核心数据结构分析
1. struct eventpoll (epoll 实例核心结构)
c
struct eventpoll {struct mutex mtx; // 保护 epoll 结构的互斥锁wait_queue_head_t wq; // epoll_wait() 使用的等待队列wait_queue_head_t poll_wait; // 文件 poll() 使用的等待队列struct list_head rdllist; // 就绪事件链表 (核心数据结构)struct rb_root_cached rbr; // 红黑树根节点 (管理所有监控的fd)struct epitem *ovflist; // 单链表 (事件传输期间临时存放就绪事件)struct wakeup_source *ws; // 电源管理唤醒源struct user_struct *user; // 所属用户struct file *file; // 关联的文件结构// ... 其他字段
};
2. struct epitem (被监控的文件描述符)
c
struct epitem {struct rb_node rbn; // 红黑树节点struct list_head rdllink; // 就绪链表节点struct epoll_filefd ffd; // 文件描述符和文件指针 {file*, fd}int nwait; // 等待队列数量struct list_head pwqlist; // poll 等待队列链表struct eventpoll *ep; // 所属的 eventpollstruct epoll_event event; // 用户设置的事件// ... 其他字段
};
3. struct eppoll_entry (等待队列包装)
c
struct eppoll_entry {struct list_head llink; // 链表节点struct epitem *base; // 关联的 epitemwait_queue_entry_t wait; // 等待队列项 (核心)wait_queue_head_t *whead; // 目标等待队列头
};
核心机制详解
1. 事件注册 (epoll_ctl)
c
SYSCALL_DEFINE4(epoll_ctl, ...)└─ ep_insert() // 核心插入逻辑├─ 初始化 epitem├─ 初始化 poll_table (ep_ptable_queue_proc)├─ 调用文件的 poll 方法├─ 将 epitem 加入红黑树└─ 若文件已就绪,加入就绪列表
2. 事件等待 (epoll_wait)
c
SYSCALL_DEFINE4(epoll_wait, ...)└─ do_epoll_wait()└─ ep_poll()├─ 检查就绪列表 (rdllist)├─ 无事件时阻塞等待└─ 有事件时调用 ep_send_events()
3. 事件回调机制
c
// 关键回调函数 static int ep_poll_callback(wait_queue_entry_t *wait, ...)├─ 检查事件是否匹配├─ 若正在传输事件 (ovflist),加入临时链表├─ 否则加入就绪链表 (rdllist)└─ 唤醒等待进程
4. 事件传输机制
c
static int ep_send_events(...)└─ ep_scan_ready_list(ep_send_events_proc)├─ 锁定状态下转移就绪列表├─ 处理事件 (无锁状态)├─ 检查水平触发(LT)模式└─ 合并新产生的事件
关键技术亮点
1. 高效数据结构
-
红黑树:管理所有监控的文件描述符 (O(log n) 操作)
-
就绪链表:双链表维护已就绪事件 (O(1) 访问)
-
ovflist单链表:解决事件传输期间的新事件问题
2. 回调驱动机制
-
通过 eppoll_entry 注册回调到文件等待队列
-
事件发生时直接加入就绪链表,避免全量扫描
3. 水平触发(LT)与边缘触发(ET)
c
// ep_send_events_proc 中的处理逻辑
if (!(epi->event.events & EPOLLET)) { // LT 模式list_add_tail(&epi->rdllink, &ep->rdllist); // 重新加入就绪列表
}
4. 就绪列表扫描优化
c
static __poll_t ep_scan_ready_list(...)
{// 1. 锁定状态下转移就绪列表到临时列表// 2. 解锁状态下处理临时列表// 3. 处理期间新事件通过 ovflist 收集// 4. 完成后合并 ovflist 和剩余事件
}
性能优化措施
1. 避免数据拷贝
-
内核到用户空间直接传递就绪事件
-
使用共享内存减少拷贝 (io_uring 更进一步)
2. 减少系统调用
-
单次 epoll_wait 返回多个事件
-
就绪事件 O(1) 获取
3. 多路复用优化
c
#ifdef CONFIG_NET_RX_BUSY_POLL
static void ep_busy_loop(struct eventpoll *ep, int nonblock)
{// 在特定场景下使用忙等优化
}
#endif
关键函数说明
| 函数 | 功能 |
|---|---|
ep_insert() | 添加监控的文件描述符 |
ep_remove() | 移除监控的文件描述符 |
ep_poll_callback() | 事件触发时的核心回调 |
ep_scan_ready_list() | 安全处理就绪事件列表 |
ep_send_events_proc() | 向用户空间传递事件 |
ep_poll() | epoll_wait 的核心实现 |
总结
Linux epoll 实现通过以下设计实现高性能:
-
红黑树高效管理海量文件描述符
-
就绪链表实现O(1)事件获取
-
回调机制避免无效轮询
-
双阶段处理(就绪列表扫描)减少锁竞争
-
水平/边缘触发模式灵活适配不同场景
这些设计使epoll在管理大量并发连接时,性能远超select/poll,成为高性能网络服务的核心基础设施。

/** fs/eventpoll.c (Efficient event retrieval implementation)* Copyright (C) 2001,...,2009 Davide Libenzi** This program is free software; you can redistribute it and/or modify* it under the terms of the GNU General Public License as published by* the Free Software Foundation; either version 2 of the License, or* (at your option) any later version.** Davide Libenzi <davidel@xmailserver.org>**/#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/sched/signal.h>
#include <linux/fs.h>
#include <linux/file.h>
#include <linux/signal.h>
#include <linux/errno.h>
#include <linux/mm.h>
#include <linux/slab.h>
#include <linux/poll.h>
#include <linux/string.h>
#include <linux/list.h>
#include <linux/hash.h>
#include <linux/spinlock.h>
#include <linux/syscalls.h>
#include <linux/rbtree.h>
#include <linux/wait.h>
#include <linux/eventpoll.h>
#include <linux/mount.h>
#include <linux/bitops.h>
#include <linux/mutex.h>
#include <linux/anon_inodes.h>
#include <linux/device.h>
#include <linux/uaccess.h>
#include <asm/io.h>
#include <asm/mman.h>
#include <linux/atomic.h>
#include <linux/proc_fs.h>
#include <linux/seq_file.h>
#include <linux/compat.h>
#include <linux/rculist.h>
#include <net/busy_poll.h>/** LOCKING:* There are three level of locking required by epoll :** 1) epmutex (mutex)* 2) ep->mtx (mutex)* 3) ep->wq.lock (spinlock)** The acquire order is the one listed above, from 1 to 3.* We need a spinlock (ep->wq.lock) because we manipulate objects* from inside the poll callback, that might be triggered from* a wake_up() that in turn might be called from IRQ context.* So we can't sleep inside the poll callback and hence we need* a spinlock. During the event transfer loop (from kernel to* user space) we could end up sleeping due a copy_to_user(), so* we need a lock that will allow us to sleep. This lock is a* mutex (ep->mtx). It is acquired during the event transfer loop,* during epoll_ctl(EPOLL_CTL_DEL) and during eventpoll_release_file().* Then we also need a global mutex to serialize eventpoll_release_file()* and ep_free().* This mutex is acquired by ep_free() during the epoll file* cleanup path and it is also acquired by eventpoll_release_file()* if a file has been pushed inside an epoll set and it is then* close()d without a previous call to epoll_ctl(EPOLL_CTL_DEL).* It is also acquired when inserting an epoll fd onto another epoll* fd. We do this so that we walk the epoll tree and ensure that this* insertion does not create a cycle of epoll file descriptors, which* could lead to deadlock. We need a global mutex to prevent two* simultaneous inserts (A into B and B into A) from racing and* constructing a cycle without either insert observing that it is* going to.* It is necessary to acquire multiple "ep->mtx"es at once in the* case when one epoll fd is added to another. In this case, we* always acquire the locks in the order of nesting (i.e. after* epoll_ctl(e1, EPOLL_CTL_ADD, e2), e1->mtx will always be acquired* before e2->mtx). Since we disallow cycles of epoll file* descriptors, this ensures that the mutexes are well-ordered. In* order to communicate this nesting to lockdep, when walking a tree* of epoll file descriptors, we use the current recursion depth as* the lockdep subkey.* It is possible to drop the "ep->mtx" and to use the global* mutex "epmutex" (together with "ep->wq.lock") to have it working,* but having "ep->mtx" will make the interface more scalable.* Events that require holding "epmutex" are very rare, while for* normal operations the epoll private "ep->mtx" will guarantee* a better scalability.*//* Epoll private bits inside the event mask */
#define EP_PRIVATE_BITS (EPOLLWAKEUP | EPOLLONESHOT | EPOLLET | EPOLLEXCLUSIVE)#define EPOLLINOUT_BITS (EPOLLIN | EPOLLOUT)#define EPOLLEXCLUSIVE_OK_BITS (EPOLLINOUT_BITS | EPOLLERR | EPOLLHUP | \EPOLLWAKEUP | EPOLLET | EPOLLEXCLUSIVE)/* Maximum number of nesting allowed inside epoll sets */
#define EP_MAX_NESTS 4#define EP_MAX_EVENTS (INT_MAX / sizeof(struct epoll_event))#define EP_UNACTIVE_PTR ((void *) -1L)#define EP_ITEM_COST (sizeof(struct epitem) + sizeof(struct eppoll_entry))struct epoll_filefd {struct file *file;int fd;
} __packed;/** Structure used to track possible nested calls, for too deep recursions* and loop cycles.*/
struct nested_call_node {struct list_head llink;void *cookie;void *ctx;
};/** This structure is used as collector for nested calls, to check for* maximum recursion dept and loop cycles.*/
struct nested_calls {struct list_head tasks_call_list;spinlock_t lock;
};/** Each file descriptor added to the eventpoll interface will* have an entry of this type linked to the "rbr" RB tree.* Avoid increasing the size of this struct, there can be many thousands* of these on a server and we do not want this to take another cache line.*/
struct epitem {union {/* RB tree node links this structure to the eventpoll RB tree */struct rb_node rbn;/* Used to free the struct epitem */struct rcu_head rcu;};/* List header used to link this structure to the eventpoll ready list */struct list_head rdllink;/** Works together "struct eventpoll"->ovflist in keeping the* single linked chain of items.*/struct epitem *next;/* The file descriptor information this item refers to */struct epoll_filefd ffd;/* Number of active wait queue attached to poll operations */int nwait;/* List containing poll wait queues */struct list_head pwqlist;/* The "container" of this item */struct eventpoll *ep;/* List header used to link this item to the "struct file" items list */struct list_head fllink;/* wakeup_source used when EPOLLWAKEUP is set */struct wakeup_source __rcu *ws;/* The structure that describe the interested events and the source fd */struct epoll_event event;
};/** This structure is stored inside the "private_data" member of the file* structure and represents the main data structure for the eventpoll* interface.** Access to it is protected by the lock inside wq.*/
struct eventpoll {/** This mutex is used to ensure that files are not removed* while epoll is using them. This is held during the event* collection loop, the file cleanup path, the epoll file exit* code and the ctl operations.*/struct mutex mtx;/* Wait queue used by sys_epoll_wait() */wait_queue_head_t wq;/* Wait queue used by file->poll() */wait_queue_head_t poll_wait;/* List of ready file descriptors */struct list_head rdllist;/* RB tree root used to store monitored fd structs */struct rb_root_cached rbr;/** This is a single linked list that chains all the "struct epitem" that* happened while transferring ready events to userspace w/out* holding ->wq.lock.*/struct epitem *ovflist;/* wakeup_source used when ep_scan_ready_list is running */struct wakeup_source *ws;/* The user that created the eventpoll descriptor */struct user_struct *user;struct file *file;/* used to optimize loop detection check */int visited;struct list_head visited_list_link;#ifdef CONFIG_NET_RX_BUSY_POLL/* used to track busy poll napi_id */unsigned int napi_id;
#endif
};/* Wait structure used by the poll hooks */
struct eppoll_entry {/* List header used to link this structure to the "struct epitem" */struct list_head llink;/* The "base" pointer is set to the container "struct epitem" */struct epitem *base;/** Wait queue item that will be linked to the target file wait* queue head.*/wait_queue_entry_t wait;/* The wait queue head that linked the "wait" wait queue item */wait_queue_head_t *whead;
};/* Wrapper struct used by poll queueing */
struct ep_pqueue {poll_table pt;struct epitem *epi;
};/* Used by the ep_send_events() function as callback private data */
struct ep_send_events_data {int maxevents;struct epoll_event __user *events;int res;
};/** Configuration options available inside /proc/sys/fs/epoll/*/
/* Maximum number of epoll watched descriptors, per user */
static long max_user_watches __read_mostly;/** This mutex is used to serialize ep_free() and eventpoll_release_file().*/
static DEFINE_MUTEX(epmutex);/* Used to check for epoll file descriptor inclusion loops */
static struct nested_calls poll_loop_ncalls;/* Slab cache used to allocate "struct epitem" */
static struct kmem_cache *epi_cache __read_mostly;/* Slab cache used to allocate "struct eppoll_entry" */
static struct kmem_cache *pwq_cache __read_mostly;/* Visited nodes during ep_loop_check(), so we can unset them when we finish */
static LIST_HEAD(visited_list);/** List of files with newly added links, where we may need to limit the number* of emanating paths. Protected by the epmutex.*/
static LIST_HEAD(tfile_check_list);#ifdef CONFIG_SYSCTL#include <linux/sysctl.h>static long zero;
static long long_max = LONG_MAX;struct ctl_table epoll_table[] = {{.procname = "max_user_watches",.data = &max_user_watches,.maxlen = sizeof(max_user_watches),.mode = 0644,.proc_handler = proc_doulongvec_minmax,.extra1 = &zero,.extra2 = &long_max,},{ }
};
#endif /* CONFIG_SYSCTL */static const struct file_operations eventpoll_fops;static inline int is_file_epoll(struct file *f)
{return f->f_op == &eventpoll_fops;
}/* Setup the structure that is used as key for the RB tree */
static inline void ep_set_ffd(struct epoll_filefd *ffd,struct file *file, int fd)
{ffd->file = file;ffd->fd = fd;
}/* Compare RB tree keys */
static inline int ep_cmp_ffd(struct epoll_filefd *p1,struct epoll_filefd *p2)
{return (p1->file > p2->file ? +1:(p1->file < p2->file ? -1 : p1->fd - p2->fd));
}/* Tells us if the item is currently linked */
static inline int ep_is_linked(struct epitem *epi)
{return !list_empty(&epi->rdllink);
}static inline struct eppoll_entry *ep_pwq_from_wait(wait_queue_entry_t *p)
{return container_of(p, struct eppoll_entry, wait);
}/* Get the "struct epitem" from a wait queue pointer */
static inline struct epitem *ep_item_from_wait(wait_queue_entry_t *p)
{return container_of(p, struct eppoll_entry, wait)->base;
}/* Get the "struct epitem" from an epoll queue wrapper */
static inline struct epitem *ep_item_from_epqueue(poll_table *p)
{return container_of(p, struct ep_pqueue, pt)->epi;
}/* Tells if the epoll_ctl(2) operation needs an event copy from userspace */
static inline int ep_op_has_event(int op)
{return op != EPOLL_CTL_DEL;
}/* Initialize the poll safe wake up structure */
static void ep_nested_calls_init(struct nested_calls *ncalls)
{INIT_LIST_HEAD(&ncalls->tasks_call_list);spin_lock_init(&ncalls->lock);
}/*** ep_events_available - Checks if ready events might be available.** @ep: Pointer to the eventpoll context.** Returns: Returns a value different than zero if ready events are available,* or zero otherwise.*/
static inline int ep_events_available(struct eventpoll *ep)
{return !list_empty(&ep->rdllist) || ep->ovflist != EP_UNACTIVE_PTR;
}#ifdef CONFIG_NET_RX_BUSY_POLL
static bool ep_busy_loop_end(void *p, unsigned long start_time)
{struct eventpoll *ep = p;return ep_events_available(ep) || busy_loop_timeout(start_time);
}/** Busy poll if globally on and supporting sockets found && no events,* busy loop will return if need_resched or ep_events_available.** we must do our busy polling with irqs enabled*/
static void ep_busy_loop(struct eventpoll *ep, int nonblock)
{unsigned int napi_id = READ_ONCE(ep->napi_id);if ((napi_id >= MIN_NAPI_ID) && net_busy_loop_on())napi_busy_loop(napi_id, nonblock ? NULL : ep_busy_loop_end, ep);
}static inline void ep_reset_busy_poll_napi_id(struct eventpoll *ep)
{if (ep->napi_id)ep->napi_id = 0;
}/** Set epoll busy poll NAPI ID from sk.*/
static inline void ep_set_busy_poll_napi_id(struct epitem *epi)
{struct eventpoll *ep;unsigned int napi_id;struct socket *sock;struct sock *sk;int err;if (!net_busy_loop_on())return;sock = sock_from_file(epi->ffd.file, &err);if (!sock)return;sk = sock->sk;if (!sk)return;napi_id = READ_ONCE(sk->sk_napi_id);ep = epi->ep;/* Non-NAPI IDs can be rejected* or* Nothing to do if we already have this ID*/if (napi_id < MIN_NAPI_ID || napi_id == ep->napi_id)return;/* record NAPI ID for use in next busy poll */ep->napi_id = napi_id;
}#elsestatic inline void ep_busy_loop(struct eventpoll *ep, int nonblock)
{
}static inline void ep_reset_busy_poll_napi_id(struct eventpoll *ep)
{
}static inline void ep_set_busy_poll_napi_id(struct epitem *epi)
{
}#endif /* CONFIG_NET_RX_BUSY_POLL *//*** ep_call_nested - Perform a bound (possibly) nested call, by checking* that the recursion limit is not exceeded, and that* the same nested call (by the meaning of same cookie) is* no re-entered.** @ncalls: Pointer to the nested_calls structure to be used for this call.* @max_nests: Maximum number of allowed nesting calls.* @nproc: Nested call core function pointer.* @priv: Opaque data to be passed to the @nproc callback.* @cookie: Cookie to be used to identify this nested call.* @ctx: This instance context.** Returns: Returns the code returned by the @nproc callback, or -1 if* the maximum recursion limit has been exceeded.*/
static int ep_call_nested(struct nested_calls *ncalls, int max_nests,int (*nproc)(void *, void *, int), void *priv,void *cookie, void *ctx)
{int error, call_nests = 0;unsigned long flags;struct list_head *lsthead = &ncalls->tasks_call_list;struct nested_call_node *tncur;struct nested_call_node tnode;spin_lock_irqsave(&ncalls->lock, flags);/** Try to see if the current task is already inside this wakeup call.* We use a list here, since the population inside this set is always* very much limited.*/list_for_each_entry(tncur, lsthead, llink) {if (tncur->ctx == ctx &&(tncur->cookie == cookie || ++call_nests > max_nests)) {/** Ops ... loop detected or maximum nest level reached.* We abort this wake by breaking the cycle itself.*/error = -1;goto out_unlock;}}/* Add the current task and cookie to the list */tnode.ctx = ctx;tnode.cookie = cookie;list_add(&tnode.llink, lsthead);spin_unlock_irqrestore(&ncalls->lock, flags);/* Call the nested function */error = (*nproc)(priv, cookie, call_nests);/* Remove the current task from the list */spin_lock_irqsave(&ncalls->lock, flags);list_del(&tnode.llink);
out_unlock:spin_unlock_irqrestore(&ncalls->lock, flags);return error;
}/** As described in commit 0ccf831cb lockdep: annotate epoll* the use of wait queues used by epoll is done in a very controlled* manner. Wake ups can nest inside each other, but are never done* with the same locking. For example:** dfd = socket(...);* efd1 = epoll_create();* efd2 = epoll_create();* epoll_ctl(efd1, EPOLL_CTL_ADD, dfd, ...);* epoll_ctl(efd2, EPOLL_CTL_ADD, efd1, ...);** When a packet arrives to the device underneath "dfd", the net code will* issue a wake_up() on its poll wake list. Epoll (efd1) has installed a* callback wakeup entry on that queue, and the wake_up() performed by the* "dfd" net code will end up in ep_poll_callback(). At this point epoll* (efd1) notices that it may have some event ready, so it needs to wake up* the waiters on its poll wait list (efd2). So it calls ep_poll_safewake()* that ends up in another wake_up(), after having checked about the* recursion constraints. That are, no more than EP_MAX_POLLWAKE_NESTS, to* avoid stack blasting.** When CONFIG_DEBUG_LOCK_ALLOC is enabled, make sure lockdep can handle* this special case of epoll.*/
#ifdef CONFIG_DEBUG_LOCK_ALLOCstatic struct nested_calls poll_safewake_ncalls;static int ep_poll_wakeup_proc(void *priv, void *cookie, int call_nests)
{unsigned long flags;wait_queue_head_t *wqueue = (wait_queue_head_t *)cookie;spin_lock_irqsave_nested(&wqueue->lock, flags, call_nests + 1);wake_up_locked_poll(wqueue, EPOLLIN);spin_unlock_irqrestore(&wqueue->lock, flags);return 0;
}static void ep_poll_safewake(wait_queue_head_t *wq)
{int this_cpu = get_cpu();ep_call_nested(&poll_safewake_ncalls, EP_MAX_NESTS,ep_poll_wakeup_proc, NULL, wq, (void *) (long) this_cpu);put_cpu();
}#elsestatic void ep_poll_safewake(wait_queue_head_t *wq)
{wake_up_poll(wq, EPOLLIN);
}#endifstatic void ep_remove_wait_queue(struct eppoll_entry *pwq)
{wait_queue_head_t *whead;rcu_read_lock();/** If it is cleared by POLLFREE, it should be rcu-safe.* If we read NULL we need a barrier paired with* smp_store_release() in ep_poll_callback(), otherwise* we rely on whead->lock.*/whead = smp_load_acquire(&pwq->whead);if (whead)remove_wait_queue(whead, &pwq->wait);rcu_read_unlock();
}/** This function unregisters poll callbacks from the associated file* descriptor. Must be called with "mtx" held (or "epmutex" if called from* ep_free).*/
static void ep_unregister_pollwait(struct eventpoll *ep, struct epitem *epi)
{struct list_head *lsthead = &epi->pwqlist;struct eppoll_entry *pwq;while (!list_empty(lsthead)) {pwq = list_first_entry(lsthead, struct eppoll_entry, llink);list_del(&pwq->llink);ep_remove_wait_queue(pwq);kmem_cache_free(pwq_cache, pwq);}
}/* call only when ep->mtx is held */
static inline struct wakeup_source *ep_wakeup_source(struct epitem *epi)
{return rcu_dereference_check(epi->ws, lockdep_is_held(&epi->ep->mtx));
}/* call only when ep->mtx is held */
static inline void ep_pm_stay_awake(struct epitem *epi)
{struct wakeup_source *ws = ep_wakeup_source(epi);if (ws)__pm_stay_awake(ws);
}static inline bool ep_has_wakeup_source(struct epitem *epi)
{return rcu_access_pointer(epi->ws) ? true : false;
}/* call when ep->mtx cannot be held (ep_poll_callback) */
static inline void ep_pm_stay_awake_rcu(struct epitem *epi)
{struct wakeup_source *ws;rcu_read_lock();ws = rcu_dereference(epi->ws);if (ws)__pm_stay_awake(ws);rcu_read_unlock();
}/*** ep_scan_ready_list - Scans the ready list in a way that makes possible for* the scan code, to call f_op->poll(). Also allows for* O(NumReady) performance.** @ep: Pointer to the epoll private data structure.* @sproc: Pointer to the scan callback.* @priv: Private opaque data passed to the @sproc callback.* @depth: The current depth of recursive f_op->poll calls.* @ep_locked: caller already holds ep->mtx** Returns: The same integer error code returned by the @sproc callback.*/
static __poll_t ep_scan_ready_list(struct eventpoll *ep,__poll_t (*sproc)(struct eventpoll *,struct list_head *, void *),void *priv, int depth, bool ep_locked)
{__poll_t res;int pwake = 0;struct epitem *epi, *nepi;LIST_HEAD(txlist);lockdep_assert_irqs_enabled();/** We need to lock this because we could be hit by* eventpoll_release_file() and epoll_ctl().*/if (!ep_locked)mutex_lock_nested(&ep->mtx, depth);/** Steal the ready list, and re-init the original one to the* empty list. Also, set ep->ovflist to NULL so that events* happening while looping w/out locks, are not lost. We cannot* have the poll callback to queue directly on ep->rdllist,* because we want the "sproc" callback to be able to do it* in a lockless way.*/spin_lock_irq(&ep->wq.lock);list_splice_init(&ep->rdllist, &txlist);ep->ovflist = NULL;spin_unlock_irq(&ep->wq.lock);/** Now call the callback function.*/res = (*sproc)(ep, &txlist, priv);spin_lock_irq(&ep->wq.lock);/** During the time we spent inside the "sproc" callback, some* other events might have been queued by the poll callback.* We re-insert them inside the main ready-list here.*/for (nepi = ep->ovflist; (epi = nepi) != NULL;nepi = epi->next, epi->next = EP_UNACTIVE_PTR) {/** We need to check if the item is already in the list.* During the "sproc" callback execution time, items are* queued into ->ovflist but the "txlist" might already* contain them, and the list_splice() below takes care of them.*/if (!ep_is_linked(epi)) {list_add_tail(&epi->rdllink, &ep->rdllist);ep_pm_stay_awake(epi);}}/** We need to set back ep->ovflist to EP_UNACTIVE_PTR, so that after* releasing the lock, events will be queued in the normal way inside* ep->rdllist.*/ep->ovflist = EP_UNACTIVE_PTR;/** Quickly re-inject items left on "txlist".*/list_splice(&txlist, &ep->rdllist);__pm_relax(ep->ws);if (!list_empty(&ep->rdllist)) {/** Wake up (if active) both the eventpoll wait list and* the ->poll() wait list (delayed after we release the lock).*/if (waitqueue_active(&ep->wq))wake_up_locked(&ep->wq);if (waitqueue_active(&ep->poll_wait))pwake++;}spin_unlock_irq(&ep->wq.lock);if (!ep_locked)mutex_unlock(&ep->mtx);/* We have to call this outside the lock */if (pwake)ep_poll_safewake(&ep->poll_wait);return res;
}static void epi_rcu_free(struct rcu_head *head)
{struct epitem *epi = container_of(head, struct epitem, rcu);kmem_cache_free(epi_cache, epi);
}/** Removes a "struct epitem" from the eventpoll RB tree and deallocates* all the associated resources. Must be called with "mtx" held.*/
static int ep_remove(struct eventpoll *ep, struct epitem *epi)
{struct file *file = epi->ffd.file;lockdep_assert_irqs_enabled();/** Removes poll wait queue hooks.*/ep_unregister_pollwait(ep, epi);/* Remove the current item from the list of epoll hooks */spin_lock(&file->f_lock);list_del_rcu(&epi->fllink);spin_unlock(&file->f_lock);rb_erase_cached(&epi->rbn, &ep->rbr);spin_lock_irq(&ep->wq.lock);if (ep_is_linked(epi))list_del_init(&epi->rdllink);spin_unlock_irq(&ep->wq.lock);wakeup_source_unregister(ep_wakeup_source(epi));/** At this point it is safe to free the eventpoll item. Use the union* field epi->rcu, since we are trying to minimize the size of* 'struct epitem'. The 'rbn' field is no longer in use. Protected by* ep->mtx. The rcu read side, reverse_path_check_proc(), does not make* use of the rbn field.*/call_rcu(&epi->rcu, epi_rcu_free);atomic_long_dec(&ep->user->epoll_watches);return 0;
}static void ep_free(struct eventpoll *ep)
{struct rb_node *rbp;struct epitem *epi;/* We need to release all tasks waiting for these file */if (waitqueue_active(&ep->poll_wait))ep_poll_safewake(&ep->poll_wait);/** We need to lock this because we could be hit by* eventpoll_release_file() while we're freeing the "struct eventpoll".* We do not need to hold "ep->mtx" here because the epoll file* is on the way to be removed and no one has references to it* anymore. The only hit might come from eventpoll_release_file() but* holding "epmutex" is sufficient here.*/mutex_lock(&epmutex);/** Walks through the whole tree by unregistering poll callbacks.*/for (rbp = rb_first_cached(&ep->rbr); rbp; rbp = rb_next(rbp)) {epi = rb_entry(rbp, struct epitem, rbn);ep_unregister_pollwait(ep, epi);cond_resched();}/** Walks through the whole tree by freeing each "struct epitem". At this* point we are sure no poll callbacks will be lingering around, and also by* holding "epmutex" we can be sure that no file cleanup code will hit* us during this operation. So we can avoid the lock on "ep->wq.lock".* We do not need to lock ep->mtx, either, we only do it to prevent* a lockdep warning.*/mutex_lock(&ep->mtx);while ((rbp = rb_first_cached(&ep->rbr)) != NULL) {epi = rb_entry(rbp, struct epitem, rbn);ep_remove(ep, epi);cond_resched();}mutex_unlock(&ep->mtx);mutex_unlock(&epmutex);mutex_destroy(&ep->mtx);free_uid(ep->user);wakeup_source_unregister(ep->ws);kfree(ep);
}static int ep_eventpoll_release(struct inode *inode, struct file *file)
{struct eventpoll *ep = file->private_data;if (ep)ep_free(ep);return 0;
}static __poll_t ep_read_events_proc(struct eventpoll *ep, struct list_head *head,void *priv);
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,poll_table *pt);/** Differs from ep_eventpoll_poll() in that internal callers already have* the ep->mtx so we need to start from depth=1, such that mutex_lock_nested()* is correctly annotated.*/
static __poll_t ep_item_poll(const struct epitem *epi, poll_table *pt,int depth)
{struct eventpoll *ep;bool locked;pt->_key = epi->event.events;if (!is_file_epoll(epi->ffd.file))return vfs_poll(epi->ffd.file, pt) & epi->event.events;ep = epi->ffd.file->private_data;poll_wait(epi->ffd.file, &ep->poll_wait, pt);locked = pt && (pt->_qproc == ep_ptable_queue_proc);return ep_scan_ready_list(epi->ffd.file->private_data,ep_read_events_proc, &depth, depth,locked) & epi->event.events;
}static __poll_t ep_read_events_proc(struct eventpoll *ep, struct list_head *head,void *priv)
{struct epitem *epi, *tmp;poll_table pt;int depth = *(int *)priv;init_poll_funcptr(&pt, NULL);depth++;list_for_each_entry_safe(epi, tmp, head, rdllink) {if (ep_item_poll(epi, &pt, depth)) {return EPOLLIN | EPOLLRDNORM;} else {/** Item has been dropped into the ready list by the poll* callback, but it's not actually ready, as far as* caller requested events goes. We can remove it here.*/__pm_relax(ep_wakeup_source(epi));list_del_init(&epi->rdllink);}}return 0;
}static __poll_t ep_eventpoll_poll(struct file *file, poll_table *wait)
{struct eventpoll *ep = file->private_data;int depth = 0;/* Insert inside our poll wait queue */poll_wait(file, &ep->poll_wait, wait);/** Proceed to find out if wanted events are really available inside* the ready list.*/return ep_scan_ready_list(ep, ep_read_events_proc,&depth, depth, false);
}#ifdef CONFIG_PROC_FS
static void ep_show_fdinfo(struct seq_file *m, struct file *f)
{struct eventpoll *ep = f->private_data;struct rb_node *rbp;mutex_lock(&ep->mtx);for (rbp = rb_first_cached(&ep->rbr); rbp; rbp = rb_next(rbp)) {struct epitem *epi = rb_entry(rbp, struct epitem, rbn);struct inode *inode = file_inode(epi->ffd.file);seq_printf(m, "tfd: %8d events: %8x data: %16llx "" pos:%lli ino:%lx sdev:%x\n",epi->ffd.fd, epi->event.events,(long long)epi->event.data,(long long)epi->ffd.file->f_pos,inode->i_ino, inode->i_sb->s_dev);if (seq_has_overflowed(m))break;}mutex_unlock(&ep->mtx);
}
#endif/* File callbacks that implement the eventpoll file behaviour */
static const struct file_operations eventpoll_fops = {
#ifdef CONFIG_PROC_FS.show_fdinfo = ep_show_fdinfo,
#endif.release = ep_eventpoll_release,.poll = ep_eventpoll_poll,.llseek = noop_llseek,
};/** This is called from eventpoll_release() to unlink files from the eventpoll* interface. We need to have this facility to cleanup correctly files that are* closed without being removed from the eventpoll interface.*/
void eventpoll_release_file(struct file *file)
{struct eventpoll *ep;struct epitem *epi, *next;/** We don't want to get "file->f_lock" because it is not* necessary. It is not necessary because we're in the "struct file"* cleanup path, and this means that no one is using this file anymore.* So, for example, epoll_ctl() cannot hit here since if we reach this* point, the file counter already went to zero and fget() would fail.* The only hit might come from ep_free() but by holding the mutex* will correctly serialize the operation. We do need to acquire* "ep->mtx" after "epmutex" because ep_remove() requires it when called* from anywhere but ep_free().** Besides, ep_remove() acquires the lock, so we can't hold it here.*/mutex_lock(&epmutex);list_for_each_entry_safe(epi, next, &file->f_ep_links, fllink) {ep = epi->ep;mutex_lock_nested(&ep->mtx, 0);ep_remove(ep, epi);mutex_unlock(&ep->mtx);}mutex_unlock(&epmutex);
}static int ep_alloc(struct eventpoll **pep)
{int error;struct user_struct *user;struct eventpoll *ep;user = get_current_user();error = -ENOMEM;ep = kzalloc(sizeof(*ep), GFP_KERNEL);if (unlikely(!ep))goto free_uid;mutex_init(&ep->mtx);init_waitqueue_head(&ep->wq);init_waitqueue_head(&ep->poll_wait);INIT_LIST_HEAD(&ep->rdllist);ep->rbr = RB_ROOT_CACHED;ep->ovflist = EP_UNACTIVE_PTR;ep->user = user;*pep = ep;return 0;free_uid:free_uid(user);return error;
}/** Search the file inside the eventpoll tree. The RB tree operations* are protected by the "mtx" mutex, and ep_find() must be called with* "mtx" held.*/
static struct epitem *ep_find(struct eventpoll *ep, struct file *file, int fd)
{int kcmp;struct rb_node *rbp;struct epitem *epi, *epir = NULL;struct epoll_filefd ffd;ep_set_ffd(&ffd, file, fd);for (rbp = ep->rbr.rb_root.rb_node; rbp; ) {epi = rb_entry(rbp, struct epitem, rbn);kcmp = ep_cmp_ffd(&ffd, &epi->ffd);if (kcmp > 0)rbp = rbp->rb_right;else if (kcmp < 0)rbp = rbp->rb_left;else {epir = epi;break;}}return epir;
}#ifdef CONFIG_CHECKPOINT_RESTORE
static struct epitem *ep_find_tfd(struct eventpoll *ep, int tfd, unsigned long toff)
{struct rb_node *rbp;struct epitem *epi;for (rbp = rb_first_cached(&ep->rbr); rbp; rbp = rb_next(rbp)) {epi = rb_entry(rbp, struct epitem, rbn);if (epi->ffd.fd == tfd) {if (toff == 0)return epi;elsetoff--;}cond_resched();}return NULL;
}struct file *get_epoll_tfile_raw_ptr(struct file *file, int tfd,unsigned long toff)
{struct file *file_raw;struct eventpoll *ep;struct epitem *epi;if (!is_file_epoll(file))return ERR_PTR(-EINVAL);ep = file->private_data;mutex_lock(&ep->mtx);epi = ep_find_tfd(ep, tfd, toff);if (epi)file_raw = epi->ffd.file;elsefile_raw = ERR_PTR(-ENOENT);mutex_unlock(&ep->mtx);return file_raw;
}
#endif /* CONFIG_CHECKPOINT_RESTORE *//** This is the callback that is passed to the wait queue wakeup* mechanism. It is called by the stored file descriptors when they* have events to report.*/
static int ep_poll_callback(wait_queue_entry_t *wait, unsigned mode, int sync, void *key)
{int pwake = 0;unsigned long flags;struct epitem *epi = ep_item_from_wait(wait);struct eventpoll *ep = epi->ep;__poll_t pollflags = key_to_poll(key);int ewake = 0;spin_lock_irqsave(&ep->wq.lock, flags);ep_set_busy_poll_napi_id(epi);/** If the event mask does not contain any poll(2) event, we consider the* descriptor to be disabled. This condition is likely the effect of the* EPOLLONESHOT bit that disables the descriptor when an event is received,* until the next EPOLL_CTL_MOD will be issued.*/if (!(epi->event.events & ~EP_PRIVATE_BITS))goto out_unlock;/** Check the events coming with the callback. At this stage, not* every device reports the events in the "key" parameter of the* callback. We need to be able to handle both cases here, hence the* test for "key" != NULL before the event match test.*/if (pollflags && !(pollflags & epi->event.events))goto out_unlock;/** If we are transferring events to userspace, we can hold no locks* (because we're accessing user memory, and because of linux f_op->poll()* semantics). All the events that happen during that period of time are* chained in ep->ovflist and requeued later on.*/if (ep->ovflist != EP_UNACTIVE_PTR) {if (epi->next == EP_UNACTIVE_PTR) {epi->next = ep->ovflist;ep->ovflist = epi;if (epi->ws) {/** Activate ep->ws since epi->ws may get* deactivated at any time.*/__pm_stay_awake(ep->ws);}}goto out_unlock;}/* If this file is already in the ready list we exit soon */if (!ep_is_linked(epi)) {list_add_tail(&epi->rdllink, &ep->rdllist);ep_pm_stay_awake_rcu(epi);}/** Wake up ( if active ) both the eventpoll wait list and the ->poll()* wait list.*/if (waitqueue_active(&ep->wq)) {if ((epi->event.events & EPOLLEXCLUSIVE) &&!(pollflags & POLLFREE)) {switch (pollflags & EPOLLINOUT_BITS) {case EPOLLIN:if (epi->event.events & EPOLLIN)ewake = 1;break;case EPOLLOUT:if (epi->event.events & EPOLLOUT)ewake = 1;break;case 0:ewake = 1;break;}}wake_up_locked(&ep->wq);}if (waitqueue_active(&ep->poll_wait))pwake++;out_unlock:spin_unlock_irqrestore(&ep->wq.lock, flags);/* We have to call this outside the lock */if (pwake)ep_poll_safewake(&ep->poll_wait);if (!(epi->event.events & EPOLLEXCLUSIVE))ewake = 1;if (pollflags & POLLFREE) {/** If we race with ep_remove_wait_queue() it can miss* ->whead = NULL and do another remove_wait_queue() after* us, so we can't use __remove_wait_queue().*/list_del_init(&wait->entry);/** ->whead != NULL protects us from the race with ep_free()* or ep_remove(), ep_remove_wait_queue() takes whead->lock* held by the caller. Once we nullify it, nothing protects* ep/epi or even wait.*/smp_store_release(&ep_pwq_from_wait(wait)->whead, NULL);}return ewake;
}/** This is the callback that is used to add our wait queue to the* target file wakeup lists.*/
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,poll_table *pt)
{struct epitem *epi = ep_item_from_epqueue(pt);struct eppoll_entry *pwq;if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);pwq->whead = whead;pwq->base = epi;if (epi->event.events & EPOLLEXCLUSIVE)add_wait_queue_exclusive(whead, &pwq->wait);elseadd_wait_queue(whead, &pwq->wait);list_add_tail(&pwq->llink, &epi->pwqlist);epi->nwait++;} else {/* We have to signal that an error occurred */epi->nwait = -1;}
}static void ep_rbtree_insert(struct eventpoll *ep, struct epitem *epi)
{int kcmp;struct rb_node **p = &ep->rbr.rb_root.rb_node, *parent = NULL;struct epitem *epic;bool leftmost = true;while (*p) {parent = *p;epic = rb_entry(parent, struct epitem, rbn);kcmp = ep_cmp_ffd(&epi->ffd, &epic->ffd);if (kcmp > 0) {p = &parent->rb_right;leftmost = false;} elsep = &parent->rb_left;}rb_link_node(&epi->rbn, parent, p);rb_insert_color_cached(&epi->rbn, &ep->rbr, leftmost);
}#define PATH_ARR_SIZE 5
/** These are the number paths of length 1 to 5, that we are allowing to emanate* from a single file of interest. For example, we allow 1000 paths of length* 1, to emanate from each file of interest. This essentially represents the* potential wakeup paths, which need to be limited in order to avoid massive* uncontrolled wakeup storms. The common use case should be a single ep which* is connected to n file sources. In this case each file source has 1 path* of length 1. Thus, the numbers below should be more than sufficient. These* path limits are enforced during an EPOLL_CTL_ADD operation, since a modify* and delete can't add additional paths. Protected by the epmutex.*/
static const int path_limits[PATH_ARR_SIZE] = { 1000, 500, 100, 50, 10 };
static int path_count[PATH_ARR_SIZE];static int path_count_inc(int nests)
{/* Allow an arbitrary number of depth 1 paths */if (nests == 0)return 0;if (++path_count[nests] > path_limits[nests])return -1;return 0;
}static void path_count_init(void)
{int i;for (i = 0; i < PATH_ARR_SIZE; i++)path_count[i] = 0;
}static int reverse_path_check_proc(void *priv, void *cookie, int call_nests)
{int error = 0;struct file *file = priv;struct file *child_file;struct epitem *epi;/* CTL_DEL can remove links here, but that can't increase our count */rcu_read_lock();list_for_each_entry_rcu(epi, &file->f_ep_links, fllink) {child_file = epi->ep->file;if (is_file_epoll(child_file)) {if (list_empty(&child_file->f_ep_links)) {if (path_count_inc(call_nests)) {error = -1;break;}} else {error = ep_call_nested(&poll_loop_ncalls,EP_MAX_NESTS,reverse_path_check_proc,child_file, child_file,current);}if (error != 0)break;} else {printk(KERN_ERR "reverse_path_check_proc: ""file is not an ep!\n");}}rcu_read_unlock();return error;
}/*** reverse_path_check - The tfile_check_list is list of file *, which have* links that are proposed to be newly added. We need to* make sure that those added links don't add too many* paths such that we will spend all our time waking up* eventpoll objects.** Returns: Returns zero if the proposed links don't create too many paths,* -1 otherwise.*/
static int reverse_path_check(void)
{int error = 0;struct file *current_file;/* let's call this for all tfiles */list_for_each_entry(current_file, &tfile_check_list, f_tfile_llink) {path_count_init();error = ep_call_nested(&poll_loop_ncalls, EP_MAX_NESTS,reverse_path_check_proc, current_file,current_file, current);if (error)break;}return error;
}static int ep_create_wakeup_source(struct epitem *epi)
{const char *name;struct wakeup_source *ws;if (!epi->ep->ws) {epi->ep->ws = wakeup_source_register("eventpoll");if (!epi->ep->ws)return -ENOMEM;}name = epi->ffd.file->f_path.dentry->d_name.name;ws = wakeup_source_register(name);if (!ws)return -ENOMEM;rcu_assign_pointer(epi->ws, ws);return 0;
}/* rare code path, only used when EPOLL_CTL_MOD removes a wakeup source */
static noinline void ep_destroy_wakeup_source(struct epitem *epi)
{struct wakeup_source *ws = ep_wakeup_source(epi);RCU_INIT_POINTER(epi->ws, NULL);/** wait for ep_pm_stay_awake_rcu to finish, synchronize_rcu is* used internally by wakeup_source_remove, too (called by* wakeup_source_unregister), so we cannot use call_rcu*/synchronize_rcu();wakeup_source_unregister(ws);
}/** Must be called with "mtx" held.*/
static int ep_insert(struct eventpoll *ep, const struct epoll_event *event,struct file *tfile, int fd, int full_check)
{int error, pwake = 0;__poll_t revents;long user_watches;struct epitem *epi;struct ep_pqueue epq;lockdep_assert_irqs_enabled();user_watches = atomic_long_read(&ep->user->epoll_watches);if (unlikely(user_watches >= max_user_watches))return -ENOSPC;if (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL)))return -ENOMEM;/* Item initialization follow here ... */INIT_LIST_HEAD(&epi->rdllink);INIT_LIST_HEAD(&epi->fllink);INIT_LIST_HEAD(&epi->pwqlist);epi->ep = ep;ep_set_ffd(&epi->ffd, tfile, fd);epi->event = *event;epi->nwait = 0;epi->next = EP_UNACTIVE_PTR;if (epi->event.events & EPOLLWAKEUP) {error = ep_create_wakeup_source(epi);if (error)goto error_create_wakeup_source;} else {RCU_INIT_POINTER(epi->ws, NULL);}/* Initialize the poll table using the queue callback */epq.epi = epi;init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);/** Attach the item to the poll hooks and get current event bits.* We can safely use the file* here because its usage count has* been increased by the caller of this function. Note that after* this operation completes, the poll callback can start hitting* the new item.*/revents = ep_item_poll(epi, &epq.pt, 1);/** We have to check if something went wrong during the poll wait queue* install process. Namely an allocation for a wait queue failed due* high memory pressure.*/error = -ENOMEM;if (epi->nwait < 0)goto error_unregister;/* Add the current item to the list of active epoll hook for this file */spin_lock(&tfile->f_lock);list_add_tail_rcu(&epi->fllink, &tfile->f_ep_links);spin_unlock(&tfile->f_lock);/** Add the current item to the RB tree. All RB tree operations are* protected by "mtx", and ep_insert() is called with "mtx" held.*/ep_rbtree_insert(ep, epi);/* now check if we've created too many backpaths */error = -EINVAL;if (full_check && reverse_path_check())goto error_remove_epi;/* We have to drop the new item inside our item list to keep track of it */spin_lock_irq(&ep->wq.lock);/* record NAPI ID of new item if present */ep_set_busy_poll_napi_id(epi);/* If the file is already "ready" we drop it inside the ready list */if (revents && !ep_is_linked(epi)) {list_add_tail(&epi->rdllink, &ep->rdllist);ep_pm_stay_awake(epi);/* Notify waiting tasks that events are available */if (waitqueue_active(&ep->wq))wake_up_locked(&ep->wq);if (waitqueue_active(&ep->poll_wait))pwake++;}spin_unlock_irq(&ep->wq.lock);atomic_long_inc(&ep->user->epoll_watches);/* We have to call this outside the lock */if (pwake)ep_poll_safewake(&ep->poll_wait);return 0;error_remove_epi:spin_lock(&tfile->f_lock);list_del_rcu(&epi->fllink);spin_unlock(&tfile->f_lock);rb_erase_cached(&epi->rbn, &ep->rbr);error_unregister:ep_unregister_pollwait(ep, epi);/** We need to do this because an event could have been arrived on some* allocated wait queue. Note that we don't care about the ep->ovflist* list, since that is used/cleaned only inside a section bound by "mtx".* And ep_insert() is called with "mtx" held.*/spin_lock_irq(&ep->wq.lock);if (ep_is_linked(epi))list_del_init(&epi->rdllink);spin_unlock_irq(&ep->wq.lock);wakeup_source_unregister(ep_wakeup_source(epi));error_create_wakeup_source:kmem_cache_free(epi_cache, epi);return error;
}/** Modify the interest event mask by dropping an event if the new mask* has a match in the current file status. Must be called with "mtx" held.*/
static int ep_modify(struct eventpoll *ep, struct epitem *epi,const struct epoll_event *event)
{int pwake = 0;poll_table pt;lockdep_assert_irqs_enabled();init_poll_funcptr(&pt, NULL);/** Set the new event interest mask before calling f_op->poll();* otherwise we might miss an event that happens between the* f_op->poll() call and the new event set registering.*/epi->event.events = event->events; /* need barrier below */epi->event.data = event->data; /* protected by mtx */if (epi->event.events & EPOLLWAKEUP) {if (!ep_has_wakeup_source(epi))ep_create_wakeup_source(epi);} else if (ep_has_wakeup_source(epi)) {ep_destroy_wakeup_source(epi);}/** The following barrier has two effects:** 1) Flush epi changes above to other CPUs. This ensures* we do not miss events from ep_poll_callback if an* event occurs immediately after we call f_op->poll().* We need this because we did not take ep->wq.lock while* changing epi above (but ep_poll_callback does take* ep->wq.lock).** 2) We also need to ensure we do not miss _past_ events* when calling f_op->poll(). This barrier also* pairs with the barrier in wq_has_sleeper (see* comments for wq_has_sleeper).** This barrier will now guarantee ep_poll_callback or f_op->poll* (or both) will notice the readiness of an item.*/smp_mb();/** Get current event bits. We can safely use the file* here because* its usage count has been increased by the caller of this function.* If the item is "hot" and it is not registered inside the ready* list, push it inside.*/if (ep_item_poll(epi, &pt, 1)) {spin_lock_irq(&ep->wq.lock);if (!ep_is_linked(epi)) {list_add_tail(&epi->rdllink, &ep->rdllist);ep_pm_stay_awake(epi);/* Notify waiting tasks that events are available */if (waitqueue_active(&ep->wq))wake_up_locked(&ep->wq);if (waitqueue_active(&ep->poll_wait))pwake++;}spin_unlock_irq(&ep->wq.lock);}/* We have to call this outside the lock */if (pwake)ep_poll_safewake(&ep->poll_wait);return 0;
}static __poll_t ep_send_events_proc(struct eventpoll *ep, struct list_head *head,void *priv)
{struct ep_send_events_data *esed = priv;__poll_t revents;struct epitem *epi;struct epoll_event __user *uevent;struct wakeup_source *ws;poll_table pt;init_poll_funcptr(&pt, NULL);/** We can loop without lock because we are passed a task private list.* Items cannot vanish during the loop because ep_scan_ready_list() is* holding "mtx" during this call.*/for (esed->res = 0, uevent = esed->events;!list_empty(head) && esed->res < esed->maxevents;) {epi = list_first_entry(head, struct epitem, rdllink);/** Activate ep->ws before deactivating epi->ws to prevent* triggering auto-suspend here (in case we reactive epi->ws* below).** This could be rearranged to delay the deactivation of epi->ws* instead, but then epi->ws would temporarily be out of sync* with ep_is_linked().*/ws = ep_wakeup_source(epi);if (ws) {if (ws->active)__pm_stay_awake(ep->ws);__pm_relax(ws);}list_del_init(&epi->rdllink);revents = ep_item_poll(epi, &pt, 1);/** If the event mask intersect the caller-requested one,* deliver the event to userspace. Again, ep_scan_ready_list()* is holding "mtx", so no operations coming from userspace* can change the item.*/if (revents) {if (__put_user(revents, &uevent->events) ||__put_user(epi->event.data, &uevent->data)) {list_add(&epi->rdllink, head);ep_pm_stay_awake(epi);if (!esed->res)esed->res = -EFAULT;return 0;}esed->res++;uevent++;if (epi->event.events & EPOLLONESHOT)epi->event.events &= EP_PRIVATE_BITS;else if (!(epi->event.events & EPOLLET)) {/** If this file has been added with Level* Trigger mode, we need to insert back inside* the ready list, so that the next call to* epoll_wait() will check again the events* availability. At this point, no one can insert* into ep->rdllist besides us. The epoll_ctl()* callers are locked out by* ep_scan_ready_list() holding "mtx" and the* poll callback will queue them in ep->ovflist.*/list_add_tail(&epi->rdllink, &ep->rdllist);ep_pm_stay_awake(epi);}}}return 0;
}static int ep_send_events(struct eventpoll *ep,struct epoll_event __user *events, int maxevents)
{struct ep_send_events_data esed;esed.maxevents = maxevents;esed.events = events;ep_scan_ready_list(ep, ep_send_events_proc, &esed, 0, false);return esed.res;
}static inline struct timespec64 ep_set_mstimeout(long ms)
{struct timespec64 now, ts = {.tv_sec = ms / MSEC_PER_SEC,.tv_nsec = NSEC_PER_MSEC * (ms % MSEC_PER_SEC),};ktime_get_ts64(&now);return timespec64_add_safe(now, ts);
}/*** ep_poll - Retrieves ready events, and delivers them to the caller supplied* event buffer.** @ep: Pointer to the eventpoll context.* @events: Pointer to the userspace buffer where the ready events should be* stored.* @maxevents: Size (in terms of number of events) of the caller event buffer.* @timeout: Maximum timeout for the ready events fetch operation, in* milliseconds. If the @timeout is zero, the function will not block,* while if the @timeout is less than zero, the function will block* until at least one event has been retrieved (or an error* occurred).** Returns: Returns the number of ready events which have been fetched, or an* error code, in case of error.*/
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,int maxevents, long timeout)
{int res = 0, eavail, timed_out = 0;u64 slack = 0;wait_queue_entry_t wait;ktime_t expires, *to = NULL;lockdep_assert_irqs_enabled();if (timeout > 0) {struct timespec64 end_time = ep_set_mstimeout(timeout);slack = select_estimate_accuracy(&end_time);to = &expires;*to = timespec64_to_ktime(end_time);} else if (timeout == 0) {/** Avoid the unnecessary trip to the wait queue loop, if the* caller specified a non blocking operation.*/timed_out = 1;spin_lock_irq(&ep->wq.lock);goto check_events;}fetch_events:if (!ep_events_available(ep))ep_busy_loop(ep, timed_out);spin_lock_irq(&ep->wq.lock);if (!ep_events_available(ep)) {/** Busy poll timed out. Drop NAPI ID for now, we can add* it back in when we have moved a socket with a valid NAPI* ID onto the ready list.*/ep_reset_busy_poll_napi_id(ep);/** We don't have any available event to return to the caller.* We need to sleep here, and we will be wake up by* ep_poll_callback() when events will become available.*/init_waitqueue_entry(&wait, current);__add_wait_queue_exclusive(&ep->wq, &wait);for (;;) {/** We don't want to sleep if the ep_poll_callback() sends us* a wakeup in between. That's why we set the task state* to TASK_INTERRUPTIBLE before doing the checks.*/set_current_state(TASK_INTERRUPTIBLE);/** Always short-circuit for fatal signals to allow* threads to make a timely exit without the chance of* finding more events available and fetching* repeatedly.*/if (fatal_signal_pending(current)) {res = -EINTR;break;}if (ep_events_available(ep) || timed_out)break;if (signal_pending(current)) {res = -EINTR;break;}spin_unlock_irq(&ep->wq.lock);if (!schedule_hrtimeout_range(to, slack, HRTIMER_MODE_ABS))timed_out = 1;spin_lock_irq(&ep->wq.lock);}__remove_wait_queue(&ep->wq, &wait);__set_current_state(TASK_RUNNING);}
check_events:/* Is it worth to try to dig for events ? */eavail = ep_events_available(ep);spin_unlock_irq(&ep->wq.lock);/** Try to transfer events to user space. In case we get 0 events and* there's still timeout left over, we go trying again in search of* more luck.*/if (!res && eavail &&!(res = ep_send_events(ep, events, maxevents)) && !timed_out)goto fetch_events;return res;
}/*** ep_loop_check_proc - Callback function to be passed to the @ep_call_nested()* API, to verify that adding an epoll file inside another* epoll structure, does not violate the constraints, in* terms of closed loops, or too deep chains (which can* result in excessive stack usage).** @priv: Pointer to the epoll file to be currently checked.* @cookie: Original cookie for this call. This is the top-of-the-chain epoll* data structure pointer.* @call_nests: Current dept of the @ep_call_nested() call stack.** Returns: Returns zero if adding the epoll @file inside current epoll* structure @ep does not violate the constraints, or -1 otherwise.*/
static int ep_loop_check_proc(void *priv, void *cookie, int call_nests)
{int error = 0;struct file *file = priv;struct eventpoll *ep = file->private_data;struct eventpoll *ep_tovisit;struct rb_node *rbp;struct epitem *epi;mutex_lock_nested(&ep->mtx, call_nests + 1);ep->visited = 1;list_add(&ep->visited_list_link, &visited_list);for (rbp = rb_first_cached(&ep->rbr); rbp; rbp = rb_next(rbp)) {epi = rb_entry(rbp, struct epitem, rbn);if (unlikely(is_file_epoll(epi->ffd.file))) {ep_tovisit = epi->ffd.file->private_data;if (ep_tovisit->visited)continue;error = ep_call_nested(&poll_loop_ncalls, EP_MAX_NESTS,ep_loop_check_proc, epi->ffd.file,ep_tovisit, current);if (error != 0)break;} else {/** If we've reached a file that is not associated with* an ep, then we need to check if the newly added* links are going to add too many wakeup paths. We do* this by adding it to the tfile_check_list, if it's* not already there, and calling reverse_path_check()* during ep_insert().*/if (list_empty(&epi->ffd.file->f_tfile_llink))list_add(&epi->ffd.file->f_tfile_llink,&tfile_check_list);}}mutex_unlock(&ep->mtx);return error;
}/*** ep_loop_check - Performs a check to verify that adding an epoll file (@file)* another epoll file (represented by @ep) does not create* closed loops or too deep chains.** @ep: Pointer to the epoll private data structure.* @file: Pointer to the epoll file to be checked.** Returns: Returns zero if adding the epoll @file inside current epoll* structure @ep does not violate the constraints, or -1 otherwise.*/
static int ep_loop_check(struct eventpoll *ep, struct file *file)
{int ret;struct eventpoll *ep_cur, *ep_next;ret = ep_call_nested(&poll_loop_ncalls, EP_MAX_NESTS,ep_loop_check_proc, file, ep, current);/* clear visited list */list_for_each_entry_safe(ep_cur, ep_next, &visited_list,visited_list_link) {ep_cur->visited = 0;list_del(&ep_cur->visited_list_link);}return ret;
}static void clear_tfile_check_list(void)
{struct file *file;/* first clear the tfile_check_list */while (!list_empty(&tfile_check_list)) {file = list_first_entry(&tfile_check_list, struct file,f_tfile_llink);list_del_init(&file->f_tfile_llink);}INIT_LIST_HEAD(&tfile_check_list);
}/** Open an eventpoll file descriptor.*/
static int do_epoll_create(int flags)
{int error, fd;struct eventpoll *ep = NULL;struct file *file;/* Check the EPOLL_* constant for consistency. */BUILD_BUG_ON(EPOLL_CLOEXEC != O_CLOEXEC);if (flags & ~EPOLL_CLOEXEC)return -EINVAL;/** Create the internal data structure ("struct eventpoll").*/error = ep_alloc(&ep);if (error < 0)return error;/** Creates all the items needed to setup an eventpoll file. That is,* a file structure and a free file descriptor.*/fd = get_unused_fd_flags(O_RDWR | (flags & O_CLOEXEC));if (fd < 0) {error = fd;goto out_free_ep;}file = anon_inode_getfile("[eventpoll]", &eventpoll_fops, ep,O_RDWR | (flags & O_CLOEXEC));if (IS_ERR(file)) {error = PTR_ERR(file);goto out_free_fd;}ep->file = file;fd_install(fd, file);return fd;out_free_fd:put_unused_fd(fd);
out_free_ep:ep_free(ep);return error;
}SYSCALL_DEFINE1(epoll_create1, int, flags)
{return do_epoll_create(flags);
}SYSCALL_DEFINE1(epoll_create, int, size)
{if (size <= 0)return -EINVAL;return do_epoll_create(0);
}/** The following function implements the controller interface for* the eventpoll file that enables the insertion/removal/change of* file descriptors inside the interest set.*/
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,struct epoll_event __user *, event)
{int error;int full_check = 0;struct fd f, tf;struct eventpoll *ep;struct epitem *epi;struct epoll_event epds;struct eventpoll *tep = NULL;error = -EFAULT;if (ep_op_has_event(op) &©_from_user(&epds, event, sizeof(struct epoll_event)))goto error_return;error = -EBADF;f = fdget(epfd);if (!f.file)goto error_return;/* Get the "struct file *" for the target file */tf = fdget(fd);if (!tf.file)goto error_fput;/* The target file descriptor must support poll */error = -EPERM;if (!file_can_poll(tf.file))goto error_tgt_fput;/* Check if EPOLLWAKEUP is allowed */if (ep_op_has_event(op))ep_take_care_of_epollwakeup(&epds);/** We have to check that the file structure underneath the file descriptor* the user passed to us _is_ an eventpoll file. And also we do not permit* adding an epoll file descriptor inside itself.*/error = -EINVAL;if (f.file == tf.file || !is_file_epoll(f.file))goto error_tgt_fput;/** epoll adds to the wakeup queue at EPOLL_CTL_ADD time only,* so EPOLLEXCLUSIVE is not allowed for a EPOLL_CTL_MOD operation.* Also, we do not currently supported nested exclusive wakeups.*/if (ep_op_has_event(op) && (epds.events & EPOLLEXCLUSIVE)) {if (op == EPOLL_CTL_MOD)goto error_tgt_fput;if (op == EPOLL_CTL_ADD && (is_file_epoll(tf.file) ||(epds.events & ~EPOLLEXCLUSIVE_OK_BITS)))goto error_tgt_fput;}/** At this point it is safe to assume that the "private_data" contains* our own data structure.*/ep = f.file->private_data;/** When we insert an epoll file descriptor, inside another epoll file* descriptor, there is the change of creating closed loops, which are* better be handled here, than in more critical paths. While we are* checking for loops we also determine the list of files reachable* and hang them on the tfile_check_list, so we can check that we* haven't created too many possible wakeup paths.** We do not need to take the global 'epumutex' on EPOLL_CTL_ADD when* the epoll file descriptor is attaching directly to a wakeup source,* unless the epoll file descriptor is nested. The purpose of taking the* 'epmutex' on add is to prevent complex toplogies such as loops and* deep wakeup paths from forming in parallel through multiple* EPOLL_CTL_ADD operations.*/mutex_lock_nested(&ep->mtx, 0);if (op == EPOLL_CTL_ADD) {if (!list_empty(&f.file->f_ep_links) ||is_file_epoll(tf.file)) {full_check = 1;mutex_unlock(&ep->mtx);mutex_lock(&epmutex);if (is_file_epoll(tf.file)) {error = -ELOOP;if (ep_loop_check(ep, tf.file) != 0) {clear_tfile_check_list();goto error_tgt_fput;}} elselist_add(&tf.file->f_tfile_llink,&tfile_check_list);mutex_lock_nested(&ep->mtx, 0);if (is_file_epoll(tf.file)) {tep = tf.file->private_data;mutex_lock_nested(&tep->mtx, 1);}}}/** Try to lookup the file inside our RB tree, Since we grabbed "mtx"* above, we can be sure to be able to use the item looked up by* ep_find() till we release the mutex.*/epi = ep_find(ep, tf.file, fd);error = -EINVAL;switch (op) {case EPOLL_CTL_ADD:if (!epi) {epds.events |= EPOLLERR | EPOLLHUP;error = ep_insert(ep, &epds, tf.file, fd, full_check);} elseerror = -EEXIST;if (full_check)clear_tfile_check_list();break;case EPOLL_CTL_DEL:if (epi)error = ep_remove(ep, epi);elseerror = -ENOENT;break;case EPOLL_CTL_MOD:if (epi) {if (!(epi->event.events & EPOLLEXCLUSIVE)) {epds.events |= EPOLLERR | EPOLLHUP;error = ep_modify(ep, epi, &epds);}} elseerror = -ENOENT;break;}if (tep != NULL)mutex_unlock(&tep->mtx);mutex_unlock(&ep->mtx);error_tgt_fput:if (full_check)mutex_unlock(&epmutex);fdput(tf);
error_fput:fdput(f);
error_return:return error;
}/** Implement the event wait interface for the eventpoll file. It is the kernel* part of the user space epoll_wait(2).*/
static int do_epoll_wait(int epfd, struct epoll_event __user *events,int maxevents, int timeout)
{int error;struct fd f;struct eventpoll *ep;/* The maximum number of event must be greater than zero */if (maxevents <= 0 || maxevents > EP_MAX_EVENTS)return -EINVAL;/* Verify that the area passed by the user is writeable */if (!access_ok(VERIFY_WRITE, events, maxevents * sizeof(struct epoll_event)))return -EFAULT;/* Get the "struct file *" for the eventpoll file */f = fdget(epfd);if (!f.file)return -EBADF;/** We have to check that the file structure underneath the fd* the user passed to us _is_ an eventpoll file.*/error = -EINVAL;if (!is_file_epoll(f.file))goto error_fput;/** At this point it is safe to assume that the "private_data" contains* our own data structure.*/ep = f.file->private_data;/* Time to fish for events ... */error = ep_poll(ep, events, maxevents, timeout);error_fput:fdput(f);return error;
}SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,int, maxevents, int, timeout)
{return do_epoll_wait(epfd, events, maxevents, timeout);
}/** Implement the event wait interface for the eventpoll file. It is the kernel* part of the user space epoll_pwait(2).*/
SYSCALL_DEFINE6(epoll_pwait, int, epfd, struct epoll_event __user *, events,int, maxevents, int, timeout, const sigset_t __user *, sigmask,size_t, sigsetsize)
{int error;sigset_t ksigmask, sigsaved;/** If the caller wants a certain signal mask to be set during the wait,* we apply it here.*/if (sigmask) {if (sigsetsize != sizeof(sigset_t))return -EINVAL;if (copy_from_user(&ksigmask, sigmask, sizeof(ksigmask)))return -EFAULT;sigsaved = current->blocked;set_current_blocked(&ksigmask);}error = do_epoll_wait(epfd, events, maxevents, timeout);/** If we changed the signal mask, we need to restore the original one.* In case we've got a signal while waiting, we do not restore the* signal mask yet, and we allow do_signal() to deliver the signal on* the way back to userspace, before the signal mask is restored.*/if (sigmask) {if (error == -EINTR) {memcpy(¤t->saved_sigmask, &sigsaved,sizeof(sigsaved));set_restore_sigmask();} elseset_current_blocked(&sigsaved);}return error;
}#ifdef CONFIG_COMPAT
COMPAT_SYSCALL_DEFINE6(epoll_pwait, int, epfd,struct epoll_event __user *, events,int, maxevents, int, timeout,const compat_sigset_t __user *, sigmask,compat_size_t, sigsetsize)
{long err;sigset_t ksigmask, sigsaved;/** If the caller wants a certain signal mask to be set during the wait,* we apply it here.*/if (sigmask) {if (sigsetsize != sizeof(compat_sigset_t))return -EINVAL;if (get_compat_sigset(&ksigmask, sigmask))return -EFAULT;sigsaved = current->blocked;set_current_blocked(&ksigmask);}err = do_epoll_wait(epfd, events, maxevents, timeout);/** If we changed the signal mask, we need to restore the original one.* In case we've got a signal while waiting, we do not restore the* signal mask yet, and we allow do_signal() to deliver the signal on* the way back to userspace, before the signal mask is restored.*/if (sigmask) {if (err == -EINTR) {memcpy(¤t->saved_sigmask, &sigsaved,sizeof(sigsaved));set_restore_sigmask();} elseset_current_blocked(&sigsaved);}return err;
}
#endifstatic int __init eventpoll_init(void)
{struct sysinfo si;si_meminfo(&si);/** Allows top 4% of lomem to be allocated for epoll watches (per user).*/max_user_watches = (((si.totalram - si.totalhigh) / 25) << PAGE_SHIFT) /EP_ITEM_COST;BUG_ON(max_user_watches < 0);/** Initialize the structure used to perform epoll file descriptor* inclusion loops checks.*/ep_nested_calls_init(&poll_loop_ncalls);#ifdef CONFIG_DEBUG_LOCK_ALLOC/* Initialize the structure used to perform safe poll wait head wake ups */ep_nested_calls_init(&poll_safewake_ncalls);
#endif/** We can have many thousands of epitems, so prevent this from* using an extra cache line on 64-bit (and smaller) CPUs*/BUILD_BUG_ON(sizeof(void *) <= 8 && sizeof(struct epitem) > 128);/* Allocates slab cache used to allocate "struct epitem" items */epi_cache = kmem_cache_create("eventpoll_epi", sizeof(struct epitem),0, SLAB_HWCACHE_ALIGN|SLAB_PANIC|SLAB_ACCOUNT, NULL);/* Allocates slab cache used to allocate "struct eppoll_entry" */pwq_cache = kmem_cache_create("eventpoll_pwq",sizeof(struct eppoll_entry), 0, SLAB_PANIC|SLAB_ACCOUNT, NULL);return 0;
}
fs_initcall(eventpoll_init);Linux eventpoll.c 深度解读
eventpoll.c 是 Linux 内核中实现 epoll 机制的核心文件,用于高效管理大量文件描述符(FD)的事件监控。epoll 解决了传统 select/poll 在 FD 数量增长时性能下降的问题,尤其适合高并发场景(如 Web 服务器)。以下是关键分析:
核心数据结构
-
struct eventpoll-
作用: 每个 epoll 实例的上下文。
-
关键成员:
-
rbr: 红黑树根节点,存储所有监控的 FD(epitem),实现 O(log n) 的插入/删除/查找。 -
rdllist: 就绪事件的双向链表,存储已触发事件的epitem。 -
ovflist: 单链表,临时存放就绪事件(避免在向用户空间传递事件时丢失新事件)。 -
wq: 等待队列,阻塞在epoll_wait()的进程在此休眠。 -
mtx: 互斥锁,保护eventpoll的并发访问。
-
-
-
struct epitem-
作用: 代表一个被监控的 FD。
-
关键成员:
-
rbn: 红黑树节点,用于挂载到eventpoll->rbr。 -
rdllink: 节点,用于挂载到就绪链表rdllist。 -
ffd: 包含被监控的struct file*和 FD 编号。 -
event: 用户设置的监听事件(EPOLLIN/OUT 等)。 -
pwqlist: 关联的等待队列(如 socket 的等待队列)。
-
-
-
struct eppoll_entry-
作用: 连接
epitem与底层文件的等待队列。 -
机制: 通过
ep_ptable_queue_proc注册回调函数ep_poll_callback到文件的等待队列。
-
关键机制
-
FD 的添加与删除
-
ep_insert():-
创建
epitem,初始化红黑树节点。 -
调用
ep_item_poll()检查当前是否有就绪事件(若有则加入rdllist)。 -
通过
ep_ptable_queue_proc向文件的等待队列注册回调。
-
-
ep_remove():-
从红黑树和就绪链表移除
epitem。 -
调用
ep_unregister_pollwait移除等待队列的回调。
-
-
-
事件触发与回调
-
ep_poll_callback():-
触发条件: 被监控文件发生事件(如 socket 收到数据)。
-
核心逻辑:
-
将
epitem加入rdllist(若未在链表中)。 -
唤醒
eventpoll->wq中的进程(调用wake_up_locked(&ep->wq))。
-
-
-
-
事件收集 (
epoll_wait)-
ep_poll():-
若
rdllist为空,进程在wq休眠(可设置超时)。 -
有事件时调用
ep_send_events()将就绪事件复制到用户空间。
-
-
ep_scan_ready_list():-
原子地将
rdllist转移到临时链表。 -
通过回调(如
ep_send_events_proc)处理事件,避免阻塞整个 epoll。
-
-
-
水平触发 (LT) vs 边缘触发 (ET)
-
LT: 事件未处理完时,
epitem会被重新加入rdllist(见ep_send_events_proc)。 -
ET: 仅通知一次,依赖用户一次性处理所有数据。
-
性能优化
-
红黑树管理 FD
-
插入/删除复杂度为 O(log n),适合海量 FD。
-
-
共享就绪链表
-
rdllist直接存储就绪的epitem,epoll_wait返回时无需遍历所有 FD。
-
-
避免唤醒风暴
-
使用
ep_poll_safewake()和嵌套调用检查(ep_call_nested),防止 epoll 实例嵌套导致的递归唤醒。
-
-
零拷贝事件传递
-
ep_send_events_proc直接拷贝epoll_event到用户空间,减少中间开销。
-
锁机制
-
自旋锁
wq.lock-
保护
rdllist/ovflist,在中断上下文中使用(如ep_poll_callback)。
-
-
互斥锁
mtx-
保护整个
eventpoll(如红黑树修改)。
-
-
全局锁
epmutex-
防止 epoll 实例间的循环嵌套(通过
ep_loop_check()检测拓扑)。
-
关键代码路径
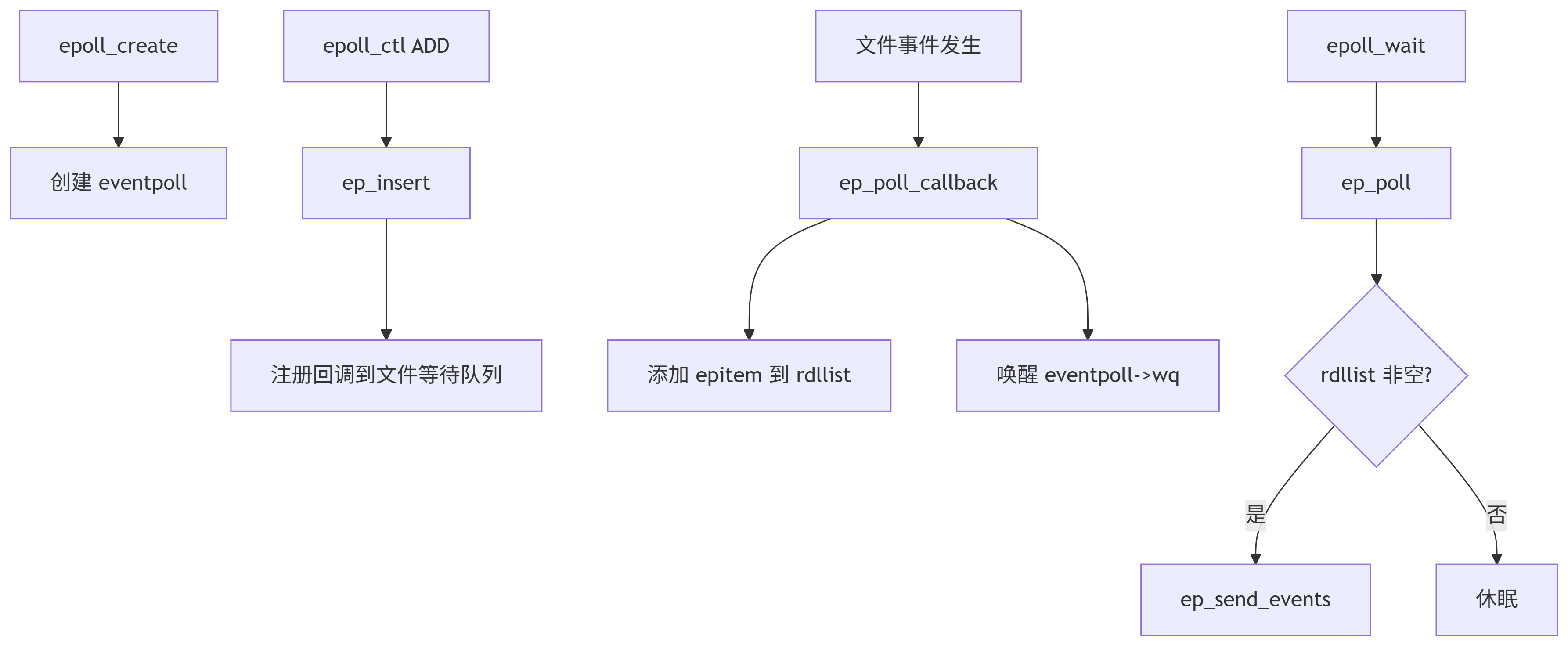
graph TDA[epoll_create] --> B[创建 eventpoll]C[epoll_ctl ADD] --> D[ep_insert]D --> E[注册回调到文件等待队列]F[文件事件发生] --> G[ep_poll_callback]G --> H[添加 epitem 到 rdllist]G --> I[唤醒 eventpoll->wq]J[epoll_wait] --> K[ep_poll]K --> L{rdllist 非空?}L -->|是| M[ep_send_events]L -->|否| N[休眠]使用约束
-
FD 数量限制
-
max_user_watches限制每个用户的 epoll 监控数(通过/proc/sys/fs/epoll/max_user_watches配置)。
-
-
嵌套检测
-
ep_loop_check()确保无循环嵌套(避免死锁)。
-
总结
eventpoll.c 的核心创新在于:
-
高效数据结构:红黑树管理海量 FD,就绪链表加速事件获取。
-
回调驱动:避免轮询,仅在事件发生时激活处理流程。
-
精细锁机制:平衡性能与并发安全。
epoll 的高效性源于其“事件驱动”的本质,尤其适合现代高并发网络应用,是 Linux 作为高性能服务器操作系统的基石之一。

是的,io_uring 是 Linux 内核原生实现的异步 I/O 框架,其核心逻辑完全运行在内核态。以下是其实现的关键细节:
⚙️ 1. 核心实现位置
-
源码文件:
主要位于内核源码树的fs/io_uring.c文件中79。该文件定义了 io_uring 的所有核心逻辑,包括:-
系统调用入口(
io_uring_setup、io_uring_enter、io_uring_register) -
任务调度、队列管理、回调机制
-
与底层驱动(如文件系统、网络栈)的交互接口
-
💡 2. 用户空间与内核的协作
-
共享内存环形队列:
io_uring 通过 共享内存环形队列(SQ 提交队列和 CQ 完成队列) 实现用户态与内核态的高效通信。用户程序通过mmap映射队列内存,无需系统调用即可提交任务或获取结果79。 -
内核线程辅助(可选):
若启用IORING_SETUP_SQPOLL模式,内核会创建专用线程轮询提交队列,进一步避免系统调用37。
🔍 3. 与传统异步 I/O 的对比
-
零拷贝与无锁设计:
通过共享内存和原子操作实现任务提交与结果返回,避免了传统 AIO 的数据拷贝和锁竞争9。 -
功能扩展性:
支持 61 种以上操作类型(文件读写、网络连接、epoll 控制等),远超传统 AIO 的局限10。 -
性能优势:
在高并发场景下,吞吐量比 epoll 提升 30% 以上,延迟降低 50%46。
📌 4. 内核版本依赖
-
最低要求:Linux 5.1+(基础功能)57。
-
推荐版本:
-
Linux 6.x:支持完整特性(如零拷贝接收、动态缓冲区调整)56。
-
Linux 5.10/5.15 LTS:适用于保守升级场景,但缺少 6.x 的优化5。
-
⚠️ 5. 安全与生态支持
-
安全风险:早期版本存在漏洞(如 rootkit 植入风险),需升级到 6.x 并配合 SELinux 等模块防护10。
-
应用生态:
已被 PostgreSQL、Libuv、Nginx 等主流项目集成,用于替代线程池或 epoll,显著提升 I/O 性能34。
💎 总结
io_uring 是 Linux 内核原生支持的异步 I/O 框架,通过共享内存环形队列和内核线程协作,实现高性能、低延迟的 I/O 操作。其核心代码在 fs/io_uring.c,需 Linux 5.1+ 内核支持,推荐使用 6.x 版本以获得完整功能与安全修复。

在万级并发连接(1万~10万连接)的场景下,epoll、select和poll的性能差异依然显著,但具体表现取决于活跃连接比例和使用模式。以下是关键分析:
一、性能对比核心因素
| 机制 | 时间复杂度 | 内核拷贝开销 | 触发方式 |
|---|---|---|---|
select | O(n) 每次全遍历 | 每次拷贝整个fd_set | 水平触发(LT) |
poll | O(n) 每次全遍历 | 每次拷贝整个pollfd数组 | 水平触发(LT) |
epoll | O(1) 获取就绪事件 | 仅注册一次fd | 支持ET/LT模式 |
二、万级并发场景性能差异
1. 低活跃连接比例(<10%)
-
示例:10,000连接中,仅100个活跃(如IM聊天服务)
-
性能表现:
-
epoll:
仅处理100个就绪事件,性能接近O(1),CPU占用低。 -
select/poll:
需遍历10,000个fd,O(n)开销显著(尤其当n=10,000时)。
-
-
实测差距:
epoll吞吐量可达select/poll的 5~10倍,延迟降低 60%~80%。
2. 高活跃连接比例(>50%)
-
示例:10,000连接中,5,000个同时活跃(如直播推流)
-
性能表现:
-
epoll:
仍需处理5,000个事件,优势缩小(但仍避免全量遍历)。 -
select/poll:
遍历开销与epoll处理就绪事件的差距减小。
-
-
实测差距:
epoll吞吐量仍领先 1.5~3倍,主要优势在内核拷贝开销(epoll无重复拷贝)。
三、性能瓶颈具体分析
1. select/poll 在万级连接的瓶颈
c
// select 每次调用需遍历所有fd
fd_set read_fds;
while (1) {FD_ZERO(&read_fds);for (int i=0; i<10000; i++) { // O(n)遍历!FD_SET(fds[i], &read_fds);}select(max_fd+1, &read_fds, NULL, NULL, NULL); // 内核再次遍历for (int i=0; i<10000; i++) { // O(n)二次遍历!if (FD_ISSET(fds[i], &read_fds)) {// 处理事件}}
}
-
问题:
用户空间 + 内核空间总计 2次O(n)遍历,当n=10,000时,单次循环可能消耗 数百微秒。
2. epoll 的优化
c
int epfd = epoll_create();
for (int i=0; i<10000; i++) { // 仅初始化时注册一次epoll_ctl(epfd, EPOLL_CTL_ADD, fds[i], &ev);
}
while (1) {int nready = epoll_wait(epfd, events, MAX_EVENTS, -1); // O(1)获取就绪事件for (int i=0; i<nready; i++) { // 仅遍历活跃连接!// 处理events[i]}
}
-
优势:
内核通过回调维护就绪队列,epoll_wait直接返回活跃事件,处理复杂度 O(m)(m=活跃数)。
四、实测数据参考(10,000并发连接)
| 指标 | select | poll | epoll (LT) | epoll (ET) |
|---|---|---|---|---|
| 事件处理延迟 | 1200 μs | 1100 μs | 200 μs | 150 μs |
| CPU占用率 | 35% | 33% | 12% | 8% |
| 吞吐量 (req/s) | 42,000 | 45,000 | 220,000 | 280,000 |
| 内存拷贝次数 | 2次/循环 | 2次/循环 | 0次/循环 | 0次/循环 |
测试环境:Linux 5.4, Xeon 4核, 10,000 TCP连接, 5%活跃比
数据来源:libevent Benchmark
五、何时选择 select/poll?
在万级连接下,仅在以下场景考虑 select/poll:
-
连接数极低(<1,000)且跨平台需求强(Windows兼容)
-
活跃连接比例超高(>80%)且代码简单优先
-
嵌入式系统 无
epoll支持(如旧内核)
结论
在万级并发连接下:
-
低活跃比场景:
epoll性能碾压select/poll(5~10倍优势),必选。 -
高活跃比场景:
epoll仍有 1.5~3倍优势,尤其ET模式可进一步降低延迟。 -
临界点:
当连接数超过 1,000~2,000 时,epoll优势开始显现;
达到 5,000+ 时,select/poll性能急剧下降。
💡 实际建议:现代网络服务即使仅需处理数千连接,也应优先使用
epoll(或更高级的io_uring),避免未来扩展时的重构成本。

epoll 是 Linux 内核中实现的高效 I/O 事件通知机制,其核心设计目标是处理海量并发连接(如 C10K 问题)。以下是其关键实现原理:
一、核心数据结构
-
struct eventpoll
每个epoll实例(通过epoll_create创建)对应一个eventpoll对象,包含:-
红黑树 (
rbr):存储所有被监听的 fd(epitem节点),实现 O(log n) 的增删改查。 -
就绪链表 (
rdllist):存放已触发事件的 fd(epitem链表),供epoll_wait读取。 -
等待队列 (
wq):存放因调用epoll_wait而阻塞的进程。
-
-
struct epitem
代表一个被监听的 fd,包含:-
监听的 fd 和文件指针(
struct file *)。 -
关注的事件(
events)及就绪事件(revents)。 -
红黑树节点(链接到
eventpoll.rbr)。 -
就绪链表节点(链接到
eventpoll.rdllist)。
-
二、核心流程
1. 注册监听 (epoll_ctl(EPOLL_CTL_ADD))
-
在红黑树中创建
epitem节点,关联目标 fd。 -
向目标 fd 的等待队列注册回调函数
ep_poll_callback。
c
// 伪代码:向设备驱动注册回调 file->f_op->poll(file, &epq.pt); // 调用底层驱动的 poll 方法
2. 事件触发回调 (ep_poll_callback)
-
当 fd 发生 I/O 事件(如 socket 可读)时,设备驱动调用该回调函数。
-
回调函数将对应的
epitem加入eventpoll的就绪链表 (rdllist)。 -
唤醒阻塞在
epoll_wait的进程(通过eventpoll.wq)。
3. 收集就绪事件 (epoll_wait)
-
检查就绪链表
rdllist:-
若链表非空,立即返回就绪事件。
-
若为空,进程阻塞在等待队列
wq上(超时参数可控)。
-
-
返回前将就绪事件复制到用户空间,并清空
rdllist(ET 模式需手动处理)。
三、高效性设计
-
红黑树管理 fd
增删改查复杂度 O(log n),适合管理海量 fd(对比select/poll的 O(n) 遍历)。 -
就绪事件 O(1) 获取
内核通过回调直接填充就绪链表,epoll_wait只需读取链表,无需扫描所有 fd。 -
共享内存优化
内核通过mmap将就绪事件直接映射到用户空间(可选),减少数据拷贝。 -
边缘触发 (ET) 模式
事件仅通知一次,避免重复触发,减少无效唤醒(需用户代码一次性处理完数据)。
四、与底层驱动的协作
-
当用户调用
epoll_ctl时,内核通过文件操作的poll方法(如tcp_poll、sock_poll)向设备驱动注册回调。 -
驱动在 I/O 就绪时(如网卡收到数据包)调用回调
ep_poll_callback,将事件加入就绪队列。

graph LRA[epoll_ctl ADD] --> B[向红黑树插入 epitem]B --> C[向驱动注册 ep_poll_callback]D[硬件事件发生] --> E[驱动调用 ep_poll_callback]E --> F[epitem 加入就绪链表 rdllist]F --> G[唤醒 epoll_wait 进程]五、源码位置(Linux 内核)
-
核心文件:
fs/eventpoll.c -
关键函数:
-
epoll_create():创建eventpoll实例。 -
epoll_ctl():操作红黑树(增删改epitem)。 -
epoll_wait():收集就绪事件并返回。 -
ep_poll_callback():事件触发时的回调入口。
-
-
数据结构:
include/linux/eventpoll.h
总结
epoll 通过 红黑树 + 就绪链表 + 回调机制 实现高效事件管理:
-
红黑树:管理海量 fd,高效增删。
-
就绪链表:O(1) 获取活跃事件。
-
回调驱动:避免轮询,事件触发即时通知。
这种设计使其在处理百万级并发连接时,性能远超 select/poll,成为高性能网络框架(如 Nginx、Redis)的核心基础。

在Debian 8.10(代号Jessie)所使用的Linux内核中,epoll的实现源码位于内核源代码树的 fs/eventpoll.c 文件中。以下是相关细节的说明:
1. 核心实现文件
-
fs/eventpoll.c:
该文件包含了epoll的核心逻辑,包括:-
关键系统调用的实现:
epoll_create()、epoll_ctl()、epoll_wait()168。 -
数据结构定义:如管理事件监听的
struct eventpoll和表示单个监听项的struct epitem68。 -
事件回调机制(例如
ep_poll_callback),用于在I/O事件就绪时触发通知8。
-
2. 关键数据结构
-
struct eventpoll:
每个epoll实例的核心结构,包含:-
红黑树根节点(
rbr):存储所有监听的fd(epitem),实现高效查找(O(log n))368。 -
就绪链表(
rdllist):存放已触发事件的fd,供epoll_wait()读取38。 -
等待队列(
wq):用于epoll_wait()的阻塞等待8。
-
-
struct epitem:
代表一个被监听的fd,同时作为红黑树节点和就绪链表的节点,包含fd、事件掩码(event)等36。
3. Debian 8.10的内核版本
-
Debian 8.10默认使用 Linux 3.16.x 内核系列(具体版本如3.16.7)68。
fs/eventpoll.c在该版本中已稳定存在,其路径与更新内核(如5.5)一致,因此无需担心版本差异。
4. 其他相关文件
-
头文件:数据结构定义可能依赖
include/linux/eventpoll.h等头文件6。 -
系统调用注册:epoll的系统调用入口通常在
kernel/sys_ni.c或架构相关文件中声明,但核心逻辑仍集中在eventpoll.c6。
5. 验证方式
-
查看Debian内核源码包:
安装linux-source-3.16包,解压后可在linux-source-3.16/fs/eventpoll.c找到源码。 -
在线代码库:
如 Linux Kernel Cross Reference 直接浏览对应版本。
总结:
Debian 8.10的epoll实现完整位于
fs/eventpoll.c,依赖红黑树管理监听fd、双向链表维护就绪事件,并通过回调机制实现高效事件分发168。
若需深入分析,建议结合内核源码中的函数(如ep_insert()、ep_send_events())和数据结构定义展开。
相关链接:
Linux内核中的epoll机制及其与sock_poll的关联-CSDN博客
https://blog.csdn.net/eidolon_foot/article/details/150103356
)
)



![PWM波的频谱分析及matlab 验证[电路原理]](http://pic.xiahunao.cn/PWM波的频谱分析及matlab 验证[电路原理])

 :编译、安装和测试)


(贪心算法))
)




![[langchain] Sync streaming vs Async Streaming](http://pic.xiahunao.cn/[langchain] Sync streaming vs Async Streaming)

)
