GraphRAG——v0.3.6版本使用详细教程、GraphRAG数据写入Neo4j图数据库、GraphRAG与Dify集成
- 理论部分
- 安装
- 知识图谱生成
- 测试
- 将数据导入到Neo4j图数据库可视化
- 将GraphRAG与Dify集成
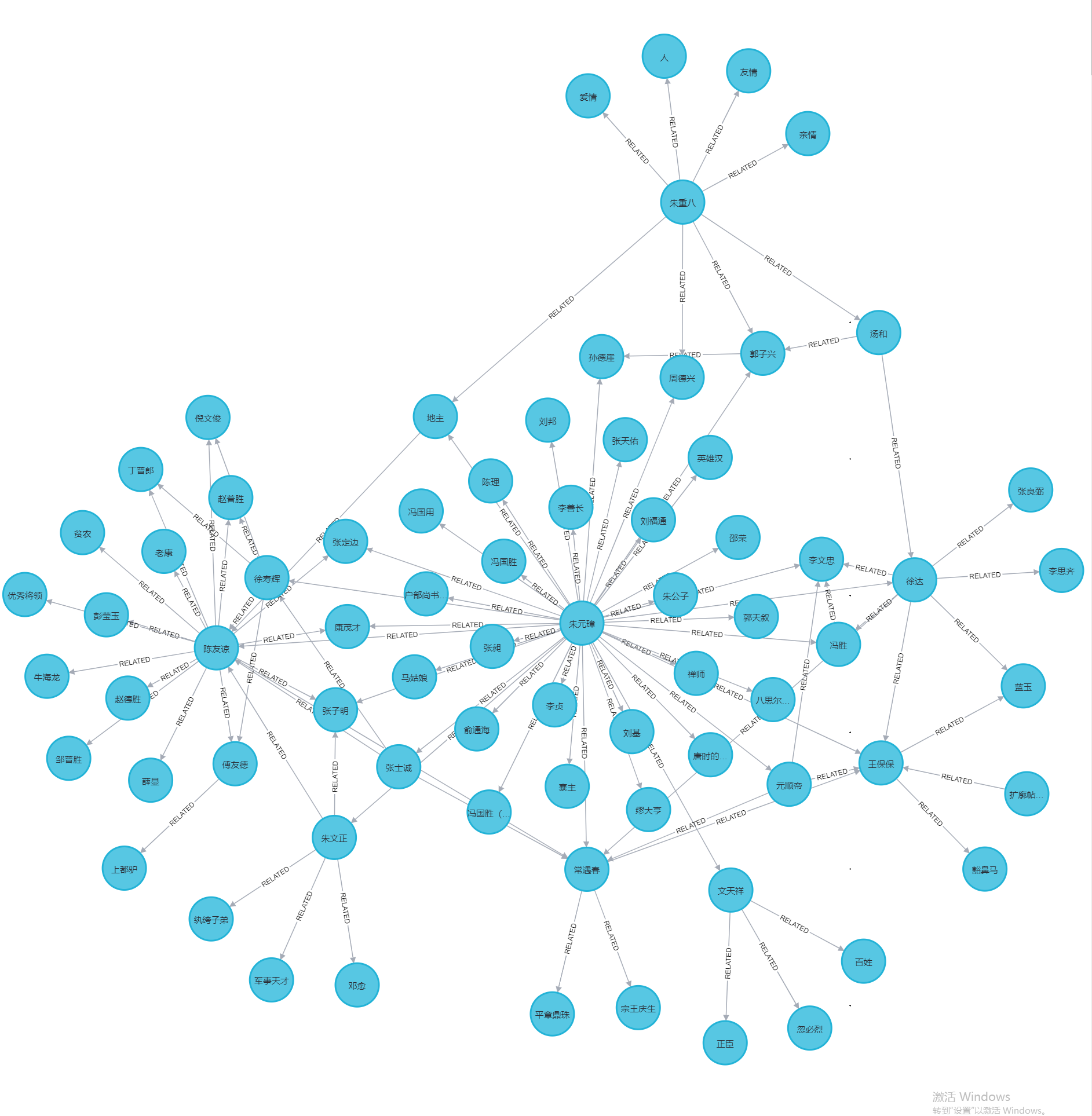
理论部分
https://guoqingru.blog.csdn.net/article/details/150771388?spm=1011.2415.3001.5331
安装
## 创建虚拟环境
conda create -n GraphRAG_0_3_6 python=3.11# 激活虚拟环境
source activate GraphRAG_0_3_6# 安装相关依赖包
# 我安装的版本是graphrag==0.3.5
pip install graphrag==0.3.5 --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simplepip install future --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install fastapi==0.112.0 --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple uvicorn==0.30.6
知识图谱生成
# 创建文件目录
mkdir -p ./ragtest/input#下载测试txt文档
curl https://www.gutenberg.org/cache/epub/24022/pg24022.txt -o ./ragtest/input/book.txt# 设置你的工作区变量
"""
要初始化你的工作区,首先运行 graphrag init 命令。由于我们在上一步已经配置了一个名为 ./ragtest 的目录,运行以下命令:
"""
# 初始化配置(首次)
python -m graphrag.index --init --root ./ragtest
其会生成相关的文件如下所示:
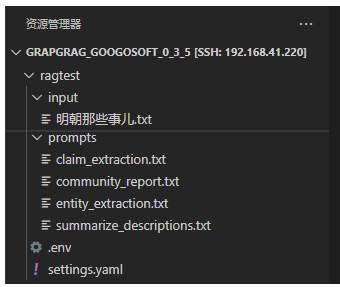
修改相关的配置文件settings.yaml,内容如下:
encoding_model: cl100k_base
skip_workflows: []
llm:api_key: ${GRAPHRAG_API_KEY}type: openai_chat # or azure_openai_chatmodel: gpt-3.5-turbomodel_supports_json: true # recommended if this is available for your model.# max_tokens: 4000# request_timeout: 180.0api_base: http://192.168.41.216:8082/v1 # api_version: 2024-02-15-preview# organization: <organization_id># deployment_name: <azure_model_deployment_name># tokens_per_minute: 150_000 # set a leaky bucket throttle# requests_per_minute: 10_000 # set a leaky bucket throttlemax_retries: 10# max_retry_wait: 10.0# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-timesconcurrent_requests: 25 # the number of parallel inflight requests that may be made# temperature: 0 # temperature for sampling# top_p: 1 # top-p sampling# n: 1 # Number of completions to generateparallelization:stagger: 0.3# num_threads: 50 # the number of threads to use for parallel processingasync_mode: threaded # or asyncioembeddings:## parallelization: override the global parallelization settings for embeddingsasync_mode: threaded # or asynciollm:api_key: ${GRAPHRAG_API_KEY}type: openai_embedding # or azure_openai_embeddingmodel: gpt-4api_base: http://192.168.41.216:8080/v1# api_version: 2024-02-15-preview# organization: <organization_id># deployment_name: <azure_model_deployment_name># tokens_per_minute: 150_000 # set a leaky bucket throttle# requests_per_minute: 10_000 # set a leaky bucket throttlemax_retries: 10# max_retry_wait: 10.0# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times# concurrent_requests: 25 # the number of parallel inflight requests that may be made# batch_size: 16 # the number of documents to send in a single request# batch_max_tokens: 8191 # the maximum number of tokens to send in a single request# target: required # or optionalchunks:size: 1200overlap: 100group_by_columns: [id] # by default, we don't allow chunks to cross documentsinput:type: file # or blobfile_type: text # or csvbase_dir: "input"file_encoding: utf-8file_pattern: ".*\\.txt$"cache:type: file # or blobbase_dir: "cache"# connection_string: <azure_blob_storage_connection_string># container_name: <azure_blob_storage_container_name>storage:type: file # or blobbase_dir: "output/${timestamp}/artifacts"# connection_string: <azure_blob_storage_connection_string># container_name: <azure_blob_storage_container_name>reporting:type: file # or console, blobbase_dir: "output/${timestamp}/reports"# connection_string: <azure_blob_storage_connection_string># container_name: <azure_blob_storage_container_name>entity_extraction:## llm: override the global llm settings for this task## parallelization: override the global parallelization settings for this task## async_mode: override the global async_mode settings for this taskprompt: "prompts/entity_extraction.txt"entity_types: [organization,person,geo,event]max_gleanings: 1summarize_descriptions:## llm: override the global llm settings for this task## parallelization: override the global parallelization settings for this task## async_mode: override the global async_mode settings for this taskprompt: "prompts/summarize_descriptions.txt"max_length: 500claim_extraction:## llm: override the global llm settings for this task## parallelization: override the global parallelization settings for this task## async_mode: override the global async_mode settings for this taskenabled: trueprompt: "prompts/claim_extraction.txt"description: "Any claims or facts that could be relevant to information discovery."max_gleanings: 1community_reports:## llm: override the global llm settings for this task## parallelization: override the global parallelization settings for this task## async_mode: override the global async_mode settings for this taskprompt: "prompts/community_report.txt"max_length: 2000max_input_length: 8000cluster_graph:max_cluster_size: 10embed_graph:enabled: false # if true, will generate node2vec embeddings for nodes# num_walks: 10# walk_length: 40# window_size: 2# iterations: 3# random_seed: 597832umap:enabled: false # if true, will generate UMAP embeddings for nodessnapshots:graphml: falseraw_entities: falsetop_level_nodes: falselocal_search:# text_unit_prop: 0.5# community_prop: 0.1# conversation_history_max_turns: 5# top_k_mapped_entities: 10# top_k_relationships: 10# llm_temperature: 0 # temperature for sampling# llm_top_p: 1 # top-p sampling# llm_n: 1 # Number of completions to generate# max_tokens: 12000global_search:# llm_temperature: 0 # temperature for sampling# llm_top_p: 1 # top-p sampling# llm_n: 1 # Number of completions to generate# max_tokens: 12000# data_max_tokens: 12000# map_max_tokens: 1000# reduce_max_tokens: 2000# concurrency: 32
注意:
claim_extraction:enabled: true # 一定要将其改成true,否则不会生成create_final_covariates.parquet文件
经过上述配置文件修改后
我在生成过程中,当所处理的文本较短时,可以正常生成如下所需文件
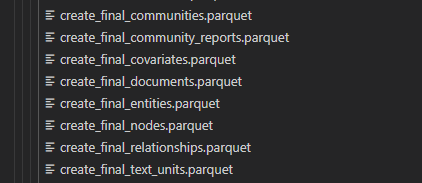
问题:
当时当文本文件较大时,create_final_community_reports.parquet文件会没有生成,这个问题待解决
上述修改完毕后,在项目根目录下执行以下语句:
# 开始索引生成
python -m graphrag.index --root ./ragtest
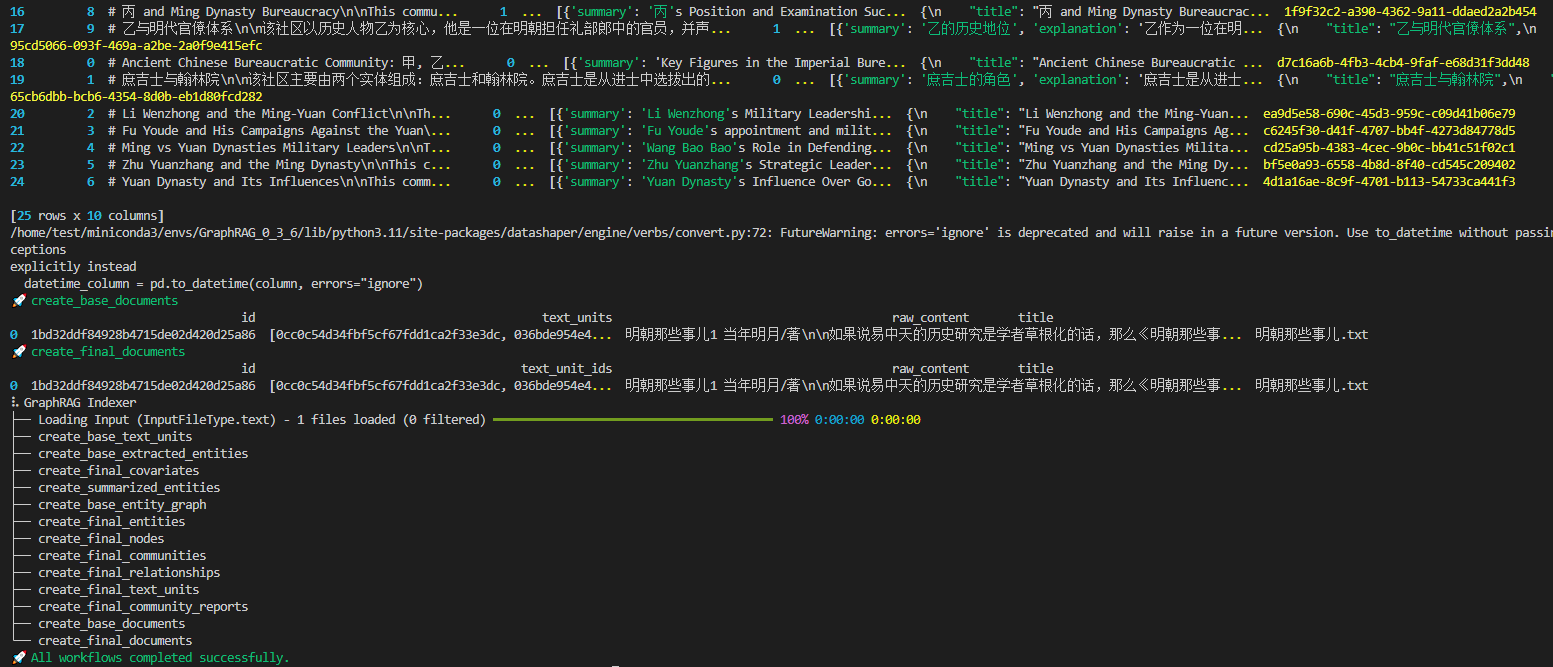
测试
我所采用数据文本是《明朝那些事儿》第一册
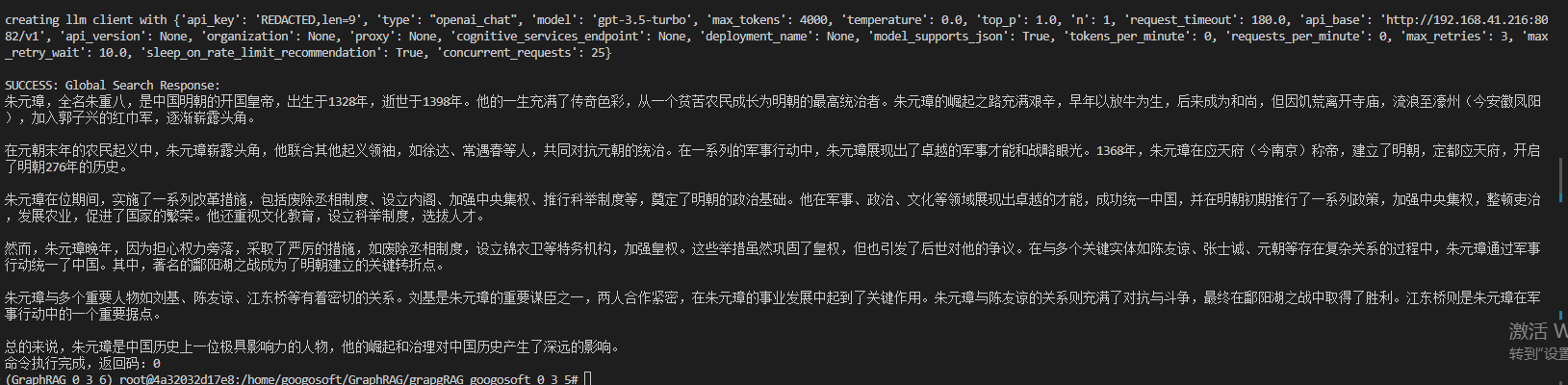
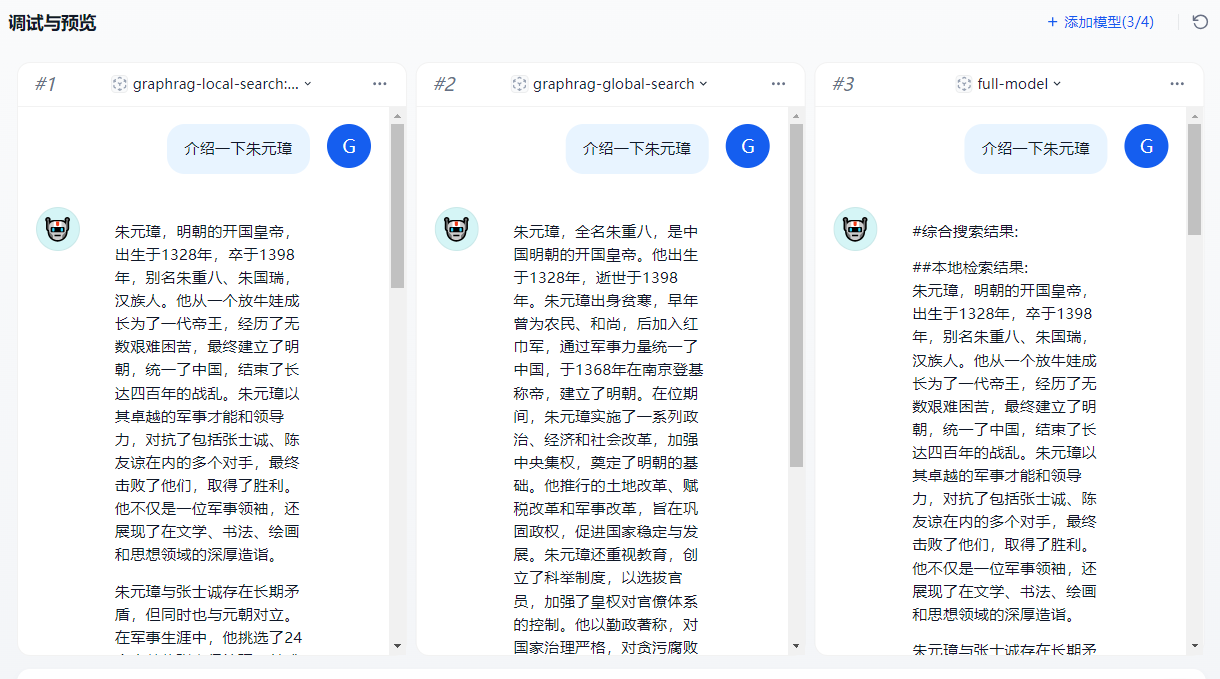
python -m graphrag.query --root ./ragtest --method global "介绍一下朱元璋的生平"
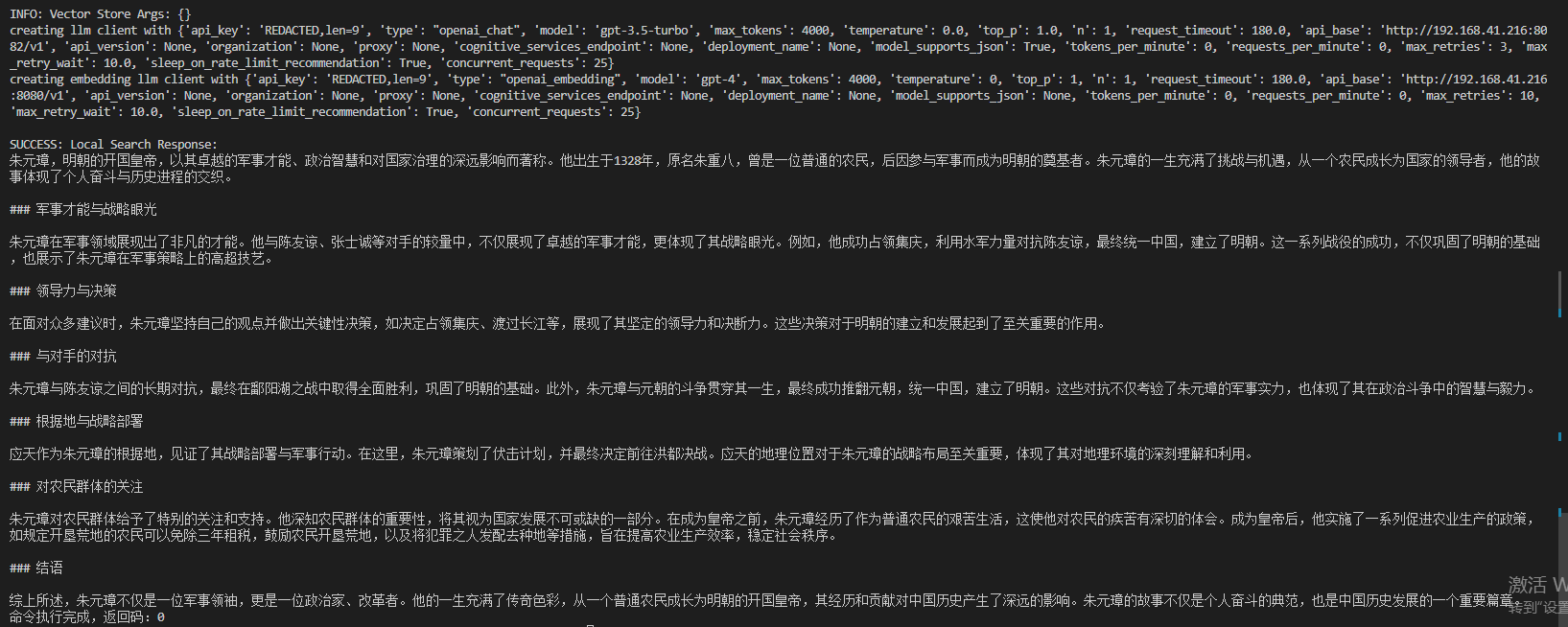
python -m graphrag.query --root ./ragtest --method local "详细的介绍一下马皇后"
global
local
将数据导入到Neo4j图数据库可视化
在项目过程中,由于GraphRAG版本的差异,相应的字段信息不同,致使0.3.x以下的GraphRAG生成的知识图谱与较新的版本生成的字段不同,在执行官方提供的插入Neo4数据库的执行语句会失败
Neo4j执行语句如下:
import pandas as pd
from neo4j import GraphDatabase
import time
NEO4J_URI = "neo4j://192.168.41.220:7687" # or neo4j+s://xxxx.databases.neo4j.io
NEO4J_USERNAME = "neo4j"
NEO4J_PASSWORD = "googosoft" #你自己的密码
NEO4J_DATABASE = "neo4j"# Create a Neo4j driver
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USERNAME, NEO4J_PASSWORD))# 检查连接
try:driver.verify_connectivity()print("✅ 成功连接到 Neo4j 数据库!")
except Exception as e:print("❌ 无法连接到 Neo4j:", e)# 重置数据库:删除所有节点和关系
reset_cypher = """
MATCH (n)
DETACH DELETE n
"""
with driver.session(database=NEO4J_DATABASE) as session:session.run(reset_cypher)print("🗑️ 数据库已重置(所有节点和关系已删除)")GRAPHRAG_FOLDER = "/home/googosoft/GraphRAG/grapgRAG_googosoft_0_3_5/ragtest/output/20250826-213649/artifacts"statements = """
create constraint chunk_id if not exists for (c:__Chunk__) require c.id is unique;
create constraint document_id if not exists for (d:__Document__) require d.id is unique;
create constraint entity_id if not exists for (c:__Community__) require c.community is unique;
create constraint entity_id if not exists for (e:__Entity__) require e.id is unique;
create constraint entity_title if not exists for (e:__Entity__) require e.name is unique;
create constraint entity_title if not exists for (e:__Covariate__) require e.title is unique;
create constraint related_id if not exists for ()-[rel:RELATED]->() require rel.id is unique;
""".split(";")for statement in statements:if len((statement or "").strip()) > 0:print(statement)driver.execute_query(statement)def batched_import(statement, df, batch_size=1000):"""Import a dataframe into Neo4j using a batched approach.Parameters: statement is the Cypher query to execute, df is the dataframe to import, and batch_size is the number of rows to import in each batch."""total = len(df)start_s = time.time()for start in range(0,total, batch_size):batch = df.iloc[start: min(start+batch_size,total)]result = driver.execute_query("UNWIND $rows AS value " + statement,rows=batch.to_dict('records'),database_=NEO4J_DATABASE)print(result.summary.counters)print(f'{total} rows in { time.time() - start_s} s.')return totaldoc_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/create_final_documents.parquet', columns=["id", "title"])
doc_df.head(2)# import documents
statement = """
MERGE (d:__Document__ {id:value.id})
SET d += value {.title}
"""batched_import(statement, doc_df)text_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/create_final_text_units.parquet',columns=["id","text","n_tokens","document_ids"])
text_df.head(2)statement = """
MERGE (c:__Chunk__ {id:value.id})
SET c += value {.text, .n_tokens}
WITH c, value
UNWIND value.document_ids AS document
MATCH (d:__Document__ {id:document})
MERGE (c)-[:PART_OF]->(d)
"""batched_import(statement, text_df)entity_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/create_final_entities.parquet',columns=["name", "type", "description", "human_readable_id", "id", "description_embedding","text_unit_ids"])
entity_df.head(2)entity_statement = """
MERGE (e:__Entity__ {id:value.id})
SET e += value {.human_readable_id, .description, name:replace(value.name,'"','')}
WITH e, value
CALL db.create.setNodeVectorProperty(e, "description_embedding", value.description_embedding)
CALL apoc.create.addLabels(e, case when coalesce(value.type,"") = "" then [] else [apoc.text.upperCamelCase(replace(value.type,'"',''))] end) yield node
UNWIND value.text_unit_ids AS text_unit
MATCH (c:__Chunk__ {id:text_unit})
MERGE (c)-[:HAS_ENTITY]->(e)
"""batched_import(entity_statement, entity_df)rel_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/create_final_relationships.parquet',columns=["source", "target", "id", "rank", "weight", "human_readable_id", "description","text_unit_ids"])
rel_df.head(2)rel_statement = """MATCH (source:__Entity__ {name:replace(value.source,'"','')})MATCH (target:__Entity__ {name:replace(value.target,'"','')})// not necessary to merge on id as there is only one relationship per pairMERGE (source)-[rel:RELATED {id: value.id}]->(target)SET rel += value {.rank, .weight, .human_readable_id, .description, .text_unit_ids}RETURN count(*) as createdRels
"""batched_import(rel_statement, rel_df)community_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/create_final_communities.parquet',columns=["id", "level", "title", "text_unit_ids", "relationship_ids"])community_df.head(2)statement = """
MERGE (c:__Community__ {community:value.id})
SET c += value {.level, .title}
/*
UNWIND value.text_unit_ids as text_unit_id
MATCH (t:__Chunk__ {id:text_unit_id})
MERGE (c)-[:HAS_CHUNK]->(t)
WITH distinct c, value
*/
WITH *
UNWIND value.relationship_ids as rel_id
MATCH (start:__Entity__)-[:RELATED {id:rel_id}]->(end:__Entity__)
MERGE (start)-[:IN_COMMUNITY]->(c)
MERGE (end)-[:IN_COMMUNITY]->(c)
RETURn count(distinct c) as createdCommunities
"""batched_import(statement, community_df)community_report_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/create_final_community_reports.parquet',columns=["id", "community", "level", "title", "summary", "findings", "rank","rank_explanation", "full_content"])
community_report_df.head(2)
# import communities
community_statement = """MATCH (c:__Community__ {community: value.community})
SET c += value {.level, .title, .rank, .rank_explanation, .full_content, .summary}
WITH c, value
UNWIND range(0, size(value.findings)-1) AS finding_idx
WITH c, value, finding_idx, value.findings[finding_idx] as finding
MERGE (c)-[:HAS_FINDING]->(f:Finding {id: finding_idx})
SET f += finding"""
batched_import(community_statement, community_report_df)
将GraphRAG与Dify集成
在完成上述的任务后,我编写代码提供了一个api接口,以便可以集成到Dify中
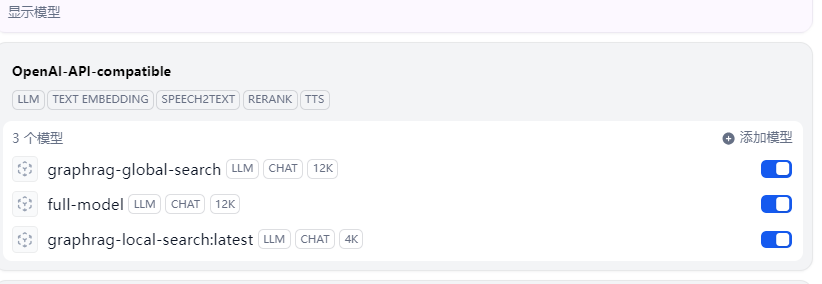
由于GraphRAG有两种问答模型,分别是global与local模式,所以我配置了三种,即global、local与混合模型
接口配置截图
模型选择
模型测试
高级用法:数据统计与分析)

识别数据集:12k+图像,yolo标注)


:基于PyTorch的VGG16-SE网络实战)
![[电商网站-动态渲染商品-尺寸、尺码、颜色图片等];库存缺货状态动态对应。](http://pic.xiahunao.cn/[电商网站-动态渲染商品-尺寸、尺码、颜色图片等];库存缺货状态动态对应。)

)



)





 - LeetCode】437. 路径总和 III)
 方法详解)