1. 概念
对链表而言,双向均可遍历是最方便的,另外首尾相连循环遍历也可大大增加链表操作的便捷性。因此,双向循环链表,是在实际运用中是最常见的链表形态。

2. 基本操作
与普通的链表完全一致,双向循环链表虽然指针较多,但逻辑是完全一样。基本的操作包括:
- 节点设计
- 初始化空链表
- 增删节点
- 链表遍历
- 销毁链表
3. 节点设计
双向链表的节点只是比单向链表多了一个前向指针。示例代码如下所示:
typedef struct node
{// 以整型数据为例int data; // 指向相邻的节点的双向指针struct node * prev;struct node * next;
}node;
3. 初始化
所谓初始化,就是构建一条不含有效节点的空链表。
以带头结点的双向循环链表为例,初始化后,其状态如下图所示:
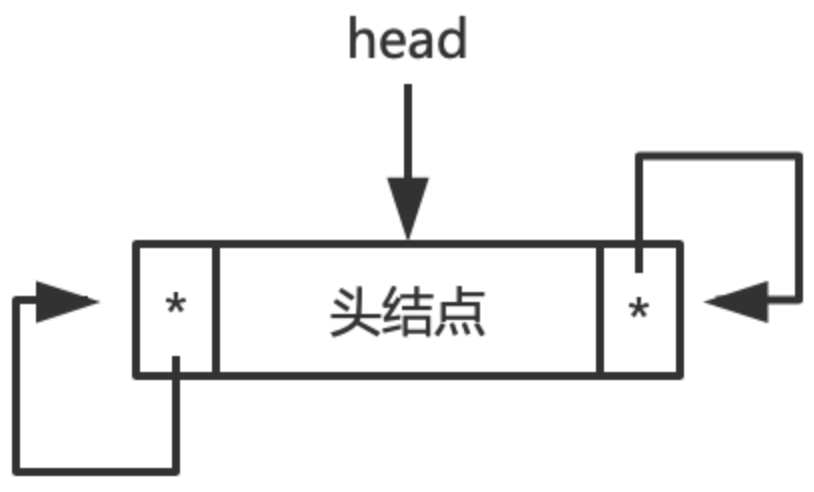
在初始空链表的情况下,链表只有一个头结点,下面是初始化示例代码:
node * initList()
{// 申请头结点node * head = malloc(sizeof(node));// 让首尾互相指向// 不需要对头结点的 data 做任何操作if(head != NULL){head->prev = head;head->next = head;}return head;
}
4. 插入节点
与单链表类似,也可以对双链表中的任意节点进行增删操作,常见的有所谓的头插法、尾插法等,即:将新节点插入到链表的首部或者尾部,示例代码是:
- 头插法:将新节点插入到链表的头部
// 将新节点new,插入到链表的首部
void insertHead(node *head, node

)



—— 神经网络实验)
)



)

:非固定高度的容器实现折叠面板效果)

)



