文章目录
- 一、简介
- 1.1 contiguous PTE
- 1.2 demo
- 二、Linux 内核中的实现
- 2.1 宏定义
- 2.2 __create_pgd_mapping
- 2.2.1 alloc_init_cont_pmd
- init_pmd
- 2.2.2 alloc_init_cont_pte
- init_pte
- 2.3 hugetlbpage
- 2.3.1 find_num_contig
- 2.3.2 num_contig_ptes
- 2.3.3 huge_pte_offset
- 2.3.4 huge_pte_alloc
- 2.3.5 set_huge_pte_at
- 参考资料
一、简介
1.1 contiguous PTE
ARM64支持 contiguous PTE 映射, 可以让 16 个连续的 page 通过 CONT-PTE 只占一个 TLB entry。
在 ARMv8-A 架构中,Contiguous Bit(连续位)是页表项(Page Table Entry, PTE)中的一个硬件标志位,用于指示:当前页表项所映射的物理内存区域,实际上是由多个物理上连续的小页组成的一个大块。
Contiguous Bit 位于 页表项的 bit 52(高位区域,不影响物理地址编码)。
当 contiguous = 1 时,表示该 PTE 实际映射的是 一组连续的页,而不仅仅是单个页。
该特性允许 TLB(Translation Lookaside Buffer)和硬件页表遍历单元 将一组连续的页“视为”一个更大的块,从而:
减少 TLB 条目占用;
提高 TLB 命中率;
降低页表遍历开销。
它节省 TLB,但不节省页表内存(仍然需要多个 PTE 条目)。
备注:
PTE_CONT 仍需多个 PTE 条目,而 block mapping(大页) 仅需一个
允许 MMU 将多个连续的、基础的页表项映射聚合起来,并缓存到单个 TLB 条目中。这相当于在软件层面创建了一个“虚拟”的大页,而无需硬件在页表结构的更高层级(如 PMD)上直接支持该特定尺寸的大页。
一种 “硬件辅助的软件大页” 机制。硬件提供支持,但由操作系统负责识别和标记哪些区域是符合条件的连续区域。
Contiguous Bit 主要出现在以下两种页表项中:
| 页表项 | 是否支持 CONT | 描述 |
|---|---|---|
| PMD | 支持 | 可将 16 个连续的 2MB 页合并为一个 32MB 块(4KB 粒度) |
| PTE | 支持 | 可将 16 个连续的 4KB 页合并为一个 64KB 块 |
对于 4KB 页,16 个连续的 PTE 形成了一个 16 * 4KB = 64KB 的“连续页”。
这个机制也可以应用于更高层次的页表条目(如 PMD)。例如,16 个连续的 2MB 条目(假如它们本身是传统大页或也是由连续 PTE 构成的)可以组合成一个 32MB 的“连续大页”。
Contiguous PTE 映射的实际效果(以 4KB 粒度为例):
| 映射方式 | 映射大小 | 所需 PTE 条目 | TLB 条目 |
|---|---|---|---|
| 普通 PTE | 64KB | 16 个 | 16 个 |
| Contiguous PTE | 64KB | 16 个(首个带 PTE_CONT) | 1 个 |
Contiguous Bit 只在最后一级页表(PTE 或 PMD)中有效,且必须满足物理地址连续、对齐等条件。
如下图所示:
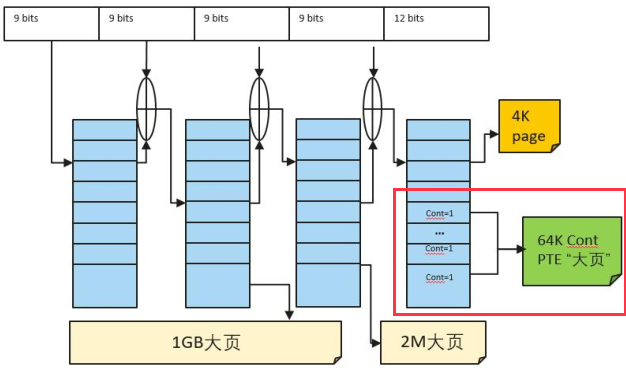
这个机制的本质是在软件层面定义新的、更大的“大页”尺寸,而无需硬件为此提供额外的页表层级。
基础大页(传统方式):硬件定义了 PMD(Page Middle Directory)和 PUD(Page Upper Directory)级别,直接映射像 2MB 或 1GB 这样的大页。这些条目有专门的比特位来标识自己是大页。
连续大页(新方式):在 PTE 级别,硬件本身只支持基础页(如 4KB)。但 Contiguous Bit 允许操作系统将多个连续的 PTE “粘合”在一起,形成一个在硬件看来是更大的、可被一个 TLB 条目缓存的“虚拟大页”。
已4KB为例:
* ---------------------------------------------------* | Page Size | CONT PTE | PMD | CONT PMD | PUD |* ---------------------------------------------------* | 4K | 64K | 2M | 32M | 1G |* ---------------------------------------------------
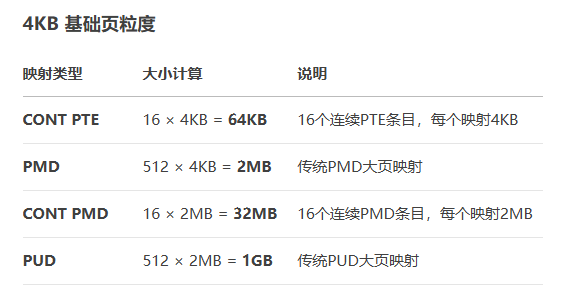
大页如下图所示:
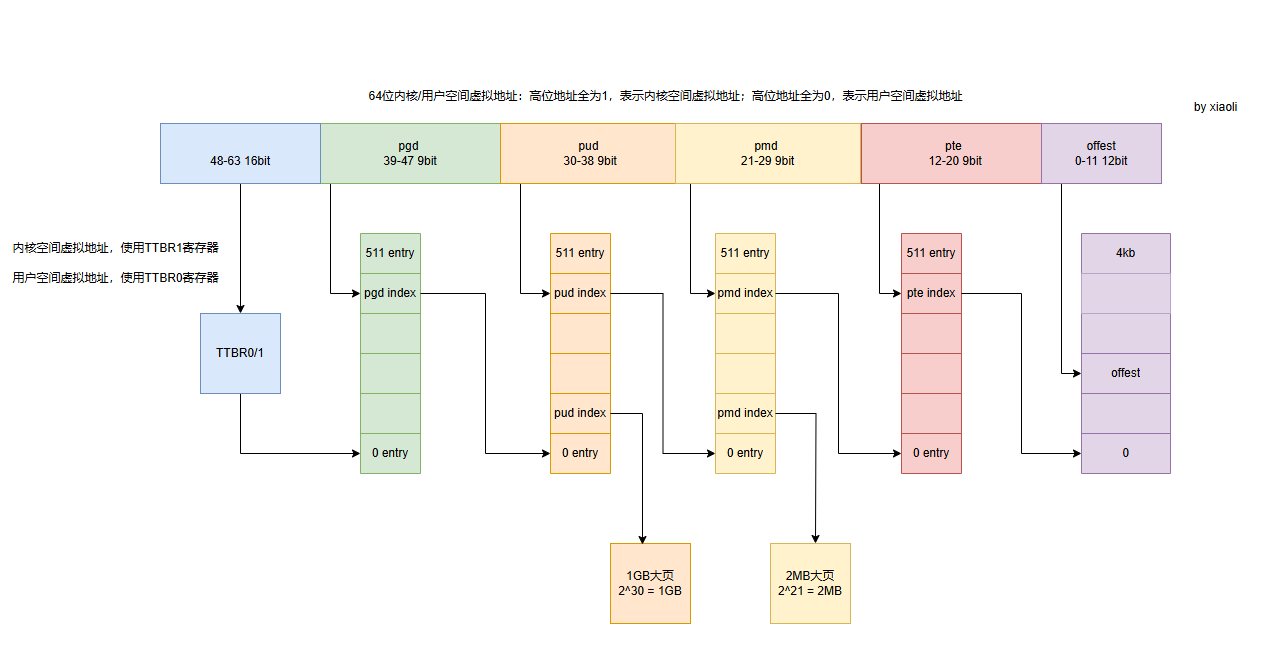
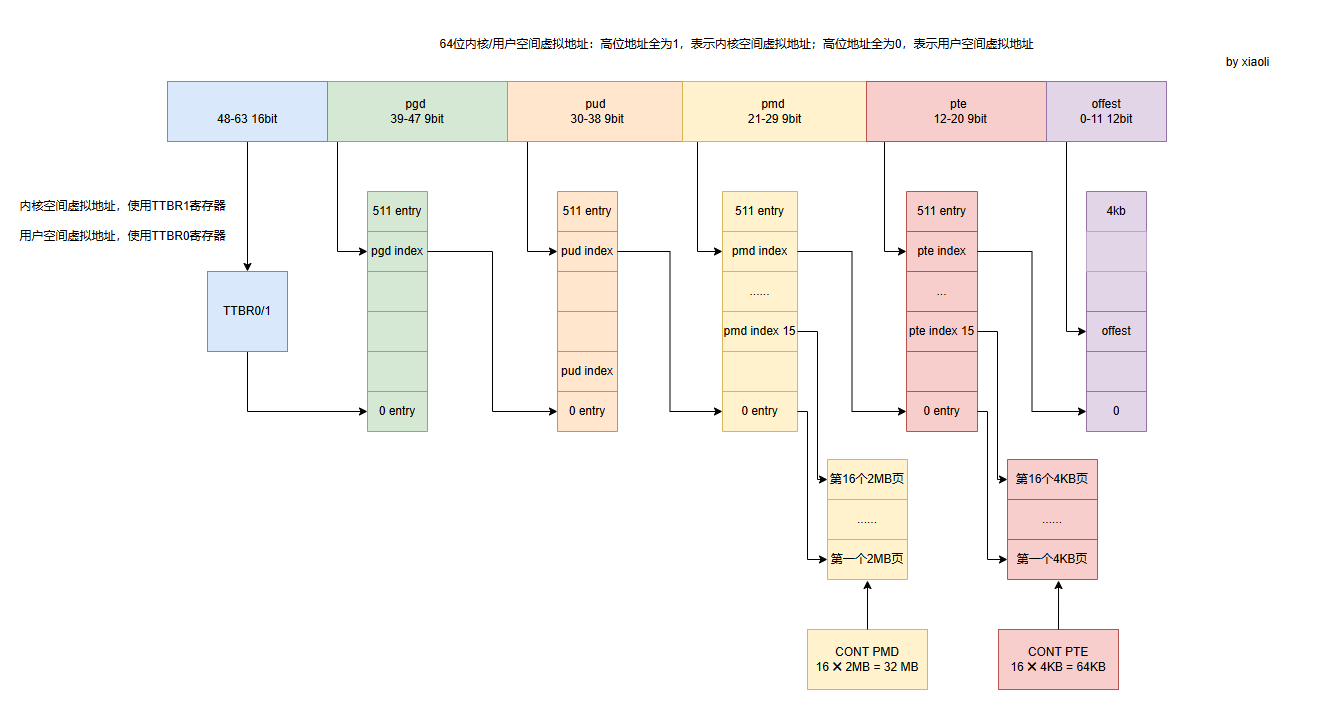
CONT PTE 如下图所示:
1.2 demo
(1)没有 Contiguous Bit
假设基础页大小(Granule Size)为 4KB。要映射一段 64KB 的连续虚拟地址到 64KB 的连续物理内存,需要 16 个 PTE。在默认情况下,这可能会占用 多达 16 个 TLB 条目。
虚拟地址 物理地址 TLB 条目
0x1000 - 0x1fff -> 0xa000 - 0xafff | Entry 1
0x2000 - 0x2fff -> 0xb000 - 0xbfff | Entry 2
... ... | ...
0x4000 - 0x4fff -> 0xd000 - 0xdfff | Entry 16
(2)启用 Contiguous Bit
操作系统检测到这 16 个页(0xa000, 0xb000, …, 0xd000)是物理连续的。它在设置这 16 个 PTE 时,为每一个 PTE 都设置 Contiguous Bit。
MMU 在遍历页表或缓存到 TLB 时,看到连续的 PTE 都具有 Contiguous Bit set,并且满足其他条件(如权限一致),它就可以将整个 16*4KB = 64KB 的映射关系合并到一个 TLB 条目中。
虚拟地址 物理地址 TLB 条目
0x1000 - 0x4fff -> 0xa000 - 0xdfff | One Big Entry| (Covers 64KB)
注意: 每个 PTE 仍然独立存在于页表中,Contiguous Bit 只是一个给 MMU 的提示(Hint),告诉它可以进行聚合缓存。
(3)Contiguous Bit 的工作原理
当 CPU 进行地址转换时:
(1)MMU 遍历页表,找到对应的 PTE。
(2)若检测到 CONT = 1,则:
TLB 存储时:将整个连续区域(如 16 × 4KB)作为一个条目缓存,而非 16 个独立条目。
地址解码时:硬件自动计算偏移量,无需额外查表。
(3)若 CONT = 0,则按普通单页处理
二、Linux 内核中的实现
2.1 宏定义
(1)PTE_CONT
在 ARM64 的页表条目格式中,第 52 位被预留用作 Contiguous Bit。
/** Level 3 descriptor (PTE).*/
#define PTE_VALID (_AT(pteval_t, 1) << 0)
#define PTE_TYPE_MASK (_AT(pteval_t, 3) << 0)
#define PTE_TYPE_PAGE (_AT(pteval_t, 3) << 0)
#define PTE_USER (_AT(pteval_t, 1) << 6) /* AP[1] */
#define PTE_RDONLY (_AT(pteval_t, 1) << 7) /* AP[2] */
#define PTE_SHARED (_AT(pteval_t, 3) << 8) /* SH[1:0], inner shareable */
#define PTE_AF (_AT(pteval_t, 1) << 10) /* Access Flag */
#define PTE_NG (_AT(pteval_t, 1) << 11) /* nG */
#define PTE_GP (_AT(pteval_t, 1) << 50) /* BTI guarded */
#define PTE_DBM (_AT(pteval_t, 1) << 51) /* Dirty Bit Management */
#define PTE_CONT (_AT(pteval_t, 1) << 52) /* Contiguous range */
#define PTE_PXN (_AT(pteval_t, 1) << 53) /* Privileged XN */
#define PTE_UXN (_AT(pteval_t, 1) << 54) /* User XN */
#define PTE_SWBITS_MASK _AT(pteval_t, (BIT(63) | GENMASK(58, 55)))
#define PTE_CONT (_AT(pteval_t, 1) << 52) /* Contiguous range */
(2)CONFIG_ARM64_CONT_PTE/PMD
在 Linux 内核中,这个特性通过 CONFIG_ARM64_CONT_PTE 和 CONFIG_ARM64_CONT_PMD 等配置选项来启用。内核的内存管理子系统会尝试在分配内存时寻找满足连续物理地址对齐要求的内存块,并在设置页表时相应地标记 Contiguous Bit。
// v6.16/source/arch/arm64/Kconfigconfig ARM64_CONT_PTE_SHIFTintdefault 5 if PAGE_SIZE_64KBdefault 7 if PAGE_SIZE_16KBdefault 4config ARM64_CONT_PMD_SHIFTintdefault 5 if PAGE_SIZE_64KBdefault 5 if PAGE_SIZE_16KBdefault 4
ARM64_CONT_PTE: 控制 PTE 级别的连续位使用(例如,16个4KB页 -> 64KB)。
ARM64_CONT_PMD: 控制 PMD 级别的连续位使用(例如,16个2MB页 -> 32MB)。
这些宏定义是 Linux 内核中 ARM64 架构支持 Contiguous PTE 功能的核心配置,它们根据编译时配置和基础页大小来计算连续映射的各种参数。让我们逐行解析:
/** Contiguous page definitions.*//* * PTE 级别的连续映射配置 *//* * CONT_PTE_SHIFT: 连续PTE映射的总位宽偏移量* CONFIG_ARM64_CONT_PTE_SHIFT: 配置的连续PTE数量以2为底的对数(如16个PTE → 4)* PAGE_SHIFT: 基础页大小以2为底的对数(如4KB → 12)* 计算公式:总偏移 = 数量偏移 + 页大小偏移* 例如:4 + 12 = 16 → 64KB*/
#define CONT_PTE_SHIFT (CONFIG_ARM64_CONT_PTE_SHIFT + PAGE_SHIFT)/* * CONT_PTES: 连续PTE的数量* 计算公式:1 << CONFIG_ARM64_CONT_PTE_SHIFT* 例如:1 << 4 = 16个PTE*/
#define CONT_PTES (1 << (CONT_PTE_SHIFT - PAGE_SHIFT))/* * CONT_PTE_SIZE: 连续PTE映射的总大小* 计算公式:PTE数量 × 基础页大小* 例如:16 × 4KB = 64KB*/
#define CONT_PTE_SIZE (CONT_PTES * PAGE_SIZE)/* * CONT_PTE_MASK: 用于地址对齐的掩码* 计算公式:~(CONT_PTE_SIZE - 1)* 例如:~(64KB - 1) = 0xFFFF0000 (64KB对齐掩码)*/
#define CONT_PTE_MASK (~(CONT_PTE_SIZE - 1))/* * PMD 级别的连续映射配置 * 逻辑与PTE级别类似,但基于PMD大小*//* * CONT_PMD_SHIFT: 连续PMD映射的总位宽偏移量* CONFIG_ARM64_CONT_PMD_SHIFT: 配置的连续PMD数量以2为底的对数(如16个PMD → 4)* PMD_SHIFT: PMD大页大小以2为底的对数(如2MB → 21)* 例如:4 + 21 = 25 → 32MB*/
#define CONT_PMD_SHIFT (CONFIG_ARM64_CONT_PMD_SHIFT + PMD_SHIFT)/* * CONT_PMDS: 连续PMD的数量* 计算公式:1 << CONFIG_ARM64_CONT_PMD_SHIFT* 例如:1 << 4 = 16个PMD*/
#define CONT_PMDS (1 << (CONT_PMD_SHIFT - PMD_SHIFT))/* * CONT_PMD_SIZE: 连续PMD映射的总大小* 计算公式:PMD数量 × PMD大页大小* 例如:16 × 2MB = 32MB*/
#define CONT_PMD_SIZE (CONT_PMDS * PMD_SIZE)/* * CONT_PMD_MASK: 用于PMD级别地址对齐的掩码* 计算公式:~(CONT_PMD_SIZE - 1)* 例如:~(32MB - 1) = 0xFE000000 (32MB对齐掩码)*/
#define CONT_PMD_MASK (~(CONT_PMD_SIZE - 1))
配置示例
假设典型配置:
PAGE_SHIFT = 12 (4KB基础页)
PMD_SHIFT = 21 (2MB大页)
CONFIG_ARM64_CONT_PTE_SHIFT = 4 (16个PTE)
CONFIG_ARM64_CONT_PMD_SHIFT = 4 (16个PMD)
计算结果:
PTE级别:
CONT_PTE_SHIFT = 4 + 12 = 16
CONT_PTES = 1 << 4 = 16
CONT_PTE_SIZE = 16 × 4KB = 64KB
CONT_PTE_MASK = 0xFFFF0000
PMD级别:
CONT_PMD_SHIFT = 4 + 21 = 25
CONT_PMDS = 1 << 4 = 16
CONT_PMD_SIZE = 16 × 2MB = 32MB
CONT_PMD_MASK = 0xFE000000
2.2 __create_pgd_mapping
ARM64 内核线性映射中的使用,ARM64架构下Linux 在启动时通过 create_mapping() 建立内核的线性映射。在此过程中,会尝试使用 CONT-PTE。
// v6.16/source/arch/arm64/mm/mmu.c__create_pgd_mapping()-->__create_pgd_mapping_locked()-->alloc_init_p4d()-->alloc_init_pud()-->alloc_init_cont_pmd()
2.2.1 alloc_init_cont_pmd
/*** alloc_init_cont_pmd - 初始化PMD级别页表并可能创建连续映射* @pudp: 指向父级PUD(Page Upper Directory)条目的指针* @addr: 要映射的起始虚拟地址* @end: 要映射的结束虚拟地址(不包括)* @phys: 要映射的起始物理地址* @prot: 页面保护标志(读/写/执行等)* @pgtable_alloc: 分配页表页的函数指针* @flags: 控制标志(如NO_EXEC_MAPPINGS, NO_CONT_MAPPINGS)** 此函数负责在虚拟地址范围[addr, end)和物理地址phys之间建立PMD级别的映射。* 它会检查条件,如果满足(地址对齐且未禁止),就使用PTE_CONT位来创建* 连续的块映射,以提高TLB效率。*/
static void alloc_init_cont_pmd(pud_t *pudp, unsigned long addr,unsigned long end, phys_addr_t phys,pgprot_t prot,phys_addr_t (*pgtable_alloc)(enum pgtable_type),int flags)
{unsigned long next;pud_t pud = READ_ONCE(*pudp);pmd_t *pmdp;/** 检查pgd/pud中是否已经存在初始的段映射。* 如果存在段映射,说明已经有大页映射,不应该继续操作。*/BUG_ON(pud_sect(pud));/* 如果PUD条目为空(未初始化),需要分配并设置一个新的PMD表 */if (pud_none(pud)) {pudval_t pudval = PUD_TYPE_TABLE | PUD_TABLE_UXN | PUD_TABLE_AF;phys_addr_t pmd_phys;/* 如果需要禁止执行映射,设置PXN位 */if (flags & NO_EXEC_MAPPINGS)pudval |= PUD_TABLE_PXN;/* 确保分配函数存在 */ BUG_ON(!pgtable_alloc);/* 分配一个PMD页表页 */ pmd_phys = pgtable_alloc(TABLE_PMD);/* 将PMD表临时映射到内核地址空间以便操作 */pmdp = pmd_set_fixmap(pmd_phys);/* 清空新分配的PMD表(将所有条目初始化为0) */init_clear_pgtable(pmdp);/* 移动指针到当前addr对应的PMD条目位置 */pmdp += pmd_index(addr);/* 将PMD表的物理地址和属性填入PUD条目 */__pud_populate(pudp, pmd_phys, pudval);} else {/* 如果PUD已存在,检查其有效性 */BUG_ON(pud_bad(pud));/* 直接映射已存在的PMD表中对应addr的条目 */pmdp = pmd_set_fixmap_offset(pudp, addr);}/* 循环处理整个地址范围,每次处理一个可能的连续块 */do {pgprot_t __prot = prot; /* 使用传入的保护标志作为默认值 *//* 计算当前连续块的结束地址:取addr+CONT_PMD_SIZE和end的最小值 */next = pmd_cont_addr_end(addr, end);/* * 使用连续映射的条件检查:* 1. 虚拟地址(addr, next)、物理地址(phys)都按CONT_PMD_SIZE对齐* 2. 没有明确禁止使用连续映射(NO_CONT_MAPPINGS标志未设置)*/if ((((addr | next | phys) & ~CONT_PMD_MASK) == 0) &&(flags & NO_CONT_MAPPINGS) == 0)/* 满足条件,在保护标志中添加PTE_CONT位 */__prot = __pgprot(pgprot_val(prot) | PTE_CONT);/* * 初始化PMD条目:根据情况创建块映射、PTE表映射或连续映射* 如果__prot包含PTE_CONT,会设置一系列连续的PMD条目*/init_pmd(pmdp, addr, next, phys, __prot, pgtable_alloc, flags);/* 移动PMD指针到下一个要处理的条目位置 */pmdp += pmd_index(next) - pmd_index(addr);/* 物理地址增加刚刚映射的大小 */phys += next - addr;/* 更新当前地址,如果未到达结束地址则继续循环 */ } while (addr = next, addr != end);/* 清除临时映射 */pmd_clear_fixmap();
}
alloc_init_cont_pmd 函数。这个函数是 Linux 内核中 ARM64 架构内存初始化代码的关键部分,负责创建 PMD (Page Middle Directory) 级别的页表映射,并智能地使用 Contiguous Bit 来创建大块映射。
在给定的虚拟地址范围 [addr, end) 内,为 PUD(Page Upper Directory)条目指向的 PMD 表 初始化一系列页表项(PTE 或 block mapping),并尽可能使用“连续映射”(contiguous mapping),即设置 PTE_CONT 标志位,以减少 TLB 条目消耗。
Contiguous PMD 映射的实际效果(以 4KB 粒度为例):
| 映射方式 | 映射大小 | 所需 PMD 条目 | TLB 条目 |
|---|---|---|---|
| 普通 PMD | 2MB | 16 个 | 16 个 |
| Contiguous PMD | 2MB | 16 个(首个带 PTE_CONT) | 1 个 |
init_pmd
/*** init_pmd - 初始化PMD条目,尝试创建块映射或降级到PTE映射* @pmdp: 指向PMD条目的指针* @addr: 当前处理的起始虚拟地址* @end: 要映射的结束虚拟地址(不包括)* @phys: 要映射的起始物理地址* @prot: 页面保护标志(可能包含PTE_CONT)* @pgtable_alloc: 分配页表页的函数指针* @flags: 控制标志(如NO_BLOCK_MAPPINGS)** 此函数负责初始化一个或多个PMD条目。它首先尝试创建PMD级别的块映射(2MB/512MB),* 如果无法创建块映射,则降级到PTE级别的映射(可能使用连续PTE)。*/
static void init_pmd(pmd_t *pmdp, unsigned long addr, unsigned long end,phys_addr_t phys, pgprot_t prot,phys_addr_t (*pgtable_alloc)(enum pgtable_type), int flags)
{unsigned long next;/* 循环处理当前PMD条目负责的地址范围 */do {/* 读取PMD条目的当前值,用于后续的安全检查 */pmd_t old_pmd = READ_ONCE(*pmdp);/* 计算当前PMD条目管辖范围内的结束地址(通常是addr + PMD_SIZE) */next = pmd_addr_end(addr, end);/* * 首先尝试段映射(块映射)的条件检查:* 1. 虚拟地址(addr, next)、物理地址(phys)都按PMD_SIZE对齐(如2MB边界)* 2. 没有明确禁止使用块映射(NO_BLOCK_MAPPINGS标志未设置)*/if (((addr | next | phys) & ~PMD_MASK) == 0 &&(flags & NO_BLOCK_MAPPINGS) == 0) {/* 创建PMD级别的块映射(大页映射) */pmd_set_huge(pmdp, phys, prot);/** 安全检查:PMD条目一旦被设置,后续只能更新权限属性,不能改变映射类型。* 确保旧的PMD值和新的PMD值在允许的变更范围内(主要是权限位的变化)。*/BUG_ON(!pgattr_change_is_safe(pmd_val(old_pmd),READ_ONCE(pmd_val(*pmdp))));} else {/* * 无法创建块映射,降级到PTE级别的映射:* 1. 地址未对齐,无法使用大页* 2. 或者明确禁止了块映射* 调用alloc_init_cont_pte来初始化PTE表,该函数可能会使用PTE_CONT连续位*/alloc_init_cont_pte(pmdp, addr, next, phys, prot,pgtable_alloc, flags);/* * 安全检查:确保PMD条目的变化是预期的* - 如果旧值是0(空),现在应该被填充为指向PTE表的指针* - 如果旧值非空,新值应该与旧值相同(说明已经初始化过了)*/BUG_ON(pmd_val(old_pmd) != 0 &&pmd_val(old_pmd) != READ_ONCE(pmd_val(*pmdp)));}/* 物理地址增加刚刚处理的范围大小 */phys += next - addr;/* * 更新循环变量:* - pmdp++: 移动到下一个PMD条目* - addr = next: 更新当前地址到下一个块的起始* - 如果未到达结束地址则继续循环*/} while (pmdp++, addr = next, addr != end);
}
init_pmd() 函数是 Linux 内核 ARM64 架构中用于初始化 PMD(Page Middle Directory)页表项的核心函数,它负责在给定的虚拟地址范围内,为二级页表(PMD)建立合适的映射。
该函数体现了 ARM64 内存管理中 “优先使用大块映射(block mapping)” 的设计哲学,并与 alloc_init_cont_pmd() 和 alloc_init_cont_pte() 协同工作,实现从 大页(section)→ 连续 PTE → 普通 PTE 的多层次、高效内存映射策略。
2.2.2 alloc_init_cont_pte
/*** alloc_init_cont_pte - 初始化PTE级别页表并可能创建连续PTE映射* @pmdp: 指向父级PMD(Page Middle Directory)条目的指针* @addr: 要映射的起始虚拟地址* @end: 要映射的结束虚拟地址(不包括)* @phys: 要映射的起始物理地址* @prot: 页面保护标志(可能包含PTE_CONT)* @pgtable_alloc: 分配页表页的函数指针* @flags: 控制标志(如NO_EXEC_MAPPINGS, NO_CONT_MAPPINGS)** 此函数负责在虚拟地址范围[addr, end)和物理地址phys之间建立PTE级别的映射。* 它是init_pmd的降级路径,当无法创建PMD块映射时调用。它会检查条件,如果满足* (地址对齐且未禁止),就使用PTE_CONT位来创建连续的PTE映射,以提高TLB效率。*/
static void alloc_init_cont_pte(pmd_t *pmdp, unsigned long addr,unsigned long end, phys_addr_t phys,pgprot_t prot,phys_addr_t (*pgtable_alloc)(enum pgtable_type),int flags)
{unsigned long next;pmd_t pmd = READ_ONCE(*pmdp);pte_t *ptep;/* 检查PMD条目中是否已经存在段映射(不应该存在) */BUG_ON(pmd_sect(pmd));/* 如果PMD条目为空(未初始化),需要分配并设置一个新的PTE表 */if (pmd_none(pmd)) {pmdval_t pmdval = PMD_TYPE_TABLE | PMD_TABLE_UXN | PMD_TABLE_AF;phys_addr_t pte_phys;/* 如果需要禁止执行映射,设置PXN位 */if (flags & NO_EXEC_MAPPINGS)pmdval |= PMD_TABLE_PXN;/* 确保分配函数存在 */BUG_ON(!pgtable_alloc);/* 分配一个PTE页表页 */pte_phys = pgtable_alloc(TABLE_PTE);/* 将PTE表临时映射到内核地址空间以便操作 */ptep = pte_set_fixmap(pte_phys);/* 清空新分配的PTE表(将所有条目初始化为0) */init_clear_pgtable(ptep);/* 移动指针到当前addr对应的PTE条目位置 */ptep += pte_index(addr);/* 将PTE表的物理地址和属性填入PMD条目 */__pmd_populate(pmdp, pte_phys, pmdval);} else {/* 如果PMD已存在,检查其有效性 */BUG_ON(pmd_bad(pmd));/* 直接映射已存在的PTE表中对应addr的条目 */ptep = pte_set_fixmap_offset(pmdp, addr);}/* 循环处理整个地址范围,每次处理一个可能的连续PTE块 */do {pgprot_t __prot = prot; /* 使用传入的保护标志作为默认值 *//* 计算当前连续PTE块的结束地址:取addr+CONT_PTE_SIZE和end的最小值 */next = pte_cont_addr_end(addr, end);/* * 使用连续PTE映射的条件检查:* 1. 虚拟地址(addr, next)、物理地址(phys)都按CONT_PTE_SIZE对齐(如64KB边界)* 2. 没有明确禁止使用连续映射(NO_CONT_MAPPINGS标志未设置)*/if ((((addr | next | phys) & ~CONT_PTE_MASK) == 0) &&(flags & NO_CONT_MAPPINGS) == 0)/* 满足条件,在保护标志中添加PTE_CONT位 */__prot = __pgprot(pgprot_val(prot) | PTE_CONT);/* * 初始化PTE条目:设置单个PTE或一系列连续的PTE* 如果__prot包含PTE_CONT,会设置多个连续的PTE条目并标记CONT位*/init_pte(ptep, addr, next, phys, __prot);/* 移动PTE指针到下一个要处理的条目位置 */ptep += pte_index(next) - pte_index(addr);/* 物理地址增加刚刚映射的大小 */phys += next - addr;/* 更新当前地址,如果未到达结束地址则继续循环 */} while (addr = next, addr != end);/** 注意:屏障和维护操作对于清除临时映射槽是必要的,* 这确保了所有之前的页表写入对表遍历器(MMU)都是可见的。*/pte_clear_fixmap();
}
alloc_init_cont_pte() 函数在虚拟地址范围 [addr, end) 内,为 PMD 条目指向的 PTE 表 初始化一系列页表项(PTE),并尽可能使用“连续映射”(contiguous mapping),即设置 PTE_CONT 标志位,以减少 TLB 条目消耗。
alloc_init_cont_pte() 函数是 Linux 内核 ARM64 架构中用于初始化 PTE(Page Table Entry)层级映射的关键函数,它在无法使用更高级别的大页映射(如 PMD block 或 contiguous PMD)时,退化到 PTE 层级,并尽可能使用“连续映射”(contiguous mapping) 来优化 TLB 性能。
该函数与 alloc_init_cont_pmd() 和 init_pmd() 构成 ARM64 内存初始化的完整链条,体现了内核“尽可能使用大块映射 → 否则使用连续小页 → 最后才是普通小页”的映射优先级策略。
Contiguous PTE 映射的实际效果(以 4KB 粒度为例):
| 映射方式 | 映射大小 | 所需 PMD 条目 | TLB 条目 |
|---|---|---|---|
| 普通 PTE | 4KB | 16 个 | 16 个 |
| Contiguous PTE | 4KB | 16 个(首个带 PTE_CONT) | 1 个 |
init_pte
/*** init_pte - 初始化一个或多个PTE条目* @ptep: 指向PTE条目的指针* @addr: 要映射的起始虚拟地址* @end: 要映射的结束虚拟地址(不包括)* @phys: 要映射的起始物理地址* @prot: 页面保护标志(可能包含PTE_CONT)** 此函数负责设置一个或多个连续的PTE条目。它是页表初始化的最底层函数,* 实际将物理页帧映射到虚拟地址。如果prot中包含PTE_CONT标志,则会设置* 一系列连续的PTE,硬件可以将它们聚合缓存。*/
static void init_pte(pte_t *ptep, unsigned long addr, unsigned long end,phys_addr_t phys, pgprot_t prot)
{/* 循环处理地址范围,每次处理一个PAGE_SIZE大小的页面 */do {/* 读取PTE条目的当前值,用于后续的安全检查 */pte_t old_pte = __ptep_get(ptep);/** 设置PTE条目:将物理地址和保护标志组合成PTE值并写入* __phys_to_pfn(phys): 将物理地址转换为页帧号(PFN)* pfn_pte(): 将PFN和保护标志组合成PTE值* __set_pte_nosync(): 异步设置PTE,不包含内存屏障* * 注意:使此次写入对表遍历器(MMU)可见所需的内存屏障* 被延迟到alloc_init_cont_pte()函数的末尾执行。*/__set_pte_nosync(ptep, pfn_pte(__phys_to_pfn(phys), prot));/** 安全检查:PTE条目一旦被设置,后续只能更新权限属性,不能改变映射类型。* 确保旧的PTE值和新的PTE值在允许的变更范围内(主要是权限位的变化)。* 这是防止意外覆盖有效映射的重要保护机制。*/BUG_ON(!pgattr_change_is_safe(pte_val(old_pte),pte_val(__ptep_get(ptep))));/* 物理地址增加一个页面大小 */phys += PAGE_SIZE;/* * 更新循环变量:* - ptep++: 移动到下一个PTE条目* - addr += PAGE_SIZE: 更新虚拟地址到下一个页面* - 如果未到达结束地址则继续循环*/} while (ptep++, addr += PAGE_SIZE, addr != end);
}
init_pte() 函数是 Linux 内核 ARM64 架构中用于初始化 PTE(Page Table Entry)页表项的底层核心函数,它负责在给定的虚拟地址范围内,为每个 PTE 条目设置物理页帧映射。
该函数是整个 ARM64 内存映射初始化链条的最末端,承接 alloc_init_cont_pte() 的调用,完成最终的页表填充工作。
在虚拟地址范围 [addr, end) 内,从 ptep 开始,逐个设置 PTE 条目,将虚拟页映射到物理页,支持:
普通 PTE 映射;
或者(在上层已设置 PTE_CONT 时)作为连续映射的一部分。
2.3 hugetlbpage
请参考 :https://elixir.bootlin.com/linux/v6.16/source/arch/arm64/mm/mmu.c
首先需要明确:标准的 HugeTLB Pages(如 2MB, 1GB)和 CONT-PTE 映射是两种不同的机制,但它们可以协同工作。
(1)标准 HugeTLB:使用更高层级的页表条目(如 PMD 或 PUD)。一个 PMD 条目直接映射一个 2MB 的大页。这是最节省 TLB 和页表内存的方式。
(2)CONT-PTE:仍然使用 PTE 级别的条目,但通过硬件提示将它们聚合。它节省 TLB,但不节省页表内存(仍然需要多个 PTE 条目)。
/** HugeTLB Support Matrix** ---------------------------------------------------* | Page Size | CONT PTE | PMD | CONT PMD | PUD |* ---------------------------------------------------* | 4K | 64K | 2M | 32M | 1G |* | 16K | 2M | 32M | 1G | |* | 64K | 2M | 512M | 16G | |* ---------------------------------------------------*/
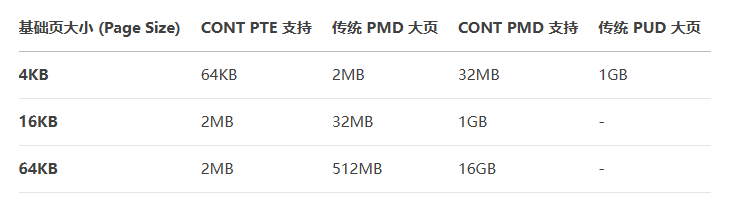
ARM64支持3种页面大小:4KB, 16KB, 64KB。
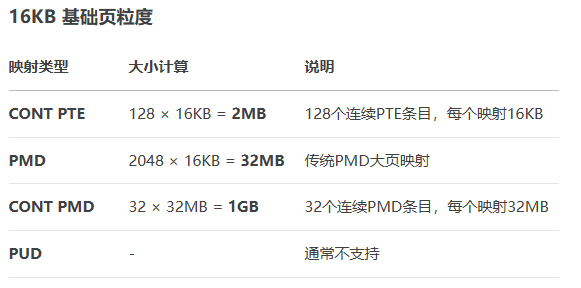
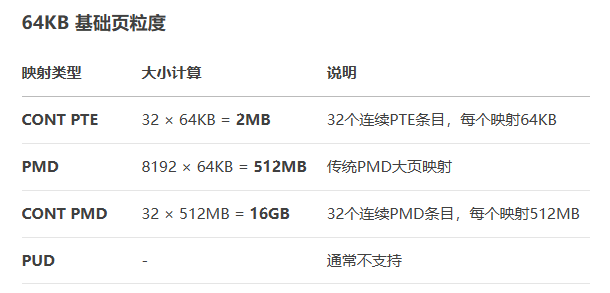
已4KB为例:
* ---------------------------------------------------* | Page Size | CONT PTE | PMD | CONT PMD | PUD |* ---------------------------------------------------* | 4K | 64K | 2M | 32M | 1G |* ---------------------------------------------------
相关函数:
2.3.1 find_num_contig
/*** find_num_contig - 根据页表条目指针确定连续映射的数量和大小* @mm: 目标进程的内存管理结构体* @addr: 要检查的虚拟地址(用于遍历页表)* @ptep: 要检查的页表条目指针* @pgsize: 输出参数,返回每个连续块的大小** 返回值: CONT_PMDS(如果是PMD级别的连续映射)或 CONT_PTES(如果是PTE级别的连续映射)** 此函数通过检查页表条目指针所在的层级,来判断是PMD级别的连续映射还是PTE级别的连续映射,* 并相应设置连续块的大小和数量。*/
static int find_num_contig(struct mm_struct *mm, unsigned long addr,pte_t *ptep, size_t *pgsize)
{pgd_t *pgdp = pgd_offset(mm, addr);p4d_t *p4dp;pud_t *pudp;pmd_t *pmdp;/* 默认设置为PTE级别的大小(基础页大小) */*pgsize = PAGE_SIZE;/* 遍历页表层次结构,获取PMD指针 */p4dp = p4d_offset(pgdp, addr);pudp = pud_offset(p4dp, addr);pmdp = pmd_offset(pudp, addr);/* * 关键检查:如果传入的ptep指针实际上指向的是PMD条目* 这意味着我们处理的是PMD级别的连续映射(如32MB)*/if ((pte_t *)pmdp == ptep) {*pgsize = PMD_SIZE; // 设置块大小为PMD大小(2MB)return CONT_PMDS; // 返回PMD级别的连续映射标识}/* 否则,处理的是PTE级别的连续映射(如64KB) */return CONT_PTES; // 返回PTE级别的连续映射标识
}
find_num_contig() 函数是 Linux ARM64 架构中用于判断一个页表项(PTE)是否属于“连续映射”(contiguous mapping)并返回其连续条目数量的核心辅助函数。
(1)目的:此函数用于确定一个页表条目指针 ptep 所处的层级,从而判断是哪种类型的连续映射。
(2)页表遍历:函数通过 pgd_offset() → p4d_offset() → pud_offset() → pmd_offset() 的标准路径,找到给定地址 addr 对应的 PMD 指针。
(3)关键比较:if ((pte_t )pmdp == ptep)
这里将 pmdp(PMD 条目的指针)强制转换为 pte_t 类型,然后与传入的 ptep 进行比较。
如果相等:说明调用者传入的 ptep 实际上指向的是一个 PMD 条目。这意味着要处理的是 PMD 级别的连续映射(例如 32MB 的 CONT-PMD 映射)。
如果不相等:说明 ptep 指向的是真正的 PTE 条目,要处理的是 PTE 级别的连续映射(例如 64KB 的 CONT-PTE 映射)。
(4)输出参数设置:
对于 PMD 级别:*pgsize = PMD_SIZE(通常是 2MB)
对于 PTE 级别:*pgsize = PAGE_SIZE(通常是 4KB),但实际使用时,连续块的总大小是 CONT_PTES * PAGE_SIZE(如 16 * 4KB = 64KB)
(5)返回值:
CONT_PMDS:表示是 PMD 级别的连续映射,通常对应 16 个连续的 PMD 条目(组成 32MB)
CONT_PTES:表示是 PTE 级别的连续映射,通常对应 16 个连续的 PTE 条目(组成 64KB)
2.3.2 num_contig_ptes
/*** num_contig_ptes - 根据大页尺寸计算连续页表条目数量和每个条目的大小* @size: 输入的大页尺寸(如PUD_SIZE, PMD_SIZE, CONT_PMD_SIZE, CONT_PTE_SIZE)* @pgsize: 输出参数,返回每个连续页表条目所代表的实际映射大小** 返回值: 需要设置的连续页表条目数量(CONT_PMDS或CONT_PTES)* 对于非连续映射的大页,返回1** 此函数将抽象的大页尺寸转换为具体的页表操作参数,是连接HUGETLB子系统* 和CONT-PTE机制的关键桥梁。*/
static inline int num_contig_ptes(unsigned long size, size_t *pgsize)
{int contig_ptes = 1; // 默认值:单个页表条目*pgsize = size; // 默认输出大小就是输入大小/* 根据输入的大页尺寸进行分派处理 */switch (size) {case CONT_PMD_SIZE:/* * 处理CONT_PMD_SIZE(如32MB):* - 每个PMD条目映射PMD_SIZE(2MB)* - 需要CONT_PMDS(16)个连续的PMD条目*/*pgsize = PMD_SIZE;contig_ptes = CONT_PMDS;break;case CONT_PTE_SIZE:/* * 处理CONT_PTE_SIZE(如64KB):* - 每个PTE条目映射PAGE_SIZE(4KB) * - 需要CONT_PTES(16)个连续的PTE条目*/*pgsize = PAGE_SIZE;contig_ptes = CONT_PTES;break;default:/* * 处理传统大页尺寸(PUD_SIZE, PMD_SIZE)或其他有效尺寸:* 保持默认值 contig_ptes = 1, *pgsize = size* 同时验证尺寸是否是大页的有效尺寸*/WARN_ON(!__hugetlb_valid_size(size));}return contig_ptes;
}
num_contig_ptes() 函数是 Linux ARM64 架构中用于将大页或连续映射的“总尺寸”(size)转换为“连续 PTE 条目数量”(ncontig)和“单个条目粒度”(pgsize)的核心内联函数。
三种处理情况:
(1)CONT_PMD_SIZE (如32MB):
→ 输出:*pgsize = PMD_SIZE (2MB), return CONT_PMDS (16)
含义:需要16个连续的PMD条目,每个映射2MB
(2)CONT_PTE_SIZE (如64KB):
→ 输出:*pgsize = PAGE_SIZE (4KB), return CONT_PTES (16)
含义:需要16个连续的PTE条目,每个映射4KB
(3)传统大页(PUD_SIZE, PMD_SIZE):
→ 输出:*pgsize = size, return 1
含义:只需要1个页表条目(PUD或PMD)
使用示例:
size_t pgsize;
int ncontig;// 示例1:处理64KB CONT-PTE大页
ncontig = num_contig_ptes(CONT_PTE_SIZE, &pgsize);
// 结果:ncontig = 16, pgsize = 4096 (4KB)// 示例2:处理32MB CONT-PMD大页
ncontig = num_contig_ptes(CONT_PMD_SIZE, &pgsize);
// 结果:ncontig = 16, pgsize = 2097152 (2MB)// 示例3:处理传统2MB大页
ncontig = num_contig_ptes(PMD_SIZE, &pgsize);
// 结果:ncontig = 1, pgsize = 2097152 (2MB)
2.3.3 huge_pte_offset
/*** huge_pte_offset - 根据虚拟地址和大小,查找对应的大页页表条目指针* @mm: 目标进程的内存管理结构体* @addr: 要查找的虚拟地址* @sz: 期望的大页大小(如PUD_SIZE, PMD_SIZE, CONT_PMD_SIZE, CONT_PTE_SIZE)** 此函数遍历页表层次结构,根据地址和指定的大小找到对应级别的页表条目。* 它支持传统大页和CONT-PTE连续位大页。返回值是指向相应级别页表条目的指针* (可能转换为pte_t*),如果找不到则返回NULL。*/
pte_t *huge_pte_offset(struct mm_struct *mm,unsigned long addr, unsigned long sz)
{pgd_t *pgdp;p4d_t *p4dp;pud_t *pudp, pud;pmd_t *pmdp, pmd;/* 1. 从PGD开始遍历,获取addr对应的PGD条目 */pgdp = pgd_offset(mm, addr);if (!pgd_present(READ_ONCE(*pgdp)))return NULL;/* 2. 获取P4D条目(在ARM64中通常只是包装层) */p4dp = p4d_offset(pgdp, addr);if (!p4d_present(READ_ONCE(*p4dp)))return NULL;/* 3. 获取PUD条目并检查 */pudp = pud_offset(p4dp, addr);pud = READ_ONCE(*pudp);/* 如果期望的不是PUD_SIZE大小的大页且PUD为空,返回NULL */if (sz != PUD_SIZE && pud_none(pud))return NULL;/* 检查PUD级别是否是大页映射或交换条目 */if (pud_leaf(pud) || !pud_present(pud))return (pte_t *)pudp; // 返回PUD指针(转换为pte_t*)/* 4. 如果PUD是表项(指向下一级),继续检查PMD级别 *//* 对于CONT_PMD_SIZE(如32MB)映射,需要对地址进行掩码对齐 */if (sz == CONT_PMD_SIZE)addr &= CONT_PMD_MASK;/* 获取PMD条目 */pmdp = pmd_offset(pudp, addr);pmd = READ_ONCE(*pmdp);/* 如果期望的不是PMD_SIZE或CONT_PMD_SIZE且PMD为空,返回NULL */if (!(sz == PMD_SIZE || sz == CONT_PMD_SIZE) &&pmd_none(pmd))return NULL;/* 检查PMD级别是否是大页映射或交换条目 */if (pmd_leaf(pmd) || !pmd_present(pmd))return (pte_t *)pmdp; // 返回PMD指针(转换为pte_t*)/* 5. 处理CONT_PTE_SIZE(如64KB)的特殊情况 */if (sz == CONT_PTE_SIZE)/* 对地址进行CONT_PTE对齐,然后获取PTE条目 */return pte_offset_huge(pmdp, (addr & CONT_PTE_MASK));/* 6. 如果以上都不匹配,返回NULL */return NULL;
}
huge_pte_offset() 函数是 Linux ARM64 架构中用于在进程地址空间(mm_struct)中查找大页(hugetlbpage)对应 PTE 指针的核心函数。它不仅处理标准的大页映射(如 2MB/1GB block mapping),还特别支持基于 PTE_CONT 的“连续映射”(contiguous mapping)。
2.3.4 huge_pte_alloc
/*** huge_pte_alloc - 为大页映射分配并初始化页表条目* @mm: 目标进程的内存管理结构体* @vma: 相关的虚拟内存区域* @addr: 要映射的虚拟地址* @sz: 期望的大页大小(PUD_SIZE, PMD_SIZE, CONT_PMD_SIZE, CONT_PTE_SIZE)** 此函数负责为大页映射分配所需的各级页表条目。它会根据请求的大页尺寸,* 遍历页表层次结构,必要时分配中间页表页,并返回指向最终级别页表条目的指针。* 这是huge_pte_offset的"分配"版本,用于建立新映射。*/
pte_t *huge_pte_alloc(struct mm_struct *mm, struct vm_area_struct *vma,unsigned long addr, unsigned long sz)
{pgd_t *pgdp;p4d_t *p4dp;pud_t *pudp;pmd_t *pmdp;pte_t *ptep = NULL; // 返回值,指向最终级别的页表条目/* 1. 获取PGD条目,这是所有地址转换的起点 */pgdp = pgd_offset(mm, addr);/* 2. 分配或获取P4D条目(在ARM64中通常只是包装层) */p4dp = p4d_alloc(mm, pgdp, addr);if (!p4dp)return NULL;/* 3. 分配或获取PUD条目 */pudp = pud_alloc(mm, p4dp, addr);if (!pudp)return NULL;/* 4. 根据请求的大页尺寸进行分派处理 */if (sz == PUD_SIZE) {/* 处理1GB大页:直接在PUD级别创建映射,返回PUD指针 */ptep = (pte_t *)pudp;} else if (sz == (CONT_PTE_SIZE)) {/* 处理CONT_PTE_SIZE大页(如64KB):需要PTE级别的连续映射 */pmdp = pmd_alloc(mm, pudp, addr);if (!pmdp)return NULL;/* 确保地址按CONT_PTE_SIZE对齐(硬件要求) */WARN_ON(addr & (sz - 1));/* 分配PTE表并返回PTE条目指针 */ptep = pte_alloc_huge(mm, pmdp, addr);} else if (sz == PMD_SIZE) {/* 处理2MB大页:在PMD级别创建映射 */if (want_pmd_share(vma, addr) && pud_none(READ_ONCE(*pudp)))/* 如果允许且适合共享PMD,使用共享映射 */ptep = huge_pmd_share(mm, vma, addr, pudp);else/* 否则分配专用的PMD条目 */ptep = (pte_t *)pmd_alloc(mm, pudp, addr);} else if (sz == (CONT_PMD_SIZE)) {/* 处理CONT_PMD_SIZE大页(如32MB):需要PMD级别的连续映射 */pmdp = pmd_alloc(mm, pudp, addr);/* 确保地址按CONT_PMD_SIZE对齐(硬件要求) */WARN_ON(addr & (sz - 1));/* 返回PMD指针,后续操作会设置CONT_PTE位 */return (pte_t *)pmdp;}return ptep;
}
huge_pte_alloc() 函数是 Linux ARM64 架构中用于为大页(hugetlbpage)或连续映射分配页表项的核心函数。该函数不仅支持标准的大页(如 2MB PMD、1GB PUD),还特别支持基于硬件特性的 连续映射(contiguous mapping),如 CONT_PTE_SIZE 和 CONT_PMD_SIZE。
PUD_SIZE (1GB):最简单的情况,直接使用 PUD 条目作为大页映射。
PMD_SIZE (2MB):处理传统 2MB 大页。包含优化路径:检查是否可以使用 huge_pmd_share 进行映射共享,减少页表占用。
CONT_PMD_SIZE (32MB = 16 ✖ 2MB):处理 16个PMD 级别的连续映射。分配 PMD 条目后直接返回,后续由调用者设置 CONT_PTE 位。
CONT_PTE_SIZE (64KB = 16 ✖ 4KB):处理 16个PTE 级别的连续映射。需要分配 PMD 和 PTE 表,是最复杂的情况。
支持的映射类型总结:
已4KB为例:
* ---------------------------------------------------* | Page Size | CONT PTE | PMD | CONT PMD | PUD |* ---------------------------------------------------* | 4K | 64K | 2M | 32M | 1G |* ---------------------------------------------------
2.3.5 set_huge_pte_at
/*** set_huge_pte_at - 设置一个大页的页表条目(支持CONT-PTE连续映射)* @mm: 目标进程的内存管理结构体* @addr: 要映射的起始虚拟地址* @ptep: 指向页表条目的指针(可能是PTE、PMD或PUD级别)* @pte: 要设置的新页表条目值* @sz: 大页的大小(PUD_SIZE, PMD_SIZE, CONT_PMD_SIZE, CONT_PTE_SIZE)** 此函数负责设置大页映射的页表条目,处理包括CONT-PTE连续映射在内的各种情况。* 它会智能地处理单个条目或连续条目块的操作,确保正确性和性能。*/
void set_huge_pte_at(struct mm_struct *mm, unsigned long addr,pte_t *ptep, pte_t pte, unsigned long sz)
{size_t pgsize; // 实际操作的页面大小int i; // 循环计数器int ncontig; // 需要设置的连续条目数量unsigned long pfn, dpfn; // 页帧号和页帧号增量pgprot_t hugeprot; // 页面保护标志/* 1. 根据大页尺寸计算连续条目数量和每个条目代表的大小 */ncontig = num_contig_ptes(sz, &pgsize);/* 2. 情况1:新PTE是"非Present"的(空或交换条目) */if (!pte_present(pte)) {/* 简单循环设置ncontig个空条目 */for (i = 0; i < ncontig; i++, ptep++, addr += pgsize)__set_ptes(mm, addr, ptep, pte, 1);return;}/* 3. 情况2:新PTE是Present的,但不要求连续映射 */if (!pte_cont(pte)) {/* 只设置单个条目(可能是传统大页) */__set_ptes(mm, addr, ptep, pte, 1);return;}/* 4. 情况3:新PTE是Present的且要求连续映射(最复杂的路径) *//* 从PTE中提取页帧号(PFN) */pfn = pte_pfn(pte);/* 计算每个连续块之间的PFN增量(如64KB / 4KB = 16) */dpfn = pgsize >> PAGE_SHIFT;/* 从PTE中提取保护标志 */hugeprot = pte_pgprot(pte);/* * 关键步骤:在设置新映射前,清除并刷新旧映射* 这确保了TLB和缓存的正确性,特别是对于连续映射*/clear_flush(mm, addr, ptep, pgsize, ncontig);/* * 循环设置连续的页表条目:* - i: 循环ncontig次(如16次)* - ptep++: 移动到下一个PTE条目* - addr += pgsize: 虚拟地址增加一个块大小* - pfn += dpfn: 物理页帧号递增dpfn(保持物理连续性)*/for (i = 0; i < ncontig; i++, ptep++, addr += pgsize, pfn += dpfn)/* 为每个连续块创建新的PTE并设置 */__set_ptes(mm, addr, ptep, pfn_pte(pfn, hugeprot), 1);
}
set_huge_pte_at() 函数是 Linux ARM64 架构中用于设置大页(hugetlbpage)或连续映射(contiguous mapping)页表项的核心函数。它在 hugetlb_fault 或 THP(透明大页)缺页处理中被调用,负责将一个构造好的 PTE 条目安全地写入页表。
参考资料
Linux 6.16
与标准的 jsonrpc的区别)



)
![【题解】洛谷P1776 宝物筛选 [单调队列优化多重背包]](http://pic.xiahunao.cn/【题解】洛谷P1776 宝物筛选 [单调队列优化多重背包])
)





---初始轨迹生成后的关键点采样)
)

及与Kafka实现的对比分析)
)


