第一次知道VAE可能还是许嵩。当然,这里的VAE指的是变分自编码器(Variational Autoencoder, VAE)
Seq2Seq
在 Seq2Seq 框架提出之前,深度神经网络在图像分类等问题上取得了非常好的效果。在其擅长解决的问题中,==输入和输出通常都可以表示为固定长度的向量==,如果长度稍有变化,会使用填充(Padding)等操作,其目的是将序列数据转换成固定长度的格式,以便于输入到需要固定长度输入的神经网络中。
但是,Padding可能引入的问题:例如在计算损失时可能需要特殊的处理来忽略这些补零的元素,以免它们影响模型的训练效果。这通常通过使用掩码(Mask)来实现,掩码可以指示哪些位置是补零的,以便在计算过程中忽略这些位置。然而许多重要的问题,例如机器翻译、语音识别、对话系统等,表示成序列后,其长度事先并不知道。
结构最重要的地方在于输入序列和输出序列的长度是可变的。
Encoder-Decoder
Transformer的设计为Encoder-Decoder结构。其实和seq2seq是差不多的,只不过从名字上看,seq2seq关注的是输入输出的形式,Encoder-Decoder关注的是结构。
这里简单再回顾一下Transformer。对于ByteNet and ConvS2S,计算长距离的操作次数分别是指数和线性的,而Transformer把次数降低到了常数次。虽然位置注意力加权造成了有效分辨率的降低,但是可以通过多头注意力机制来弥补。
使用循环自注意力机制而非序列对齐的循环网络,已经被证明是有效的,Transformer则完全只使用self-attention计算输入输出的representations,而没有使用sequence aligned RNNs or convolution
encoder是把input sequence 的symbol representations转换为representations z,decoder是把symbols的一个个element转换为output sequence。网络是自回归的,这意味着之前产生的symbols可以作为下一个的额外输入。
下面这幅图的左右两边就是encoder and decoder:
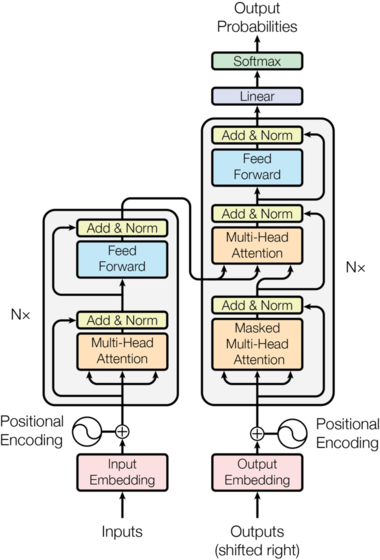
encoder由6层layer堆叠得到,即上图中的N=6。每个layer又有两个sub-layers,分别是multi-head self-attention, 和position-wise fully connected feed- forward network,两个部分由又都有残差的连接:
class EncoderLayer(nn.Module):"Encoder is made up of self-attn and feed forward (defined below)"def __init__(self, size, self_attn, feed_forward, dropout):super(EncoderLayer, self).__init__()self.self_attn = self_attnself.feed_forward = feed_forwardself.sublayer = clones(SublayerConnection(size, dropout), 2)self.size = sizedef forward(self, x, mask):"Follow Figure 1 (left) for connections."x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))。# 注意力部分的残差return self.sublayer[1](x, self.feed_forward) # ffn的残差# SublayerConnection 不光包含了残差,还有layerNorm,Dropoutdecoder也是6层堆叠,不过sublayer是3层,多出来的multi-head attention负责处理encoder的输z出。
class DecoderLayer(nn.Module):"Decoder is made of self-attn, src-attn, and feed forward (defined below)"def __init__(self, size, self_attn, src_attn, feed_forward, dropout):super(DecoderLayer, self).__init__()self.size = sizeself.self_attn = self_attnself.src_attn = src_attnself.feed_forward = feed_forwardself.sublayer = clones(SublayerConnection(size, dropout), 3)def forward(self, x, memory, src_mask, tgt_mask):"Follow Figure 1 (right) for connections."m = memoryx = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))。# 关注selfx = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask)) # 关注encoder的输出return self.sublayer[2](x, self.feed_forward) # forward之后加残差注意,在self attention的部分是带masked的,这样是为了避免当前位置关注到后续位置:
prevent positions from attending to subsequent positions subsequent positions。
使用mask二维的行和列分别表示当前位置和对应能注意到的最远的位置,所以画出来就是一个上三角矩阵:
def subsequent_mask(size):"Mask out subsequent positions."attn_shape = (1, size, size)subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')return torch.from_numpy(subsequent_mask) == 0plt.figure(figsize=(5,5))
plt.imshow(subsequent_mask(20)[0])
这个mask机制,还有输出embding偏移一个位置的机制一起作用,保证了输出只受前面的输出的影响。
AE(自动编码器Auto-Encoder)
Encoder-Decoder是把输入和输出做映射,所以适用于自监督学习也可以监督学习。自编码器就是针对自监督或者无监督学习的,所以它关注是自我的重构,所以通常是一个对称的网络结构,即编码器和解码器具有相似的结构,甚至是对称的。
理想的AE的输入和输出是完全一样的,那么好好的图像我处理半天还是原来的图像,意义何在呢?其实在Encoder和Decoder之间还有一个Bottleneck,它存在是为了限制从编码器到解码器的信息流,因此只允许最重要的信息通过。
由于瓶颈的设计方式是将图像所拥有的最大信息捕获在其中,所以AE的作用之一就是来降维,或者说压缩图像。这种AE其实就是不完整的自动编码器 Undercomplete autoencoders。
此外,还有去噪自动编码器 Denoising autoencoders:
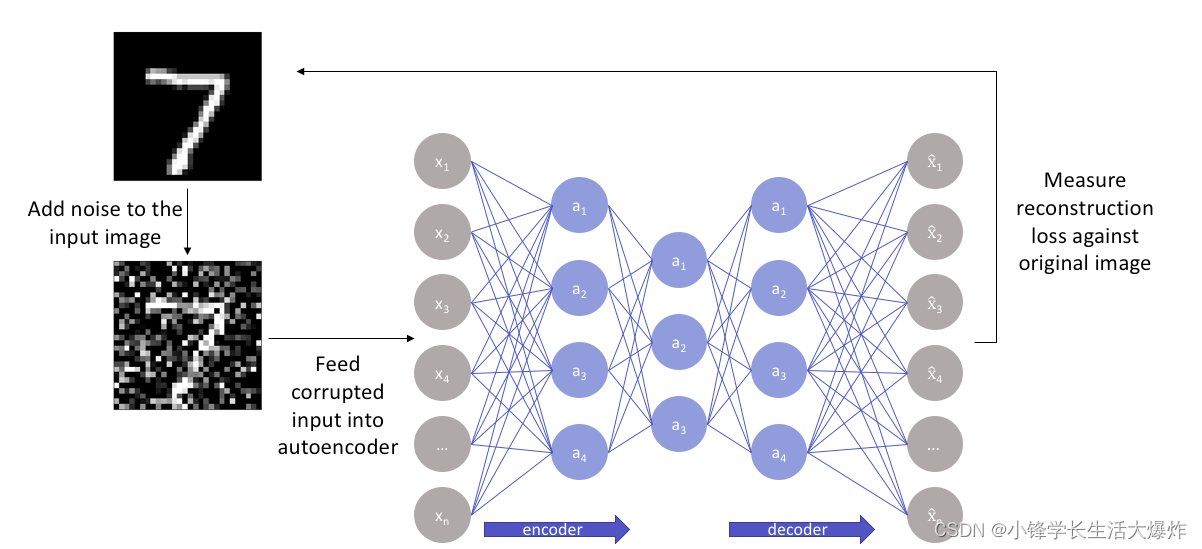
在对自动编码器进行去噪处理时,我们输入图像的嘈杂版本,其中噪声是通过数字更改添加的。噪声图像被馈送到编码器-解码器架构,并将输出与真值图像进行比较。
你会发现,这其实就是图像去噪领域中最常用的结构。背后的原理是自动编码器通过将输入数据映射到低维流形(如在不完整的自动编码器中)来执行此操作,其中噪声滤波变得更加容易。
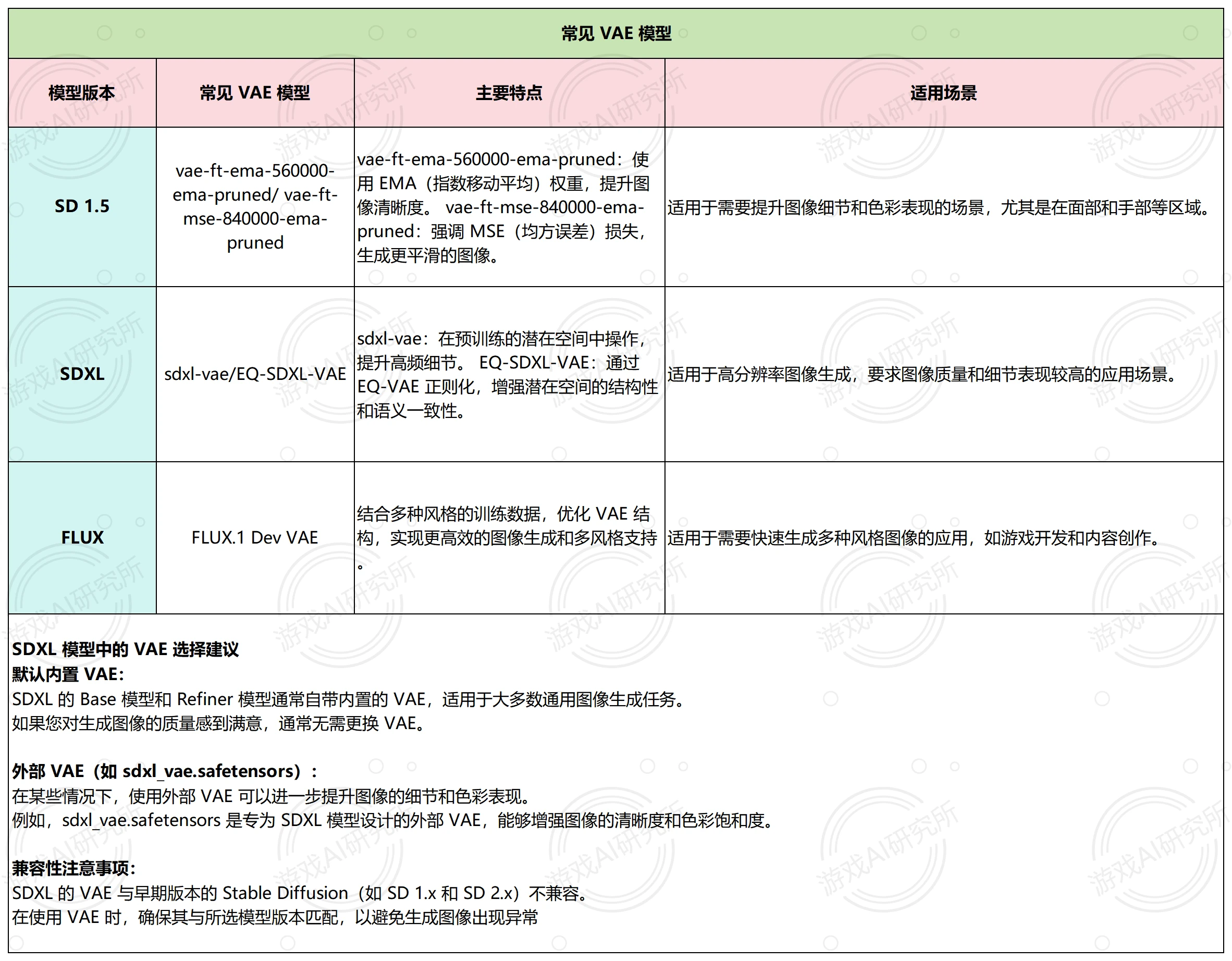
VAE( 变分自编码器Variational Auto-Encoder)
终于到了VAE。VAE最开始由Kingma and Welling在2014年提出,论文是Auto-Encoding Variational Bayes。在Tutorial on Diffusion Models for Imaging and Vision中,第一节讲的就是VAE,甚至在DDPM之前。
既然是AE的一种,那在结构上仍然有encoder和decoder,目的和作用仍然是通过重建自身学习图像的特征表示。VAE的核心特点在于,它不是将输入直接映射到一个固定的向量,而是将输入映射到一个概率分布上。这种方法使得VAE不仅能够进行数据重构,还能生成新的、与输入数据相似的数据。
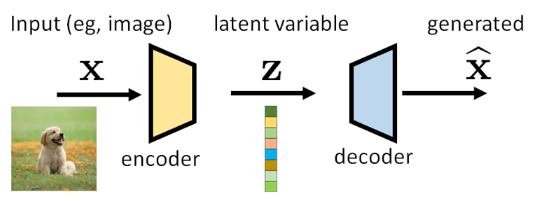
由encoder编码的 z称为隐式变量latent variable,z充当了encoder和decoder之间承上启下的工作,一方面从x中压缩信息,虽然是有损的lossy,但是却封装了x的重要的高级语义信息;另一方面z又是decoder的seed,决定了生成的结果。我们熟知的JPEG压缩中的DCT变换其实就是得到z的过程,余弦的系数就是z,而DCT和逆DCT就是encoder和decoder;
x,z都可以分别使用概率分布来表示,并且通过条件转移概率来表示。所以VAE其实是一个贝叶斯网络。在VAE的假设之中,我们常常直接将分布p(z)假设为一个零均值、单位方差的高斯分布 ,真实的分布可能与这个假设相差甚远,但是做这样一个假设有着多个优点:1.高斯分布的线性变换依旧为一个高斯分布,数据处理简单;2.只要将高斯分布通过足够复杂的映射函数,就能得到任何一种分布.
一个例子就是高斯混合模型,GMM,Gaussian Mixture Module,它是多个高斯模型的加权:
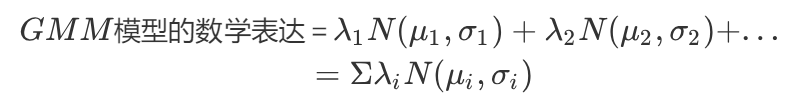
可以得到x的概率分布,这是一个total probability全概率的形式:
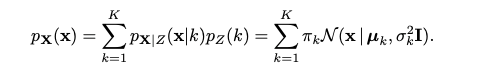
k表示第k个cluster,表示第k类的权重。
那么encoder做的就是从x提取z,就是在判断x属于哪个类,把样本映射到了一个分布上。decoder就会在那一类z中做一个采样。恢复的过程仍然是贝叶斯全概率的形式:
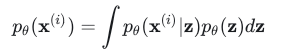
theta是z的分布相关参数。但是上面的公式需要找到所有z的可能取值,这是不可能的,所以VAE引入贝叶斯变分中近似表示的方法,使用NN来表示encoder和decoder,相关参数分别使用和
来表示:
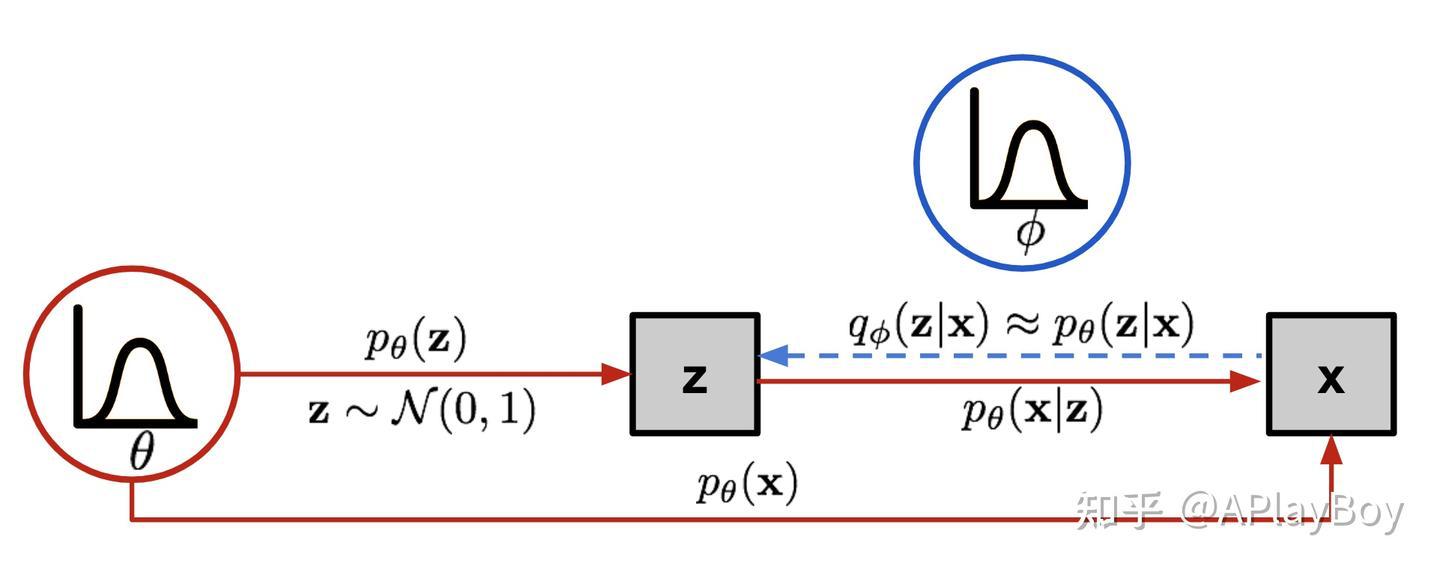
为了得到这两个参数,就需要设立一个目标函数或者说loss函数。我们在这使用的损失函数被称为“证据下界”(Evidence Lower Bound, ELBO)
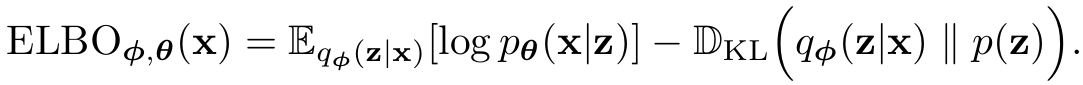
除了基于KL散度的ELBO,VAE还使用了重参数化,模拟采样,使得网络可以反向传播。从而可以训练:
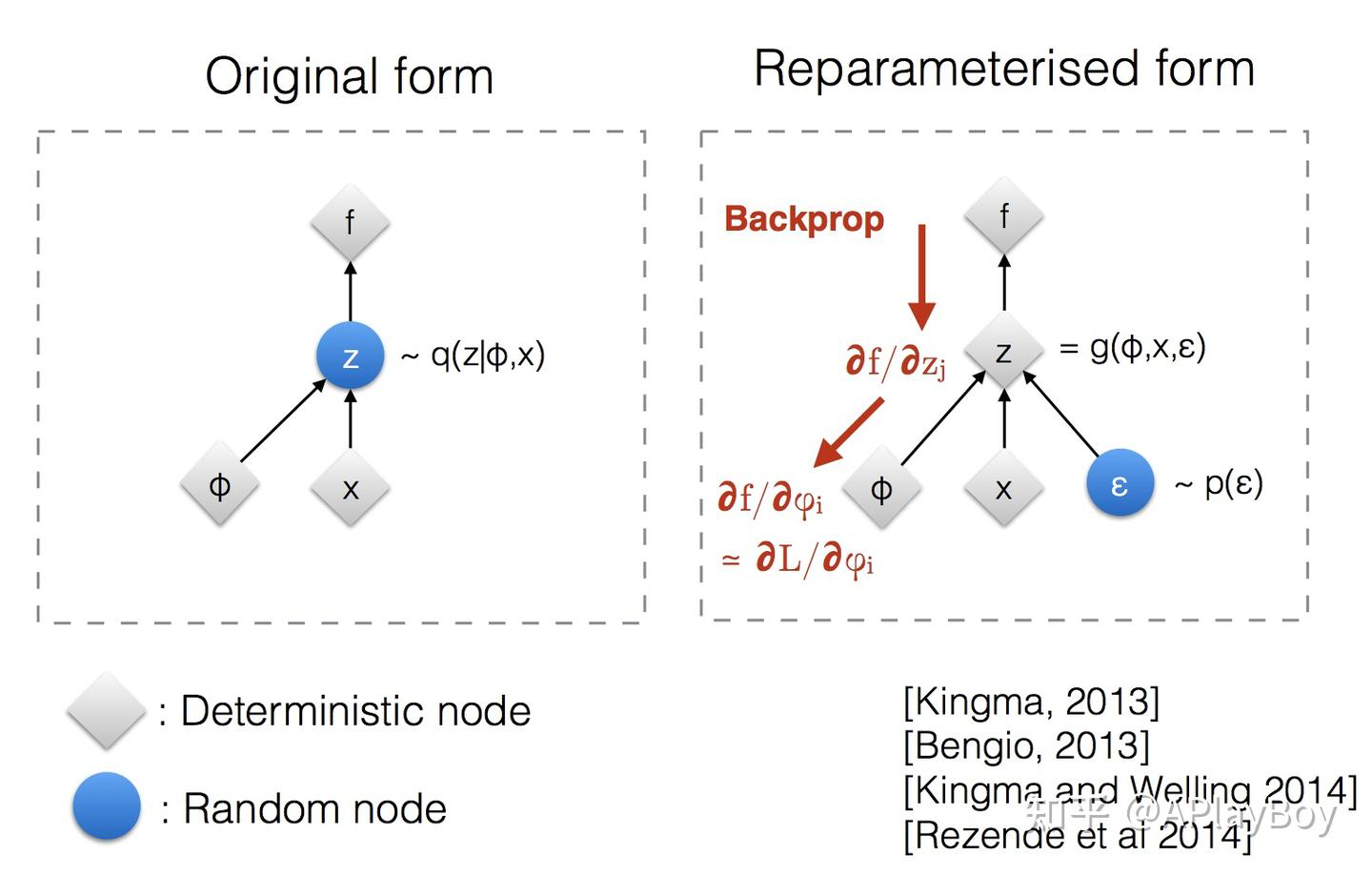
EncoderNetworkϕ的作用就是估计z的均值和方差:
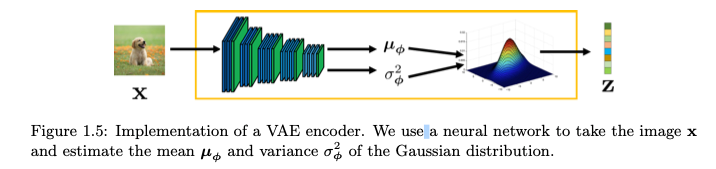
和使用自编码用于图像压缩不同,VAE在训练完成后只使用decoder的部分,这样只要给了隐变量z,就可以生成图像:
GAN生成的质量好,但是和数据的关联度不大,VAE正好相反,可以和GAN可以互补。在stable diffusion中,VAE 可以使生成的图像颜色更鲜艳、细节更清晰,改善面部和手部的表现。
VAE也有很多扩展,可以参考https://zhuanlan.zhihu.com/p/682709613
贝叶斯变分(变分贝叶斯,Variational Bayes,VB)是一类用于贝叶斯估计和机器学习领域的近似计算技术,其核心思想是通过引入一个易于处理的近似分布来逼近复杂的后验分布,从而简化计算过程并实现对数据潜在分布的推断。
reference:
1.变分自编码器(VAE)在AIGC中的应用及其技术解析-腾讯云开发者社区-腾讯云
2.https://zhuanlan.zhihu.com/p/26819995884
3.https://www.zhihu.com/question/1891410702348027478/answer/1893822993005802489
4.【教程】深度学习中的自动编码器Autoencoder是什么?-腾讯云开发者社区-腾讯云
5.https://arxiv.org/pdf/2403.18103
6.变分自编码器VAE - 小舟渡河 - 博客园Transformer 学习笔记 | Seq2Seq,Encoder-Decoder,分词器tokenizer,attention,词嵌入-阿里云开发者社区




高级用法:数据统计与分析)

识别数据集:12k+图像,yolo标注)


:基于PyTorch的VGG16-SE网络实战)
![[电商网站-动态渲染商品-尺寸、尺码、颜色图片等];库存缺货状态动态对应。](http://pic.xiahunao.cn/[电商网站-动态渲染商品-尺寸、尺码、颜色图片等];库存缺货状态动态对应。)

)



)


