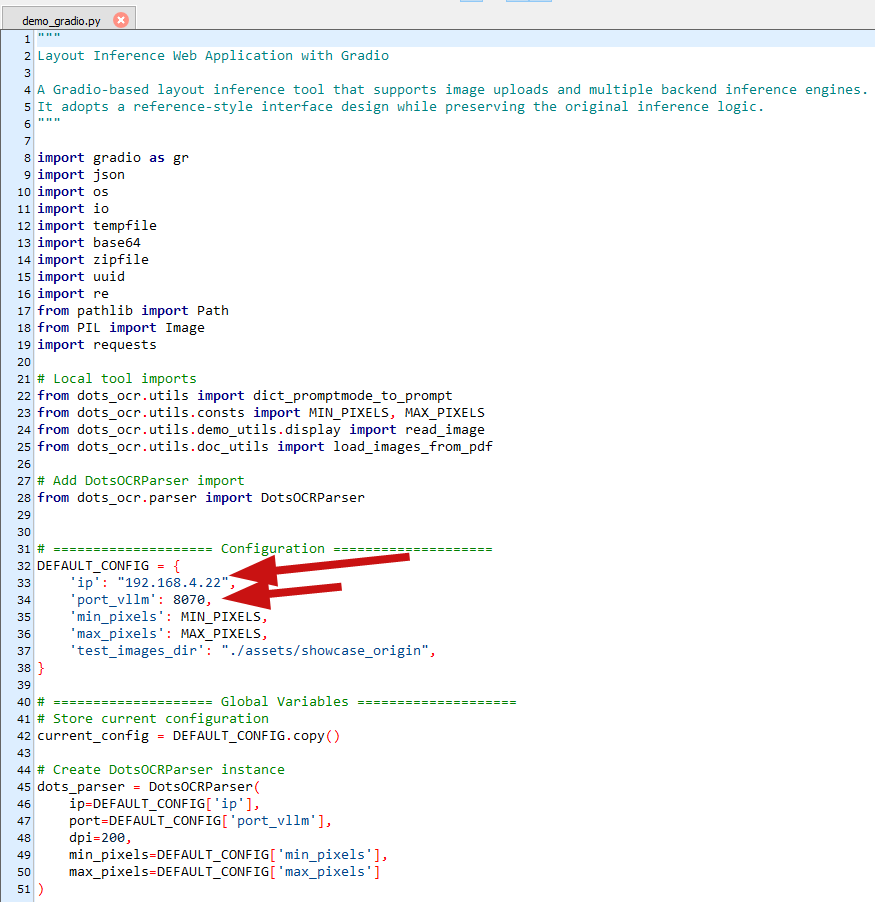
执行如下指令启动gradio服务
python demo/demo_gradio.py
脚本代码:
"""
Layout Inference Web Application with GradioA Gradio-based layout inference tool that supports image uploads and multiple backend inference engines.
It adopts a reference-style interface design while preserving the original inference logic.
"""import gradio as gr
import json
import os
import io
import tempfile
import base64
import zipfile
import uuid
import re
from pathlib import Path
from PIL import Image
import requests# Local tool imports
from dots_ocr.utils import dict_promptmode_to_prompt
from dots_ocr.utils.consts import MIN_PIXELS, MAX_PIXELS
from dots_ocr.utils.demo_utils.display import read_image
from dots_ocr.utils.doc_utils import load_images_from_pdf# Add DotsOCRParser import
from dots_ocr.parser import DotsOCRParser# ==================== Configuration ====================
DEFAULT_CONFIG = {'ip': "192.168.4.22",'port_vllm': 8070,'min_pixels': MIN_PIXELS,'max_pixels': MAX_PIXELS,'test_images_dir': "./assets/showcase_origin",
}# ==================== Global Variables ====================
# Store current configuration
current_config = DEFAULT_CONFIG.copy()# Create DotsOCRParser instance
dots_parser = DotsOCRParser(ip=DEFAULT_CONFIG['ip'],port=DEFAULT_CONFIG['port_vllm'],dpi=200,min_pixels=DEFAULT_CONFIG['min_pixels'],max_pixels=DEFAULT_CONFIG['max_pixels']
)# Store processing results
processing_results = {'original_image': None,'processed_image': None,'layout_result': None,'markdown_content': None,'cells_data': None,'temp_dir': None,'session_id': None,'result_paths': None,'pdf_results': None # Store multi-page PDF results
}# PDF caching mechanism
pdf_cache = {"images": [],"current_page": 0,"total_pages": 0,"file_type": None, # 'image' or 'pdf'"is_parsed": False, # Whether it has been parsed"results": [] # Store parsing results for each page
}def read_image_v2(img):"""Reads an image, supports URLs and local paths"""if isinstance(img, str) and img.startswith(("http://", "https://")):with requests.get(img, stream=True) as response:response.raise_for_status()img = Image.open(io.BytesIO(response.content))elif isinstance(img, str):img, _, _ = read_image(img, use_native=True)elif isinstance(img, Image.Image):passelse:raise ValueError(f"Invalid image type: {type(img)}")return imgdef load_file_for_preview(file_path):"""Loads a file for preview, supports PDF and image files"""global pdf_cacheif not file_path or not os.path.exists(file_path):return None, "<div id='page_info_box'>0 / 0</div>"file_ext = os.path.splitext(file_path)[1].lower()if file_ext == '.pdf':try:# Read PDF and convert to images (one image per page)pages = load_images_from_pdf(file_path)pdf_cache["file_type"] = "pdf"except Exception as e:return None, f"<div id='page_info_box'>PDF loading failed: {str(e)}</div>"elif file_ext in ['.jpg', '.jpeg', '.png']:# For image files, read directly as a single-page imagetry:image = Image.open(file_path)pages = [image]pdf_cache["file_type"] = "image"except Exception as e:return None, f"<div id='page_info_box'>Image loading failed: {str(e)}</div>"else:return None, "<div id='page_info_box'>Unsupported file format</div>"pdf_cache["images"] = pagespdf_cache["current_page"] = 0pdf_cache["total_pages"] = len(pages)pdf_cache["is_parsed"] = Falsepdf_cache["results"] = []return pages[0], f"<div id='page_info_box'>1 / {len(pages)}</div>"def turn_page(direction):"""Page turning function"""global pdf_cacheif not pdf_cache["images"]:return None, "<div id='page_info_box'>0 / 0</div>", "", ""if direction == "prev":pdf_cache["current_page"] = max(0, pdf_cache["current_page"] - 1)elif direction == "next":pdf_cache["current_page"] = min(pdf_cache["total_pages"] - 1, pdf_cache["current_page"] + 1)index = pdf_cache["current_page"]current_image = pdf_cache["images"][index] # Use the original image by defaultpage_info = f"<div id='page_info_box'>{index + 1} / {pdf_cache['total_pages']}</div>"# If parsed, display the results for the current pagecurrent_md = ""current_md_raw = ""current_json = ""if pdf_cache["is_parsed"] and index < len(pdf_cache["results"]):result = pdf_cache["results"][index]if 'md_content' in result:# Get the raw markdown contentcurrent_md_raw = result['md_content']# Process the content after LaTeX renderingcurrent_md = result['md_content'] if result['md_content'] else ""if 'cells_data' in result:try:current_json = json.dumps(result['cells_data'], ensure_ascii=False, indent=2)except:current_json = str(result.get('cells_data', ''))# Use the image with layout boxes (if available)if 'layout_image' in result and result['layout_image']:current_image = result['layout_image']return current_image, page_info, current_jsondef get_test_images():"""Gets the list of test images"""test_images = []test_dir = current_config['test_images_dir']if os.path.exists(test_dir):test_images = [os.path.join(test_dir, name) for name in os.listdir(test_dir) if name.lower().endswith(('.png', '.jpg', '.jpeg', '.pdf'))]return test_imagesdef convert_image_to_base64(image):"""Converts a PIL image to base64 encoding"""buffered = io.BytesIO()image.save(buffered, format="PNG")img_str = base64.b64encode(buffered.getvalue()).decode()return f"data:image/png;base64,{img_str}"def create_temp_session_dir():"""Creates a unique temporary directory for each processing request"""session_id = uuid.uuid4().hex[:8]temp_dir = os.path.join(tempfile.gettempdir(), f"dots_ocr_demo_{session_id}")os.makedirs(temp_dir, exist_ok=True)return temp_dir, session_iddef parse_image_with_high_level_api(parser, image, prompt_mode, fitz_preprocess=False):"""Processes using the high-level API parse_image from DotsOCRParser"""# Create a temporary session directorytemp_dir, session_id = create_temp_session_dir()try:# Save the PIL Image as a temporary filetemp_image_path = os.path.join(temp_dir, f"input_{session_id}.png")image.save(temp_image_path, "PNG")# Use the high-level API parse_imagefilename = f"demo_{session_id}"results = parser.parse_image(# input_path=temp_image_path,input_path=image,filename=filename, prompt_mode=prompt_mode,save_dir=temp_dir,fitz_preprocess=fitz_preprocess)# Parse the resultsif not results:raise ValueError("No results returned from parser")result = results[0] # parse_image returns a list with a single result# Read the result fileslayout_image = Nonecells_data = Nonemd_content = Noneraw_response = Nonefiltered = False# Read the layout imageif 'layout_image_path' in result and os.path.exists(result['layout_image_path']):layout_image = Image.open(result['layout_image_path'])# Read the JSON dataif 'layout_info_path' in result and os.path.exists(result['layout_info_path']):with open(result['layout_info_path'], 'r', encoding='utf-8') as f:cells_data = json.load(f)# Read the Markdown contentif 'md_content_path' in result and os.path.exists(result['md_content_path']):with open(result['md_content_path'], 'r', encoding='utf-8') as f:md_content = f.read()# Check for the raw response file (when JSON parsing fails)if 'filtered' in result:filtered = result['filtered']return {'layout_image': layout_image,'cells_data': cells_data,'md_content': md_content,'filtered': filtered,'temp_dir': temp_dir,'session_id': session_id,'result_paths': result,'input_width': result['input_width'],'input_height': result['input_height'],}except Exception as e:# Clean up the temporary directory on errorimport shutilif os.path.exists(temp_dir):shutil.rmtree(temp_dir, ignore_errors=True)raise edef parse_pdf_with_high_level_api(parser, pdf_path, prompt_mode):"""Processes using the high-level API parse_pdf from DotsOCRParser"""# Create a temporary session directorytemp_dir, session_id = create_temp_session_dir()try:# Use the high-level API parse_pdffilename = f"demo_{session_id}"results = parser.parse_pdf(input_path=pdf_path,filename=filename,prompt_mode=prompt_mode,save_dir=temp_dir)# Parse the resultsif not results:raise ValueError("No results returned from parser")# Handle multi-page resultsparsed_results = []all_md_content = []all_cells_data = []for i, result in enumerate(results):page_result = {'page_no': result.get('page_no', i),'layout_image': None,'cells_data': None,'md_content': None,'filtered': False}# Read the layout imageif 'layout_image_path' in result and os.path.exists(result['layout_image_path']):page_result['layout_image'] = Image.open(result['layout_image_path'])# Read the JSON dataif 'layout_info_path' in result and os.path.exists(result['layout_info_path']):with open(result['layout_info_path'], 'r', encoding='utf-8') as f:page_result['cells_data'] = json.load(f)all_cells_data.extend(page_result['cells_data'])# Read the Markdown contentif 'md_content_path' in result and os.path.exists(result['md_content_path']):with open(result['md_content_path'], 'r', encoding='utf-8') as f:page_content = f.read()page_result['md_content'] = page_contentall_md_content.append(page_content)# Check for the raw response file (when JSON parsing fails)page_result['filtered'] = Falseif 'filtered' in page_result:page_result['filtered'] = page_result['filtered']parsed_results.append(page_result)# Merge the content of all pagescombined_md = "\n\n---\n\n".join(all_md_content) if all_md_content else ""return {'parsed_results': parsed_results,'combined_md_content': combined_md,'combined_cells_data': all_cells_data,'temp_dir': temp_dir,'session_id': session_id,'total_pages': len(results)}except Exception as e:# Clean up the temporary directory on errorimport shutilif os.path.exists(temp_dir):shutil.rmtree(temp_dir, ignore_errors=True)raise e# ==================== Core Processing Function ====================
def process_image_inference(test_image_input, file_input,prompt_mode, server_ip, server_port, min_pixels, max_pixels,fitz_preprocess=False):"""Core function to handle image/PDF inference"""global current_config, processing_results, dots_parser, pdf_cache# First, clean up previous processing results to avoid confusion with the download buttonif processing_results.get('temp_dir') and os.path.exists(processing_results['temp_dir']):import shutiltry:shutil.rmtree(processing_results['temp_dir'], ignore_errors=True)except Exception as e:print(f"Failed to clean up previous temporary directory: {e}")# Reset processing resultsprocessing_results = {'original_image': None,'processed_image': None,'layout_result': None,'markdown_content': None,'cells_data': None,'temp_dir': None,'session_id': None,'result_paths': None,'pdf_results': None}# Update configurationcurrent_config.update({'ip': server_ip,'port_vllm': server_port,'min_pixels': min_pixels,'max_pixels': max_pixels})# Update parser configurationdots_parser.ip = server_ipdots_parser.port = server_portdots_parser.min_pixels = min_pixelsdots_parser.max_pixels = max_pixels# Determine the input sourceinput_file_path = Noneimage = None# Prioritize file input (supports PDF)if file_input is not None:input_file_path = file_inputfile_ext = os.path.splitext(input_file_path)[1].lower()if file_ext == '.pdf':# PDF file processingtry:return process_pdf_file(input_file_path, prompt_mode)except Exception as e:return None, f"PDF processing failed: {e}", "", "", gr.update(value=None), None, ""elif file_ext in ['.jpg', '.jpeg', '.png']:# Image file processingtry:image = Image.open(input_file_path)except Exception as e:return None, f"Failed to read image file: {e}", "", "", gr.update(value=None), None, ""# If no file input, check the test image inputif image is None:if test_image_input and test_image_input != "":file_ext = os.path.splitext(test_image_input)[1].lower()if file_ext == '.pdf':return process_pdf_file(test_image_input, prompt_mode)else:try:image = read_image_v2(test_image_input)except Exception as e:return None, f"Failed to read test image: {e}", "", "", gr.update(value=None), gr.update(value=None), None, ""if image is None:return None, "Please upload image/PDF file or select test image", "", "", gr.update(value=None), None, ""try:# Clear PDF cache (for image processing)pdf_cache["images"] = []pdf_cache["current_page"] = 0pdf_cache["total_pages"] = 0pdf_cache["is_parsed"] = Falsepdf_cache["results"] = []# Process using the high-level API of DotsOCRParseroriginal_image = imageparse_result = parse_image_with_high_level_api(dots_parser, image, prompt_mode, fitz_preprocess)# Extract parsing resultslayout_image = parse_result['layout_image']cells_data = parse_result['cells_data']md_content = parse_result['md_content']filtered = parse_result['filtered']# Handle parsing failure caseif filtered:# JSON parsing failed, only text content is availableinfo_text = f"""
**Image Information:**
- Original Size: {original_image.width} x {original_image.height}
- Processing: JSON parsing failed, using cleaned text output
- Server: {current_config['ip']}:{current_config['port_vllm']}
- Session ID: {parse_result['session_id']}"""# Store resultsprocessing_results.update({'original_image': original_image,'processed_image': None,'layout_result': None,'markdown_content': md_content,'cells_data': None,'temp_dir': parse_result['temp_dir'],'session_id': parse_result['session_id'],'result_paths': parse_result['result_paths']})return (original_image, # No layout imageinfo_text,md_content,md_content, # Display raw markdown textgr.update(visible=False), # Hide download buttonNone, # Page info"" # Current page JSON output)# JSON parsing successful case# Save the raw markdown content (before LaTeX processing)md_content_raw = md_content or "No markdown content generated"# Store resultsprocessing_results.update({'original_image': original_image,'processed_image': None, # High-level API does not return processed_image'layout_result': layout_image,'markdown_content': md_content,'cells_data': cells_data,'temp_dir': parse_result['temp_dir'],'session_id': parse_result['session_id'],'result_paths': parse_result['result_paths']})# Prepare display informationnum_elements = len(cells_data) if cells_data else 0info_text = f"""
**Image Information:**
- Original Size: {original_image.width} x {original_image.height}
- Model Input Size: {parse_result['input_width']} x {parse_result['input_height']}
- Server: {current_config['ip']}:{current_config['port_vllm']}
- Detected {num_elements} layout elements
- Session ID: {parse_result['session_id']}"""# Current page JSON outputcurrent_json = ""if cells_data:try:current_json = json.dumps(cells_data, ensure_ascii=False, indent=2)except:current_json = str(cells_data)# Create the download ZIP filedownload_zip_path = Noneif parse_result['temp_dir']:download_zip_path = os.path.join(parse_result['temp_dir'], f"layout_results_{parse_result['session_id']}.zip")try:with zipfile.ZipFile(download_zip_path, 'w', zipfile.ZIP_DEFLATED) as zipf:for root, dirs, files in os.walk(parse_result['temp_dir']):for file in files:if file.endswith('.zip'):continuefile_path = os.path.join(root, file)arcname = os.path.relpath(file_path, parse_result['temp_dir'])zipf.write(file_path, arcname)except Exception as e:print(f"Failed to create download ZIP: {e}")download_zip_path = Nonereturn (layout_image,info_text,md_content or "No markdown content generated",md_content_raw, # Raw markdown textgr.update(value=download_zip_path, visible=True) if download_zip_path else gr.update(visible=False), # Set the download fileNone, # Page info (not displayed for image processing)current_json # Current page JSON)except Exception as e:return None, f"Error during processing: {e}", "", "", gr.update(value=None), None, ""def process_pdf_file(pdf_path, prompt_mode):"""Dedicated function for processing PDF files"""global pdf_cache, processing_results, dots_parsertry:# First, load the PDF for previewpreview_image, page_info = load_file_for_preview(pdf_path)# Parse the PDF using DotsOCRParserpdf_result = parse_pdf_with_high_level_api(dots_parser, pdf_path, prompt_mode)# Update the PDF cachepdf_cache["is_parsed"] = Truepdf_cache["results"] = pdf_result['parsed_results']# Handle LaTeX table renderingcombined_md = pdf_result['combined_md_content']combined_md_raw = combined_md or "No markdown content generated" # Save the raw content# Store resultsprocessing_results.update({'original_image': None,'processed_image': None,'layout_result': None,'markdown_content': combined_md,'cells_data': pdf_result['combined_cells_data'],'temp_dir': pdf_result['temp_dir'],'session_id': pdf_result['session_id'],'result_paths': None,'pdf_results': pdf_result['parsed_results']})# Prepare display informationtotal_elements = len(pdf_result['combined_cells_data'])info_text = f"""
**PDF Information:**
- Total Pages: {pdf_result['total_pages']}
- Server: {current_config['ip']}:{current_config['port_vllm']}
- Total Detected Elements: {total_elements}
- Session ID: {pdf_result['session_id']}"""# Content of the current page (first page)current_page_md = ""current_page_md_raw = ""current_page_json = ""current_page_layout_image = preview_image # Use the original preview image by defaultif pdf_cache["results"] and len(pdf_cache["results"]) > 0:current_result = pdf_cache["results"][0]if current_result['md_content']:# Raw markdown contentcurrent_page_md_raw = current_result['md_content']# Process the content after LaTeX renderingcurrent_page_md = current_result['md_content']if current_result['cells_data']:try:current_page_json = json.dumps(current_result['cells_data'], ensure_ascii=False, indent=2)except:current_page_json = str(current_result['cells_data'])# Use the image with layout boxes (if available)if 'layout_image' in current_result and current_result['layout_image']:current_page_layout_image = current_result['layout_image']# Create the download ZIP filedownload_zip_path = Noneif pdf_result['temp_dir']:download_zip_path = os.path.join(pdf_result['temp_dir'], f"layout_results_{pdf_result['session_id']}.zip")try:with zipfile.ZipFile(download_zip_path, 'w', zipfile.ZIP_DEFLATED) as zipf:for root, dirs, files in os.walk(pdf_result['temp_dir']):for file in files:if file.endswith('.zip'):continuefile_path = os.path.join(root, file)arcname = os.path.relpath(file_path, pdf_result['temp_dir'])zipf.write(file_path, arcname)except Exception as e:print(f"Failed to create download ZIP: {e}")download_zip_path = Nonereturn (current_page_layout_image, # Use the image with layout boxesinfo_text,combined_md or "No markdown content generated", # Display the markdown for the entire PDFcombined_md_raw or "No markdown content generated", # Display the raw markdown for the entire PDFgr.update(value=download_zip_path, visible=True) if download_zip_path else gr.update(visible=False), # Set the download filepage_info,current_page_json)except Exception as e:# Reset the PDF cachepdf_cache["images"] = []pdf_cache["current_page"] = 0pdf_cache["total_pages"] = 0pdf_cache["is_parsed"] = Falsepdf_cache["results"] = []raise edef clear_all_data():"""Clears all data"""global processing_results, pdf_cache# Clean up the temporary directoryif processing_results.get('temp_dir') and os.path.exists(processing_results['temp_dir']):import shutiltry:shutil.rmtree(processing_results['temp_dir'], ignore_errors=True)except Exception as e:print(f"Failed to clean up temporary directory: {e}")# Reset processing resultsprocessing_results = {'original_image': None,'processed_image': None,'layout_result': None,'markdown_content': None,'cells_data': None,'temp_dir': None,'session_id': None,'result_paths': None,'pdf_results': None}# Reset the PDF cachepdf_cache = {"images": [],"current_page": 0,"total_pages": 0,"file_type": None,"is_parsed": False,"results": []}return (None, # Clear file input"", # Clear test image selectionNone, # Clear result image"Waiting for processing results...", # Reset info display"## Waiting for processing results...", # Reset Markdown display"馃晲 Waiting for parsing result...", # Clear raw Markdown textgr.update(visible=False), # Hide download button"<div id='page_info_box'>0 / 0</div>", # Reset page info"馃晲 Waiting for parsing result..." # Clear current page JSON)def update_prompt_display(prompt_mode):"""Updates the prompt display content"""return dict_promptmode_to_prompt[prompt_mode]# ==================== Gradio Interface ====================
def create_gradio_interface():"""Creates the Gradio interface"""# CSS styles, matching the reference stylecss = """#parse_button {background: #FF576D !important; /* !important 纭繚瑕嗙洊涓婚榛樿鏍峰紡 */border-color: #FF576D !important;}/* 榧犳爣鎮仠鏃剁殑棰滆壊 */#parse_button:hover {background: #F72C49 !important;border-color: #F72C49 !important;}#page_info_html {display: flex;align-items: center;justify-content: center;height: 100%;margin: 0 12px;}#page_info_box {padding: 8px 20px;font-size: 16px;border: 1px solid #bbb;border-radius: 8px;background-color: #f8f8f8;text-align: center;min-width: 80px;box-shadow: 0 1px 3px rgba(0,0,0,0.1);}#markdown_output {min-height: 800px;overflow: auto;}footer {visibility: hidden;}#info_box {padding: 10px;background-color: #f8f9fa;border-radius: 8px;border: 1px solid #dee2e6;margin: 10px 0;font-size: 14px;}#result_image {border-radius: 8px;}#markdown_tabs {height: 100%;}"""with gr.Blocks(theme="ocean", css=css, title='dots.ocr') as demo:# Titlegr.HTML("""<div style="display: flex; align-items: center; justify-content: center; margin-bottom: 20px;"><h1 style="margin: 0; font-size: 2em;">馃攳 dots.ocr</h1></div><div style="text-align: center; margin-bottom: 10px;"><em>Supports image/PDF layout analysis and structured output</em></div>""")with gr.Row():# Left side: Input and Configurationwith gr.Column(scale=1, elem_id="left-panel"):gr.Markdown("### 馃摜 Upload & Select")file_input = gr.File(label="Upload PDF/Image", type="filepath", file_types=[".pdf", ".jpg", ".jpeg", ".png"],)test_images = get_test_images()test_image_input = gr.Dropdown(label="Or Select an Example",choices=[""] + test_images,value="",)gr.Markdown("### 鈿欙笍 Prompt & Actions")prompt_mode = gr.Dropdown(label="Select Prompt",choices=["prompt_layout_all_en", "prompt_layout_only_en", "prompt_ocr"],value="prompt_layout_all_en",show_label=True)# Display current prompt contentprompt_display = gr.Textbox(label="Current Prompt Content",value=dict_promptmode_to_prompt[list(dict_promptmode_to_prompt.keys())[0]],lines=4,max_lines=8,interactive=False,show_copy_button=True)with gr.Row():process_btn = gr.Button("馃攳 Parse", variant="primary", scale=2, elem_id="parse_button")clear_btn = gr.Button("馃棏锔?Clear", variant="secondary", scale=1)with gr.Accordion("馃洜锔?Advanced Configuration", open=False):fitz_preprocess = gr.Checkbox(label="Enable fitz_preprocess for images", value=True,info="Processes image via a PDF-like pipeline (image->pdf->200dpi image). Recommended if your image DPI is low.")with gr.Row():server_ip = gr.Textbox(label="Server IP", value=DEFAULT_CONFIG['ip'])server_port = gr.Number(label="Port", value=DEFAULT_CONFIG['port_vllm'], precision=0)with gr.Row():min_pixels = gr.Number(label="Min Pixels", value=DEFAULT_CONFIG['min_pixels'], precision=0)max_pixels = gr.Number(label="Max Pixels", value=DEFAULT_CONFIG['max_pixels'], precision=0)# Right side: Result Displaywith gr.Column(scale=6, variant="compact"):with gr.Row():# Result Imagewith gr.Column(scale=3):gr.Markdown("### 馃憗锔?File Preview")result_image = gr.Image(label="Layout Preview",visible=True,height=800,show_label=False)# Page navigation (shown during PDF preview)with gr.Row():prev_btn = gr.Button("猬?Previous", size="sm")page_info = gr.HTML(value="<div id='page_info_box'>0 / 0</div>", elem_id="page_info_html")next_btn = gr.Button("Next 鉃?, size="sm")# Info Displayinfo_display = gr.Markdown("Waiting for processing results...",elem_id="info_box")# Markdown Resultwith gr.Column(scale=3):gr.Markdown("### 鉁旓笍 Result Display")with gr.Tabs(elem_id="markdown_tabs"):with gr.TabItem("Markdown Render Preview"):md_output = gr.Markdown("## Please click the parse button to parse or select for single-task recognition...",label="Markdown Preview",max_height=600,latex_delimiters=[{"left": "$$", "right": "$$", "display": True},{"left": "$", "right": "$", "display": False},],show_copy_button=False,elem_id="markdown_output")with gr.TabItem("Markdown Raw Text"):md_raw_output = gr.Textbox(value="馃晲 Waiting for parsing result...",label="Markdown Raw Text",max_lines=100,lines=38,show_copy_button=True,elem_id="markdown_output",show_label=False)with gr.TabItem("Current Page JSON"):current_page_json = gr.Textbox(value="馃晲 Waiting for parsing result...",label="Current Page JSON",max_lines=100,lines=38,show_copy_button=True,elem_id="markdown_output",show_label=False)# Download Buttonwith gr.Row():download_btn = gr.DownloadButton("猬囷笍 Download Results",visible=False)# When the prompt mode changes, update the display contentprompt_mode.change(fn=update_prompt_display,inputs=prompt_mode,outputs=prompt_display,show_progress=False)# Show preview on file uploadfile_input.upload(fn=load_file_for_preview,inputs=file_input,outputs=[result_image, page_info],show_progress=False)# Page navigationprev_btn.click(fn=lambda: turn_page("prev"), outputs=[result_image, page_info, current_page_json],show_progress=False)next_btn.click(fn=lambda: turn_page("next"), outputs=[result_image, page_info, current_page_json],show_progress=False)process_btn.click(fn=process_image_inference,inputs=[test_image_input, file_input,prompt_mode, server_ip, server_port, min_pixels, max_pixels, fitz_preprocess],outputs=[result_image, info_display, md_output, md_raw_output,download_btn, page_info, current_page_json],show_progress=True)clear_btn.click(fn=clear_all_data,outputs=[file_input, test_image_input,result_image, info_display, md_output, md_raw_output,download_btn, page_info, current_page_json],show_progress=False)return demo# ==================== Main Program ====================
if __name__ == "__main__":demo = create_gradio_interface()demo.queue().launch(server_name="0.0.0.0", server_port=8091, debug=True))


)


![[自动化Adapt] 录制引擎 | iframe 穿透 | NTP | AIOSQLite | 数据分片](http://pic.xiahunao.cn/[自动化Adapt] 录制引擎 | iframe 穿透 | NTP | AIOSQLite | 数据分片)






)





