数据存储是后台服务系统永远绕不开的知识
笔者希望能够从宏观的角度出发,思考数据存储系统的共性和设计方案,尝试从Mysql和RocketMQ的角度去思考谈谈系统存储架构的设计哲学
前置的知识
什么是RocketMQ、什么是Mysql,他们对于后端系统的主用途有什么差异
RocketMQ本质上就是一个消息的中间件——强调的应该是消息的处理能力,对于整个消息的吞吐更为关系,如何高效率的完成MQ消息的收、存、发是MQ这个组件的核心思考
MySQL本质上是一个数据源,存放的是主数据——强调于DB的数据存储修改的能力,与业务系统的交互的ACID的能力,如何有更丰富的功能进行数据的查找和存储,也就是他对于数据的规则化甚至于大小会有更高的要求
这个两个主要用途的差异其实就造成了他们实际存储于磁盘的差异,也注定其实Mysqld的存储系统和存储结构会更加的复杂和全面
从RocketMQ入手来纵观这个消息中间件
RocketMQ的一个重要的特性
1. 顺序写——极致的顺序写(话说如果是这要不是分割的任务要落到服务端这个样子性能会高是怎么做到的)
2. 任务是流式任务——我不关心任务是什么东西,我只关心任务能不呢发出去能不呢存下来
所以RocketMQ本身的行为就是较为粗暴的——同时也是非常厉害的一个架构设计
将所有的元数据信息全部由一个文件存在一起,有一个msglen表明这个文件的长度——然后用msgbody进行分割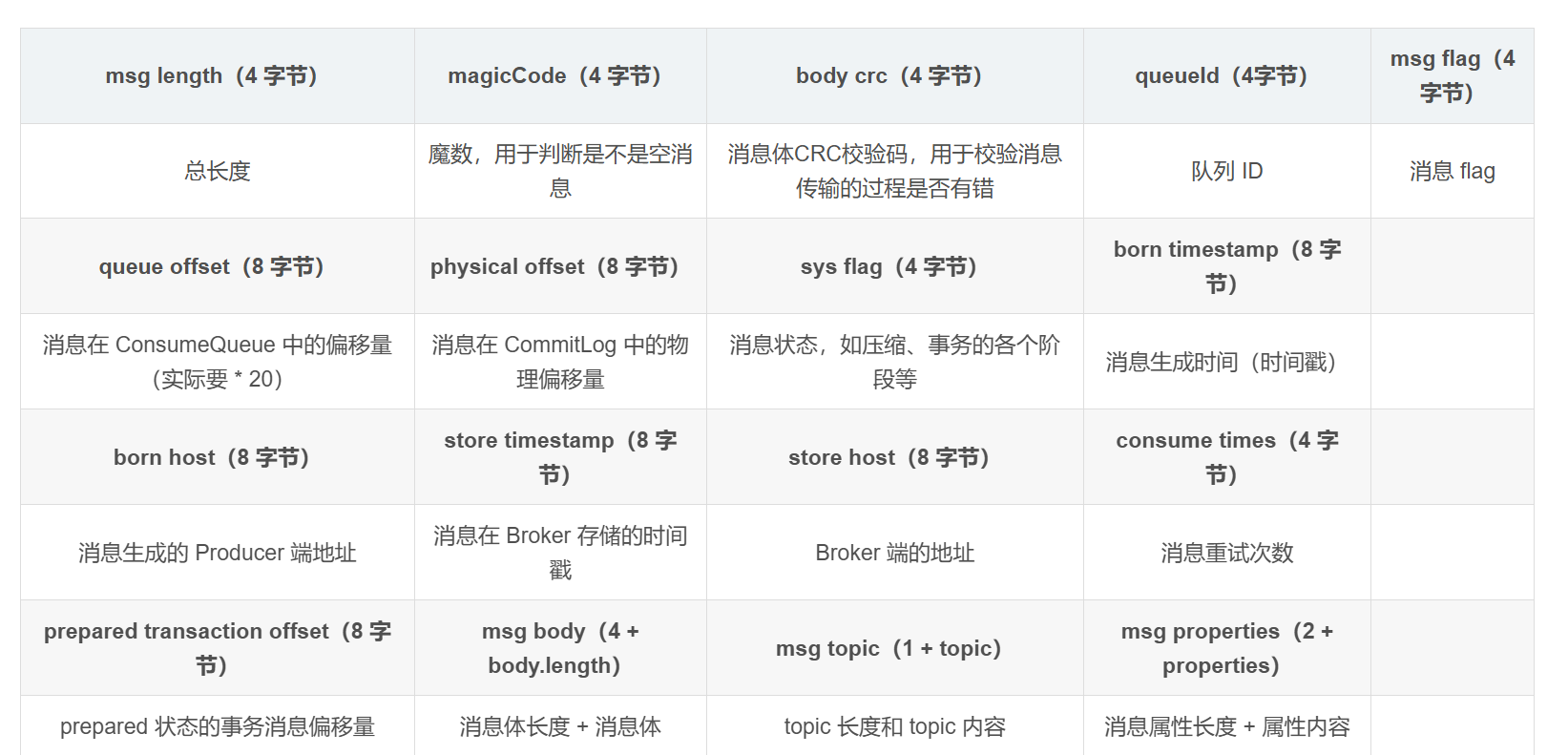
这个情况下其实存在一个非常明显的缺点
整个文件的元数据都放在一个文件里了,如果后续的消息增多了他的体积其实特别大
其次是因为极致的顺序写,如果后续消费者订阅的时候就需要额外的空间建立Index(也就是我们的consumequeueIndex)进行消息体的查询
无疑这个方案就是空间换时间的思想
试想一下,我们的Mysql的数据库中,能允许这个粗暴的方案吗?答案肯定是否定的
也就是这个Mysql因为对于空间的压缩(因为是主数据源),同时考虑到后期需要根据某些条件进行相关的查询,所以我们引入了一个逻辑的B+树的结构和一个优化存储的方法
而且数据的表结构是能变更的,数据的内容也要变更的,概括来说就是“数据可靠为基石,数据查询效率要高”
对于表结构的元数据,Mysql会专门分出一个数据结构表,每一张表都会有一个.frm的文件,这个存储元数据结构,数据的顺序,索引信息和相关——建立的是相关表结构的定义
对于数据库实际的行存储来看
MySQL其实是存储的是Compact化后的信息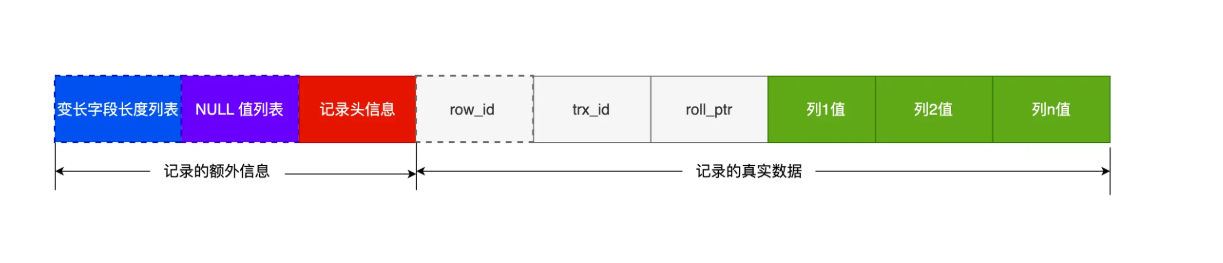
我们再此不讨论他的一个业务细节,了解思想即可
变长字段长度列表其实存储的是varchar()的相关信息,因为存储的时候的长度并不是确定的,需要一个变长的列表进行整个空间的说明,NULL标志位其实就是标记NULL值得——这里可以用bit进行表示(0表示一种状态、1表示一种状态),记录头信息这个东西比较重要的——稍后我也将从这个点去说明为什么我们需要记录整个行所占得字节,列数据就是实际的数据了(这里得详细信息推荐看小林CodingMySQL 一行记录是怎么存储的? | 小林coding)
记录头信息有什么?它需要做到什么?
在回答这个问题之前先看看Mysql的逻辑的B+树吧
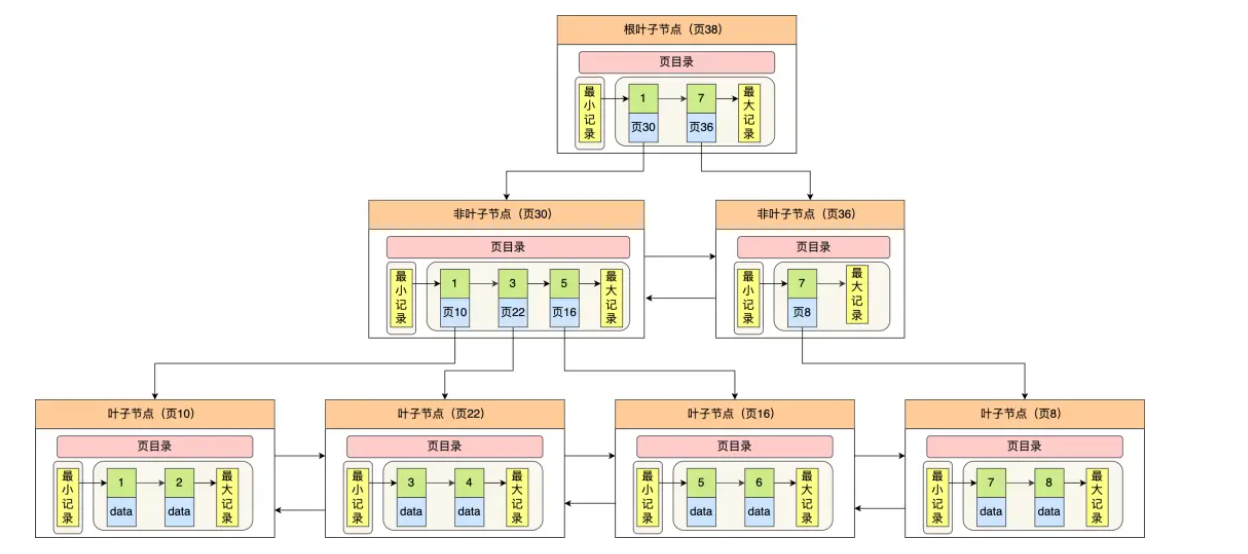
不难发现——行和行之间是有单向的指针相接的——那底层真的是指针吗?
显然是不可能得
那InnoDB要怎么存这个信息呢?——一般来说根据存储来看都是希望进行相对位置得偏移量得计算来得出最终的位置得——Mysql也是这样做的
来看看Compact头吧

在这个Compact头得基础下配合上.frm表结构元数据文件,InnoDB存储引擎能将相关得空间压缩到极致
从存储消息性能的角度理解结构的差异——为什么一个采取分页分区分段一个采用顺序写
RocektMQ存储模式与MySQL存储模式选型得核心差异和设计哲学——本质上就是存储文件的修改与否决定的——RocketMQ是典型的写优先的模型,后续数据不会修改;但是对于Mysql这种数据库来说读写改的操作相对就是平衡的,不存在所谓的写优先的场景的
修改的时候Mysql是以页为基本单位的,后续调整要是超过了相关的页存储的空间,会进行整页的复制,将数据记录复制到新的页中
这个时候的读写相对是平衡的
从存储本身的需求理解结构的差异——为什么行两个系统的存储的元数据结构差异较大
对于Mysql来说DB需要为每一个数据定一个结构——这就是为什么有.frm这个表结构元数据的原因
存在表结构的元数据,结构就有一定格式
进而这就是为什么可以用相关的转义字段进行优化——节省空间内存
有NULL值的存在,所以这就是为什么希望有一个bit能对这个NULL存的优化
数据库的基本能力是要有事务保证即ACID
Mysql的undolog是保证原子性的基础——这也就是为什么数据结构会有roll-ptr指针的核心
为了实现隔离性、Mysql底层会依赖于MVCC极致——这个时候trx-id其实发挥了很重要的作用
希望满足B+树的范围查询——所以我们会有逻辑指针指向下一个节点的关系
对于RocketMQ来说完全没有这个需求
msgLen 进行整个消息的总长度的划定
queueID指明队列的ID
queueOffset指明队列的逻辑偏移量
physicalOffSet指明的是commitlog中的偏移量——物理偏移量
bodyLength指明消息体的长度
body转存具体的内容
结合文件的偏移量+长度(size)我们完全可以轻而易举的提取到整个文件
对于MQ来说只要能提取出来,其他的修改和划页存储都不重要了——当然他因为用顺序存取,所以希望划分结构也是很困难的事情更重要的是它不需要把整个系统划分更细致的数据结构
)
:锁问题排查全攻略——揪出“阻塞元凶”)


-- 集合类型)
:在QtOpenGL环境下,按需加载彩虹四边形的顶点属性 (Unity、Unreal Engine、Three.js与Godot))










)


