PostgreSQL与SQL Server:B树索引差异及去重的优势
在优化查询性能方面,索引是数据库工程师可使用的最强大工具之一。PostgreSQL和Microsoft SQL Server(或Azure SQL)都将B树索引用作其默认索引结构,但每个系统实现、维护和使用这些索引的方式存在细微却重要的差异。
在这篇博文中,我们探讨了PostgreSQL和SQL Server的几个关键差异点:它们的B树索引在底层的实现方式,以及它们在磁盘上存储和访问数据的方式。我们还将对每个数据库系统中值的去重对索引大小的影响进行基准测试。
我们在文末还附上了一份全面的参考指南(参见Postgres与SQL Server索引对比表)。无论你是在优化查询,还是在规划迁移,这些差异都会对性能和索引策略产生显著影响。
PostgreSQL与SQL Server中B树索引的工作原理
从宏观层面来看,这两种数据库都使用B树索引来加快等值查询和范围查询的速度。B树保持有序状态,并且经过平衡处理,以确保稳定的读取性能。不过,尽管这两种数据库中B树的概念相似,但其实现方式却会对性能产生重要影响。
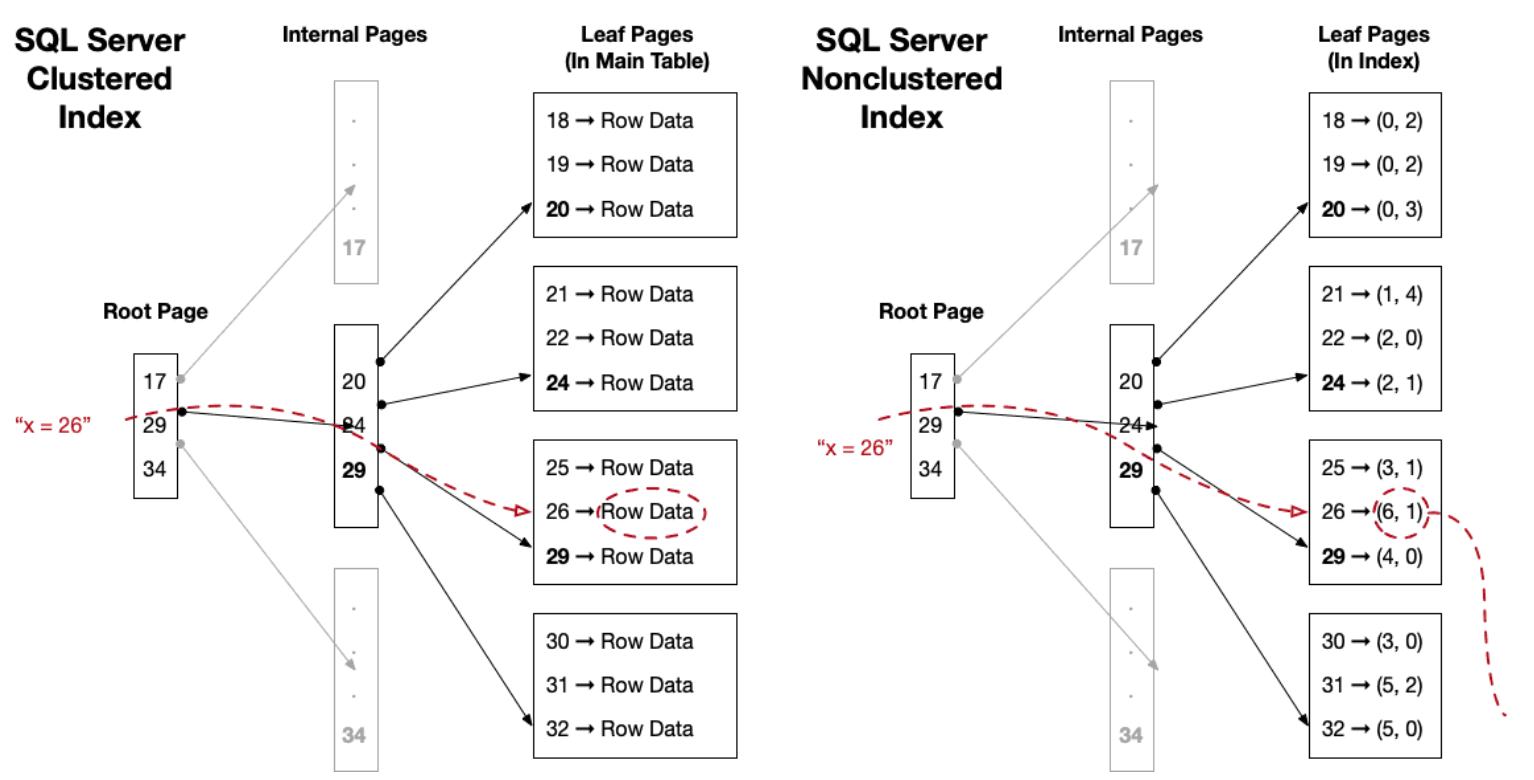
SQL Server 使用聚集索引通过索引列对表的数据进行物理排序。定义聚集索引后,表中的行将按照与索引本身相同的顺序存储。非聚集索引单独存储,并使用行定位符(RID 或聚集键)指向行。这种物理排序有利于范围扫描或分页查询,但这也意味着每个表只能有一个聚集索引。更重要的是,SQL Server 会完整存储每个索引项,即使同一页上的多个项具有相同的值。由于没有去重功能,因此包含许多重复值的索引可能会变得很大,并消耗过多的 I/O。
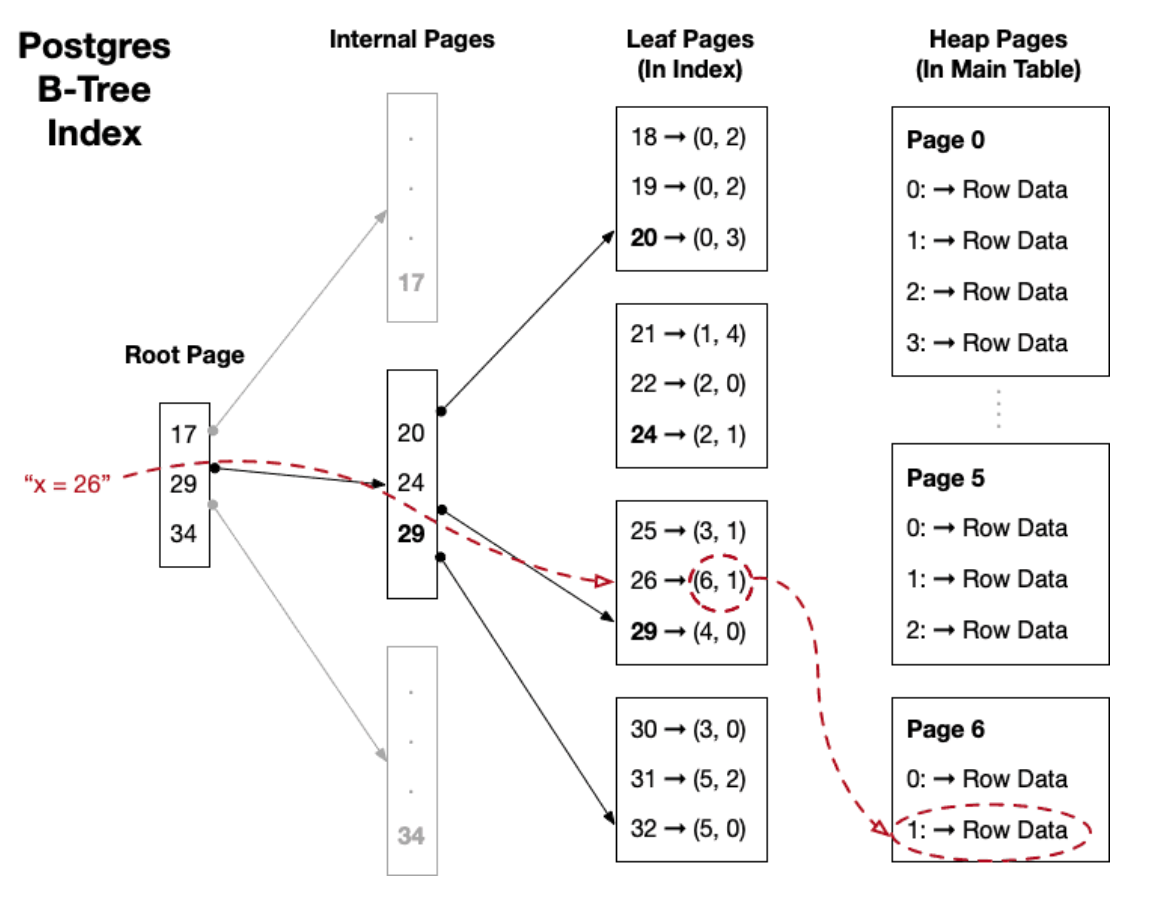
PostgreSQL没有SQL Server意义上的聚集索引。所有PostgreSQL表都存储为无序堆,而索引纯粹是指向堆中元组的逻辑结构。这种设计为PostgreSQL提供了一定的灵活性:它使索引维护更简单,并避免了物理重排的复杂性。
然而,这也意味着你不能依赖索引来定义表的物理布局。如果查询性能取决于按特定顺序读取数据,Postgres确实允许你运行CLUSTER命令,但这需要完整的表锁。在生产环境中,你可以使用pg_repack等工具来达到类似的效果。
因此,虽然这两种数据库都默认使用B树索引,但SQL Server的索引与物理存储之间的紧密耦合带来了一系列不同的预期和限制。PostgreSQL的索引模型存在一些性能缺陷(因为它没有聚簇索引的实现),但去重等独特功能使其在其他情况下表现更佳。
PostgreSQL的B树去重
PostgreSQL 13版本引入了去重功能,以解决传统B-Tree索引中一个常见的低效问题。当许多行共享相同的索引值(比如状态码、布尔标志或时间戳)时,标准的B-Tree会单独存储每个值及其对应的元组指针。这会导致索引页膨胀,并增加维护成本,对于写入密集型工作负载来说尤其如此。
PostgreSQL默认会对单个索引页内的重复值进行去重处理。它不会多次存储相同的键值,而是只存储一次,并维护一个紧凑的结构来跟踪所有匹配的堆指针。这能显著减小索引大小,并提高缓存性能,因为更多的索引条目可以放入内存中。
SQL Server不支持去重。即使值完全相同,每个索引项也会独立存储。在分布倾斜的数据集中,PostgreSQL的方法能生成更紧凑、更高效的索引,页面更少,磁盘I/O也更少。
在PostgreSQL与SQL Server上对B树索引进行基准测试
为了了解PostgreSQL的索引去重功能对实际性能和存储的影响,我们进行了一项基准测试,在不同的数据重复程度下比较PostgreSQL和SQL Server的B-Tree索引大小。每个测试都创建了一个包含1000万行的表,这些行的值重复程度各不相同,从完全唯一的值到重复1000倍的值不等。
以下是我们在两个数据库中构建测试的方式,以便您可以自行复现该测试。
PostgreSQL测试设置
CREATE TABLE factor_1(col int);
CREATE TABLE factor_10(col int);
CREATE TABLE factor_100(col int);
CREATE TABLE factor_1000(col int);INSERT INTO factor_1 SELECT * FROM GENERATE_SERIES(1, 10000000);
INSERT INTO factor_10 SELECT val / 10 FROM GENERATE_SERIES(1, 10000000) x(val);
INSERT INTO factor_100 SELECT val / 100 FROM GENERATE_SERIES(1, 10000000) x(val);
INSERT INTO factor_1000 SELECT val / 1000 FROM GENERATE_SERIES(1, 10000000) x(val);CREATE INDEX factor_1_idx ON factor_1(col);
CREATE INDEX factor_10_idx ON factor_10(col);
CREATE INDEX factor_100_idx ON factor_100(col);
CREATE INDEX factor_1000_idx ON factor_1000(col);CREATE INDEX factor_1_idx_no_dup_fill100 ON factor_1(col) WITH (deduplicate_items = off, fillfactor = 100);
CREATE INDEX factor_10_idx_no_dup_fill100 ON factor_10(col) WITH (deduplicate_items = off, fillfactor = 100);
CREATE INDEX factor_100_idx_no_dup_fill100 ON factor_100(col) WITH (deduplicate_items = off, fillfactor = 100);
CREATE INDEX factor_1000_idx_no_dup_fill100 ON factor_1000(col) WITH (deduplicate_items = off, fillfactor = 100);
SQL Server 测试设置
CREATE TABLE factor_1(col int);
CREATE TABLE factor_10(col int);
CREATE TABLE factor_100(col int);
CREATE TABLE factor_1000(col int);INSERT INTO factor_1 SELECT * FROM GENERATE_SERIES(1, 10000000);
INSERT INTO factor_10 SELECT value / 10 FROM GENERATE_SERIES(1, 10000000);
INSERT INTO factor_100 SELECT value / 100 FROM GENERATE_SERIES(1, 10000000);
INSERT INTO factor_1000 SELECT value / 1000 FROM GENERATE_SERIES(1, 10000000);CREATE INDEX factor_1_idx ON factor_1(col);
CREATE INDEX factor_10_idx ON factor_10(col);
CREATE INDEX factor_100_idx ON factor_100(col);
CREATE INDEX factor_1000_idx ON factor_1000(col);
基准测试结果:PostgreSQL的去重功能减小了索引大小
当我们对比PostgreSQL和SQL Server的索引大小时,发现随着数据重复率的增加,两者的差异显著扩大。当值重复1000次时,启用去重功能的PostgreSQL索引比关闭去重功能的相同索引小3倍。而SQL Server不支持去重功能,会完整存储每个重复值,相比之下,PostgreSQL始终能生成更小、更高效的索引。
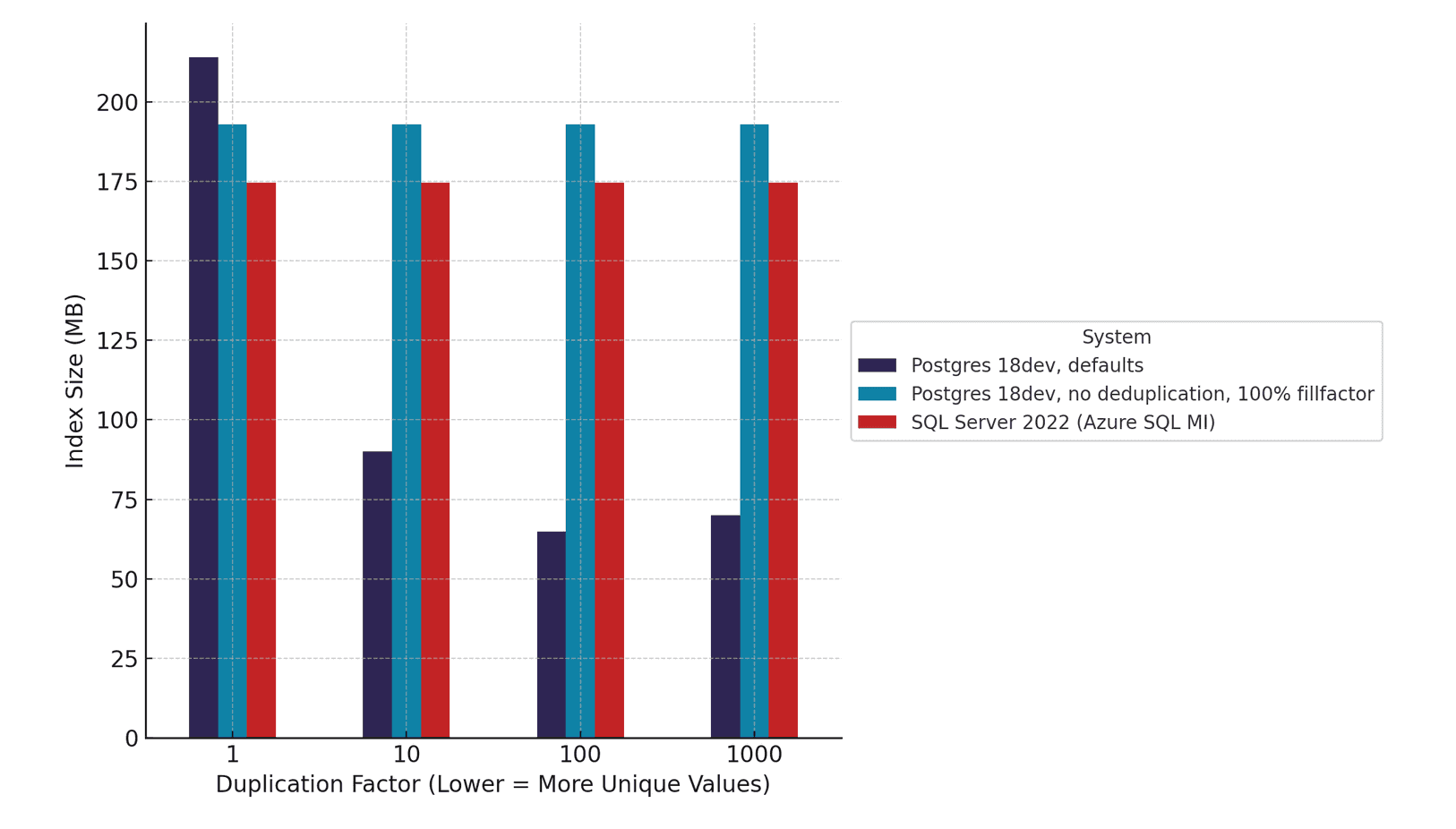
这种差异至关重要。在生产系统中,状态标志、时间戳和分类字段等基数较高的列很常见。当这些值在数百万行中重复出现时,大型索引会迅速成为性能瓶颈,导致扫描速度变慢、I/O 增加以及内存使用量膨胀。
PostgreSQL的去重功能显著减小了索引大小,这使得索引更易于保存在内存中,并减轻了磁盘压力。对于从SQL Server迁移到PostgreSQL的团队,或者只是通过频繁使用的索引来扩展工作负载的团队而言,这种优化并非只是理论层面的。它对资源使用、查询性能和整体运营效率都有着直接影响。
对比表:PostgreSQL 与 SQL Server 的索引
PostgreSQL和SQL Server在B树及其他索引类型的索引实现上存在显著差异。我们整理了一份全面的索引对比表,供您在从SQL Server迁移到PostgreSQL时参考。
(某些索引类型存在于SQL Server中,但不存在于PostgreSQL中,反之亦然。我们已按如下方式标注支持情况:🟢 支持的索引类型 🔴 不支持的索引类型。)
| 索引类型 | 使用案例示例 | PostgreSQL | SQL Server |
|---|---|---|---|
| B-Tree | 最适合通用索引、等值查询和范围查询(例如,按年龄或日期筛选用户)。 | 🟢 默认索引类型,支持等值查询和范围查询、排序以及带前缀的模式匹配。 | 🟢 在SQL Server上,聚集索引和非聚集索引的默认结构是B-Tree。 |
| Clustered | 按索引键自动对表行进行排序;最适合频繁排序的查询。 | 🔴 PostgreSQL 没有聚簇索引;相反,您可以使用 CLUSTER 命令根据非聚簇索引对表进行排序;但是,当插入新数据时,这种顺序不会被保留。 | 🟢 相当于PostgreSQL的B树;根据键对数据进行排序和存储。 |
| Nonclustered | 适用于可加快搜索速度且不影响物理存储顺序的索引。 | 🟢 在PostgreSQL中,所有索引都是非聚集索引。 | 🟢 可以在堆或聚集索引上创建;数据存储与表分开。 |
| Hash | 针对精确匹配查找进行了优化,例如按用户ID或电子邮件地址搜索。 | 🟢 在PostgreSQL中,哈希索引只能为单个列建立索引。虽然你可以创建多个索引来支持查询,但通常多列B-Tree索引更为有效。 | 🟢 用于内存优化表;需要固定的桶数量。 |
| Filtered / Partial | 对数据子集(例如仅活跃用户)进行索引时效率很高。 | 🟢 PostgreSQL 可以使用部分索引仅对行的一个子集进行索引。 | 🟢 筛选索引是一种非聚集索引,仅对表中的一部分行进行索引。 |
| BRIN | 最适合数据自然有序的超大型表格,例如时间序列数据。 | 🟢 存储块范围的摘要;最适合大型、顺序存储的数据。 | 🔴 N/A 🔴 不适用 |
| Full-text | 用于自然语言搜索,例如搜索文章或产品评论中的文本。 | 🟢 PostgreSQL支持通过在tsvector列上使用GIN索引来进行全文搜索。 | 🟢 SQL Server 对基于文本的查询使用倒排索引,类似于 PostgreSQL 的 GIN。 |
| GIN | 非常适合为JSONB、数组和全文搜索建立索引(例如,搜索产品描述)。 | 🟢 倒排索引;最适用于JSON、全文搜索和数组。 | 🔴 通过全文索引实现部分功能。 |
| Vector | 在高维数据中高效执行相似性搜索或最近邻搜索,这在人工智能和机器学习应用中最为常见。 | 🟢 PostgreSQL本身不包含向量支持,但开源扩展pgvector支持向量存储和索引。 | 🔴 SQL Server本身不支持向量索引或搜索。微软建议改用其Azure AI搜索。 |
| XML | 针对查询和存储XML文档进行了优化。 | 🔴 PostgreSQL 不直接支持在 XML 类型上创建索引;但是,可以在 XML 数据的子集上使用表达式索引。对于非结构化文档,JSONB 是推荐的数据类型。 | 🟢 SQL Server 对 XML 数据类型有专用索引。 |
| Spatial | 用于地理查询,例如查找半径范围内的位置。 | 🟢 在PostgreSQL中,空间索引查询由开源的PostGIS扩展提供。 | 🟢 SQL Server 具有内置的空间数据类型。 |
| SP-GiST | 用于层级数据结构,如基于树的搜索(例如路由网络)。 | 🟢 支持非平衡树结构,如四叉树和k-d树,适用于分层数据。 | 🔴 N/A 🔴 不适用 |
| GiST | 适用于几何和全文搜索查询,例如查找附近的位置。 | 🟢 专用索引的基础架构;用于几何和全文搜索。 | 🔴 N/A 🔴 不适用 |
| Columnstore | 最适合OLAP工作负载和分析查询(例如,数据仓库)。 | 🔴 虽然PostgreSQL有不同的扩展提供列式存储,如Citus和Timescale,但这是一个相对较新的实现,可能会受使用场景的限制。 | 🟢 自SQL Server 2012起,SQL Server就内置了作为索引类型实现的列存储。 |
为你的工作选择合适的索引
理解PostgreSQL和SQL Server索引之间的差异,在优化查询性能、规划迁移或设计高性能数据库时至关重要。选择合适的索引策略需要深入了解查询执行模式和性能权衡。许多团队会手动尝试不同的索引策略,这可能导致过度索引、冗余索引或错失优化机会。
与反复试验不同,pganalyze 索引顾问通过针对真实查询执行数据应用约束编程模型,自动检测缺失的索引、冗余的索引以及多列索引的最佳列顺序。这消除了猜测工作,确保PostgreSQL数据库的索引设置能实现最佳性能。

)

:入门从0到1(零基础))
快速排序)


与XGBoost)



- MTK phy-mtk-hdmi.c 和 phy-mtk-hdmi-mt8173.c)







